Subes decenas de miles de filas de Excel a una herramienta de IA, y la interfaz reporta "saldo insuficiente" —¿pero si la cuenta tiene dinero? Este es el escenario más común de problemas al usar IA para procesar grandes volúmenes de datos de Excel, y detrás de esto están las dobles restricciones del mecanismo de pre-deducción de tokens y los límites de la ventana de contexto.
Valor principal: Al terminar de leer este artículo, entenderás completamente por qué un Excel grande puede generar errores, cómo usar la IA correctamente para analizar decenas de miles de filas de datos, y cuál es la solución más económica y eficiente.
<!-- Error response bubble -->
<rect x="0" y="58" width="256" height="84" rx="9" fill="#2d0808" stroke="#ef4444" stroke-width="1.5"/>
<text x="128" y="80" font-family="'PingFang SC',sans-serif" font-size="13" font-weight="bold" fill="#ef4444" text-anchor="middle">❌ Error 402Error: Saldo insuficiente</text>
<text x="128" y="100" font-family="monospace" font-size="10" fill="#fca5a5" text-anchor="middle">Saldo insuficienteCode: INSUFFICIENT_FUNDS</text>
<text x="128" y="116" font-family="'PingFang SC',sans-serif" font-size="10" fill="#fca5a5" text-anchor="middle">Saldo insuficiente, por favor recargue y vuelva a intentarlo.El saldo de su cuenta es insuficiente para esta invocación.</text>
<text x="128" y="132" font-family="'PingFang SC',sans-serif" font-size="9" fill="#94a3b8" text-anchor="middle">(Retención $9.00 · Saldo $5.20)(Sugerencia: el costo de la invocación del modelo se pre-deduce según la cantidad de tokens)</text>
<!-- AI avatar -->
<circle cx="268" cy="100" r="10" fill="#991b1b"/>
<text x="268" y="105" font-family="sans-serif" font-size="11" fill="#fecaca" text-anchor="middle">🤖IA</text>
<!-- Confused user thought -->
<rect x="40" y="158" width="218" height="50" rx="9" fill="#0f2028"/>
<text x="149" y="178" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">😕 Pero mi cuenta claramente tiene saldo.¿Pero si tengo dinero en la cuenta?</text>
<text x="149" y="196" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">¿Por qué dice saldo insuficiente??¿Por qué reporta saldo insuficiente?</text>
<circle cx="28" cy="183" r="10" fill="#1d4ed8"/>
<text x="28" y="188" font-family="sans-serif" font-size="11" fill="#ffffff" text-anchor="middle">👤Usuario</text>
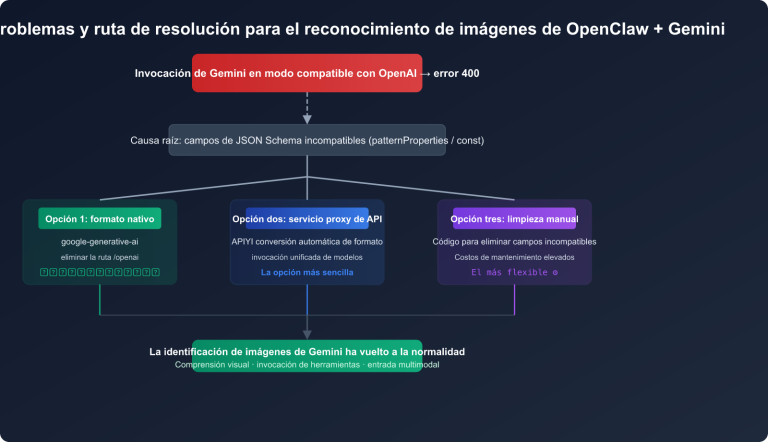
1. ¿Por qué subir un Excel grande genera un error de "saldo insuficiente"?
Muchos usuarios se confunden la primera vez que se encuentran con este problema: el saldo de la cuenta es claramente suficiente, ¿por qué la API sigue devolviendo un error de saldo insuficiente?
