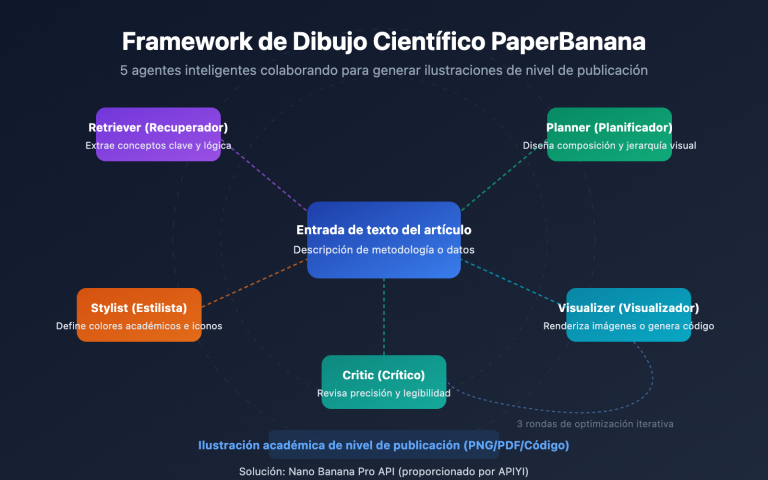
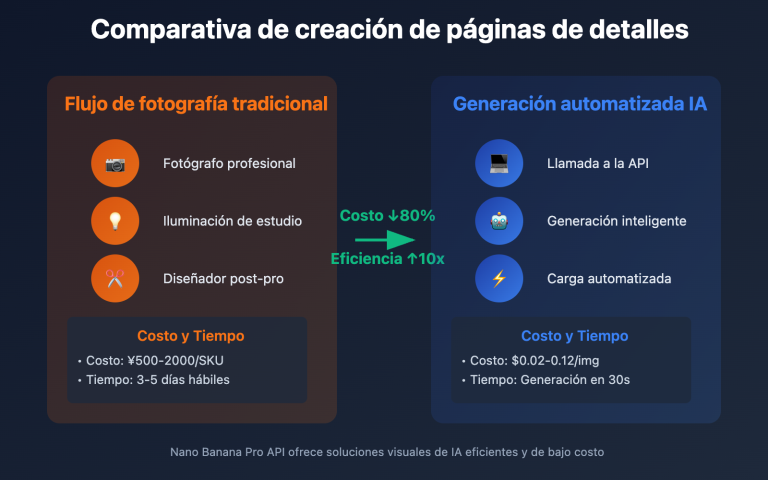
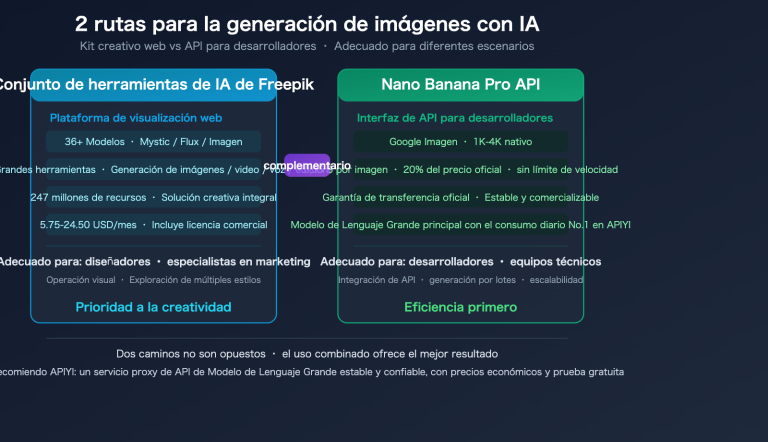
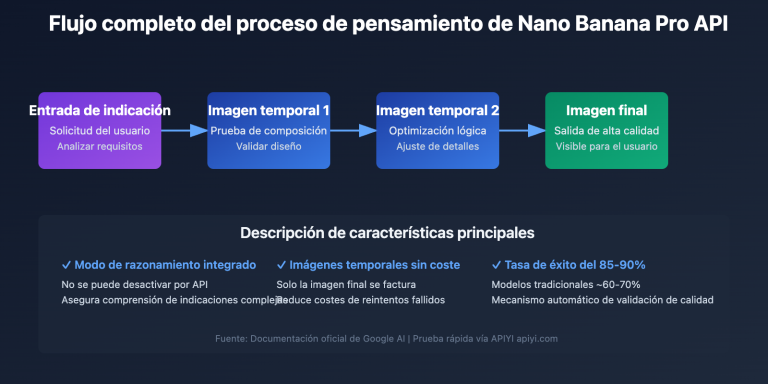
Nota del autor: Detalle de cómo PaperBanana utiliza la generación de código Matplotlib ejecutable en lugar de imágenes de píxeles para crear gráficos estadísticos científicos, eliminando por completo el problema de las alucinaciones numéricas. Cubre 7 tipos de gráficos, incluyendo diagramas de barras, gráficos de líneas y diagramas de dispersión.
