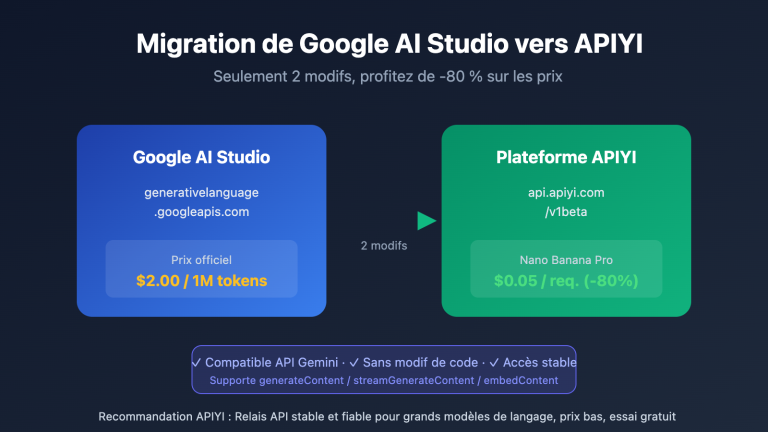
Beaucoup de designers se posent la même question lors de leur première rencontre avec GPT-Image-2 : lorsque je télécharge une photo et que je demande à l'IA de « changer la couleur des vêtements du personnage en bleu », est-ce qu'elle modifie les pixels avec précision comme Photoshop, ou est-ce qu'elle redessine l'image en arrière-plan ? La réponse à cette question influence directement la façon dont nous utilisons les outils d'édition d'images par IA et notre compréhension de la prévisibilité des résultats.
En réalité, il s'agit d'un détail technique largement mal compris. Cet article explore les principes de l'édition d'images par IA, en analysant en profondeur les mécanismes de fonctionnement des modèles d'image autorégressifs de nouvelle génération comme GPT-Image-2 et Nano Banana. Nous répondrons à la question fondamentale : « modification locale ou redessin complet ? » et révélerons comment ces modèles parviennent à maintenir une cohérence visuelle impressionnante tout en redessinant l'image entière.
| Question clé | Réponse intuitive | Réponse réelle |
|---|---|---|
| Méthode d'édition | Couverture locale type PS | Redessin par jetons (tokens) |
| Source de cohérence | Conservation des pixels non modifiés | Ancrage des caractéristiques via auto-attention |
| Architecture dominante | Débruitage par diffusion | Transformer autorégressif |
| Éditions multiples | Accumulation d'artefacts | Pas de dérive notable avec GPT-Image-2 |
Une fois ce principe compris, vous découvrirez que la rédaction des invites (prompts), l'utilisation des masques et les stratégies d'intégration des images de référence reposent sur de nouvelles bases théoriques. Nous conseillons aux lecteurs de tester ces concepts en temps réel via l'interface GPT-Image-2 sur la plateforme APIYI (apiyi.com) pour confronter la théorie à la pratique.
Principe de l'édition d'images par IA : pas de modification locale type PS, mais un redessin intelligent
De nombreux utilisateurs, basés sur leur expérience avec l'interface web de ChatGPT, pensent naturellement que l'édition d'images par IA ressemble à une « modification locale » dans Photoshop : le système identifie la zone à modifier, recouvre quelques pixels sur l'image originale, et laisse le reste intact. Ce modèle mental est intuitif, mais totalement erroné.
Tous les modèles d'édition d'images par IA dominants reposent essentiellement sur une logique de « redessin ». Qu'il s'agisse de GPT-Image-2, de Nano Banana ou de la série Stable Diffusion, ils doivent d'abord encoder l'image originale dans une représentation interne (jetons ou espace latent), puis le modèle « imagine » la représentation interne complète de la nouvelle image, avant de la décoder en pixels. Il n'existe aucune étape de « retouche directe » sur l'image originale.
C'est pourquoi, parfois, si vous demandez à l'IA de changer uniquement la couleur d'un œil, vous remarquerez que les mèches de cheveux ou la texture de l'arrière-plan ont également subi de légères modifications. Le modèle ne fait pas preuve de paresse ; il redessine effectivement l'image entière, mais il le fait de manière à ce que la plupart des zones soient extrêmement proches de l'original.
La question se pose alors : puisqu'il s'agit d'un redessin, pourquoi les images éditées par GPT-Image-2 semblent-elles si cohérentes avec l'original, permettant même des modifications répétées sans « dériver » ? La réponse réside dans son architecture. Si vous souhaitez vérifier ce comportement par vous-même, vous pouvez appeler l'interface /v1/images/edits de GPT-Image-2 sur APIYI (apiyi.com), utiliser la même invite pour modifier plusieurs fois la même image et observer les changements de détails.
