عند تحميل عشرات الآلاف من صفوف Excel إلى أداة AI، تُبلغ الواجهة عن "رصيد غير كافٍ" — لكن الحساب لديه أموال بوضوح؟ هذا هو السيناريو الأكثر شيوعًا للمشاكل عند استخدام AI لمعالجة بيانات Excel الكبيرة، ووراء ذلك يكمن القيد المزدوج لآلية خصم التوكن المسبق وقيود نافذة السياق.
القيمة الأساسية: بعد قراءة هذا المقال، ستفهم تمامًا لماذا تحدث الأخطاء في ملفات Excel الكبيرة، وكيفية استخدام AI لتحليل عشرات الآلاف من صفوف البيانات بشكل صحيح، وأي الحلول هو الأكثر توفيرًا وفعالية.
<!-- Error response bubble -->
<rect x="0" y="58" width="256" height="84" rx="9" fill="#2d0808" stroke="#ef4444" stroke-width="1.5"/>
<text x="128" y="80" font-family="'PingFang SC',sans-serif" font-size="13" font-weight="bold" fill="#ef4444" text-anchor="middle">❌ خطأ 402</text>
<text x="128" y="100" font-family="monospace" font-size="10" fill="#fca5a5" text-anchor="middle">رصيد غير كافٍ</text>
<text x="128" y="116" font-family="'PingFang SC',sans-serif" font-size="10" fill="#fca5a5" text-anchor="middle">الرصيد غير كافٍ، يرجى إعادة الشحن والمحاولة مرة أخرى</text>
<text x="128" y="132" font-family="'PingFang SC',sans-serif" font-size="9" fill="#94a3b8" text-anchor="middle">(مخصوم 9.00 دولار · الرصيد 5.20 دولار)</text>
<!-- AI avatar -->
<circle cx="268" cy="100" r="10" fill="#991b1b"/>
<text x="268" y="105" font-family="sans-serif" font-size="11" fill="#fecaca" text-anchor="middle">🤖</text>
<!-- Confused user thought -->
<rect x="40" y="158" width="218" height="50" rx="9" fill="#0f2028"/>
<text x="149" y="178" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">😕 لكن لدي رصيد بالفعل في حسابي!</text>
<text x="149" y="196" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">لماذا يقول الرصيد غير كافٍ؟؟</text>
<circle cx="28" cy="183" r="10" fill="#1d4ed8"/>
<text x="28" y="188" font-family="sans-serif" font-size="11" fill="#ffffff" text-anchor="middle">👤</text>
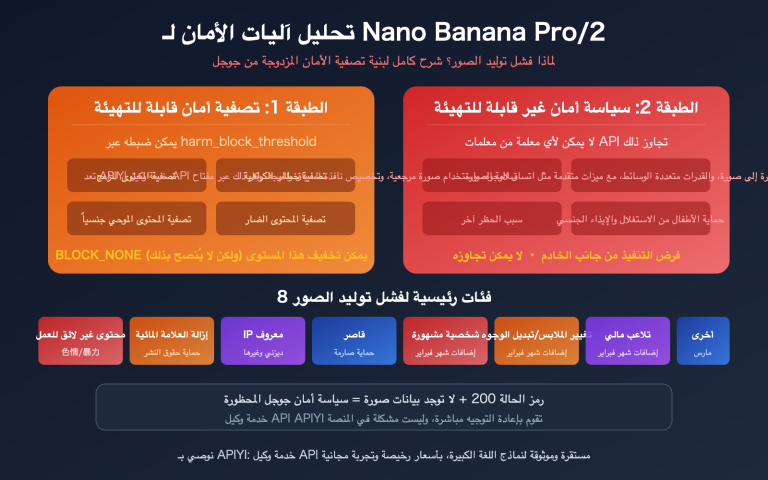
أولاً: لماذا تظهر رسالة "الرصيد غير كافٍ" عند تحميل ملف Excel كبير؟
يشعر العديد من المستخدمين بالحيرة عند مواجهة هذه المشكلة لأول مرة: لماذا تُرجع الواجهة خطأ "الرصيد غير كافٍ" بينما رصيد الحساب يكفي بوضوح؟
هنا، نحتاج إلى فهم آلية أساسية لواجهات برمجة تطبيقات الذكاء الاصطناعي (AI API): آلية الخصم المسبق للتوكنات (Tokens).