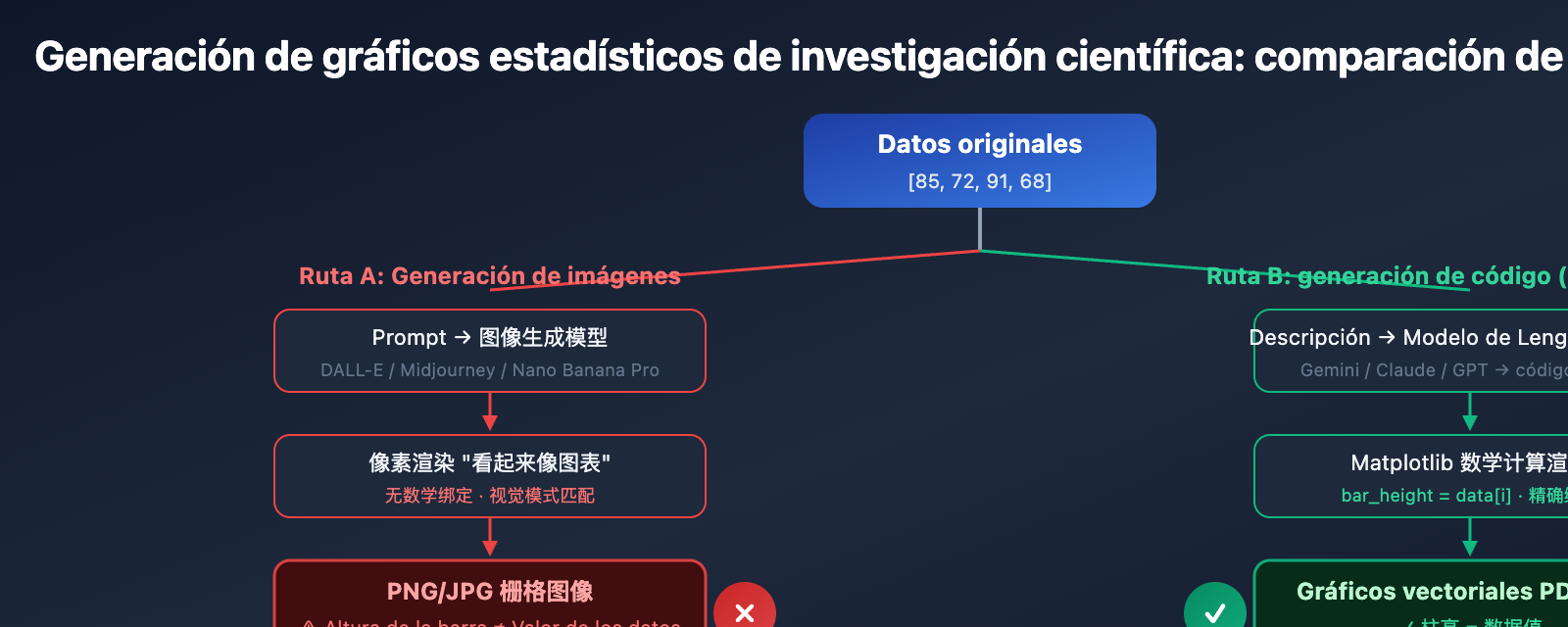
Los gráficos estadísticos en los artículos de investigación científica son el soporte de las conclusiones principales del experimento: la altura de una barra, la tendencia de una línea o la distribución de los puntos en un diagrama de dispersión; cada dato debe ser exacto. Sin embargo, al usar generadores de imágenes generales como DALL-E o Midjourney para crear estos gráficos, surge un problema crítico: la alucinación numérica (Numerical Hallucination). Alturas de barras que no coinciden con la escala, puntos de datos desplazados o etiquetas de ejes erróneas; estos gráficos que "parecen correctos pero tienen datos falsos" pueden tener consecuencias desastrosas si aparecen en una publicación académica.
