En abril de 2026, Claude Opus 4.7 redefinió el estándar de los modelos de programación al alcanzar un 87.6% en SWE-bench Verified. Sin embargo, apenas dos semanas después, xAI lanzó Grok 4.3, un modelo que cuesta solo una décima parte y desafía la idea de que "los modelos de programación deben ser costosos". Este artículo responde a las dos preguntas que más preocupan a los desarrolladores: ¿Puede Grok 4.3 reemplazar a Claude Opus 4.7 en tareas de programación? y Si no es un reemplazo total, ¿qué ventajas competitivas ofrece Grok 4.3?
Valor principal: Al terminar de leer, sabrás exactamente cuándo elegir Grok 4.3, cuándo Claude Opus 4.7, o cómo combinarlos, además de cómo reducir tus costos operativos en más de un 60% mediante el servicio proxy de API de APIYI.

Diferencias clave: Grok 4.3 vs Claude Opus 4.7
Para determinar si es posible un "reemplazo directo", primero alineemos todos los parámetros críticos de ambos modelos en el contexto de la programación.
Resumen de parámetros: Grok 4.3 vs Claude Opus 4.7
| Dimensión de comparación | Grok 4.3 | Claude Opus 4.7 | Ganador |
|---|---|---|---|
| Fecha de lanzamiento | 30-04-2026 | 16-04-2026 | Claude (14 días antes) |
| Precio de entrada | $1.25 / 1M | $5.00 / 1M | Grok 4.3 |
| Precio de salida | $2.50 / 1M | $25.00 / 1M | Grok 4.3 |
| Ventana de contexto | 1M tokens | 1M tokens | Empate |
| Salida máxima | Estándar | 128K tokens | Claude |
| Velocidad de salida | 207 tokens/seg | ~78 tokens/seg | Grok 4.3 |
| Modo de razonamiento | Activado por defecto | xhigh / Adaptativo | Claude (más detallado) |
| SWE-bench Verified | ~73% | 87.6% | Claude (+14.6pt) |
| SWE-bench Pro | No público | 64.3% | Claude |
| CursorBench | No público | 70% | Claude |
| Vending-Bench (agentes) | Top | Medio | Grok 4.3 |
| Descuento Prompt Caching | 75% | 90% | Claude |
| Descuento Batch API | 50% | 50% | Empate |
| Entrada de video | ✅ Nativa | ❌ No compatible | Grok 4.3 |
| Generación de documentos PDF/XLSX/PPTX | ✅ Nativa | ❌ Requiere post-procesamiento | Grok 4.3 |
| Herramientas de servidor | ✅ Web/código integrado | ❌ Requiere configuración propia | Grok 4.3 |
Definición rápida
Resumiendo la tabla anterior: Claude Opus 4.7 sigue siendo el estándar de oro para "tareas de programación que requieren alta precisión", mientras que Grok 4.3 es la mejor opción para escenarios de desarrollo "sensibles al costo, de cadena larga y multimodales". No son modelos sustitutos, sino que representan dos polos distintos: "precisión frente a relación calidad-precio".
🎯 Sugerencia de prueba rápida: Ambos modelos ya están disponibles en APIYI (apiyi.com), con una
base_urlunificada:https://vip.apiyi.com/v1. Los precios de Grok 4.3 son idénticos a los del sitio oficial de xAI ($1.25/$2.50), y Claude Opus 4.7 se ofrece al precio oficial de Anthropic ($5.00/$25.00) sin recargos. Puedes invocarlos directamente mediante el SDK de OpenAI.

Comparativa de precios: Grok 4.3 vs. Claude Opus 4.7
El precio es la dimensión donde hay mayor diferencia. Vamos a analizarlo a tres niveles: precio unitario, costes ocultos de los tokenizadores y cuotas mensuales de proyectos típicos.
Precios estándar: Grok 4.3 vs. Claude Opus 4.7
La siguiente tabla muestra los precios públicos oficiales vigentes en mayo de 2026. Ambos modelos están disponibles en el servicio proxy de API de APIYI, aplicando la facturación según los precios oficiales.
| Concepto de facturación | Grok 4.3 | Claude Opus 4.7 | Múltiplo de precio |
|---|---|---|---|
| Tokens de entrada | $1.25 / 1M | $5.00 / 1M | Claude es 4.0 veces más caro |
| Tokens de salida | $2.50 / 1M | $25.00 / 1M | Claude es 10.0 veces más caro |
| Entrada en caché | $0.31 / 1M | $0.50 / 1M | Claude es 1.6 veces más caro |
| Precio mixto 3:1 | ~$1.56 / 1M | ~$10.00 / 1M | Claude es 6.4 veces más caro |
Costes ocultos del tokenizador en Claude Opus 4.7
Con el lanzamiento de Claude Opus 4.7, se introdujo un nuevo tokenizador. Las pruebas de la industria muestran que una misma entrada de código genera aproximadamente un 35% más de tokens que en la versión Opus 4.6. Esto significa que, aunque el precio oficial por unidad no cambie, la factura real de las solicitudes aumentará.
| Tipo de contenido | Tokens Opus 4.6 | Tokens Opus 4.7 | Cambio en coste real |
|---|---|---|---|
| Código en inglés puro | 100k | 130k+ | +30% |
| Código mixto chino/inglés | 100k | 135k+ | +35% |
| Con muchos emojis / comentarios | 100k | 140k+ | +40% |
Si sumamos este factor a la comparación, el coste real de las tareas de programación en Claude Opus 4.7 comparado con Grok 4.3 sube a 8–10 veces más, en lugar del múltiplo de 6.4 que indica la tabla de precios base.
💡 Consejo de optimización de costes: Recomendamos habilitar el almacenamiento en caché de la indicación (prompt caching) al realizar llamadas largas a Claude Opus 4.7 (ahorra hasta un 90%), es la clave para compensar el aumento de precios del tokenizador. El servicio proxy de APIYI apiyi.com soporta completamente los campos de caché nativos de Anthropic, sin trabajo de integración adicional.
