L'année 2026 marque un tournant majeur pour les grands modèles de langage open source : Moonshot AI a officiellement publié son modèle phare, Kimi K2.6. Avec un score de 58,6 sur le benchmark SWE-Bench Pro, il surpasse le GPT-5.4 (57,7) et le Claude Opus 4.6 (53,4), s'imposant comme le modèle le plus performant pour la résolution réelle de problèmes sur GitHub.
Cet article vous guide à travers le processus d'intégration de l'API Kimi K2.6, en explorant son architecture MoE 1T, sa fenêtre de contexte de 256K, ses capacités de Function Call et de continuation de préfixe. Nous vous proposons un exemple de code complet pour configurer l'API en moins de 5 minutes. Par ailleurs, en comparant les tarifs officiels, APIYI (apiyi.com) propose, via le canal de relais de Huawei Cloud, un tarif de 0,60 $ pour l'entrée et 2,40 $ pour la sortie par million de tokens, soit environ 60 % du prix officiel (¥6,5 / ¥27).
Valeur ajoutée : À la fin de cet article, vous maîtriserez l'invocation complète de l'API Kimi K2.6, l'orchestration d'outils via Function Call, les techniques d'optimisation par mise en cache de préfixe, et vous saurez quand K2.6 est la solution au meilleur rapport qualité-prix.

Points clés de l'API Kimi K2.6
Kimi K2.6 est le modèle phare open source de nouvelle génération publié par Moonshot AI en avril 2026. Il conserve l'architecture MoE de la série Kimi K2 tout en apportant des améliorations significatives au codage, à la gestion du long contexte et à l'invocation d'outils. Le tableau suivant résume les caractéristiques techniques essentielles pour les développeurs :
| Point clé | Spécifications détaillées | Valeur réelle |
|---|---|---|
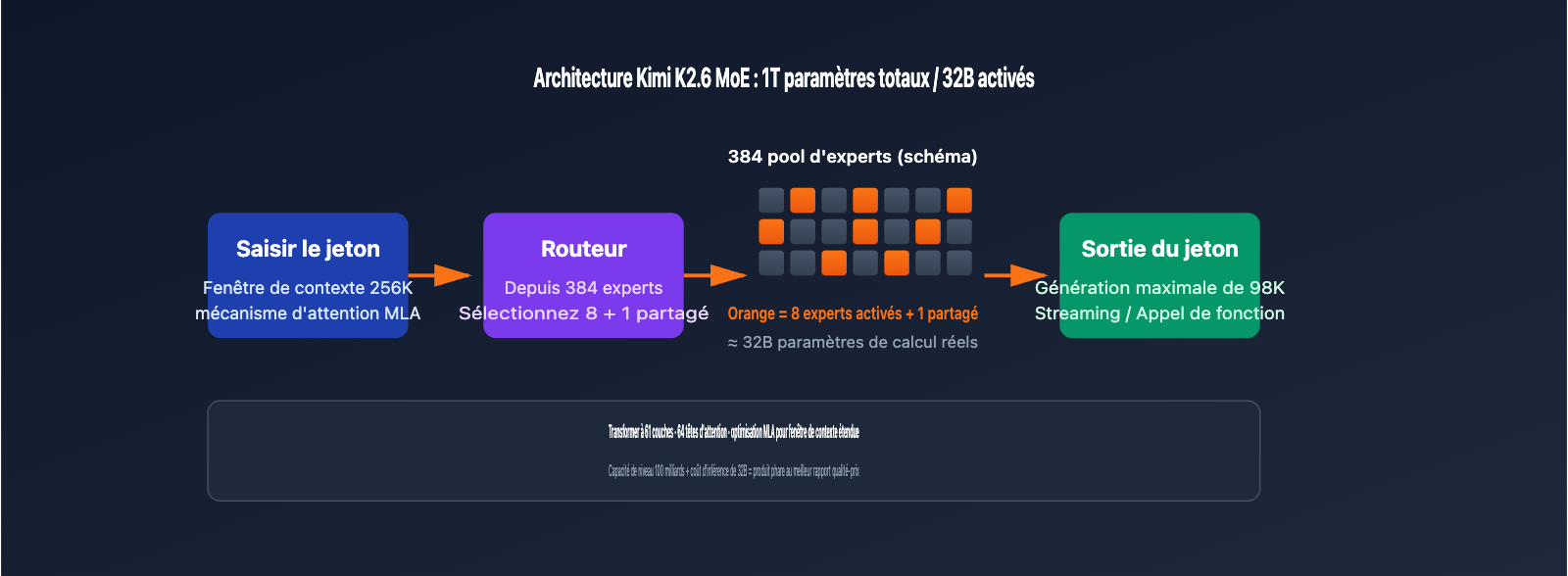
| Architecture MoE | 1T paramètres totaux / 32B activés / 384 experts | Capacités équivalentes à un modèle de 100 milliards, coût d'inférence d'un 32B |
| Fenêtre de contexte | 256K tokens (exactement 262 144) | Traitement massif de bases de code ou de documents juridiques |
| Génération max | Jusqu'à 98 304 tokens en une seule sortie | Idéal pour la refactorisation de code long et la rédaction de documents |
| Multimodal | Encodeur visuel MoonViT 400M intégré | Support natif des entrées image et vidéo |
| Orchestration d'agents | Agent Swarm : 300 sous-agents / 4 000 étapes | Gestion de flux de R&D complexes et multi-étapes |
| Licence | Modified MIT License | Adapté à un usage commercial, sans restrictions majeures |
Analyse détaillée des capacités de l'API Kimi K2.6