Valor principal: Al terminar de leer este artículo, entenderás por qué PaperBanana prefiere la generación de código sobre la generación de imágenes para crear gráficos científicos, dominarás los métodos de generación de código Matplotlib para 7 tipos de gráficos estadísticos y aprenderás cómo lograr una visualización de datos académicos con cero alucinaciones y a bajo costo mediante la API de Nano Banana Pro.

Puntos clave de los gráficos estadísticos científicos en Nano Banana Pro
| Punto clave | Descripción | Valor |
|---|---|---|
| Generación de código en lugar de píxeles | PaperBanana genera código Matplotlib ejecutable en lugar de renderizar imágenes directamente | Altura de barras, puntos de datos y ejes 100% precisos matemáticamente |
| Eliminación total de alucinaciones numéricas | El enfoque basado en código garantiza que cada valor coincida exactamente con los datos originales | Elimina el problema crítico de "parece correcto pero los datos están mal" |
| Cobertura total de 7 tipos de gráficos | Gráficos de barras, líneas, dispersión, mapas de calor, radar, circulares y multipanel | Cubre más del 95% de las necesidades de gráficos estadísticos en artículos científicos |
| 240 pruebas de ChartMimic | Validación en benchmarks estándar de que el código generado funciona y coincide visualmente | 72.7% de tasa de éxito en evaluaciones ciegas, cubriendo líneas/barras/dispersión/multipanel |
| Editable y reproducible | El código Python de salida permite ajustar libremente colores, anotaciones y fuentes | Sin necesidad de regenerar; se puede pulir directamente hasta alcanzar el estándar de publicación |
Por qué los gráficos estadísticos científicos no deben generarse como imágenes
Los modelos tradicionales de generación de imágenes por IA (como DALL-E 3 o Midjourney V7) enfrentan un defecto fundamental al crear gráficos científicos: renderizan los gráficos como «píxeles» en lugar de dibujarlos basándose en «datos». Esto significa que, al generar un gráfico de barras, el modelo no calcula la altura de las barras basándose en valores como [85, 72, 91, 68], sino que rellena píxeles basándose en patrones visuales que «parecen un gráfico de barras».
El resultado son alucinaciones numéricas: alturas de barras que no coinciden con la escala del eje Y, puntos de datos desviados de su posición real y etiquetas de ejes con caracteres extraños o errores. En las evaluaciones de PaperBanana, las «alucinaciones numéricas y la duplicación de elementos» son los errores de fidelidad más comunes al usar modelos de generación de imágenes para crear gráficos estadísticos.
PaperBanana adopta una estrategia completamente diferente: para los gráficos estadísticos, el agente Visualizer no utiliza la capacidad de generación de imágenes de Nano Banana Pro, sino que genera código Python Matplotlib ejecutable. Este enfoque de «código primero» elimina de raíz las alucinaciones numéricas, ya que el código vincula los datos con los elementos visuales mediante cálculos matemáticos precisos.
Análisis profundo del problema de las alucinaciones numéricas
¿Qué son las alucinaciones numéricas en los gráficos estadísticos científicos?
Las alucinaciones numéricas se refieren al fenómeno en el que los modelos de generación de imágenes por IA producen elementos visuales que no coinciden con los datos reales al crear gráficos estadísticos. Las manifestaciones específicas incluyen:
- Desviación de la altura de las barras: La altura de las barras en un gráfico de barras no corresponde con los valores de la escala del eje Y.
- Desplazamiento de los puntos de datos: Los puntos en un gráfico de dispersión se desvían de las coordenadas (x, y) correctas.
- Errores de escala: Los intervalos de la escala en los ejes no son uniformes o las etiquetas numéricas son incorrectas.
- Confusión en la leyenda: Los colores de la leyenda no coinciden con las series de datos reales.
- Etiquetas ilegibles: Aparecen errores ortográficos o superposición de texto en las etiquetas de los ejes.