Estimación mensual para proyectos de programación: Grok 4.3 vs. Claude Opus 4.7
A continuación, una estimación mensual para un negocio de "asistente de código para equipos medianos", asumiendo una relación de entrada/salida de 4:1 (los escenarios de programación tienen entradas más largas) y sin considerar descuentos por caché.
| Volumen de negocio | Tokens mensuales | Cuota mensual Grok 4.3 | Cuota mensual Claude Opus 4.7 | Diferencia |
|---|---|---|---|---|
| Desarrollador individual | 50M | ~$70 | ~$700 (aprox. $945 con aumento del 35%) | 13.5 veces |
| Equipo mediano | 1,000M | ~$1,400 | ~$14,000 (real aprox. $19,000) | 13.5 veces |
| Gran empresa | 10,000M | ~$14,000 | ~$140,000 (real aprox. $189,000) | 13.5 veces |
La brecha de precios a escala empresarial se traduce en una diferencia de "millones de dólares anuales", razón por la cual la arquitectura híbrida se ha convertido en la opción principal para la IA de programación en 2026.
🎯 Consejo de presupuesto: Si tu presupuesto mensual de IA para programación es inferior a $1500, te sugerimos priorizar el uso total de Grok 4.3 y cambiar a Claude Opus 4.7 solo en momentos críticos. Esta estrategia tiene un coste de ingeniería cercano a cero en el servicio de APIYI apiyi.com; solo necesitas cambiar el campo model en la capa de aplicación según la etiqueta de la tarea.
Comparativa de capacidad de programación: Grok 4.3 vs. Claude Opus 4.7
Más allá del precio, lo que realmente determina si un modelo puede sustituir a otro es su capacidad de programación. Lo analizamos desde tres perspectivas: benchmarks públicos, escenarios de ingeniería real y tareas de larga cadena.
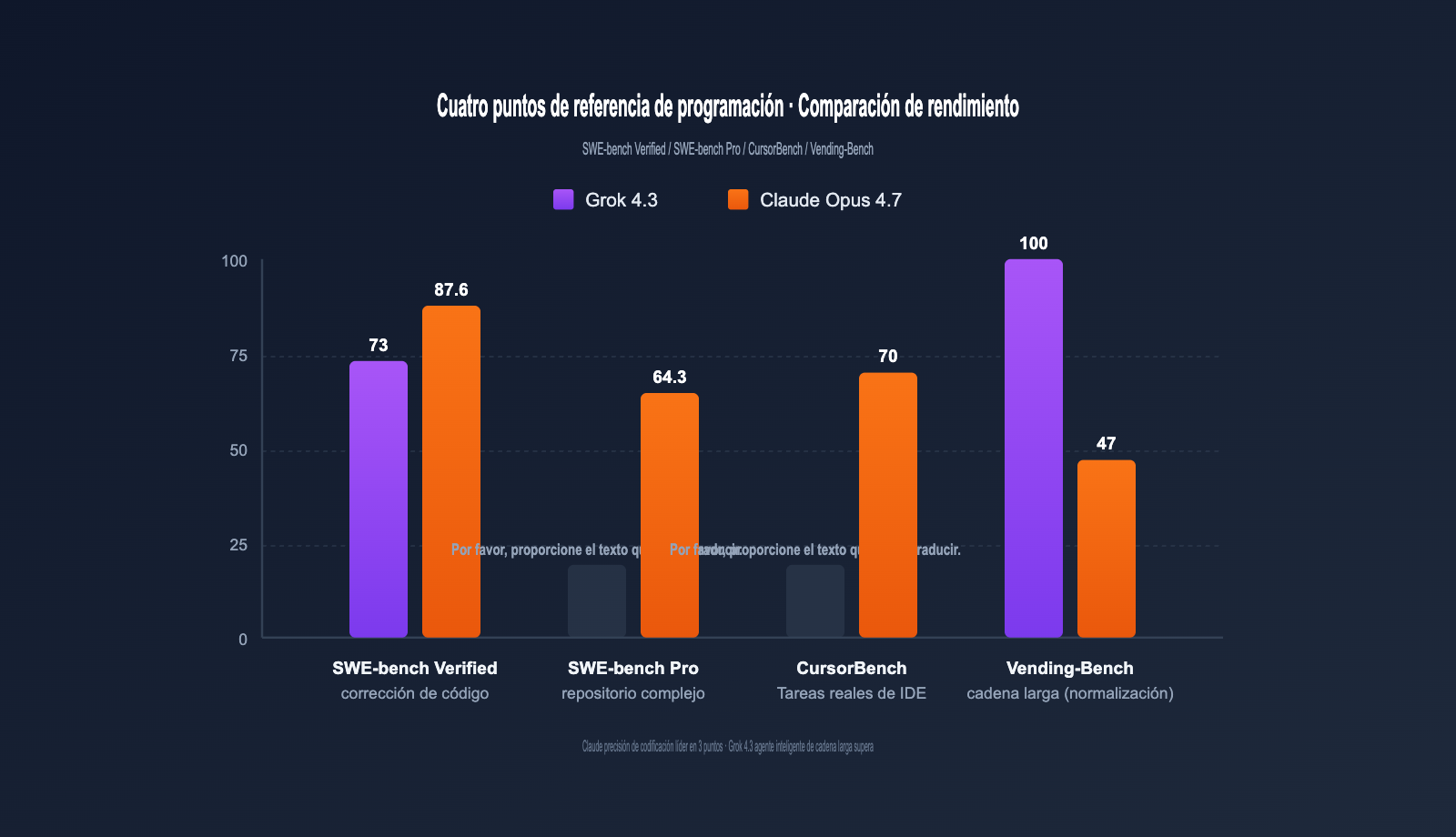
Referencias comparativas de programación
La tabla a continuación resume los datos clave de programación publicados oficialmente por OpenAI, xAI, Anthropic y por terceros (Vellum, Vals.ai, Artificial Analysis).
| Benchmark de programación | Grok 4.3 | Claude Opus 4.7 | Diferencia | Tipo de tarea |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87.6% | Claude +14.6pt | Reparación de código real |
| SWE-bench Pro | No público | 64.3% | Claude lidera | Bugs en repos complejos |
| CursorBench | No público | 70% | Claude lidera | Tareas reales en IDE |
| Aider Polyglot | Medio | Potente | Claude lidera | Migración multilingüe |
| HumanEval+ | Excelente | Excelente | Empate | Generación a nivel función |
| Tareas reales de producción | Bueno | 3x Opus 4.6 | Claude lidera | Reparación de legado |
| Vending-Bench (neto) | Top | 47.1 | Grok 4.3 lidera | Agentes de larga cadena |
| Velocidad de salida (tps) | 207 | ~78 | Grok 4.3 +166% | Respuesta en tiempo real |
En resumen: Claude Opus 4.7 lidera con claridad en tareas de programación sensibles a la precisión; Grok 4.3 supera a Claude en tareas de agentes de larga cadena; y Grok 4.3 es 2.6 veces más rápido en respuesta en tiempo real.
