Nota del autor: Comparto mi experiencia práctica con Claude Opus 4.7 para procesar archivos CSV y Excel, explicando por qué no deberías simplemente volcar tablas grandes a la IA, sino pedirle que escriba scripts, cree herramientas y realice validaciones.
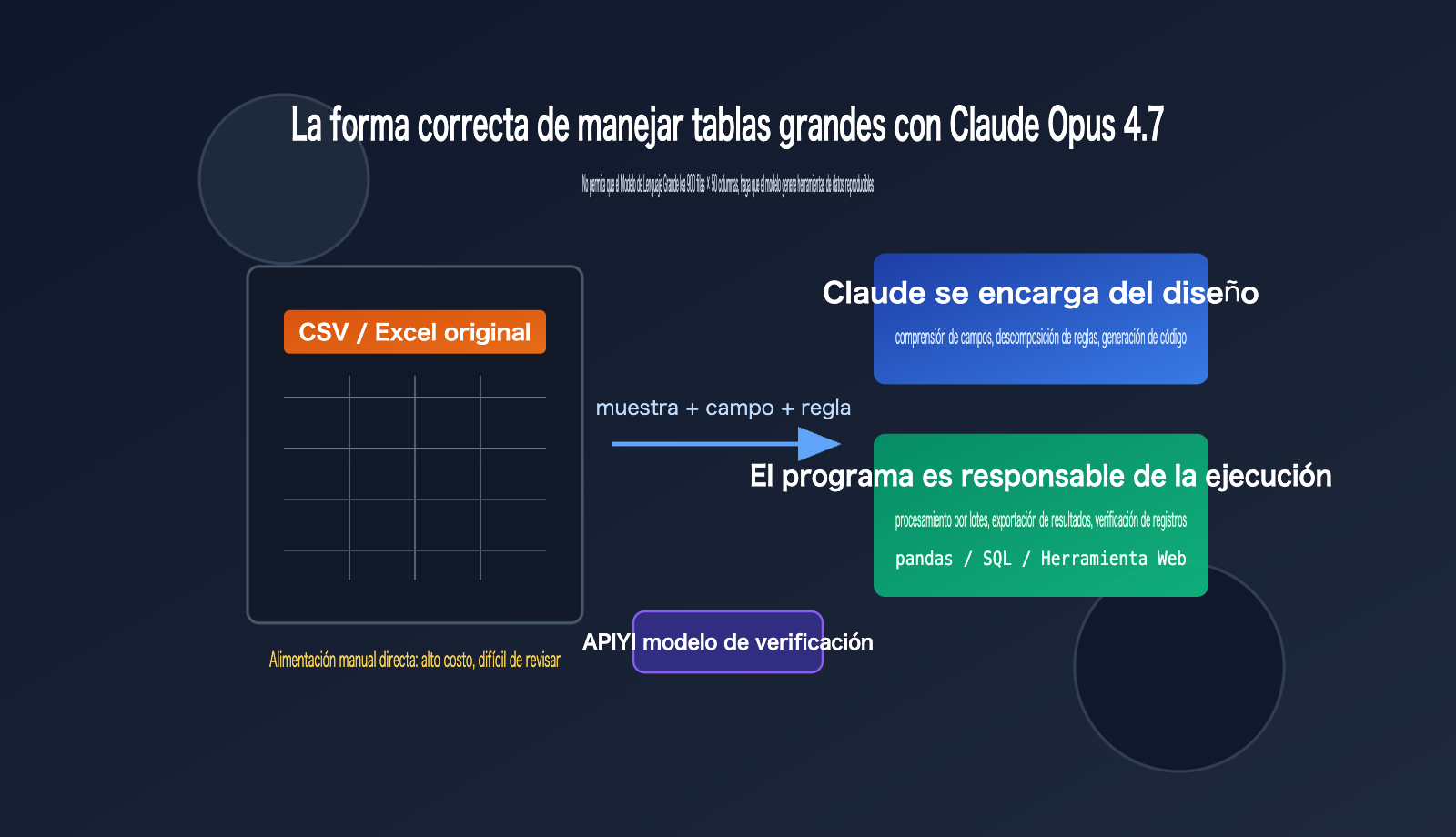
Si tienes un archivo CSV o Excel de más de 900 filas y 50 columnas y le preguntas directamente a Claude Opus 4.7: "Ayúdame a procesar esta tabla", lo más probable es que obtengas una respuesta que parece inteligente pero que no es reproducible. El problema no es que Claude Opus 4.7 no sea capaz, sino que lo estás tratando como a un lector de tablas humano en lugar de como a un diseñador de flujos de procesamiento de datos.
