Nota del autor: Comparación objetiva de Claude Opus 4.6 y GPT-5.4 en 12 pruebas de referencia, precios, ventana de contexto, capacidades de agente y casos de uso, para ayudar a los desarrolladores a tomar la decisión correcta.
En febrero y marzo de 2026, el campo de la IA recibió dos modelos insignia de gran peso: Claude Opus 4.6 de Anthropic (5 de febrero) y GPT-5.4 de OpenAI (5 de marzo). Ambos son los modelos generales más potentes jamás creados por sus respectivas empresas, pero sus filosofías de diseño y áreas de fortaleza son completamente diferentes.
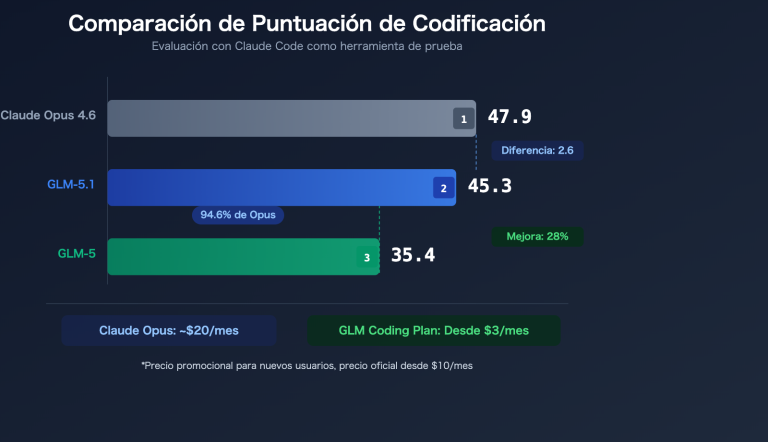
Las pruebas de referencia muestran: GPT-5.4 gana en 5 categorías, Claude Opus 4.6 gana en 3 categorías, pero la ventaja de Claude en dimensiones centrales como programación, razonamiento y calidad del código tiene un valor práctico mayor.
Valor central: Después de leer este artículo, sabrás con claridad qué modelo elegir para diferentes escenarios como programación, razonamiento, automatización o visión.

Comparativa de datos clave entre Claude Opus 4.6 y GPT-5.4
| Dimensión de comparación | Claude Opus 4.6 | GPT-5.4 | Explicación |
|---|---|---|---|
| Fecha de lanzamiento | 2026-02-05 | 2026-03-05 | Diferencia de 1 mes |
| ID del modelo | claude-opus-4-6 | gpt-5.4 | — |
| Ventana de contexto | 200K (1M Beta) | 1,000K | GPT soporta oficialmente 1M |
| Salida máxima | 128K | 128K | Igual |
| Precio de entrada | $5.00/M | $2.50/M | GPT es 50% más barato |
| Precio de salida | $25.00/M | $15.00/M | GPT es 40% más barato |
| Caché de entrada | $0.50/M | $0.25/M | GPT es 50% más barato |
| Modo de razonamiento | Pensamiento adaptativo (Adaptive) | Razonamiento de 5 niveles (none→xhigh) | Cada uno tiene sus características |
