title: "Análisis profundo de MiniMax-M2.7: Rendimiento de nivel Tier-1 a una fracción del coste"
description: "Descubre cómo MiniMax-M2.7 utiliza 10B de parámetros activos para igualar a GPT-5 y Claude Opus, ofreciendo una eficiencia sin precedentes."
Nota del autor: Análisis detallado de las capacidades principales, puntos de referencia de rendimiento y métodos de integración API para los modelos MiniMax-M2.7 y M2.7-highspeed, diseñados para ayudar a los desarrolladores a obtener capacidades de IA de nivel insignia a un coste extremadamente bajo.
MiniMax lanzó el 18 de marzo de 2026 el modelo de lenguaje grande insignia MiniMax-M2.7, el primer modelo de IA que participa profundamente en su propio proceso de evolución. Con solo 10B de parámetros activos, ha alcanzado un rendimiento de nivel Tier-1, equiparable a Claude Opus 4.6 y GPT-5, manteniendo un precio 50 veces menor que los modelos insignia convencionales. La versión lanzada simultáneamente, MiniMax-M2.7-highspeed, aumenta la velocidad de salida en un 66%, alcanzando los 100 tps.
Valor central: A través de datos de referencia reales y tutoriales de integración, te ayudamos a determinar si MiniMax-M2.7 es la opción de modelo insignia con la mejor relación calidad-precio en la actualidad.

Puntos clave de MiniMax-M2.7
| Punto | Descripción | Valor |
|---|---|---|
| 230B total / 10B activos | Arquitectura de mezcla de expertos (MoE), activa solo 10B por inferencia | Rendimiento insignia + coste de inferencia bajísimo |
| Entrenamiento de autoevolución recursiva | El modelo ejecuta de forma autónoma más de 100 rondas de iteración para optimizar su propio entrenamiento | Mejora del 30% en rendimiento sin intervención humana |
| SWE-bench 78% | Supera significativamente el 55% de Opus 4.6 en el benchmark de ingeniería de software | La mejor opción para tareas de programación e ingeniería |
| Precio 1/50 de Opus | $0.30/M entrada, $1.20/M tokens salida | Reducción drástica de costes para despliegues empresariales a gran escala |
Detalles de la arquitectura técnica de MiniMax-M2.7
MiniMax-M2.7 utiliza una arquitectura Transformer de mezcla de expertos dispersa (Sparse Mixture-of-Experts), con un total de 230B de parámetros, pero activando solo 10B por token. Este diseño convierte a M2.7 en el modelo más compacto de su nivel de rendimiento, logrando un desempeño Tier-1 equivalente a Claude Opus 4.6 y GPT-5 con recursos computacionales mínimos.
Su ventana de contexto alcanza los 205K tokens (aprox. 307 páginas de documentos A4), lo que permite el análisis de documentos extensos y la comprensión de bases de código masivas. En la evaluación de Artificial Intelligence Index de Artificial Analysis, M2.7 obtuvo una puntuación perfecta de 50, situándose en el primer puesto entre 136 modelos de su categoría.