Différences fondamentales entre la modification locale PS et le redessin par IA
| Dimension de comparaison | Modification locale Photoshop | Redessin intelligent GPT-Image-2 |
|---|---|---|
| Unité d'opération | Pixel | Jeton visuel (blocs 8×8 ou 16×16) |
| Zones non éditées | Physiquement inchangées | Reconstruites via encodage-décodage |
| Garantie de cohérence | 100% (copie directe des pixels) | Assurée par le mécanisme d'attention |
| Compréhension sémantique | Aucune, uniquement valeurs de pixels | Compréhension sémantique (vêtements, fond, lumière) |
| Transition des bords | Nécessite un adoucissement manuel | Transition naturelle automatique selon la sémantique |
Photoshop est une « modification mécanique » basée sur les pixels, tandis que l'IA est une « compréhension suivie d'un redessin » basée sur la sémantique. C'est pourquoi l'IA peut réaliser des modifications globales impossibles pour Photoshop, comme « transformer le jour en crépuscule » : elle modifie la représentation sémantique de l'image, et non les valeurs RVB des pixels.
Principe d'édition de gpt-image-2 : comment le Transformer autorégressif « comprend » l'image originale
Pour vraiment comprendre le principe d'édition de gpt-image-2, il est impossible de faire l'impasse sur un choix architectural clé fait par OpenAI lors du lancement de ce modèle le 21 avril 2026 : l'abandon des modèles de diffusion utilisés par la série DALL-E au profit d'un Transformer autorégressif. Cette décision s'inspire directement de l'architecture multimodale de GPT-4o.
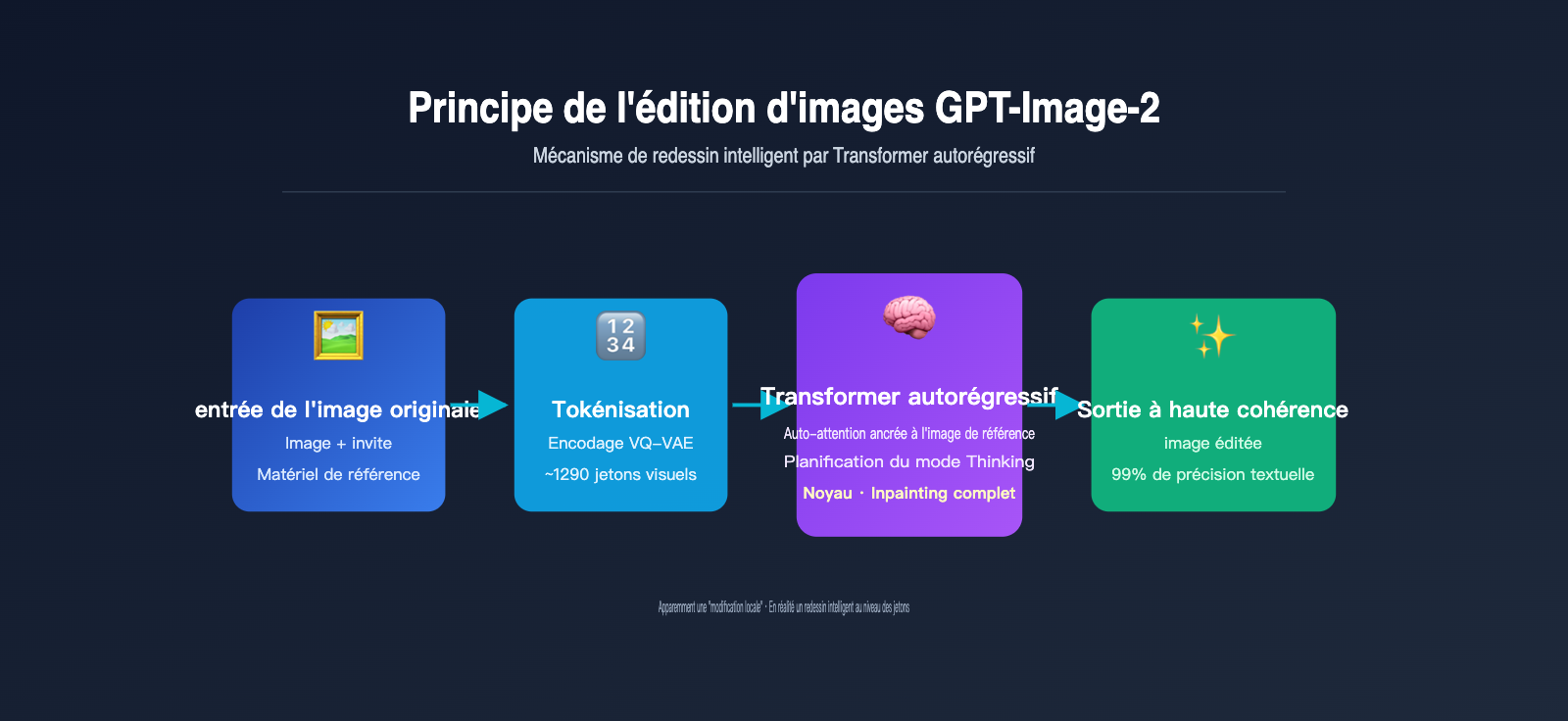
La génération autorégressive repose essentiellement sur le même mécanisme que celui utilisé par ChatGPT pour rédiger des textes : la prédiction du jeton (token) suivant. La différence ici est que le « jeton » n'est pas un mot, mais un jeton visuel. Le modèle procède comme suit :
- Tokénisation de l'image : grâce à un mécanisme de discrétisation similaire au VQ-VAE, l'image est découpée en environ 1024 à 1290 jetons visuels, chaque jeton correspondant approximativement à un bloc de 8×8 ou 16×16 pixels de l'image originale.