شرح مفصل لآلية الخصم المسبق للتوكنات
عندما تقوم بتحميل ملف وإرسال طلب في عميل ذكاء اصطناعي مثل Cherry Studio أو Chatbox، فإن واجهة API لا تنتظر حتى يتم إنشاء الاستجابة لإجراء الخصم. بل تقوم، في لحظة إرسال الطلب، بتقدير الحد الأقصى لعدد التوكنات التي قد يستهلكها هذا الطلب، وتقوم بـ "تجميد" (خصم مسبق) المبلغ المقابل مؤقتًا من رصيد الحساب.
عملية الخصم المسبق تسير تقريبًا كالتالي:
- يقوم المستخدم بتحميل ملف Excel ← يقوم العميل بتحويل محتوى الملف إلى نص عادي.
- يتم إدخال النص العادي بالكامل في الموجه (prompt) (سياق المحادثة).
- تقوم واجهة API بحساب عدد توكنات الإدخال + تقدير الحد الأقصى لعدد توكنات الإخراج.
- يقرر النظام: إجمالي الخصم المسبق > رصيد الحساب ← يُرجع خطأ "الرصيد غير كافٍ".
لذا، في جوهر الأمر، ليست المشكلة أنك "لا تملك المال"، بل إن مبلغ الخصم المسبق لهذا الطلب كبير جدًا، ويتجاوز رصيد الحساب الحالي.
الاختلافات الجوهرية بين عملاء الذكاء الاصطناعي و ChatGPT
لدى الكثيرين سوء فهم: يعتقدون أن تحميل ملف Excel في Cherry Studio هو نفس تحميل ملف في ChatGPT.
في الواقع، الأمر مختلف تمامًا:
| معيار المقارنة | Cherry Studio / Chatbox | ChatGPT (مفسر الأكواد) |
|---|---|---|
| طريقة معالجة الملفات | يُحوّل إلى نص ويُدرج بالكامل في السياق | يُعالَج بتشغيل الكود في بيئة معزولة (Sandbox) |
| استهلاك التوكنات | حجم الملف يساوي استهلاك التوكنات مباشرةً | لا يشغل توكنات سياق المحادثة |
| حجم الملف المناسب | يُوصى بأقل من 100 سطر | يدعم ملفات أكبر (الحد الرسمي حوالي 512 ميجابايت) |
| قدرة تحليل البيانات | فهم نصي فقط، لا يمكنه تنفيذ الأكواد | يمكنه تشغيل Python مباشرة لإجراء التحليلات الإحصائية |
| طريقة الوصول إلى API | يتم الاستدعاء عبر مفتاح API، ويُحاسب بالتوكنات | اشتراك ChatGPT Plus |
🎯 فهم أساسي: عند استخدام خدمة وكيل API (مثل APIYI apiyi.com) لاستدعاء الذكاء الاصطناعي، يتم تحميل الملفات عبر عميل طرف ثالث، ويتم تحويل جميع محتويات الملف إلى توكنات نصية تُرسل إلى النموذج. هذا يختلف تمامًا عن آلية معالجة الملفات في بيئة ChatGPT المعزولة الرسمية.
ثانياً: كم تستهلك ملفات Excel الكبيرة من التوكنات؟
قبل مناقشة الحلول، دعونا نكوّن فهمًا بديهيًا لكمية استهلاك التوكنات.
