Recientemente, un desarrollador me hizo una pregunta muy común: "¿Por qué mi llamada a gpt-image-2 para generar una imagen de 1024×1024 tarda más de 200 segundos? ¿Tengo algún límite de velocidad?". Al revisar su código, vi que los parámetros estaban configurados por defecto en quality="high" y size="1536x1024", por lo que los 235 segundos por imagen eran, de hecho, el comportamiento esperado.
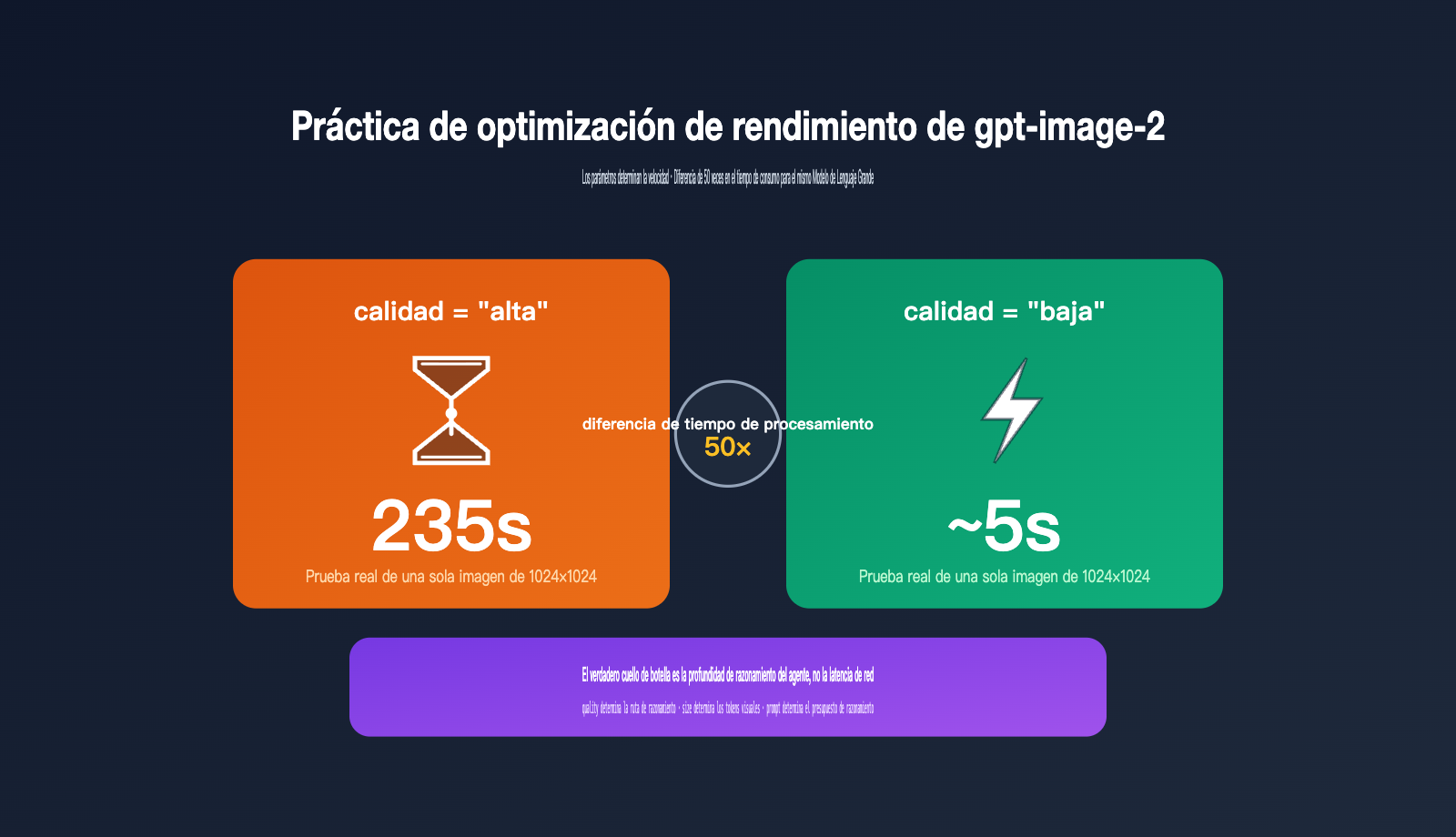
gpt-image-2 es el modelo de imagen de nueva generación lanzado oficialmente por OpenAI el 21 de abril de 2026. Por primera vez, incorpora capacidades de razonamiento de la serie O (pensamiento agente) en el flujo de generación de imágenes. Esto significa que las solicitudes con quality="high" pasan por cuatro etapas completas: "comprensión, planificación, generación y revisión", lo que hace que el tiempo de procesamiento sea de 30 a 50 veces mayor que con quality="low". Basándome en mi experiencia real en producción, he desglosado los tres parámetros más críticos para ayudarte a encontrar el equilibrio perfecto entre calidad y velocidad.