| Control de ordenador | ✅ (72.7%) | ✅ (75.0%) | GPT supera al humano |
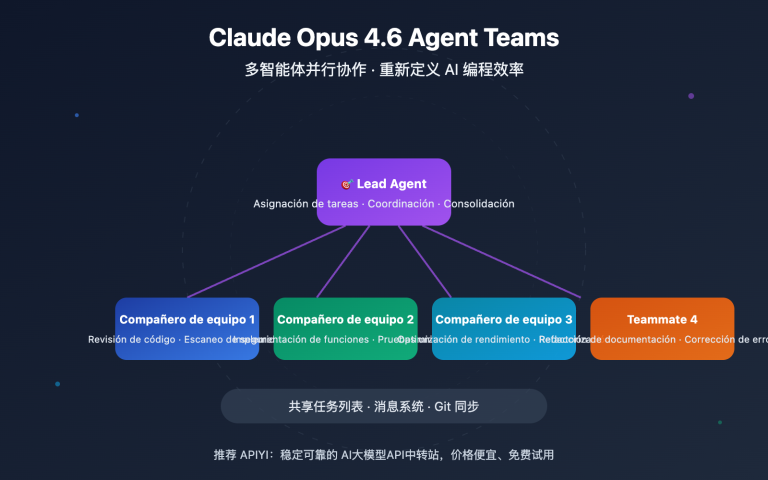
| Equipos de agentes | ✅ Agent Teams | ❌ | Exclusivo de Claude |
| Búsqueda de herramientas | ❌ | ✅ Token reducido 47% | Exclusivo de GPT |
| Complementos financieros | ❌ | ✅ Excel/Sheets | Exclusivo de GPT |
Diferencias en la filosofía de diseño entre Claude Opus 4.6 y GPT-5.4
Las filosofías de diseño de los dos modelos son completamente diferentes:
Claude Opus 4.6 sigue la ruta de la "inteligencia profunda". El pensamiento adaptativo (Adaptive Thinking) permite que el modelo determine la profundidad del razonamiento según la complejidad del problema, sin necesidad de configurar manualmente un presupuesto. La función Agent Teams permite que una instancia principal de Claude genere múltiples subagentes independientes para trabajar en paralelo, coordinándose a través de listas de tareas compartidas y sistemas de mensajes. Esta arquitectura es más adecuada para tareas de programación complejas que requieren una comprensión profunda y cadenas de razonamiento largas.
GPT-5.4 sigue la ruta del "asistente multifuncional". Por primera vez, integra programación (heredada de GPT-5.3 Codex), control de ordenador, visión de resolución completa y búsqueda de herramientas en un modelo general. El mecanismo de búsqueda de herramientas permite que el modelo busque definiciones de herramientas según sea necesario, reduciendo el uso de tokens en un 47%. Los complementos financieros (Moody's, MSCI, etc.) y ChatGPT para Excel apuntan a trabajos profesionales de nivel empresarial.
🎯 Consejo de selección: Las áreas de fortaleza de ambos son casi complementarias. A través de APIYI apiyi.com, puedes usar una sola clave API para invocar tanto a Claude Opus 4.6 como a GPT-5.4, y cambiar entre ellos según el escenario.