Puntuación de tareas de codificación
Al convertir los benchmarks en una calificación de estrellas basada en tareas de negocio, la distribución de capacidades es más clara.
| Tarea de programación | Grok 4.3 | Claude Opus 4.7 | ¿Se puede sustituir? |
|---|---|---|---|
| Generación de funciones | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sustitución total |
| Generación de unit tests | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sustitución total |
| Comentarios / Documentación | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sustitución total |
| Corrección de bugs simples | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sustitución posible |
| Refactorización de estilo | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sustitución posible |
| Refactorización inter-archivo | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ No recomendado |
| Bugs en repos complejos | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ No recomendado |
| Diseño de sistemas grandes | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude tiene ventaja |
| Código legal / médico | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Imprescindible Claude |
| Agentes de larga cadena | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 supera |
🎯 Regla de sustitución: Para tareas de "nivel de función, tests, comentarios y bugs simples", Grok 4.3 es un sustituto perfecto con 1/10 del coste. Para "refactorización compleja y bugs críticos", se recomienda mantener Claude Opus 4.7. La arquitectura híbrida es la solución óptima.
Pruebas reales en tareas de programación
Para aterrizar la comparativa, probamos 5 tareas comunes usando ambos modelos bajo el mismo base_url en APIYI.
| Tarea realizada | Rendimiento Grok 4.3 | Rendimiento Claude Opus 4.7 | Conclusión |
|---|---|---|---|
| Escribir un componente React | 8s, 1 intento | 18s, 1 intento | ✅ Sustitución (2x más rápido) |
| Corregir NullPointer | 6s, localización correcta | 14s, sol. correcta + 3 opciones | ⚠️ Sustitución parcial |
| Refactorizar 5 archivos (dependencias) | 25s, 2 reintentos | 40s, 1 intento | ❌ Mejor Claude |
| Generar tests Python | 12s, 82% cobertura | 22s, 95% cobertura | ✅ Sustitución (acep.) |
| Agente de 10 pasos | 50s, ejecución completa | 90s, atascado parcialmente | ✅ Grok 4.3 supera |
Razones técnicas del liderazgo de Claude Opus 4.7
Vale la pena entender por qué Claude Opus 4.7 lidera por 14 puntos en SWE-bench; esto ayuda a evaluar dónde su ventaja es "estructural" y dónde es "marginal".
| Dimensión técnica | Inversión Claude Opus 4.7 | Impacto en la codificación |
|---|---|---|
| Modo xhigh reasoning | Más tokens de razonamiento interno | Calidad estable en lógica compleja |
| Thinking adaptativo | Decide cuándo razonar largo o corto | Eficiencia en tareas simples |
| 1M contexto + 128K salida | Antecesor con 200K | Salida de archivos o proyectos enteros |
| Nuevo tokenizador | Segmentación de código fina | Precisión mayor, aunque más tokens |
| Entrenamiento en producción | Resuelve 3x más tareas que 4.6 | Capacidad real superior al benchmark |
Estas inversiones técnicas hacen que la ventaja de Claude Opus 4.7 sea estructural en tareas que requieren razonamiento largo y gran contexto. Sin embargo, en tareas cortas o autocompletado, Grok 4.3 es la ventana perfecta para optimizar costes.
Análisis profundo de las ventajas diferenciales de Grok 4.3
Si solo nos fijamos en SWE-bench, Grok 4.3 parece estar por debajo de Claude Opus 4.7 en casi todo. Sin embargo, en escenarios de desarrollo reales, Grok 4.3 posee varias capacidades que Claude simplemente no tiene, y estas son sus verdaderas ventajas competitivas.
Ventajas de precio y velocidad de Grok 4.3
Primero, es 10 veces más barato. En la mayoría de las tareas de codificación diarias, la diferencia de precisión es del nivel "90% frente a 95%", pero la diferencia de costes es del nivel "$1 frente a $10". Delegar las tareas sencillas de alta frecuencia a Grok 4.3 permite multiplicar por 10 el presupuesto de herramientas de IA de tu equipo.
Segundo, la velocidad de salida es 2,6 veces mayor. La diferencia entre 207 tps y 78 tps supone una mejora cualitativa en escenarios sensibles a la latencia como la "generación de código en streaming", "sugerencias en línea en el IDE" y "programación en pareja en tiempo real". Mientras que los 78 tps de Claude Opus 4.7 "siguen el ritmo del pensamiento humano", los 207 tps de Grok 4.3 ya son "el doble de rápidos que el cerebro humano".
Capacidad de entrada de vídeo de Grok 4.3
Esta es una capacidad que Claude Opus 4.7 no posee en absoluto. Grok 4.3 admite de forma nativa la entrada de vídeo. Escenarios de aplicación típicos:
| Escenario | Uso de Grok 4.3 | Alternativa para Claude Opus 4.7 |
|---|---|---|
| Conversión de grabación de pantalla a código | Enviar el archivo de vídeo directamente | Requiere OCR + múltiples capturas de pantalla |
| Vídeo de reproducción de errores → Solución | Una sola solicitud | Requiere descripción manual fotograma a fotograma |
| Vídeo educativo → Tutorial de código | Extracción y análisis de fotogramas | No es viable |
| Animación de diseño UI → Código frontend | Entrada de vídeo | No es viable |
Si en tu equipo el QA envía vídeos de reproducción de errores, los diseñadores envían animaciones de UI o necesitas realizar ingeniería inversa de código a partir de tutoriales de YouTube, Grok 4.3 es actualmente la única solución viable y rentable.
Capacidad de generación de documentos de Grok 4.3
Grok 4.3 puede generar archivos PDF/XLSX/PPTX directamente en la conversación, lo que en escenarios de codificación significa:
# Grok 4.3 genera documentos PDF de API con una sola llamada
from openai import OpenAI
client = OpenAI(
api_key="Tu clave API de APIYI",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "Genera un documento PDF estilo OpenAPI para esta ruta de FastAPI: ..."
