Google ha lanzado oficialmente Gemma 4, que adopta por primera vez la licencia de código abierto Apache 2.0 y presenta 4 modelos que cubren desde Raspberry Pi hasta centros de datos. Como versión de código abierto de la tecnología homóloga de Gemini 3, Gemma 4 ha logrado una mejora integral y superior a Gemma 3 en dimensiones como razonamiento, codificación, visión y ventana de contexto larga.
Valor central: Tras leer este artículo, dominarás la selección de los 4 modelos de Gemma 4, las innovaciones arquitectónicas clave, los límites de las capacidades multimodales y los requisitos de hardware para el despliegue local.

Resumen de información clave de Gemma 4
Gemma 4 fue lanzado el 2 de abril de 2026 en Google Cloud Next, construido sobre la investigación homóloga de Gemini 3, siendo la cuarta generación de la familia de modelos de código abierto de Google.
| Elemento de información | Detalles |
|---|---|
| Fecha de lanzamiento | 2 de abril de 2026 |
| Cantidad de modelos | 4 (E2B / E4B / 26B-A4B / 31B) |
| Acuerdo de licencia | Apache 2.0 (por primera vez, anteriormente era licencia propietaria de Google) |
| Ventana de contexto máxima | 256K tokens (31B y 26B-A4B) |
| Multimodal | Texto + imagen + video + audio (E2B/E4B) |
| Aspectos destacados de la arquitectura | Primera variante MoE, tecnología PLE, atención híbrida |
| Plataformas disponibles | Hugging Face, Google AI Studio, Vertex AI, Ollama, etc. |
Vista general de los cuatro modelos de Gemma 4
| Modelo | Parámetros efectivos | Parámetros totales | Arquitectura | Contexto | Multimodal |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Denso | 128K | Texto+imagen+video+audio |
| Gemma 4 E4B | 4.5B | 8B | Denso | 128K | Texto+imagen+video+audio |
| Gemma 4 26B-A4B | 3.8B activados | 25.2B | MoE | 256K | Texto+imagen+video |
| Gemma 4 31B | 30.7B | 30.7B | Denso | 256K | Texto+imagen+video |
Reglas de nomenclatura: El prefijo "E" representa "Parámetros efectivos" (Effective Parameters), ya que la tecnología PLE hace que los parámetros totales sean mayores que los efectivos. 26B-A4B indica una arquitectura MoE con 26B de parámetros totales y 4B de parámetros activados por token.
🎯 Consejo técnico: Los 4 modelos de Gemma 4 cubren todos los escenarios, desde dispositivos de borde hasta inferencia en la nube. Si necesitas comparar el rendimiento entre varios modelos de código abierto, te sugerimos utilizar la plataforma APIYI apiyi.com para una integración unificada, permitiéndote cambiar y evaluar diferentes modelos rápidamente.
title: "Comparativa de rendimiento: Gemma 4 vs Gemma 3, el mayor salto generacional"
description: "Analizamos el impresionante salto de rendimiento de Gemma 4 frente a Gemma 3, con mejoras de hasta 4.3x en razonamiento matemático y código."
Comparativa de rendimiento: Gemma 4 vs Gemma 3, el mayor salto generacional
Google ha calificado oficialmente a Gemma 4 como "el mayor salto de rendimiento en una sola generación dentro del ecosistema de modelos de código abierto". Los datos de los benchmarks respaldan totalmente esta afirmación.