Par rapport à la génération K2.5, le K2.6 apporte des améliorations majeures sur trois axes : premièrement, le score de 58,6 au SWE-Bench Pro, surpassant pour la première fois le GPT-5.4 et le Claude Opus 4.6 sur des tâches réelles ; deuxièmement, le passage de 100 à 300 sous-agents dans Agent Swarm et de 1 500 à 4 000 étapes de coordination, permettant de gérer des tâches de développement plus longues ; et troisièmement, l'ouverture de la fenêtre de 256K sur toute la gamme, avec une réduction significative de l'utilisation de la VRAM et de la latence grâce au Multi-head Latent Attention (MLA).
🎯 Conseil technique : Pour vos développements, nous recommandons d'appeler directement Kimi K2.6 via la plateforme APIYI (apiyi.com). Cette plateforme accède aux modèles officiels via le canal de relais de Huawei Cloud, garantit une compatibilité totale avec le SDK OpenAI et permet de changer de modèle sans modifier votre code existant.
Analyse détaillée de l'architecture technique de l'API Kimi K2.6
Comprendre l'architecture sous-jacente de Kimi K2.6 vous aidera à faire les bons choix selon vos cas d'usage. Sa conception équilibre parfaitement une "capacité de paramètres à l'échelle du millier de milliards" avec un "coût d'inférence maîtrisé".
Mécanisme d'activation creuse MoE
Kimi K2.6 utilise une architecture de mélange d'experts (MoE) avec 1 000 milliards de paramètres, répartis sur 384 réseaux experts. Lors de l'inférence de chaque jeton, seuls 8 experts (plus 1 expert partagé) sont activés, soit 32 milliards de paramètres participant au calcul. Cette conception permet au modèle de bénéficier de l'étendue des connaissances d'un modèle massif tout en conservant la vitesse d'inférence d'un modèle de 32B, ce qui en fait l'un des modèles phares les plus rentables pour l'invocation du modèle via API.
Optimisation de la fenêtre de contexte
| Composant technique | Rôle | Configuration K2.6 |
|---|---|---|
| Multi-head Latent Attention (MLA) | Réduit le volume du cache KV pour l'inférence longue | 64 têtes d'attention |
| Nombre de couches | Détermine la profondeur d'inférence | 61 couches Transformer |
| Fenêtre de contexte | Nombre maximal de jetons par entrée | 262 144 jetons (256K) |
| Encodage de position | Technologie clé pour les séquences ultra-longues | Entraînement spécifique au contexte long |
| Mise en cache des préfixes | Réduit les coûts en cas de répétition de l'invite | Réduction du coût d'entrée d'environ 75 % après succès |
💡 Aperçu de l'architecture : Dans les scénarios de conversations multi-tours ou avec une invite système fixe, la mise en cache des préfixes peut réduire considérablement les coûts d'entrée. Nous recommandons de maintenir une invite système stable dans les environnements de production pour maximiser le taux de réussite du cache.
Comparaison des performances de l'API Kimi K2.6
Les tests de référence sont le moyen le plus direct de déterminer si un modèle mérite d'être intégré. Voici une comparaison des performances de Kimi K2.6, GPT-5.4 et Claude Opus 4.6 sur cinq benchmarks faisant autorité.