}],
extra_body={"output_format": "pdf"}
)
# La respuesta contiene la URL del archivo descargable
print(response.choices[0].message.attachments[0].url)
Para hacer lo mismo, Claude Opus 4.7 requiere una cadena de tres pasos: Claude → Markdown → Pandoc → PDF. Grok 4.3 lo hace todo en un solo paso.
Ventaja de Grok 4.3 en agentes de cadena larga
Vending-Bench es un benchmark de agentes de cadena larga que simula la "gestión de una máquina expendedora durante 7 días", donde el beneficio neto de Grok 4.3 supera significativamente al de Claude Opus 4.7. Esto significa que en tareas de agentes que "requieren toma de decisiones continua, invocación de herramientas y recordar estados intermedios", Grok 4.3 es, de hecho, más potente.
| Escenario de cadena larga | Ventaja de Grok 4.3 |
|---|---|
| Operaciones automatizadas (autorreparación) | Toma de decisiones estable en cadenas largas, ideal para agentes SRE |
| Pipeline de análisis de datos | Invocación de herramientas en múltiples pasos + agregación de resultados |
| Revisión + fusión automática de PR | Puede completar procesos largos de forma independiente |
| Escaneo de cumplimiento + reparación automática | Procesamiento por lotes en repositorios a gran escala |
Aplicación del modo 16-Agent Heavy de Grok 4.3 en codificación
Grok 4.3 ofrece un sistema de programación paralela de 16 agentes bajo la suscripción SuperGrok Heavy ($300/mes), lo que en escenarios de codificación significa:
| Tarea de codificación | Modo de agente único | Modo 16-Agent Heavy |
|---|---|---|
| Análisis de repositorios grandes | 30 minutos en serie | 3–5 minutos en paralelo |
| Revisión de PR completa | Uno por uno | 16 PRs revisados simultáneamente |
| Generación de pruebas unitarias por lotes | Invocación en serie | Generación paralela de 16 archivos |
| Migración de código multilingüe | Un solo hilo | Paralelismo multimodular |
Aunque el modo 16-Agent está limitado a la suscripción, la interfaz estándar de la API no expone directamente el acceso a 16 agentes. Sin embargo, puedes implementar tu propia orquestación multi-agente en la capa de aplicación usando Grok 4.3, logrando resultados cercanos al Heavy nativo. Combinado con la velocidad de salida de 207 tps de Grok 4.3, la capacidad de procesamiento de Grok 4.3 es, en realidad, superior a la de Claude Opus 4.7 en escenarios de automatización de codificación a gran escala.
Ventaja de las herramientas de servidor de Grok 4.3
Grok 4.3 tiene integradas tres tipos de herramientas del lado del servidor; basta con declarar el campo tools para usarlas, mientras que con Claude Opus 4.7 todo esto debe construirse en la capa de aplicación.
| Herramienta integrada | Precio de Grok 4.3 | Alternativa para Claude Opus 4.7 |
|---|---|---|
| Web Search | $5 / 1k usos | Requiere integrar Tavily / SerpAPI |
| Code Execution (Sandbox) | $5 / 1k usos | Requiere construir un Docker sandbox propio |
| X (Twitter) Search | $5 / 1k usos | Sin alternativa |
Para un agente de codificación que requiere búsqueda en la web + ejecución de código, Grok 4.3 se integra de una sola vez, mientras que Claude Opus 4.7 requiere combinar tres servicios de terceros, lo que aumenta enormemente la complejidad de ingeniería.
💡 Sugerencia sobre herramientas de servidor: Recomendamos elegir Grok 4.3 directamente para agentes de codificación que necesiten búsqueda web, ya que el coste de integración es mínimo. Si el proyecto ya utiliza Claude Opus 4.7 + búsqueda de terceros, puedes mantener a Claude para tareas de alta dificultad y utilizar APIYI (apiyi.com) para integrar simultáneamente Grok 4.3 para las tareas que requieran búsqueda web.
Matriz de decisión: ¿Puede Grok 4.3 sustituir a Claude Opus 4.7?
Resumimos todas las dimensiones anteriores en una matriz de decisión ejecutable.
Decisión según el tipo de tarea
| Tu tarea principal de codificación | Solución recomendada | Motivo |
|---|---|---|
| Autocompletado de código / Sugerencias en línea | Grok 4.3 | 2,6 veces más rápido + 1/10 del precio |
| Generación automática de pruebas unitarias | Grok 4.3 | 80%+ de cobertura es suficiente |
| Comentarios de código / Generación de documentos | Grok 4.3 | Tarea sencilla, calidad equivalente |
| Code Review (nivel PR) | Grok 4.3 | Precio económico, permite revisión total |
| Corrección de errores simples | Grok 4.3 | La diferencia de precisión es mínima |
| Refactorización a gran escala | Claude Opus 4.7 | SWE-bench Pro 64.3% es el techo |
| Corrección de errores críticos | Claude Opus 4.7 | El coste de rehacer supera la diferencia de precio |
| Archivos cruzados / Repositorios grandes | Claude Opus 4.7 | Precisión más estable en contextos largos |
| Código de cumplimiento legal / médico | Claude Opus 4.7 | Altos requisitos de seguridad / cumplimiento |
| Agente de operaciones automatizadas | Grok 4.3 | Supera en Vending-Bench de cadena larga |
| Desarrollo basado en vídeo | Grok 4.3 | Claude no tiene alternativa |
| Búsqueda web + ejecución en sandbox | Grok 4.3 | Herramientas integradas en el servidor |
Decisión según el presupuesto del equipo
| Presupuesto mensual de IA para codificación | Configuración recomendada | Ajuste clave |
|---|---|---|
| < $200 | Grok 4.3 completo | Usar Claude solo para errores críticos |
| $200 – $1500 | 80% Grok 4.3 + 20% Claude | Usar Claude para refactorización entre archivos |
| $1500 – $10k | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | Tres niveles de estratificación |
| > $10k | Enrutamiento automático + Batch + Cache | Arquitectura híbrida obligatoria |
Decisión según la tolerancia a la precisión
| Tolerancia a la precisión de la tarea | Elección recomendada |
|---|---|
| Precisión del 90% aceptable | Grok 4.3 (cobertura del 90% de tareas) |
| Precisión del 95% necesaria | Claude Opus 4.7 + Prompt Caching |
| Precisión del 99% obligatoria | Claude Opus 4.7 + modo xhigh + revisión humana |
🎯 Sugerencia de arquitectura híbrida: En la plataforma APIYI (apiyi.com), Grok 4.3 y Claude Opus 4.7 comparten el mismo
base_urly clave API; la capa de aplicación solo necesita cambiar el campomodelsegún la etiqueta de la tarea o la longitud del token. El coste de ingeniería de esta arquitectura híbrida es casi nulo, mientras que el ahorro presupuestario puede alcanzar entre el 60% y el 80%.