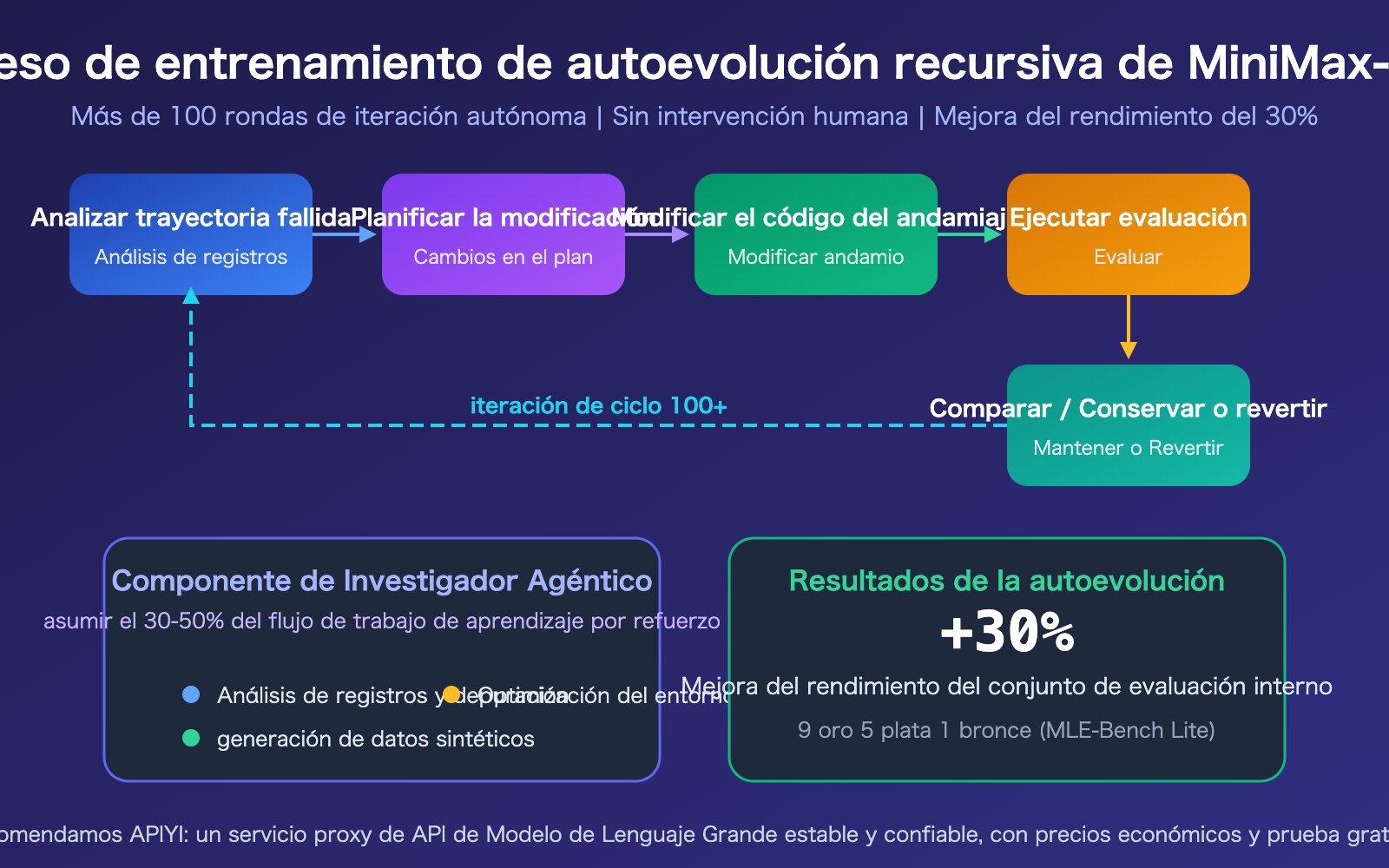
Mecanismo de autoevolución recursiva de MiniMax-M2.7
La "autoevolución recursiva" es el avance técnico más disruptivo de M2.7. Durante el entrenamiento, el modelo ejecuta de forma autónoma un ciclo iterativo completo: análisis de trayectorias fallidas → planificación de modificaciones → edición del código de andamiaje de entrenamiento → ejecución de evaluaciones → comparación de resultados → decisión de conservar o revertir. Este proceso se ejecutó de forma totalmente autónoma durante más de 100 rondas.
Su componente central, el "Investigador Agéntico" (Agentic Researcher), asumió entre el 30% y el 50% del flujo de trabajo de aprendizaje por refuerzo, incluyendo análisis de registros y depuración, generación de datos sintéticos y optimización del entorno de entrenamiento. Esto resultó en una mejora del rendimiento del 30% sin intervención humana.
Rendimiento y comparativa del modelo MiniMax-M2.7
Resultados de las pruebas de referencia de MiniMax-M2.7
| Prueba de referencia | Puntuación M2.7 | Claude Opus 4.6 | Serie GPT-5 | Notas |
|---|---|---|---|---|
| SWE-bench Verified | 78% | 55% | — | Práctica de ingeniería de software, ventaja significativa |
| SWE-Pro | 56.2% | ~57% | 56.2% (Codex) | Nivel cercano a los modelos insignia |
| VIBE-Pro | 55.6% | — | — | Entrega de proyectos de extremo a extremo |
| Terminal Bench 2 | 57.0% | — | — | Sistemas de ingeniería complejos |
| MLE-Bench Lite | 66.6% | 75.7% | 71.2% (5.4) | Competiciones de ML, 9 oros, 5 platas, 1 bronce |
| GDPval-AA ELO | 1495 | — | — | Líder en productividad de oficina |
Comparativa de precios de MiniMax-M2.7
La estrategia de precios de M2.7 es extremadamente competitiva; con un rendimiento prácticamente equivalente, el coste es solo una fracción de los modelos insignia convencionales:
| Métrica | MiniMax-M2.7 | Claude Opus 4.6 | GPT-5 | Diferencia de factor |
|---|---|---|---|---|
| Precio de entrada | $0.30/M | $15/M | $10/M | 50x / 33x más barato |
| Precio de salida | $1.20/M | $75/M | $30/M | 62x / 25x más barato |
| Ventana de contexto | 205K | 1M | 128K | Entre ambos |
| Parámetros activos | 10B | — | — | El modelo Tier-1 más pequeño |
🎯 Recomendación de elección: MiniMax-M2.7 destaca en tareas de programación e ingeniería con una relación calidad-precio excepcional. Recomendamos realizar pruebas de integración rápida a través de la plataforma APIYI apiyi.com, la cual permite la invocación unificada tanto para MiniMax-M2.7 como para M2.7-highspeed, facilitando comparativas reales con otros modelos insignia.
