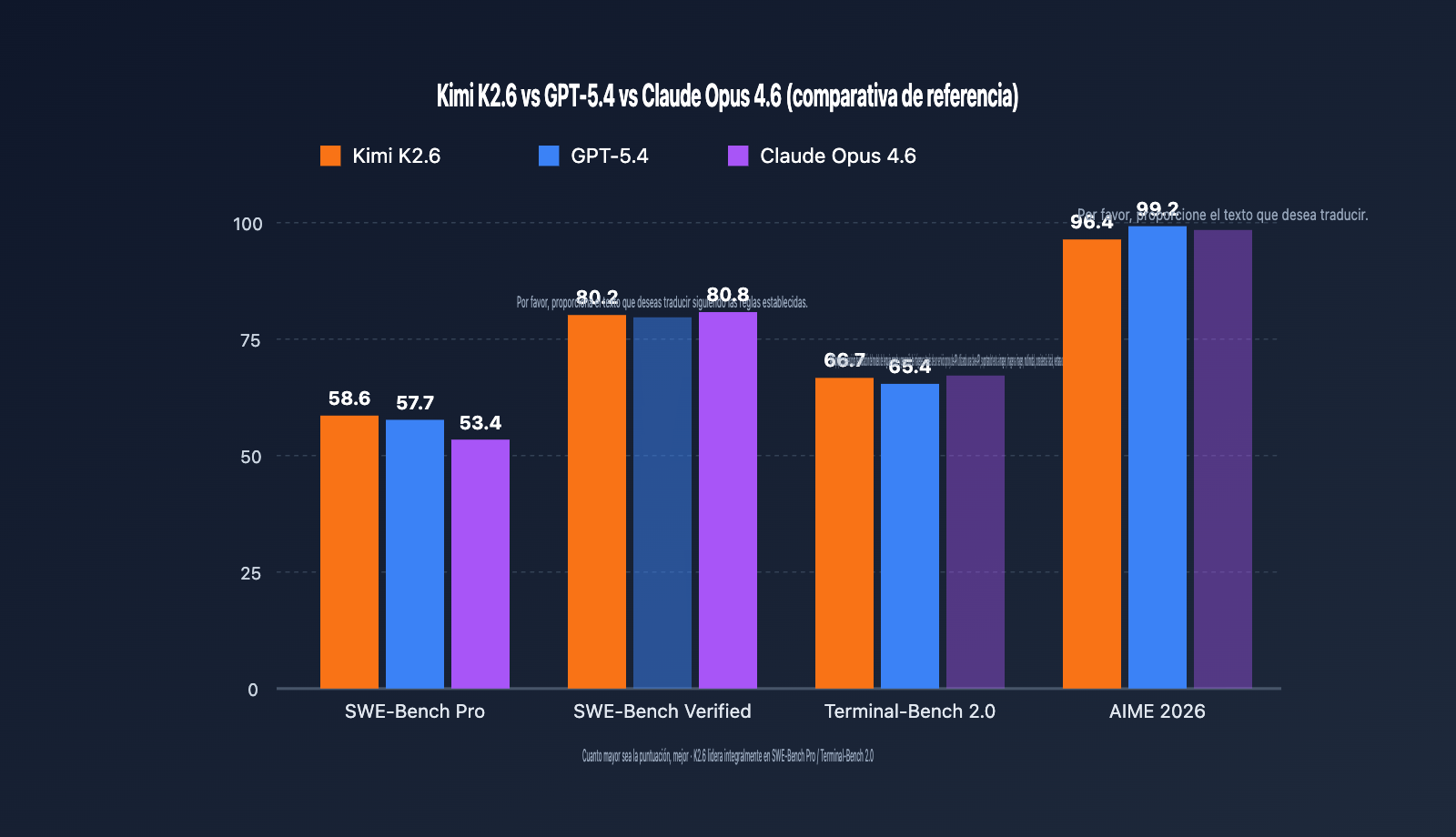
El 2026 marca un punto de inflexión para los Modelos de Lenguaje Grande de código abierto desarrollados en China. Moonshot AI ha lanzado oficialmente su modelo insignia, Kimi K2.6, el cual ha superado a GPT-5.4 (57.7) y Claude Opus 4.6 (53.4) en el benchmark SWE-Bench Pro con una puntuación de 58.6 puntos, consolidándose como el modelo invocable con la mayor tasa de resolución real de problemas de GitHub.
