Recientemente, un proyecto de código abierto en GitHub llamado ARIS-Code ha superado silenciosamente las 8400 estrellas y 783 forks. Fue desarrollado por el usuario wanshuiyin, quien iteró sobre la versión de código abierto de Claude Code. Su nombre completo es Auto-Research-In-Sleep (Investigación automática mientras duermes). No es solo marketing: realmente permite que Claude Code ejecute experimentos, busque bibliografía y modifique artículos mientras duermes, permitiendo que al despertar tu progreso de trabajo haya avanzado significativamente.
La discusión que ARIS-Code ha generado en el ámbito académico es especialmente notable: los tres casos de artículos comunitarios publicados por el autor muestran que los borradores generados alcanzaron una puntuación de 7-8/10 en evaluaciones de IA, y ya han sido enviados a conferencias de primer nivel en CS, AAAI 2026 e IEEE TGRS. Esto significa que la investigación científica totalmente automatizada por IA ya no es solo una demostración, sino que tiene la capacidad real de producir borradores listos para su envío.
En este artículo, analizaremos en profundidad la arquitectura central de ARIS-Code, sus 42 habilidades (Skills) integradas y cómo conectarlo a modelos Claude a través de un servicio proxy de API de terceros en entornos locales, para ayudarte a decidir si esta herramienta encaja en tu flujo de trabajo científico.
🎯 Nota especial: Dado que ARIS-Code es una iteración basada en la versión de código abierto de Claude Code, su ejecutor solo puede conectarse a modelos de la serie Claude (Sonnet/Opus/Haiku). No admite modelos de las series GPT o Gemini como ejecutor principal. Recomendamos conectarse a los modelos Claude a través de la plataforma APIYI (apiyi.com), que es compatible con el protocolo nativo de Anthropic, ofrece un acceso estable y un modelo de pago por uso, sin necesidad de tarjetas de crédito internacionales.
¿Qué es el proyecto ARIS-Code: Auto-Research-In-Sleep?
ARIS (Auto-Research-In-Sleep) es un sistema de flujo de trabajo de investigación autónomo orientado a investigadores académicos en ML/IA. La dirección del proyecto en GitHub es: github.com/wanshuiyin/Auto-claude-code-research-in-sleep. Su objetivo de diseño es muy claro: permitir que los investigadores completen todo el proceso —desde la revisión bibliográfica, generación de ideas, ejecución de experimentos, redacción de artículos hasta la respuesta a revisiones (Rebuttal)— con una intervención humana mínima, liberando a los investigadores del trabajo manual repetitivo.
La esencia de ARIS-Code es una biblioteca de metodologías. Todo el sistema está compuesto por archivos Markdown puros (SKILL.md); no hay marcos que instalar, bases de datos que mantener ni Docker que configurar. Cada habilidad (Skill) es una descripción del flujo de trabajo que puede ser leída por cualquier agente de Modelo de Lenguaje Grande. Por lo tanto, puedes cambiar el ejecutor de Claude Code a Codex CLI, OpenClaw, Cursor, Trae o cualquier otra herramienta que admita el modo Agente, y el flujo de trabajo seguirá siendo efectivo.
Este diseño de "cero dependencias y cero bloqueo" es la característica más importante que distingue a ARIS-Code de otras herramientas de IA para la investigación. En esencia, convierte el proceso de investigación en una ingeniería de indicaciones (indicación) explícita y ejecutable, en lugar de encapsularlo en una herramienta de caja negra. Esto es de gran importancia para los investigadores, ya que significa que el flujo de trabajo es legible, modificable y transferible, en lugar de estar atado a un producto comercial específico.
Vale la pena mencionar que el repositorio de ARIS-Code ya ha acumulado 719 commits y el proyecto sigue iterando rápidamente. En los últimos tres meses se han añadido habilidades de alto valor como paper-talk (generación de presentaciones para conferencias), resubmit-pipeline (flujo de trabajo para reenvío tras rechazo) y kill-argument (generación de contraargumentos adversarios), lo que mantiene el ecosistema muy activo.