Integración y ejemplos de código para Grok 4.3 y Claude Opus 4.7
Ambos modelos son totalmente compatibles con el SDK de OpenAI a través del servicio proxy de API de APIYI, lo que hace que el costo de migración sea casi nulo.
Invocación unificada para Grok 4.3 y Claude Opus 4.7
# Puedes usar la misma base_url + clave API, solo cambia el campo model
from openai import OpenAI
client = OpenAI(
api_key="Tu clave API de APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Invocar Grok 4.3 (alta relación costo-beneficio)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Genera pruebas unitarias para esta función"}]
)
# Invocar Claude Opus 4.7 (alta precisión)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refactoriza las dependencias circulares de estos 5 archivos"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
Código completo para enrutamiento inteligente en escenarios de programación
Ver el código completo en Python para enrutamiento automático por tipo de tarea
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="Tu clave API de APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Reglas de clasificación de tareas de programación
SIMPLE_KEYWORDS = ["comentario", "comment", "docstring", "renombrar", "formato"]
TEST_KEYWORDS = ["prueba unitaria", "unit test", "casos de prueba", "pytest"]
COMPLEX_KEYWORDS = ["refactor", "refactorizar", "archivos cruzados", "dependencia circular", "migración"]
CRITICAL_KEYWORDS = ["bug crítico", "critical", "corrección producción", "cumplimiento"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""Clasifica la tarea según las palabras clave de la indicación"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""Selecciona el modelo según el tipo de tarea"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""Invocación con enrutamiento inteligente para programación"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # Estimación simplificada
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "Eres un ingeniero full-stack senior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("Añade docstring a esta función add"))
print(smart_code_call("Ayúdame a escribir 5 pruebas unitarias con pytest"))
print(smart_code_call("Refactoriza la dependencia circular de estos tres archivos"))
print(smart_code_call("Bug crítico en producción, arréglalo ya"))
Notas sobre la invocación de Grok 4.3 y Claude Opus 4.7
| Punto a considerar | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| Campo de modelo | grok-4.3 |
claude-opus-4-7 |
| Configuración de razonamiento | Activado por defecto | extra_body={"thinking": {"type": "enabled"}} |
| Caché de indicación | Automático (75% descuento) | Declaración explícita cache_control (90% descuento) |
| API por lotes | 50% descuento | 50% descuento |
| Salida máxima | Estándar | 128K (requiere declaración explícita de max_tokens) |
| Entrada de video | Campo video_url |
❌ No compatible |
| Salida de documento | extra_body={"output_format": ...} |
❌ Requiere post-procesamiento |
| Búsqueda web en servidor | tools=[{"type": "web_search"}] |
❌ Requiere terceros |
| Llamada a funciones | ✅ Completa | ✅ Completa |
🎯 Consejos de integración: Recomendamos solicitar primero una clave de prueba en APIYI (apiyi.com) para verificar el flujo básico. Grok 4.3 y Claude Opus 4.7 comparten la misma clave API; ejecuta 100 muestras de negocio reales en cada uno para realizar pruebas A/B antes de tomar la decisión final.
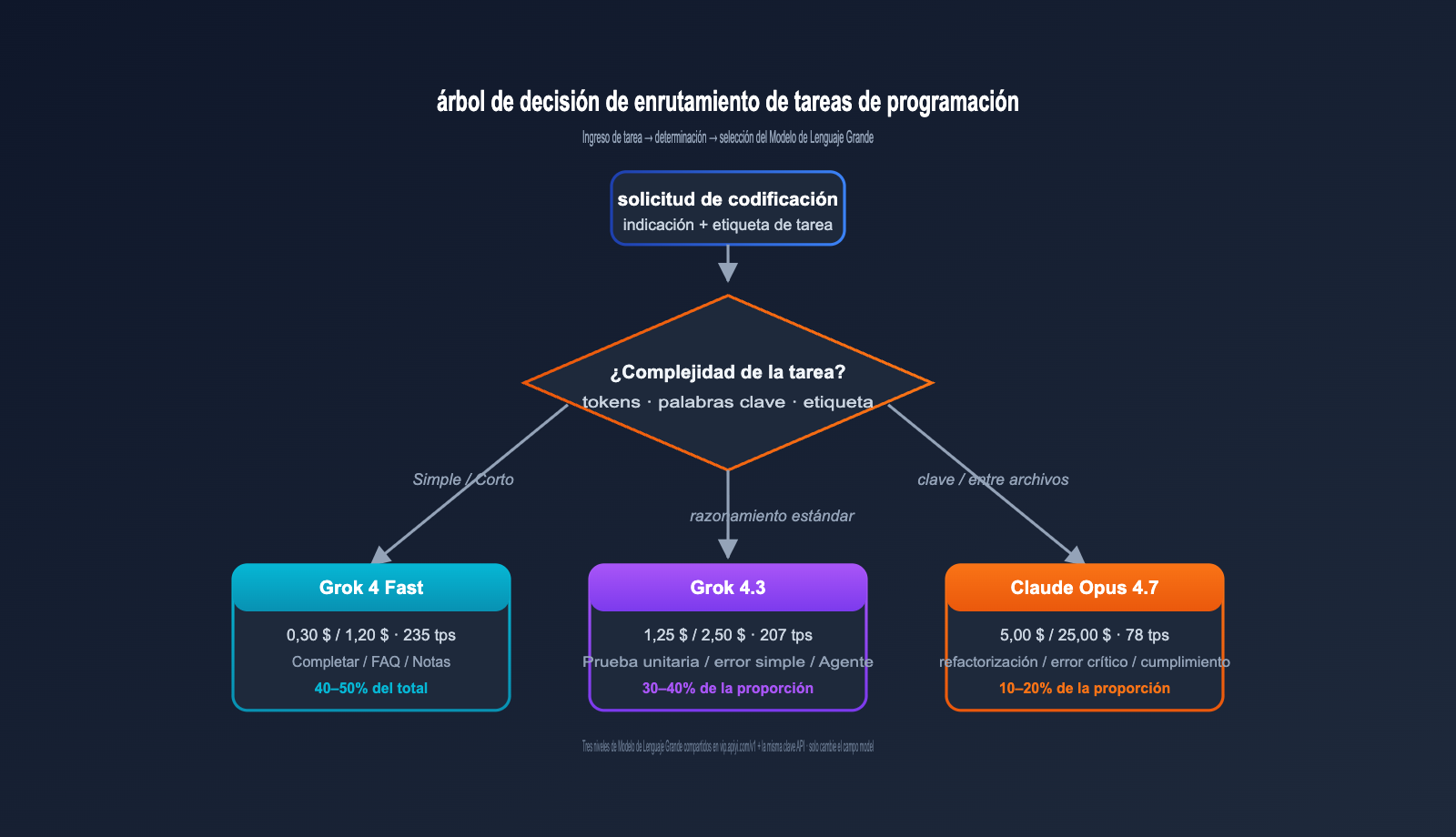
Recomendaciones para escenarios de programación: Grok 4.3 vs. Claude Opus 4.7
6 escenarios para elegir a Grok 4.3 como tu modelo principal
Si tu flujo de trabajo cumple con cualquiera de los siguientes puntos, Grok 4.3 es la mejor opción:
- Escenario 1: Desarrolladores individuales / Proyectos independientes: Con un presupuesto mensual < $300, Grok 4.3 hace que tus tokens rindan 10 veces más.