Análisis detallado de MiniMax-M2.7-highspeed
MiniMax-M2.7-highspeed es la versión optimizada en rendimiento de la serie insignia M2.7. Ofrece resultados idénticos a la versión estándar (ambos poseen el mismo nivel de inteligencia), pero la versión highspeed está diseñada específicamente para escenarios de aplicación sensibles a la latencia.
Ventajas clave de MiniMax-M2.7-highspeed
- Velocidad de salida: Alcanza los 100 tokens/s, un 66% más rápido que la versión estándar.
- Latencia sub-segundo: Se ha optimizado el tiempo de respuesta del primer token, ideal para interacciones en tiempo real.
- Arquitectura de motor de inferencia mejorada: El motor de inferencia subyacente está optimizado específicamente, no se trata simplemente de una degradación por cuantización.
- Consistencia de resultados: Produce resultados exactamente iguales a la versión estándar, sin sacrificar el nivel de inteligencia.
Escenarios de aplicación para MiniMax-M2.7-highspeed
| Escenario | Descripción | ¿Por qué elegir highspeed? |
|---|---|---|
| Asistente de programación interactivo | Autocompletado y refactorización de código en tiempo real en el IDE | Respuesta en menos de un segundo que mejora la experiencia de codificación |
| Bucle de agentes en tiempo real | Ejecución de razonamiento en múltiples pasos del Agent Loop | Reduce el tiempo de espera en cada paso, acelerando el flujo general |
| Flujos de trabajo empresariales de alto rendimiento | Procesamiento de documentos por lotes, extracción de datos | 100 tps que reducen drásticamente el tiempo de finalización |
| Sistemas de atención al cliente en línea | Diálogo y resolución de dudas en tiempo real | Respuesta rápida que el usuario percibe como instantánea |
Sugerencia: Si tu aplicación tiene requisitos estrictos de velocidad de respuesta, MiniMax-M2.7-highspeed es una de las opciones más rápidas entre los modelos de nivel insignia actuales. Puedes invocar este modelo directamente a través de APIYI apiyi.com.
Inicio rápido con la API de MiniMax-M2.7
Ejemplo minimalista
A continuación, tienes el código más sencillo para invocar a MiniMax-M2.7 a través de la plataforma APIYI; funciona con solo 10 líneas:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.7",
messages=[{"role": "user", "content": "Analiza los cuellos de botella de rendimiento de este código y da sugerencias de optimización"}]
)
print(response.choices[0].message.content)
Ver código de implementación completo (incluye cambio a versión highspeed)
import openai
from typing import Optional
def call_minimax_m27(
prompt: str,
model: str = "MiniMax-M2.7",
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
use_highspeed: bool = False
) -> str:
"""
Invoca a MiniMax-M2.7 o M2.7-highspeed
Args:
prompt: Entrada del usuario
model: Nombre del modelo
system_prompt: Indicación del sistema
max_tokens: Número máximo de tokens de salida
use_highspeed: Si se debe usar la versión highspeed
"""
if use_highspeed:
model = "MiniMax-M2.7-highspeed"
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
# Invocación de la versión estándar
result = call_minimax_m27(
prompt="Implementa un caché LRU eficiente en Python",
system_prompt="Eres un ingeniero senior de Python"
)
# Invocación de la versión highspeed (ideal para escenarios en tiempo real)
fast_result = call_minimax_m27(
prompt="Explica rápidamente la función de este código",
use_highspeed=True
)
Sugerencia: Obtén saldo de prueba gratuito a través de APIYI (apiyi.com) para verificar rápidamente el rendimiento de MiniMax-M2.7 en tus casos de uso. La plataforma permite cambiar entre la versión estándar y la highspeed con un solo clic.