- Concaténation de séquences : les jetons de l'invite textuelle de l'utilisateur et les jetons visuels de l'image originale sont assemblés en une longue séquence, puis envoyés dans un Transformer unifié.
- Génération jeton par jeton : le modèle prédit chaque jeton visuel de l'image de sortie un par un, de gauche à droite (ou selon un ordre de balayage tramé). Chaque nouveau jeton généré peut « voir » toutes les entrées précédentes ainsi que le contenu déjà généré.
- Décodage en pixels : une fois tous les jetons visuels générés, ils sont convertis en une image matricielle finale via un décodeur.
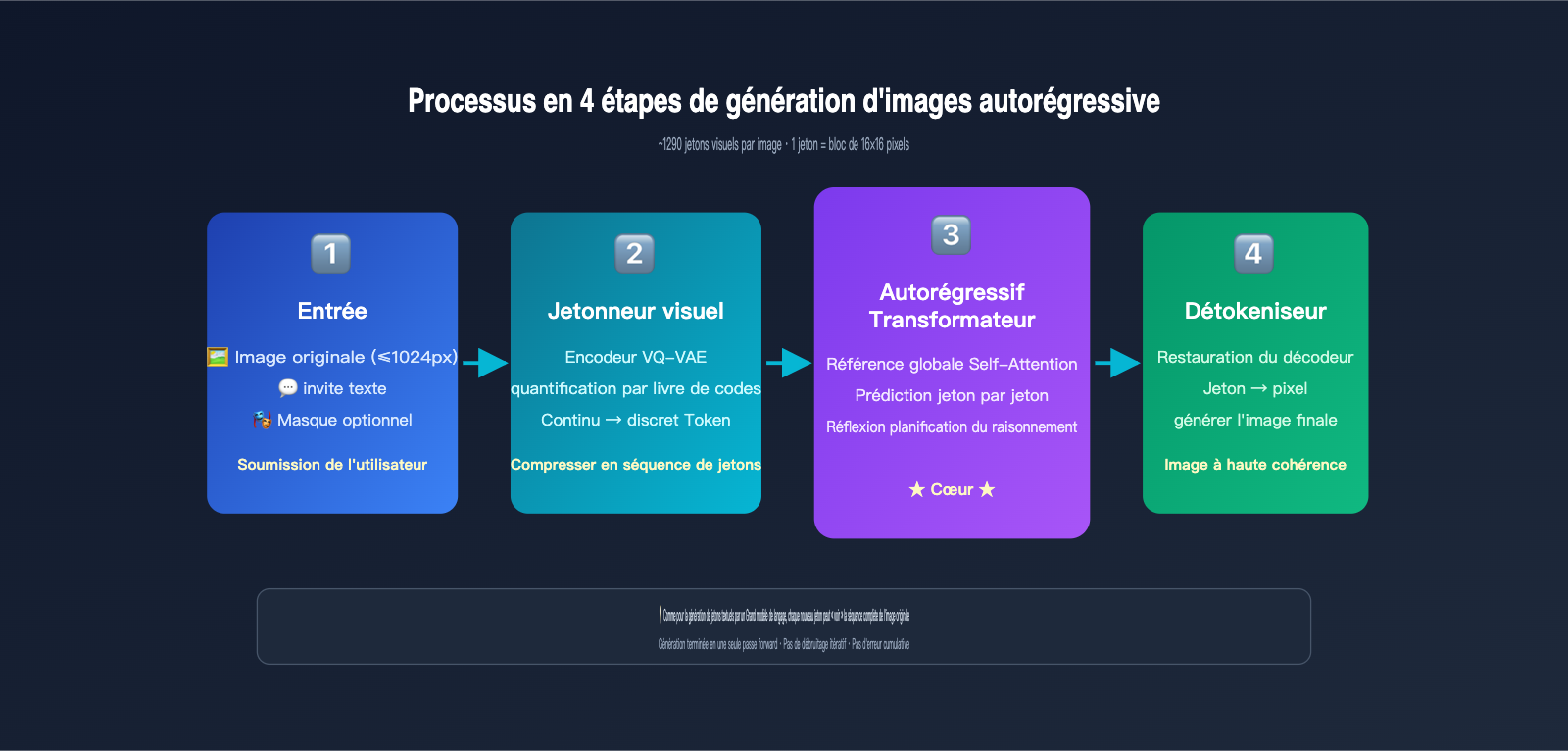
L'idée fondamentale ici est la suivante : lorsque GPT-Image-2 génère une nouvelle image, tous les jetons de l'image originale sont dans son « champ de vision ». C'est exactement le même principe que lorsque vous discutez avec ChatGPT : il peut voir tous les messages précédents. Le mécanisme d'auto-attention (Self-Attention) permet à chaque nouveau jeton généré de « se référer » aux caractéristiques de n'importe quelle partie de l'image originale.
