layout: post
title: "Explicación detallada: Por qué los tokens de salida de Gemini 3.1 Pro Preview superan con creces el texto visible – Mecanismo de cadena de razonamiento Thinking Tokens, reglas de facturación y técnicas para ahorrar dinero ajustando thinking_level"
description: "Descubre por qué una respuesta corta de Gemini 3.1 Pro puede costar cientos de tokens. Explicamos el mecanismo de Thinking Tokens, cómo se factura y cómo usar el parámetro thinking_level para ahorrar hastaFX 80% en costos."
author: APIYI
categories: [AI, Google Gemini, Cost Optimization]
tags: [Gemini 3.1 Pro, Thinking Tokens, Modelo de Lenguaje Grande, API Costos, Optimización]
image: /assets/images/gemini-thinking-tokens-cover.png
date: 2024-12-12
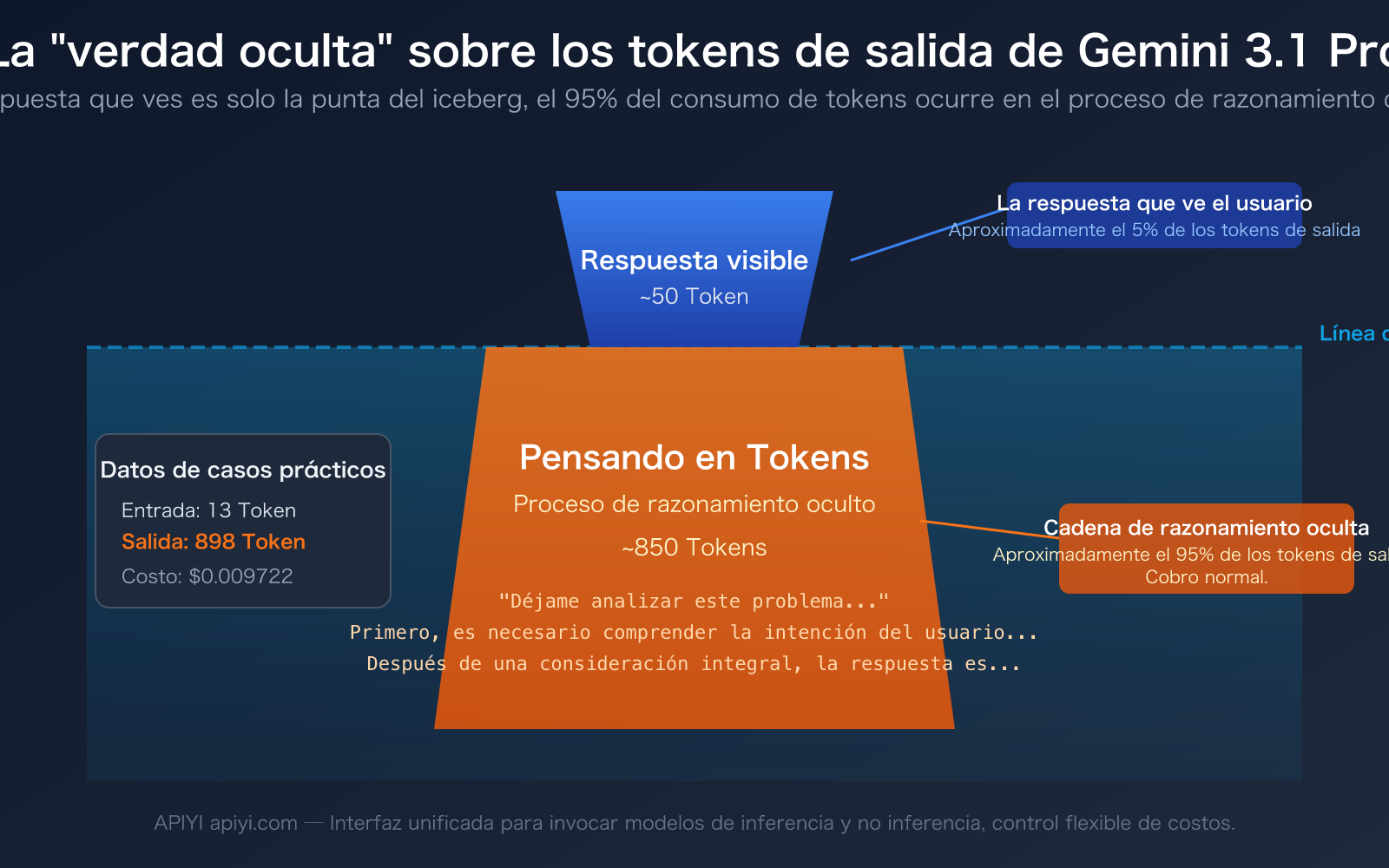
"¡Solo envié una frase y el modelo respondió con una docena de palabras! ¿Por qué muestra casi 900 tokens de salida? ¿A dónde se fue mi dinero?" — Esta es la confusión real de muchos desarrolladores al usar Gemini 3.1 Pro Preview por primera vez. Los datos en la captura de pantalla también muestran claramente este fenómeno: 13 tokens de entrada, pero ¡hasta 898 tokens de salida!
La respuesta son los Thinking Tokens (Tokens de Razonamiento). Gemini 3.1 Pro es un modelo de razonamiento. Antes de darte una respuesta, realiza una extensa cadena de pensamiento en su "cerebro". Este contenido de razonamiento no se muestra por defecto, pero se cuenta como tokens de salida y se factura normalmente.
Valor central: Después de leer este artículo, comprenderás completamente el mecanismo de Thinking Tokens en los modelos de razonamiento, aprenderás a usar el parámetro thinking_level para controlar la profundidad del razonamiento y ahorrar entre un 50% y un 80% en el costo de tokens de salida, manteniendo la calidad.
Puntos clave sobre los Thinking Tokens de Gemini 3.1 Pro
