title: "Análisis técnico de Qwen3.5-Omni: El modelo multimodal nativo de Alibaba"
description: "Exploramos la arquitectura Thinker-Talker, la ventana de contexto de 256K y las capacidades multimodales de Qwen3.5-Omni."
Nota del autor: Análisis detallado de la arquitectura Thinker-Talker MoE, la ventana de contexto de 256K, las capacidades de codificación de audio y video, y la capacidad emergente de Audio-Visual Vibe Coding del modelo multimodal nativo Qwen3.5-Omni de Alibaba.
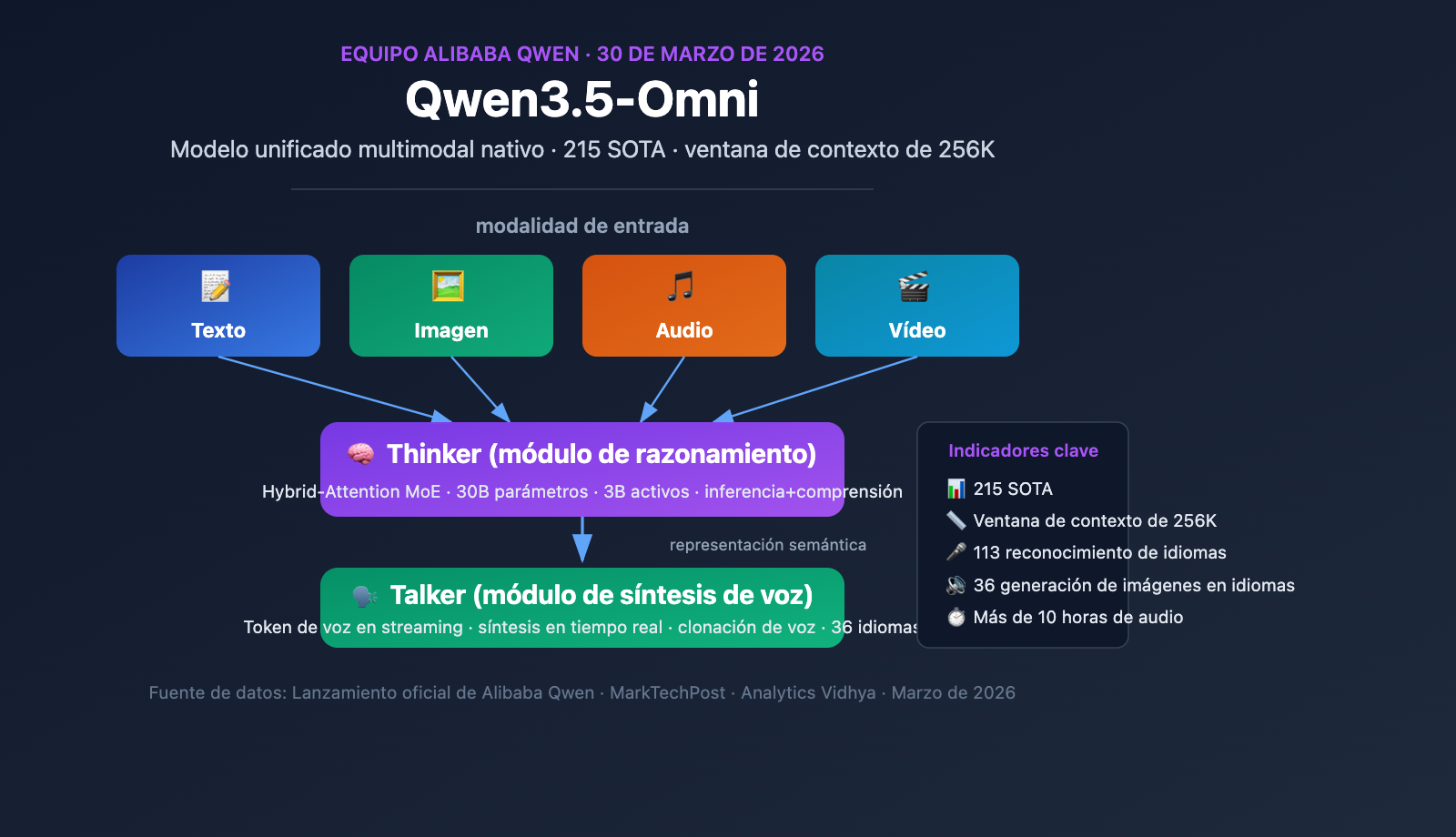
El equipo de Qwen de Alibaba lanzó oficialmente Qwen3.5-Omni el 30 de marzo de 2026. Se trata de un modelo multimodal nativo capaz de procesar texto, imágenes, audio y video simultáneamente dentro de un único flujo de cómputo. Como parte de la intensa ofensiva de lanzamientos de Alibaba entre marzo y abril, Qwen3.5-Omni alcanzó el estado del arte (SOTA) en 215 pruebas de referencia, marcando un avance significativo para los fabricantes de IA chinos en el campo de los modelos de lenguaje grandes (LLM) de modalidad completa.