Un enfoque mejor es: proporciona a Claude Opus 4.7 una pequeña muestra de datos, una descripción completa de los campos y el resultado deseado. Pídele que escriba un script en Python, genere una herramienta web o diseñe un pipeline de datos reproducible, y luego usa ese script para procesar los datos completos. Esto permite aprovechar la capacidad de razonamiento y codificación del modelo, mientras dejas que el cálculo, el filtrado, la agregación y la validación los realice un programa determinista.
Puntos clave para procesar CSV con Claude Opus 4.7
Claude Opus 4.7 ya es un modelo muy potente para codificación y flujos de trabajo agentes, y la documentación oficial destaca su idoneidad para código complejo, flujos de trabajo empresariales y escenarios de hojas de cálculo. Pero una "ventana de contexto más grande" no significa que "debas volcar toda la tabla en la conversación", especialmente cuando los datos contienen muchas filas duplicadas, valores atípicos, columnas ocultas, formatos confusos y reglas de negocio. Alimentar manualmente los datos crudos es ineficiente y hace que los resultados sean difíciles de auditar.
El método realmente eficiente para procesar CSV con Claude Opus 4.7 consiste en situar al modelo en tres puntos: comprender el objetivo de negocio, generar el programa de procesamiento e interpretar los resultados. En cuanto a la lectura fila por fila, conversión de tipos, eliminación de duplicados, agregación, ordenamiento y exportación de archivos, esto debe dejarse en manos de Python, SQL, herramientas del lado del navegador o la cadena de herramientas de análisis de datos propia de Claude.
| Escenario | Problema de pedir a la IA que lea la tabla | Enfoque recomendado con Claude Opus 4.7 | Ventaja del resultado |
|---|---|---|---|
| CSV de 900 filas × 50 columnas | Alto consumo de contexto, riesgo de omitir columnas/filas | Proporcionar 20 filas de muestra y descripción de campos, pedir a Claude un script de pandas | Reproducible y ejecutable por lotes |
| Excel con varias hojas | Fórmulas ocultas, celdas combinadas y formatos afectan la comprensión | Pedir primero a Claude un script de detección de estructura, obtener una vista general del libro | Entender la estructura antes de procesar |
| Filtrado por reglas de negocio | El lenguaje natural suele omitir condiciones de contorno | Pedir a Claude que convierta las reglas en funciones y casos de prueba | Reglas claras y verificables |
| Generar informes | Las respuestas únicas son difíciles de revisar | Pedir a Claude que genere un script de exportación y un resumen de validación | Salida estable, fácil de entregar |
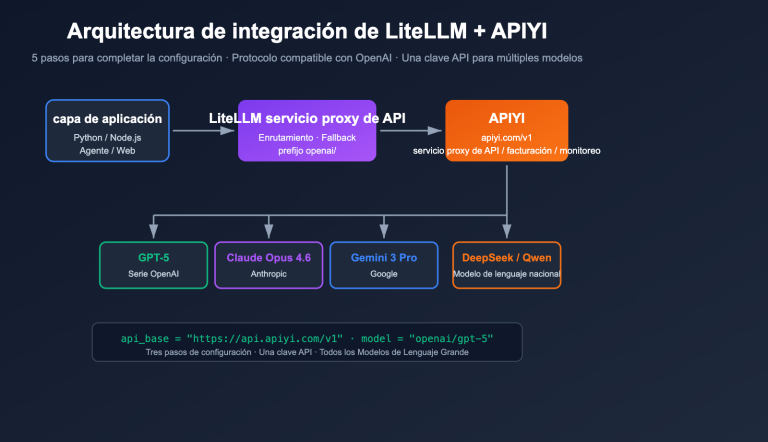
Aquí hay un juicio importante: Claude Opus 4.7 puede "participar en el análisis de datos", pero no debería ser el "único entorno de ejecución para los datos en sí". Si necesitas verificar repetidamente las indicaciones de procesamiento de datos o la selección de modelos a través de una API, recomendamos usar el servicio proxy de API APIYI (apiyi.com) para realizar pruebas con muestras pequeñas y luego consolidar las indicaciones estables en scripts, evitando tener que copiar tablas grandes cada vez.
Principios de división de tareas para procesar CSV con Claude Opus 4.7
Claude Opus 4.7 es más adecuado para juicios de alto nivel, como la inferencia del significado de los campos, el diseño de estrategias de limpieza, la sugerencia de casos excepcionales, la generación de código y la interpretación de resultados. No es adecuado para realizar cálculos deterministas en el cuadro de chat, ya que el texto de la tabla en la ventana de chat perderá parte de la información estructural y no es conveniente para ejecuciones repetidas o gestión de versiones.