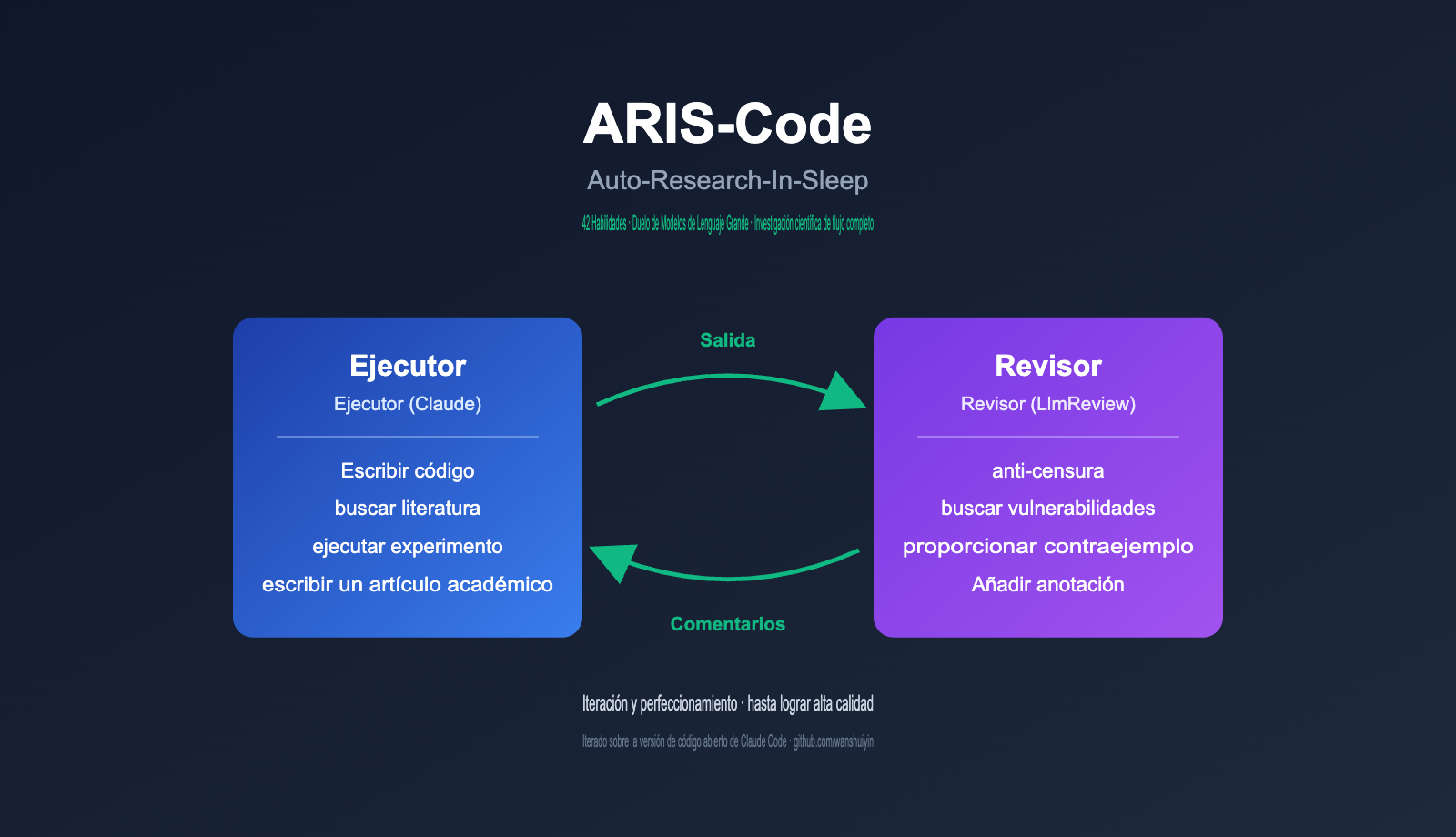
Arquitectura central de ARIS-Code: El sistema de revisión adversarial Executor-Reviewer
El valor de ingeniería más crítico de ARIS-Code reside en su arquitectura adversarial de doble modelo, lo que marca la diferencia fundamental respecto a otros asistentes de investigación en el mercado. El autor del proyecto plantea en el README una observación profunda: la autoevaluación de un solo modelo presenta debilidades estructurales, ya que cuando el mismo modelo ejecuta la tarea y revisa el resultado, tiende a reproducir sistemáticamente sus propios puntos ciegos, cayendo en la trampa del óptimo local.