Capacités de codage et d'ingénierie logicielle
| Benchmark | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | Modèle dominant |
|---|---|---|---|---|
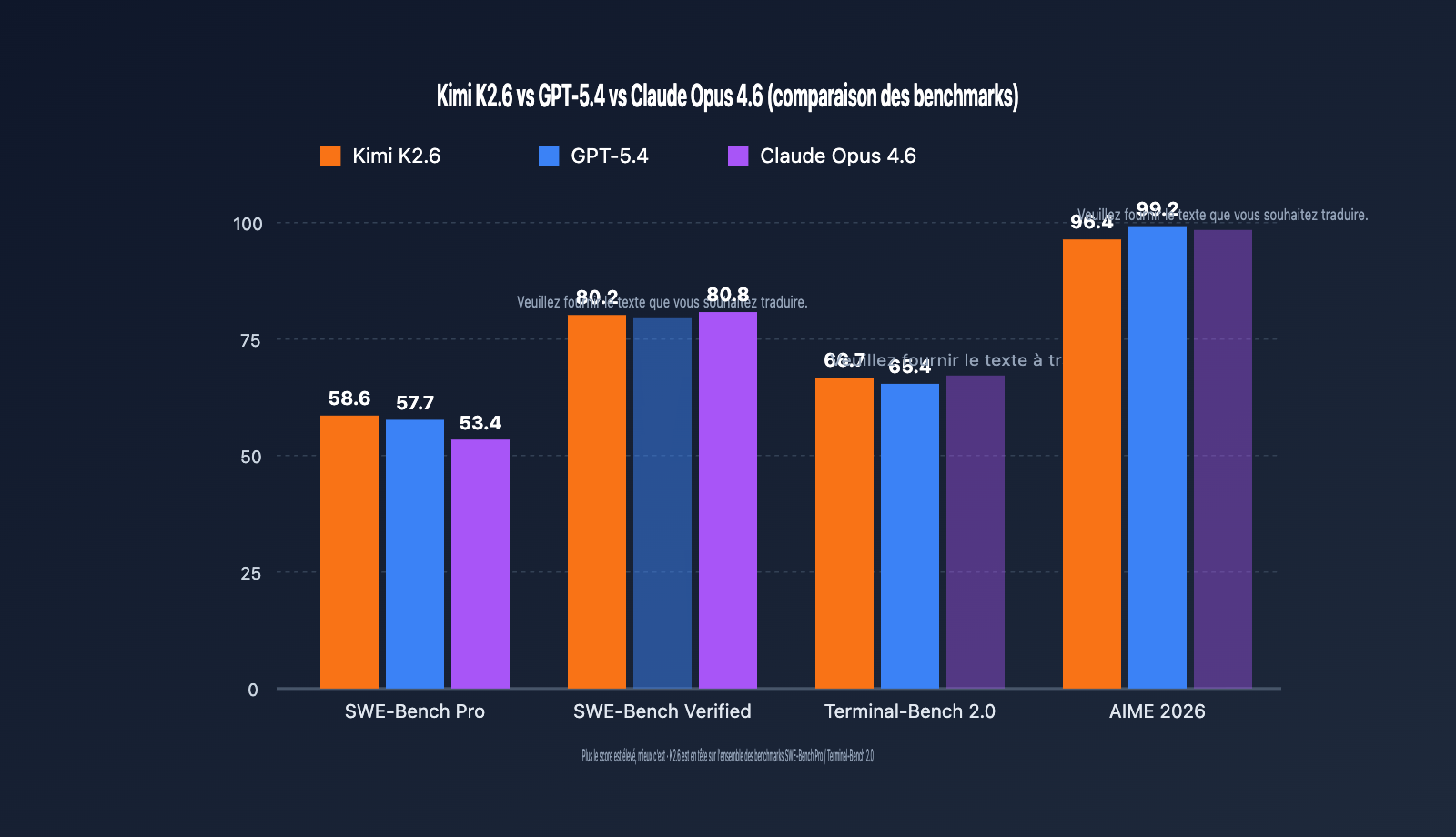
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (with tools) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
Analyse clé :
- SWE-Bench Pro mesure la capacité de résolution de bout en bout de problèmes GitHub réels. K2.6 obtient un score de 58,6, permettant pour la première fois à un modèle ouvert de surpasser les modèles propriétaires phares sur ce benchmark. Cela signifie que pour les tâches de maintenance de code et de correction de bugs, K2.6 est un choix prioritaire.
- SWE-Bench Verified est une version relativement simplifiée ; Claude Opus 4.6 l'emporte légèrement (80,8 contre 80,2), ce qui montre que Claude conserve un avantage sur les tâches de code standardisées.
- Terminal-Bench 2.0 teste la capacité d'orchestration de commandes terminales. Le score de 66,7 de K2.6 est en tête, ce qui le rend adapté aux scénarios DevOps et d'automatisation des opérations.
- AIME / HMMT et autres raisonnements mathématiques purs restent le point fort de GPT-5.4. Pour les scénarios purement mathématiques, nous recommandons de conserver l'option GPT-5.4.
🎯 Conseils par scénario : Pour différentes tâches, nous suggérons d'effectuer des tests A/B entre les modèles : privilégiez K2.6 pour la maintenance de code, GPT-5.4 pour le raisonnement mathématique, et gardez l'option Claude pour l'écriture créative longue.