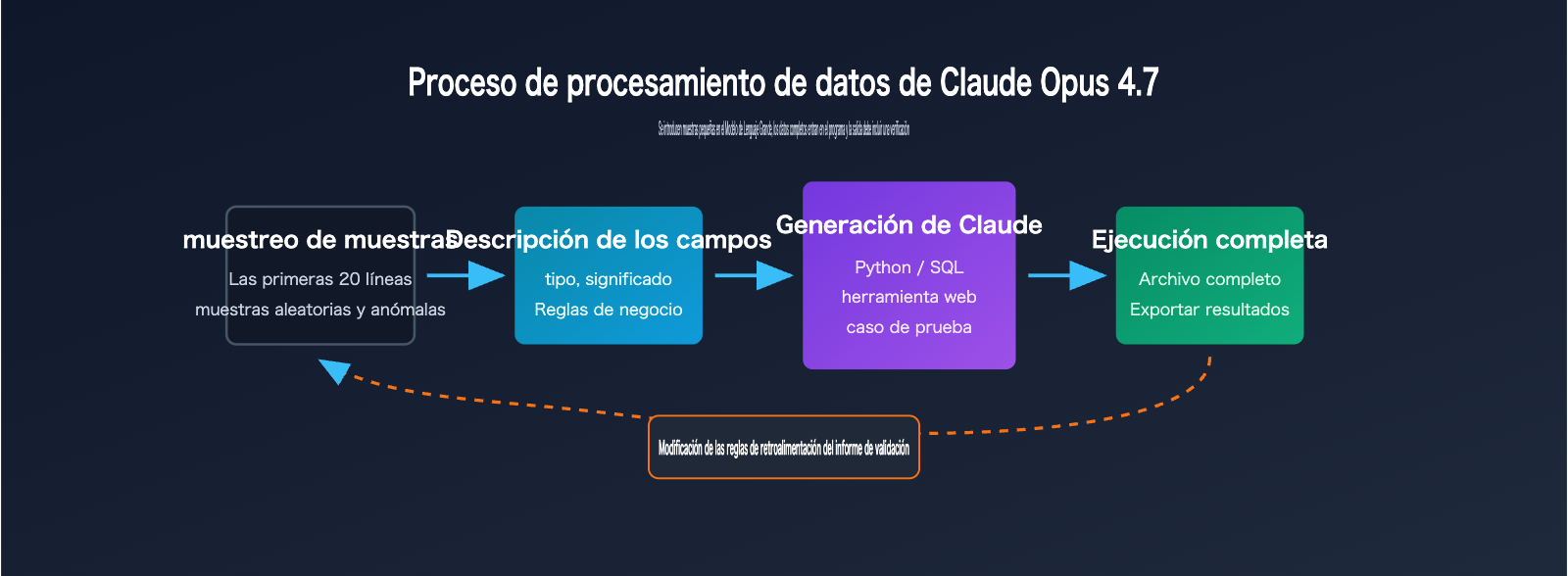
Un principio más sólido es "dar muestras pequeñas al modelo y datos grandes al programa". Puedes proporcionar primero 20 filas iniciales, 20 filas aleatorias y 20 filas con anomalías, además de un diccionario de campos y la salida deseada. Una vez que Claude Opus 4.7 genere el script basado en esta información, puedes ejecutar el script con el archivo CSV o Excel completo. De esta manera, el modelo se encarga del diseño y el programa se encarga de la ejecución.