La mayor diferencia entre un modelo de razonamiento y un modelo de conversación común radica en la composición de los tokens de salida. Estos son los conceptos clave que necesitas entender:
| Punto | Explicación | Impacto práctico |
|---|---|---|
| Tokens de salida = Pensamiento + Respuesta | Los tokens de salida de Gemini 3.1 Pro incluyen Thinking Tokens (cadena de razonamiento) y la respuesta real | Ves pocas palabras, pero el total de tokens es alto |
| Los Thinking Tokens se facturan normalmente | El proceso de razonamiento, aunque invisible, se factura al precio de los tokens de salida ($12/millón de tokens) | Una pregunta simple puede costar 5-10 veces más que en un modelo común |
thinking_level es ajustable |
Admite tres niveles de control de profundidad de razonamiento: LOW/MEDIUM/HIGH | El nivel LOW puede ahorrar más del 80% de los tokens de salida |
| Los modelos no de razonamiento no tienen este problema | Modelos como GPT-4o, Claude Sonnet 4.6 (con Extended Thinking desactivado) ofrecen "lo que ves es lo que pagas" | Para tareas simples, usar modelos no de razonamiento es más rentable |
Caso real de consumo de Thinking Tokens en Gemini 3.1 Pro
Volviendo al ejemplo de la captura de pantalla. El usuario hizo una pregunta simple, el modelo respondió con aproximadamente una docena de palabras, pero los tokens de salida mostraron entre 891 y 898. La composición de estos tokens es aproximadamente la siguiente:
- Respuesta visible: Aproximadamente 30-50 tokens (la docena de palabras que ves)
- Thinking Tokens: Aproximadamente 840-860 tokens (el proceso de razonamiento interno del modelo)
Es decir, más del 95% de los tokens de salida son invisibles para ti, consumidos en la cadena de razonamiento del modelo. Es como si le preguntaras a un profesor de matemáticas "¿cuánto es 1+1?" y él solo dijera "es 2", pero en su mente pensó: "Este es un problema aritmético básico, requiere una operación de suma…" — y tú pagas por todo el proceso de pensamiento del profesor.
