Note de l'auteur : Plongée au cœur des causes profondes des surcharges fréquentes de l'API Nano Banana Pro. De l'architecture des puces TPU de Google aux différences entre AI Studio et Vertex AI, découvrez la vérité technique derrière cette pénurie.
Depuis son lancement en novembre 2025, les développeurs font face à un phénomène déroutant : même si Google possède ses propres puces TPU, l'API de génération d'images affiche fréquemment des erreurs de "surcharge du modèle". Pourquoi les puces maison ne résolvent-elles pas le problème de puissance de calcul ? Quelle est la différence fondamentale entre AI Studio et Vertex AI ? Cet article part de la logique de base de l'architecture de calcul de Google pour analyser ces questions en profondeur.
Valeur ajoutée : Grâce à des données réelles et une analyse d'architecture, nous vous aidons à comprendre les causes profondes des problèmes de stabilité de Nano Banana Pro et à choisir une solution d'accès API plus fiable.
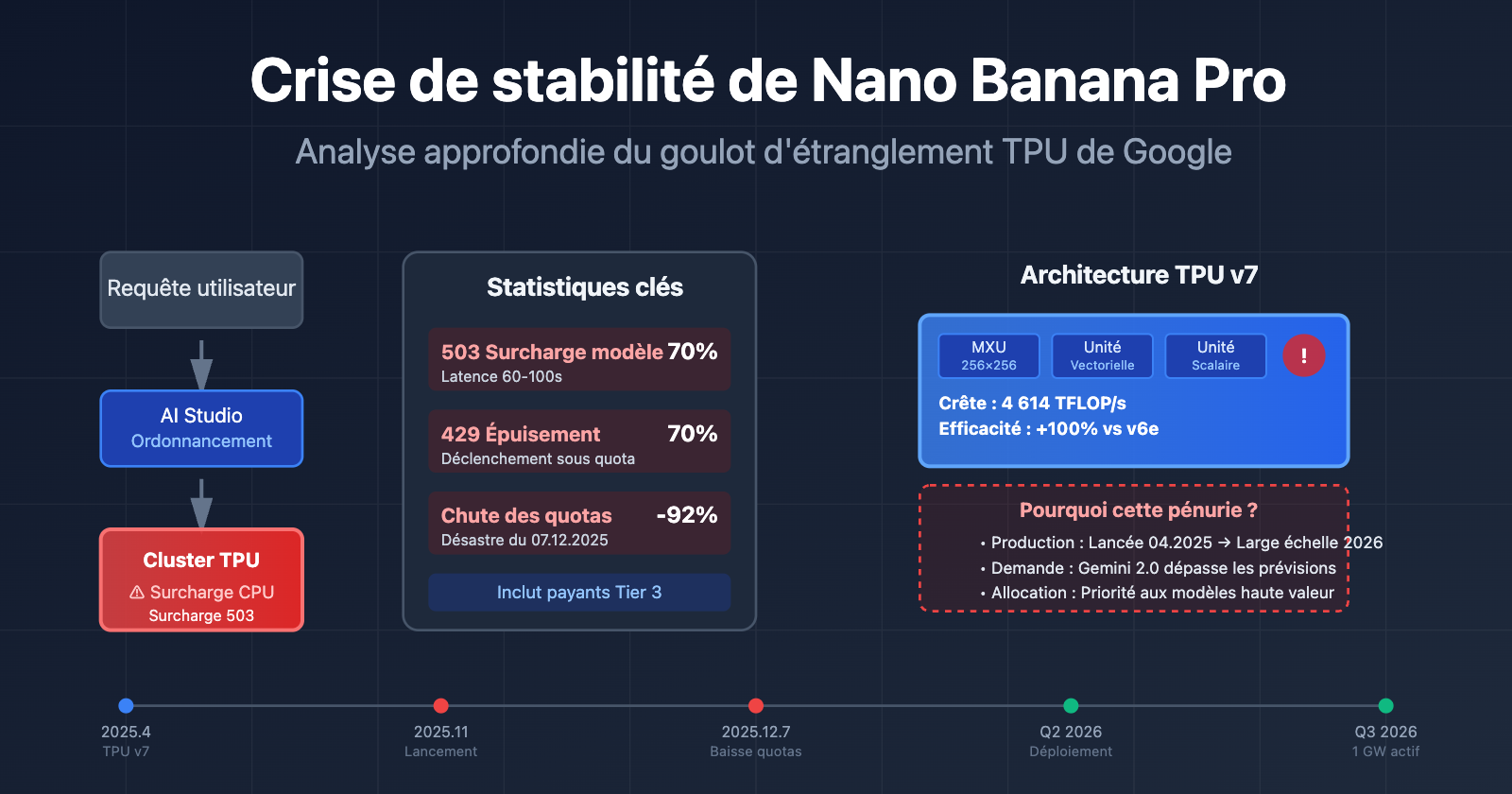
Problèmes centraux de stabilité de l'API Nano Banana Pro
Depuis son lancement en novembre 2025, Nano Banana Pro (gemini-2.0-flash-preview-image-generation) traverse une crise de stabilité persistante. Voici les données sur les principaux problèmes signalés par la communauté des développeurs :
| Type de problème | Fréquence d'occurrence | Manifestations typiques | Périmètre d'impact |