Aquí es necesario entender un mecanismo clave de las API de IA: el mecanismo de pre-deducción de tokens.
Explicación detallada del mecanismo de pre-deducción de tokens
Cuando subes un archivo y envías una solicitud en clientes de IA como Cherry Studio o Chatbox, la API no espera a que se genere la respuesta para deducir el coste. En el momento en que se envía la solicitud, estima previamente la cantidad máxima de tokens que podría consumir esta solicitud y "congela" (pre-deduce) temporalmente el coste correspondiente del saldo de la cuenta.
Este proceso de pre-deducción es aproximadamente el siguiente:
- El usuario sube el archivo Excel → el cliente convierte el contenido del archivo a texto plano
- El texto plano se inserta completamente en la indicación (ventana de contexto de la conversación)
- La API calcula el número de tokens de entrada + estima el número máximo de tokens de salida
- El sistema determina: total pre-deducido > saldo de la cuenta → devuelve el error "saldo insuficiente"
Así que, en esencia, no es que "no tengas dinero", sino que la cantidad pre-deducida para esta solicitud es demasiado grande, superando el saldo actual de tu cuenta.
Diferencias esenciales entre los clientes de IA y ChatGPT
Mucha gente tiene un concepto erróneo: piensan que subir un Excel en Cherry Studio es lo mismo que subir un archivo en ChatGPT.
En realidad, es completamente diferente:
| Dimensión de comparación | Cherry Studio / Chatbox | ChatGPT (Code Interpreter) |
|---|---|---|
| Método de procesamiento de archivos | Se convierte a texto y se inserta completamente en el contexto | Se procesa ejecutando código en un entorno sandbox |
| Consumo de tokens | El tamaño del archivo es directamente igual al consumo de tokens | No ocupa tokens del contexto de la conversación |
| Tamaño de archivo adecuado | Se recomiendan menos de 100 líneas | Admite archivos grandes (límite oficial de aprox. 512 MB) |
| Capacidad de análisis de datos | Solo comprensión de texto, no puede ejecutar código | Puede ejecutar Python directamente para estadísticas |
| Método de acceso a la API | Invocación del modelo mediante clave API, facturación por token | Modelo de suscripción ChatGPT Plus |
🎯 Conocimiento clave: Al invocar la IA utilizando un servicio proxy de API (como APIYI apiyi.com), la carga de archivos se realiza a través de un cliente de terceros, y todo el contenido del archivo se convierte en tokens de texto que se transmiten al Modelo de Lenguaje Grande. Esto es completamente diferente del mecanismo de sandbox oficial de ChatGPT para el procesamiento de archivos.
2. ¿Cuántos tokens consume realmente un Excel grande?
Antes de discutir las soluciones, primero establezcamos una comprensión intuitiva del consumo de tokens.
Conceptos básicos de conversión de tokens
| Tipo de contenido | Estimación de tokens |
|---|---|
| 1 palabra en inglés | Aprox. 1-2 tokens |
| 1 carácter en inglés | Aprox. 0.25 tokens (4 caracteres = 1 token) |
| 1 carácter chino | Aprox. 1-2 tokens |
| 1 fecha (ej. 2024-01-15) | Aprox. 5 tokens |
| 1 número (ej. 12345.67) | Aprox. 3-4 tokens |
| 1 fila de datos de Excel (10 columnas) | Aprox. 30-80 tokens |
Cálculo de casos reales
Tomemos como ejemplo un escenario real encontrado por un usuario:
Archivo A: Datos de eficiencia de procesos de 60,000 filas × 10 columnas
Estimación: 60,000 filas × 10 columnas × promedio de 5 tokens/celda
= 60,000 × 50
= 3,000,000 tokens (¡aprox. 3 millones de tokens!)