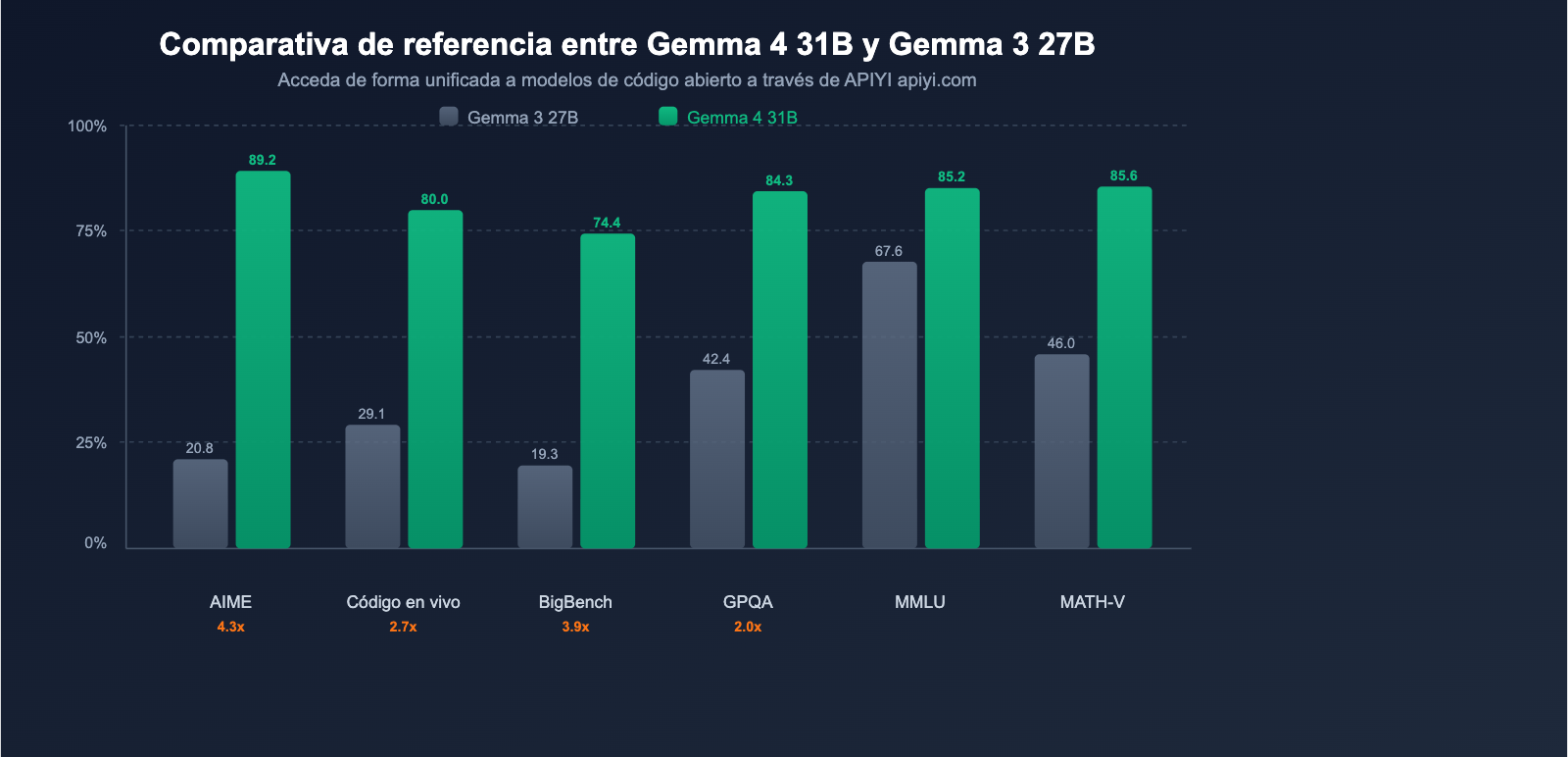
Comparativa de benchmarks clave
| Benchmark | Gemma 3 27B | Gemma 4 31B | Mejora |
|---|---|---|---|
| AIME 2026 (Razonamiento matemático) | 20.8% | 89.2% | +68.4 pts (4.3x) |
| LiveCodeBench v6 (Codificación) | 29.1% | 80.0% | +50.9 pts (2.7x) |
| BigBench Extra Hard (Razonamiento) | 19.3% | 74.4% | +55.1 pts (3.9x) |
| GPQA Diamond (Razonamiento científico) | 42.4% | 84.3% | +41.9 pts (2.0x) |
| MMLU Pro (Conocimiento) | 67.6% | 85.2% | +17.6 pts |
| MATH-Vision (Matemáticas visuales) | 46.0% | 85.6% | +39.6 pts |
| MRCR 128K (Ventana de contexto larga) | 13.5% | 66.4% | +52.9 pts |
Hallazgos clave: El razonamiento matemático en AIME saltó del 20.8% al 89.2%, una mejora de 4.3 veces; la codificación en LiveCodeBench pasó del 29.1% al 80.0%, un incremento de 2.7 veces. No se trata de una mejora incremental, sino de un salto generacional.
Datos completos de los 4 modelos
| Benchmark | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (Multimodal) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
Ventaja de eficiencia de MoE: El modelo 26B-A4B logra aproximadamente el 97% del rendimiento del modelo denso de 31B utilizando solo 3.8B de parámetros activos, lo que reduce drásticamente los costes de invocación del modelo. En LMArena, el 26B-A4B (~1441 ELO) supera incluso al modelo gpt-oss-120B de OpenAI.