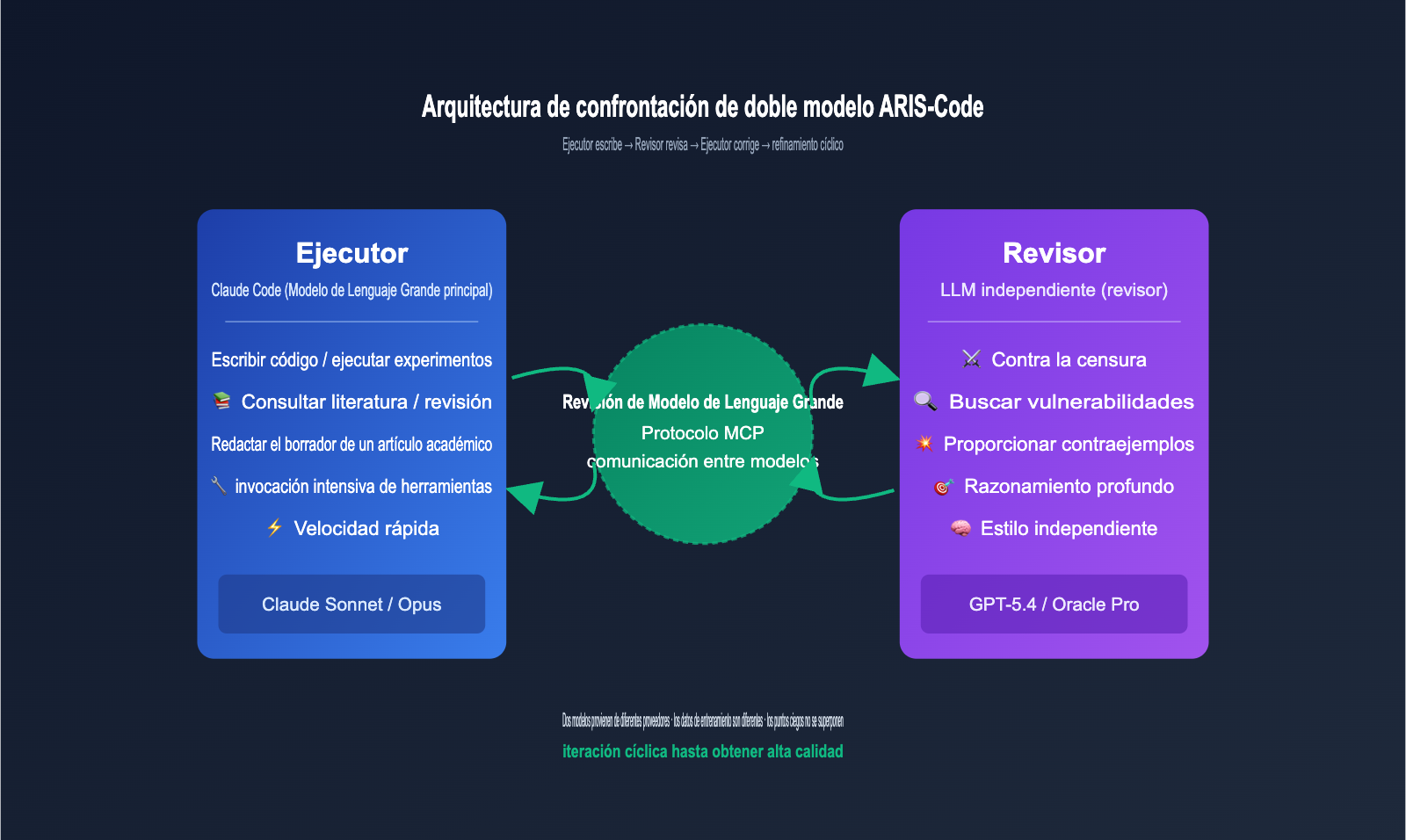
La solución propuesta por ARIS-Code consiste en delegar la autoridad de revisión a un modelo completamente independiente. La división de roles es la siguiente:
| Rol | Selección de modelo | Definición de responsabilidad | Tendencia de capacidad recomendada |
|---|---|---|---|
| Executor (Ejecutor) | Claude Sonnet / Opus | Ejecución principal: escribir código, buscar literatura, ejecutar experimentos, redactar artículos | Alta velocidad, ventana de contexto amplia, invocación de herramientas estable |
| Reviewer (Revisor) | GPT-5.4 (Codex MCP) / Oracle Pro | Revisión adversarial: encontrar vulnerabilidades, cuestionar conclusiones, proponer contraejemplos | Razonamiento profundo, pensamiento crítico, estilo independiente |
| Mecanismo de coordinación | Cadena de herramientas LlmReview | Comunicación entre modelos, persistencia de estado | Transmisión transparente mediante protocolo MCP |
El flujo de trabajo completo se puede resumir en un ciclo sencillo: El Executor escribe → El Reviewer critica → El Executor corrige → Se repite el proceso hasta que el Reviewer otorga su aprobación. Este ciclo es efectivo porque ambos modelos provienen de diferentes fabricantes, tienen datos de entrenamiento distintos y estilos de razonamiento diferentes, por lo que sus puntos ciegos no se solapan.