Este artículo detalla el proceso de integración de la API de Kimi K2.6, analizando su arquitectura MoE de 1T, su ventana de contexto de 256K, su capacidad de invocación de herramientas (Function Call) y el relleno de prefijos. Además, a través de ejemplos de código, te ayudaremos a completar la integración en 5 minutos. En cuanto a costes, APIYI (apiyi.com) ofrece acceso a través del canal de Huawei Cloud con una tarifa de $0.60 por cada 1M de tokens de entrada y $2.40 por cada 1M de salida, aproximadamente un 40% más barato que el precio oficial de ¥6.5 / ¥27.
Valor clave: Al terminar de leer, dominarás el método de invocación de la API de Kimi K2.6, la orquestación de herramientas, trucos de optimización de caché de prefijos y sabrás cuándo elegir K2.6 como la opción con mejor relación coste-beneficio.

Puntos clave de la API de Kimi K2.6
Kimi K2.6 es el modelo insignia de código abierto de nueva generación lanzado por Moonshot AI en abril de 2026. Mantiene la arquitectura MoE de la serie Kimi K2 y presenta mejoras significativas en codificación, ventana de contexto larga e invocación de herramientas. La siguiente tabla resume las especificaciones principales:
| Punto clave | Especificaciones detalladas | Valor real |
|---|---|---|
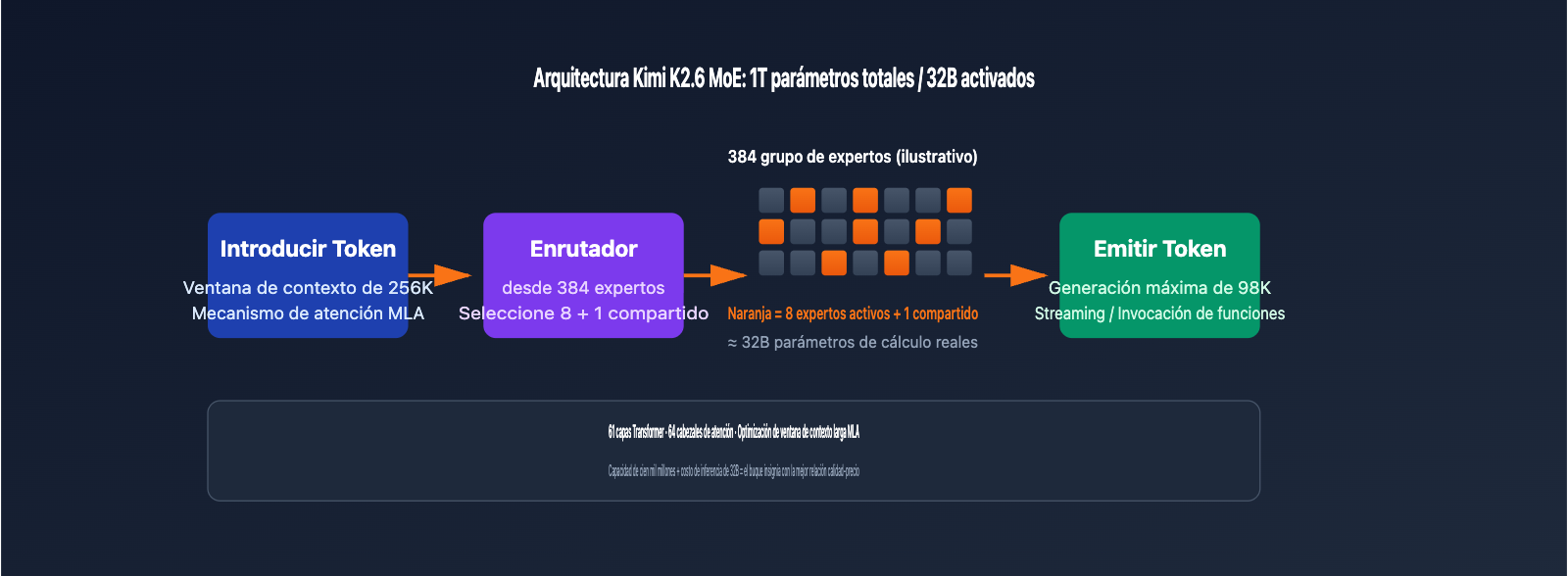
| Arquitectura MoE | 1T parámetros totales / 32B activados / 384 expertos (8 seleccionados + 1 compartido) | Capacidad de nivel de cientos de miles de millones, con costes de inferencia comparables a modelos de 32B |
| Ventana de contexto | 256K tokens (precisamente 262,144) | Procesa repositorios de código extensos o documentos legales de una sola vez |
| Generación máxima | Hasta 98,304 tokens en una sola salida | Ideal para escenarios de refactorización de código largo y generación de documentos |
| Capacidad multimodal | Codificador visual MoonViT de 400M integrado | Soporte nativo para entradas de imagen y vídeo |
| Orquestación de agentes | Agent Swarm admite 300 sub-agentes / 4,000 pasos de coordinación | Capaz de manejar flujos de desarrollo complejos y de varios pasos |
| Licencia de código abierto | Licencia MIT modificada | Apta para uso comercial sin restricciones significativas |
Análisis detallado de las capacidades de la API de Kimi K2.6
Comparado con la generación anterior, K2.5, el K2.6 ofrece mejoras disruptivas en tres dimensiones: primero, supera los 58.6 puntos en SWE-Bench Pro, superando por primera vez a GPT-5.4 y Claude Opus 4.6 en tareas de resolución de problemas en repositorios de código abierto; segundo, el número de sub-agentes de Agent Swarm aumentó de 100 a 300, y los pasos de coordinación subieron de 1500 a 4000, permitiendo tareas de desarrollo más extensas; tercero, la ventana de contexto de 256K está abierta en toda la serie, y gracias a la Atención Latente de Múltiples Cabezales (MLA), se han reducido significativamente los costes de memoria y latencia en inferencias de contexto largo.