|---|---|---|---|
| 503 Surcharge du modèle | Haute fréquence (plus de 70 % des erreurs) | Le temps de réponse passe brusquement de 30 secondes à 60-100 secondes | Tous les niveaux d'utilisateurs (y compris les abonnés Tier 3) |
| 429 Épuisement des ressources | Environ 70 % des erreurs API | Se déclenche même en étant bien en dessous des limites de quota | Utilisateurs du niveau gratuit et abonnés Tier 1 |
| Réduction soudaine des quotas | 7 décembre 2025 | Le niveau gratuit passe de 3 à 2 images/jour, le 2.5 Pro est retiré du niveau gratuit | Utilisateurs du niveau gratuit dans le monde entier |
| Service indisponible | Intermittent | Génération rapide la veille, indisponibilité totale le lendemain | Développeurs d'applications dépendant du niveau gratuit |
Les causes profondes de l'instabilité de Nano Banana Pro
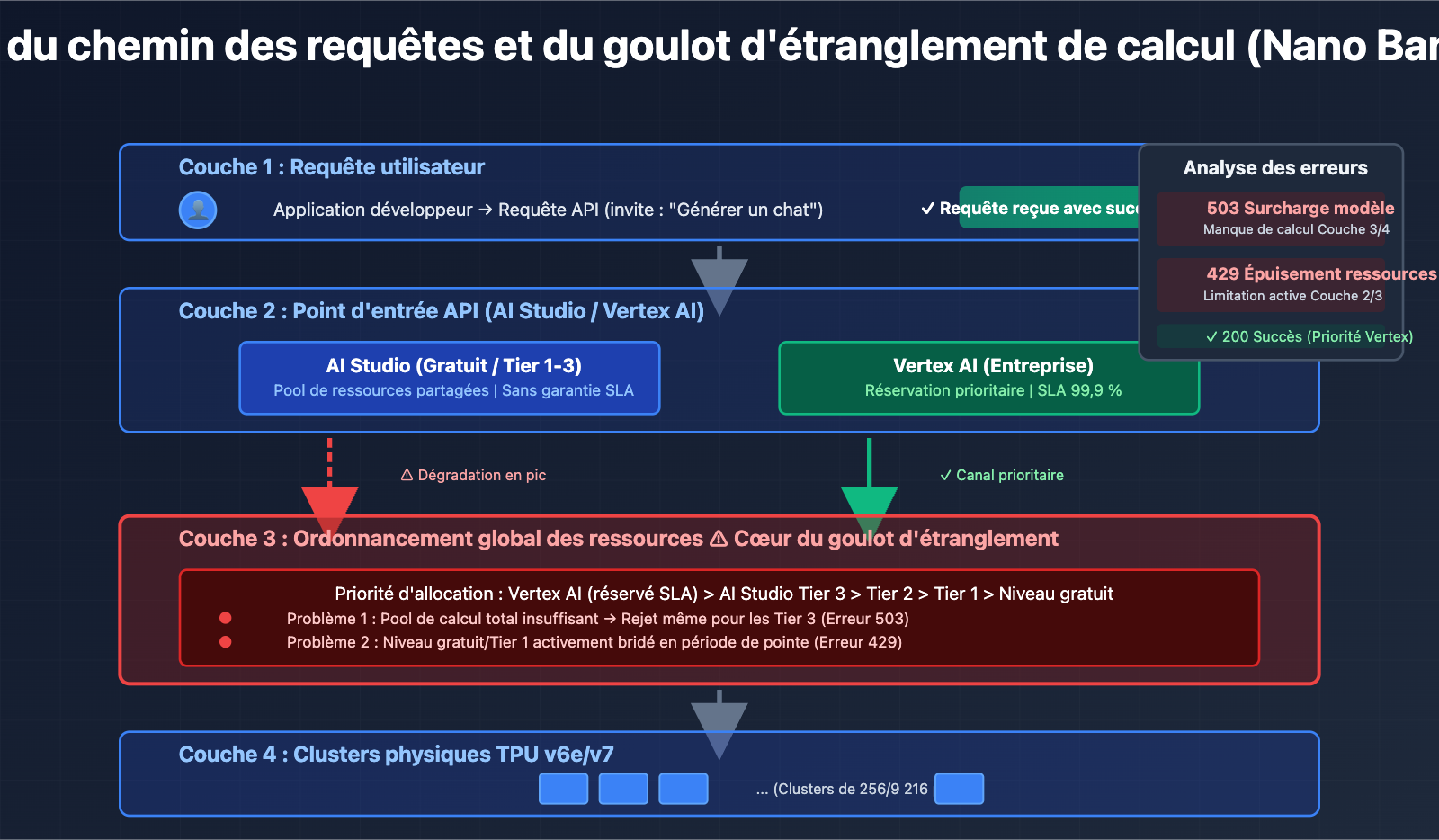
Le cœur de ces problèmes ne réside pas dans des défauts du code, mais dans un goulot d'étranglement de la capacité de calcul côté serveurs de Google. Même les utilisateurs Tier 3 (le niveau de quota le plus élevé) rencontrent des erreurs de surcharge alors que leur fréquence de requêtes est bien inférieure aux limites officielles. Cela démontre que le problème se situe au niveau de l'infrastructure et non de la gestion des quotas par utilisateur.