Análisis detallado de las pruebas de referencia de Claude Opus 4.6 vs GPT-5.4
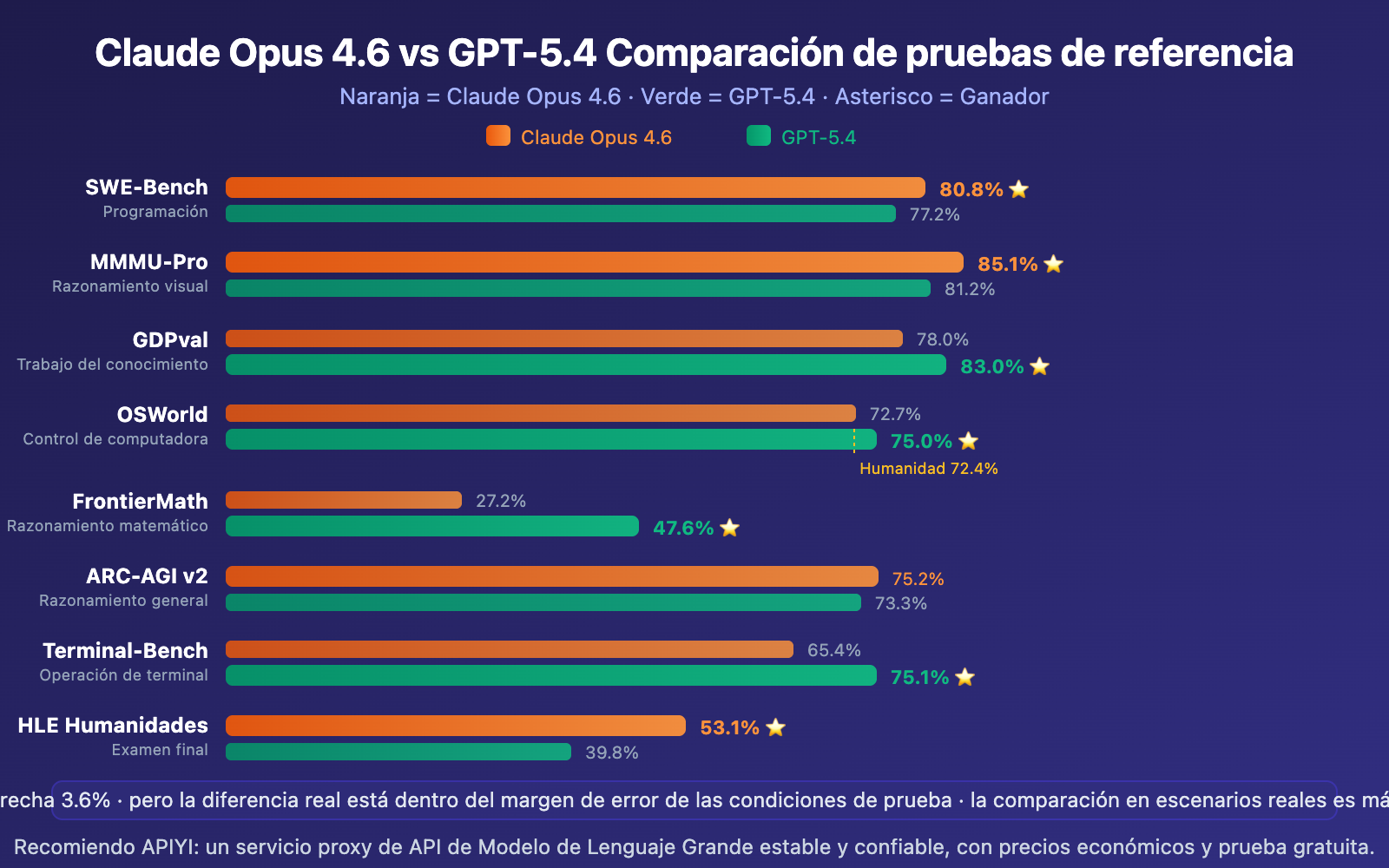
Tabla completa de pruebas de referencia de Claude Opus 4.6 vs GPT-5.4
| Prueba de referencia | Claude Opus 4.6 | GPT-5.4 | Diferencia | Ganador |
|---|---|---|---|---|
| SWE-Bench Verified | 80.8% | 77.2% | +3.6% | Claude |
| SWE-Bench Pro (alta dificultad) | ~45.9% | 57.7% | +11.8% | GPT |
| MMMU-Pro razonamiento visual | 85.1% | 81.2% | +3.9% | Claude |
| GDPval trabajo de conocimiento | 78.0% | 83.0% | +5.0% | GPT |
| OSWorld control de ordenador | 72.7% | 75.0% | +2.3% | GPT |
| FrontierMath matemáticas | 27.2% | 47.6% | +20.4% | GPT |
| ARC-AGI v2 razonamiento general | 75.2% | 73.3% | +1.9% | Claude |
| Terminal-Bench terminal | 65.4% | 75.1% | +9.7% | GPT |
| Humanity's Last Exam | 53.1% | 39.8% | +13.3% | Claude |
| Tau2 Telecom | 99.3% | 98.9% | +0.4% | Claude |
| GPQA razonamiento de posgrado | 91.3% | 92.8% | +1.5% | GPT |
| BrowseComp navegación web | 84.0% | 82.7% | +1.3% | Claude |
Es importante señalar que: las diferencias del 80.0%, 80.6% y 80.8% en SWE-Bench en realidad ya están dentro del margen de error de las condiciones de prueba. En otras palabras, en las pruebas de referencia de programación estandarizadas, ambos modelos ya están convergiendo. Las diferencias reales se manifiestan en la calidad del código, la comprensión de la arquitectura y la experiencia real de desarrollo.
🎯 Recomendación práctica: Las pruebas de referencia son solo un punto de partida. Te sugerimos obtener créditos gratuitos a través de APIYI apiyi.com y comparar el rendimiento real de ambos modelos en tus propios proyectos. Esto es más valioso que cualquier prueba de referencia.