🎯 Consejo técnico: Para el desarrollo real, recomendamos llamar directamente a Kimi K2.6 a través de la plataforma APIYI (apiyi.com). Esta plataforma accede al modelo oficial a través del canal de Huawei Cloud, es totalmente compatible con el SDK de OpenAI y permite cambiar de modelo sin modificar el código existente.
Explicación detallada de la arquitectura técnica de la API Kimi K2.6
Comprender la arquitectura subyacente de Kimi K2.6 te ayudará a elegir la opción más adecuada según tus casos de uso de negocio. Su diseño equilibra una "capacidad de parámetros a escala de billones" con un "costo de inferencia de decenas de miles de millones".
Mecanismo de activación dispersa MoE
Kimi K2.6 utiliza una arquitectura de Mezcla de Expertos (MoE) con 1 billón de parámetros, distribuida en 384 redes expertas. Durante la inferencia de cada token, solo se activan 8 de ellas (más 1 experto compartido), lo que significa que 32B de parámetros participan en el cálculo. Este diseño permite que el modelo posea la amplitud de conocimientos de un modelo de cientos de miles de millones de parámetros, manteniendo la velocidad de inferencia de uno de 32B, convirtiéndolo en uno de los modelos insignia con mejor relación costo-eficiencia para la invocación del modelo.
Optimización de la ventana de contexto larga
| Componente técnico | Función | Configuración K2.6 |
|---|---|---|
| Multi-head Latent Attention (MLA) | Reduce el volumen de la caché KV en inferencias largas | 64 cabezales de atención |
| Capas de red | Determina la profundidad de inferencia del modelo | 61 capas Transformer |
| Ventana de contexto | Máximo de tokens por entrada | 262,144 tokens (256K) |
| Codificación posicional | Técnica clave para secuencias extralargas | Entrenamiento especializado en contexto largo |
| Caché de prefijo | Reduce costos al reutilizar el prompt | Reduce el costo de entrada aprox. un 75% tras el acierto |
💡 Perspectiva de arquitectura: En escenarios de diálogo multironda o con system prompt fijo, el uso de la caché de prefijo puede reducir significativamente los costos de entrada. Recomendamos mantener el system prompt estable en entornos de producción para maximizar la tasa de aciertos en caché.
Comparativa de rendimiento de la API Kimi K2.6
Las pruebas de referencia son la base más intuitiva para decidir si un modelo vale la pena. A continuación, comparamos el rendimiento de Kimi K2.6, GPT-5.4 y Claude Opus 4.6 en cinco puntos de referencia autorizados.