💡 Recomendación: Si buscas el máximo rendimiento, elige el 31B; si buscas la mejor relación coste-eficiencia, el 26B-A4B es ideal (97% de rendimiento con solo el 12% de parámetros activos). A través de la plataforma APIYI (apiyi.com), puedes comparar rápidamente el rendimiento real de ambas versiones en tus casos de uso específicos.
6 innovaciones tecnológicas clave en la arquitectura de Gemma 4
Gemma 4 introduce varias tecnologías innovadoras a nivel de arquitectura, lo cual es la razón fundamental de su salto en rendimiento.

Técnica 1: Incrustaciones por capa (PLE)
PLE añade una ruta condicional paralela fuera del flujo residual principal, generando vectores de token dedicados para cada capa del decodificador. Esta técnica mejora la capacidad expresiva de los modelos pequeños, permitiendo que el E2B, con 2.3B de parámetros efectivos, obtenga un rendimiento muy superior a su tamaño.
Técnica 2: Atención híbrida (Hybrid Attention)
Alterna entre capas de atención de ventana deslizante local y atención de contexto completo global:
- Capa de ventana deslizante: procesa el contexto local (E2B/E4B: 512 tokens; 31B/26B: 1024 tokens).
- Capa de atención global: procesa el rango de contexto completo.
Este diseño híbrido reduce significativamente la carga computacional mientras mantiene capacidades de contexto largo.
Técnica 3: Codificación posicional Dual RoPE
- La capa de ventana deslizante utiliza RoPE estándar.
- La capa de atención global utiliza RoPE proporcional.
Este diseño de doble RoPE hace posible un contexto de 256K sin sacrificar la calidad.
Técnica 4: Caché KV compartida
Las últimas N capas reutilizan los tensores K/V de la última capa no compartida del mismo tipo, reduciendo drásticamente el cálculo y el uso de memoria de video. Esta es una de las tecnologías clave que permite a Gemma 4 ejecutar modelos grandes en hardware de consumo.
Técnica 5: Mezcla de expertos MoE (26B-A4B)
Gemma 4 introduce por primera vez variantes MoE:
- 128 expertos pequeños.
- Activación de 8 expertos por token + 1 experto compartido.
- Alcanza aproximadamente el 97% del rendimiento de un modelo denso de 31B con solo 3.8B de parámetros activos.
Técnica 6: Multimodal nativo
Las capacidades visuales y de audio se integran directamente en la fase de preentrenamiento:
- Codificador visual: E2B/E4B ~150M de parámetros; 31B/26B ~550M de parámetros.
- Codificador de audio: Conformer estilo USM, ~300M de parámetros (solo E2B/E4B).
- Soporta imágenes con relación de aspecto variable, con presupuesto de tokens configurable (70-1120 tokens).
Análisis detallado de las capacidades multimodales y de agente de Gemma 4
Gemma 4 no es solo un modelo de conversación; es un sistema multimodal equipado con capacidades completas de agente.
Capacidades de entrada multimodal
| Modalidad | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| Texto | ✅ | ✅ | ✅ | ✅ |
| Imagen | ✅ | ✅ | ✅ | ✅ |
| Video (máx. 60s, 1fps) | ✅ | ✅ | ✅ | ✅ |
| Audio (máx. 30s) | ✅ | ✅ | ❌ | ❌ |
Las capacidades visuales incluyen:
- Detección de objetos y salida de cuadros delimitadores (formato JSON nativo)
- Detección y señalamiento de elementos de GUI
- Análisis de documentos/PDF y comprensión de gráficos
- Comprensión de pantallas/interfaces de usuario
- Entrada cruzada de texto e imagen (mezcla en cualquier orden)
Llamada a funciones nativa y capacidades de agente
Gemma 4 integra capacidades de llamada a funciones desde su fase de entrenamiento, no añadidas mediante ajuste fino posterior:
- Llamada a funciones nativa: Optimizada directamente durante el entrenamiento, admite la orquestación de múltiples herramientas.
- Pensamiento extendido (Extended Thinking): Se puede habilitar el razonamiento de varios pasos mediante
enable_thinking=True. - Salida estructurada: Salida JSON nativa, ideal para la integración con API.
- Flujos de agente multironda: Admite ciclos de agente autónomos de planificación-ejecución-observación.
# Ejemplo de llamada a funciones de Gemma 4 (a través de la interfaz unificada de APIYI)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtener el clima de una ciudad específica",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "¿Cómo está el clima hoy en Pekín?"}],
tools=tools,
tool_choice="auto",
)
🚀 Inicio rápido: La llamada a funciones nativa de Gemma 4 lo convierte en la opción ideal para construir agentes de IA. Recomendamos utilizar la plataforma APIYI (apiyi.com) para una integración rápida, ya que admite interfaces compatibles con OpenAI sin necesidad de adaptaciones adicionales.