OpenAI a également introduit un « mode réflexion » (Thinking mode) dans GPT-Image-2, permettant au modèle d'effectuer un raisonnement interne avant de commencer réellement à générer des jetons visuels : il analyse ce que l'utilisateur souhaite modifier, quelles parties doivent être conservées et comment organiser la disposition spatiale. Cela améliore considérablement la précision de l'exécution des instructions d'édition complexes, atteignant 99 % de précision textuelle et une disposition multi-objets très précise. Si vous avez besoin de tester ces capacités en environnement de production, vous pouvez accéder à gpt-image-2 via APIYI (apiyi.com), qui propose des spécifications d'interface conformes à celles de l'officiel et une commutation facile entre plusieurs modèles.
Tokenizer visuel : l'équilibre entre compression et conservation d'informations
Le tokenizer visuel est le goulot d'étranglement clé de tout système de génération d'image autorégressive. Il doit trouver un compromis entre deux objectifs :
- Taux de compression élevé : moins il y a de jetons, plus le Transformer traite rapidement et plus le coût est faible.
- Qualité de reconstruction élevée : les pixels décodés doivent restaurer l'image originale le plus fidèlement possible, sans perte de détails.
L'approche dominante est le VQ-VAE (Vector Quantized Variational Autoencoder) : un encodeur compresse les zones de l'image en un vecteur continu, qui est ensuite mappé vers un « livre de codes » fini pour trouver l'index du code le plus proche ; cet index constitue le jeton. Une image de 1024×1024 est généralement compressée en environ 1024 jetons, avec une densité d'informations extrêmement élevée.
C'est précisément parce que cette compression est intrinsèquement destructrice qu'aucun outil d'édition IA ne peut garantir une « conservation à 100 % des valeurs de pixels des zones non modifiées ». Cela nous amène à la question cruciale suivante : la cohérence.
Mécanismes fondamentaux de la cohérence d'image par IA : tokenisation visuelle et ancrage attentionnel
Puisque GPT-Image-2 procède à un redessin complet de l'image, comment la cohérence d'image par IA est-elle réellement préservée ? Pourquoi, lorsque vous retouchez un portrait, les traits de votre visage, votre teint ou votre coiffure ne se transforment-ils pas en ceux d'une autre personne ? La réponse tient en quatre niveaux.
Premier niveau : L'abstraction élevée des tokens visuels. Après le passage par le tokenizer, la séquence de tokens générée pour un visage encode les caractéristiques essentielles de "cette personne" : forme du visage, proportions des traits, carnation, etc. Tant que ces "tokens d'identité" sont globalement conservés lors de la génération de la nouvelle image, le personnage reste inchangé.
Deuxième niveau : La référence globale du Self-Attention. Lors de la génération de chaque nouveau token, le Transformer autorégressif calcule ses poids d'attention par rapport à tous les tokens d'entrée (y compris ceux de l'image originale). Si l'utilisateur n'a pas spécifié de modification pour une zone donnée, le modèle attribue un poids élevé aux tokens correspondants de l'image source, ce qui revient, dans les faits, à "copier" l'original.
Troisième niveau : Le biais inductif des données d'entraînement. OpenAI a utilisé une quantité massive de paires "image originale-image éditée" pour entraîner GPT-Image-2. Le modèle a appris une règle implicite : sauf demande explicite dans l'invite, il faut autant que possible laisser les autres zones intactes. Ce biais est ancré dans les poids du modèle et s'applique naturellement lors de l'inférence.
Quatrième niveau : La planification explicite du mode Thinking. GPT-Image-2 commence par une phase de réflexion interne pour identifier "quelles zones modifier et lesquelles conserver" avant de lancer la génération. C'est comme s'il se créait une liste de contrôle avant de commencer.