Capacidad de codificación e ingeniería de software
| Prueba de referencia | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | Modelo superior |
|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (con herramientas) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
Interpretación clave:
- SWE-Bench Pro mide la capacidad de resolución integral de problemas reales en GitHub. K2.6 obtuvo 58.6 puntos, permitiendo por primera vez que un modelo de código abierto supere a los modelos insignia de código cerrado en este benchmark, lo que significa que K2.6 debe ser la primera opción para mantenimiento de código y corrección de bugs.
- SWE-Bench Verified es una versión simplificada donde Claude Opus 4.6 gana por poco (80.8 vs 80.2); la brecha es pequeña, pero indica que Claude aún tiene ventaja en tareas de código estandarizadas.
- Terminal-Bench 2.0 evalúa la capacidad de orquestación de comandos de terminal, donde K2.6 lidera con 66.7 puntos, siendo ideal para DevOps y tareas de automatización operativa.
- AIME / HMMT y otros razonamientos puramente matemáticos siguen siendo el fuerte de GPT-5.4, por lo que para escenarios matemáticos complejos, sugerimos mantener a GPT-5.4.
🎯 Recomendación de escenarios: Sugerimos realizar pruebas A/B entre modelos para diferentes tareas: K2.6 para mantenimiento de código, GPT-5.4 para razonamiento matemático y mantener a Claude como opción para escritura creativa de formato largo.
Primeros pasos rápidos con la API de Kimi K2.6
A continuación, veremos un código completo que demuestra cómo invocar a Kimi K2.6. La API de la serie Kimi es totalmente compatible con el protocolo del SDK de OpenAI, por lo que si ya tienes código que utiliza OpenAI, solo necesitas reemplazar base_url y model.
Ejemplo minimalista (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Eres un ingeniero Python senior."},
{"role": "user", "content": "Usa asyncio para implementar un pool de peticiones concurrentes, limitando la concurrencia máxima a 10."}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
Ver ejemplo completo de invocación asíncrona con streaming (incluye manejo de errores)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""Invoca Kimi K2.6 en modo streaming y muestra los tokens en tiempo real"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[Límite de tasa alcanzado, se sugiere configurar reintentos o actualizar el plan]")
raise
except APIError as e:
print(f"\n[Error de API: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="Explica cómo la arquitectura MoE reduce los costos de inferencia",
system="Eres un experto en arquitectura de IA, responde de forma concisa y profesional"
)
print(f"\n\n[Número total de tokens: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 Inicio rápido: Después de obtener tu clave API desde la plataforma APIYI (apiyi.com), simplemente configura
base_urlcomohttps://api.apiyi.com/v1. Todos los SDK del ecosistema de OpenAI (Python/Node.js/Go) funcionarán directamente; la integración se completa en 5 minutos.
Invocación con Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "Escribe una función debounce en TypeScript con soporte para genéricos" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
Invocación directa con cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Hola, Kimi K2.6"}
],
"max_tokens": 1024
}'
Práctica de llamadas a funciones (Function Call)
La capacidad de Function Call (llamadas a herramientas) de K2.6 es una mejora significativa respecto a la serie K2, con un rendimiento excelente en el Berkeley Function-Calling Leaderboard. A continuación, presentamos un ejemplo completo de "consulta del clima" para mostrar el flujo de orquestación de herramientas.
Definición e invocación de herramientas
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Consulta el clima en tiempo real de una ciudad específica",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nombre de la ciudad"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""Interfaz simulada de consulta de clima"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "soleado"}
messages = [{"role": "user", "content": "Ayúdame a consultar el clima en Pekín y Shanghái"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
Completado de prefijo (Modo Parcial)
K2.6 admite el "completado de prefijo" al estilo OpenAI, lo que significa que puedes pre-rellenar el inicio de un mensaje del asistente para que el modelo continúe generando a partir de ese punto. Es útil para forzar salidas JSON o restricciones de formato específicas:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Devuelve los datos del PIB de Pekín (2023) en formato JSON"},
{"role": "assistant", "content": '{"city": "Pekín", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 Optimización de costos: Para escenarios con una indicación de sistema larga (como RAG o Agentes), una vez que el prefijo se encuentra en caché, el costo de entrada se reduce en un 25%, lo que es ideal para diálogos de múltiples turnos y flujos de trabajo con plantillas fijas. Se recomienda habilitar el monitoreo de caché a nivel de cuenta en la plataforma apiyi.com para observar la tasa de aciertos en tiempo real.