Para evitar que las alucinaciones de los Modelos de Lenguaje Grande contaminen las conclusiones científicas, ARIS-Code también ha diseñado una cadena de auditoría de evidencia de múltiples capas: experiment-audit (integridad del código) → result-to-claim (resultados a afirmaciones) → paper-claim-audit (auditoría de afirmaciones del artículo) → citation-audit (verificación de citas). Cada capa cuenta con un veredicto JSON independiente y un hash SHA256 para la verificación de reproducibilidad; este rigor de ingeniería es bastante inusual en herramientas de IA para la investigación.
🔧 Sugerencia de configuración: Si deseas reproducir completamente la arquitectura de doble modelo de ARIS-Code, en entornos locales recomendamos obtener las claves API de Claude y de la serie GPT a través de APIYI (apiyi.com). Una sola plataforma gestiona ambos conjuntos de interfaces, evitando la necesidad de abrir cuentas en el extranjero o vincular tarjetas de crédito por separado.
Pipeline científico completo con 42 Skills integrados en ARIS-Code
Lo más impresionante de ARIS-Code son sus más de 42 Skills integrados. Estas habilidades no son herramientas aisladas, sino un pipeline que cubre todo el ciclo de vida de la investigación. Los he clasificado según la etapa del flujo de trabajo:
| Etapa del flujo de trabajo | Skills representativos | Capacidad central |
|---|---|---|
| Etapa de selección (Idea Discovery) | research-lit / novelty-check / idea-creator / idea-discovery | Búsqueda bibliográfica multifuente, verificación de novedad entre modelos, generación de 8-12 ideas candidatas |
| Etapa experimental (Experimentation) | experiment-bridge / experiment-queue / run-experiment | Revisión de código → despliegue en GPU → orquestación de semillas múltiples → manejo automático de OOM |
| Revisión automática (Auto Review) | auto-review-loop / research-review / experiment-audit | 4 rondas de mejora iterativa, revisión por pares estructurada, verificación de integridad del código |
| Redacción de artículos (Paper Writing) | paper-writing / paper-claim-audit / proof-checker / citation-audit | Narrativa → LaTeX → PDF, auditoría de afirmaciones, verificación de pruebas, verificación de citas |
| Respuesta a Rebuttal | rebuttal | Análisis de comentarios de revisores → redacción de respuestas → pruebas de estrés |
| Meta-habilidades | research-wiki / meta-optimize / deepxiv | Base de conocimientos persistente, optimización de bucle externo, fuentes bibliográficas alternativas |
El Skill con mayor valor práctico es experiment-bridge, que integra "revisión de código → despliegue remoto en GPU → inicio de experimento → recuperación de resultados" en un solo pipeline. Cuando el Reviewer sugiere "aquí es necesario realizar un experimento de ablación", el Executor escribe automáticamente el script, lo sincroniza mediante rsync al nodo de GPU, inicia el entrenamiento, monitorea los registros y recopila los resultados; todo el proceso ocurre sin intervención manual del investigador.
Otro punto destacable es el Skill citation-audit, que elimina el mayor dolor de cabeza al redactar artículos con modelos de lenguaje: las alucinaciones en las citas, al conectarse a bases de datos reales como DBLP y CrossRef. Cada BibTeX proviene de una base de datos real, no de una invención del modelo. Este es un requisito básico para la escritura académica; cualquier cita ficticia puede provocar el rechazo directo del artículo.