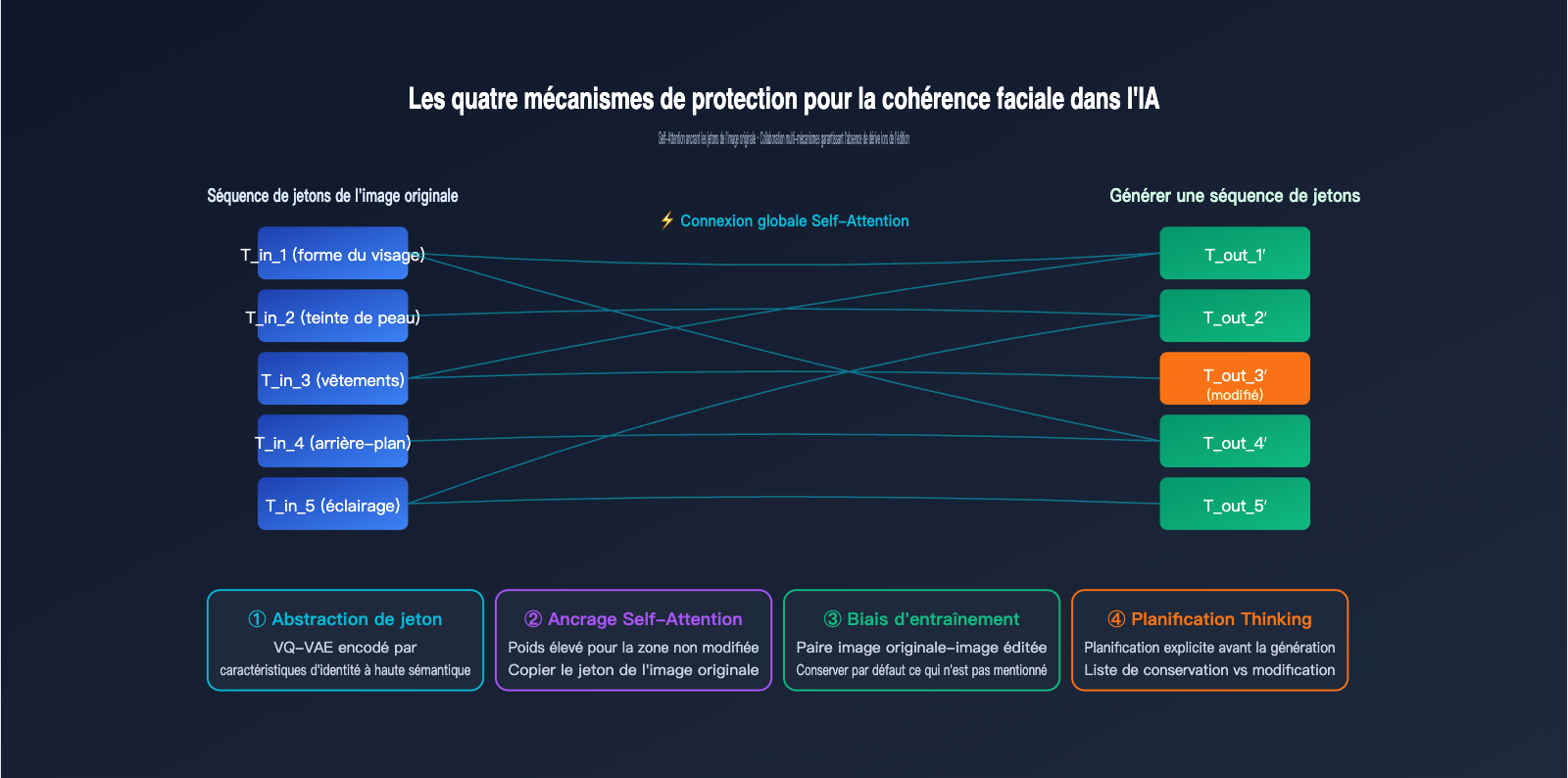
Comparaison des quatre niveaux de protection de la cohérence
| Niveau de mécanisme | Portée | Scénarios d'échec |
|---|---|---|
| Abstraction des tokens | Caractéristiques d'identité globales | Visage trop éloigné (tokens insuffisants) |
| Self-Attention | Ancrage des détails locaux | Conflit sémantique entre l'invite et l'original |
| Biais d'entraînement | Conservation par défaut des zones non mentionnées | Invite trop agressive |
| Planification Thinking | Instructions d'édition complexes | Nécessite plusieurs itérations de réglage |
En comprenant ces quatre niveaux de protection, vous serez capable de rédiger des invites plus précises pour éviter la "dérive". Par exemple, au lieu de dire "redessine les vêtements de cette personne", préférez "en conservant l'identité du personnage, change uniquement la couleur des vêtements du blanc au bleu". Lors de nos tests de GPT-Image-2 sur APIYI (apiyi.com), nous avons constaté que l'ajout de contraintes explicites, comme "garder les autres éléments inchangés", permet au mode Thinking d'être beaucoup plus efficace.
Mode masque : faire passer le redessin pour une modification locale
Si vous recherchez une expérience de "modification locale" plus certaine, GPT-Image-2 propose le paramètre mask via le point de terminaison /v1/images/edits. Vous pouvez transmettre une image de masque binarisée : les zones blanches autorisent l'IA à générer, tandis que les zones noires doivent impérativement conserver l'image originale.