Valor central: Descubre en 3 minutos el diseño de la arquitectura Thinker-Talker de Qwen3.5-Omni, la estrategia de selección entre sus tres variantes de modelo y su capacidad emergente de Audio-Visual Vibe Coding.
Información clave del modelo multimodal Qwen3.5-Omni
Resumen de parámetros clave de Qwen3.5-Omni
| Parámetro | Detalles |
|---|---|
| Fecha de lanzamiento | 30 de marzo de 2026 |
| Desarrollador | Equipo de Qwen de Alibaba |
| Arquitectura | Thinker-Talker + Hybrid-Attention MoE |
| Variantes del modelo | Plus (MoE 30B-A3B), Flash (MoE ligero), Light (modelo denso/pesos abiertos) |
| Ventana de contexto | 256K tokens |
| Capacidad de audio | 10+ horas de audio continuo |
| Capacidad de video | 400+ segundos de video a 720p (muestreo a 1 FPS) |
| Reconocimiento de voz | 113 idiomas y dialectos (frente a los 19 de la generación anterior) |
| Generación de voz | 36 idiomas (frente a los 10 de la generación anterior) |
| Datos de entrenamiento | Más de 100 millones de horas de datos de audio y video |
| Resultados de referencia | SOTA en 215 pruebas de comprensión de audio/video |
Posicionamiento del modelo Qwen3.5-Omni
El significado central de Qwen3.5-Omni radica en su multimodalidad nativa: no es una solución ensamblada donde un modelo de texto se conecta a módulos de audio y video, sino un modelo unificado preentrenado desde cero con más de 100 millones de horas de datos de audio y video. Todas las modalidades se procesan en el mismo flujo de cómputo, lo que significa que el modelo puede comprender verdaderamente la información semántica en el audio y el video, en lugar de simplemente transcribir el audio y el video a texto para su posterior procesamiento.