أساسيات تحويل التوكنات
| نوع المحتوى | تقدير التوكنات |
|---|---|
| كلمة إنجليزية واحدة | حوالي 1-2 توكن |
| حرف إنجليزي واحد | حوالي 0.25 توكن (4 أحرف = 1 توكن) |
| حرف صيني واحد | حوالي 1-2 توكن |
| تاريخ واحد (مثل 2024-01-15) | حوالي 5 توكنات |
| رقم واحد (مثل 12345.67) | حوالي 3-4 توكنات |
| صف واحد من بيانات Excel (10 أعمدة) | حوالي 30-80 توكن |
حسابات حالات عملية
لنأخذ مثالًا على سيناريو حقيقي واجهه المستخدمون:
الملف A: بيانات كفاءة العمليات 60 ألف سطر × 10 أعمدة
تقدير: 60,000 سطر × 10 أعمدة × متوسط 5 توكنات/خلية
= 60,000 × 50
= 3,000,000 توكن (حوالي 3 ملايين توكن!)
الملف B: بيانات الأعمال 40 ألف سطر × 8 أعمدة
تقدير: 40,000 سطر × 8 أعمدة × متوسط 5 توكنات/خلية
= 40,000 × 40
= 1,600,000 توكن (حوالي 1.6 مليون توكن)
مقارنة نافذة السياق والتكلفة لمختلف النماذج
| النموذج | نافذة السياق | سعر الإدخال للوحدة (دولار/مليون توكن) | تكلفة معالجة 3 ملايين توكن |
|---|---|---|---|
| GPT-4o | 128 ألف توكن | $2.50 | لا يمكن المعالجة (تجاوز الحد) |
| Claude 3.5 Sonnet | 200 ألف توكن | $3.00 | لا يمكن المعالجة (تجاوز الحد) |
| Gemini 1.5 Pro | مليون توكن | $1.25 | لا يمكن المعالجة (تجاوز الحد) |
| Gemini 1.5 Pro 2.0 | 2 مليون توكن | $1.25 | حوالي $3.75/مرة |
💡 كما نرى، فإن نافذة السياق لمعظم النماذج لا تستوعب 60 ألف سطر من Excel على الإطلاق. وحتى لو استخدمنا نموذج Gemini ذو سياق 2 مليون توكن بصعوبة، فإن كل طلب سيكلف حوالي 3.75 دولار أمريكي.
ثالثًا: 4 حلول صحيحة لمعالجة بيانات Excel الضخمة باستخدام الذكاء الاصطناعي
بعد فهم الأسباب الجذرية، نقدم فيما يلي 4 حلول مجربة لمعالجة بيانات Excel الضخمة باستخدام الذكاء الاصطناعي، مرتبة حسب الأفضلية.
<line x1="0" y1="56" x2="194" y2="56" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#34d399">حالات الاستخدام خطوات التشغيل</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="93" font-size="9.5" fill="#6ee7b7">معالجة البيانات المتشابهة بانتظام استخرج 10 صفوف من البيانات النموذجية للذكاء الاصطناعي</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="115" font-size="9.5" fill="#6ee7b7">المهام الحساسة للتكلفة فهم الذكاء الاصطناعي للهيكل، وتوليد نصوص التحليل</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="137" font-size="9.5" fill="#6ee7b7">تتطلب دقة عالية ③ تشغيل السكريبت محليًا لمعالجة جميع البيانات</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#34d399">المزايا حالات الاستخدام</text>
<text x="0" y="186" font-size="10" fill="#a7f3d0">استهلاك توكنز منخفض جدًا حجم البيانات > 10,000 سطر</text>
<text x="0" y="200" font-size="10" fill="#a7f3d0">يمكن تشغيله بشكل متكرر تحليل إحصائي / توليد التقارير</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#065f46" stroke="#10b981" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#34d399" text-anchor="middle">عرض التفاصيل استهلاك التوكن: < 2,000</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#93c5fd">حالات الاستخدام خطوات التشغيل</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="93" font-size="9.5" fill="#93c5fd">5000-20000 صف من البيانات ① تقسيم حسب السطر إلى عدة ملفات فرعية</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="115" font-size="9.5" fill="#93c5fd">يتطلب فهم الذكاء الاصطناعي لكل صف ② استدعاء API بشكل متكرر لمعالجة كل دفعة</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="137" font-size="9.5" fill="#93c5fd">تحليل المشاعر وما شابه ③ تلخيص نتائج كل دفعة</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#93c5fd">المزايا حالات الاستخدام</text>
<text x="0" y="186" font-size="10" fill="#bfdbfe">تكلفة يمكن التحكم فيها ٥٠٠٠-٢٠ ألف سطر بيانات</text>