D'après les réponses officielles de Google sur les forums de développeurs, les ressources de calcul sont actuellement réallouées aux nouveaux modèles de la gamme Gemini 2.0, ce qui restreint la capacité disponible pour les modèles de génération d'images comme Nano Banana Pro. Cette stratégie d'allocation des ressources est la cause directe de l'instabilité du service.
🎯 Conseil technique : Pour utiliser Nano Banana Pro dans un environnement de production, il est recommandé de passer par la plateforme APIYI (apiyi.com). Cette plateforme propose un équilibrage de charge intelligent et des mécanismes de basculement automatique, ce qui permet d'améliorer significativement le taux de réussite et la stabilité des appels API.
La vérité sur l'architecture des puces TPU de Google
Beaucoup pensent que Google, avec ses propres puces TPU (Tensor Processing Unit), devrait pouvoir répondre facilement aux besoins de calcul des grands modèles de langage. Mais la réalité est bien plus complexe qu'on ne l'imagine.
L'architecture de pointe du TPU v7 (Ironwood)
En avril 2025, lors de la conférence Cloud Next, Google a dévoilé la septième génération de ses TPU : Ironwood. C'est la version la plus puissante à ce jour :
| Paramètres d'architecture | TPU v7 (Ironwood) | TPU v6e (Trillium) | Amélioration |
|---|---|---|---|
| Puissance de calcul brute | 4 614 TFLOP/s | env. 2 300 TFLOP/s | ~100 % |
| Efficacité énergétique | Référence | Comparaison | Performance/Watt boostée de 100 % |
| Configuration de cluster | 256 puces / 9 216 puces | Configuration unique | Capacité d'extension flexible |
| Unités de matrice | 256×256 MXU (systolic array) | 128×128 MXU | Densité de calcul multipliée par 4 |
| Scénarios d'application | L'ère de l'inférence (Inference-first) | Mixte entraînement/inférence | Optimisation spécifique pour l'inférence |
Les composants clés de l'architecture TPU
Chaque puce TPU contient un ou plusieurs TensorCores. Chaque TensorCore est composé des éléments suivants :
- Unités de multiplication matricielle (MXU) : Les TPU v6e et v7 utilisent des réseaux de multiplieurs-accumulateurs 256×256 (contre 128×128 pour les versions précédentes).
- Unités vectorielles : Pour traiter les opérations non matricielles.
- Unités scalaires : Pour gérer la logique de contrôle.
Cette architecture en "systolic array" (réseau systolique) est particulièrement adaptée à l'inférence de réseaux de neurones, mais elle a aussi ses limites.
Pourquoi les puces maison ne règlent-elles pas la pénurie de puissance ?
Malgré la puissance du TPU v7, les problèmes de stabilité de Nano Banana Pro persistent pour trois raisons principales :
1. Le cycle de montée en charge de la production
Le TPU v7 a été annoncé en avril 2025, mais son déploiement massif prend du temps. Google a annoncé fin 2025 un partenariat de dix milliards de dollars avec Anthropic, prévoyant de mettre en ligne plus de 1 GW de puissance IA en 2026. Cela signifie que la période allant de novembre 2025 au début de 2026 est une phase de transition, où la cohabitation des anciennes et nouvelles architectures crée des tensions sur les ressources disponibles.
2. L'explosion de la demande
Après la sortie de la série Gemini 2.0 fin 2025, le volume de requêtes API a dépassé toutes les prévisions initiales de Google. L'afflux d'utilisateurs sur le palier gratuit (notamment pour la génération d'images via Nano Banana Pro) a directement empiété sur les ressources dédiées aux utilisateurs payants.