Capacidades avanzadas de la API de Kimi K2.6
Además de Function Call, K2.6 ofrece tres capacidades avanzadas: orquestación de múltiples agentes (Agent Swarm), ventana de contexto larga de 256K y capacidades multimodales nativas, que conforman su competitividad central en escenarios de codificación, automatización de I+D y análisis de documentos.
Orquestación de múltiples agentes con Agent Swarm
Una de las capacidades más distintivas de K2.6 es Agent Swarm, que permite programar hasta 300 subagentes paralelos en una sola tarea, ejecutando 4,000 pasos de coordinación. Esta característica hace que K2.6 destaque en escenarios como la refactorización de grandes bases de código, análisis cruzado de múltiples documentos y flujos complejos de I+D.
Modos de programación de subagentes
Agent Swarm de K2.6 admite tres modos de orquestación típicos:
| Modo de orquestación | Escenarios aplicables | Número de subagentes | Pasos de coordinación |
|---|---|---|---|
| Paralelo simple | Resumen masivo de documentos, revisión de código | 10-50 | < 200 |
| Programación por niveles | Refactorización de código multimodular | 50-150 | 500-1500 |
| Colaboración profunda | Flujos de trabajo entre repositorios | 150-300 | 1500-4000 |
Ejemplo de programación simple de agentes
A continuación se muestra cómo coordinar 5 subagentes paralelos para completar una tarea de revisión de código:
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""Subagente de revisión para un solo módulo"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Eres un experto en revisión de código, enfocado en seguridad y rendimiento."},
{"role": "user", "content": f"Revisar el módulo {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""Programación paralela de múltiples subagentes"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# Flujo principal: coordinar 5 subagentes para revisar 5 módulos
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Mejores prácticas para Agent Swarm
- Control de granularidad: Cada subagente debe manejar entre 5K y 20K tokens; un exceso aumentará innecesariamente los costos de coordinación.
- Aislamiento de errores: Implementa
try/exceptindividual para cada subagente y evita fallos en cascada. - Agregación de resultados: Designa un "agente principal" para recopilar resultados y realizar validación cruzada.
- Gestión de tiempos de espera: Establece un tiempo de espera de 60-120 segundos para subagentes individuales y 10-30 minutos para el agente principal.
- Control de tasa: Usa semáforos para limitar la concurrencia máxima y evitar disparar el límite de tasa de la API.
Uso de contexto largo (256K)
La ventana de contexto de 256K (262,144 tokens) es un punto de venta clave de K2.6. Esto equivale a unos 400,000-500,000 caracteres en chino, lo que permite albergar grandes repositorios de código o libros técnicos completos.
Uso típico de contexto largo
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""Carga todos los archivos con la extensión especificada en el repositorio"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
print(f"Estimación de tokens del repositorio: {len(repo_text) // 2}") # En chino, 1 token ≈ 2 caracteres
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Eres un arquitecto senior experto en el análisis de grandes bases de código."},
{"role": "user", "content": f"Analiza la arquitectura del siguiente proyecto y proporciona sugerencias de refactorización:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
Equilibrio entre costo y rendimiento en contexto largo
| Escala de entrada | Costo estimado/uso | Latencia (primer token) | Escenarios aplicables |
|---|---|---|---|
| 8K | $0.005 | 1-2 segundos | Análisis de un solo archivo |
| 32K | $0.019 | 3-5 segundos | Revisión a nivel de módulo |
| 100K | $0.06 | 8-15 segundos | Análisis de repositorios medianos |
| 200K | $0.12 | 18-30 segundos | Repositorios grandes / libros completos |
| 256K (capacidad plena) | $0.154 | 25-40 segundos | Documentos extremadamente largos |
🎯 Consejos de optimización: En escenarios de contexto largo, se recomienda dividir la indicación de sistema en dos partes: "Instrucciones fijas + Documento dinámico". Una vez que la parte fija sea alcanzada por la caché de prefijo, las llamadas posteriores solo cobrarán por la parte que cambia, lo que permite reducir los costos totales de 100 llamadas en un 40%-60% en escenarios RAG.
Invocación visual multimodal
K2.6 cuenta con un codificador visual MoonViT incorporado de 400 millones de parámetros, compatible nativamente con entradas de imagen y video. La interfaz multimodal es compatible con el protocolo de OpenAI:
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Analiza este diagrama de arquitectura e identifica posibles puntos únicos de fallo"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
Escenarios de uso multimodal:
- Análisis y sugerencias de modificación en diagramas de arquitectura/flujo.