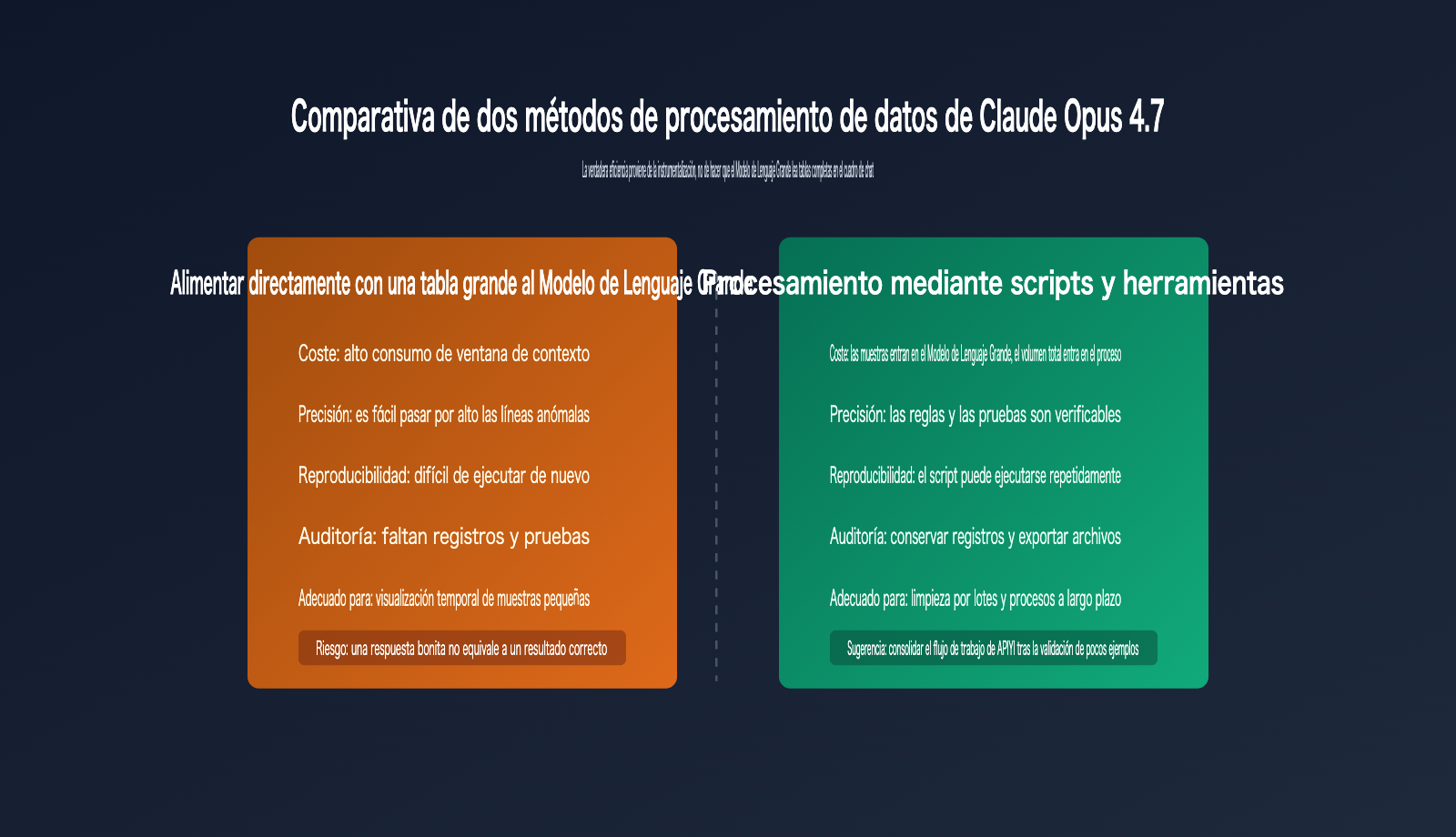
¿Por qué no deberías alimentar a Claude Opus 4.7 con tablas grandes de Excel directamente?
Aunque Excel y CSV parecen tablas, su complejidad es totalmente distinta. CSV es una estructura de filas y columnas de texto plano, mientras que Excel puede contener múltiples hojas, fórmulas, formatos, estados de filtro, columnas ocultas, celdas combinadas, series de fechas y formatos numéricos localizados. Al copiar y pegar Excel directamente como texto para la IA, generalmente se aplana esta información crítica, lo que provoca que el modelo no vea el libro de trabajo original, sino un texto plano distorsionado.
La documentación oficial en inglés indica que los productos relacionados con Claude ya admiten herramientas de análisis, ejecución de código, complementos de datos y capacidades para escenarios de Excel; estos puntos confirman un hecho: el procesamiento de tablas debe apoyarse en un entorno de herramientas, no solo en el "cálculo mental" del modelo de lenguaje dentro de la ventana de chat. Incluso si Claude Opus 4.7 admite una ventana de contexto más grande, esta debería aprovecharse para reglas de negocio, descripciones de campos, ejemplos de muestras y requisitos de validación, en lugar de desperdiciarla en las filas y columnas originales de toda la tabla.
| Característica de datos | Riesgo de subir/pegar directamente | Entrada recomendada para Claude Opus 4.7 | Herramienta de ejecución recomendada |
|---|---|---|---|
| Muchas columnas | El modelo difícilmente recuerda el significado de cada una | Diccionario de campos, tipos de columna, descripción de columnas clave | pandas, SQL |
| Muchas filas | Alto costo de tokens, resultados no reproducibles | Muestras de encabezado, muestras aleatorias, muestras de anomalías | Procesamiento por bloques en Python |
| Múltiples hojas | La relación entre hojas se pierde fácilmente | Resumen de estructura del libro, descripción del uso de las hojas | openpyxl, complemento de Excel |
| Datos sucios | Los valores atípicos afectan la inferencia | Estadísticas de valores faltantes, filas duplicadas, ejemplos de formato | Scripts de calidad de datos |
| Reglas complejas | La explicación en lenguaje natural tiende a desviarse | Reglas claras, contraejemplos, ejemplos de salida esperada | Pruebas unitarias, scripts de validación |
Consejo técnico: Si necesitas integrar Claude Opus 4.7 en un sistema de procesamiento de datos existente, puedes realizar una validación a nivel de interfaz a través de APIYI (apiyi.com). Se recomienda usar muestras pequeñas para probar la indicación, los parámetros del modelo y el manejo de errores antes de integrar la cadena completa de procesamiento de archivos.