3. Priorité d'allocation des ressources
Google doit jongler avec les besoins de calcul de plusieurs lignes de produits IA : Gemini 2.5 Pro (texte), Gemini 2.0 Flash (multimodal), Nano Banana Pro (génération d'images), etc. Quand la puissance de calcul manque, les modèles ayant la plus forte valeur commerciale sont prioritaires, ce qui entraîne directement les limitations de capacité constatées sur Nano Banana Pro.
🎯 Analyse d'architecture : Concevoir ses propres puces ne signifie pas disposer d'une puissance infinie. La capacité de production des puces, la construction des centres de données et l'approvisionnement en énergie sont autant de goulots d'étranglement. Nous conseillons aux entreprises d'utiliser la plateforme APIYI (apiyi.com) pour bénéficier d'une orchestration multi-cloud et éviter les risques de saturation liés à un fournisseur unique.
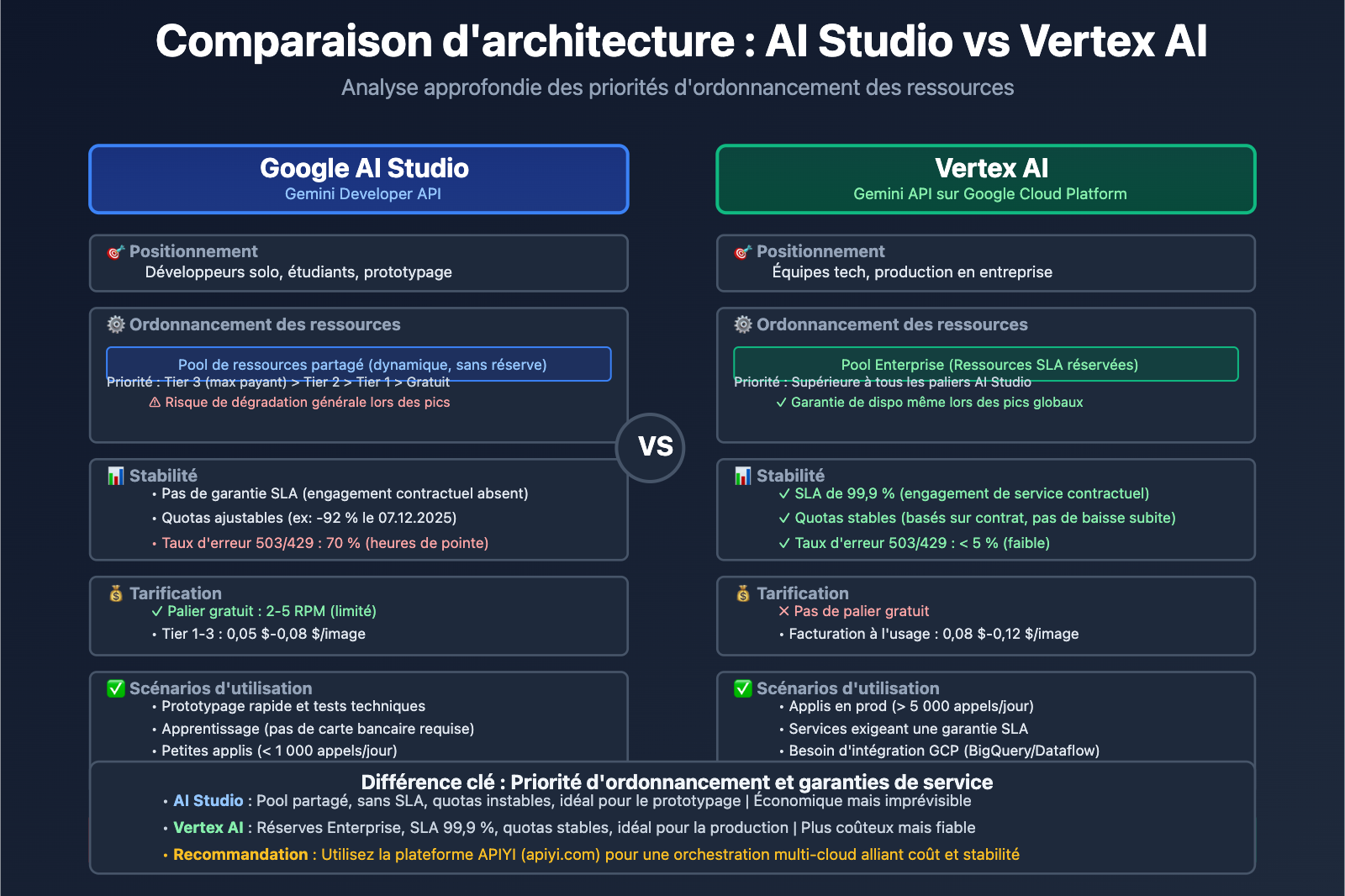
AI Studio vs Vertex AI : Les différences fondamentales
Beaucoup de développeurs se posent la question : si Gemini AI Studio et Vertex AI permettent tous deux d'appeler les modèles Gemini, pourquoi y a-t-il de telles différences de stabilité et de quotas ? La réponse réside dans le positionnement architectural de chaque plateforme.