Los investigadores también aprecian especialmente research-wiki, una base de conocimientos persistente entre sesiones que acumula notas de lectura, borradores de ideas y registros de experimentos fallidos, formando una memoria de investigación privada que crece constantemente. Cuando retomas una línea de investigación tras tres meses de pausa, no necesitas volver a leer todos los artículos relacionados; el asistente de IA ya ha conservado el contexto por ti.
💡 Consejo de uso: La invocación de cualquier Skill consume una gran cantidad de tokens de la API de Claude, especialmente en tareas de generación de texto largo como paper-writing. Recomendamos acceder a los modelos de Claude a través de apiyi.com, ya que la plataforma admite facturación por uso y proporciona un monitoreo completo del consumo de tokens, facilitando la estimación de costos por artículo.
Configuración completa para conectar ARIS-Code a APIYI
Dado que el ejecutor de ARIS-Code es una iteración basada en la versión de código abierto de Claude Code, solo acepta el protocolo API nativo de Anthropic. Esto significa que los modelos de las familias GPT y Gemini no pueden utilizarse como ejecutor. Esta es una restricción estricta y, a menudo, el punto de mayor confusión para los desarrolladores durante su primera implementación.
Los pasos para conectar modelos de Claude a través de APIYI son muy sencillos y pueden resumirse en 5 pasos:
# Paso 1: Clonar el repositorio del proyecto
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# Paso 2: Instalar Skills en el directorio de configuración local de Claude Code
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# Paso 3: Configurar la dirección del servicio proxy de API de APIYI (paso clave)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="Tu clave API de APIYI"
# Paso 4: Iniciar Claude Code
claude
# Paso 5: Invocar cualquier Skill dentro de Claude Code
# Por ejemplo: /research-pipeline "factorized gap in discrete diffusion LMs"
Lo más importante aquí es el paso 3, donde se configura la variable de entorno ANTHROPIC_BASE_URL. Esto le indica a Claude Code que no solicite el endpoint oficial de Anthropic, sino que utilice la puerta de enlace (gateway) del servicio proxy. La interfaz de esta puerta de enlace es totalmente compatible con el protocolo nativo de Anthropic, por lo que no es necesario modificar el código de los Skills integrados en ARIS-Code; todas las funciones, incluyendo llamadas a herramientas, salida en streaming y cadenas de pensamiento (thinking), se transmitirán de forma transparente.
Si también necesitas implementar el lado del revisor (Codex MCP), el proceso es:
# Instalar Codex MCP para el lado de revisión
npm install -g @openai/codex
codex setup # Aquí también puedes ingresar la dirección del servicio proxy para modelos GPT
claude mcp add codex -s user -- codex mcp-server
Para los investigadores que deseen reproducir completamente los efectos a nivel de artículo científico de ARIS-Code, el proyecto también ofrece una solución de conexión Oracle MCP utilizando GPT-5.4 Pro como revisor avanzado. Este esquema es muy útil durante la fase crítica de redacción del artículo, ya que la profundidad de crítica y la capacidad de construcción de contraejemplos de la versión Pro son significativamente superiores a las de la versión básica.
🚀 Solución de acceso unificado: La plataforma APIYI (apiyi.com) admite simultáneamente las familias Claude (Sonnet 4.5/Opus 4), GPT (GPT-5/o4) y Gemini (Gemini 3 Pro), entre otros modelos principales. Una sola clave API puede gestionar tanto el ejecutor como el revisor de ARIS-Code, lo cual es muy conveniente para la gestión de costos y el registro de invocaciones del modelo en equipos de investigación.
Niveles de esfuerzo de ARIS-Code y estrategias de configuración de GPU
ARIS-Code ofrece 4 niveles de Effort Level (nivel de esfuerzo) para equilibrar el costo y la calidad, un diseño muy orientado a la ingeniería. Las exigencias de profundidad varían enormemente según la etapa de la investigación: no hay necesidad de gastar tokens en la fase de exploración inicial, pero en la fase de envío del artículo, es necesario llevar la calidad al límite.