Prise en main rapide de l'API Kimi K2.6
Découvrons ensemble comment invoquer Kimi K2.6 grâce à un code complet. Les API de la série Kimi sont entièrement compatibles avec le protocole SDK OpenAI. Si vous disposez déjà d'un code utilisant OpenAI, il vous suffit de remplacer base_url et model.
Exemple minimaliste (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Vous êtes un ingénieur Python expérimenté."},
{"role": "user", "content": "Implémentez un pool de requêtes concurrentes en utilisant asyncio, avec une limite de 10 accès simultanés."}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
Voir l’exemple complet d’appel asynchrone en streaming (avec gestion des erreurs)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""Appel en streaming de Kimi K2.6 et impression des jetons en temps réel"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[Limite de débit atteinte, configuration de réessais ou mise à niveau du forfait conseillée]")
raise
except APIError as e:
print(f"\n[Erreur API : {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="Expliquez comment l'architecture MoE permet de réduire les coûts d'inférence",
system="Vous êtes un expert en architecture IA, vos réponses sont concises et professionnelles"
)
print(f"\n\n[Nombre total de jetons : {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 Démarrage rapide : Après avoir obtenu votre clé API sur la plateforme APIYI apiyi.com, réglez simplement
base_urlsurhttps://api.apiyi.com/v1. Tous les SDK de l'écosystème OpenAI (Python/Node.js/Go) fonctionnent nativement. L'intégration se fait en 5 minutes.
Appel avec Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "Écrivez une fonction de debounce en TypeScript avec support des génériques" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
Appel direct avec cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Bonjour, Kimi K2.6"}
],
"max_tokens": 1024
}'
Utilisation pratique des fonctions (Function Call)
La capacité de Function Call de K2.6 est une amélioration notable par rapport à la série K2, affichant d'excellentes performances sur le classement Berkeley Function-Calling. Voici le flux d'orchestration d'outils via un exemple de "météo".
Définition et appel d'outils
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Consulter la météo en temps réel pour une ville donnée",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nom de la ville"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""Interface de simulation de requête météo"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "Ensoleillé"}
messages = [{"role": "user", "content": "Aide-moi à vérifier la météo à Pékin et Shanghai"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
Complétion de préfixe (Mode partiel)
K2.6 supporte la "complétion de préfixe" à la mode OpenAI, ce qui signifie que vous pouvez pré-remplir le message de l'assistant, et le modèle continuera à générer à partir de cette position. Utile pour forcer la sortie JSON ou des contraintes de format spécifiques :
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Donnez les données du PIB de Pékin en 2023 au format JSON"},
{"role": "assistant", "content": '{"city": "Pékin", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 Optimisation des coûts : Pour les scénarios à long message système (RAG, Agents), une fois que le préfixe est mis en cache, le coût d'entrée diminue d'environ 25 %. Idéal pour les dialogues multi-tours et les modèles fixes à haute fréquence. Il est conseillé d'activer la surveillance de cache au niveau du compte sur apiyi.com pour observer le taux de succès en temps réel.
Capacités avancées de l'API Kimi K2.6
Au-delà du Function Call, K2.6 propose l'orchestration multi-agents Agent Swarm, une fenêtre de contexte étendue de 256K et des capacités multimodales natives, constituant son avantage compétitif pour le codage, l'automatisation R&D et l'analyse de documents.
Orchestration multi-agents Agent Swarm
L'une des capacités les plus différenciantes de K2.6 est Agent Swarm — il peut gérer jusqu'à 300 sous-agents en parallèle en une seule tâche, effectuant 4 000 actions de coordination. Cette fonctionnalité excelle dans le refactoring de bases de code importantes, l'analyse croisée de documents et les pipelines R&D complexes.
Modes d'ordonnancement des sous-agents
L'Agent Swarm de K2.6 prend en charge trois modes d'orchestration :
| Mode | Scénario d'application | Nombre de sous-agents | Étapes de coordination |
|---|---|---|---|
| Parallèle simple | Résumé de documents, revue de code | 10-50 | < 200 |
| Ordonnancement hiérarchique | Refactoring multi-modules | 50-150 | 500-1500 |
| Collaboration profonde | Pipeline d'agents inter-dépôts | 150-300 | 1500-4000 |
Exemple d'ordonnancement d'agents simplifié
Voyons comment coordonner 5 sous-agents parallèles pour une tâche de revue de code :
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""Sous-agent de revue de module unique"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Vous êtes expert en revue de code, focus sur la sécurité et les performances."},
{"role": "user", "content": f"Revoyez le module {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""Ordonnancement parallèle de plusieurs sous-agents"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# Flux principal : coordonner 5 sous-agents pour examiner 5 modules
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Bonnes pratiques pour l'Agent Swarm
- Contrôle de la granularité : Chaque sous-agent gère 5K-20K jetons, au-delà, les frais de coordination deviennent prohibitifs ;
- Isolation des erreurs : Chaque sous-agent doit posséder son propre try/except ;
- Agrégation des résultats : Configurez un "agent maître" pour collecter et vérifier les résultats ;
- Gestion des timeouts : 60-120 s pour un sous-agent, 10-30 min pour l'agent maître ;
- Contrôle du débit : Utilisez des sémaphores pour limiter la concurrence.
