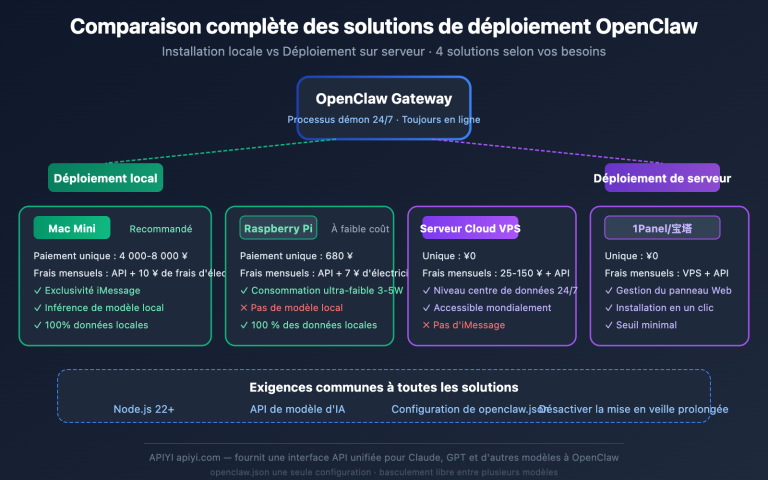
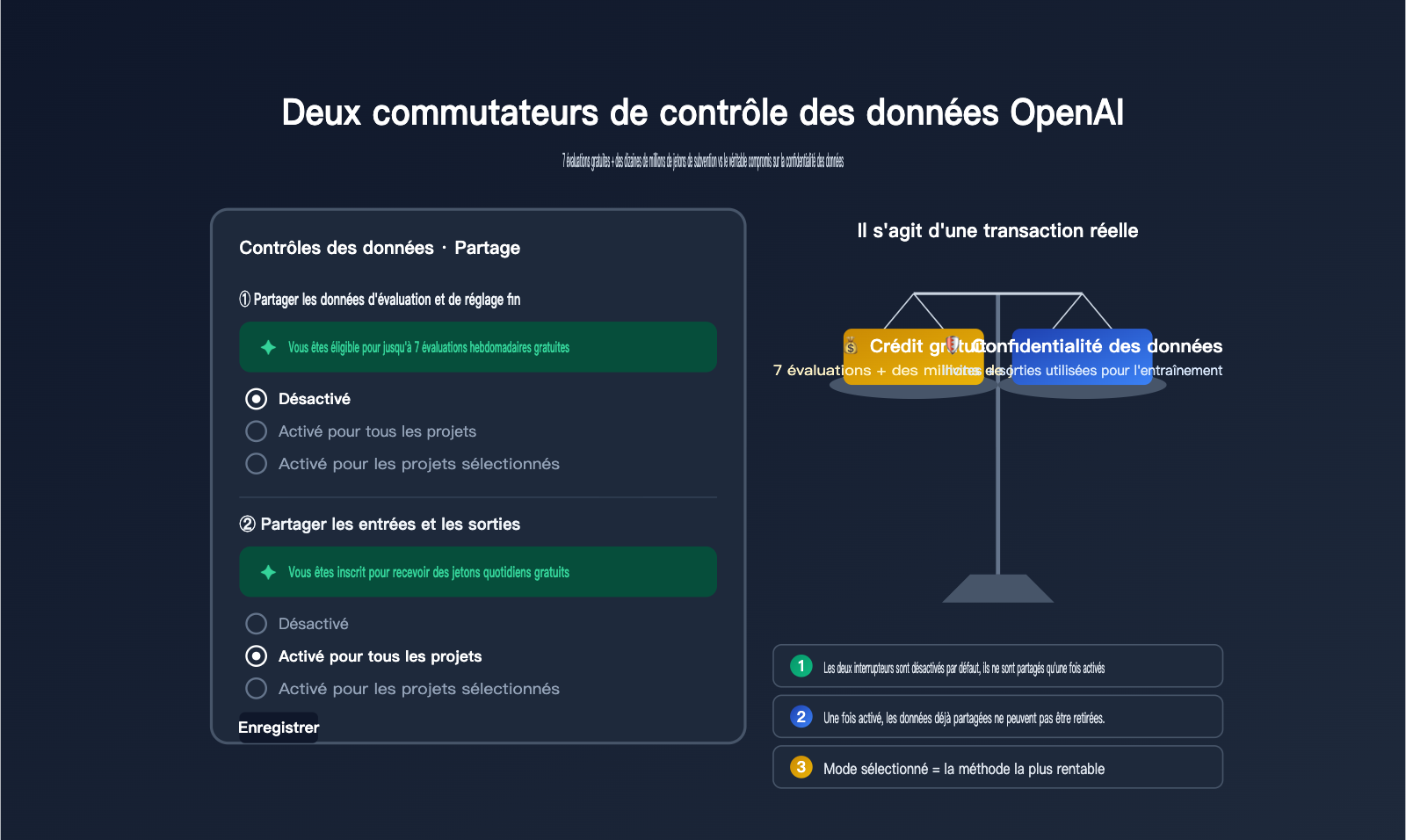
Récemment, un client nous a interrogés à ce sujet : en consultant la page « Data Controls » dans son interface OpenAI, il a remarqué deux options — « Share evaluation and fine-tuning data with OpenAI » (Partager les données d'évaluation et de fine-tuning avec OpenAI) et « Share inputs and outputs with OpenAI » (Partager les entrées et sorties avec OpenAI). Chacune propose trois niveaux : Disabled (Désactivé), Enabled for all projects (Activé pour tous les projets) et Enabled for selected projects (Activé pour certains projets). La première affiche un message vert indiquant « You're eligible for up to 7 free weekly evals », tandis que la seconde mentionne « You're enrolled for complimentary daily tokens ». Cela ressemble à une offre de ressources gratuites, mais il hésitait sur la pertinence de les activer et sur le coût caché de cette décision.
En réalité, ces deux options constituent un échange bilatéral où OpenAI troque des « crédits gratuits » contre vos « données d'entraînement/évaluation ». Le prix à payer est bien réel : vos données d'évaluation et vos entrées/sorties d'API seront utilisées par OpenAI pour améliorer ses futurs modèles. Parmi les clients d'APIYI (apiyi.com), nous avons vu des utilisateurs activer ces options pendant six mois avant de réaliser qu'il s'agissait d'une faille de confidentialité, tout comme nous en avons vu d'autres les désactiver pendant six mois avant de découvrir qu'ils gaspillaient des millions de jetons gratuits chaque jour. Cet article s'appuie sur la documentation officielle pour décrypter le fonctionnement réel de ces options, les crédits obtenus, l'impact sur la confidentialité et nos recommandations de configuration.
Définitions clés des deux paramètres de contrôle des données OpenAI