La causa raíz de las alucinaciones numéricas
El objetivo de entrenamiento de los modelos generales de generación de imágenes es "generar imágenes visualmente realistas", no "generar gráficos de datos precisos". Cuando el modelo ve en una indicación algo como "gráfico de barras, valores [85, 72, 91, 68]", no establece un mapeo matemático de los valores a la altura de los píxeles, sino que genera una apariencia aproximada basada en los "patrones visuales" de la gran cantidad de gráficos de barras presentes en su conjunto de entrenamiento.
| Tipo de problema | Manifestación específica | Frecuencia | Gravedad |
|---|---|---|---|
| Desviación de la altura | La altura de la barra no coincide con el valor | Muy alta | Fatal: Cambia la conclusión del experimento |
| Desplazamiento de puntos | Los puntos se desvían de las coordenadas correctas | Alta | Fatal: Distorsión de datos |
| Errores de escala | Escala del eje no uniforme | Alta | Grave: Induce a error al lector |
| Confusión en la leyenda | El color no coincide con la serie | Media | Grave: Imposible distinguir los datos |
| Etiquetas ilegibles | Texto superpuesto o errores ortográficos | Media | Moderada: Afecta la legibilidad |
Cómo el método de generación de código de PaperBanana elimina las alucinaciones numéricas
La solución de PaperBanana es sencilla y radical: para los gráficos estadísticos científicos, no genera imágenes, sino código.
Cuando el agente Visualizer de PaperBanana recibe una tarea de gráfico estadístico, convierte la descripción del gráfico en código Python Matplotlib ejecutable. En este código, la altura de cada barra, las coordenadas de cada punto de datos y la escala de cada eje se determinan con precisión mediante cálculos matemáticos, en lugar de ser "adivinados" por una red neuronal.
Este enfoque de "código primero" también aporta un valor añadido importante: la editabilidad. No recibes una imagen rasterizada imposible de modificar, sino un fragmento de código Python claro. Puedes ajustar libremente los colores, las fuentes, las anotaciones, la posición de la leyenda e incluso modificar los datos subyacentes y volver a ejecutarlo, lo cual es especialmente útil durante la fase de revisión por pares de una revista científica.
🎯 Sugerencia técnica: La capacidad de generación de código de PaperBanana está impulsada por un Modelo de Lenguaje Grande. También puedes llamar directamente a modelos como Nano Banana Pro a través de APIYI (apiyi.com) para generar código Matplotlib. La plataforma es compatible con la interfaz de OpenAI y el coste por llamada es extremadamente bajo.
Generación de código para 7 tipos de gráficos estadísticos científicos con Nano Banana Pro
PaperBanana ha verificado la eficacia del método de generación de código en 240 casos de prueba del benchmark ChartMimic, cubriendo tipos comunes como gráficos de líneas, de barras, de dispersión y multipanel. A continuación, se presentan plantillas de indicación y ejemplos de código para 7 tipos de gráficos científicos.
Categoría 1: Gráfico de barras (Bar Chart)
El gráfico de barras es uno de los tipos más utilizados en artículos científicos para comparar resultados experimentales bajo diferentes condiciones.
import matplotlib.pyplot as plt
import numpy as np
# 实验数据
models = ['GPT-4o', 'Claude 4', 'Gemini 2', 'Llama 3', 'Qwen 3']
accuracy = [89.2, 91.5, 87.8, 83.4, 85.1]
colors = ['#3b82f6', '#10b981', '#f59e0b', '#ef4444', '#8b5cf6']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(models, accuracy, color=colors, width=0.6, edgecolor='white')
# 添加数值标签
for bar, val in zip(bars, accuracy):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}%', ha='center', va='bottom', fontsize=10, fontweight='bold')
ax.set_ylabel('Accuracy (%)', fontsize=12)
ax.set_title('Model Performance Comparison on MMLU Benchmark', fontsize=14)
ax.set_ylim(75, 95)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('bar_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Categoría 2: Gráfico de líneas (Line Chart)
Los gráficos de líneas muestran tendencias a lo largo del tiempo o condiciones, ideales para curvas de entrenamiento y experimentos de ablación.