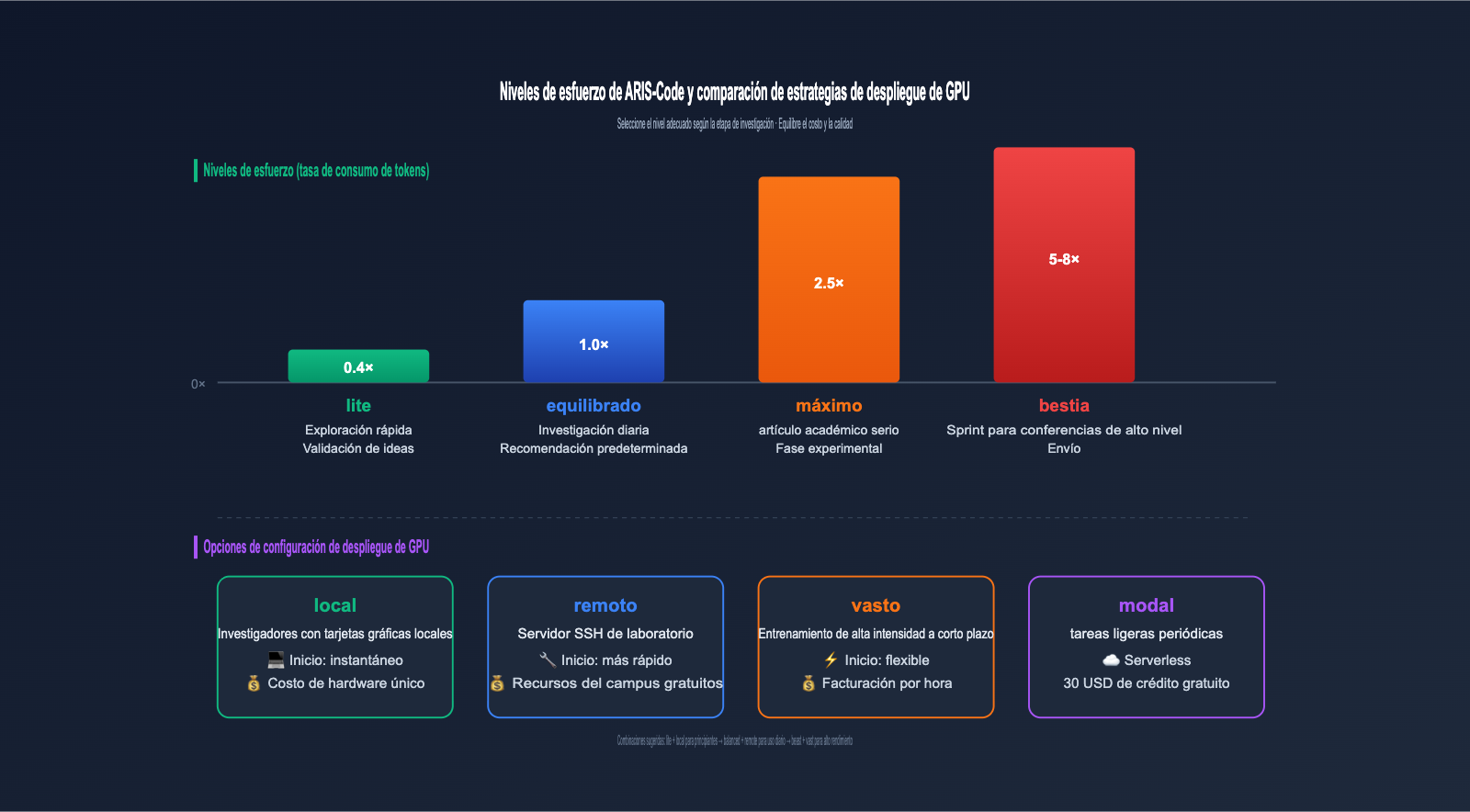
| Effort Level | Multiplicador de tokens | Escenarios de uso | Estimación por invocación |
|---|---|---|---|
| lite | 0.4× | Exploración rápida, validación de ideas | Muy bajo |
| balanced | 1.0× | Flujo de investigación diario predeterminado | Estándar |
| max | 2.5× | Fase experimental de artículos serios | Medio-alto |
| beast | 5-8× | Sprint para conferencias top, modo envío | Alto |
Para la GPU, ARIS-Code también ofrece 4 opciones de configuración, equilibrando las necesidades de quienes trabajan localmente y quienes usan la nube:
| Configuración GPU | Escenarios de uso | Características de costo |
|---|---|---|
| local | Investigadores con tarjeta gráfica local | Costo de hardware único |
| remote | Servidor SSH de laboratorio | Recursos universitarios gratuitos |
| vast | Entrenamiento intensivo a corto plazo | Pago por hora, flexible |
| modal | Tareas ligeras periódicas | Serverless, 30 USD de crédito gratuito |
💰 Consejo de control de costos: Si estás empezando a probar ARIS-Code, te sugiero usar primero lite + local para validar el flujo, utilizando el servicio proxy de apiyi.com para facilitar el cálculo del consumo de tokens. Una vez que el flujo sea estable, puedes actualizar a los modos max o beast para investigaciones serias; esto evitará desperdiciar costos elevados de tokens debido a errores de configuración iniciales.