Cependant, il est important de souligner que le mode masque ne change pas la nature du redessin. Son rôle est d'ajouter une contrainte stricte lors de la génération des tokens : les tokens correspondant aux zones noires doivent être strictement identiques aux tokens de l'image originale. Il s'agit d'une "génération sous contrainte" au sein du cadre autorégressif, et non d'une simple superposition de pixels à la Photoshop.
Modèles de diffusion vs Génération d'images autorégressive : Comparaison des principes de fonctionnement
Pour bien comprendre les avantages de GPT-Image-2, il est nécessaire de le comparer systématiquement à la génération précédente de modèles de diffusion (Stable Diffusion, DALL-E 3, Midjourney). Ces deux systèmes reposent sur des principes fondamentalement différents en matière d'édition d'images par IA.
Le flux de travail des modèles de diffusion commence par une image de pur bruit, qui subit des dizaines d'étapes de débruitage itératif pour faire apparaître progressivement l'image finale. Lors d'une édition, le modèle compresse d'abord l'image originale dans l'espace latent, ajoute une partie du bruit dans cet espace, puis utilise une invite pour guider le processus de débruitage, avant de décoder le tout en pixels. Le mode inpainting réinitialise, à chaque étape de débruitage, les zones latentes situées en dehors du masque pour les ramener à leur état original, permettant ainsi de "verrouiller" les zones non modifiées.
Le flux de travail des modèles autorégressifs est totalement différent : l'image est encodée en jetons (tokens), puis prédite jeton par jeton, exactement comme on rédigerait un texte. Il n'y a pas de débruitage itératif, pas de bruit latent, et la génération se fait en une seule passe.
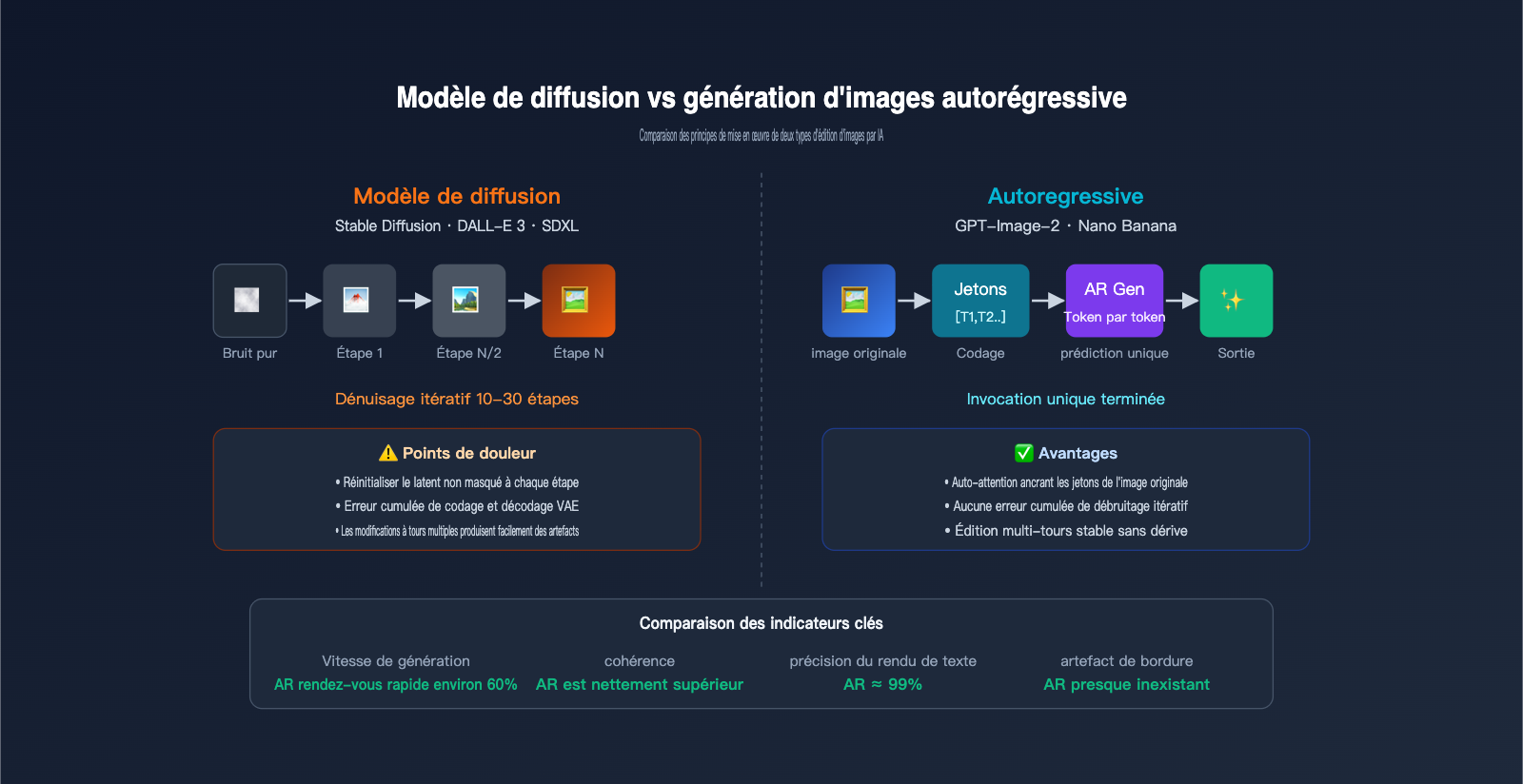
Les différences de performance entre ces deux paradigmes dans des scénarios d'édition d'image sont considérables, comme le montre le tableau ci-dessous :
| Comparaison | Modèles de diffusion (SD/DALL-E 3) | Modèles autorégressifs (GPT-Image-2/Nano Banana) |
|---|---|---|
| Méthode de génération | Itérations de débruitage multi-étapes | Prédiction de séquence de jetons unique |
| Implémentation du masque | Réinitialisation du latent non masqué à chaque étape | Contrainte stricte au niveau du jeton |
| Gestion des bordures | Sujette aux artefacts de fusion latente | Transition naturelle (au niveau sémantique) |
| Rendu de texte | Fréquents échecs | Précision d'environ 99 % |
| Édition multi-tours | Perte de réencodage accumulée | Presque aucune dérive |
| Instructions complexes | Difficile de disposer précisément | Supporte la disposition de plus de 100 objets |
| Vitesse | Généralement 10-30 secondes | Environ 60 % plus rapide que la diffusion |
| Rendu de texte long | Difficile | N'importe quelle langue/script |
Le point sensible majeur des modèles de diffusion réside dans la perte de réencodage du VAE : même si, théoriquement, les zones non masquées sont verrouillées, les conversions successives entre le latent et les pixels introduisent de légères différences de couleur. Après plusieurs éditions, ces pertes s'accumulent et forment des artefacts visibles à l'œil nu. GPT-Image-2 contourne ce problème grâce à son architecture autorégressive, où le décodage des jetons ne se produit qu'une seule fois.