En accédant à la page Settings → Data Controls → Sharing, vous découvrirez deux options distinctes, souvent confondues. Elles diffèrent par leur contenu, leurs avantages et leur impact sur la confidentialité. Comprendre leurs limites est essentiel pour faire les bons choix.
| Paramètre | Share evaluation and fine-tuning data | Share inputs and outputs |
|---|---|---|
| Contenu partagé | Invites d'évaluation + résultats + logique de notation + données de fine-tuning | Toutes les entrées et sorties des invocations du modèle |
| Avantages gratuits | Jusqu'à 7 exécutions d'évaluation gratuites par semaine | Crédits de jetons quotidiens (selon le niveau et le groupe de modèles) |
| Usage des données | Amélioration du pipeline d'évaluation + entraînement des futurs modèles | Utilisé directement pour entraîner / améliorer les modèles |
| État par défaut | Désactivé | Désactivé |
| Granularité | Trois niveaux : Désactivé / Tous / Sélectionnés | Trois niveaux : Désactivé / Tous / Sélectionnés |
| Autorisations | Propriétaire de l'organisation uniquement | Propriétaire de l'organisation uniquement |
| Portée | Données partagées uniquement après activation | Trafic partagé uniquement après activation |
| Facilité de désactivation | Commutation possible à tout moment | Commutation possible à tout moment |
🎯 Conseil pour une compréhension rapide : Si vous souhaitez simplement "obtenir des crédits gratuits en toute sécurité", vous pouvez régler l'option sur "Enabled for selected projects". Créez un projet de test dédié pour vos scripts de développement ou internes, et faites passer le trafic de vos projets principaux et de votre API de production via la passerelle APIYI (apiyi.com) pour éviter d'exposer l'ensemble de vos projets au pipeline d'entraînement de données.
