title: "Llama 4: Análisis de los nuevos modelos multimodales MoE de Meta"
description: "Meta lanza Llama 4 Scout y Maverick, modelos multimodales MoE. Scout destaca con 10M de tokens de contexto, mientras que Maverick supera a GPT-4o."
Nota del autor: Meta ha lanzado Llama 4 Scout y Maverick, utilizando una arquitectura MoE multimodal nativa. Scout cuenta con una ventana de contexto de 10 millones de tokens, mientras que Maverick supera a GPT-4o en evaluaciones integrales. Este artículo analiza en profundidad los detalles técnicos y su impacto en los desarrolladores.
Meta ha lanzado oficialmente la familia de modelos Llama 4, y los primeros modelos de código abierto multimodales nativos MoE, Llama 4 Scout y Maverick, han generado un gran interés en la comunidad de IA. Este artículo ofrece un análisis rápido sobre el profundo impacto de este hito para los desarrolladores de IA y la industria en general.
Valor central: Descubre en 3 minutos los avances técnicos clave, el rendimiento en evaluaciones y el valor de aplicación real de Llama 4 Scout y Maverick.

Resumen de información clave: Llama 4 Scout y Maverick
| Ítem | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| Fecha de lanzamiento | 5 de abril de 2025 | 5 de abril de 2025 |
| Tipo de arquitectura | MoE multimodal nativo | MoE multimodal nativo |
| Parámetros activos | 17 mil millones | 17 mil millones |
| Número de expertos | 16 | 128 |
| Parámetros totales | 109 mil millones | 400 mil millones |
| Ventana de contexto | 10 millones de tokens | 1 millón de tokens |
| Licencia de código abierto | Licencia Llama | Licencia Llama |
Posicionamiento clave de Llama 4 Scout y Maverick
Llama 4 es la cuarta generación de la familia de Modelos de Lenguaje Grande lanzada por Meta, y es la primera versión de la serie Llama en adoptar una arquitectura multimodal nativa y de Mezcla de Expertos (MoE). En comparación con la serie Llama 3, Llama 4 ha experimentado una reestructuración fundamental a nivel de arquitectura.