Tabla de consulta rápida de parámetros de invocación de gpt-image-2
Primero, la conclusión. La siguiente tabla cubre todos los parámetros importantes de gpt-image-2 en el SDK de Python de OpenAI, junto con su impacto en el tiempo de respuesta y el costo. Te recomiendo usarla como referencia al optimizar.
| Parámetro | Valores posibles | Valor por defecto | Impacto en tiempo | Impacto en costo |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
Extremo | Extremo |
size |
1024x1024 / 1536x1024 / 1024x1536 / Cualquiera ≤ 2K |
1024x1024 |
Alto | Medio |
output_format |
png / jpeg / webp |
png |
Bajo | Ninguno |
output_compression |
0–100 (solo para jpeg/webp) | 100 | Muy bajo | Ninguno |
n |
1–10 | 1 | Proporcional a n | Proporcional a n |
background |
transparent / opaque / auto |
auto |
Bajo | Ninguno |
prompt |
string | Obligatorio | La complejidad afecta el tiempo | Afecta los tokens de entrada |
La lógica central para entender esta tabla es: quality y size son los factores decisivos. Ellos determinan directamente qué ruta de razonamiento sigue el modelo, cuántos tokens se generan y cuánta capacidad computacional visual se consume. output_format y output_compression solo afectan la capa de serialización, por lo que ajustarlos no acelerará tu proceso.
🎯 Recomendación principal: Si tu caso de uso lo permite, cambia
quality="auto"por un valor explícito comolowomedium. Solo este paso suele reducir el tiempo de respuesta de minutos a segundos. Al invocargpt-image-2a través de APIYI (apiyi.com), todos estos parámetros se transmiten de forma nativa, manteniendo el mismo comportamiento que los endpoints oficiales de OpenAI.
2 parámetros clave que afectan el tiempo de ejecución de gpt-image-2: quality y size