Archivo B: Datos de negocio de 40,000 filas × 8 columnas
Estimación: 40,000 filas × 8 columnas × promedio de 5 tokens/celda
= 40,000 × 40
= 1,600,000 tokens (aprox. 1.6 millones de tokens)
Comparativa de ventanas de contexto y costes de los Modelos de Lenguaje Grande
| Modelo | Ventana de contexto | Precio por 1M tokens de entrada ($) | Coste de procesamiento de 3 millones de tokens |
|---|---|---|---|
| GPT-4o | 128K tokens | $2.50 | No se puede procesar (excede el límite) |
| Claude 3.5 Sonnet | 200K tokens | $3.00 | No se puede procesar (excede el límite) |
| Gemini 1.5 Pro | 1M tokens | $1.25 | No se puede procesar (excede el límite) |
| Gemini 1.5 Pro 2.0 | 2M tokens | $1.25 | Aprox. $3.75/solicitud |
💡 Como puedes ver, la mayoría de las ventanas de contexto de los Modelos de Lenguaje Grande simplemente no pueden manejar un Excel de 60,000 filas. Incluso si se fuerza con un Modelo de Lenguaje Grande como Gemini 2M de contexto, cada solicitud costaría aproximadamente $3.75 USD.
Tres: 4 soluciones correctas para que la IA procese grandes volúmenes de datos Excel
Ahora que entendemos la causa raíz, te presentamos 4 soluciones probadas, ordenadas por nivel de recomendación.
<line x1="0" y1="56" x2="194" y2="56" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#34d399">Pasos de operación</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="93" font-size="9.5" fill="#6ee7b7">① Extraer 10 filas de datos de muestra para la IA</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="115" font-size="9.5" fill="#6ee7b7">② AI entiende la estructura, genera scripts de análisis</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="137" font-size="9.5" fill="#6ee7b7">③ Ejecutar el script localmente, procesar todos los datos</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#34d399">Escenarios de aplicación</text>
<text x="0" y="186" font-size="10" fill="#a7f3d0">Volumen de datos > 10.000 filas</text>
<text x="0" y="200" font-size="10" fill="#a7f3d0">Análisis estadístico / Generación de informes</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#065f46" stroke="#10b981" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#34d399" text-anchor="middle">Consumo de tokens: < 2.000</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#93c5fd">Pasos de operación</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="93" font-size="9.5" fill="#93c5fd">① Dividir por línea en múltiples subarchivos</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="115" font-size="9.5" fill="#93c5fd">② Invocar la API en un bucle para procesar cada lote</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="137" font-size="9.5" fill="#93c5fd">③ Resumir los resultados de cada lote</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#93c5fd">Escenarios de aplicación</text>
<text x="0" y="186" font-size="10" fill="#bfdbfe">5,000-20,000 filas de datos</text>
<text x="0" y="200" font-size="10" fill="#bfdbfe">Clasificación por línea / Análisis de sentimiento</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#1e3a5f" stroke="#3b82f6" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#93c5fd" text-anchor="middle">Costo total aproximadamente $0.5-1.5</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#d8b4fe">Pasos a seguir</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="93" font-size="9.5" fill="#d8b4fe">① Realizar estadísticas de agregación con tablas dinámicas de Excel</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="115" font-size="9.5" fill="#d8b4fe">② Datos resumidos (decenas de líneas) para la IA</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="137" font-size="9.5" fill="#d8b4fe">③ AI escribe informes de análisis y perspectivas</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#d8b4fe">Escenarios de aplicación</text>
<text x="0" y="186" font-size="10" fill="#e9d5ff">Se necesita un informe de análisis de tendencias general.</text>
<text x="0" y="200" font-size="10" fill="#e9d5ff">No es necesario entender los datos originales línea por línea</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#3b0764" stroke="#a855f7" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#d8b4fe" text-anchor="middle">Consumo de tokens: mínimo</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#fdba74">Recomendar modelo</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="93" font-size="9.5" fill="#fdba74">Gemini 2.0 Flash (1M ventana de contexto)</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="115" font-size="9.5" fill="#fdba74">Gemini 1.5 Pro (1M de ventana de contexto)</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="137" font-size="9.5" fill="#fdba74">Claude 3.5 Sonnet(200K)</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#fdba74">Escenarios de aplicación</text>
<text x="0" y="186" font-size="10" fill="#fed7aa">Volumen de datos < 5000 filas</text>
<text x="0" y="200" font-size="10" fill="#fed7aa">Puede asumir costos de API más altos</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#431407" stroke="#f97316" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#fdba74" text-anchor="middle">Costo: $1-5 / vez</text>
Solución A (¡Altamente recomendada!): Datos de muestra + que la IA escriba el script
Idea principal: No dejes que la IA procese directamente todos los datos. En su lugar, permite que la IA entienda la estructura de los datos y luego genere un script de procesamiento que se ejecute localmente.