Scout se posiciona como un modelo eficiente para el procesamiento de textos largos, ofreciendo la ventana de contexto de 10 millones de tokens más larga de la industria con un costo de inferencia extremadamente bajo. Maverick, por su parte, se posiciona como un modelo general de alto rendimiento, logrando capacidades integrales que superan a GPT-4o mediante su red de 128 expertos.
Ambos modelos ya tienen sus pesos disponibles para descarga; los desarrolladores pueden obtenerlos a través de llama.com y Hugging Face.
Análisis de la arquitectura técnica de Llama 4 Scout y Maverick
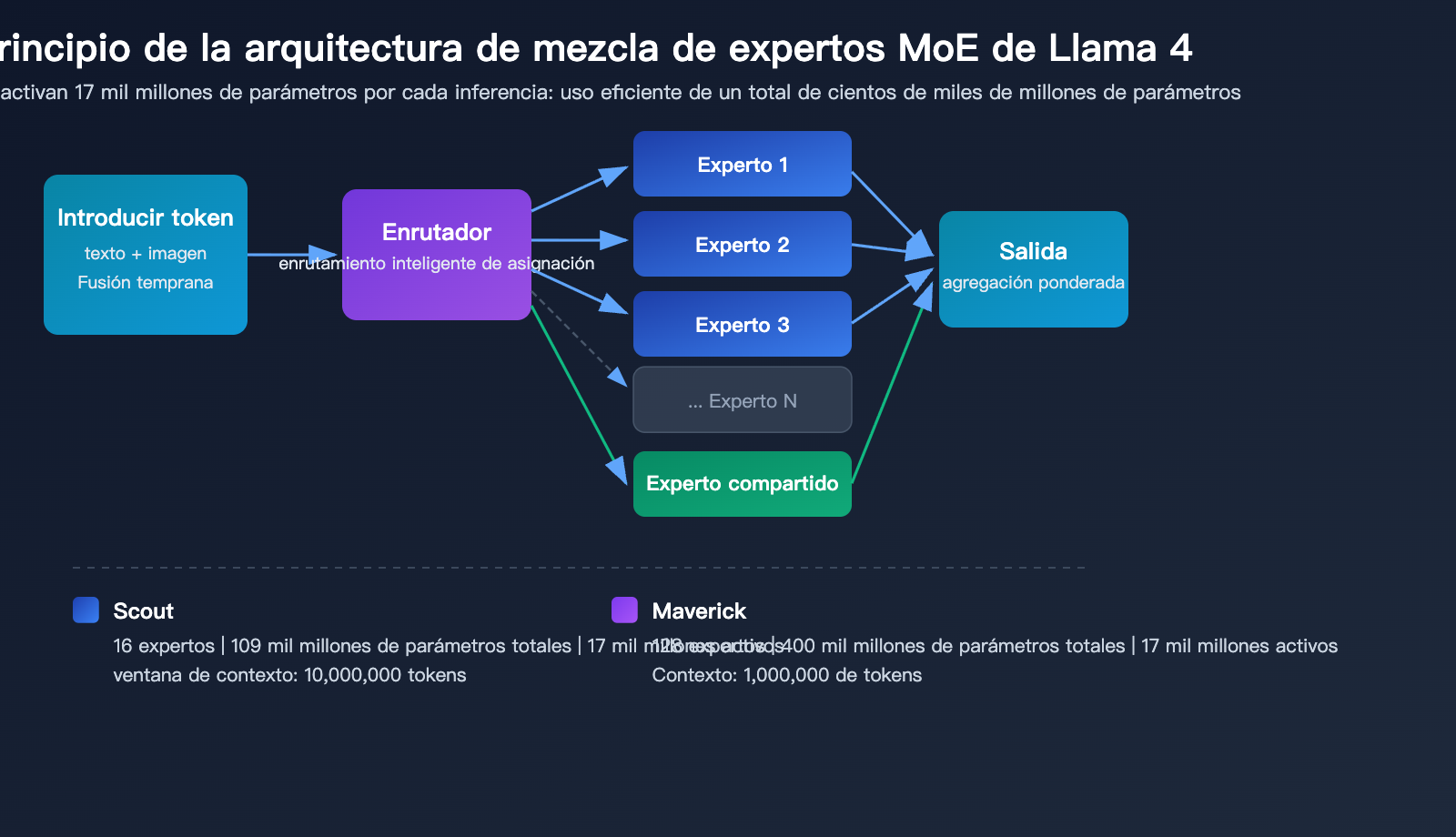
Arquitectura de multimodalidad nativa Early Fusion
La mayor innovación arquitectónica de Llama 4 reside en su entrenamiento multimodal nativo. A diferencia de los enfoques anteriores que integraban módulos visuales en modelos de lenguaje ya existentes, Llama 4 adopta desde la fase de preentrenamiento un esquema de Early Fusion (fusión temprana), integrando los tokens de texto y visuales directamente en la red troncal del modelo.
Esto significa que, al procesar contenido mixto de imagen y texto, Llama 4 ya no realiza un procesamiento en dos etapas de "ver primero y hablar después", sino que comprende y razona sobre la imagen y el texto como una entrada unificada.
Mecanismo de mezcla de expertos (MoE) de Llama 4
| Detalles técnicos | Scout (16 expertos) | Maverick (128 expertos) |
|---|---|---|
| Parámetros totales | 109 mil millones | 400 mil millones |
| Activación por inferencia | 17 mil millones de parámetros | 17 mil millones de parámetros |
| Expertos en enrutamiento | 16 + experto compartido | 128 + experto compartido |
| Eficiencia de inferencia | Ejecutable en una sola H100 (INT4) | Ejecutable en una sola DGX H100 |
| Arquitectura de contexto | iRoPE (atención sin entrelazado de codificación posicional) | Atención estándar |
La ventaja principal de la arquitectura MoE es que, aunque el número total de parámetros alcanza los 109 mil millones y 400 mil millones respectivamente, solo se activan 17 mil millones de parámetros en cada inferencia. Esto permite que Llama 4 Scout pueda ejecutarse en una sola GPU NVIDIA H100 mediante cuantización INT4, reduciendo drásticamente la barrera de despliegue.