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 21)
train_loss = 2.5 * np.exp(-0.15 * epochs) + 0.3 + np.random.normal(0, 0.02, 20)
val_loss = 2.5 * np.exp(-0.12 * epochs) + 0.45 + np.random.normal(0, 0.03, 20)
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(epochs, train_loss, 'o-', color='#3b82f6', label='Train Loss', linewidth=2, markersize=4)
ax.plot(epochs, val_loss, 's--', color='#ef4444', label='Val Loss', linewidth=2, markersize=4)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Loss', fontsize=12)
ax.set_title('Training and Validation Loss Curves', fontsize=14)
ax.legend(fontsize=11, frameon=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('line_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Categoría 3: Gráfico de dispersión (Scatter Plot)
Se utiliza para mostrar la correlación entre dos variables o la distribución de clústeres.
Categoría 4: Mapa de calor (Heatmap)
Ideal para mostrar matrices de confusión, matrices de pesos de atención y matrices de coeficientes de correlación.
Categoría 5: Gráfico de radar (Radar Chart)
Se utiliza para la comparación de capacidades multidimensionales, común en la evaluación integral de modelos.
Categoría 6: Gráfico de tarta/anillo (Pie/Donut Chart)
Muestra proporciones de composición, adecuado para el análisis de distribución de conjuntos de datos y asignación de recursos.
Categoría 7: Gráfico combinado multipanel (Multi-Panel)
Combina varios subgráficos en una sola figura, siendo la forma de gráfico compuesto más común en los artículos científicos.
| Tipo de gráfico | Escenario de aplicación | Función clave de Matplotlib | Uso común |
|---|---|---|---|
| Gráfico de barras | Comparación discreta | ax.bar() |
Comparación de rendimiento, ablación |
| Gráfico de líneas | Cambio de tendencia | ax.plot() |
Curvas de entrenamiento, análisis de convergencia |
| Gráfico de dispersión | Correlación/Clúster | ax.scatter() |
Distribución de características, visualización de embeddings |
| Mapa de calor | Datos matriciales | sns.heatmap() |
Matriz de confusión, pesos de atención |
| Gráfico de radar | Comparación multidimensional | ax.plot() + polar |
Evaluación integral de modelos |
| Gráfico de tarta | Composición proporcional | ax.pie() |
Distribución de conjuntos de datos |
| Multipanel | Presentación compuesta | plt.subplots() |
Figura 1(a)(b)(c) |
💰 Optimización de costes: Al usar APIYI (apiyi.com) para llamar a un Modelo de Lenguaje Grande y generar código Matplotlib, el coste por cada llamada es mucho menor que el de la generación de imágenes. Generar un fragmento de 50 líneas de código Matplotlib cuesta aproximadamente $0.01, y el código se puede modificar y ejecutar repetidamente sin necesidad de llamar de nuevo a la API. También se recomienda usar la herramienta online Image.apiyi.com para verificar rápidamente el efecto de la visualización.
Guía rápida de Nano Banana Pro para gráficos estadísticos científicos
Ejemplo minimalista: Genera código para gráficos de barras precisos con IA
Esta es la forma más sencilla de llamar a un Modelo de Lenguaje Grande a través de una API para que la IA genere automáticamente código de Matplotlib basado en tus datos:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # 使用 APIYI 统一接口
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{
"role": "user",
"content": """Generate publication-ready Python Matplotlib code for a grouped bar chart.
Data:
- Models: ['Method A', 'Method B', 'Method C', 'Ours']
- BLEU Score: [32.1, 35.4, 33.8, 38.7]
- ROUGE-L: [41.2, 43.8, 42.1, 47.3]
Requirements:
- Grouped bars with distinct colors (blue and green)
- Value labels on top of each bar
- Clean academic style, no top/right spines
- Title: 'Translation Quality Comparison'
- Save as PDF at 300 dpi
- Figsize: (8, 5)"""
}]
)
print(response.choices[0].message.content)
Ver la herramienta completa de generación de código para gráficos científicos
import openai
from typing import Dict, List, Optional
def generate_chart_code(
chart_type: str,
data: Dict,
title: str,
style: str = "academic",
figsize: str = "(8, 5)",
save_format: str = "pdf"
) -> str:
"""
使用 AI 生成科研统计图的 Matplotlib 代码
Args:
chart_type: 图表类型 - bar/line/scatter/heatmap/radar/pie/multi-panel
data: 数据字典,包含标签 and 数值
title: 图表标题
style: 风格 - academic/minimal/detailed
figsize: 图表尺寸
save_format: 导出格式 - pdf/png/svg
Returns:
可执行的 Matplotlib Python 代码
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI统一接口
)
style_guide = {
"academic": "Clean academic style
## Técnicas de ingeniería de indicaciones para gráficos estadísticos científicos con Nano Banana Pro
La clave para que la IA genere código de Matplotlib de alta calidad reside en qué tan estructurada esté la **indicación**. Aquí tienes 5 técnicas fundamentales que han sido verificadas.