Errores clave al procesar Excel con Claude Opus 4.7
El primer error es interpretar que "el modelo puede entender tablas" como "el modelo debe procesar tablas grandes directamente". En archivos pequeños, análisis temporales y preguntas exploratorias, subir un CSV o Excel es muy cómodo; pero en tareas como limpieza por lotes, calificación de listas de clientes, conciliación de pedidos o clasificación financiera, lo que realmente necesitas son reglas ejecutables y repetibles, no respuestas únicas en lenguaje natural.
El segundo error es proporcionar solo las primeras 20 filas como muestra. Las primeras 20 filas suelen mostrar solo la estructura normal y no cubren situaciones excepcionales. Una mejor combinación de muestras es "primeras 20 filas + 20 filas aleatorias + 20 filas de anomalías + diccionario de campos + 3 filas de salida objetivo"; de esta manera, Claude Opus 4.7 podrá escribir una lógica de procesamiento mucho más cercana a la realidad del negocio.
Flujo de trabajo de 5 pasos para procesar CSV con Claude Opus 4.7
Este flujo es adecuado para la mayoría de las tareas de automatización de CSV y Excel, especialmente para escenarios con más de 500 filas, más de 20 columnas y reglas que requieren ajustes frecuentes. No necesitas entregar el archivo completo al modelo desde el principio; basta con dejar claros los ejemplos, la estructura y los objetivos, y luego pedirle que genere scripts, pruebas y explicaciones de salida.
| Paso | Material para Claude Opus 4.7 | Contenido que Claude debe generar | Puntos que el humano debe confirmar |
|---|---|---|---|
| 1. Detección de estructura | Formato de archivo, nombres de campos, filas de muestra | Suposiciones de tipos de campo y plan de limpieza | ¿Es correcto el significado de los campos? |
| 2. Definición de reglas | Objetivos de negocio, condiciones de filtro, contraejemplos | Tabla de reglas de procesamiento y condiciones de borde | ¿Cubre las excepciones del negocio? |
| 3. Generación de scripts | Datos de muestra, formato de salida objetivo | Script de procesamiento en Python o SQL | ¿Se puede ejecutar localmente? |
| 4. Validación de muestra pequeña | Muestras de 20 a 60 filas | Salida esperada y aserciones de prueba | ¿La salida es intuitiva? |
| 5. Ejecución completa | Ruta del archivo completo | Archivo de resultados, registros, informe de validación | ¿Están alineados los totales, montos y grupos? |
El valor central de este flujo es convertir una "pregunta única" en un "activo ejecutable". Cuando las reglas de negocio cambian, solo necesitas pedirle a Claude Opus 4.7 que modifique el script y las pruebas, sin necesidad de volver a subir los datos completos, reexplicar el contexto o arriesgarse a ver si el modelo recordó todos los detalles.
Plantilla de indicación para procesar CSV con Claude Opus 4.7
Puedes reutilizar directamente la siguiente estructura de indicación. Ten en cuenta que no debes pegar solo el contenido del CSV, sino también especificar el significado de los campos, los objetivos de procesamiento, las muestras de anomalías y los criterios de aceptación. Cuanto más claro tenga el modelo "qué se considera correcto", más estable será el script generado.
Tengo una tarea de procesamiento de datos CSV/Excel, por favor no des una conclusión directamente.
Objetivo:
Calificar la tabla de clientes según industria, cargo y tamaño de la empresa, y generar los leads principales.
Muestras de datos:
1. Primeras 20 filas: ...
2. 20 filas aleatorias: ...
3. 20 filas de anomalías: ...
Descripción de campos:
- company_name: nombre de la empresa
- title: cargo del contacto
- employee_count: número de empleados, puede estar vacío
- industry: industria, puede haber sinónimos
Por favor, completa lo siguiente:
1. Primero explica los campos y los posibles problemas de calidad de los datos
2. Escribe un script de Python para leer input.csv
3. Genera cleaned.csv y scored.csv
4. Añade validaciones básicas: conteo de filas, valores nulos, valores duplicados, distribución de puntuación
5. No asumas significados de campos desconocidos; si encuentras reglas inciertas, márcalas primero como TODO
Si deseas convertir este flujo en un servicio de API, puedes usar la plantilla de indicación, el diccionario de campos y los datos de muestra como entradas fijas, y llamar a Claude Opus 4.7 u otros modelos disponibles a través de APIYI (apiyi.com) para realizar pruebas comparativas. Esto permite evaluar rápidamente las diferencias entre modelos en cuanto a generación de código, interpretación de reglas y manejo de anomalías.