Pasos de operación:
Paso uno: Extrae datos de muestra (10 filas son suficientes)
import pandas as pd
# Lee las primeras 10 filas como muestra (incluyendo el encabezado)
df_sample = pd.read_excel("your_data.xlsx", nrows=10)
# Imprime en formato de texto para copiarlo fácilmente a la IA
print(df_sample.to_string())
print("\n--- Resumen de datos ---")
print(f"Número total de filas: {len(pd.read_excel('your_data.xlsx'))}")
print(f"Nombres de columna: {list(df_sample.columns)}")
print(f"Tipos de datos:\n{df_sample.dtypes}")
Paso dos: Envía los datos de muestra y tus requisitos a la IA
Ejemplo de indicación:
Aquí tienes una muestra de las primeras 10 filas de mis datos de Excel y una descripción de su estructura:
[Pega aquí el contenido de la salida del paso anterior]
El conjunto de datos completo tiene 60.000 filas. Necesito analizar lo siguiente:
1. Calcular la tasa de finalización del proceso por departamento
2. Identificar los nodos de proceso con un tiempo medio de procesamiento superior a 2 horas
3. Generar un informe de tendencias semanales
Por favor, escríbeme un script de Python que lea los datos completos y genere los resultados del análisis.
Paso tres: Ejecuta el script generado por la IA localmente
La IA, basándose en tus 10 filas de datos de muestra, entenderá el significado de los campos y generará un script de análisis completo. Ejecutas este script localmente para procesar las 60.000 filas de datos completas. Todo el proceso ya no requiere la invocación del modelo de IA, con un consumo de tokens nulo.
Ventajas de la solución:
- Consumo de tokens extremadamente bajo (solo 10 filas de muestra ≈ unos cientos de tokens)
- El script local se puede ejecutar repetidamente; si los datos se actualizan, simplemente lo vuelves a ejecutar.
- Ideal para escenarios donde necesitas procesar datos similares de forma regular.
🎯 Herramienta recomendada: Utiliza Claude 3.5 Sonnet o GPT-4o en APIYI apiyi.com para generar scripts de procesamiento de datos. Estos modelos son excelentes para tareas de generación de código, y una sola solicitud suele consumir menos de 2000 tokens, con un costo muy bajo.
Solución B: Procesamiento de datos por lotes
Escenario aplicable: El número de filas de datos está entre 5.000 y 20.000, y la IA necesita entender el contenido de cada fila (como análisis de sentimiento, clasificación de texto).
Pasos de operación:
import pandas as pd
def process_in_batches(file_path, batch_size=500):
"""Procesa un archivo Excel grande por lotes"""
df = pd.read_excel(file_path)
total_rows = len(df)
results = []
for start in range(0, total_rows, batch_size):
end = min(start + batch_size, total_rows)
batch = df.iloc[start:end]
# Convierte este lote de datos a texto CSV para pasarlo a la IA
batch_text = batch.to_csv(index=False)
print(f"Procesando filas {start+1}-{end} (de un total de {total_rows} filas)")
# Aquí se invoca la API de IA para procesar batch_text
# result = call_ai_api(batch_text)
# results.append(result)
return results
Cada lote de 500 filas consume aproximadamente 25.000-40.000 tokens. El costo total para procesar 60.000 filas de datos completos usando GPT-4o mini es de aproximadamente $0.5-$1.5 USD.