Cependant, l'approche autorégressive a aussi un coût. Sa génération est plus onéreuse, principalement parce que le nombre de jetons est élevé et que chaque jeton nécessite une passe complète dans le Transformer. Nous recommandons d'utiliser GPT-Image-2 (accessible via APIYI apiyi.com) pour les scénarios exigeant une cohérence parfaite et un rendu de texte impeccable, tandis que les scénarios à haute concurrence, plus sensibles aux coûts, peuvent continuer à s'appuyer sur la série Stable Diffusion en complément.
Pratique du principe d'édition de GPT-Image-2 : invocation d'API et optimisation de la cohérence
Maintenant que vous comprenez le principe d'édition de GPT-Image-2, voyons comment mettre ce mécanisme en pratique. Voici un exemple minimal exécutable pour appeler l'interface d'édition de GPT-Image-2 via le service proxy API d'APIYI :
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="Gardez l'identité du personnage et l'arrière-plan intacts, changez uniquement la couleur du haut de blanc à bleu foncé",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Notez la rédaction de l'invite : précisez explicitement ce qui doit être conservé et ce qui doit être modifié. Cela déclenche directement le mode "Thinking" de GPT-Image-2 pour planifier la génération selon vos attentes. Si vous souhaitez effectuer une édition de zone précise, vous pouvez ajouter le paramètre mask :
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="Changez le vêtement blanc pour un costume bleu foncé",
size="1024x1024"
)
Le masque est une image PNG de même dimension, où la zone blanche représente la plage autorisée à la modification, et la zone noire force le maintien des jetons (tokens) de l'image originale.
5 conseils pratiques pour l'optimisation de la cohérence
Pour le débogage réel de la cohérence des images IA, nous avons résumé 5 expériences issues de tests concrets :
- Soyez explicite sur ce qu'il faut "conserver" dans l'invite : ne dites pas seulement "changez X", dites "gardez Y inchangé et changez X".
- Utilisez une résolution d'image de référence modérée : OpenAI recommande que le côté le plus long de l'image de référence ne dépasse pas 1024px ; une taille trop grande dilue l'attention des jetons.
- Utilisez la même image de base pour les éditions multi-tours : ne prenez pas le résultat de l'édition précédente comme entrée pour la suivante. Travaillez plutôt à partir de l'image originale pour effectuer des modifications sur différentes dimensions, puis fusionnez les invites à la fin.
- Divisez les instructions pour les scènes complexes : divisez "changez le personnage en style japonais avec un arrière-plan au crépuscule" en deux étapes, en ne modifiant qu'une variable à la fois.
- Choisissez le paramètre de qualité "high" : une qualité inférieure réduit le nombre de jetons, ce qui affaiblit directement la cohérence.