Pratique du contexte étendu 256K
Le contexte 256K (262 144 jetons) est l'argument phare de K2.6. Cela correspond à environ 400 000 – 500 000 caractères chinois, permettant de contenir une large base de code ou un livre technique complet.
Usage typique du contexte long
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""Charger tous les fichiers du dépôt avec les extensions spécifiées"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
# Estimation : 1 jeton ≈ 2 caractères
print(f"Estimation jetons totaux : {len(repo_text) // 2}")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Vous êtes un architecte senior, expert en analyse de grandes bases de code."},
{"role": "user", "content": f"Analysez l'architecture du projet suivant et proposez des refactorisations :\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
Équilibre entre coût et performance pour les longs contextes
| Taille entrée | Coût estimé/appel | Latence 1er jeton | Scénario |
|---|---|---|---|
| 8K | 0,005 $ | 1-2 s | Analyse fichier unique |
| 32K | 0,019 $ | 3-5 s | Revue au niveau module |
| 100K | 0,06 $ | 8-15 s | Analyse dépôt moyen |
| 200K | 0,12 $ | 18-30 s | Gros dépôt / Livre entier |
| 256K (max) | 0,154 $ | 25-40 s | Documents extrêmement longs |
🎯 Astuces pour longs documents : Divisez le prompt système en "instructions fixes + document dynamique". La partie fixe sera mise en cache, réduisant les coûts de 40 à 60 % pour les scénarios RAG.
Appel visuel multimodal
K2.6 intègre l'encodeur visuel MoonViT (400M paramètres), supportant nativement les entrées image et vidéo, toujours via le protocole OpenAI :
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Analysez ce diagramme d'architecture et identifiez les points de défaillance potentiels"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
Scénarios d'application multimodaux :
- Analyse et modification de schémas d'architecture ou de flux ;
- Revue de maquettes UI et génération de code ;
- Compréhension de captures d'écran de documents techniques ;
- Extraction de données de graphiques ;
- Inspection visuelle de contrôle qualité industriel.
Migration et optimisation des performances de l'API Kimi K2.6
Si votre projet utilise actuellement OpenAI, K2.5 ou d'autres modèles, la migration vers K2.6 ne nécessite généralement que 3 à 5 lignes de code. De plus, des stratégies de concurrence et de mise en cache bien pensées permettent d'amplifier considérablement les avantages économiques de K2.6.
Migration depuis la série OpenAI GPT
# Code original (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# Migration vers K2.6 (modifiez simplement base_url et model)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
Migration depuis Kimi K2 / K2.5
Bien que les identifiants des modèles de la série K2 diffèrent, le protocole API reste identique :
| Ancien ID de modèle | Nouvel ID de modèle | Date de fin de support prévue |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
25-05-2026 |
kimi-k2.5 |
kimi-k2.6 |
Support continu, mais mise à niveau recommandée |
moonshot-v1-128k |
kimi-k2.6 |
Courant 2026 |
Vérification de la compatibilité avant migration
Avant de migrer, nous vous conseillons de vérifier les points suivants :
- Limite max_tokens : K2.6 peut générer jusqu'à 98K tokens en une seule fois. Si votre code impose une limite codée en dur à 8K, vous pouvez l'augmenter.
- Plage de température : Pour K2.6, une valeur entre 0,1 et 0,7 est recommandée ; une valeur trop élevée pourrait nuire à la qualité du code.
- Séquences d'arrêt (stop sequences) : K2.6 prend en charge les séquences d'arrêt personnalisées, comme OpenAI.
- Comportement de tool_choice : Le mode
autode K2.6 est plus enclin à appeler des outils. Si vous préférez une approche prudente, utiliseznoneou spécifiez explicitement l'outil. - Protocole de streaming : Le format SSE est strictement identique, aucune modification n'est nécessaire côté frontal.