Consideraciones:
- Después de procesar cada lote, es necesario consolidar los resultados, prestando atención a la precisión estadística entre lotes.
- El procesamiento por lotes puede perder relaciones entre filas, por lo que es adecuado para tareas donde las filas son independientes.
Solución C: Preprocesamiento de datos antes de la carga
Escenario aplicable: Necesitas que la IA analice tendencias generales y escriba informes de análisis, pero no necesitas que la IA vea cada fila de datos original.
Pasos de operación:
Paso 1: Crea un resumen de datos usando tablas dinámicas de Excel o Python
import pandas as pd
df = pd.read_excel("data.xlsx")
# Genera estadísticas de resumen
summary = {
"Número total de filas": len(df),
"Rango de tiempo": f"{df['日期'].min()} hasta {df['日期'].max()}",
"Estadísticas por departamento": df.groupby('部门')['完成率'].mean().to_dict(),
"Tendencia mensual": df.groupby(df['日期'].dt.month)['处理时长'].mean().to_dict(),
"Cantidad de datos anómalos": len(df[df['处理时长'] > 120])
}
# Convierte el resumen a texto estructurado para que la IA escriba el informe de análisis
import json
print(json.dumps(summary, ensure_ascii=False, indent=2))
Paso 2: Pasa los datos resumidos a la IA para que escriba el informe de análisis
Los datos resumidos suelen tener solo unas pocas cientos de líneas, por lo que pasarlos a la IA apenas consume tokens, pero permite que la IA genere informes completos de análisis de tendencias y perspectivas de negocio.
Solución D: Elegir un Modelo de Lenguaje Grande con ventana de contexto extendida
Escenario aplicable: Realmente necesitas que la IA entienda el contenido semántico de todos los datos y estás dispuesto a asumir un costo más alto.
| Modelo | Contexto máximo | Volumen de datos adecuado | Costo de referencia |
|---|---|---|---|
| Gemini 1.5 Pro | 1 millón de tokens | Aprox. 20.000-30.000 filas | Facturación por uso a través de APIYI |
| Gemini 2.0 Flash | 1 millón de tokens | Aprox. 20.000-30.000 filas | Excelente relación calidad-precio |
| Claude 3.5 Sonnet | 200.000 tokens | Aprox. 3.000-5.000 filas | Excelente calidad en generación de código |
💡 Incluso al usar Modelos de Lenguaje Grande con ventana de contexto extendida, se recomienda encarecidamente limpiar los datos primero (eliminar filas vacías, fusionar columnas duplicadas, eliminar campos irrelevantes) para reducir el consumo de tokens y evitar activar límites de pre-autorización.
🎯 Ventaja de la interfaz unificada: A través de la plataforma APIYI apiyi.com, puedes usar una interfaz API unificada para invocar varios Modelos de Lenguaje Grande con ventana de contexto extendida como Gemini, Claude, GPT, etc., sin necesidad de registrar una cuenta separada para cada modelo, lo que facilita el cambio rápido y la comparación de costos.
IV. Cómo evitar volver a caer en los mismos errores
Una vez que domines las soluciones anteriores, aquí tienes algunas mejores prácticas para el uso diario de la IA en el procesamiento de datos.