<text x="0" y="200" font-size="10" fill="#bfdbfe">مناسب لكميات البيانات المتوسطة تصنيف السطر/تحليل المشاعر</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#1e3a5f" stroke="#3b82f6" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#93c5fd" text-anchor="middle">عرض التفاصيل التكلفة الإجمالية حوالي 0.5-1.5 دولار</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#d8b4fe">حالات الاستخدام خطوات التشغيل</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="93" font-size="9.5" fill="#d8b4fe">يتطلب تحليل الاتجاه العام ① جدول Pivot في Excel لإحصائيات التجميع</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="115" font-size="9.5" fill="#d8b4fe">كتابة تقارير التحليل ② بيانات ملخصة (عشرات الأسطر) للذكاء الاصطناعي</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="137" font-size="9.5" fill="#d8b4fe">لا يتطلب رؤية الصفوف الأصلية ③ AI كتابة تقارير التحليل والرؤى</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#d8b4fe">المزايا سيناريوهات الاستخدام</text>
<text x="0" y="186" font-size="10" fill="#e9d5ff">استهلاك توكنز منخفض مطلوب تقرير تحليل الاتجاهات الشامل</text>
<text x="0" y="200" font-size="10" fill="#e9d5ff">توليد تقارير سريعة لا حاجة لفهم البيانات الخام سطرًا بسطر</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#3b0764" stroke="#a855f7" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#d8b4fe" text-anchor="middle">عرض التفاصيل استهلاك التوكن: قليل جدًا</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#fdba74">حالات الاستخدام نموذج موصى به</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="93" font-size="9.5" fill="#fdba74">يتطلب فهم الذكاء الاصطناعي للمعنى الدلالي الكامل Gemini 2.0 Flash (1M نافذة السياق)</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="115" font-size="9.5" fill="#fdba74">20-30 ألف صف من البيانات Gemini 1.5 Pro (1 مليون نافذة السياق)</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="137" font-size="9.5" fill="#fdba74">على استعداد لتحمل تكاليف عالية Claude 3.5 Sonnet(200K)</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#fdba74">المزايا سيناريوهات الاستخدام</text>
<text x="0" y="186" font-size="10" fill="#fed7aa">عملية بسيطة حجم البيانات < 5000 صف</text>
<text x="0" y="200" font-size="10" fill="#fed7aa">مناسبة للعلاقات المعقدة يمكن أن تتحمل رسوم API أعلى</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#431407" stroke="#f97316" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#fdba74" text-anchor="middle">عرض التفاصيل التكلفة: $1-5 / مرة</text>
الحل أ (موصى به بشدة): بيانات عينة + جعل الذكاء الاصطناعي يكتب نصًا برمجيًا
الفكرة الأساسية: بدلاً من جعل الذكاء الاصطناعي يعالج البيانات بالكامل مباشرةً، نجعله يفهم بنية البيانات ثم يولد نصًا برمجيًا للمعالجة يعمل محليًا.
خطوات التشغيل:
الخطوة الأولى: استخراج بيانات عينة (10 صفوف كافية)
import pandas as pd
# قراءة أول 10 صفوف كعينة (بما في ذلك رؤوس الأعمدة)
df_sample = pd.read_excel("your_data.xlsx", nrows=10)
# الإخراج بتنسيق نصي لسهولة النسخ إلى الذكاء الاصطناعي
print(df_sample.to_string())
print("\n--- نظرة عامة على البيانات ---")
print(f"إجمالي عدد الصفوف: {len(pd.read_excel('your_data.xlsx'))}")
print(f"أسماء الأعمدة: {list(df_sample.columns)}")
print(f"أنواع البيانات:\n{df_sample.dtypes}")
الخطوة الثانية: إرسال بيانات العينة والمتطلبات إلى الذكاء الاصطناعي
مثال على موجه:
فيما يلي عينة من أول 10 صفوف من بيانات Excel الخاصة بي ووصف هيكلها:
[الصق محتوى الإخراج من الخطوة السابقة]
يبلغ إجمالي البيانات 60 ألف صف. أحتاج إلى تحليل ما يلي:
1. إحصاء معدل إنجاز العملية حسب القسم
2. تحديد نقاط العملية التي يتجاوز متوسط وقت معالجتها ساعتين
3. إنشاء تقرير اتجاهات أسبوعي
الرجاء كتابة نص برمجي بايثون ليقرأ البيانات الكاملة ويخرج نتائج التحليل.