Este mecanismo no es un error, sino una característica de diseño de los modelos de razonamiento. La razón por la que Gemini 3.1 Pro se desempeña mejor en problemas complejos (95.1% en MATH, 77.1% en ARC-AGI-2) es precisamente porque realiza un razonamiento profundo antes de responder.
Mecanismo de funcionamiento de los Thinking Tokens del modelo de razonamiento Gemini 3.1 Pro
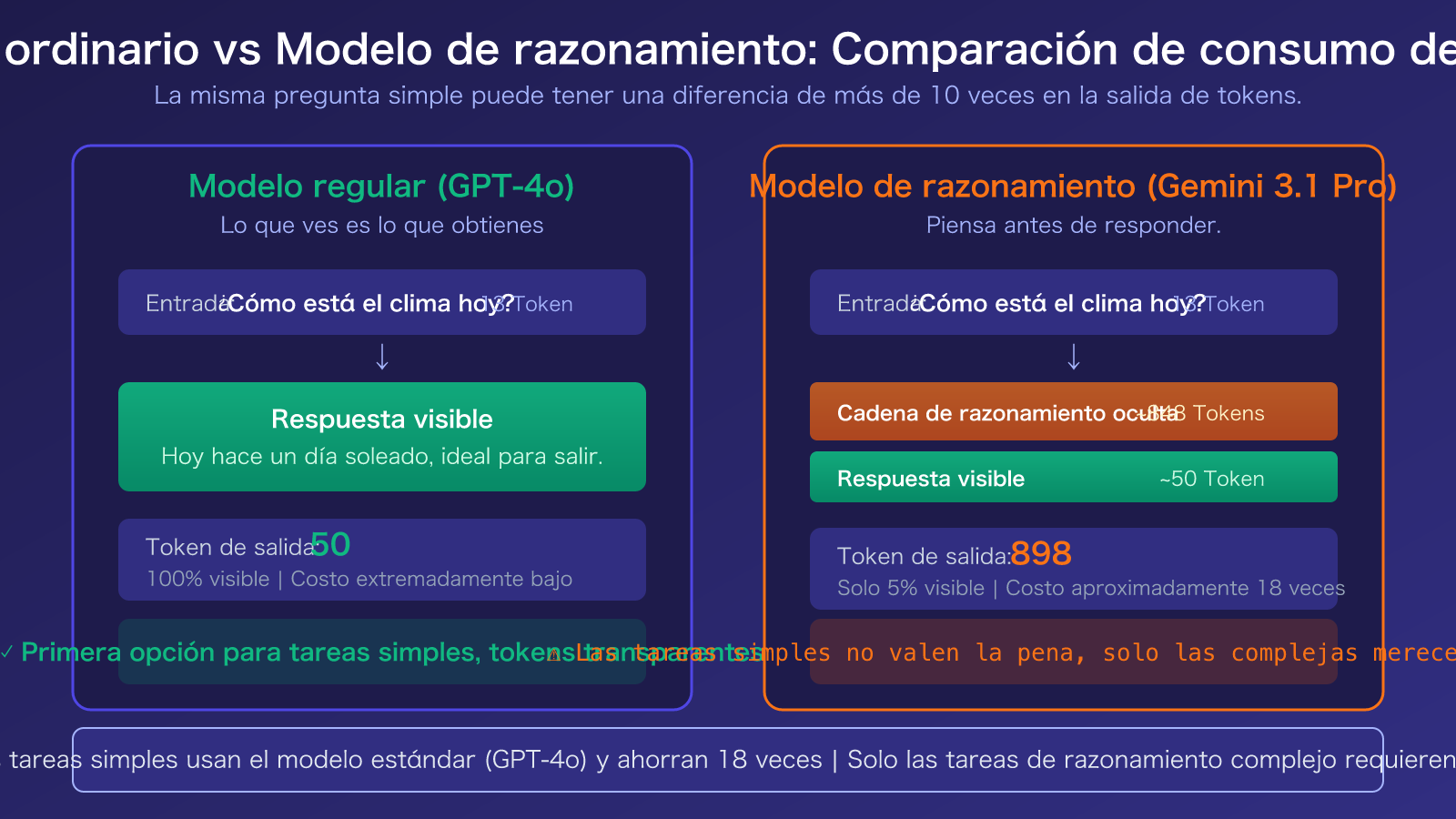
Diferencia fundamental entre modelos de razonamiento y modelos normales
Un modelo normal (como GPT-4o) genera una respuesta directamente después de recibir tu pregunta. Lo que ves es lo que consumes en tokens de salida. Esto es «lo que ves es lo que obtienes».