### Técnica 1: Los datos deben proporcionarse explícitamente
Nunca permitas que la IA "invente" los datos. Proporciona claramente los valores completos en la **indicación**, incluyendo etiquetas, valores numéricos y unidades.
```text
✅ Correcto: Datos: modelos=['A','B','C'], precisión=[89.2, 91.5, 87.8]
❌ Incorrecto: Genera un gráfico de barras comparando tres modelos
Técnica 2: Especificar restricciones de estilo académico
Los gráficos para artículos científicos tienen requisitos tipográficos estrictos. Define las siguientes restricciones en tu indicación:
- Eliminar los bordes superior y derecho (
spines['top'].set_visible(False)) - Jerarquía de tamaños de fuente: Título 14pt, etiquetas de ejes 12pt, marcas de graduación 10pt
- Paleta de colores apta para daltónicos (evitar la combinación rojo-verde)
- Salida en formato PDF/EPS con más de 300 dpi
Técnica 3: Solicitar anotaciones de valores numéricos
Añade etiquetas con valores precisos encima de las barras. Esto permite al lector interpretar los datos sin tener que recurrir constantemente a los ejes, y es una herramienta crucial para eliminar la "ambigüedad visual".
Técnica 4: Especificar la ejecutabilidad
Solicita explícitamente que el código generado pueda "ejecutarse directamente sin ninguna modificación". Esto obligará a la IA a incluir todas las sentencias import necesarias, las definiciones de datos y los comandos para guardar el archivo.
Técnica 5: Prever flexibilidad para las revisiones
Pide a la IA que coloque las definiciones de datos y los parámetros de estilo por separado en la parte superior del código. Esto facilitará enormemente realizar modificaciones rápidas más adelante.
| Técnica | Punto clave | Impacto en la calidad del código |
|---|---|---|
| 1 | Datos explícitos | Elimina la invención de datos y asegura la precisión |
| 2 | Restricciones de estilo académico | Cumple con los requisitos de maquetación de las revistas |
| 3 | Anotaciones numéricas | Mejora la legibilidad del gráfico |
| 4 | Ejecutabilidad | Código listo para usar desde el primer momento |
| 5 | Separación de parámetros | Duplica la eficiencia al realizar correcciones para los revisores |
🎯 Sugerencia práctica: Combina estas 5 técnicas en tu plantilla de indicación estándar. Utiliza APIYI (apiyi.com) para llamar a diferentes modelos e iterar hasta encontrar el estilo de código que mejor se adapte a tu campo de investigación. La plataforma permite alternar entre Gemini, Claude, GPT y otros modelos para comparar los resultados generados.
Preguntas frecuentes
P1: ¿Es más lento generar código que generar imágenes directamente en PaperBanana?
Al contrario, la generación de código suele ser más rápida. Generar un bloque de código Matplotlib de 50 a 80 líneas toma solo de 2 a 5 segundos, mientras que generar una imagen puede tardar de 10 a 30 segundos. Lo más importante es que, una vez generado el código, puedes ejecutarlo localmente y modificarlo repetidamente sin necesidad de llamar a la API cada vez. Usar un Modelo de Lenguaje Grande a través de APIYI (apiyi.com) para generar código cuesta aproximadamente $0.01 por vez, mucho menos que los $0.05 que suele costar la generación de imágenes.
P2: ¿Cuál es la calidad del código Matplotlib generado? ¿Requiere muchas modificaciones?
En las 240 pruebas de referencia de ChartMimic realizadas por PaperBanana, el código Python generado fue ejecutable directamente y el resultado visual coincidió con la descripción original. En el uso real, normalmente solo se necesitan pequeños ajustes en la paleta de colores o las fuentes. Recomendamos usar los modelos Claude o Gemini a través de la plataforma APIYI (apiyi.com) para generar código, ya que ambos destacan por su excelente calidad en tareas de programación. La herramienta en línea Image.apiyi.com también permite previsualizar los resultados rápidamente.