Bonnes pratiques d'optimisation des performances
Optimisation de la vitesse d'invocation
| Optimisation | Méthode de mise en œuvre | Gain attendu |
|---|---|---|
| Requêtes simultanées | Utiliser AsyncOpenAI + asyncio.gather | Débit x3-10 |
| Sortie en streaming | Activer stream=True | Latence initiale réduite de 70 % |
| Mise en cache du préfixe | Fixer le system prompt | Coût d'entrée réduit de 75 % |
| max_tokens raisonnable | Définir une limite selon la tâche | Latence par requête réduite de 30 % |
| Contrôle de la température | temp=0.2 pour les tâches de code | Sortie plus stable |
Conseils pour la gestion des erreurs
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"Limite de débit atteinte, nouvelle tentative dans {wait}s")
time.sleep(wait)
except APITimeoutError:
print(f"Délai d'attente dépassé, tentative {attempt+1}")
except APIError as e:
print(f"Erreur API : {e}")
if attempt == max_retries - 1:
raise
raise Exception("Nombre maximal de tentatives atteint")
Avantages tarifaires et choix de scénarios pour l'API Kimi K2.6
Le prix est un facteur déterminant dans le choix d'un modèle. Le tableau ci-dessous compare les prix affichés de Kimi K2.6 selon différents canaux (par 1M de tokens) :
| Canal d'invocation | Prix entrée | Prix sortie | Remarques |
|---|---|---|---|
| Plateforme officielle Kimi | ¥6.5 (~$0.95) | ¥27 (~$4.00) | Facturation officielle |
| APIYI (Proxy Huawei Cloud) | $0.60 | $2.40 | ~40% moins cher que le site officiel |
| OpenRouter (Parasail) | $0.60 | $2.40+ | Canal non officiel |
| GPT-5.4 (Référence) | $2.50 | $15.00 | 4 à 6 fois plus cher que K2.6 |
| Claude Opus 4.6 (Référence) | $15.00 | $75.00 | Plus de 25 fois plus cher que K2.6 |
Estimation des coûts réels
Prenons l'exemple d'un assistant de code quotidien (session type : 5K tokens en entrée / 2K tokens en sortie), avec 100 000 appels par mois :
| Modèle | Coût mensuel entrée | Coût mensuel sortie | Coût total mensuel |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1 250 | $3 000 | $4 250 |
| Claude Opus 4.6 | $7 500 | $15 000 | $22 500 |
Conclusion : Pour le codage, les agents et les contextes longs, K2.6 offre des performances comparables à GPT-5.4 ou Claude Opus 4.6, pour un coût représentant seulement 1/5ème à 1/30ème du prix. C'est une solution idéale pour les petites équipes et les développeurs indépendants soucieux de leur budget.
🎯 Conseil de sélection : Le choix du modèle dépend de vos besoins spécifiques. Nous vous recommandons d'effectuer des tests réels via la plateforme APIYI (apiyi.com) pour déterminer ce qui vous convient le mieux. La plateforme propose une interface unifiée pour Kimi K2.6, GPT-5.4, Claude Opus 4.6 et bien d'autres, facilitant ainsi la comparaison et la transition.