Comparaison des plateformes
| Dimension | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API sur GCP) |
|---|---|---|
| Utilisateurs cibles | Développeurs individuels, étudiants, startups | Équipes en entreprise, applications en production |
| Seuil d'entrée | Une simple clé API suffit pour prototyper en quelques minutes | Nécessite un compte Google Cloud et une configuration de facturation |
| Modèle de tarification | Palier gratuit (limité) + Payant (Tier 1/2/3) | Facturation à l'usage (pas de palier gratuit), intégré à GCP |
| Garantie SLA | Aucun SLA (Service Level Agreement) | SLA de classe entreprise, 99,9 % de disponibilité garantie |
| Étendue des fonctions | API d'appel de modèle + outil de prototypage visuel | Workflow ML complet (labellisation, entraînement, fine-tuning, déploiement, monitoring) |
| Stabilité des quotas | Soumis à l'ordonnancement global, les quotas peuvent varier | Quotas réservés pour les entreprises, priorité d'allocation |
Atouts et limites de AI Studio
Avantages :
- Prise en main ultra-rapide : Obtenez une clé API immédiatement sans configurer de services cloud complexes.
- Outil de prototypage visuel : Interface de test d'invites (prompts) intégrée pour itérer rapidement.
- Généreux pour les tests : Idéal pour l'apprentissage, l'expérimentation et les petits projets.
Limites :
- Pas de garantie SLA : La disponibilité du service n'est pas contractuelle.
- Quotas instables : Comme lors de la réduction soudaine du 7 décembre 2025, où Gemini 2.5 Pro a été retiré du palier gratuit et les limites de 2.5 Flash ont chuté de 250 à 20 appels par jour (une baisse de 92 %).
- Manque de fonctionnalités entreprise : Impossible d'intégrer nativement BigQuery, Dataflow ou d'autres services de données GCP.
Les capacités "Entreprise" de Vertex AI
Atouts majeurs :
- Priorité des ressources : Les requêtes des utilisateurs payants sont prioritaires dans le système d'ordonnancement interne de Google.
- Intégration MLOps : Gestion complète du cycle de vie des modèles (entraînement, versions, tests A/B, alertes).
- Souveraineté des données : Possibilité de choisir la région de stockage des données pour se conformer au RGPD ou à d'autres réglementations.
- Support dédié : Accès à des équipes de support technique et de conseil en architecture.
Scénarios d'utilisation :
- Applications en production dépassant 10 000 requêtes par jour.
- Projets nécessitant du fine-tuning (ajustement fin) ou un entraînement personnalisé.
- Entreprises exigeant des garanties strictes sur la disponibilité et les temps de réponse.
🎯 Notre conseil : Si votre application a dépassé le stade du prototype et que vous dépassez les 5 000 appels quotidiens, migrez vers Vertex AI ou passez par une plateforme unifiée comme APIYI (apiyi.com). Ce type de plateforme agrège les ressources de plusieurs fournisseurs cloud pour permettre un basculement intelligent via une interface unique, alliant la simplicité de AI Studio à la robustesse de Vertex AI.
Les raisons profondes de la pénurie de Nano Banana Pro
D'après les analyses précédentes, on peut résumer la pénurie persistante de Nano Banana Pro en trois grands facteurs clés :
1. Aspect technique : Déséquilibre entre capacité de calcul et demande
- Montée en puissance des TPU v7 : Lancés en avril 2025, leur déploiement massif ne sera finalisé qu'en 2026.
- Priorité à l'entraînement sur l'inférence : Les tâches d'entraînement de la série Gemini 3.0 mobilisent une part immense des ressources TPU v6e et v7.
- Intensité de calcul de la génération d'images : L'inférence du modèle de diffusion (Diffusion Model) de Nano Banana Pro nécessite 5 à 10 fois plus de puissance de calcul qu'un modèle textuel.