الخطوة الثالثة: تشغيل النص البرمجي الذي أنشأه الذكاء الاصطناعي محليًا
سيقوم الذكاء الاصطناعي، بناءً على بيانات العينة المكونة من 10 صفوف، بفهم معاني الحقول ثم إنشاء نص برمجي تحليلي كامل. عند تشغيل هذا النص البرمجي محليًا لمعالجة 60 ألف صف من البيانات بالكامل، لن تحتاج إلى استدعاء واجهة برمجة تطبيقات الذكاء الاصطناعي على الإطلاق، مما يعني استهلاك توكنز صفر.
مزايا الحل:
- استهلاك توكنز منخفض للغاية (10 صفوف عينة فقط ≈ بضع مئات من التوكنز)
- يمكن تشغيل النص البرمجي المحلي بشكل متكرر، وإعادة تشغيله مباشرة بعد تحديث البيانات
- مناسب للسيناريوهات التي تتطلب معالجة دورية لبيانات من نفس النوع
🎯 الأدوات الموصى بها: استخدم APIYI apiyi.com لاستدعاء Claude 3.5 Sonnet أو GPT-4o لإنشاء نصوص معالجة البيانات. تتفوق هذه النماذج بشكل ممتاز في مهام توليد التعليمات البرمجية، وعادةً ما لا يتجاوز استهلاك الطلب الواحد 2000 توكنز، مما يجعل التكلفة منخفضة للغاية.
الحل ب: معالجة البيانات على دفعات
حالات الاستخدام: عندما يتراوح عدد صفوف البيانات بين 5000 و 20 ألف صف، ويتطلب الأمر من الذكاء الاصطناعي فهم محتوى كل صف (مثل تحليل المشاعر، تصنيف النصوص).
خطوات التشغيل:
import pandas as pd
def process_in_batches(file_path, batch_size=500):
"""معالجة ملف Excel الكبير على دفعات"""
df = pd.read_excel(file_path)
total_rows = len(df)
results = []
for start in range(0, total_rows, batch_size):
end = min(start + batch_size, total_rows)
batch = df.iloc[start:end]
# تحويل هذه الدفعة من البيانات إلى نص CSV، ثم تمريرها إلى الذكاء الاصطناعي للمعالجة
batch_text = batch.to_csv(index=False)
print(f"تتم معالجة الصفوف من {start+1} إلى {end} (من إجمالي {total_rows} صفًا)")
# هنا يتم استدعاء واجهة برمجة تطبيقات الذكاء الاصطناعي لمعالجة batch_text
# result = call_ai_api(batch_text)
# results.append(result)
return results
تستهلك كل دفعة مكونة من 500 صف حوالي 25,000-40,000 توكنز، وتبلغ التكلفة الإجمالية لمعالجة 60 ألف صف من البيانات بالكامل باستخدام GPT-4o mini حوالي 0.5-1.5 دولار أمريكي.
ملاحظات هامة:
- بعد معالجة كل دفعة، يجب تجميع النتائج، مع الانتباه لدقة الإحصائيات عبر الدفعات.
- قد تؤدي المعالجة على دفعات إلى فقدان العلاقات بين الصفوف، وهي مناسبة للمهام المستقلة بين الصفوف.