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#ef4444"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#2d1414" stroke="#ef4444" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#fca5a5">Paso 2: 📊 Aumento masivo de tokens: ≈ 3 millones de tokens</text>
<text x="22" y="86" font-size="10" fill="#ef4444">Convertir a texto CSV, 100.000 tokens</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#ef4444"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#3d0808" stroke="#dc2626" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#ff6b6b">Paso 3: 💥 Error de API 402: Saldo insuficiente</text>
<text x="22" y="142" font-size="10" fill="#fca5a5">Invocación del modelo de IA</text>
<!-- Problem stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Tasa de éxito</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#ef4444" text-anchor="middle">20%</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Tiempo de respuesta</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#ef4444" text-anchor="middle">~120s</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#2d0808" stroke="#dc2626" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#ff6b6b" text-anchor="middle">Costo: $0.25</text>
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#10b981"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#022c22" stroke="#10b981" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#6ee7b7">Paso 2: 🤖 IA comprende la estructura, genera scripts de análisis en Python</text>
<text x="22" y="86" font-size="10" fill="#34d399">Generar script local, 1000 tokens</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#10b981"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#064e3b" stroke="#059669" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#34d399">Paso 3: 🚀 Ejecutar el script localmente para procesar 60.000 filas de datos completas</text>
<text x="22" y="142" font-size="10" fill="#a7f3d0">Ejecutar script local para procesar</text>
<!-- Success stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Tasa de éxito</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#34d399" text-anchor="middle">99%</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Tiempo de respuesta</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#34d399" text-anchor="middle">~1s</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#064e3b" stroke="#059669" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#34d399" text-anchor="middle">Costo: $0.0025</text>
Método de estimación de tokens antes de usar
Antes de subir un archivo, puedes usar el siguiente método para estimar rápidamente la cantidad de tokens:
import pandas as pd
def estimate_tokens(file_path):
"""Estima aproximadamente la cantidad de tokens después de convertir un archivo Excel a texto."""
df = pd.read_excel(file_path)
# Convierte los datos a texto CSV
csv_text = df.to_csv(index=False)
# Estimación aproximada: ~4 caracteres/token para inglés, ~1.5 caracteres/token para chino
char_count = len(csv_text)
estimated_tokens = char_count / 3.5 # Promedio para mezcla de chino e inglés
print(f"Número de filas del archivo: {len(df)}")
print(f"Número de columnas del archivo: {len(df.columns)}")
print(f"Número de caracteres CSV: {char_count:,}")
print(f"Tokens estimados: {estimated_tokens:,.0f}")
print(f"Costo estimado (calculado con GPT-4o a $2.5/1M): ${estimated_tokens/1_000_000*2.5:.4f}")
if estimated_tokens > 100_000:
print("⚠️ Advertencia: La cantidad de tokens supera los 100.000. Se recomienda usar la Solución A (muestras + script).")
estimate_tokens("your_data.xlsx")
Tabla de errores comunes y soluciones
| Fenómeno del error | Causa raíz | Solución |
|---|---|---|
| Reporta "saldo insuficiente" pero hay saldo | La pre-retención de tokens excede el saldo de la cuenta | Recargar saldo o cambiar a la Solución A/C |
| Respuesta muy lenta o tiempo de espera agotado | Demasiados tokens de entrada, largo tiempo de inferencia | Reducir la cantidad de datos de entrada |
| Resultados de análisis de IA imprecisos | Demasiados datos, efecto "lost-in-the-middle" | Simplificar datos, usar procesamiento por lotes |
| La API reporta "context length exceeded" | Excede la ventana de contexto máxima del modelo | Cambiar a un Modelo de Lenguaje Grande con mayor ventana de contexto o procesamiento por lotes |
| Costo muy alto por cada uso | Carga repetida de grandes cantidades de datos | Usar la Solución A para generar scripts locales reutilizables |
V. Ejercicio práctico: Análisis de 60,000 filas de datos de procesos
A continuación, demostraremos el proceso completo, desde la identificación de problemas hasta su solución, con un caso de negocio integral.
Contexto: El equipo de operaciones tiene un conjunto de datos de eficiencia de procesos de 60,000 filas, que incluye campos como: departamento, nombre del proceso, hora de inicio, hora de finalización, persona a cargo, estado de finalización, etc. Quieren que la IA analice qué nodos de proceso tienen la eficiencia más baja.