Un modelo de razonamiento (como Gemini 3.1 Pro Preview), después de recibir la pregunta, primero genera una cadena de razonamiento interna (Chain of Thought) y luego, basándose en el resultado del razonamiento, genera la respuesta final. Solo ves la respuesta final, pero se facturan el total de tokens de «cadena de razonamiento + respuesta».
| Tipo de modelo | Modelo representativo | Composición de tokens de salida | Costo para preguntas simples | Ventaja en problemas complejos |
|---|---|---|---|---|
| Modelo normal | GPT-4o, Claude Sonnet 4.6 | 100% respuesta visible | Bajo (lo que ves es lo que obtienes) | Capacidad de razonamiento general |
| Modelo de razonamiento | Gemini 3.1 Pro, GPT-5.4 Thinking | Cadena de razonamiento + respuesta visible | Alto (5-10 veces o más) | Fuerte capacidad de razonamiento complejo |
| Modelo conmutables | Claude Sonnet 4.6 (Extended Thinking) | Opcional activar razonamiento | Conmutación flexible | Activar razonamiento según necesidad |
3 detalles clave sobre los Thinking Tokens de Gemini 3.1 Pro
Detalle 1: Forma de facturación de los Thinking Tokens. Según la documentación oficial de Google, los Thinking Tokens se facturan al precio estándar de los tokens de salida. El precio de los tokens de salida de Gemini 3.1 Pro es de $12 por millón de tokens. Cuando el modelo gasta 4000 tokens en razonar y 500 tokens en responder, pagas por 4500 tokens de salida, no por 500.
Detalle 2: Cómo distinguirlos en la respuesta de la API. En la respuesta de la API de Gemini, el campo usage_metadata devolverá por separado thoughts_token_count (número de tokens de razonamiento) y candidates_token_count (número total de tokens de salida). Pero atención: candidatesTokenCount en la API de Gemini ya incluye los Thinking Tokens, mientras que en Vertex AI, candidatesTokenCount no los incluye.
Detalle 3: El contenido de la cadena de razonamiento no es visible por defecto. Puedes obtener un resumen del proceso de razonamiento (no la cadena completa) configurando includeThoughts: true, o activar la función de visualización de la cadena de razonamiento en herramientas como Cherry Studio para ver el proceso de pensamiento del modelo.
🎯 Consejo para ahorrar: Si solo necesitas conversaciones simples o tareas de traducción, sin razonamiento profundo, se recomienda cambiar a un modelo normal (como GPT-4o-mini o Claude Sonnet 4.6). APIYI apiyi.com permite cambiar de modelo modificando solo un parámetro
model, sin necesidad de alterar otro código.