Guía de hardware para el despliegue local de Gemma 4
La licencia Apache 2.0 significa que puedes desplegar Gemma 4 libremente en cualquier hardware. A continuación, se detallan los requisitos de hardware para cada modelo.
Resumen de requisitos de hardware
| Modelo | Hardware mínimo | Escenario de despliegue típico |
|---|---|---|
| E2B (2.3B) | <1.5GB de RAM | Raspberry Pi 5 (133 tok/s prellenado, 7.6 tok/s decodificación) |
| E4B (4.5B) | NPU/GPU de nivel móvil | Dispositivos móviles, Apple Silicon (MLX) |
| 26B-A4B (MoE) | Una sola GPU de consumo (cuantizada) | Estaciones de trabajo personales, servidores pequeños |
| 31B (Denso) | Una sola H100 de 80GB (FP16) | Inferencia en la nube, centros de datos |
Hardware y marcos compatibles
| Hardware/Marco | Estado de soporte |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ Soporte para toda la serie |
| Google TPU (Trillium/Ironwood) | ✅ Optimización nativa |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ Compatible |
| Qualcomm NPU (IQ8) | ✅ Inferencia en dispositivos móviles |
| GGUF (llama.cpp/Ollama) | ✅ Cuantización de 2-bit/4-bit |
| ONNX (WebGPU/Navegador) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ Despliegue en contenedores |
El modelo E2B puede ejecutarse en una Raspberry Pi 5 a una velocidad de 7.6 tokens por segundo, lo que abre posibilidades totalmente nuevas para aplicaciones de IA en el borde (edge AI).
Licencia Apache 2.0: ¿Por qué esta vez es diferente?
Gemma 4 adopta por primera vez la licencia Apache 2.0, lo que supone un cambio significativo. Anteriormente, todos los modelos Gemma utilizaban acuerdos de licencia propios de Google, los cuales incluían restricciones de uso específicas y cláusulas de rescisión.
Comparativa de licencias
| Dimensión | Gemma 3 (Licencia Google) | Gemma 4 (Apache 2.0) |
|---|---|---|
| Uso comercial | Con condiciones | ✅ Totalmente libre |
| Modificación y distribución | Sujeto a términos adicionales | ✅ Totalmente libre |
| Modelos derivados | Limitado | ✅ Totalmente libre |
| Derecho de rescisión | Google se reserva el derecho | ❌ Irrevocable |
| Concesión de patentes | Limitada | ✅ Autorización explícita |
Apache 2.0 significa que:
- Las empresas pueden utilizarlo en productos comerciales con total tranquilidad y sin riesgos legales.
- Es posible ajustar y distribuir modelos derivados libremente.
- Se alinea con las estrategias de código abierto de Meta Llama y DeepSeek.
- Reduce drásticamente las barreras de cumplimiento para la adopción empresarial.
💰 Optimización de costes: Apache 2.0 + despliegue local = cero costes de invocación del modelo. Para escenarios con un alto volumen de inferencia, el despliegue local de Gemma 4 puede resultar más económico que la invocación del modelo vía API. Si necesitas comparar la rentabilidad entre el despliegue local y el uso de API, puedes utilizar la plataforma APIYI (apiyi.com) para validar los resultados antes de decidirte por el despliegue local.
Obtención y puesta en marcha rápida de Gemma 4
Canales de descarga del modelo
| Plataforma | Modelos disponibles | Uso |
|---|---|---|
| Hugging Face | Los 4 modelos (base + IT) | Descarga general, investigación |
| Google AI Studio | 31B, 26B MoE | Experiencia online gratuita |
| Vertex AI | Los 4 modelos | Despliegue a nivel empresarial |
| Ollama / llama.cpp | Versiones cuantizadas GGUF | Despliegue local rápido |
| Google AI Edge Gallery | E4B, E2B | Despliegue en dispositivos móviles |
Despliegue con un clic en Ollama
# Desplegar Gemma 4 31B (recomendado)
ollama run gemma4:31b
# Desplegar versión MoE (alta relación coste-rendimiento)
ollama run gemma4:26b-a4b
# Desplegar versión ligera (dispositivos de borde)
ollama run gemma4:e4b
Soporte para ajuste fino (fine-tuning)
Gemma 4 ofrece un ecosistema completo para el ajuste fino:
| Marco de trabajo | Métodos soportados |
|---|---|
| TRL | SFT, DPO, aprendizaje por refuerzo (incluye multimodal) |
| PEFT | LoRA, QLoRA (vía bitsandbytes) |
| Vertex AI | Entrenamiento gestionado |
| Unsloth Studio | Ajuste fino mediante interfaz de usuario |
Los codificadores de visión y audio pueden congelarse, ajustando únicamente la parte de texto, lo que reduce significativamente los costes de entrenamiento.