الحل ج: المعالجة المسبقة للبيانات قبل الرفع
حالات الاستخدام: عندما تحتاج إلى تحليل الذكاء الاصطناعي للاتجاهات العامة وكتابة تقارير تحليلية، ولكن لا تحتاج إلى أن يرى الذكاء الاصطناعي كل صف من البيانات الأصلية.
خطوات التشغيل:
الخطوة 1: إنشاء ملخص للبيانات باستخدام جداول Excel المحورية أو Python
import pandas as pd
df = pd.read_excel("data.xlsx")
# توليد إحصائيات ملخصة
summary = {
"إجمالي عدد الصفوف": len(df),
"النطاق الزمني": f"{df['日期'].min()} إلى {df['日期'].max()}",
"الإحصاء حسب القسم": df.groupby('部门')['完成率'].mean().to_dict(),
"الاتجاه الشهري": df.groupby(df['日期'].dt.month)['处理时长'].mean().to_dict(),
"عدد البيانات الشاذة": len(df[df['处理时长'] > 120])
}
# تحويل الملخص إلى نص منظم، وتمريره إلى الذكاء الاصطناعي لكتابة تقرير التحليل
import json
print(json.dumps(summary, ensure_ascii=False, indent=2))
الخطوة 2: إعطاء البيانات الملخصة للذكاء الاصطناعي لكتابة تقرير التحليل
عادةً ما تكون البيانات الملخصة بضع مئات من الصفوف فقط، ولا تستهلك تقريبًا أي توكنز عند تمريرها إلى الذكاء الاصطناعي، ومع ذلك، يمكن للذكاء الاصطناعي إنشاء تحليل اتجاهات كامل وتقارير رؤى أعمال.
الحل د: اختيار نموذج لغة كبير ذي نافذة سياق ضخمة
حالات الاستخدام: عندما تحتاج حقًا إلى أن يفهم الذكاء الاصطناعي المحتوى الدلالي للبيانات بالكامل، وتكون مستعدًا لتحمل تكاليف أعلى.
| النموذج | أقصى نافذة سياق | حجم البيانات المناسب | التكلفة التقديرية |
|---|---|---|---|
| Gemini 1.5 Pro | مليون توكنز | حوالي 20-30 ألف صف | يتم الدفع حسب الاستخدام عبر APIYI |
| Gemini 2.0 Flash | مليون توكنز | حوالي 20-30 ألف صف | قيمة ممتازة مقابل السعر |
| Claude 3.5 Sonnet | 200 ألف توكنز | حوالي 3000-5000 صف | جودة توليد التعليمات البرمجية ممتازة |
💡 حتى عند استخدام نموذج لغة كبير ذي نافذة سياق ضخمة، يوصى بشدة بتنظيف البيانات أولاً (حذف الصفوف الفارغة، دمج الأعمدة المكررة، إزالة الحقول غير ذات الصلة) لتقليل استهلاك التوكنز وتجنب تجاوز حدود الخصم المسبق.
🎯 ميزة الواجهة الموحدة: من خلال منصة APIYI apiyi.com، يمكنك استخدام واجهة API موحدة لاستدعاء نماذج لغة كبيرة متعددة ذات سياق ضخم مثل Gemini و Claude و GPT، دون الحاجة إلى تسجيل حساب منفصل لكل نموذج، مما يسهل التبديل السريع ومقارنة التكاليف.
رابعًا: كيف تتجنب الوقوع في الأخطاء مرة أخرى
بعد فهم الحلول المذكورة أعلاه، إليك بعض أفضل الممارسات اليومية لمعالجة البيانات باستخدام الذكاء الاصطناعي.