Analyse détaillée du paramètre "Share evaluation and fine-tuning data"
Bien que ce paramètre soit intitulé "Partager les données d'évaluation et de fine-tuning", sa portée réelle est plus large que ce que suggère son nom. Une fois activé, OpenAI récupère non seulement vos invites d'évaluation et vos complétions, mais aussi votre logique de notation (grading logic) et les invites/complétions de vos jeux de données de fine-tuning. Cela signifie que votre manière d'évaluer le modèle, votre définition d'une "bonne réponse" et les connaissances métier contenues dans vos données d'entraînement sont collectées par OpenAI.
En contrepartie, vous bénéficiez de 7 exécutions d'évaluation gratuites par semaine. OpenAI précise dans son centre d'aide que "les évaluations que vous partagez avec OpenAI sont actuellement traitées sans frais jusqu'à 7 exécutions par semaine". Au-delà de ce quota ou si vous utilisez des modèles non éligibles, la tarification standard par jeton s'applique. Bien que ce chiffre semble modeste, pour les équipes qui comparent régulièrement différents modèles, cela peut représenter une économie de plusieurs centaines de dollars en coûts d'évaluation.
Il est important de noter que ce paramètre ne s'applique qu'aux données générées après son activation. Les données historiques ne sont pas partagées rétroactivement, et la désactivation ne permet pas de "retirer" les données déjà partagées. Votre décision doit donc se baser sur la quantité de données d'évaluation que vous prévoyez de partager dans les 6 à 12 prochains mois, et non sur les données dont vous disposez actuellement.
| Dimension | Avantages de l'activation | Coûts de l'activation |
|---|---|---|
| Avantages directs | 7 évaluations gratuites par semaine | / |
| Avantages indirects | Optimisation du pipeline d'évaluation par OpenAI | / |
| Coût en données | / | Collecte des invites d'évaluation, des complétions et de la logique de notation |
| Coût métier | / | Fuite du savoir-faire métier via les jeux de données de fine-tuning |
| Réversibilité | Désactivation possible à tout moment | Les données partagées ne peuvent être retirées |
🎯 Quand activer le partage Eval/FT : Si vos évaluations reposent sur des benchmarks publics ou des jeux de données de test non sensibles, l'activation est pratiquement sans risque. Si vos invites d'évaluation contiennent des données clients réelles, des règles métier internes ou une logique de notation propriétaire, nous vous recommandons d'utiliser le mode "Selected" et de ne l'activer que pour vos projets en environnement de bac à sable (sandbox).