- Revisión de diseños UI y generación de código.
- Comprensión de capturas de pantalla de documentación técnica.
- Extracción de contenido de tablas de datos y gráficos.
- Inspección visual de calidad industrial.
Migración a la API de Kimi K2.6 y optimización de rendimiento
Si tu proyecto utiliza actualmente OpenAI, K2.5 u otros modelos, migrar a K2.6 suele requerir solo de 3 a 5 líneas de código. Además, una estrategia adecuada de concurrencia y caché puede potenciar aún más las ventajas de costo de K2.6.
Migración desde la serie GPT de OpenAI
# Código original (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# Migración a K2.6 (solo cambia base_url y model)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
Migración desde Kimi K2 / K2.5
Aunque los IDs de los modelos de la serie K2 son diferentes, el protocolo de la API es totalmente compatible:
| ID de modelo antiguo | ID de modelo nuevo | Fecha de retiro prevista |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
25-05-2026 |
kimi-k2.5 |
kimi-k2.6 |
Soporte continuo, pero se recomienda actualizar |
moonshot-v1-128k |
kimi-k2.6 |
Durante 2026 |
Verificación de compatibilidad antes de la migración
Antes de migrar, te recomendamos revisar los siguientes puntos:
- Límite de max_tokens: K2.6 puede generar hasta 98K tokens en una sola respuesta. Si tu código tiene un límite fijo de 8K, puedes ampliarlo.
- Rango de temperature: Para K2.6 se recomienda un valor entre 0.1 y 0.7; un valor demasiado alto podría afectar la calidad del código.
- stop sequences: K2.6 admite secuencias de parada personalizadas, igual que OpenAI.
- Comportamiento de tool_choice: El modo
autode K2.6 tiende a invocar herramientas con mayor frecuencia; si necesitas un comportamiento más conservador, cámbialo anoneo especifícalo explícitamente. - Protocolo de streaming: El formato SSE es idéntico, por lo que no es necesario modificar el código del frontend.
Mejores prácticas de optimización de rendimiento
Optimización de la velocidad de invocación
| Elemento de optimización | Método de implementación | Mejora esperada |
|---|---|---|
| Solicitudes concurrentes | Usar AsyncOpenAI + asyncio.gather | Rendimiento 3-10x |
| Salida en streaming | Habilitar stream=True | Reducción del 70% en latencia inicial |
| Caché de prefijo | Fijar el system prompt | Reducción del 75% en costos de entrada |
| max_tokens adecuado | Establecer límite según la tarea | Reducción del 30% en latencia |
| Control de temperatura | temp=0.2 para tareas de código | Salida más estable |
Recomendaciones para el manejo de errores
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"Límite de tasa alcanzado, reintentando en {wait}s")
time.sleep(wait)
except APITimeoutError:
print(f"Tiempo de espera agotado, reintento {attempt+1}")
except APIError as e:
print(f"Error de API: {e}")
if attempt == max_retries - 1:
raise
raise Exception("Se alcanzó el número máximo de reintentos")
Ventajas de precio y selección de escenarios para la API de Kimi K2.6
El precio es un factor que no se puede ignorar al elegir un modelo. La siguiente tabla compara los precios de lista de Kimi K2.6 en diferentes canales (unidad: por cada 1M de tokens):
| Canal de invocación | Precio de entrada | Precio de salida | Notas |
|---|---|---|---|
| Plataforma oficial Kimi | ¥6.5 (~$0.95) | ¥27 (~$4.00) | Facturación oficial nacional |
| APIYI (Proxy oficial Huawei Cloud) | $0.60 | $2.40 | Aprox. 60% del precio oficial |
| OpenRouter (Parasail) | $0.60 | $2.40+ | Canal no oficial |
| GPT-5.4 (Referencia) | $2.50 | $15.00 | 4-6 veces más caro que K2.6 |
| Claude Opus 4.6 (Referencia) | $15.00 | $75.00 | Más de 25 veces más caro que K2.6 |
Estimación de costos reales
Tomando como ejemplo un asistente de código cotidiano (asumiendo por sesión: 5K tokens de entrada / 2K tokens de salida), con 100,000 invocaciones al mes:
| Modelo | Costo mensual entrada | Costo mensual salida | Costo total mensual |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1,250 | $3,000 | $4,250 |
| Claude Opus 4.6 | $7,500 | $15,000 | $22,500 |
Conclusión: En escenarios de alta frecuencia como codificación, agentes y contextos largos, el rendimiento de K2.6 está al nivel de GPT-5.4/Claude Opus 4.6, pero con un costo de solo 1/5 a 1/30 parte. Es especialmente amigable para equipos pequeños y desarrolladores individuales con presupuestos ajustados.