2. Aspect commercial : Ajustement de la stratégie de l'offre gratuite
| Chronologie | Changement de politique | Raison du contexte |
|---|---|---|
| Novembre 2025 | Lancement de Nano Banana Pro, offre gratuite : 3 images/jour | Obtenir rapidement des retours utilisateurs et s'imposer sur le marché. |
| 7 décembre 2025 | Offre gratuite réduite à 2 images/jour, retrait de Gemini 2.5 Pro du plan gratuit | Les coûts de calcul dépassent le budget, nécessité de freiner la croissance des utilisateurs gratuits. |
| Janvier 2026 | RPM (Requêtes Par Minute) de l'offre gratuite passe de 10 à 5 | Réservation de ressources pour les clients entreprises de Gemini 2.0 Flash. |
Google a explicitement déclaré sur ses forums officiels que ces ajustements visaient à "garantir une qualité de service durable". En réalité, l'explosion du nombre d'utilisateurs gratuits (notamment via des outils d'automatisation et des appels en masse) a provoqué une dérive des coûts, obligeant Google à durcir ses règles.
3. Aspect architectural : Isolation des ressources entre AI Studio et Vertex AI
Bien que les deux plateformes exploitent les mêmes modèles sous-jacents, elles n'ont pas la même priorité dans l'ordonnancement des ressources de Google :
- Vertex AI : Connecté directement au pool de calcul de niveau entreprise de GCP, bénéficiant de réservations de ressources avec garanties SLA.
- AI Studio : Partage un pool de ressources globales, avec un risque de dégradation de service lors des pics d'utilisation.
Cette conception fait que les utilisateurs de l'offre gratuite et du Tier 1 sur AI Studio sont bien plus susceptibles de rencontrer des erreurs 429/503, tandis que les utilisateurs payants de Vertex AI sont moins impactés.
4. Stratégie produit : De la "conquête de marché" à "l'optimisation de la rentabilité"
Au lancement, Google a adopté une stratégie agressive de gratuité pour contrer DALL-E 3 et Midjourney. Cependant, face à l'explosion de la base d'utilisateurs, Google a réalisé que le modèle gratuit n'était pas viable à cette échelle et a commencé à privilégier les "utilisateurs payants à haute valeur ajoutée".
Le point de bascule a été la réduction des quotas et le retrait du plan gratuit de 2.5 Pro en décembre 2025, un événement que la communauté des développeurs a baptisé le "Free Tier Fiasco" (le fiasco de l'offre gratuite).
🎯 Stratégie de réponse : Pour les applications en production qui dépendent de Nano Banana Pro, nous vous conseillons d'adopter une stratégie de sauvegarde multi-cloud. Via la plateforme APIYI (apiyi.com), vous pouvez configurer des règles de basculement automatique entre Nano Banana Pro, DALL-E 3, Stable Diffusion, etc., sous une interface unique. Si un service est surchargé, le système bascule automatiquement vers une solution de secours pour assurer la continuité de votre activité.
Comment les développeurs peuvent gérer l'instabilité de Nano Banana Pro
Sur la base de nos analyses, voici quatre solutions techniques éprouvées :
Solution 1 : Implémenter un mécanisme de retry avec "Exponential Backoff"
import time
import random
def call_nano_banana_with_retry(prompt, max_retries=5):
"""Appel de l'API Nano Banana Pro avec une stratégie d'attente exponentielle"""
for attempt in range(max_retries):
try:
response = call_api(prompt) # Votre fonction d'appel API réelle
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
# Temps d'attente = (2 ^ tentative) + une variation aléatoire (jitter)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Erreur de surcharge détectée, attente de {wait_time:.2f} secondes avant nouvel essai...")
time.sleep(wait_time)
else:
raise e
raise Exception("Nombre maximal de tentatives atteint")
L'idée clé : Lorsqu'une erreur 503/429 survient, on augmente le temps d'attente de manière exponentielle (1s → 2s → 4s → 8s) pour éviter l'effet d'avalanche sur le serveur.
Implémentation complète de niveau production (cliquez pour dérouler)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, prompt: str, **kwargs) -> Optional[Dict[str, Any]]:
"""Méthode de génération d'image de niveau production avec gestion d'erreurs complète"""
for attempt in range(self.max_retries):
try:
# Logique réelle d'appel API
response = self._call_api(prompt, **kwargs)
logger.info(f"Requête réussie (tentative {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"Erreur {error_code}: {str(e)[:100]} | "
f"Attente {wait_time:.2f}s (tentative {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"Nombre max de tentatives atteint, échec final : {str(e)}")
raise
else:
logger.error(f"Erreur non rejouable : {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""Calcule le délai exponentiel avec 'jitter' pour éviter les tentatives synchronisées"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # Attente max de 60 secondes
def _parse_error_code(self, error: Exception) -> int:
"""Extrait le code d'état HTTP à partir de l'exception"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""Logique réelle d'appel API (à remplacer par l'implémentation réelle)"""
# Insérez ici votre code d'appel API
pass
# Exemple d'utilisation
client = NanoBananaClient(api_key="votre_cle_api")
result = client.generate_image("un chat mignon jouant du piano")
Solution 2 : Contrôle de l'intervalle entre les requêtes
D'après les retours de la communauté, ajouter un délai fixe de 5 à 10 secondes entre chaque requête peut réduire considérablement le taux d'erreurs 503 :
import time
def batch_generate_images(prompts):
"""Génération par lots avec contrôle strict de la fréquence"""
results = []
for i, prompt in enumerate(prompts):
result = call_api(prompt)
results.append(result)
if i < len(prompts) - 1: # Pas besoin d'attendre après la dernière requête
time.sleep(7) # Intervalle fixe de 7 secondes
return results
Cas d'usage : Applications non temps réel, comme la génération de contenu en masse ou le traitement de données hors ligne.