Flujo de trabajo práctico con ARIS-Code: De una frase a un artículo académico
Lo más impresionante de ARIS-Code es su pipeline de extremo a extremo /research-pipeline, una habilidad (Skill) que conecta todas las etapas mencionadas en un solo comando. Solo necesitas proporcionar una descripción de la dirección de investigación y el sistema generará automáticamente un borrador en un plazo de 8 a 24 horas.
La forma típica de invocarlo es la siguiente:
# Escenario 1: Nuevo campo, empezando desde cero
/research-pipeline "factorized gap in discrete diffusion LMs"
# Escenario 2: Mejorar un artículo existente
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# Escenario 3: Solo refutación (Rebuttal)
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
Durante la ejecución, ARIS-Code sigue un proceso paso a paso: revisión bibliográfica → generación de ideas → verificación de novedad → diseño experimental → programación de GPU → recopilación de resultados → redacción del artículo → auditoría de citas → empaquetado de formato. Cuando encuentra puntos de decisión ambiguos, se detiene y espera un punto de control humano; con la configuración predeterminada --AUTO_PROCEED false, puedes intervenir manualmente después de cada ronda de retroalimentación de los revisores.
ARIS-Code también ofrece un parámetro style-ref muy útil, con el que puedes especificar un artículo de referencia de estilo (por ejemplo, el mejor artículo histórico de la misma conferencia). El sistema imitará su estructura y ritmo narrativo, pero sin copiar párrafos específicos. Para los investigadores que buscan "tasa de aceptación", esto es casi una ventaja injusta, ya que las exigencias implícitas de los revisores de conferencias de alto nivel sobre el estilo suelen ser más difíciles de captar que el contenido mismo.
Otro detalle técnico destacable es que ARIS-Code integra sincronización bidireccional con Overleaf, monitoreo de curvas de entrenamiento en W&B y notificaciones móviles a través de Lark/Feishu. Cuando los experimentos en la GPU alcanzan un punto de inflexión clave, recibes una notificación inmediata en tu teléfono, logrando realmente "hacer investigación mientras duermes".
📊 Datos de rendimiento: Los tres casos de artículos comunitarios publicados por el autor muestran que los artículos generados por ARIS-Code obtuvieron puntuaciones de 7-8/10 en revisiones de IA (conferencias CS, AAAI 2026, IEEE TGRS). Sin embargo, el autor advierte claramente que los revisores humanos aportan perspectivas que los sistemas de revisión por IA no pueden captar, por lo que no pueden reemplazar completamente el control humano.
Preguntas frecuentes (FAQ) sobre ARIS-Code
Q1: ¿Por qué ARIS-Code no puede usar GPT-5 como ejecutor?
Debido a que ARIS-Code es una iteración derivada de la versión de código abierto de Claude Code, su capa de ejecución está totalmente bloqueada en el protocolo de API nativo de Anthropic, incluyendo el formato de llamada a herramientas, el formato de salida en streaming y el formato de cadena de pensamiento, todos profundamente vinculados a los modelos de Claude. Si deseas cambiar el ejecutor, tendrías que usar distribuciones de OpenClaw o Codex CLI, pero eso ya no sería el ARIS-Code original. Recomendamos acceder a los modelos de Claude directamente a través de apiyi.com, que es la solución más sencilla.
Q2: ¿Cuántos tokens se necesitan aproximadamente para ejecutar un artículo completo?