Comparativa de MiniMax-M2.7 frente a modelos de la competencia

| Solución | Características principales | Escenarios de uso | Relación calidad-precio |
|---|---|---|---|
| MiniMax-M2.7 | 10B parámetros activos, 78% en SWE-bench | Programación, flujos de trabajo de agentes, despliegue a gran escala | Muy alta ($0.30/$1.20) |
| M2.7-highspeed | 100 tps, 66% de mejora en velocidad | Interacción en tiempo real, integración IDE, bucles de agentes | Muy alta + Rápido |
| Claude Opus 4.6 | 1M ventana de contexto, capacidad integral superior | Documentos ultralargos, razonamiento complejo, tareas generales | Media ($15/$75) |
| GPT-5 | Ecosistema maduro, soporte multimodal | Escenarios generales, aplicaciones multimodales | Media ($10/$30) |
Nota sobre la comparativa: Los datos anteriores provienen de pruebas de referencia oficiales y evaluaciones de terceros de Artificial Analysis; puedes realizar una verificación comparativa real a través de la plataforma APIYI (apiyi.com).
Preguntas frecuentes
Q1: ¿Hay alguna diferencia en los resultados entre MiniMax-M2.7 y M2.7-highspeed?
Ambos ofrecen resultados idénticos. La versión highspeed optimiza el motor de inferencia para lograr una mayor velocidad de generación de tokens (100 tps), pero no altera la inteligencia ni la calidad de salida del modelo. Si tu caso de uso no es sensible a la latencia, la versión estándar es suficiente.
Q2: ¿La «autoevolución recursiva» de MiniMax-M2.7 significa que el modelo cambiará continuamente?
No. La autoevolución recursiva es una técnica que MiniMax emplea durante la fase de entrenamiento: el modelo optimizó de forma autónoma su propio proceso de entrenamiento y sus parámetros. Una vez publicado, los pesos del modelo son fijos. La API que invocas siempre ofrecerá resultados estables y consistentes.
Q3: ¿Cómo puedo empezar a probar MiniMax-M2.7 rápidamente?
Recomendamos utilizar una plataforma de agregación de API que soporte múltiples modelos para realizar pruebas:
- Visita APIYI en apiyi.com para registrar una cuenta.
- Obtén tu clave API y saldo gratuito.
- Utiliza los ejemplos de código de este artículo para una verificación rápida.
- Cambia el parámetro
modelpara alternar entre la versión estándar y la versión highspeed.
Resumen
Puntos clave sobre la invocación de la API de MiniMax-M2.7:
- Relación calidad-precio extrema: Con 10B de parámetros activos alcanza un rendimiento de nivel 1 (Tier-1), con un costo de apenas 1/50 del de Opus, lo que la convierte en la opción preferida para despliegues a gran escala.
- Capacidad de programación destacada: Con un 78% en SWE-bench Verified, supera ampliamente a la competencia, ofreciendo un desempeño excelente en tareas de ingeniería de software.
- Versión highspeed: Su velocidad de salida de 100 tps es ideal para interacciones en tiempo real y escenarios de bucles de agentes, manteniendo el mismo nivel de inteligencia que la versión estándar.
Para desarrolladores y usuarios empresariales que buscan la mejor relación costo-beneficio, MiniMax-M2.7 es uno de los modelos insignia más interesantes del mercado actual.
Te recomendamos verificar sus capacidades a través de APIYI en apiyi.com, donde la plataforma ofrece saldo gratuito, una interfaz unificada para múltiples modelos y soporte para cambiar entre la versión estándar y highspeed de MiniMax-M2.7 con un solo clic.
📚 Referencias
-
Lanzamiento oficial de MiniMax M2.7: Detalles sobre la arquitectura del modelo y tecnología de autoevolución
- Enlace:
minimax.io/news/minimax-m27-en - Descripción: Blog técnico oficial que incluye pruebas de referencia y detalles de la arquitectura.
- Enlace:
-
Página del modelo MiniMax M2.7: Especificaciones técnicas y documentación de la API
- Enlace:
minimax.io/models/text/m27 - Descripción: Parámetros del modelo, precios y métodos de acceso.
- Enlace:
-
Evaluación de Artificial Analysis: Evaluación de rendimiento independiente de terceros
- Enlace:
artificialanalysis.ai/models/minimax-m2-7 - Descripción: Datos de evaluación independientes sobre velocidad e índice de inteligencia.
- Enlace:
-
Documentación de la plataforma APIYI: Acceso rápido a MiniMax-M2.7
- Enlace:
docs.apiyi.com - Descripción: Obtención de clave API, lista de modelos y ejemplos de invocación del modelo.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com.