Claude Opus 4.6 vs GPT-5.4: Comparativa de Capacidades Exclusivas
Ventajas Exclusivas de Claude Opus 4.6
1. Equipos de Agentes (Agent Teams)
Los Agent Teams introducidos por Claude Opus 4.6 son una funcionalidad única en el campo de la IA actual. Una instancia principal de Claude (Lead) puede generar múltiples subagentes independientes (Teammates), cada uno con su propia ventana de contexto completa, colaborando en paralelo a través de un sistema compartido de listas de tareas y mensajes.
En tareas de investigación profunda, esta tecnología multiagente mejora el rendimiento en aproximadamente 15 puntos porcentuales. Esta arquitectura es especialmente adecuada para la refactorización paralela de grandes bases de código, donde el agente principal se encarga de la planificación y los subagentes procesan diferentes módulos.
2. Pensamiento Adaptativo (Adaptive Thinking)
A diferencia de los 5 niveles de razonamiento manual de GPT-5.4, el pensamiento adaptativo de Claude permite al modelo juzgar automáticamente la complejidad del problema y asignar dinámicamente la profundidad del razonamiento. En el nivel predeterminado high, Claude casi siempre activa la cadena de pensamiento (Chain-of-Thought); en problemas simples, lo omite automáticamente, ahorrando tokens y reduciendo la latencia.
El pensamiento adaptativo también admite pensamiento intercalado (Interleaved Thinking), que consiste en intercalar reflexiones entre llamadas a herramientas, algo muy efectivo para flujos de trabajo de tipo agente.
Ventajas Exclusivas de GPT-5.4
1. Control Nativo de Computadora
GPT-5.4 es el primer modelo general de OpenAI con capacidad nativa integrada para controlar una computadora. Su puntuación de 75.0% en OSWorld supera directamente la línea de base humana de 72.4%. Puede operar navegadores y aplicaciones de escritorio de dos maneras: mediante código Playwright o a través de instrucciones directas de teclado y ratón.
2. Búsqueda de Herramientas (Tool Search)
En sistemas con una gran cantidad de herramientas, el método tradicional requiere enviar todas las definiciones de herramientas al modelo de una sola vez. La búsqueda de herramientas de GPT-5.4 permite al modelo buscar definiciones bajo demanda, reduciendo el uso de tokens en un 47% mientras mantiene la misma precisión.
3. Integración Profunda en el Sector Financiero
La integración de ChatGPT para Excel/Google Sheets con datos de Moody's/MSCI/FactSet ha creado una ventaja ecosistémica para GPT-5.4 en el análisis financiero que Claude aún no puede igualar. Los puntos de referencia internos de banca de inversión han mejorado del 43.7% al 87.3%.
🎯 Acceso por API: Tanto Claude Opus 4.6 como GPT-5.4 pueden invocarse a través de la interfaz unificada de APIYI en apiyi.com. Los precios de GPT-5.4 siguen a los oficiales ($2.50/$15.00), con un regalo del 10% al recargar desde 100 USD.
Claude Opus 4.6 vs GPT-5.4: Guía de Selección por Escenario

Ejemplo de Acceso por API: Claude Opus 4.6 vs GPT-5.4
import openai
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Refactorización de código complejo → Claude Opus 4.6
refactor = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Refactoriza la inyección de dependencias de este módulo"}]
)
# Análisis global de proyectos muy grandes → GPT-5.4
analysis = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Analiza las vulnerabilidades de seguridad de todo el proyecto"}]
)
Recomendación: Regístrate en APIYI en apiyi.com para acceder a ambos modelos insignia desde una sola cuenta. Los precios de GPT-5.4 siguen a los oficiales, con un 10% de bonificación al recargar desde 100 USD. Cambiar de modelo solo requiere modificar un parámetro.
Preguntas frecuentes
Q1: ¿Cuál es mejor para programación, Claude Opus 4.6 o GPT-5.4?
Depende de la dimensión que evalúes. En el benchmark estándar de programación SWE-Bench, Claude lidera con un 80.8% frente al 77.2% de GPT-5.4, mostrando también una calidad de código y capacidad de refactorización de múltiples archivos superior. Sin embargo, GPT-5.4 supera a Claude en el SWE-Bench Pro de alta dificultad (57.7% vs ~45.9%) y también lidera significativamente en tareas de operación de terminal (75.1% vs 65.4%). Para la mayoría de desarrolladores, las capacidades de programación de ambos modelos ya están convergiendo.