🎯 Recomendación de selección: La elección del modelo depende principalmente de su caso de uso específico y de los requisitos de calidad. Recomendamos realizar pruebas reales a través de la plataforma APIYI apiyi.com para tomar la decisión que mejor se adapte a sus necesidades. Esta plataforma admite la invocación mediante una interfaz unificada para diversos modelos principales como Kimi K2.6, GPT-5.4 y Claude Opus 4.6, facilitando comparaciones y cambios rápidos.
Recomendaciones de escenarios de aplicación
La adaptabilidad de K2.6 varía según el escenario de negocio. La siguiente tabla ofrece recomendaciones claras:
| Escenario de aplicación | Nivel de recomendación | Razón |
|---|---|---|
| Mantenimiento y refactorización de código | ⭐⭐⭐⭐⭐ | Primero en SWE-Bench Pro, 256K permite cargar repositorios grandes |
| Orquestación de Agentes | ⭐⭐⭐⭐⭐ | 300 sub-agentes / 4000 pasos, soporta flujos de desarrollo complejos |
| Análisis de documentos largos | ⭐⭐⭐⭐⭐ | Contexto de 256K + optimización MLA, costo controlado para textos largos |
| Comprensión multimodal | ⭐⭐⭐⭐ | MoonViT nativo, entrada de imágenes y video lista para usar |
| Atención al cliente y diálogo | ⭐⭐⭐⭐ | Excelente en Function Call, caché de prefijo reduce costos |
| Razonamiento matemático puro | ⭐⭐⭐ | Puntuación de 96.4 en AIME aceptable, pero GPT-5.4 es superior |
| Escritura creativa | ⭐⭐⭐ | Expresión natural en chino, pero ligeramente inferior a Claude en tareas estilísticas |

Preguntas frecuentes
Q1: ¿Cuáles son las principales diferencias entre la API de Kimi K2.6 y K2.5 / K2?
K2.6 presenta mejoras significativas en tres áreas: 1) En SWE-Bench Pro, la puntuación subió de 53 en la versión K2.5 a 58.6, superando por primera vez a GPT-5.4 y Claude Opus 4.6; 2) la capacidad de subagentes de Agent Swarm aumentó de 100 a 300, y los pasos de coordinación pasaron de 1500 a 4000; 3) se ha habilitado la ventana de contexto de 256K en toda la serie (las versiones iniciales de K2 solo admitían 128K en algunas variantes). Según el anuncio oficial de Kimi, las versiones tempranas de K2 dejarán de estar disponibles el 25 de mayo de 2026, por lo que los nuevos proyectos deben integrarse directamente con K2.6, cuyo ID de modelo es kimi-k2.6, totalmente compatible con el SDK de OpenAI.
Q2: ¿Es la API de Kimi K2.6 totalmente compatible con el SDK de OpenAI?
Así es. Cuando se invoca a través de plataformas como APIYI, el protocolo de la API es totalmente compatible con la interfaz de chat completions de OpenAI, incluyendo parámetros como streaming, herramientas (Function Call), tool_choice, temperature, top_p, max_tokens, entre otros. Para los SDK principales de Python, Node.js o Go, solo es necesario modificar los parámetros base_url y model para realizar el cambio. Ten en cuenta que el máximo de salida de tokens en K2.6 es de 98,304, muy por encima de los 16K de GPT-5.
Q3: ¿Qué tal son la latencia y el coste al utilizar la ventana de contexto de 256K en K2.6?
K2.6 ha optimizado considerablemente el volumen de caché KV para contextos largos mediante el uso de Multi-head Latent Attention (MLA). En pruebas reales con 100K de entrada, la latencia del primer token es de aproximadamente 8-15 segundos (dependiendo de la carga del servidor), y los tokens subsiguientes se devuelven mediante streaming. En cuanto a costes, una entrada de 256K calculada a $0.60/1M cuesta unos $0.15 por uso. Si se trata de conversaciones multironda con el mismo system prompt, el coste de entrada se reduce a un 25% tras la coincidencia de caché de prefijo. Antes de pasar a producción, se recomienda realizar pruebas de extremo a extremo con tus prompts típicos y monitorear los registros de consumo de tokens para optimizar el gasto.