Explication détaillée des paramètres "Share inputs and outputs"
Il s'agit de l'une des deux options les plus "coûteuses en termes de confidentialité, mais aux retours les plus avantageux". Une fois activée, toutes les invocations de modèle passant par ce projet verront leurs invites (prompts) et leurs complétions (outputs) collectées par OpenAI pour entraîner ou améliorer leurs modèles. Cela diffère fondamentalement du comportement par défaut de l'API : depuis mars 2023, OpenAI s'engage explicitement à ne pas utiliser les données de l'API pour l'entraînement. Activer cette option revient donc à révoquer volontairement cette protection.
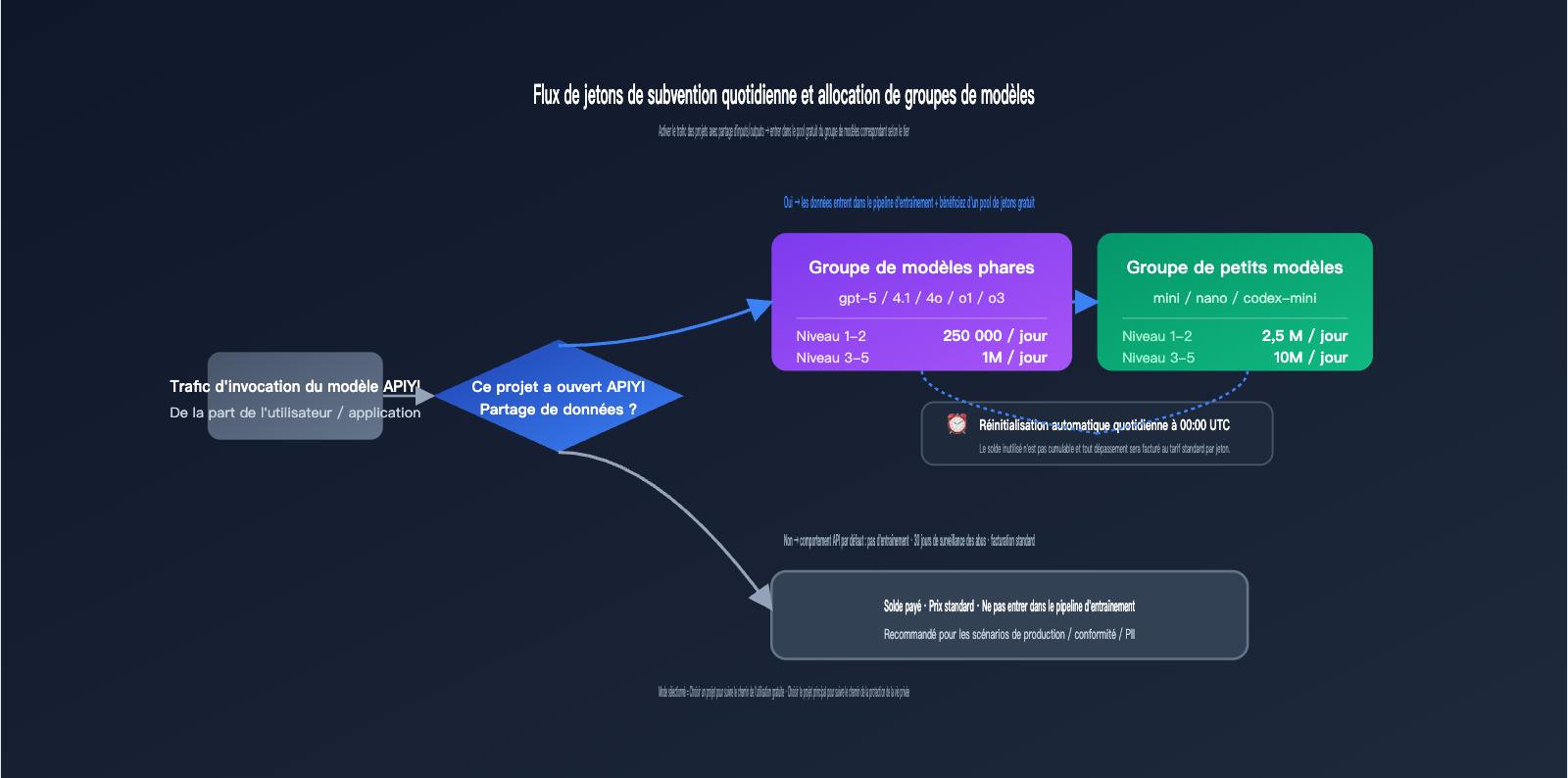
En contrepartie, vous recevez des jetons de subvention quotidiens (complimentary daily tokens), distribués par paliers selon le niveau (tier) de votre compte et le groupe de modèles. Il s'agit du programme de quota gratuit le plus précis publié par OpenAI, réinitialisé automatiquement tous les jours à 00:00 UTC.
| Groupe de modèles | Limite quotidienne Tier 1-2 | Limite quotidienne Tier 3-5 | Heure de réinitialisation |
|---|---|---|---|
| Groupe modèles phares | 250 000 jetons | 1 000 000 jetons | 00:00 UTC |
| Groupe petits modèles | 2 500 000 jetons | 10 000 000 jetons | 00:00 UTC |
La distinction entre les groupes de modèles n'est pas basée sur une estimation approximative des performances, mais sur une liste explicite fournie par OpenAI. L'invocation de modèles ne figurant pas dans ces listes ne sera pas comptabilisée dans le quota gratuit.
| Groupe de modèles | Modèles inclus |
|---|---|
| Groupe phare | gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview, gpt-4.1, gpt-4o, o1, o3, o1-preview |
| Groupe petits modèles | gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini, codex-mini-latest |
🎯 Valeur réelle des quotas de jetons : En estimant le coût de gpt-4o-mini à 0,15 $/M en entrée et 0,60 $/M en sortie, 2,5 M de jetons pour petits modèles par jour (Tier 1-2) représentent environ 1 à 2 $ de crédit gratuit quotidien, soit une économie mensuelle de 30 à 60 $. Pour les Tier 3-5, cela monte à 10 M de jetons par jour, soit 120 à 240 $ d'économie par mois. Si votre seul objectif est d'obtenir ce quota, activer le partage pour l'ensemble de votre organisation n'est pas forcément rentable. Il est conseillé de créer un projet de test indépendant et de le configurer en mode "Selected".