Datos de entrenamiento y escala de Llama 4
El volumen de datos de entrenamiento de Llama 4 alcanza los 30 billones+ de tokens, el doble que Llama 3. La cantidad de datos multilingües es 10 veces mayor que la de Llama 3, cubriendo 200 idiomas. El entrenamiento utiliza precisión FP8, logrando una eficiencia de entrenamiento de 390 TFLOPs por GPU en el modelo Behemoth.
Rendimiento de evaluación de Llama 4 Scout y Maverick
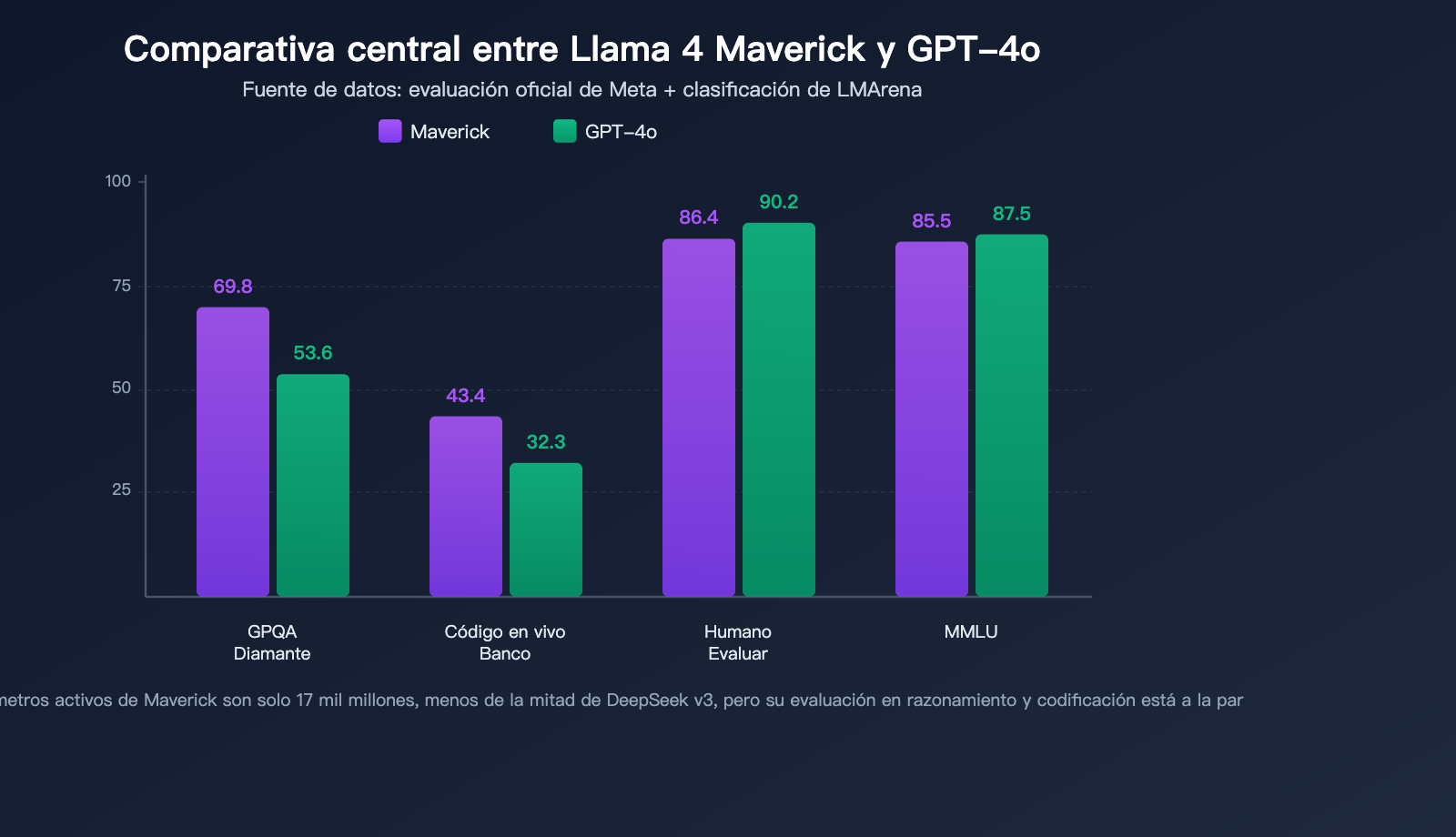
Datos de evaluación de Llama 4 Maverick
Maverick destaca en múltiples evaluaciones autorizadas, superando en capacidad integral a GPT-4o y Gemini 2.0 Flash:
| Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | Evaluación |
|---|---|---|---|---|
| MMLU | 85.5 | ~87-88 | – | Cerca del nivel superior |
| GPQA Diamond | 69.8 | 53.6 | – | Ventaja significativa |
| LiveCodeBench | 43.4 | 32.3 | – | Ventaja notable |
| HumanEval | 86.4% | 90.2% | – | Nivel cercano |
| LMArena ELO | 1417 | Inferior a 1417 | Inferior a 1417 | Nivel superior |
Puntos destacados a tener en cuenta:
Liderazgo en razonamiento científico en GPQA Diamond: Maverick obtuvo una puntuación de 69.8 en GPQA Diamond, superando en más de 16 puntos porcentuales a GPT-4o (53.6), lo que demuestra una potente capacidad de razonamiento en disciplinas profesionales.
Capacidad de codificación destacada en LiveCodeBench: En la evaluación de programación en tiempo real LiveCodeBench, Maverick lidera con 43.4 puntos frente a los 32.3 de GPT-4o, igualando a DeepSeek v3 en tareas de razonamiento y codificación, a pesar de que la cantidad de parámetros activos de Maverick es menos de la mitad que la de DeepSeek v3.
Nivel superior en evaluación de preferencia humana LMArena: La versión experimental de Maverick obtuvo una puntuación ELO de 1417 en LMArena (Chatbot Arena), situándose entre los modelos de primer nivel mundial.
Puntos destacados de la evaluación de Llama 4 Scout