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#ef4444"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#2d1414" stroke="#ef4444" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#fca5a5">الخطوة 2: تحميل البيانات 📊 زيادة هائلة في حجم التوكنات: ≈ 3 مليون توكن</text>
<text x="22" y="86" font-size="10" fill="#ef4444">تحميل جميع البيانات النصية إلى النموذج للتحليل 60,000 سطر × 10 عمود × 5 توكنز ≈ 3,000,000 توكنز</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#ef4444"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#3d0808" stroke="#dc2626" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#ff6b6b">الخطوة 3: انتظار النتائج 💥 خطأ API 402: رصيد غير كافٍ</text>
<text x="22" y="142" font-size="10" fill="#fca5a5">النموذج يعالج كميات كبيرة من البيانات، يستغرق وقتًا طويلاً وعرضة للأخطاء الخصم المسبق $9.00 > رصيد الحساب $5.20 -> فشل الطلب</text>
<!-- Problem stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">معدل النجاح استهلاك الرمز المميز</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#ef4444" text-anchor="middle">منخفض 3 ملايين</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">متوسط وقت المعالجة نتائج التحليل</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#ef4444" text-anchor="middle">ساعات أو أكثر ❌ تعذر الإكمال</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#2d0808" stroke="#dc2626" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#ff6b6b" text-anchor="middle">تكلفة باهظة، نتائج غير فعالة التكلفة المقدرة: $7.5+ و يتجاوز الحد الأقصى لنافذة السياق</text>
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#10b981"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#022c22" stroke="#10b981" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#6ee7b7">الخطوة 2: توليد السكريبت تدرك بنية الذكاء الاصطناعي، وتولد نص Python التحليلي</text>
<text x="22" y="86" font-size="10" fill="#34d399">تحميل بيانات العينة للسماح للذكاء الاصطناعي بتوليد سكريبت المعالجة يستهلك حوالي 1500-2000 توكن لإكمال توليد النص البرمجي</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#10b981"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#064e3b" stroke="#059669" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#34d399">الخطوة 3: التنفيذ المحلي 🚀 تشغيل برنامج نصي محليًا، لمعالجة كامل 60 ألف صف من البيانات</text>
<text x="22" y="142" font-size="10" fill="#a7f3d0">استخدام السكريبت المُولّد لمعالجة جميع البيانات محليًا بكفاءة يتم تنفيذ البرنامج النصي محليًا، ويتم حفظ النتائج في analysis.xlsx</text>
<!-- Success stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">معدل النجاح استهلاك التوكن</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#34d399" text-anchor="middle">مرتفع ~2000</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">متوسط وقت المعالجة نتائج التحليل</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#34d399" text-anchor="middle">دقائق ✅ كامل ودقيق</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#064e3b" stroke="#059669" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#34d399" text-anchor="middle">تكلفة منخفضة للغاية، نتائج فعالة التكلفة الفعلية: < 0.01 دولار أمريكي · يمكن إعادة استخدام البرنامج النصي بشكل متكرر</text>
طريقة تقدير التوكن قبل الاستخدام
قبل تحميل الملفات، يمكنك استخدام الطريقة التالية لتقدير كمية التوكن بسرعة:
import pandas as pd
def estimate_tokens(file_path):
"""تقدير تقريبي لعدد التوكن بعد تحويل ملف Excel إلى نص"""
df = pd.read_excel(file_path)
# تحويل البيانات إلى نص CSV
csv_text = df.to_csv(index=False)
# تقدير تقريبي: حوالي 4 أحرف/توكن للإنجليزية، وحوالي 1.5 حرف/توكن للصينية
char_count = len(csv_text)
estimated_tokens = char_count / 3.5 # متوسط للغات المختلطة (الصينية والإنجليزية)
print(f"عدد صفوف الملف: {len(df)}")
print(f"عدد أعمدة الملف: {len(df.columns)}")
print(f"عدد أحرف CSV: {char_count:,}")
print(f"عدد التوكنات المقدر: {estimated_tokens:,.0f}")
print(f"التكلفة المقدرة باستخدام GPT-4o ($2.5/1M): ${estimated_tokens/1_000_000*2.5:.4f}")
if estimated_tokens > 100_000:
print("⚠️ تحذير: تجاوز عدد التوكنات 100 ألف، يُنصح باستخدام الحل A (عينة + سكريبت)")
estimate_tokens("your_data.xlsx")
جدول الأخطاء الشائعة وحلولها
| ظاهرة الخطأ | السبب الجذري | الحل |
|---|---|---|
| يُبلغ عن "رصيد غير كافٍ" لكن يوجد رصيد | الخصم المسبق للتوكن يتجاوز رصيد الحساب | اشحن الرصيد أو استخدم الحل A/C |
| استجابة بطيئة جدًا أو انتهاء المهلة | عدد كبير جدًا من توكنات الإدخال، وقت استدلال طويل | قلل كمية بيانات الإدخال |
| نتائج تحليل الذكاء الاصطناعي غير دقيقة | كمية البيانات كبيرة جدًا، تأثير "الضياع في المنتصف" | تبسيط البيانات، واستخدام المعالجة الدفعية |
| الواجهة تُبلغ عن تجاوز طول السياق | تجاوز أقصى نافذة سياق للنموذج | استخدم نموذجًا ذا سياق أكبر أو المعالجة الدفعية |
| تكلفة عالية جدًا في كل مرة | تحميل كميات كبيرة من البيانات بشكل متكرر | استخدم الحل A لتوليد سكريبت محلي قابل لإعادة الاستخدام |
خامساً: تمرين عملي: تحليل بيانات عمليات يبلغ حجمها 60 ألف سطر
فيما يلي حالة عمل كاملة توضح العملية برمتها، من مواجهة التحديات إلى حلها.