Différence réelle entre l'API par défaut et l'activation du partage
Beaucoup d'équipes ne comprennent pas bien si les données envoyées via l'API par défaut sont utilisées pour l'entraînement. La politique réelle d'OpenAI est la suivante : les données de l'API par défaut ne sont pas utilisées pour l'entraînement, mais elles sont conservées pendant 30 jours pour la surveillance des abus (abuse monitoring). La rétention zéro des données (ZDR – Zero Data Retention) est une autre affaire : elle nécessite une demande spécifique auprès de l'équipe commerciale d'OpenAI pour les clients entreprises, et ne se résume pas à un simple bouton sur le tableau de bord.
Une fois cette base comprise, l'impact des deux options devient clair : activer "Inputs/Outputs" revient à "renoncer volontairement à la protection contre l'entraînement en vigueur depuis 2023", et activer "Eval/FT" revient à "contribuer en plus à la méthodologie d'évaluation". Aucune de ces options ne modifie la conservation de 30 jours pour la surveillance des abus, et elles ne sont pas cumulables avec la ZDR.
| Dimension | API par défaut (tout désactivé) | Activation Inputs/Outputs | Activation Eval/FT Data |
|---|---|---|---|
| Utilisé pour l'entraînement | ❌ Non | ✅ Oui | ✅ Oui + évaluation |
| Conservation (surveillance abus) | 30 jours | 30 jours | 30 jours |
| Données révocables | / | ❌ Irrévocable | ❌ Irrévocable |
| Compatibilité ZDR | ✅ ZDR possible | ❌ Incompatible | ❌ Incompatible |
| Cas d'usage idéal | Production / Conformité / PII | Dev / Test / Données publiques | Évaluation de benchmarks publics |
🎯 Conseil en matière de confidentialité : Si votre activité est soumise à des exigences de conformité (RGPD, HIPAA, NDA d'entreprise, PII clients, etc.), les deux options doivent rester désactivées. Faites transiter les flux hautement sensibles via une passerelle comme APIYI (apiyi.com) ou demandez la ZDR. S'il s'agit uniquement de projets personnels, d'outils internes ou de démonstrations lors de hackathons, vous pouvez activer les options en toute sérénité.
Cadre décisionnel : 4 points pour décider d'activer les contrôles de données OpenAI
Donner une réponse binaire "activer / désactiver" est trop simpliste. Utilisons une matrice basée sur 4 types de scénarios métier, chacun ayant sa configuration logique. Les deux dimensions clés sont : la sensibilité des données (le contenu traité implique-t-il de la confidentialité ou des secrets commerciaux ?) et le volume d'appels (la valeur réelle que vous pouvez tirer des quotas gratuits).
| Type d'activité | Sensibilité des données | Recommandation Inputs/Outputs | Recommandation Eval/FT |
|---|---|---|---|
| Développement perso / Hackathon | Faible | Activé pour tous | Activé pour tous |
| R&D interne / Sélection de modèles | Moyenne | Activé pour certains | Activé pour certains |
| Application To-C (avec PII) | Élevée | Désactivé ou sélectionné (projet dev) | Désactivé |
| Entreprise / Conformité | Très élevée | Désactivé + ZDR | Désactivé |
La première catégorie concerne les projets personnels ou les hackathons. Dans ce cas, la consommation de jetons provient principalement d'invites publiques (sujets de concours, code de démo). Activer le partage permet de bénéficier de subventions quotidiennes sans exposer d'informations sensibles. La seconde catégorie est la R&D interne : nous recommandons le mode "Selected" (sélectionné) — créez un projet dédié "data-share-test" pour les expériences partageables, tout en gardant vos projets principaux désactivés.
La troisième catégorie concerne les applications To-C, qui impliquent souvent des entrées utilisateur, des historiques de conversation ou des informations personnelles. Ici, il est conseillé de tout désactiver : le quota gratuit n'apporte pas un gain majeur, et une fois que les PII des utilisateurs sont intégrées dans le pipeline d'entraînement, elles deviennent impossibles à tracer. La quatrième catégorie concerne les entreprises ou les contextes de conformité (santé, finance, secteur public) : passez directement par la ZDR ou une passerelle de conformité comme APIYI (apiyi.com) pour éviter même la surveillance des abus sur 30 jours.