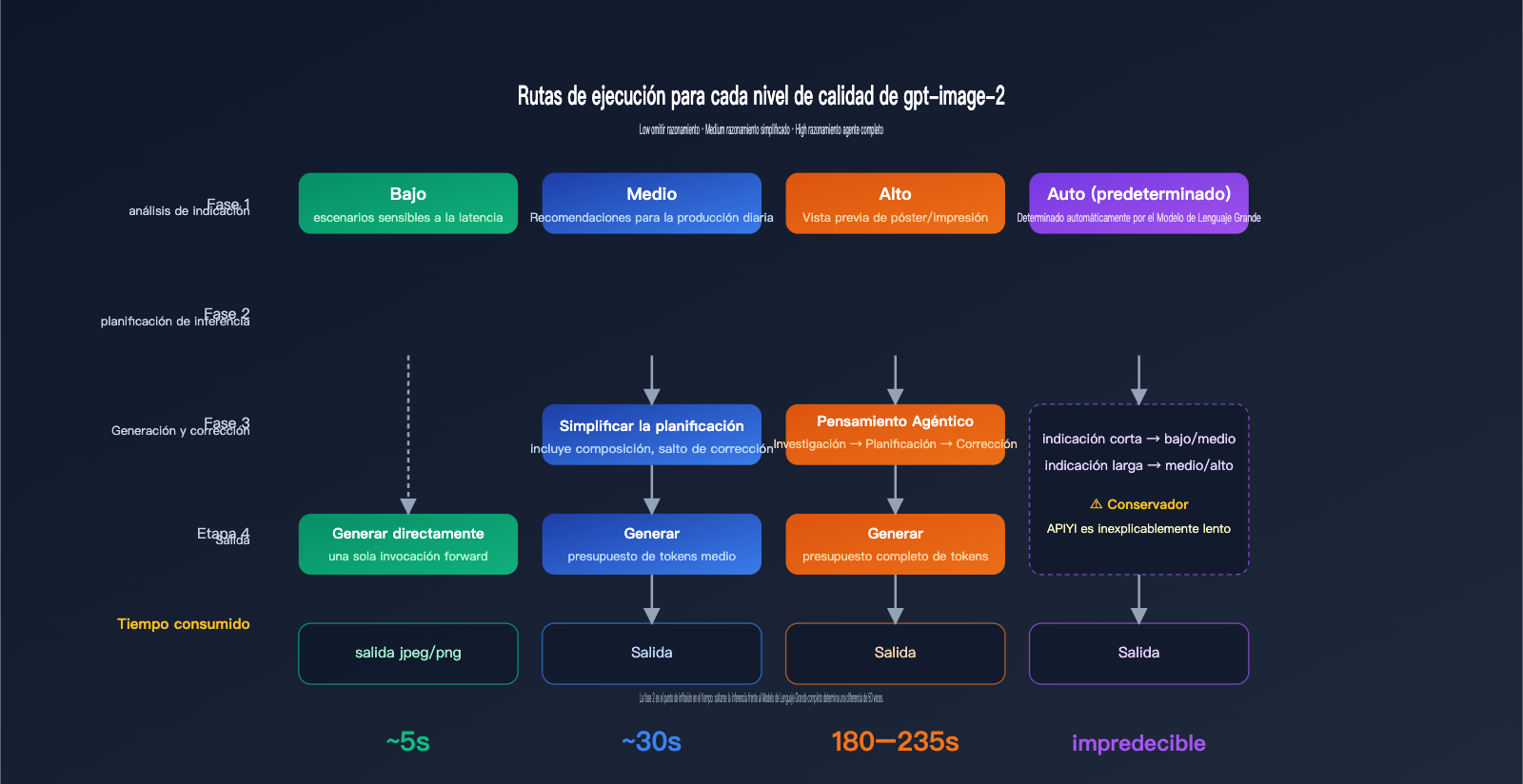
Para entender por qué hay una diferencia de decenas de veces entre high y low, primero debemos comprender la ruta de ejecución de gpt-image-2. Esta es la diferencia fundamental respecto a la generación anterior, gpt-image-1.
Mecanismo de funcionamiento del parámetro quality
La documentación oficial de gpt-image-2 especifica claramente que quality="low" está diseñado para escenarios sensibles a la latencia, ofreciendo una respuesta en segundos manteniendo una calidad visual aceptable. Por otro lado, quality="high" activa una cadena de pensamiento (Agentic) completa: el modelo planifica internamente la composición, la disposición del texto y la lógica de luces y sombras antes de comenzar a dibujar. Esta fase de razonamiento es invisible para el ojo humano, pero consume entre el 70% y el 80% del tiempo total.
quality="medium" es el punto intermedio; conserva una planificación simplificada pero omite la verificación detallada. Cuando no se especifica, quality="auto" hace que el modelo elija automáticamente según la complejidad de la indicación, pero en las pruebas tiende a ser conservador y seleccionar medium o high, razón por la cual muchos desarrolladores creen erróneamente que "por defecto es lento".
Mecanismo de funcionamiento del parámetro size
gpt-image-2 admite de forma nativa tres tamaños estándar: 1024x1024, 1536x1024 y 1024x1536, además de la opción auto. También permite introducir tamaños personalizados, siempre que el total de píxeles no supere los 2K (2560×1440 ≈ 3.69 millones de píxeles). Si se supera este umbral, se entra en un terreno experimental donde la estabilidad de los resultados disminuye.