Optimización de Thinking Tokens en Gemini 3.1 Pro: 3 estrategias para ahorrar
Estrategia 1: Usar el parámetro thinking_level para controlar la profundidad del razonamiento
Gemini 3.1 Pro proporciona el parámetro thinking_level, que admite tres niveles: LOW, MEDIUM, HIGH. El consumo de tokens varía enormemente entre niveles:
| thinking_level | Profundidad de razonamiento | Consumo de tokens | Escenario de uso | Comparación con HIGH |
|---|---|---|---|---|
| LOW | Razonamiento superficial | Mínimo | Traducción, clasificación, preguntas y respuestas simples | Ahorra aprox. 80%+ |
| MEDIUM | Razonamiento equilibrado | Medio | Programación diaria, generación de documentos, análisis general | Ahorra aprox. 50% |
| HIGH | Razonamiento profundo | Máximo | Derivación matemática, problemas científicos, lógica compleja | Línea base |
Aquí tienes un ejemplo de código para configurar thinking_level:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Para tareas simples usa LOW, reduce drásticamente los Thinking Tokens
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"总输出 Token: {response.usage.completion_tokens}")
Ver el código completo de enrutamiento inteligente (selecciona automáticamente la profundidad de razonamiento según la complejidad del problema)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Invocación inteligente de Gemini 3.1 Pro, selecciona automáticamente la profundidad de razonamiento según la complejidad de la tarea
Args:
prompt: Entrada del usuario
complexity: "low" / "medium" / "high" / "auto"
api_key: Clave API
Returns:
Diccionario que contiene la respuesta y estadísticas de uso de tokens
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Determinar automáticamente la complejidad
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# Ejemplo de uso
# Tarea simple → selección automática LOW
result = smart_gemini_call("翻译:今天天气真好")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
# Tarea compleja → selección automática HIGH
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
Recomendación: Al invocar Gemini 3.1 Pro a través de APIYI apiyi.com, se admite pasar el parámetro
thinking_level. Se recomienda configurar MEDIUM para uso diario y usar HIGH solo en escenarios de razonamiento complejo como matemáticas/ciencias.
Estrategia 2: Usar directamente modelos no de razonamiento para tareas simples
No todos los escenarios requieren un modelo de razonamiento. Para tareas como traducción, conversión de formato, preguntas y respuestas simples, usar un modelo no de razonamiento puede ahorrar entre 5 y 10 veces el costo en tokens:
- GPT-4o-mini: Relación calidad-precio excelente, primera opción para conversaciones diarias.
- Claude Sonnet 4.6 (con Extended Thinking desactivado): Alta calidad de salida, tokens "lo que ves es lo que obtienes".
- Gemini 3.1 Flash: Modelo ligero de Google, rápido y de bajo costo.
Estrategia 3: Configurar max_tokens para limitar la salida máxima
Agregar el parámetro max_tokens a la invocación de la API puede evitar que el modelo de razonamiento «piense en exceso». Pero ten en cuenta: max_tokens limita la salida total (razonamiento + respuesta). Si se configura demasiado bajo, puede truncar la respuesta. Se recomienda configurarlo entre 2 y 3 veces la longitud de respuesta esperada.
🎯 Recomendación integral: En la plataforma APIYI apiyi.com, puedes usar una interfaz unificada para acceder simultáneamente a modelos de razonamiento y no de razonamiento, cambiando dinámicamente según el tipo de tarea. Una sola clave API puede invocar toda la serie de modelos Gemini, Claude y GPT.

Preguntas frecuentes
P1: ¿Por qué los Thinking Tokens de Gemini 3.1 Pro no muestran el proceso de razonamiento por defecto?
Esta es una decisión de diseño de producto de Google. La cadena de razonamiento completa puede contener miles de tokens de derivaciones intermedias; mostrarla directamente afectaría gravemente la experiencia del usuario. Puedes obtener un resumen del razonamiento configurando includeThoughts: true, o activar la función de visualización de la cadena de razonamiento en clientes como Cherry Studio para ver el proceso de pensamiento.
P2: ¿Cómo puedo ver cuántos Thinking Tokens se consumieron específicamente en la respuesta de la API?