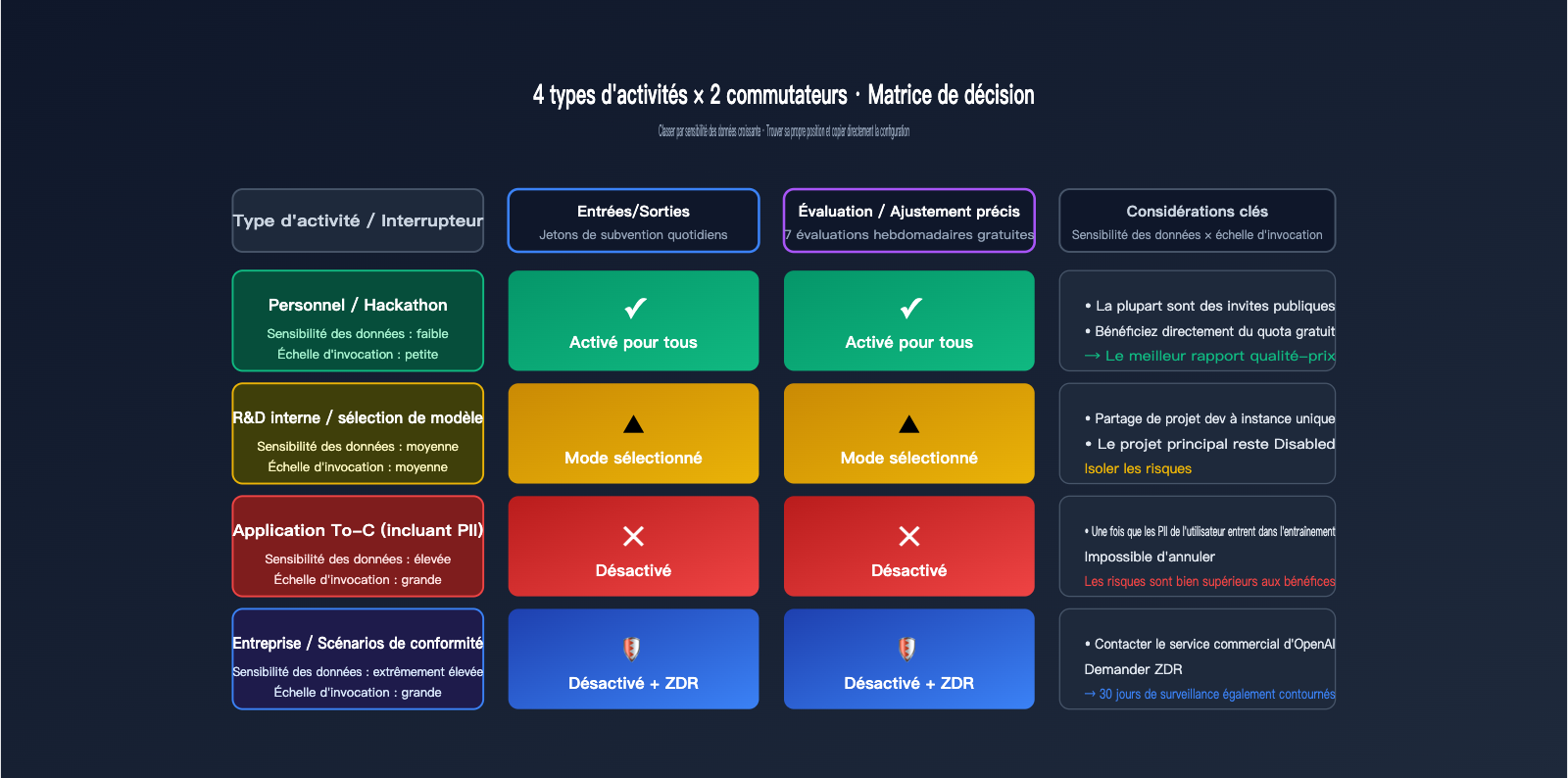
🎯 Comment choisir entre les options : Si vous décidez d'activer une option, privilégiez "Enabled for selected projects" plutôt que "Enabled for all projects". Cela permet d'isoler un projet "training-eligible" pour le développement ou les tests, tout en gardant vos projets de production isolés. En cas de changement futur, l'impact sera limité à ce seul projet, réduisant ainsi considérablement les coûts de migration.
FAQ sur les contrôles de données OpenAI
Q1 : Si j'active les options "Inputs/Outputs", OpenAI récupère-t-il immédiatement toutes mes données historiques ?