Scout, como un modelo "pequeño" con solo 17 mil millones de parámetros activos, ofrece un rendimiento impresionante:
- Supera a Gemma 3, Gemini 2.0 Flash-Lite y Mistral 3.1 en una amplia gama de benchmarks.
- Supera a todos los modelos Llama 3 de la generación anterior, incluido el Llama 3.3 70B, que tiene más parámetros.
- Cuenta con la ventana de contexto de 10 millones de tokens más larga de la industria, capaz de procesar aproximadamente 7.5 millones de palabras de texto.
- Puede ejecutarse en una sola GPU H100, con un costo de inferencia extremadamente bajo.
🎯 Consejo para desarrolladores: Tanto Llama 4 Scout como Maverick ya admiten llamadas a través de interfaces compatibles con OpenAI. Si necesitas probar rápidamente los efectos reales de estos modelos, puedes obtener una interfaz API unificada a través de la plataforma APIYI apiyi.com; con una sola clave puedes cambiar entre múltiples modelos de código abierto y cerrado.
El impacto de Llama 4 Scout y Maverick para los desarrolladores
El valor de aplicación de la ventana de contexto de 10 millones de tokens
La ventana de contexto de 10 millones de tokens de Scout es la más larga entre los modelos publicados actualmente, y esta capacidad abre nuevos horizontes de aplicación para los desarrolladores:
- Análisis completo de bases de código: Es posible introducir el código de proyectos medianos y grandes en el Modelo de Lenguaje Grande de una sola vez para su análisis.
- Procesamiento de documentos extensos: Capacidad para procesar cientos de páginas de documentación técnica, contratos legales o trabajos de investigación en una sola pasada.
- Memoria de diálogo de múltiples turnos: Mantenimiento de una memoria de contexto extremadamente larga en aplicaciones conversacionales.
- Extracción de datos a gran escala: Extracción masiva de información estructurada a partir de volúmenes ingentes de texto no estructurado.