Ejemplo de Python para procesar CSV con Claude Opus 4.7
A continuación, se muestra una versión minimalista que refleja el enfoque correcto: Claude Opus 4.7 escribe el script, el script lee el archivo completo y genera resultados y un resumen de validación. En proyectos reales, se pueden añadir registros (logs), manejo de excepciones, pruebas unitarias y archivos de configuración.
import pandas as pd
INPUT = "input.csv"
OUTPUT = "scored.csv"
df = pd.read_csv(INPUT)
required = ["company_name", "title", "employee_count", "industry"]
missing = [col for col in required if col not in df.columns]
if missing:
raise ValueError(f"Columnas faltantes: {missing}")
df["employee_count"] = pd.to_numeric(df["employee_count"], errors="coerce").fillna(0)
df["score"] = 0
df.loc[df["title"].str.contains("cto|chief|founder", case=False, na=False), "score"] += 40
df.loc[df["employee_count"].between(50, 500), "score"] += 30
df.loc[df["industry"].str.contains("ai|software|saas", case=False, na=False), "score"] += 30
print({"filas": len(df), "duplicados": int(df.duplicated().sum())})
df.sort_values("score", ascending=False).to_csv(OUTPUT, index=False)
Si además necesitas que el modelo explique los resultados, puedes pedirle que genere un summary.json y luego entregarle ese resumen a Claude Opus 4.7. Para tareas de automatización de múltiples pasos, se recomienda gestionar las invocaciones del modelo, los reintentos ante fallos y el almacenamiento de registros de forma unificada a través de APIYI (apiyi.com), facilitando así el mantenimiento de la cadena de procesamiento de datos.
Selección de herramientas de Claude Opus 4.7 para procesar Excel
Cada tarea requiere una herramienta distinta. Para exploraciones rápidas, puedes usar la capacidad de análisis de Claude o sus complementos de datos; sin embargo, para flujos de trabajo de producción, es mejor optar por scripts de Python, tuberías SQL o herramientas web. Si en tu equipo hay compañeros que no son técnicos, puedes pedirle a Claude Opus 4.7 que genere una herramienta web local que convierta la carga de archivos, la selección de reglas y la descarga de resultados en una interfaz visual.
| Solución de herramientas | Tareas adecuadas | Tareas no recomendadas | Uso recomendado |
|---|---|---|---|
| Script de Python | Limpieza masiva, puntuación, conciliación, exportación | Equipos que no conocen la línea de comandos | Pedir a Claude que escriba el script y el README |
| Herramienta web local | Personal no técnico que procesa archivos similares | Permisos de backend complejos y colaboración multiusuario | Pedir a Claude que genere HTML/JS o un servicio ligero |
| Tubería SQL | Almacenes de datos, pedidos, análisis de logs | Tablas pequeñas de Excel temporales | Pedir a Claude que escriba consultas y SQL de validación |
| Herramientas de datos de Claude | Análisis exploratorio, gráficos, informes temporales | Tareas de alta conformidad o automatización a largo plazo | Explorar primero, luego convertir en script |
| Flujo de trabajo API | Comparación de modelos, integración de sistemas automatizados | Tareas manuales de una sola vez | Depurar mediante una interfaz unificada |
Ideas para herramientas web de procesamiento de Excel con Claude Opus 4.7
Cuando el usuario no sabe Python, "pedirle a Claude que escriba una herramienta web" suele ser más práctico que "pedirle a Claude que lea un CSV directamente". Una herramienta web puede ofrecer botones de carga, mapeo de campos, configuración de reglas, vista previa de resultados y botones de descarga; así, el usuario solo necesita cambiar el archivo cada vez, sin tener que dialogar repetidamente con la IA.
Puedes pedirle a Claude Opus 4.7 lo siguiente: genera una herramienta HTML de un solo archivo que utilice Papa Parse para leer CSV, que realice el mapeo de campos y la puntuación en el frontend, y que finalmente exporte un nuevo CSV. Para tareas con volúmenes de datos pequeños, reglas no confidenciales y que solo se ejecutan en el navegador local, este método es muy económico; para tareas que requieran permisos más complejos, auditoría o archivos grandes, se debe escalar a un servicio de backend.