Paso 1: Extracción de la muestra
import pandas as pd
# Leer las primeras 10 filas
df = pd.read_excel("process_data.xlsx", nrows=10)
print("=== Muestra de datos (primeras 10 filas) ===")
print(df.to_string())
print("\n=== Descripción de campos ===")
for col in df.columns:
print(f"- {col}: {df[col].dtype}, Valor de ejemplo: {df[col].iloc[0]}")
Paso 2: Enviar a la IA para obtener el script de análisis
Envía el contenido de salida anterior a la IA, junto con la descripción de los requisitos:
A continuación se muestra la estructura y 10 filas de muestra de mis datos de proceso en Excel:
[Pegar contenido de salida]
Requisitos:
1. Calcular el tiempo promedio de procesamiento para cada 'nombre de proceso' (hora de finalización - hora de inicio)
2. Calcular la tasa de finalización del proceso por departamento (proporción de 'estado de finalización' = 'Completado')
3. Identificar los 10 procesos con el tiempo promedio de procesamiento más largo y mostrarlos en una tabla
4. Guardar los resultados en analysis_result.xlsx
Por favor, escribe un script completo y ejecutable en Python.
Paso 3: Ejecutar el script localmente
La IA generará un script de análisis similar al siguiente (versión de ejemplo simplificada):
import pandas as pd
# Leer los datos completos
df = pd.read_excel("process_data.xlsx")
# Calcular el tiempo de procesamiento (minutos)
df['处理时长_分钟'] = (
pd.to_datetime(df['结束时间']) - pd.to_datetime(df['开始时间'])
).dt.total_seconds() / 60
# Calcular el tiempo promedio por proceso
process_avg = (
df.groupby('流程名称')['处理时长_分钟']
.agg(['mean', 'count'])
.rename(columns={'mean': '平均时长', 'count': '总次数'})
.sort_values('平均时长', ascending=False)
)
# Calcular la tasa de finalización por departamento
dept_completion = (
df.groupby('部门')['完成状态']
.apply(lambda x: (x == '完成').mean() * 100)
.round(2)
.rename('完成率%')
)
# Mostrar los 10 procesos más lentos
print("=== Los 10 nodos de proceso que consumen más tiempo ===")
print(process_avg.head(10).to_string())
# Guardar resultados
with pd.ExcelWriter("analysis_result.xlsx") as writer:
process_avg.to_excel(writer, sheet_name="Análisis de Eficiencia de Procesos")
dept_completion.to_excel(writer, sheet_name="Tasa de Finalización por Departamento")
print("\n✅ Los resultados del análisis se han guardado en analysis_result.xlsx")
Comparación del consumo de tokens en todo el proceso:
| Método | Consumo de tokens | Costo estimado (GPT-4o) | Calidad del análisis |
|---|---|---|---|
| Subir 60,000 filas directamente | ~3 millones de tokens | $7.5+ y excede la ventana de contexto | No se puede completar |
| Opción A (muestra + script) | ~2000 tokens | < $0.01 | Completo y preciso |
🎯 Comparación de costos: El consumo de la Opción A es menos del 0.1% del método de carga directa, y los resultados del análisis son más precisos y reutilizables. Se recomienda usar APIYI apiyi.com para invocar GPT-4o o Claude 3.5 Sonnet para generar scripts de procesamiento de datos; los resultados son excelentes y el costo es extremadamente bajo.
VI. Preguntas Frecuentes (FAQ)
P1: No tengo conocimientos de Python, ¿puedo usar esta solución?
Absolutamente. El núcleo de la Opción A es "dejar que la IA escriba el script y tú lo ejecutas". Solo necesitas:
- Instalar Python (sitio web oficial: python.org, solo sigue los pasos 'siguiente, siguiente')
- Instalar pandas: En la terminal, escribe
pip install pandas openpyxl - Extraer datos de muestra para la IA → La IA genera el script → Guardar como archivo
.py→ Doble clic para ejecutar
Para los usuarios que no están familiarizados con la línea de comandos, también pueden usar Jupyter Notebook (incluido en el paquete de instalación de Anaconda), que es más intuitivo.
💡 En APIYI apiyi.com, también puedes usar la función de intérprete de código incorporada para que la IA genere y verifique directamente la lógica del script, reduciendo el tiempo de depuración.
P2: Además de Python, ¿existen otras formas de procesar grandes volúmenes de datos?
Sí, las siguientes son algunas formas, ordenadas por facilidad de uso:
- Funciones integradas de Excel: Tablas dinámicas + Power Query, no requiere programación, ideal para estadísticas agregadas.