Impacto en el ecosistema de código abierto de Llama 4
| Dimensión del impacto | Cambio específico | Beneficio para el desarrollador |
|---|---|---|
| Umbral de despliegue | Scout ejecutable en una sola tarjeta | Reducción de costes de hardware |
| Capacidad del modelo | Nivel superior a GPT-4o | El código abierto alcanza al cerrado |
| Multimodal | Comprensión nativa de imagen y texto | Sin necesidad de módulos visuales adicionales |
| Contexto | 10 millones de tokens | Nuevos escenarios de aplicación |
| Personalización | Ajuste fino (fine-tuning) de pesos abierto | Optimización para escenarios verticales |
El lanzamiento de Llama 4 marca la primera vez que los modelos de código abierto igualan o incluso superan en capacidad integral a los principales modelos comerciales cerrados. Para los desarrolladores, esto significa:
Ventaja de costes: El despliegue privado basado en Llama 4 puede reducir significativamente los costes de invocación del modelo, siendo ideal para escenarios de producción con alta frecuencia de uso.
Libertad de personalización: La apertura de pesos significa que los desarrolladores pueden realizar ajustes finos, cuantización, destilación y otras operaciones para crear modelos exclusivos adaptados a escenarios verticales.
Prosperidad del ecosistema: En su primer día de lanzamiento, Llama 4 recibió el apoyo de múltiples plataformas en la nube como AWS, Google Cloud, Azure, Together.ai, Groq y Fireworks.
Integración de la plataforma Llama 4
Meta ha integrado Llama 4 en sus plataformas sociales, proporcionando capacidades multimodales al asistente Meta AI:
- WhatsApp: Soporte para enviar imágenes para análisis y diálogo con IA.
- Messenger: Interacción y preguntas multimodales.
- Instagram Direct: Comprensión de imágenes y asistencia creativa.
- Meta.ai: Uso directo a través de la web.
Esta es la primera vez que un Modelo de Lenguaje Grande de IA se despliega directamente ante los consumidores a una escala tan masiva, cubriendo miles de millones de usuarios.
Llama 4 Behemoth: El modelo insignia aún en entrenamiento
Además de Scout y Maverick, Meta ha anunciado el modelo insignia de la familia Llama 4: Behemoth.
| Parámetro | Especificaciones de Behemoth |
|---|---|
| Parámetros activos | 288 mil millones |
| Número de expertos | 16 |
| Cantidad total de parámetros | Aprox. 2 billones |
| Estado de entrenamiento | En curso |
Según los datos de los puntos de control iniciales publicados por Meta, Behemoth ya ha superado a GPT-4.5, Claude Sonnet 3.7 y Gemini 2.0 Pro en varias evaluaciones STEM. Maverick ha obtenido mejoras de capacidad a través de la destilación de conocimiento de Behemoth durante su entrenamiento, lo que explica por qué Maverick logra un rendimiento de primer nivel con una cantidad menor de parámetros activos.
💡 Sugerencia de seguimiento: El lanzamiento final de Behemoth elevará aún más el límite de capacidad de los modelos de código abierto. Los desarrolladores pueden comenzar a construir aplicaciones basadas en Scout y Maverick, realizar pruebas comparativas entre modelos en la plataforma APIYI apiyi.com y realizar una transición fluida una vez que Behemoth sea lanzado.
Acceso rápido a Llama 4 Scout y Maverick
Ejemplo de invocación de API minimalista
Mediante la interfaz compatible con OpenAI, puedes invocar el modelo Llama 4 con solo 10 líneas de código:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{"role": "user", "content": "Explica cómo funciona la arquitectura MoE"}]
)
print(response.choices[0].message.content)
Ver ejemplo de invocación multimodal
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Leer y codificar la imagen local
with open("image.jpg", "rb") as f:
image_data = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Por favor, describe el contenido de esta imagen"},
{"type": "image_url", "image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
}}
]
}]
)
print(response.choices[0].message.content)
🚀 Inicio rápido: Recomendamos obtener tu clave API y saldo de prueba gratuito a través de APIYI (apiyi.com). La plataforma admite una interfaz unificada para Llama 4 Scout, Maverick y otros modelos principales, facilitando la comparación rápida del rendimiento real entre diferentes modelos.