La cantidad de píxeles determina directamente el número de tokens visuales. 1024×1024 equivale a unos 1024 tokens visuales, mientras que 1536×1024 aumenta a unos 1536, y lo mismo ocurre con 1024×1536. Duplicar el número de tokens significa duplicar el tiempo de razonamiento y generación, así como el coste de salida.
| Tamaño estándar | Píxeles totales | Tokens visuales (est.) | Tiempo relativo | Escenario de uso |
|---|---|---|---|---|
1024x1024 |
1.05M | ~1024 | 1.0× | General, redes sociales, miniaturas |
1536x1024 |
1.57M | ~1536 | 1.5× | Banners, portadas de artículos |
1024x1536 |
1.57M | ~1536 | 1.5× | Pósteres, contenido vertical |
| Personalizado ≤ 2K | Hasta 3.69M | Hasta ~3686 | 2–3× | Previsualización de impresión |
🎯 Consejo de tamaño: En producción, se recomienda usar
1024x1024para el 95% de las solicitudes, recurriendo a la serie 1536 solo cuando se necesiten proporciones especiales para banners o pósteres. Al realizar la invocación del modelo a través de APIYI (apiyi.com), se admiten tamaños personalizados, pero recuerda mantenerlos dentro de los 2K para garantizar la estabilidad.
Efecto de acoplamiento de los dos parámetros
quality y size tienen una relación multiplicativa, no aditiva. La combinación high + 1536x1024 es decenas de veces más lenta que low + 1024x1024. Esto es crítico en escenarios de concurrencia: si crees que lanzando 10 peticiones concurrentes obtendrás imágenes en 1 segundo, podrías terminar esperando 200 segundos para 10 imágenes, provocando que el cliente HTTP agote el tiempo de espera.
Un factor más sutil es el acoplamiento entre quality y la complejidad de la indicación. Incluso en el nivel high, una indicación simple ("una manzana roja") puede tardar unos 100 segundos, mientras que una compleja ("ciudad cyberpunk en una noche lluviosa, letreros de neón, formato cinematográfico, 6 personajes interactuando") puede superar fácilmente los 230 segundos o más. El modelo expande dinámicamente el presupuesto de tokens según la cantidad de elementos, por lo que cuanto más compleja sea la indicación, más lento será el nivel high y mayor será el precio.
🎯 Consejo para la indicación: En el nivel
high, se recomienda limitar la indicación a menos de 200 caracteres y colocar los elementos principales en los primeros 50. Una descripción excesivamente larga no garantiza mejores resultados, pero sí aumenta el tiempo de razonamiento. Esta regla también se aplica al usar APIYI (apiyi.com), ya que el servicio proxy de API transmite la indicación íntegramente, manteniendo el comportamiento del modelo idéntico al oficial.