Solution 3 : Stratégie de sauvegarde multi-cloud
Mise en place d'un basculement automatique via une plateforme d'API unifiée :
| Étape | Implémentation technique | Résultat attendu |
|---|---|---|
| 1. Configurer les modèles | Nano Banana Pro (Principal) + DALL-E 3 (Secours) | Tolérance aux pannes sur point unique |
| 2. Définir les règles | 3 erreurs 503 consécutives → Basculement automatique | Réduction de la latence perçue par l'utilisateur |
| 3. Monitorer le rétablissement | Test de santé du service principal toutes les 5 min | Retour automatique au service principal |
🎯 Recommandation : La plateforme APIYI (apiyi.com) supporte nativement cette stratégie d'ordonnancement multi-cloud. Il vous suffit de configurer vos règles sur la console, et le système gère la détection des pannes, le basculement du trafic et l'optimisation des coûts sans modification de votre code métier.
Solution 4 : Passage à Vertex AI ou une plateforme entreprise
Si votre application remplit l'un des critères suivants, envisagez une montée en gamme :
- Volume quotidien d'appels API > 5 000.
- Exigences strictes en matière de SLA (ex: 95ème centile < 10 secondes).
- Interruption de service inacceptable (ex: génération d'images e-commerce, modération en temps réel).
Comparatif des coûts :
AI Studio Tier 1 : 0,05 $ / image (mais souvent surchargé)
Vertex AI : 0,08 $ / image (stable, avec SLA)
Plateforme APIYI : 0,06 $ / image (multi-cloud, tolérance aux pannes auto)
Bien que le prix unitaire de Vertex AI soit plus élevé, si l'on prend en compte le coût des tentatives infructueuses, le temps de développement et les pertes commerciales, le TCO (Coût Total de Possession) réel peut s'avérer plus faible.
Foire Aux Questions (FAQ)
Q1 : Pourquoi les utilisateurs payants rencontrent-ils aussi l'erreur "modèle surchargé" ?
R : Le goulot d'étranglement de la capacité de Nano Banana Pro se situe au niveau de la couche d'ordonnancement globale de la puissance de calcul de Google, et non au niveau du quota de l'utilisateur. Même si vous êtes un utilisateur payant de niveau Tier 3, vous recevrez toujours une erreur 503 lorsque le pool global de ressources de calcul est saturé. Cela diffère des erreurs classiques de dépassement de quota 429.
La différence est la suivante :
- Erreur 429 : Votre quota personnel est épuisé (ex: limite de RPM).
- Erreur 503 : La puissance de calcul côté serveur de Google est insuffisante, indépendamment de votre quota.
Q2 : AI Studio et Vertex AI appellent-ils le même modèle ?
R : Oui, le modèle Nano Banana Pro sous-jacent (gemini-2.0-flash-preview-image-generation) appelé par les deux est exactement le même. Cependant, leurs priorités d'ordonnancement des ressources diffèrent :
- Vertex AI : Garantie de SLA de classe entreprise, allocation prioritaire de la puissance de calcul.
- AI Studio : Pool de ressources partagées, risque de dégradation pendant les heures de pointe.
C'est un peu comme la différence entre le "paiement à l'usage" et les "instances réservées annuelles" pour les serveurs cloud.
Q3 : Google continuera-t-il à réduire les quotas de l'offre gratuite ?
R : Selon les tendances historiques, Google pourrait continuer à ajuster sa politique pour l'offre gratuite :
- Novembre 2025 : 3 images/jour pour l'offre gratuite.
- 7 décembre 2025 : Passage à 2 images/jour, retrait du 2.5 Pro.
- Janvier 2026 : Le RPM passe de 10 à 5.
La position officielle de Google est de "garantir une qualité de service durable", mais il s'agit en réalité de trouver un équilibre entre le contrôle des coûts et la croissance du nombre d'utilisateurs. Il est conseillé pour les applications en production de ne pas dépendre de l'offre gratuite et de prévoir des solutions payantes ou des sauvegardes multi-cloud à l'avance.
Q4 : Quand la stabilité de Nano Banana Pro s'améliorera-t-elle ?