Compromis entre prix et cohérence pour GPT-Image-2
| Combinaison de paramètres | Coût par image | Scénario d'utilisation |
|---|---|---|
| 1024×1024 low | 0,006 $ | Esquisses créatives / prévisualisation rapide |
| 1024×1024 medium | 0,053 $ | Illustrations pour réseaux sociaux |
| 1024×1024 high | 0,211 $ | Édition de qualité commerciale / itérations répétées |
| 4K high | 0,50 $+ | Impression / affichage haute résolution |
Le coût et la cohérence sont positivement corrélés : le mode haute qualité alloue plus de jetons au modèle, ce qui permet naturellement de conserver davantage de caractéristiques de l'image originale. Nous recommandons d'utiliser en priorité le mode "high" en environnement de production. Vous pouvez également réduire les coûts de 50 % grâce à l'API Batch sur apiyi.com.
FAQ sur le principe d'édition d'images par IA et tendances futures
Q1 : GPT-Image-2 effectue-t-il une modification locale comme Photoshop ou une redessine-t-il l'image ?
R : Il redessine l'image. Tous les modèles d'image autorégressifs doivent encoder l'image originale en jetons, générer une séquence complète de jetons de sortie, puis décoder le tout en une nouvelle image. Même avec un masque, cela ajoute simplement des contraintes pendant le processus de redessin, sans réellement recouvrir les pixels localement.
Q2 : Puisqu'il s'agit d'un redessin, pourquoi l'image éditée semble-t-elle presque identique ?
R : Grâce à quatre mécanismes de cohérence : l'abstraction des caractéristiques des jetons visuels, la référence globale de l'image originale par le Self-Attention, le biais inductif des données d'entraînement et la planification explicite du mode "Thinking". Ces mécanismes permettent à l'IA de "choisir activement" de conserver les zones non mentionnées.
Q3 : L'inpainting des modèles de diffusion est-il une véritable modification locale ?
R : Non. L'inpainting de Stable Diffusion doit également faire passer les zones non masquées par le VAE (encodeur/décodeur), ce qui entraîne une légère perte de ré-encodage. Les éditions multiples accumulent des artefacts visibles, ce qui est précisément l'une des motivations principales du passage de GPT-Image-2 à l'autorégressif. Vous pouvez comparer les deux modèles via apiyi.com.
Q4 : Pourquoi GPT-Image-2 peut-il effectuer des éditions multi-tours sans dérive ?
R : Parce que l'architecture autorégressive fait référence à la séquence complète des jetons de l'image originale à chaque génération, sans erreur cumulative liée au débruitage itératif. Combiné à la planification explicite du mode "Thinking", la stabilité des éditions multi-tours dépasse largement celle des modèles de diffusion.
Q5 : Dois-je utiliser un masque ou une édition par simple invite ?
R : Privilégiez l'invite accompagnée d'instructions de conservation claires pour tirer parti de la planification automatique du mode "Thinking". N'ajoutez un masque pour une contrainte stricte que lorsque les limites de la zone à modifier sont claires et doivent être précises (comme pour certaines parties spécifiques du visage).
Q6 : Comment l'édition d'images par IA va-t-elle évoluer ?
R : Trois tendances : (1) La densité d'information des tokenizers continuera d'augmenter, réduisant le nombre de jetons et les coûts ; (2) Unification multimodale, où texte, image et vidéo partageront le même Transformer ; (3) Renforcement des capacités de raisonnement "Thinking", prenant en charge des chaînes d'édition multi-étapes plus longues. Nous vous conseillons de suivre les mises à jour des nouveaux modèles sur apiyi.com pour évaluer rapidement vos chemins de mise à niveau.
Conclusion : comprendre le principe pour mieux utiliser l'outil
Les modèles d'image autorégressifs comme GPT-Image-2 bouleversent notre intuition sur "l'édition d'images par IA". Il ne s'agit pas de modifications locales à la Photoshop, mais d'un redessin intelligent basé sur la génération d'images autorégressive. La cohérence provient de la collaboration entre quatre mécanismes : l'abstraction sémantique par tokenisation, l'ancrage global du Self-Attention, le biais d'entraînement et le mode "Thinking".
En comprenant ces principes, vous pourrez rédiger des invites capables de déclencher une planification "Thinking" efficace, éviter les pièges des éditions multi-tours et trouver l'équilibre entre coût et qualité. Nous vous recommandons d'effectuer vos tests et comparaisons via la plateforme apiyi.com, qui prend en charge l'invocation via une interface unifiée pour divers modèles majeurs tels que GPT-Image-2, Nano Banana et Stable Diffusion, facilitant ainsi la vérification rapide de tous les principes et astuces d'optimisation mentionnés dans cet article.
Cet article a été rédigé par l'équipe APIYI, basé sur des documents officiels d'OpenAI, Google DeepMind et des tests de terrain. Pour toute invocation de gpt-image-2 en environnement de production, veuillez visiter le site officiel d'APIYI : apiyi.com pour obtenir la documentation d'intégration.