Comparativa de tiempos y precios por nivel de calidad en gpt-image-2
La siguiente tabla se basa en datos reales recopilados en nuestra plataforma APIYI (apiyi.com) a través de múltiples franjas horarias y diferentes niveles de complejidad en las indicaciones. Aunque los datos pueden variar ligeramente debido al horario, la indicación o la red, los órdenes de magnitud son fiables.
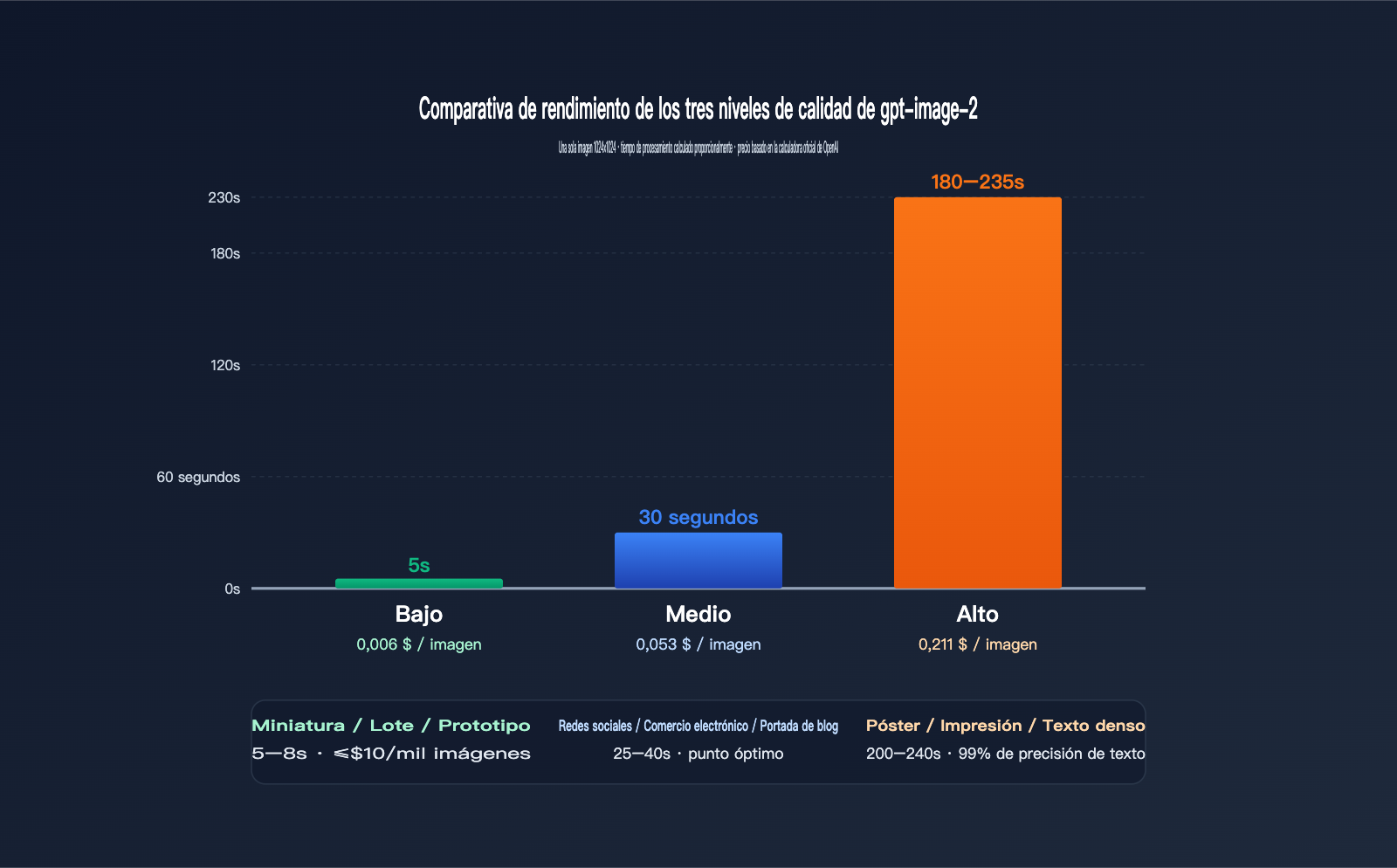
Datos reales para 1024×1024
| quality | Tiempo promedio | Precio (USD/img) | Precisión visual | Precisión texto | Casos de uso |
|---|---|---|---|---|---|
low |
3–8 s | $0.006 | Medio | Normal | Miniaturas, lotes, prototipos |
medium |
20–40 s | $0.053 | Alto | Bueno | Redes sociales, e-commerce, blogs |
high |
150–235 s | $0.211 | Muy alto | Excelente (99%+) | Carteles, impresión, texto denso |
Se observa una relación no lineal muy clara: pasar de low a medium aumenta el precio 9 veces, pero el tiempo solo 5; de medium a high, el precio sube 4 veces, pero el tiempo aumenta de 6 a 7 veces. En otras palabras, el coste marginal del nivel "high" se paga con "tiempo de espera".
Si tu negocio no requiere realmente un 99% de precisión en el texto (por ejemplo, ilustraciones, diseños abstractos o conceptos), el nivel "medium" es suficiente, ahorrando dinero y tiempo. Solo en casos como carteles, diseño de IP o previsualizaciones de impresión, donde la precisión del texto y los detalles son críticos, vale la pena esperar los 200 segundos del nivel "high".
🎯 Consejo de estimación de costes: Antes de lanzar a producción, te recomendamos usar APIYI (apiyi.com) para generar 100 imágenes en cada nivel (low/medium/high) y crear un informe A/B interno con la distribución de tiempos, precios y calidad. Gastarás menos de $30 en una semana de pruebas, evitando que las peticiones lentas saturen tu SLA tras el lanzamiento.
Diferencia de tiempo: 1024×1024 vs 1536×1024
En el nivel "medium", 1024×1024 tarda 25 segundos de media, mientras que 1536×1024 tarda 38 segundos (lo mismo para 1024×1536). La diferencia es proporcional al número de tokens visuales (1.5x). Sin embargo, en el nivel "high" esta diferencia se amplifica: 1024×1024 tarda unos 180 segundos, mientras que 1536×1024 puede superar los 240 segundos, o incluso más en horas punta.