En modo "beast", una ejecución completa de /research-pipeline consume entre 5 y 15 millones de tokens (entrada + salida), lo que equivale a un coste de entre decenas y cientos de dólares según los precios de Claude Sonnet. El modo "balanced" puede reducir esto a 2-5 millones de tokens. El coste específico depende de la complejidad del experimento y las rondas de iteración.
Q3: ¿Se puede usar ARIS-Code sin una GPU local?
Totalmente. ARIS-Code ha diseñado modos de GPU en la nube como "vast" y "modal"; este último incluso ofrece 30 dólares en crédito gratuito, más que suficiente para ejecutar experimentos ligeros. Si solo realizas artículos teóricos (/proof-writer + /formula-derivation), ni siquiera necesitas una GPU.
Q4: ¿Es obligatorio usar GPT-5.4 como revisor en la arquitectura de doble modelo?
No es obligatorio. El proyecto admite la sustitución por cualquier modelo compatible con el protocolo OpenAI, como GLM, MiniMax o Kimi. Recomendamos obtener múltiples modelos candidatos para revisores a través de plataformas de agregación como apiyi.com, lo que facilita realizar pruebas A/B para encontrar el LLM crítico que mejor se adapte a tu campo. Algunos investigadores informan que Gemini 3 Pro funciona sorprendentemente bien como revisor en artículos de razonamiento matemático, mientras que GPT-5.4 sigue siendo la opción preferida para artículos de optimización de ingeniería.
Q5: ¿Es ARIS-Code adecuado para estudiantes de grado o principiantes?
Es más adecuado para estudiantes de posgrado o personas con cierta experiencia en investigación. La razón es que la calidad de su producción depende en gran medida del juicio del investigador sobre el campo; por ejemplo, cuando un revisor plantea un contraejemplo, debes juzgar si es realmente un defecto crítico o un detalle irrelevante. Los principiantes sin experiencia pueden ser fácilmente desviados por la IA.
Q6: ¿Qué hacer si la red es inestable al ejecutar ARIS-Code en China?
La conexión directa a la interfaz oficial de Anthropic suele sufrir reinicios o tiempos de espera agotados, lo que provoca que las tareas largas de /research-pipeline fallen a mitad de camino. Una solución madura es cambiar ANTHROPIC_BASE_URL a un servicio proxy de API desplegado en un centro de datos local. De esta manera, ARIS-Code puede ejecutarse continuamente durante 8 horas en modo "sleep" sin interrupciones por fluctuaciones de red, lo cual es crucial para los experimentos continuos en modo "beast".
Resumen
La aparición de ARIS-Code confirma una tendencia importante: las herramientas de productividad científica en la era de los Modelos de Lenguaje Grande están pasando de la "asistencia puntual" a la "automatización de flujo completo". Su arquitectura de doble modelo Executor-Reviewer, sus 42 habilidades (Skills) de flujo de trabajo y su diseño basado en Markdown sin dependencias conforman un marco metodológico sumamente maduro.
Para los investigadores, el mayor obstáculo para implementar ARIS-Code no es la curva de aprendizaje técnica, sino la invocación estable de los modelos Claude. Recomendamos acceder a la familia de modelos Claude a través de la plataforma apiyi.com, obteniendo al mismo tiempo los modelos GPT necesarios para la parte del Reviewer. De esta manera, una sola plataforma puede cubrir todas las necesidades de modelos del flujo de trabajo de ARIS-Code, facilitando tanto la gestión de costos como la centralización de registros de invocación. Además, la estabilidad de los nodos IDC locales garantiza que el escenario principal de "ejecutar experimentos mientras duermes" no se vea interrumpido por problemas de red.
Si estás preparando una presentación para una conferencia importante o tienes una línea de investigación que deseas validar pero no tienes tiempo para iterar manualmente, vale la pena dedicar un fin de semana a probar ARIS-Code. Si al despertar realmente te encuentras con un borrador inicial, la inversión de tiempo habrá valido totalmente la pena.
📌 Autor: Equipo de APIYI — Enfocados a largo plazo en servicios de API de Modelos de Lenguaje Grande y ecosistemas de desarrolladores. Para más casos de integración de modelos Claude/GPT/Gemini, consulta el centro de documentación en apiyi.com.