Q2: ¿La diferencia de precio es grande? ¿Cómo elegir?
GPT-5.4 es considerablemente más económico en todos los aspectos: entrada $2.50 vs $5.00/M (50% menos), salida $15.00 vs $25.00/M (40% menos). Si el costo es el factor principal, GPT-5.4 es más adecuado. Si tu proyecto requiere una calidad de código y comprensión de arquitectura extremadamente altas, el sobreprecio de Claude vale la pena. Se recomienda utilizar ambos de forma combinada según el escenario a través de APIYI (apiyi.com) para optimizar costos.
Q3: ¿Cómo usar ambos modelos desde una misma plataforma?
Registra una cuenta en APIYI (apiyi.com):
- Obtén una clave API unificada
- Configura
base_urlcomohttps://vip.apiyi.com/v1 - Tareas de refactorización:
model="claude-opus-4-6" - Análisis de proyectos grandes:
model="gpt-5.4" - Tareas diarias:
model="gpt-5.3-chat-latest"(el más económico)
Recarga desde 100 USD y obtén un 10% adicional. Una sola cuenta para invocar todos los modelos principales.
Conclusión
Conclusiones clave de Claude Opus 4.6 vs GPT-5.4:
- Para programación y razonamiento visual, elige Claude: 80.8% en SWE-Bench, 85.1% en MMMU-Pro (el más alto de la industria), código más limpio, y la colaboración multi-agente "Agent Teams" es una ventaja única.
- Para trabajo de conocimiento y automatización, elige GPT: 83.0% en GDPval, 75.0% en OSWorld (supera a humanos), contexto de 1M disponible oficialmente, y API un 40-50% más barata.
- La estrategia más inteligente es combinarlos: Sus áreas de fortaleza son casi complementarias — usa Claude para refactorización, GPT para análisis de proyectos grandes y automatización, y GPT-5.3 Instant para tareas diarias y ahorrar.
La diferencia de 80.8% vs 77.2% en SWE-Bench puede parecer pequeña, pero en el desarrollo real, la ventaja de Claude en comprensión arquitectónica y limpieza de código sigue siendo notable. GPT-5.4, por su parte, ha establecido ventajas en otra dimensión gracias a su contexto de 1M, control de ordenador y precios más bajos.
Se recomienda acceder a ambos modelos insignia de forma unificada a través de APIYI (apiyi.com). Una sola clave API para invocarlos todos, con recargas desde 100 USD que incluyen un 10% adicional.
📚 Referencias
-
GPT-5.4 vs Claude Opus 4.6: Comparativa de Programación: Análisis desde la perspectiva del desarrollador sobre SWE-Bench, calidad de código y capacidades de Agente
- Enlace:
blog.getbind.co/gpt-5-4-vs-claude-opus-4-6-which-one-is-better-for-coding/ - Descripción: La comparativa más detallada en dimensiones de programación, incluye datos de SWE-Bench Pro y Terminal-Bench
- Enlace:
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro: Comparativa de los Tres Grandes: Análisis completo en 12 pruebas de referencia
- Enlace:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - Descripción: Cobertura completa de precios, contexto, pruebas de referencia, fortalezas y debilidades
- Enlace:
-
Anuncio Oficial de Claude Opus 4.6: Detalles de las nuevas funciones como Equipos de Agentes y Pensamiento Adaptativo
- Enlace:
anthropic.com/news/claude-opus-4-6 - Descripción: Fuente de primera mano para conocer las funciones exclusivas de Claude
- Enlace:
-
Documentación de la API de Pensamiento Adaptativo de Claude Opus 4.6: Guía de integración para desarrolladores
- Enlace:
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - Descripción: Conoce los métodos de uso específicos y la configuración de parámetros del Pensamiento Adaptativo
- Enlace:
Autor: Equipo Técnico de APIYI
Intercambio Técnico: Bienvenido a discutir en la sección de comentarios. Para más información, visita el centro de documentación de APIYI docs.apiyi.com