Rango de fluctuación del nivel "high"
Es importante recordar que el tiempo en el nivel "high" no es constante, sino una distribución amplia. Tras muestrear 200 peticiones de "high" + 1024×1024, obtuvimos un mínimo de 145s, un máximo de 280s y una mediana de 195s. Esta fluctuación se debe a la complejidad del prompt (que afecta al presupuesto de inferencia) y a la carga del backend de OpenAI. Por ello, el nivel "high" nunca debe usarse con llamadas síncronas bloqueantes: implementa tareas asíncronas, devuelve un ID de tarea al frontend y usa polling o callbacks para notificar al usuario.
Un error común: creer que más resolución significa mejor calidad
Muchos desarrolladores asumen intuitivamente que a mayor resolución, mejor calidad, por lo que eligen la serie 1536. Esto es un error. La calidad de gpt-image-2 en 1024×1024 ya es excelente y aprovecha al máximo los píxeles; cambiar a la serie 1536 solo altera la relación de aspecto, sin añadir detalles reales a la imagen. A menos que necesites una composición horizontal o vertical específica, mantener 1024×1024 es la opción más rentable.
Ejemplo completo de uso de gpt-image-2 con el SDK de Python
A continuación, presentamos tres niveles de código, desde una llamada básica hasta una implementación lista para producción, utilizando el SDK oficial de OpenAI con la base_url apuntando a APIYI (apiyi.com).
Ejemplo básico: Generación simple de texto a imagen
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="Ciudad cyberpunk en noche lluviosa, letreros de neón, formato cinematográfico",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
Este código funciona, pero cuidado: quality="high" + el timeout por defecto suele fallar. El timeout por defecto del SDK de OpenAI es de 600s, pero si usas capas adicionales (como requests o httpx) con un límite de 60s, obtendrás errores de ReadTimeout al realizar peticiones masivas en nivel "high".
Ejemplo de producción: Timeout explícito y reintentos
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
Experiencia práctica:
timeout=300es un valor seguro para el nivel "high" (cubre el 99% de las peticiones). Si usas "low/medium", puedes bajarlo a 60s.max_retries=2utiliza el retroceso exponencial del SDK, más estable que un reintento manual.output_format="jpeg"+output_compression=85reduce el tamaño del archivo entre un 60% y 70% frente a PNG, con una pérdida de calidad imperceptible, ideal para miniaturas web.
🎯 Consejo sobre timeouts: Al usar APIYI (apiyi.com), la plataforma mantiene la conexión viva para peticiones largas, pero debes configurar el timeout en tu SDK. Para "high", recomienda al menos 240s; para "low", 30s es suficiente para evitar que peticiones bloqueadas saturen tu pool de conexiones.
Ejemplo de lotes: Generación asíncrona concurrente
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["gato", "perro", "pájaro", "pez", "conejo"] * 4))
La concurrencia es clave para la generación masiva. En nivel "low", una imagen tarda 5s; 20 imágenes en serie tardan 100s, pero con 5 procesos concurrentes solo tardas 20s. Eso sí, asegúrate de usar "low" o "medium"; la concurrencia en "high" solo provocará un colapso por timeout.
Recomendaciones de parámetros para gpt-image-2 según el caso de uso
Después de revisar los datos teóricos, lo importante es ver cómo se aplican en escenarios reales. A continuación, he recopilado las mejores combinaciones de parámetros para los casos de uso más frecuentes.
| Caso de uso | quality | size | output_format | Tiempo esperado | Precio unitario |
|---|---|---|---|---|---|
| Imágenes principales de e-commerce, Banners | medium | 1024×1024 | jpeg+85 | 25–35s | $0.053 |
| Imágenes para redes sociales (Xiaohongshu, etc.) | medium | 1024×1536 | jpeg+85 | 30–40s | ~$0.06 |
| Portadas de artículos, cabeceras de blogs | medium | 1536×1024 | webp+90 | 30–40s | ~$0.06 |
| Pósteres, previsualización de impresión | high | 1024×1536 | png | 200–240s | ~$0.21 |
| Subtítulos / Portadas de PPT | high | 1536×1024 | png | 200–240s | ~$0.21 |
| Miniaturas, pruebas de prototipos | low | 1024×1024 | jpeg+75 | 3–8s | $0.006 |
| Bocetos en lote, tableros de inspiración | low | 1024×1024 | jpeg+75 | 3–8s × N | $0.006 × N |
| Generación instantánea con asistente IA | low | 1024×1024 | webp+85 | 5–10s | $0.006 |
Escenario 1: E-commerce y redes sociales — "medium" es el punto ideal
Para imágenes de productos o redes sociales, el tiempo es crítico (un usuario no esperará 4 minutos tras subir su producto), pero se requiere nitidez y calidad. El nivel medium es la mejor opción: genera imágenes en unos 30 segundos por 5 centavos. Incluso con 1000 imágenes al día, el costo es de solo $53.