- Escenario 2: Programación sencilla de alta frecuencia: Autocompletado en el IDE, generación de pruebas unitarias, escritura de comentarios y formato de código.
- Escenario 3: Agentes de cadena larga: Operaciones automatizadas (Ops), agentes de revisión de PR y bots de escaneo de cumplimiento.
- Escenario 4: Desarrollo basado en video: Video de reproducción de errores → solución, animaciones de UI → código frontend.
- Escenario 5: Agente de programación + búsqueda web: Herramientas integradas de
web_searchycode_executionen el servidor. - Escenario 6: Escenarios de chat en tiempo real: Salida de 207 tps, ideal para programación en pareja (Pair Programming) y autocompletado en streaming.
6 escenarios para elegir a Claude Opus 4.7 como tu modelo principal
Si tu negocio requiere lo siguiente, la prima de precisión de Claude Opus 4.7 vale la pena:
- Escenario 1: Refactorización de código a gran escala: 64.3% en SWE-bench Pro, el más alto de la industria.
- Escenario 2: Corrección de errores críticos: Donde un error implica rehacer el trabajo; la precisión es más importante que el costo.
- Escenario 3: Análisis entre archivos / repositorios grandes: Necesidad dual de contexto largo y alta precisión.
- Escenario 4: Código sensible a cumplimiento / seguridad: Escenarios legales, médicos y financieros.
- Escenario 5: Diseño de sistemas complejos: Razonamiento de arquitectura y diseño de API.
- Escenario 6: Flujos de trabajo existentes con Claude Code: Si el equipo ya está familiarizado con la CLI de Claude Code, el costo de migración supera la diferencia de precio.
Proporción recomendada para arquitectura híbrida
Para equipos de desarrollo de tamaño mediano o superior, recomendamos la siguiente distribución:
| Tipo de tarea | Modelo de enrutamiento | Sugerencia de proporción |
|---|---|---|
| Autocompletado simple / FAQ | Grok 4 Fast | 40–50% |
| Programación estándar | Grok 4.3 | 30–40% |
| Refactorización compleja / errores críticos | Claude Opus 4.7 | 10–20% |
| Tareas extremadamente complejas (xhigh) | Claude Opus 4.7 + thinking | < 5% |
Esta estratificación reduce el costo total de IA en programación al 15–25% de lo que costaría usar "solo Claude Opus 4.7", manteniendo la calidad en tareas críticas prácticamente intacta.
Comparativa de costos en un equipo de desarrollo real
La siguiente tabla muestra la comparativa de costos de un equipo mixto de 30 personas (frontend/backend) en mayo de 2026 antes y después de cambiar a una arquitectura híbrida. El escenario de negocio es "Asistente de codificación en IDE + Agente de revisión de PR + Generación de pruebas automatizadas".
| Dimensión | Solo Claude Opus 4.7 | Arquitectura Híbrida (Grok 4.3 + Claude) |
|---|---|---|
| Volumen mensual de llamadas | 1.2B tokens | 1.2B tokens |
| Proporción Claude Opus 4.7 | 100% | 12% |
| Proporción Grok 4.3 | 0% | 70% |
| Proporción Grok 4 Fast | 0% | 18% |
| Factura mensual (incl. 35% aumento tokenizer) | ~$23,000 | ~$3,800 |
| Ahorro de costos | — | 83% |
| Calidad en tareas críticas (tipo SWE-bench Pro) | 100% base | ~99% (sigue usando Claude) |
| Experiencia en tareas simples | Media (78 tps) | Excelente (207 tps) |
| Horas de ingeniería para la migración | — | 16 horas |
La arquitectura híbrida reduce los costos al 17% del original, manteniendo la calidad en tareas críticas casi intacta, mientras que la velocidad de respuesta en tareas simples aumenta 2.6 veces (gracias a Grok 4.3). Es la actualización de arquitectura más valiosa para equipos de desarrollo medianos y grandes en la actualidad.
💡 Consejo de implementación: Recomendamos realizar la clasificación de dificultad de la tarea en el plugin del IDE; el autocompletado simple se dirige automáticamente a Grok 4.3, mientras que las tareas complejas entre archivos van a Claude Opus 4.7. En la plataforma APIYI (apiyi.com), ambos modelos comparten la misma gestión de autenticación y cuotas, manteniendo los costos de ingeniería bajo control.
Preguntas frecuentes sobre Grok 4.3 vs. Claude Opus 4.7
Q1: ¿Puede Grok 4.3 reemplazar realmente a Claude Opus 4.7 en programación?