P3: ¿Cómo puedo empezar rápidamente a generar código para gráficos científicos con IA?
Te recomendamos este camino rápido:
- Regístrate en APIYI (apiyi.com) para obtener tu API Key y saldo de prueba gratuito.
- Prepara tus datos experimentales (nombres de modelos, valores de métricas, etc.).
- Usa la plantilla de indicación de este artículo, sustituyendo los ejemplos por tus datos reales.
- Llama a la API para generar el código Matplotlib y ejecútalo localmente para ver el resultado.
- Ajusta los parámetros de estilo según los requisitos de la revista y exporta el PDF final.
Resumen
Puntos clave del método de generación de código para gráficos estadísticos de investigación de Nano Banana Pro:
- El código antes que los píxeles: PaperBanana utiliza la generación de código Matplotlib para gráficos estadísticos de investigación en lugar de renderizado de imágenes, eliminando de raíz las alucinaciones numéricas.
- Cobertura total de 7 tipos de gráficos: Gráficos de barras, líneas, dispersión, mapas de calor, radar, circulares y multipanel; cubriendo todas las necesidades de visualización de datos para artículos científicos.
- Editable y reproducible: La salida de código permite modificaciones libres y una reproducción precisa; para las revisiones de los evaluadores, solo necesitas ajustar parámetros en lugar de volver a generar todo.
- 5 técnicas de indicación (prompt): Datos explícitos, restricciones académicas, anotaciones numéricas, ejecutabilidad y separación de parámetros, garantizando que el código generado sea de alta calidad y funcional.
Ante la exigencia de precisión en los gráficos estadísticos de investigación, el enfoque de "el código es el gráfico" es el único camino confiable. Al usar IA para asistir en la generación de código Matplotlib, obtienes la eficiencia de la IA manteniendo la precisión del código: lo mejor de ambos mundos.
Te recomendamos probar la generación de código para gráficos estadísticos asistida por IA a través de APIYI (apiyi.com). La plataforma ofrece cuotas gratuitas y múltiples opciones de modelos. También puedes usar la herramienta en línea Image.apiyi.com para previsualizar los resultados.
📚 Referencias
⚠️ Nota sobre el formato de los enlaces: Todos los enlaces externos usan el formato
Nombre del recurso: domain.com, lo que facilita la copia pero evita el salto por clic para prevenir la pérdida de autoridad SEO.
-
Página de inicio del proyecto PaperBanana: Página oficial de lanzamiento, incluye el artículo y la demo.
- Enlace:
dwzhu-pku.github.io/PaperBanana/ - Descripción: Conoce los principios básicos y los datos de evaluación de la generación de código para gráficos estadísticos de PaperBanana.
- Enlace:
-
Artículo de PaperBanana: Texto completo del pre-print en arXiv.
- Enlace:
arxiv.org/abs/2601.23265 - Descripción: Comprende a fondo la elección técnica entre generación de código vs. generación de imágenes y el benchmark ChartMimic.
- Enlace:
-
Documentación oficial de Matplotlib: Biblioteca de visualización de datos para Python.
- Enlace:
matplotlib.org/stable/ - Descripción: Referencia de la API de Matplotlib para entender y modificar el código de los gráficos generado por IA.
- Enlace:
-
Documentación oficial de Nano Banana Pro: Introducción al modelo de Google DeepMind.
- Enlace:
deepmind.google/models/gemini-image/pro/ - Descripción: Conoce las capacidades de generación de imágenes de Nano Banana Pro en escenarios de diagramas metodológicos.
- Enlace:
-
Herramienta de generación de imágenes en línea de APIYI: Previsualización de gráficos sin código.
- Enlace:
Image.apiyi.com - Descripción: Previsualiza rápidamente el efecto de los gráficos estadísticos de investigación generados por IA.
- Enlace:
Autor: APIYI Team
Intercambio técnico: Te invitamos a compartir tus plantillas de indicaciones para gráficos estadísticos y trucos de Matplotlib en la sección de comentarios. Para más información sobre modelos de IA, visita la comunidad técnica de APIYI en apiyi.com.