Al mismo tiempo, Qwen3.5-Omni es uno de los modelos de la serie lanzados intensivamente por Alibaba entre marzo y abril de 2026. Apenas unos días después, el 2 de abril, Alibaba lanzó el modelo Qwen3.6-Plus (que admite una ventana de contexto de 1 millón de tokens y se enfoca en la programación basada en agentes), lo que demuestra la fuerte inversión de Alibaba en el campo de los modelos de lenguaje grandes.
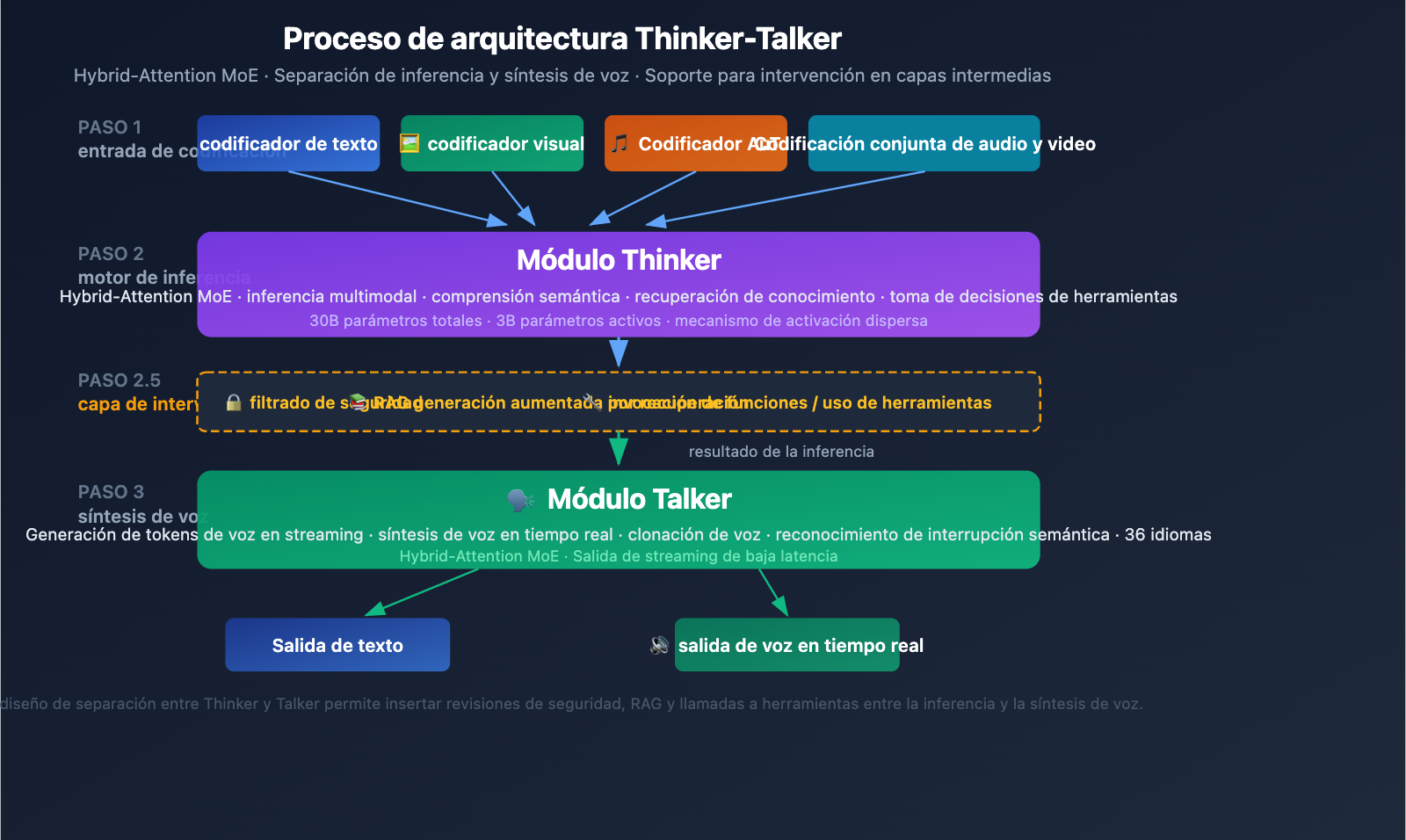
Análisis detallado de la arquitectura Thinker-Talker de Qwen3.5-Omni
Diseño de doble módulo Thinker-Talker
Qwen3.5-Omni utiliza una arquitectura única de doble módulo llamada Thinker-Talker. Este diseño, introducido por primera vez en Qwen2.5-Omni, ha recibido una actualización importante en la versión 3.5: ambos módulos ahora emplean la arquitectura Hybrid-Attention MoE (Mezcla de Expertos con Atención Híbrida).
Módulo Thinker (Pensador):
- Procesa todas las modalidades de entrada: texto, imagen, audio y video.
- Ejecuta tareas de razonamiento y comprensión.
- Genera representaciones de razonamiento interno.
- Utiliza un codificador nativo Audio Transformer (AuT) para procesar el audio.
- Produce representaciones semánticas estructuradas.
Módulo Talker (Expresador):
- Recibe las representaciones de razonamiento del Thinker.
- Convierte las representaciones semánticas en Tokens de voz fluidos.
- Admite síntesis de voz en tiempo real.
- Logra una expresión vocal natural (incluyendo entonación, emoción y pausas).
Valor de ingeniería de la arquitectura Thinker-Talker
La ventaja principal de este diseño separado es la intervencionabilidad intermedia: los sistemas externos (tuberías de recuperación RAG, filtros de seguridad, llamadas a funciones) pueden intervenir entre la salida del Thinker y la síntesis del Talker. Esto significa que:
- Las empresas pueden añadir revisiones de seguridad antes de la salida de voz.
- Los desarrolladores pueden activar llamadas a herramientas basadas en los resultados del razonamiento.
- Los sistemas RAG pueden complementar los resultados con recuperación de conocimientos antes de responder.