Non. Les deux options précisent explicitement : "Only traffic sent after turning this setting on will be shared" (Seul le trafic envoyé après l'activation de ce paramètre sera partagé) et "Only evaluation and fine-tuning data created after turning this setting on will be shared" (Seules les données d'évaluation et de fine-tuning créées après l'activation seront partagées). Les paramètres ne s'appliquent qu'aux données générées après l'activation ; les données historiques ne sont pas partagées rétroactivement.
Q2 : Les jetons gratuits sont-ils la même chose que les "Credit Grants" ?
Ce n'est pas la même chose, mais ils sont liés. Le partage via "Inputs/Outputs" permet d'obtenir un "pool de jetons quotidien", réinitialisé automatiquement à 00:00 UTC. Les "petits centimes" de crédits que vous voyez dans la section "Credit Grants" du tableau de bord OpenAI correspondent à la comptabilisation a posteriori de ce pool converti en valeur monétaire. Vous pouvez considérer cela comme deux manières de présenter le même programme.
Q3 : Si j'active le mode "Selected" pour un seul projet, le trafic de mon projet principal est-il totalement sécurisé ?
Tout à fait. Dans les paramètres, OpenAI permet de sélectionner précisément quels projets participent au partage. Le trafic des projets non sélectionnés est traité selon le comportement API par défaut : pas d'entraînement et conservation pendant 30 jours pour la surveillance des abus. Si cela vous inquiète toujours, vous pouvez rediriger le trafic de votre projet principal vers une passerelle comme APIYI (apiyi.com) pour isoler complètement les données au niveau de l'architecture.
Q4 : Comment sont comptabilisés les "7 free weekly evals" (7 évaluations gratuites par semaine) ?
Le comptage se base sur le "nombre d'exécutions" et non sur le nombre de jetons. Chaque exécution d'une évaluation (quel que soit le nombre d'échantillons traités) compte pour une unité, avec un maximum de 7 gratuites par semaine. Au-delà, les évaluations sont facturées au prix standard des jetons du modèle utilisé. Certains modèles ne sont pas inclus dans la liste gratuite et seront facturés dès la première exécution.
Q5 : Si je désactive les options "Inputs/Outputs", puis-je récupérer les données déjà collectées ?
Non. La politique d'OpenAI stipule clairement que les données déjà partagées ne peuvent être retirées. Désactiver les options empêche seulement les futures données d'entrer dans le pipeline d'entraînement. C'est pourquoi nous recommandons toujours d'utiliser une passerelle comme APIYI (apiyi.com) pour le trafic de production afin d'assurer une "isolation stricte" : les données ne sont par défaut jamais envoyées vers le pipeline d'entraînement d'OpenAI, ce qui est bien plus fiable qu'une désactivation a posteriori.
3 points clés sur les contrôles de données OpenAI
Premièrement, ces deux options sont de véritables "échanges bilatéraux" : vous échangez des données réelles et quantifiables (méthodologie d'évaluation, entrées/sorties API) contre des crédits gratuits quantifiables (7 évaluations par semaine, des millions à des dizaines de millions de jetons par jour). Comprenez qu'il s'agit d'une transaction et non d'un simple cadeau pour prendre les bonnes décisions.
Deuxièmement, l'API par défaut n'entraîne pas les modèles, mais la surveillance des abus pendant 30 jours reste active. Si votre activité est soumise à des exigences de conformité strictes, les deux options doivent être désactivées, et vous devriez envisager une demande ZDR ou utiliser une passerelle conforme comme APIYI (apiyi.com). Les options déterminent uniquement si vous autorisez un "entraînement supplémentaire", pas si vous êtes surveillé.
Troisièmement, privilégiez le mode "Selected" pour une "isolation par projet". Créez un projet indépendant dédié au développement ou aux tests pour bénéficier des crédits gratuits, tout en isolant totalement votre projet de production et vos données sensibles. C'est la stratégie la plus rentable : vous obtenez les crédits gratuits sans qu'aucune donnée utilisateur ne transite par le pipeline d'entraînement.