En parte sí, en parte no. En tareas como "generación a nivel de función, pruebas unitarias, comentarios, corrección de errores simples y agentes de cadena larga", la precisión de Grok 4.3 está a menos de 5 puntos porcentuales de Claude Opus 4.7, pero a 1/10 del precio, por lo que es un reemplazo perfecto. En tareas como "refactorización entre archivos, errores en repositorios complejos, corrección de funciones críticas y código de cumplimiento", el 64.3% de Claude Opus 4.7 en SWE-bench Pro sigue siendo el techo, con una diferencia de más de 14 puntos porcentuales; no recomendamos reemplazarlo ahí. Lo más sensato es una arquitectura híbrida, enrutando automáticamente según el tipo de tarea a través de APIYI (apiyi.com).
Q2: ¿Cuál es la ventaja diferencial de Grok 4.3 en programación?
Seis ventajas clave: (1) 10 veces más barato, multiplicando el presupuesto de equipos pequeños; (2) 2.6 veces más rápido (207 vs 78 tps), mejorando la experiencia de streaming en el IDE; (3) soporte nativo para entrada de video; (4) generación de documentos PDF/XLSX/PPTX en un solo paso; (5) superioridad en agentes de cadena larga (Vending-Bench) frente a Claude; (6) herramientas de servidor integradas (web_search/code_execution), reduciendo el trabajo de ingeniería en un 60%. Si tu proyecto cumple al menos 2 de estos puntos, Grok 4.3 es una opción diferencial que vale la pena considerar.
Q3: ¿El 87.6% de Claude Opus 4.7 en SWE-bench Verified se refleja realmente en mi proyecto?
Parcialmente. SWE-bench Verified mide la "corrección de errores en repositorios de código abierto reales", lo que refleja la ventaja de Claude Opus 4.7 en contexto largo y comprensión de múltiples archivos. Sin embargo, muchas tareas diarias (pruebas, comentarios, autocompletado, documentación) no están cubiertas por SWE-bench; en estas, Grok 4.3 y Claude Opus 4.7 están casi empatados. Nuestra sugerencia: interpreta la diferencia de 87.6% vs 73% como una "diferencia de calidad en tareas complejas", no en todas. Para tareas comunes, Grok 4.3 es suficiente.
Q4: ¿El nuevo tokenizer de Claude Opus 4.7 realmente aumentará la factura un 35%?
Sí, pero hay soluciones. El nuevo tokenizer de Opus 4.7 genera un 30–40% más de tokens en promedio en código mixto (inglés/chino), lo que significa que la misma entrada costará más. Hay tres estrategias: (1) habilitar prompt caching (ahorra hasta un 90%); (2) habilitar Batch API (ahorra otro 50%); (3) enrutar tareas simples a Grok 4.3 para evitar que prompts largos y frecuentes pasen por Claude. Al combinar estas tres, puedes anular el impacto del aumento de precio. Recomendamos configurar caching y Batch en APIYI (apiyi.com) y desviar el tráfico automáticamente a Grok 4.3.
Q5: ¿Cuál usar para tareas de código con contexto largo (> 200k tokens)?
Elige según la precisión. Claude Opus 4.7 sigue liderando en precisión de contexto largo, ideal para "análisis único de repositorios gigantes" o "auditoría de código completo". Grok 4.3 destaca en tareas de resumen de contexto largo a 1/10 del precio de Claude. Si necesitas "encontrar 3 errores específicos en 800k tokens", elige Claude; si es "resumen general de 800k tokens + preguntas clave", Grok 4.3 es suficiente. Si el presupuesto es sensible, prioriza Grok 4.3; si la precisión es crítica, elige Claude.
Q6: ¿Qué modelo es mejor para herramientas de IDE como Cursor / Cline / Continue?
La estrategia híbrida es la mejor. El núcleo de herramientas como Cursor / Continue es el "autocompletado en línea + refactorización simple"; aquí, la ventaja de velocidad (207 tps) y precio de Grok 4.3 mejora significativamente la experiencia. Pero al hacer clic en "Refactorizar entre archivos" o "Corregir error complejo", cambiar automáticamente a Claude Opus 4.7 es la opción más estable. Configurar ambos modelos compartiendo la misma clave API en APIYI (apiyi.com) y dejar que el plugin del IDE enrute según la operación es la solución óptima actual.
Q7: ¿La facturación es igual para ambos modelos en APIYI?
Exactamente igual, ambos se cobran por uso de tokens. Grok 4.3 se transmite 1:1 al precio oficial de xAI ($1.25 / $2.50). Claude Opus 4.7 se transmite al precio oficial de Anthropic ($5.00 / $25.00), con soporte completo para prompt caching (90% de descuento) y Batch API (50% de descuento) de Anthropic en el canal proxy. Ambos modelos comparten la misma clave API y el mismo base_url (https://vip.apiyi.com/v1), y la facturación se descuenta del mismo saldo de cuenta, facilitando la gestión y conciliación.
Q8: Si ya uso Claude Opus 4.7 al 100%, ¿cuánto código debo cambiar para migrar a una arquitectura híbrida?
Muy poco, casi solo a nivel de configuración. Si ya usas el SDK de OpenAI para llamar a Claude Opus 4.7 a través de APIYI (apiyi.com), solo necesitas tres pasos: (1) añadir una función de clasificación de tareas en la capa de aplicación (20 líneas de código); (2) cambiar el campo model entre claude-opus-4-7 y grok-4.3 según el tipo de tarea; (3) desplegar con un despliegue gradual (canary) del 5–10% del tráfico para validar. La migración completa puede hacerse en 1 día, con ahorros de presupuesto de hasta el 60–80%.
Q9: ¿Pueden las herramientas CLI tipo Claude Code usar Grok 4.3?
No directamente, pero hay alternativas equivalentes. Claude Code es la CLI oficial de Anthropic y actualmente solo admite la familia de modelos Claude. Si buscas una experiencia CLI similar pero con Grok 4.3, puedes elegir: (1) Aider (CLI de código abierto, compatible con API de OpenAI, se conecta directamente a Grok 4.3 + APIYI); (2) Continue.dev (plugin de IDE, admite cualquier modelo compatible con OpenAI); (3) CLI propia que llame a través del SDK de OpenAI. La comunidad ya cuenta con múltiples herramientas CLI de código abierto optimizadas para Grok 4.3 en mayo de 2026, capaces de reemplazar totalmente las capacidades principales de Claude Code.