Mecanismo de activación dispersa MoE
El núcleo del diseño Hybrid-Attention MoE es la activación dispersa: el modelo solo activa una parte de sus parámetros al procesar cada Token (solo 3B activos de un total de 30B). Este mecanismo permite al modelo mantener una alta capacidad mientras controla el costo de cómputo de cada inferencia dentro de un rango aceptable, lo cual es crucial para aplicaciones en tiempo real (como el diálogo por voz).
🎯 Consejo de desarrollo: La arquitectura separada Thinker-Talker de Qwen3.5-Omni es ideal para construir flujos de trabajo de IA de varios pasos. Si necesitas integrar capacidades multimodales en tus aplicaciones, puedes probar rápidamente las diferencias de rendimiento entre Qwen3.5-Omni y otros modelos multimodales líderes a través de la plataforma APIYI apiyi.com.
Comparativa de las tres variantes del modelo Qwen3.5-Omni
Guía de selección: Plus / Flash / Light
Qwen3.5-Omni ofrece tres variantes de modelo orientadas a diferentes escenarios:
| Variante | Tipo de arquitectura | Escala de parámetros | Forma de acceso | Escenarios de uso |
|---|---|---|---|---|
| Plus | MoE (30B-A3B) | 30B total / 3B activos | API (DashScope) | Razonamiento de máxima calidad, tareas multimodales complejas |
| Flash | MoE ligero | Menos parámetros | API (DashScope) | Escenarios de baja latencia, diálogos en tiempo real |
| Light | Modelo denso | Escala menor | Pesos abiertos (HuggingFace) | Despliegue local, dispositivos de borde |
Recomendaciones de selección:
- Buscando el mejor rendimiento → Elige la variante Plus, que obtuvo la puntuación más alta en 215 pruebas de referencia.
- Buscando baja latencia → Elige la variante Flash, ideal para diálogos de voz en tiempo real e interacciones fluidas.
- Necesidad de despliegue local → Elige la variante Light, con pesos abiertos que pueden ejecutarse en una GPU local.
Cómo acceder a la API de Qwen3.5-Omni
La API de Qwen3.5-Omni sigue el formato estándar /v1/chat/completions, especificando el tipo de salida a través del parámetro modalities:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Acceso unificado a través de APIYI
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Por favor, analiza el contenido de este video"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
Ver ejemplo completo de entrada multimodal
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Entrada multimodal: imagen + audio + texto