Consejo de implementación: Si deseas integrar la herramienta web con la interpretación de modelos, sugerencias de mapeo de campos o diagnóstico de anomalías, puedes invocar la interfaz del modelo a través de APIYI (apiyi.com), dejando que el frontend se encargue solo de la interacción y el backend de las solicitudes al modelo y el registro de logs.
Lista de verificación para el procesamiento de CSV con Claude Opus 4.7
Lo que más preocupa en el procesamiento de datos no es que el código arroje un error, sino que produzca resultados incorrectos silenciosamente. Por lo tanto, independientemente de si le pides a Claude Opus 4.7 que escriba Python, SQL o una herramienta web, debes solicitarle que genere simultáneamente una lista de verificación. Esta lista no necesita ser compleja, pero debe cubrir el número de filas, campos, valores nulos, valores duplicados, indicadores clave y revisiones por muestreo.
| Elemento de verificación | Por qué es importante | Método de comprobación recomendado | Sugerencia de manejo de errores |
|---|---|---|---|
| Filas de entrada/salida | Evita eliminaciones accidentales o duplicados | Comparar len(input) y len(output) |
Explicar la diferencia en la salida |
| Campos obligatorios | Evita errores de cálculo por cambios en nombres | Comprobar el conjunto de columnas | Error inmediato si falta un campo |
| Proporción de nulos | Evita sesgos en puntuación o clasificación | Estadísticas de nulos por columna | Escribir advertencia si supera el umbral |
| Registros duplicados | Evita cobros o contactos repetidos | Eliminar duplicados por clave primaria o compuesta | Conservar informe de duplicados |
| Suma de importes y cantidades | Evita errores en la lógica de agregación | Comparar sumas antes y después del grupo | Terminar si hay inconsistencias |
| Revisión por muestreo | Detecta sesgos en la comprensión de reglas | Extraer aleatoriamente 20 filas para revisión manual | Retroalimentar a Claude para ajustar reglas |
En la práctica, puedes incluir esta tabla directamente como parte de tu indicación para que Claude Opus 4.7 añada automáticamente las comprobaciones correspondientes al generar el script. Cuando realizamos pruebas de invocación de modelos en APIYI (apiyi.com), también sugerimos establecer la salida de validación como un requisito fijo; esto facilita la comparación de la estabilidad entre diferentes modelos, en lugar de fijarse solo en si una respuesta puntual parece "bonita".
Indicaciones contraproducentes para el procesamiento de CSV con Claude Opus 4.7
No digas simplemente "ayúdame a limpiar esta tabla". Es mejor decir: "Por favor, indica primero qué información de los campos necesitas antes de escribir el script; no des una conclusión directa; registra logs en cada paso; marca con TODO las reglas que no puedas determinar; genera 5 ejemplos de pruebas unitarias". Este tipo de restricciones obligan al modelo a hacer explícitas sus inferencias implícitas y te permiten descubrir más rápido si ha malinterpretado el negocio.
Del mismo modo, no consideres las primeras 20 filas de muestra como la verdad absoluta. Las primeras 20 filas sirven para que Claude Opus 4.7 entienda la estructura, pero no son suficientes para cubrir datos sucios. Debes proporcionar muestras adicionales con anomalías, como valores nulos, duplicados, formatos de fecha confusos, importes negativos, inconsistencias en la ortografía de valores enumerados o mezclas de chino e inglés.
Preguntas frecuentes sobre el procesamiento de CSV con Claude Opus 4.7
¿Son suficientes las primeras 20 filas de muestra para que Claude Opus 4.7 procese un CSV?
No son suficientes, aunque son un buen punto de partida. Las primeras 20 filas sirven para mostrar la estructura de los campos y los registros normales, pero no cubren los datos anómalos. Es mucho más recomendable utilizar una combinación de "20 filas iniciales + 20 filas aleatorias + 20 filas con anomalías". Una vez que le proporciones la muestra a Claude Opus 4.7, pídele que redacte un script para procesar el archivo completo, en lugar de que intente sacar conclusiones basándose únicamente en la muestra.
¿Debo subir el archivo completo cuando Claude Opus 4.7 procesa un Excel?
Si se trata de una exploración puntual, puedes subir el archivo y usar las herramientas de análisis. Sin embargo, si buscas un flujo de trabajo que se reutilice a largo plazo, lo ideal es pedirle a Claude Opus 4.7 que primero escriba un script de detección de estructura y, posteriormente, genere el script de procesamiento. Para escenarios de automatización mediante API, puedes usar APIYI (apiyi.com) para probar con muestras pequeñas y confirmar que el Modelo de Lenguaje Grande comprende correctamente los campos y las reglas antes de integrar el flujo completo.
¿La ventana de contexto de 1M de Claude Opus 4.7 hace innecesarios los scripts al procesar CSV?