Consulta el campo thoughts_token_count en el usage_metadata devuelto por la API de Gemini. Si realizas la llamada a través de APIYI apiyi.com, puedes ver el desglose detallado de tokens (entrada/salida/razonamiento) para cada invocación en la página de estadísticas de uso de la plataforma, lo que facilita el monitoreo y la optimización de costos.
P3: Además de Gemini 3.1 Pro, ¿qué otros modelos tienen un mecanismo similar de Thinking Tokens?
Los principales modelos de razonamiento tienen mecanismos similares:
- GPT-5.4 Thinking: Modelo de razonamiento de OpenAI, donde los tokens de razonamiento también se facturan como tokens de salida.
- Claude Sonnet 4.6 Extended Thinking: Modo de razonamiento de Anthropic, que se puede activar selectivamente.
- DeepSeek-R1: Modelo de razonamiento de código abierto, donde la cadena de razonamiento es completamente visible.
La diferencia clave es que algunos modelos (como Claude) permiten activar/desactivar flexiblemente el modo de razonamiento, mientras que otros (como Gemini 3.1 Pro) lo tienen activado por defecto. A través de APIYI apiyi.com puedes usar una interfaz unificada para probar y comparar el consumo real de tokens de estos modelos.
Conclusión
Los puntos clave de los Thinking Tokens de Gemini 3.1 Pro:
- Los tokens de salida incluyen una cadena de razonamiento oculta: Lo que ves es solo la parte de la respuesta; más del 95% del consumo de tokens de salida ocurre en los Thinking Tokens invisibles.
- Los Thinking Tokens se facturan normalmente: Se cobran al precio estándar de los tokens de salida. El costo de preguntas simples puede ser 5-10 veces mayor que el de modelos sin razonamiento.
- Usa el parámetro
thinking_levelpara ahorrar dinero: El nivel LOW puede ahorrar más del 80% de tokens, MEDIUM es adecuado para uso diario, y usa HIGH solo para tareas complejas. - Para tareas simples, elige modelos sin razonamiento: En escenarios como traducción, clasificación o preguntas y respuestas simples, es más rentable usar directamente GPT-4o-mini o Claude Sonnet 4.6.
Al comprender el mecanismo de los Thinking Tokens, podrás asignar tu presupuesto de razonamiento de manera inteligente. Se recomienda utilizar la interfaz unificada de APIYI apiyi.com para gestionar las invocaciones de múltiples modelos, seleccionando dinámicamente entre modelos de razonamiento o modelos sin razonamiento según la complejidad de la tarea, logrando así el mejor equilibrio entre calidad y costo.
📚 Referencias
-
Documentación de Google Cloud – Modo de razonamiento Thinking: Documentación técnica oficial del modelo de razonamiento de Gemini
- Enlace:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - Descripción: Fuente autorizada sobre reglas de facturación de Thinking Tokens y configuración del parámetro
thinking_level
- Enlace:
-
Documentación para desarrolladores de Google AI – Conteo de tokens: Explicación oficial del conteo de tokens y el campo
usage_metadata- Enlace:
ai.google.dev/gemini-api/docs/tokens - Descripción: Cómo distinguir entre
thoughts_token_countycandidates_token_counten la respuesta de la API
- Enlace:
-
Google DeepMind – Ficha técnica del modelo Gemini 3.1 Pro: Detalles sobre capacidades del modelo y pruebas de referencia de razonamiento
- Enlace:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Descripción: Fuente oficial de datos de rendimiento como MATH 95.1%, ARC-AGI-2 77.1%, etc.
- Enlace:
-
OpenRouter – Mejores prácticas para tokens de razonamiento: Mejores prácticas comunitarias para la gestión de tokens en modelos de razonamiento
- Enlace:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - Descripción: Comparación de reglas de facturación de tokens de razonamiento entre modelos y recomendaciones de optimización
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Bienvenidos a discutir experiencias de optimización de tokens en modelos de razonamiento en la sección de comentarios. Para más tutoriales sobre invocación de modelos, visita el centro de documentación de APIYI en docs.apiyi.com