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Por favor, genera un informe de análisis basado en la imagen y la descripción de voz"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# Obtener respuesta de texto
print(response.choices[0].message.content)
# Si se solicitó salida de audio, obtener los datos de voz
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"Formato de audio: {audio_data.format}")
💡 Nota de integración: La API de Qwen3.5-Omni es compatible con el formato del SDK de OpenAI. Si ya tienes código basado en este SDK, solo necesitas modificar los parámetros
base_urlymodelpara cambiar rápidamente. A través de la plataforma APIYI apiyi.com, puedes probar y comparar los resultados multimodales de Qwen3.5-Omni y otros modelos como GPT-4o.
Análisis de rendimiento del benchmark de Qwen3.5-Omni
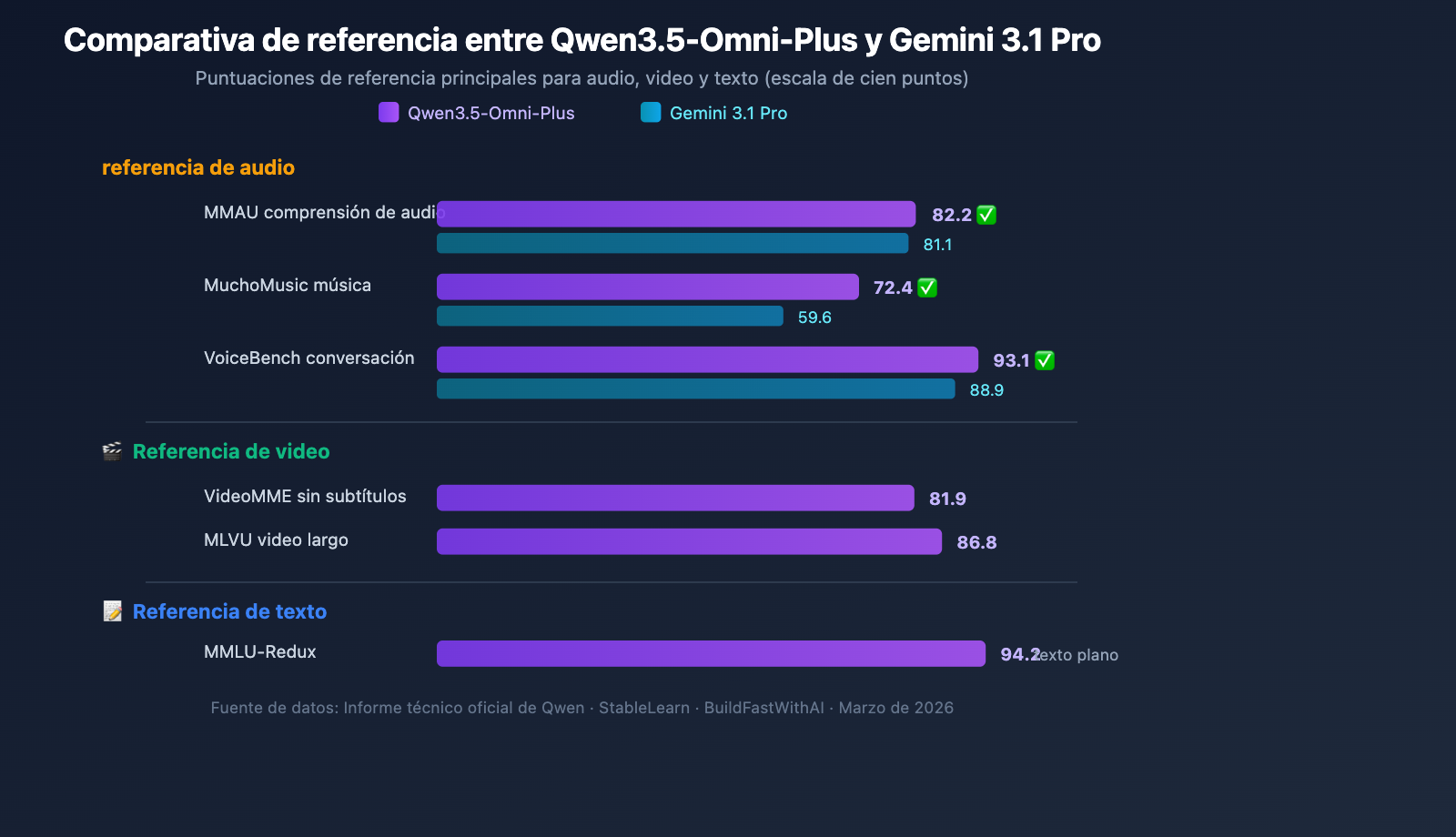
Capacidad de comprensión de audio
Qwen3.5-Omni-Plus supera ampliamente a Google Gemini 3.1 Pro en los benchmarks relacionados con audio:
| Benchmark | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | Ganador |
|---|---|---|---|
| Comprensión de audio MMAU | 82.2 | 81.1 | Qwen |
| Comprensión musical MuchoMusic | 72.4 | 59.6 | Qwen (+21%) |
| Diálogo VoiceBench | 93.1 | 88.9 | Qwen |
En la comprensión musical (MuchoMusic), la ventaja de Qwen3.5-Omni es especialmente notable, con una diferencia del 21%.
Capacidades visuales y de video
| Benchmark | Qwen3.5-Omni-Plus | Descripción |
|---|---|---|
| MMMU-Pro | 73.9 | Puntuación más alta en comprensión multimodal |
| RealWorldQA | 84.1 | Preguntas y respuestas visuales del mundo real |
| VideoMME (sin subtítulos) | 81.9 | Comprensión multimodal de video |
| MLVU | 86.8 | Comprensión de video largo |
| MVBench | 79.0 | Benchmark de video multidimensional |
| LVBench | 71.2 | Benchmark de video largo |
Mantenimiento de la capacidad de razonamiento textual
Qwen3.5-Omni logra capacidades multimodales completas sin apenas sacrificar el rendimiento en razonamiento textual:
| Benchmark | Qwen3.5-Omni-Plus | Qwen3.5-Plus (solo texto) | Diferencia |
|---|---|---|---|
| MMLU-Redux | 94.2 | 94.3 | -0.1 |
| C-Eval | 92.0 | 92.3 | -0.3 |
| IFEval | 89.7 | 89.7 | 0 |
Esto significa que elegir Qwen3.5-Omni no implica sacrificar la calidad del razonamiento textual; puedes usar un solo modelo para cubrir tanto escenarios de texto como multimodales.