Recommandations par scénario d'application
L'adéquation de K2.6 varie selon les cas d'usage. Voici nos recommandations :
| Scénario d'application | Recommandation | Raison |
|---|---|---|
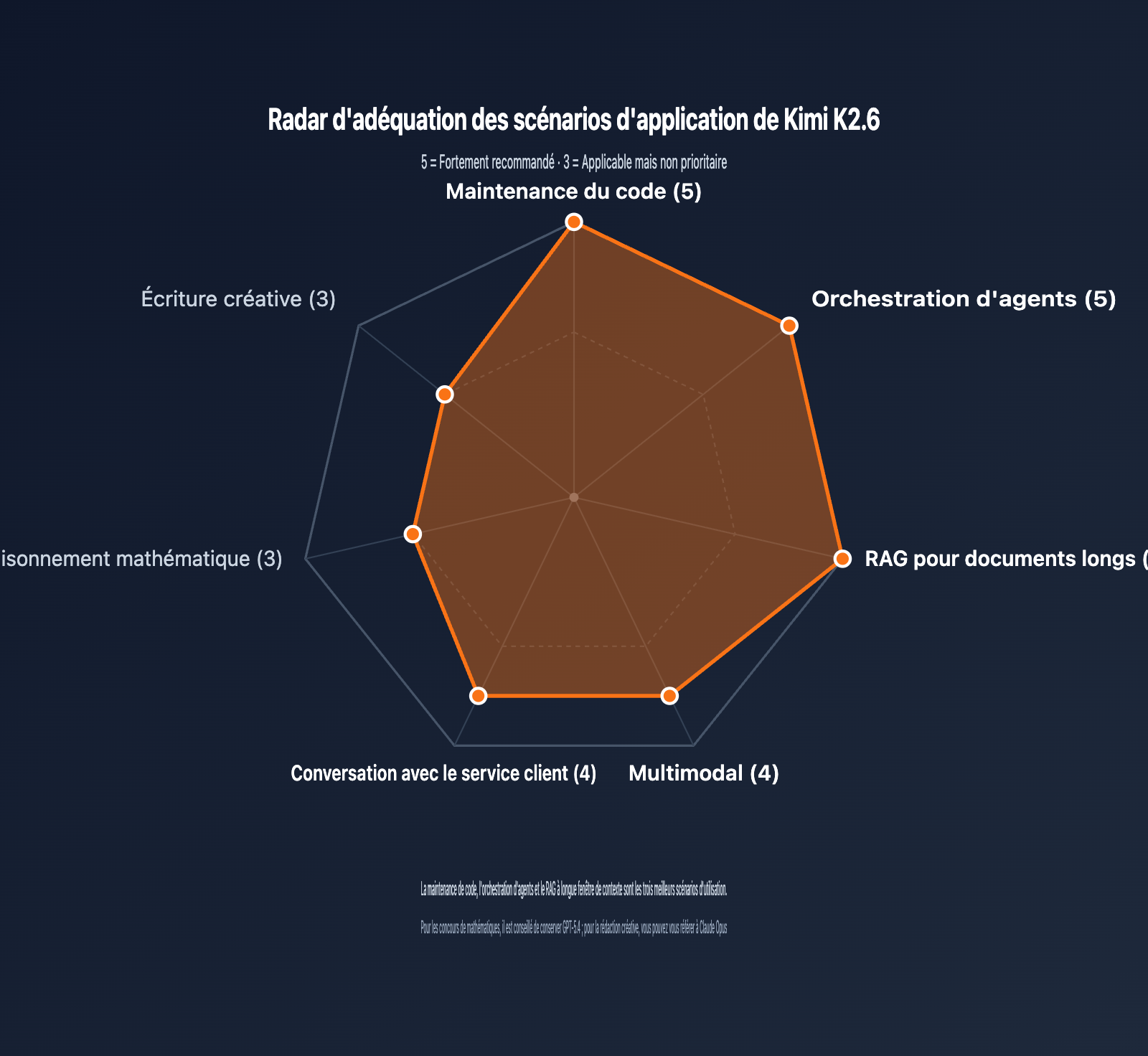
| Maintenance et refactorisation de code | ⭐⭐⭐⭐⭐ | 1er sur SWE-Bench Pro, 256K pour charger de gros dépôts |
| Orchestration d'agents | ⭐⭐⭐⭐⭐ | 300 sous-agents / 4000 étapes, idéal pour les flux complexes |
| Analyse de longs documents | ⭐⭐⭐⭐⭐ | Contexte 256K + optimisation MLA, coût maîtrisé |
| Compréhension multimodale | ⭐⭐⭐⭐ | MoonViT natif, entrée image/vidéo prête à l'emploi |
| Service client et dialogue | ⭐⭐⭐⭐ | Excellent Function Call, cache de préfixe économique |
| Raisonnement mathématique pur | ⭐⭐⭐ | Score AIME de 96.4 correct, mais GPT-5.4 est supérieur |
| Rédaction créative | ⭐⭐⭐ | Expression chinoise naturelle, mais style moins varié que Claude |
FAQ
Q1 : Quelles sont les principales différences entre l’API Kimi K2.6 et les versions K2.5 / K2 ?
La version K2.6 apporte des améliorations majeures sur trois points : 1) Le score au SWE-Bench Pro passe de 53 (pour la K2.5) à 58,6, dépassant pour la première fois GPT-5.4 et Claude Opus 4.6 ; 2) Le nombre de sous-agents Agent Swarm passe de 100 à 300, et les étapes de coordination passent de 1 500 à 4 000 ; 3) Une fenêtre de contexte de 256K est désormais disponible sur toute la gamme (certaines variantes des premières versions de K2 étaient limitées à 128K). Selon l'annonce officielle de Kimi, les anciennes versions de K2 seront retirées le 25 mai 2026. Les nouveaux projets doivent donc intégrer directement la version K2.6 (identifiant de modèle : kimi-k2.6), qui est entièrement compatible avec le SDK OpenAI.
Q2 : L’API Kimi K2.6 est-elle entièrement compatible avec le SDK OpenAI ?
Oui. Lors d'une invocation du modèle via des plateformes comme APIYI, le protocole API est totalement compatible avec l'interface chat completions d'OpenAI, incluant les paramètres pour le streaming, les outils (Function Call), tool_choice, temperature, top_p, max_tokens, etc. Avec les SDK courants en Python, Node.js ou Go, il suffit de modifier les paramètres base_url et model. Notez que le nombre maximal de tokens en sortie pour la K2.6 est de 98 304, ce qui est largement supérieur aux 16K de GPT-5.
Q3 : Qu’en est-il de la latence et des coûts lors de l’utilisation réelle de la fenêtre de contexte de 256K ?