R : Selon les informations publiques de Google, l'échéance clé est la mi-2026 :
- T2 2026 : Déploiement massif des TPU v7 (Ironwood) terminé.
- T3 2026 : Mise en service de 1 GW de puissance de calcul en collaboration avec Anthropic.
À ce moment-là, l'offre de puissance de calcul augmentera considérablement, mais la demande pourrait également croître en parallèle. Selon une estimation prudente, la stabilité s'améliorera substantiellement au second semestre 2026.
Q5 : Comment choisir son mode d'accès à Nano Banana Pro ?
R : Choisissez en fonction de l'étape de votre application :
| Étape | Solution recommandée | Raison |
|---|---|---|
| Développement de prototypes | AI Studio (offre gratuite) | Coût minimal, validation rapide des idées |
| Lancement à petite échelle | AI Studio Tier 1 + mécanisme de relance | Équilibre entre coût et stabilité |
| Environnement de production | Vertex AI ou plateforme APIYI | Garantie de SLA, support de classe entreprise |
| Activités critiques | Stratégie de sauvegarde multi-cloud (ex: plateforme APIYI) | Disponibilité maximale, basculement automatique |
🎯 Conseil de décision : Si vous hésitez, nous vous suggérons d'effectuer des tests A/B via la plateforme APIYI (apiyi.com). Cette plateforme permet de comparer les performances réelles de modèles comme Nano Banana Pro (AI Studio), Nano Banana Pro (Vertex AI) et DALL-E 3 pour une même requête, vous aidant ainsi à décider sur la base de données concrètes.
Conclusion : Porter un regard rationnel sur les défis de puissance de calcul de Nano Banana Pro
Les problèmes de stabilité de Nano Banana Pro ne sont pas des incidents isolés, mais le reflet de la contradiction entre l'offre et la demande de puissance de calcul à laquelle toute l'industrie de l'IA est confrontée :
Contradiction centrale :
- Côté demande : Croissance explosive des applications d'IA générative, en particulier dans le domaine de la génération d'images.
- Côté offre : Montée en charge lente de la production de puces, cycles de construction de centres de données longs (12 à 18 mois).
- Modèle économique : Les stratégies d'offre gratuite ne sont pas viables à long terme, mais le taux de conversion vers le payant reste faible.
Trois vérités techniques :
-
TPU maison ≠ Puissance de calcul infinie : Bien que Google dispose de puces avancées comme le TPU v7, la montée en cadence de la production, l'approvisionnement en énergie et la construction de centres de données prennent du temps. 2026 sera le tournant décisif.
-
L'essence de l'opposition AI Studio vs Vertex AI : Il ne s'agit pas d'une simple relation "version gratuite" contre "version payante", mais de priorités d'ordonnancement de ressources différentes. Derrière le SLA entreprise de Vertex AI se cache un mécanisme de réservation de puissance de calcul indépendant.
-
La pénurie va durer : Avec la sortie de la nouvelle génération de modèles comme Gemini 3.0 et GPT-5, la demande en puissance de calcul va continuer de croître. À court terme (2026-2027), la tension entre l'offre et la demande ne changera pas fondamentalement.
Conseils pratiques :
- À court terme : Utilisez des moyens techniques tels que des mécanismes de relance (retry) et le contrôle des intervalles de requêtes pour atténuer le problème.
- À moyen terme : Évaluez le ROI d'un passage à Vertex AI ou à une plateforme multi-cloud.
- À long terme : Suivez de près les progrès de l'extension de la puissance de calcul de Google à la mi-2026 et ajustez votre stratégie en conséquence.
Pour les applications d'entreprise, nous recommandons vivement d'adopter une stratégie de sauvegarde multi-cloud afin d'éviter les risques de capacité liés à un fournisseur unique. En utilisant une plateforme unifiée comme APIYI (apiyi.com), vous pouvez bénéficier de l'ordonnancement multi-cloud, du basculement automatique et de l'optimisation des coûts sans augmenter la complexité de votre code.
Dernière réflexion : Les défis de Nano Banana Pro nous rappellent que la stabilité des applications d'IA ne dépend pas seulement des capacités du modèle, mais aussi de la maturité de l'infrastructure sous-jacente. Dans cette ère où la puissance de calcul est reine, la robustesse de la conception architecturale et la diversification des fournisseurs deviennent des éléments clés de la compétitivité d'un produit.
Lectures complémentaires :
- Guide d'utilisation de l'API Nano Banana Pro
- Analyse approfondie de l'architecture Google TPU v7
- Comment choisir son API de génération d'images IA : Nano Banana Pro vs DALL-E 3 vs Stable Diffusion
- 10 meilleures pratiques pour les appels d'API d'IA en environnement de production