🎯 Recomendación de selección: Qwen3.5-Omni tiene una ventaja clara en la comprensión de audio y música. Si tu aplicación implica interacción por voz o análisis de audio, te sugerimos priorizar este modelo. Puedes comparar rápidamente el rendimiento de Qwen3.5-Omni y GPT-4o en tus escenarios específicos a través de APIYI (apiyi.com).
Las 3 capacidades diferenciales de Qwen3.5-Omni
Capacidad 1: Audio-Visual Vibe Coding
Qwen3.5-Omni demuestra una capacidad emergente que el equipo de Qwen denomina "Audio-Visual Vibe Coding": el modelo puede escribir código ejecutable viendo videos y escuchando instrucciones de voz, sin haber sido entrenado específicamente para esta tarea.
En pruebas reales, el modelo es capaz de:
- Convertir bocetos dibujados a mano (capturados por cámara) en páginas web React funcionales.
- Escribir código de funciones basándose en demostraciones en video y descripciones verbales.
- Comprender la intención del diseño visual y generar la implementación de frontend correspondiente.
Esta capacidad es de gran valor para el desarrollo rápido de prototipos y escenarios de bajo código (low-code).
Capacidad 2: Reconocimiento de interrupción semántica
Los sistemas de interacción por voz tradicionales no pueden distinguir entre las respuestas de retroalimentación del usuario (como "ajá", "sí") y una intención real de interrupción. Qwen3.5-Omni introduce un Reconocimiento de Intención de Turno (Turn-Taking Intent Recognition) nativo, que puede distinguir entre:
- Retroalimentación (Backchanneling): Respuestas como "ajá" o "sí" que no tienen intención semántica de interrumpir.
- Interrupción semántica (Semantic Interruption): Situaciones en las que el usuario tiene una intención clara de tomar el control de la conversación.
Esto hace que la experiencia de conversación por voz de Qwen3.5-Omni sea mucho más cercana a una interacción humana real.
Capacidad 3: Clonación de voz
Los usuarios pueden cargar una grabación de voz, y Qwen3.5-Omni aprenderá y clonará esas características vocales para utilizarlas en todas las salidas de voz posteriores. La voz clonada mantiene su naturalidad y estabilidad incluso en escenarios multilingües.
El lugar de Qwen3.5-Omni en la ofensiva de IA de Alibaba
Calendario de lanzamientos de modelos de IA de Alibaba (marzo-abril de 2026)
| Fecha de lanzamiento | Modelo | Posicionamiento | Características clave |
|---|---|---|---|
| 30 de marzo | Qwen3.5-Omni | Modelo multimodal nativo | Procesamiento unificado de texto/imagen/audio/video |
| 2 de abril | Qwen3.6-Plus | Modelo de agente empresarial | Ventana de contexto de 1 millón de tokens, programación basada en agentes |
| Actualización continua | Qwen3-TTS | Síntesis de voz | Serie TTS de código abierto, soporte para clonación de voz |
Este ritmo intensivo de lanzamientos demuestra que Alibaba está impulsando sus capacidades de Modelos de Lenguaje Grande en todos los frentes. Qwen3.5-Omni cubre la percepción y comprensión multimodal, mientras que Qwen3.6-Plus se enfoca en la generación de código y capacidades de agente a nivel empresarial, formando una estrategia complementaria.
Vale la pena señalar que las variantes Plus y Flash de Qwen3.5-Omni se han lanzado mediante API de código cerrado, rompiendo con la estrategia anterior de Alibaba centrada en el código abierto. Medios como WinBuzzer analizan que esto refleja un enfoque en la rentabilidad bajo presión comercial; el titular de un informe de Bloomberg fue directo: "Alibaba lanza su tercer modelo de IA de código cerrado, centrándose en las ganancias".
💰 Consejo de costos: Si estás considerando integrar Qwen3.5-Omni en tu producto, te recomiendo realizar una prueba de concepto utilizando el crédito gratuito de la plataforma APIYI (apiyi.com) para confirmar el rendimiento del modelo antes de pasar a la implementación en producción. La plataforma admite toda la gama de modelos, incluidos Qwen, GPT, Claude y Gemini, lo que facilita una selección flexible según tus necesidades.