Q10: ¿Quién es más estable en codificación de agentes (Agentic Coding)?
Depende del escenario. Los datos publicados por Anthropic muestran que Claude Opus 4.7 tiene una ventaja clara en "agentes de codificación precisos de cadena corta" (tipo SWE-bench) con 74.9 vs 47.1 de Grok 4.20. Sin embargo, en "agentes de cadena larga" (tipo Vending-Bench, que requieren decisiones continuas durante 7 días), Grok 4.3 supera a Claude Opus 4.7 por 1.5 a 2 veces. Recomendamos: usar Claude Opus 4.7 para agentes de cadena corta y Grok 4.3 para agentes de decisión autónoma de cadena larga, integrando ambos mediante APIYI (apiyi.com) y enrutando automáticamente según la duración de la tarea.
Q11: ¿Cómo pueden los usuarios de Cursor añadir Grok 4.3 a su flujo de trabajo?
Cursor admite endpoints personalizados compatibles con OpenAI; el proceso tiene tres pasos: (1) ir a la configuración de Cursor → Models → Custom API Endpoint; (2) en base_url poner https://vip.apiyi.com/v1 y en API Key poner la clave de APIYI; (3) en Model name poner grok-4.3. Una vez configurado, puedes cambiar entre Grok 4.3 y Claude Opus 4.7 en cualquier momento desde el cuadro de chat. Esta configuración permite a los usuarios de Cursor disfrutar de la experiencia del producto mientras utilizan la alta relación costo-beneficio de Grok 4.3 para tareas diarias de programación.
Resumen: ¿Puede Grok 4.3 sustituir a Claude Opus 4.7?
Volviendo a la pregunta central de esta comparativa: ¿Puede Grok 4.3 sustituir a Claude Opus 4.7 en tareas de programación?
La respuesta directa es: Puede sustituir el 60–70% de las tareas de programación diarias; para el 30–40% restante de tareas complejas, recomendamos mantener Claude Opus 4.7.
En detalle: para tareas como la generación a nivel de función, pruebas unitarias, comentarios, corrección de errores simples y agentes de cadena larga, la brecha de precisión de Grok 4.3 es inferior al 5%, pero con un precio de solo 1/10, por lo que es un sustituto perfecto. Sin embargo, en tareas como la refactorización entre archivos, errores en repositorios complejos y código de cumplimiento crítico, Claude Opus 4.7, con su 64.3% en SWE-bench Pro, sigue siendo el estándar de la industria con una ventaja de más de 14 puntos porcentuales; en estos casos, no recomendamos el cambio.
Más importante aún, Grok 4.3 no es solo una "versión barata de Claude Opus 4.7"; cuenta con seis ventajas diferenciales que Claude no posee: precio 1/10, velocidad 2.6 veces mayor, entrada de video, generación de documentos, superioridad en agentes de cadena larga y herramientas integradas en el servidor. Estas capacidades hacen que, en escenarios como el desarrollo basado en video, agentes de operaciones automatizadas y agentes de codificación con búsqueda en la web, Grok 4.3 sea, más que un "sustituto imperfecto de Claude Opus 4.7", el mejor punto de partida para productos de nueva generación.
Para los desarrolladores, la ruta de menor fricción para implementar esta arquitectura híbrida de "Grok 4.3 como base + Claude Opus 4.7 para rutas críticas" es el servicio proxy de API de APIYI (apiyi.com). Ambos modelos comparten el mismo base_url y clave API, por lo que en la capa de aplicación solo necesitas cambiar el campo model para alternar entre ellos. El precio de Grok 4.3 se transmite 1:1 respecto al sitio oficial de xAI, y el de Claude Opus 4.7 igual respecto a Anthropic, sin recargos. Si a esto le sumamos el prompt caching nativo de Anthropic (ahorro del 90%) y la API Batch (ahorro adicional del 50%), el costo total de tu IA de programación puede reducirse al 15–25% de lo que costaría usar "solo Claude Opus 4.7", manteniendo la calidad en las tareas críticas.
Finalmente, un consejo de ejecución para las próximas 24 horas: solicita hoy mismo tu clave en APIYI, ejecuta 100 tareas de programación reales en ambos modelos y utiliza los datos reales para decidir tu proporción de uso. Los puntos de referencia son solo una guía; la tasa de éxito en tu propio negocio es la base definitiva para tu decisión.
Referencias
-
Anuncio oficial de Anthropic: Detalles del lanzamiento de Claude Opus 4.7
- Enlace:
anthropic.com/claude/opus - Descripción: Incluye precios, benchmarks y explicación de los campos de la API.
- Enlace:
-
Documentación de la API de Anthropic: Especificaciones completas de Claude Opus 4.7
- Enlace:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Descripción: Ventana de contexto, límites de salida y cambios en el tokenizador.
- Enlace:
-
Documentación de modelos de xAI: Especificaciones completas de la API de Grok 4.3
- Enlace:
docs.x.ai/developers/models - Descripción: Capacidades exclusivas como entrada de video, generación de documentos y herramientas de servidor.
- Enlace:
-
Informe de referencia de Vellum: Evaluación detallada de Claude Opus 4.7
- Enlace:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Descripción: Datos de SWE-bench Verified / Pro / CursorBench.
- Enlace:
-
Clasificación de IA de Artificial Analysis: Comparativa integral de rendimiento y precio entre modelos
- Enlace:
artificialanalysis.ai/models/claude-opus-4-7 - Descripción: Evaluación integral de índice de inteligencia, velocidad y precio.
- Enlace:
-
Comparativa de modelos de DocsBot: Comparación detallada entre Grok 4.3 y Claude Opus 4.7
- Enlace:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - Descripción: Comparación de precios, rendimiento y características.
- Enlace:
-
Documentación de integración de APIYI: Tutorial completo para integrar ambos modelos mediante el servicio proxy
- Enlace:
help.apiyi.com - Descripción: Incluye campos de modelo, ejemplos de SDK y consulta de facturación.
- Enlace:
Autor: Equipo de APIYI — Especialistas en servicios proxy de API para Modelos de Lenguaje Grande, ayudando a los desarrolladores a invocar modelos líderes como Grok 4.3, Claude Opus 4.7 y GPT-5.5 con un solo clic. Visita APIYI en apiyi.com para obtener saldo de prueba gratuito.