🎯 Consejo técnico: Se recomienda probar primero el rendimiento de Gemma 4 a través de la plataforma APIYI (apiyi.com) mediante API. Una vez confirmado que cumple con tus requisitos, procede con el despliegue local o el ajuste fino para evitar el desperdicio de recursos.
Preguntas frecuentes
Q1: ¿Qué relación existe entre Gemma 4 y Gemini 3?
Gemma 4 está construido sobre la misma base de investigación que Gemini 3; se puede entender como la versión de código abierto de la tecnología de Gemini 3. Aunque Gemma 4 tiene una escala menor (máximo 31B frente a los cientos de miles de millones de Gemini), emplea las mismas innovaciones de arquitectura central. A través de la plataforma APIYI apiyi.com, puedes utilizar tanto Gemma 4 como la serie de modelos Gemini para realizar análisis comparativos.
Q2: ¿Cómo elegir entre el modelo MoE de 26B y el denso de 31B?
Si tienes hardware limitado o necesitas un alto rendimiento (throughput), elige el MoE 26B-A4B: alcanza aproximadamente el 97% del rendimiento del modelo de 31B utilizando solo 3.8B de parámetros activos. Si buscas un rendimiento máximo y cuentas con una GPU de 80GB, elige el modelo denso de 31B. El costo de inferencia de la versión MoE es aproximadamente 1/8 del de la versión densa.
Q3: ¿Para qué escenarios son adecuados E2B y E4B?
E2B es ideal para escenarios de borde extremo (Raspberry Pi, dispositivos IoT, móviles), mientras que E4B es adecuado para dispositivos móviles y despliegues en PC ligeros. Ambos admiten entrada de audio, algo que los modelos de 31B y 26B no soportan. Si tu aplicación requiere comprensión de voz, debes elegir E2B o E4B.
Q4: ¿Qué impacto tiene la licencia Apache 2.0 en el uso comercial?
Apache 2.0 es una de las licencias de código abierto más permisivas; permite el uso comercial, la modificación y la distribución de forma totalmente libre e irrevocable. A diferencia de la licencia propietaria de Google para Gemma 3, las empresas no tienen que preocuparse por riesgos de cumplimiento. Puedes probar los modelos mediante la API en la plataforma APIYI apiyi.com y, una vez confirmado el rendimiento, desplegarlos localmente en tus productos comerciales.
Resumen
Gemma 4 representa una actualización importante en la estrategia de IA de código abierto de Google. La licencia Apache 2.0 elimina las barreras de uso anteriores; sus cuatro modelos cubren desde Raspberry Pi hasta H100; ofrece un salto generacional en rendimiento de 4.3 veces en AIME y 2.7 veces en LiveCodeBench; además, su capacidad multimodal nativa y de llamada a funciones lo convierten en el modelo base preferido para el desarrollo de agentes de código abierto.
Resumen de puntos clave:
- Licencia: Por primera vez bajo Apache 2.0, uso comercial totalmente libre.
- Modelos: 4 variantes que cubren de 2B a 31B, incluyendo la primera variante MoE.
- Rendimiento: AIME +68pts (4.3x), LiveCodeBench +51pts (2.7x).
- Multimodal: Integración nativa de texto, imagen, video y audio.
- Agentes: Llamada a funciones nativa + Extended Thinking.
- Despliegue: Cobertura total desde Raspberry Pi hasta H100, compatible con múltiples marcos como GGUF/ONNX/MLX.
Recomendamos acceder rápidamente a la serie de modelos Gemma 4 a través de APIYI apiyi.com para comparar el rendimiento real de los diferentes modelos bajo una interfaz unificada.
Referencias
- Blog oficial de Google – Lanzamiento de Gemma 4:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Modelo Gemma 4:
huggingface.co/blog/gemma4 - Google AI – Ficha técnica del modelo Gemma 4:
ai.google.dev/gemma/docs/core/model_card_4
Este artículo fue redactado por el equipo técnico de APIYI. Para más tutoriales sobre el uso de Modelos de Lenguaje Grande, visita APIYI en apiyi.com