Preguntas frecuentes
Q1: ¿Qwen3.5-Omni es de código abierto o cerrado?
Qwen3.5-Omni cuenta con tres variantes: Plus y Flash actualmente solo están disponibles a través de la API DashScope de Alibaba Cloud (código cerrado), mientras que los pesos de la variante Light están abiertos y disponibles para descarga en HuggingFace (código abierto). La generación anterior, Qwen3-Omni, era completamente de código abierto bajo la licencia Apache 2.0, pero las variantes Plus/Flash de la versión 3.5 han cambiado a un modelo exclusivo de API. Si necesitas una implementación local, puedes optar por la variante Light.
Q2: ¿Cómo se compara Qwen3.5-Omni con GPT-4o?
En términos de comprensión de audio y música, Qwen3.5-Omni-Plus supera notablemente a GPT-4o. En cuanto a la comprensión de video, ambos tienen sus propias fortalezas. En razonamiento de texto, Qwen3.5-Omni está casi a la par con el modelo de solo texto de la casa, Qwen3.5-Plus. Te sugiero realizar pruebas comparativas en tu escenario de aplicación específico a través de la plataforma APIYI (apiyi.com), ya que el rendimiento puede variar significativamente según el caso de uso.
Q3: ¿Cómo empezar a usar rápidamente la API de Qwen3.5-Omni?
La API de Qwen3.5-Omni es compatible con el formato estándar del SDK de OpenAI, por lo que la integración es muy sencilla. Solo necesitas instalar el SDK de openai, configurar la clave API correspondiente y la base_url para comenzar la invocación del modelo. Puedes obtener créditos de prueba gratuitos a través de APIYI (apiyi.com) y utilizar los ejemplos de código de este artículo para verificar rápidamente los efectos de la invocación multimodal.
Resumen
Puntos clave del modelo multimodal Qwen3.5-Omni:
- Multimodalidad nativa: Procesa texto, imágenes, audio y video dentro de un único flujo, sin recurrir a soluciones ensambladas.
- Arquitectura Thinker-Talker: Separa el razonamiento de la síntesis de voz, permitiendo la intervención en capas intermedias y la invocación de herramientas.
- 3 variantes disponibles: Plus (la más potente), Flash (baja latencia) y Light (pesos abiertos para despliegue local).
- 215 hitos SOTA: Lidera significativamente sobre Gemini 3.1 Pro en comprensión de audio y música.
- Capacidad emergente: Audio-Visual Vibe Coding, que permite al modelo escribir código a través de video y voz.
Qwen3.5-Omni representa un avance importante en la IA multimodal: un solo modelo que cubre texto, visión, audio y video simultáneamente, sin sacrificar apenas su capacidad de razonamiento textual. Para los desarrolladores que necesitan capacidades multimodales, es una opción que merece ser evaluada seriamente.
Recomendamos probar rápidamente Qwen3.5-Omni y otros modelos multimodales líderes a través de APIYI (apiyi.com). La plataforma ofrece cuotas gratuitas y una interfaz de API unificada, facilitando la comparación y selección de modelos.
📚 Referencias
-
Informe de MarkTechPost: Detalles del lanzamiento de Qwen3.5-Omni
- Enlace:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - Descripción: Análisis técnico detallado e interpretación de la arquitectura.
- Enlace:
-
Repositorio de GitHub de Qwen3-Omni: Código fuente y pesos del modelo
- Enlace:
github.com/QwenLM/Qwen3-Omni - Descripción: Código completo y documentación de la generación anterior, Qwen3-Omni.
- Enlace:
-
Análisis profundo de Analytics Vidhya: Análisis del informe técnico de Qwen3.5-Omni
- Enlace:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - Descripción: Análisis detallado que cubre capacidades como la clonación de voz y el Vibe Coding.
- Enlace:
-
Informe de eWeek: Qwen3.5-Omni como el modelo multimodal más avanzado de Alibaba
- Enlace:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - Descripción: Análisis desde la perspectiva de la industria y comparativa con la competencia.
- Enlace:
-
Página del modelo en HuggingFace: Qwen3-Omni-30B-A3B-Instruct
- Enlace:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - Descripción: Descarga de pesos del modelo y especificaciones técnicas.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a debatir sobre aplicaciones prácticas de IA multimodal en la sección de comentarios. Para más recursos de desarrollo de IA, visita la documentación de APIYI en docs.apiyi.com.