- Python pandas: El más flexible, alta eficiencia de procesamiento, recomendado para usuarios intermedios y avanzados.
- Microsoft Copilot (complemento de Excel): Analiza directamente con la IA dentro de Excel, pero aún tiene limitaciones de filas.
- Herramientas profesionales de análisis de datos: Tableau, Power BI se conectan a fuentes de datos, con una fuerte capacidad de procesamiento de grandes volúmenes de datos.
P3: ¿Cuál es el saldo de cuenta adecuado para evitar errores de retención?
Esto depende de tu escenario de uso diario. Generalmente se recomienda:
- Usuarios de chat casuales: Mantener un saldo de $5-20
- Usuarios de procesamiento de datos (subidas ocasionales de archivos): Mantener un saldo de $20-50
- Invocación de API de alta frecuencia: Se recomienda configurar la recarga automática o mantener un saldo de $100+.
🎯 Gestión de saldo: En la consola de APIYI apiyi.com, puedes ver los detalles del consumo de tokens, configurar alertas de uso y evitar que un saldo insuficiente afecte tus operaciones. La plataforma admite recargas bajo demanda, sin requisitos de consumo mínimo.
P4: Mis datos contienen información privada, ¿puedo enviar datos de muestra a la IA?
Las prácticas recomendadas son:
- Anonimizar antes de enviar a la IA: Reemplaza campos sensibles como nombres, números de teléfono, identificaciones, etc., con valores de ejemplo (por ejemplo, 'Zhang San' → 'Usuario A').
- Proporcionar solo nombres de campos y tipos de datos: No proporciones valores específicos, solo informa a la IA sobre la estructura y los tipos de datos de los campos.
- Solución con modelo local: Usa Ollama para ejecutar un modelo local (como Qwen2.5), de modo que los datos nunca salgan de tu máquina.
Resumen
El error más común al procesar grandes volúmenes de datos Excel con IA es subir el archivo completo directamente, lo que provoca una explosión de tokens, errores de interfaz y costes descontrolados. La solución principal es muy sencilla:
Que la IA "vea una muestra y escriba un script", en lugar de "ver el archivo completo y hacer los cálculos".
Un vistazo a los escenarios de aplicación de las cuatro soluciones:
| Escenario | Solución recomendada | Dificultad |
|---|---|---|
| Volumen de datos > 10.000 filas, requiere análisis estadístico | Solución A: Muestra + script | ⭐⭐ (requiere ejecutar Python) |
| Volumen de datos 5.000-20.000 filas, requiere comprensión línea por línea | Solución B: Procesamiento por lotes | ⭐⭐⭐ (requiere invocar la API) |
| Solo se necesita un informe de tendencias, no un análisis línea por línea | Solución C: Resumen preprocesado | ⭐ (se puede hacer con Excel) |
| Volumen de datos < 5.000 filas, se pueden asumir costes más altos | Solución D: Modelo de Lenguaje Grande con ventana de contexto amplia | ⭐ (subida directa) |
Prueba la Solución A ahora mismo: extrae las primeras 10 filas de tu Excel, en APIYI apiyi.com selecciona GPT-4o o Claude 3.5 Sonnet, dile a la IA tus necesidades de análisis y deja que genere el script de procesamiento —la mayoría de las tareas de análisis de datos se pueden resolver por menos de $0.01.
🎯 Inicio rápido: Visita APIYI apiyi.com, regístrate para probar una variedad de modelos populares. Soporta la invocación unificada de APIs de OpenAI, Claude, Gemini y otros, se factura según el consumo real, sin cuotas mensuales ni consumo mínimo. Ideal para equipos de negocio y usuarios individuales que necesiten procesar diversas tareas de análisis de datos.
Este artículo ha sido compilado por el equipo técnico de APIYI, basado en comentarios reales de usuarios y experiencia práctica. Si tienes preguntas o sugerencias, no dudes en contactarnos a través de apiyi.com.