Grâce à l'attention latente multi-têtes (MLA), K2.6 optimise considérablement le volume du cache KV pour les longs contextes. En situation réelle avec 100K tokens en entrée, la latence du premier token est d'environ 8 à 15 secondes (selon la charge du serveur), les tokens suivants étant renvoyés en flux continu. Côté coût, une entrée de 256K à 0,60 $/1M coûte environ 0,15 $ par requête. Pour des conversations multi-tours utilisant le même system prompt, le coût d'entrée chute d'environ 25 % grâce à la mise en cache du préfixe. Avant la mise en production, nous vous recommandons d'effectuer des tests de bout en bout avec vos invites types et de surveiller les journaux de consommation de tokens pour optimiser les coûts.
Q4 : En quoi le Function Call de K2.6 diffère-t-il de celui de GPT-5 / Claude ?
Bien que l'interface soit strictement identique (protocole tools style OpenAI), les capacités internes diffèrent : 1) K2.6 prend en charge 300 sous-agents simultanés, offrant un avantage natif pour l'orchestration parallèle de multiples outils ; 2) K2.6 se situe dans le premier rang du classement Berkeley Function-Calling Leaderboard, atteignant un niveau proche de GPT-5 ; 3) K2.6 prend en charge la continuation de préfixe (Partial Mode), permettant de forcer un format de sortie JSON et de réduire le taux d'échec des appels d'outils. Pour les pipelines d'agents complexes, K2.6 représente le meilleur rapport qualité-prix.
Q5 : L’utilisation de K2.6 via APIYI est-elle officiellement autorisée ? La sécurité des données est-elle garantie ?
APIYI passe par les canaux officiels de Huawei Cloud pour accéder aux modèles Kimi ; il s'agit donc d'un canal autorisé et conforme. Les poids du modèle et les résultats d'inférence sont identiques à ceux de la version officielle. Le transfert de données est chiffré via HTTPS et la plateforme ne stocke pas le contenu des requêtes. Pour les utilisateurs professionnels, nous proposons des sous-comptes indépendants, une gestion des droits par clé API et des plafonds de consommation. Si vous avez des exigences strictes en matière de conformité des données, vous pouvez consulter la politique détaillée sur la page de conformité de apiyi.com.
Q6 : À quels types de projets K2.6 convient-il ? Quand choisir GPT-5.4 ou Claude ?
Scénarios privilégiant K2.6 : Assistants de codage, tâches SWE, RAG avec long contexte, orchestration de processus d'agents et petits/moyens projets sensibles aux coûts. Scénarios privilégiant GPT-5.4 : Compétitions mathématiques de haut niveau (AIME/HMMT) et tâches de recherche scientifique nécessitant une profondeur de raisonnement maximale. Scénarios privilégiant Claude Opus 4.6 : Rédaction créative longue, génération de documents juridiques ou contractuels avec des exigences de formatage strictes. Nous suggérons de conserver une conception d'interface permettant de basculer entre plusieurs modèles afin d'effectuer des tests comparatifs sur des tâches spécifiques avant de valider votre choix final.
Résumé
Kimi K2.6 marque un tournant pour les grands modèles de langage open-source en 2026 : il prouve qu'une architecture MoE à plus de 100 milliards de paramètres peut rivaliser directement avec les leaders fermés en matière de codage, d'agents et de gestion de longs contextes. Avec un score de 58,6 au SWE-Bench Pro, ainsi que sa capacité technique de 256K tokens de contexte et 300 sous-agents, il devient le modèle de choix pour les assistants de code et les projets d'automatisation de la R&D.
Points clés à retenir :
- Avantage d'architecture : 1T MoE / 32B activés, puissance de 100 milliards de paramètres pour le coût d'inférence d'un modèle 32B.
- Référence de pointe : Première place aux tests SWE-Bench Pro, Terminal-Bench 2.0 et HLE.
- Avantage tarifaire : 0,60 $ / 2,40 $ via APIYI, soit environ 40 % de réduction par rapport au site officiel.
- Écosystème friendly : Entièrement compatible avec le SDK OpenAI, migration effectuée en 5 minutes.
- Capacités d'ingénierie : 256K de contexte + 300 sous-agents + mise en cache de préfixe.
Pour les équipes souhaitant construire des produits basés sur l'IA en 2026, l'API Kimi K2.6 est un choix ultra-compétitif en termes de performance, de coût et d'intégration. Nous vous recommandons de tester ses capacités sur la plateforme APIYI (apiyi.com), de comparer les modèles selon vos besoins métier et de prendre la décision la plus pertinente.
Auteur : Équipe technique APIYI | Nous suivons de près l'évolution des grands modèles de langage. N'hésitez pas à nous contacter via APIYI (apiyi.com) pour des échanges techniques ou des conseils sur vos solutions.