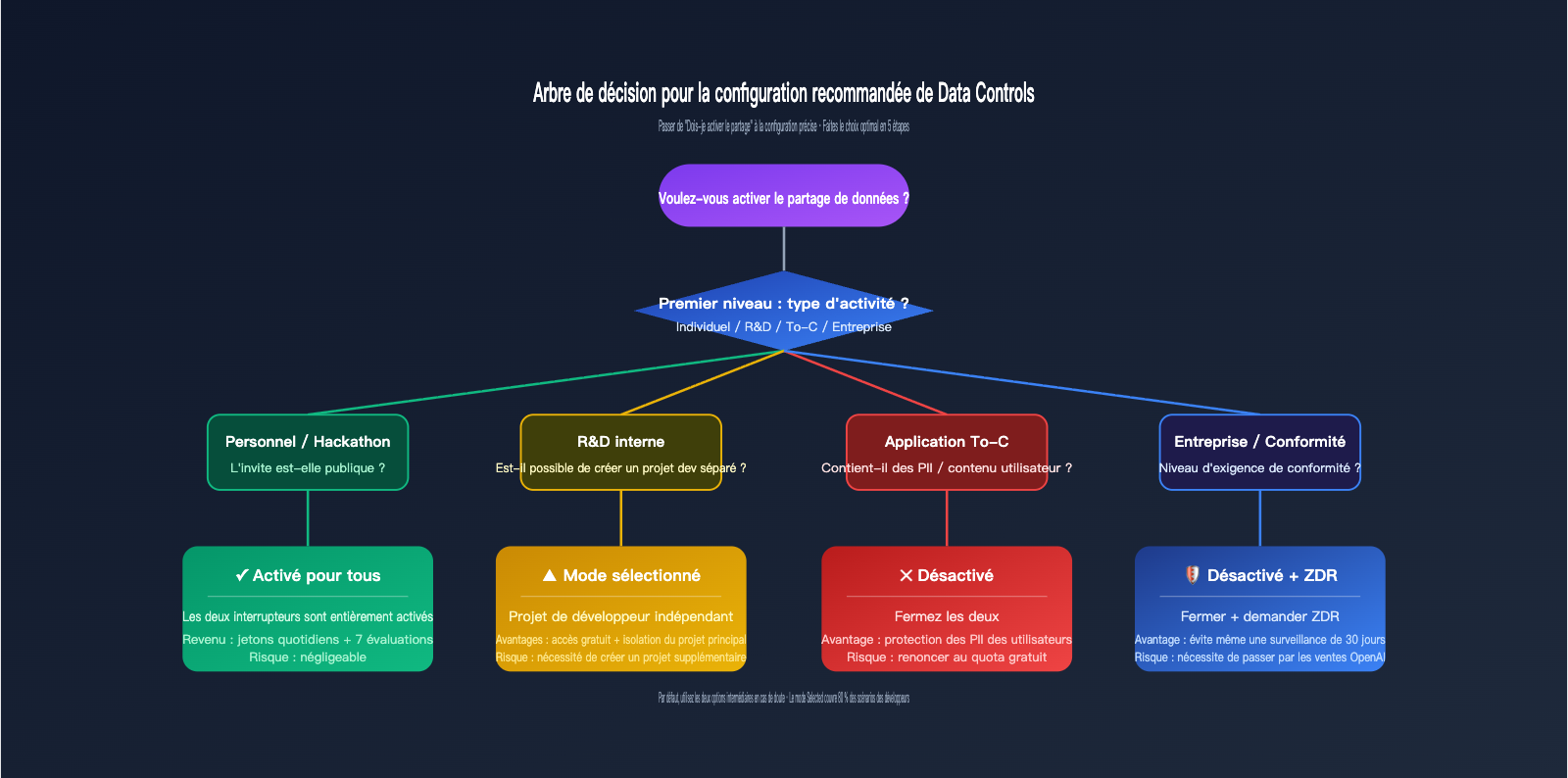
Si vous hésitez sur ces deux options, la méthode la plus prudente consiste à classer vos activités en quatre catégories (personnel / interne / To-C / entreprise), puis à utiliser le mode "Selected" pour créer un projet de test indépendant afin de profiter des crédits gratuits. Pour le trafic de production, passez par une passerelle APIYI (apiyi.com) pour assurer une isolation architecturale. Vous bénéficierez ainsi de la politique gratuite d'OpenAI tout en protégeant vos données utilisateur et votre savoir-faire métier.
📌 Auteur : Équipe technique APIYI — Nous suivons en continu les évolutions des politiques OpenAI (Data Controls, ZDR, stratégies de facturation) pour offrir aux développeurs une expérience de passerelle API multi-modèles avec facturation unifiée et confidentialité maîtrisée. Pour en savoir plus, visitez APIYI (apiyi.com).