Q4: ¿En qué se diferencia el Function Call de K2.6 del de GPT-5 / Claude?
A nivel de interfaz son idénticos (protocolo de herramientas al estilo OpenAI), pero sus capacidades internas tienen enfoques distintos: 1) K2.6 admite 300 subagentes concurrentes, lo que le da una ventaja nativa en la orquestación paralela de herramientas; 2) K2.6 se encuentra en el primer nivel del Berkeley Function-Calling Leaderboard, acercándose al nivel de GPT-5; 3) K2.6 admite escritura de prefijo (Partial Mode), lo que permite forzar un formato de salida JSON y reducir la tasa de fallos en las llamadas a herramientas. Para flujos de trabajo de agentes complejos, K2.6 es la opción con mejor relación calidad-precio.
Q5: ¿La invocación de K2.6 a través de APIYI cuenta con autorización oficial? ¿Está garantizada la seguridad de los datos?
APIYI accede a los modelos oficiales de Kimi a través del canal de transferencia oficial de Huawei Cloud. Se trata de un canal de autorización conforme a la normativa, por lo que los pesos del modelo y los resultados de inferencia son idénticos a los oficiales. La transmisión de datos utiliza cifrado HTTPS y la plataforma no almacena el contenido de las solicitudes. Para usuarios empresariales, ofrecemos características de seguridad como subcuentas independientes, control de permisos por clave API y límites de consumo. Si tienes requisitos estrictos de cumplimiento de datos, puedes consultar la política detallada en la página de cumplimiento de apiyi.com.
Q6: ¿Para qué tipo de proyectos es adecuado K2.6? ¿Cuándo debería elegir GPT-5.4 o Claude?
Escenarios para elegir K2.6: asistentes de código, tareas tipo SWE, RAG con contexto largo, orquestación de flujos de agentes y proyectos de pequeña o mediana escala sensibles al coste. Escenarios para elegir GPT-5.4: competiciones matemáticas de alta dificultad (AIME/HMMT) o tareas de investigación científica que requieran una profundidad de razonamiento superior. Escenarios para elegir Claude Opus 4.6: escritura creativa de textos largos o generación de documentos legales/contractuales que requieran un formato estrictamente estandarizado. Recomendamos mantener un diseño de interfaz que permita alternar entre modelos para realizar pruebas comparativas antes de decidir qué modelo usar en producción.
Resumen
Kimi K2.6 es un hito importante para los Modelos de Lenguaje Grande de código abierto en 2026; demuestra que una arquitectura MoE de nivel de cien mil millones de parámetros puede competir directamente con los modelos insignia de código cerrado en codificación, agentes y contextos largos. Su puntuación de 58.6 en SWE-Bench Pro, junto con su capacidad técnica de 256K de contexto y 300 subagentes, lo convierten en el modelo preferido para proyectos de asistencia de código y automatización de I+D.
Puntos clave a recordar:
- Ventaja arquitectónica: MoE de 1T / 32B activado, potencia de cien mil millones de parámetros con el coste de inferencia de un modelo de 32B.
- Liderazgo en benchmarks: Primero en SWE-Bench Pro, Terminal-Bench 2.0 y HLE.
- Ventaja de precio: A través de APIYI por $0.60 / $2.40, aproximadamente un 40% más barato que el precio oficial.
- Ecosistema amigable: Totalmente compatible con el SDK de OpenAI, migración completada en 5 minutos.
- Capacidades de ingeniería: 256K de contexto + 300 subagentes + caché de prefijo.
Para los equipos que buscan construir productos de IA en 2026, la API de Kimi K2.6 es una opción sumamente competitiva en términos de rendimiento, coste y ecosistema. Recomendamos utilizar la plataforma APIYI apiyi.com para validar rápidamente los resultados y comparar el rendimiento real de los diferentes modelos en tu escenario de negocio para tomar la mejor decisión de selección.
Autor: Equipo técnico de APIYI | Seguimos de cerca las tendencias de los Modelos de Lenguaje Grande. Te invitamos a realizar intercambios técnicos y consultar soluciones a través de APIYI apiyi.com.