No. Una ventana de contexto más amplia permite incluir más descripciones de campos, muestras y contexto de negocio, pero no puede reemplazar a un programa de cálculo reproducible. Especialmente cuando se trata de importes, rankings, agrupaciones, eliminación de duplicados o criterios estadísticos, los scripts y las validaciones son la base para obtener resultados fiables.
¿Qué diferencia hay entre procesar Excel con Claude Opus 4.7 y usar BI tradicional?
Claude Opus 4.7 es mejor para convertir requisitos ambiguos en reglas, código y explicaciones, mientras que el BI tradicional es más adecuado para informes estables, gestión de permisos, modelado de datos y colaboración entre varios usuarios. Ambos no son excluyentes: puedes usar Claude para generar scripts de limpieza y lógica de análisis, y luego integrar los resultados estables en tu plataforma de BI o almacén de datos.
Si no tengo conocimientos de programación, ¿vale la pena usar Claude Opus 4.7 para procesar CSV?
Vale la pena, pero te sugiero que le pidas que genere herramientas web locales o instrucciones detalladas, en lugar de esperar que te dé el resultado final directamente en el chat. Puedes pedirle que convierta la lógica de procesamiento en botones, formularios y funciones de descarga, de modo que tú solo te encargues de subir el archivo y verificar los resultados. Cuando necesites interfaces de modelos, puedes usar APIYI (apiyi.com) para probar rápidamente la efectividad de la generación de código de diferentes modelos.
¿Qué debo tener en cuenta al procesar archivos Excel sensibles con Claude Opus 4.7?
Los datos sensibles deben anonimizarse primero o procesarse en entornos controlados. No envíes documentos de identidad, números de teléfono, contratos de clientes o detalles financieros sin tratar a entornos inciertos. La práctica más segura es proporcionar muestras anonimizadas y la estructura de los campos, dejar que Claude escriba el script y luego ejecutar el procesamiento de datos completo de forma local o en un entorno corporativo.
Puntos clave sobre el procesamiento de CSV con Claude Opus 4.7
- La mejor forma de trabajar con CSV en Claude Opus 4.7 no es leer la tabla completa directamente, sino generar scripts ejecutables basados en muestras y reglas.
- Las primeras 20 filas solo ayudan al modelo a entender la estructura; para tareas reales, se necesitan muestras aleatorias, muestras con anomalías y un diccionario de campos.
- Excel es más complejo que CSV: las múltiples hojas, fórmulas, columnas ocultas y formatos pueden afectar los resultados, por lo que primero se debe realizar una detección de estructura.
- Para tareas por lotes, Python, SQL o herramientas web locales son más reproducibles que una respuesta única en la ventana de chat.
- Se debe generar una lista de verificación junto con el script de procesamiento, enfocándose en comprobar el número de filas, campos, valores nulos, duplicados y totales clave.
- Para escenarios de automatización de API, se recomienda realizar pruebas con muestras pequeñas antes de integrar la solución estable en el flujo de producción.
Recomendaciones para procesar Excel con Claude Opus 4.7
Claude Opus 4.7 es excelente para tareas de datos, pero la forma correcta de aprovecharlo no es simplemente "lanzarle la tabla a la IA", sino "pedirle a la IA que diseñe herramientas para procesar la tabla". Cuando el volumen de datos alcanza cientos de filas y decenas de columnas, o cuando las reglas de negocio requieren ser reutilizadas, los scripts, las herramientas web, los pipelines de SQL y los informes de validación resultan ser opciones mucho más eficientes.
Puedes ver a Claude Opus 4.7 como un asistente de ingeniería de datos: deja que analice muestras pequeñas, aclara las reglas, solicita la creación de scripts de procesamiento, genera pruebas y pide explicaciones sobre los resultados. De esta manera, conservas la ventaja del Modelo de Lenguaje Grande para entender la semántica del negocio, al tiempo que evitas la ineficiencia y la falta de trazabilidad que conlleva alimentar directamente los datos crudos.
Si estás trabajando en desarrollos relacionados con Claude Opus 4.7, CSV, Excel o automatización de datos, te recomiendo usar primero APIYI (apiyi.com) para la invocación del modelo y la validación de la indicación, y luego consolidar los flujos estables en scripts o herramientas. Esto permite un control de costos más preciso y hace que los resultados sean más fáciles de revisar por el equipo y de mantener a largo plazo.
Referencias:
- Anthropic Claude Opus 4.7: anthropic.com/claude/opus
- Guía de uso de Claude Opus 4.7: claude.com/resources/tutorials/working-with-claude-opus-4-7
- Herramienta de ejecución de código de Claude: platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool
- Plugin de datos de Claude: claude.com/plugins/data