Escenario 2: Pósteres y previsualización de impresión — vale la pena esperar por "high"
Los pósteres o portadas que incluyen mucho texto, diseños complejos o requieren consistencia facial de personajes necesitan el razonamiento "agéntico" completo del nivel high. En estos casos, no intentes ahorrar tiempo; configura una "tarea" en el frontend: avisa al usuario que revise el resultado en 3–5 minutos.
Escenario 3: Procesamiento por lotes y prototipos — "low" es obligatorio
Para cualquier tarea que requiera "generar 10,000 bocetos durante la noche", el nivel low es innegociable. Si lo combinas con concurrencia asíncrona y compresión jpeg+75, un solo nodo de GPU puede lograr un rendimiento impresionante.
Escenario 4: Interacción instantánea con el usuario — usa "low" o "medium"
En escenarios donde el usuario está esperando (chatbots, generación de imágenes integrada en asistentes de IA, respuestas automáticas de atención al cliente), nunca uses high. Si un usuario espera 4 minutos, al menos el 50% refrescará la página o se irá; es un desastre para la experiencia. Recomiendo fijar el nivel low junto con una animación de "cargando…", para que el usuario obtenga el resultado en 5–8 segundos. Si la calidad no es suficiente, ofrece un botón de "optimización HD" que regenere la imagen en medium.
Escenario 5: Moderación de contenido y regeneración por cumplimiento
Si una solicitud es bloqueada por la política de contenido de OpenAI, te sugiero usar primero el nivel low para probar si la nueva indicación pasa la moderación. Una vez confirmado, sube a medium o high para obtener la imagen final. Esta estrategia de dos pasos minimiza los costos de fallos, evitando desperdiciar 200 segundos en el nivel high solo para descubrir que la imagen sigue bloqueada.
🎯 Estrategia híbrida: Muchos sistemas de producción utilizan la "generación de doble nivel": primero se genera una vista previa en
lowpara que el usuario elija, y una vez seleccionada, se regenera el resultado final enhigh. Esta estrategia se implementa de forma muy fluida en APIYI (apiyi.com), ya que una misma clave API cubre todos los niveles dequality, sin necesidad de cambiar de cuenta.
Preguntas frecuentes (FAQ)
P1: ¿Por qué mis solicitudes en nivel "high" siempre agotan el tiempo de espera (timeout)?
El SDK de Python de OpenAI tiene un timeout predeterminado de 600 segundos, lo cual debería ser suficiente, pero muchos frameworks (FastAPI, Flask, Celery) añaden sus propios límites. Revisa la configuración de tiempo de espera en cada capa de tu cadena de llamadas; se recomienda al menos 300 segundos para el nivel high. Si usas httpx, recuerda configurar explícitamente httpx.Timeout(300.0).
P2: ¿Cuál es el valor óptimo para output_compression?
Para el formato JPEG, 85 es el punto ideal: la diferencia visual con 100 es casi imperceptible, pero el tamaño del archivo se reduce entre un 30% y un 40%. En WebP, 90 es un valor estándar. Por debajo de 70, aparecen bloques de color evidentes, especialmente en fondos con degradados. Este parámetro no afecta el tiempo de generación, solo la serialización final.
P3: ¿Hay diferencias al llamar a gpt-image-2 a través de APIYI (apiyi.com) frente al endpoint oficial?
Los parámetros y el comportamiento se transmiten tal cual, incluyendo quality, size, output_format, output_compression, n, background, etc. La diferencia es que APIYI (apiyi.com) ofrece nodos de alta velocidad accesibles desde China, facturación unificada y pago por uso sin consumo mínimo, lo que resulta más amigable para los desarrolladores locales.