Preguntas frecuentes
P1: ¿Cómo elegir entre Llama 4 Scout y Maverick?
Si necesitas procesar textos extremadamente largos (como bases de código completas o análisis de documentos extensos), elige Scout (ventana de contexto de 10 millones de tokens). Si buscas el modelo generalista con las capacidades más sólidas, elige Maverick (128 expertos, supera a GPT-4o en evaluaciones). Ambos pueden probarse en la plataforma APIYI (apiyi.com) para ayudarte a tomar la mejor decisión.
P2: ¿Es Llama 4 completamente gratuito?
Llama 4 utiliza la licencia Llama para pesos abiertos, permitiendo su uso comercial. Sin embargo, las empresas con más de 700 millones de usuarios activos mensuales deben solicitar un permiso especial a Meta. Para la gran mayoría de desarrolladores y empresas, su uso es gratuito. Si no deseas realizar el despliegue por tu cuenta, también puedes invocarlo bajo demanda mediante API a través de plataformas de terceros como APIYI (apiyi.com).
P3: ¿Es Llama 4 Maverick realmente mejor que GPT-4o?
En evaluaciones clave como GPQA Diamond (razonamiento científico) y LiveCodeBench (programación en tiempo real), Maverick supera significativamente a GPT-4o. En MMLU y HumanEval, ambos están muy cerca. En la evaluación de preferencias humanas de LMArena, Maverick también ha alcanzado una puntuación ELO de primer nivel. En general, Maverick se sitúa en el mismo nivel que GPT-4o en evaluaciones integrales, superándolo en algunos indicadores.
Resumen
Puntos clave sobre Llama 4 Scout y Maverick:
- Innovación arquitectónica: Los primeros modelos de código abierto MoE (Mezcla de Expertos) multimodales nativos, con una arquitectura de fusión temprana (Early Fusion) que logra una comprensión verdaderamente integrada de texto e imagen.
- Salto en el rendimiento: Maverick supera a GPT-4o en GPQA Diamond por más de 16 puntos porcentuales, mientras que Scout, con 17 mil millones de parámetros activos, supera a Llama 3.3 70B.
- Transformación de aplicaciones: Una ventana de contexto de 10 millones de tokens y pesos abiertos, lo que abre nuevos escenarios de aplicación y posibilidades de despliegue para los desarrolladores.
El lanzamiento de Llama 4 marca el inicio de una nueva era para los Modelos de Lenguaje Grande de código abierto. Ya sea para construir aplicaciones empresariales o proyectos personales, los desarrolladores pueden obtener capacidades comparables a los mejores modelos de código cerrado gracias a Llama 4. Recomendamos probar la serie de modelos Llama 4 rápidamente a través de APIYI (apiyi.com), plataforma que ofrece cuotas gratuitas y una interfaz unificada para múltiples modelos, ayudando a los desarrolladores a elegir la opción más eficiente.
📚 Referencias
-
Blog oficial de Meta AI – Anuncio de lanzamiento de Llama 4: Fuente autorizada de detalles técnicos y datos de evaluación del modelo.
- Enlace:
ai.meta.com/blog/llama-4-multimodal-intelligence - Descripción: Incluye una introducción completa a la arquitectura, datos de evaluación y detalles del lanzamiento.
- Enlace:
-
Sitio web oficial de Llama – Descarga de modelos: Obtén los pesos y la documentación de Llama 4.
- Enlace:
llama.com/models/llama-4 - Descripción: Ofrece descargas de modelos, información de licencias y documentación técnica.
- Enlace:
-
Hugging Face – Repositorio de modelos Llama 4: Guía de uso y alojamiento de la comunidad de código abierto.
- Enlace:
huggingface.co/meta-llama - Descripción: Proporciona tarjetas de modelo, versiones cuantizadas y debates de la comunidad.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a discutir tus experiencias con Llama 4 en la sección de comentarios. Para más información sobre la integración de modelos de IA, visita el centro de documentación de APIYI en docs.apiyi.com.