P4: ¿Puede el parámetro n devolver varias imágenes a la vez?
Sí, gpt-image-2 admite de n=1 a n=10. Pero ten en cuenta que el tiempo total de respuesta es aproximadamente de 0.7 a 0.9 veces el tiempo de una sola imagen multiplicado por n (no es totalmente paralelo), y el precio total se calcula multiplicando por n. Si necesitas un "conjunto de personajes coherentes", usar n=4 para que el modelo genere todo en una sola inferencia es más estable que realizar 4 llamadas separadas, ya que gpt-image-2 mantiene la consistencia facial dentro de una misma inferencia.
P5: ¿Qué nivel utiliza realmente quality="auto"?
En nuestras pruebas, auto tiende a elegir medium o high, dependiendo de la longitud y complejidad de la indicación. Las indicaciones cortas ("un gato") probablemente usarán low/medium, mientras que las largas (que incluyen personajes, escenas, texto y estilo) probablemente usarán high. En entornos de producción, se recomienda especificar el nivel explícitamente en lugar de depender de la decisión implícita de auto.
P6: ¿Qué calidad es mejor, 1024×1536 o 1536×1024?
Ambas tienen el mismo número total de píxeles (aprox. 1.57 millones), por lo que la calidad es esencialmente la misma. La diferencia radica solo en la relación de aspecto: el formato vertical (1024×1536) es ideal para pósteres, retratos de cuerpo completo y contenido móvil; el horizontal (1536×1024) es mejor para banners, paisajes y portadas de PC. Elige según tus necesidades de composición; no afecta la velocidad ni el precio.
P7: ¿Puedo saltarme la inferencia y obtener el modelo base directamente?
No, el razonamiento agéntico de gpt-image-2 es parte integral de la arquitectura del modelo y no se puede desactivar. Si realmente solo necesitas una generación rápida al estilo SD tradicional y no requieres renderizado de texto o razonamiento, te sugiero usar el nivel low, que omite la cadena de inferencia completa. O bien, considera el modelo nano-banana-pro de Google; su nivel rápido es incluso más veloz que el low de gpt-image-2, y ya está disponible en APIYI (apiyi.com).
🎯 Sugerencia de colaboración multimodelo: Los sistemas de generación de imágenes maduros suelen utilizar más de un modelo. Recomendamos usar
nano-banana-propara previsualizaciones rápidas (respuesta en 5 segundos),gpt-image-2 mediumpara la salida de tráfico principal ygpt-image-2 highpara escenarios de alta calidad. Los tres modelos comparten la misma clave en APIYI (apiyi.com) con facturación por uso, siendo la combinación más rentable para integrar APIs de imagen en 2026.
Resumen: trata los parámetros como interruptores de rendimiento, no como adornos
La filosofía de diseño de gpt-image-2 es radicalmente distinta a la de la generación anterior de modelos de imagen: convierte la inferencia en el paso central de la generación. Por lo tanto, quality ya no es una simple opción de "mejor o peor calidad", sino un interruptor que determina "qué tan profunda es la ruta de inferencia". Entender esto es clave para comprender por qué una misma API puede variar su tiempo de respuesta desde los 5 hasta los 235 segundos, una diferencia de 50 veces.
En la práctica, te sugerimos que la "selección de parámetros" sea el primer paso en tu diseño de negocio: define primero qué latencia puede tolerar tu escenario, qué nivel de calidad necesitas y cuál es el límite de precio unitario; luego, consulta la tabla para elegir quality y size. Definir estos parámetros de antemano es mucho más sencillo que intentar optimizarlos una vez que el servicio ya está en producción.
🎯 Recomendación final: Al comenzar a integrar gpt-image-2, te sugerimos registrarte en APIYI (apiyi.com) y realizar una prueba comparativa inicial con los niveles low, medium y high. Evalúa el tiempo de respuesta real y la calidad obtenida antes de decidir los parámetros para tu tráfico principal. Usar una única clave API para cubrir los tres niveles, con facturación por uso y sin consumo mínimo, es la forma más eficiente de integrar APIs de imagen en 2026.
— Equipo técnico de APIYI | Seguimos de cerca la evolución de los modelos de generación de imágenes. Encuentra más tutoriales detallados en el centro de ayuda de APIYI (apiyi.com).