الخلفية: لدى فريق العمليات بيانات كفاءة عمليات يبلغ حجمها 60 ألف سطر، تتضمن حقولاً مثل: القسم، اسم العملية، وقت البدء، وقت الانتهاء، المسؤول عن المعالجة، حالة الإنجاز. يرغبون في أن يحلل الذكاء الاصطناعي أي من نقاط العملية هي الأقل كفاءة.
الخطوة 1: استخراج العينة
import pandas as pd
# قراءة أول 10 أسطر
df = pd.read_excel("process_data.xlsx", nrows=10)
print("=== عينة البيانات (أول 10 أسطر) ===")
print(df.to_string())
print("\n=== وصف الحقول ===")
for col in df.columns:
print(f"- {col}: {df[col].dtype}, قيمة مثال: {df[col].iloc[0]}")
الخطوة 2: إرسالها إلى الذكاء الاصطناعي للحصول على نص التحليل
أرسل المحتوى الناتج أعلاه إلى الذكاء الاصطناعي، مع إرفاق وصف المتطلبات:
فيما يلي هيكل بيانات عملية Excel الخاصة بي و10 أسطر كعينة:
[الصق المحتوى الناتج هنا]
المتطلبات:
1. حساب متوسط مدة المعالجة لكل "اسم عملية" (وقت الانتهاء - وقت البدء)
2. إحصاء معدل إنجاز العملية حسب القسم (نسبة "الحالة المكتملة" = "مكتمل")
3. تحديد العمليات العشرة الأولى من حيث متوسط مدة المعالجة، وإخراجها في جدول
4. حفظ النتائج في analysis_result.xlsx
الرجاء كتابة نص Python برمجي كامل وقابل للتشغيل.
الخطوة 3: تشغيل النص البرمجي محلياً
سيقوم الذكاء الاصطناعي بإنشاء نص تحليلي مشابه لما يلي (نسخة مبسطة كمثال):
import pandas as pd
# قراءة البيانات كاملة
df = pd.read_excel("process_data.xlsx")
# حساب مدة المعالجة (بالدقائق)
df['处理时长_分钟'] = (
pd.to_datetime(df['结束时间']) - pd.to_datetime(df['开始时间'])
).dt.total_seconds() / 60
# إحصاء متوسط المدة حسب العملية
process_avg = (
df.groupby('流程名称')['处理时长_分钟']
.agg(['mean', 'count'])
.rename(columns={'mean': '平均时长', 'count': '总次数'})
.sort_values('平均时长', ascending=False)
)
# إحصاء معدل الإنجاز حسب القسم
dept_completion = (
df.groupby('部门')['完成状态']
.apply(lambda x: (x == '完成').mean() * 100)
.round(2)
.rename('完成率%')
)
# إخراج أبطأ 10 عمليات
print("=== أبطأ 10 نقاط عملية ===")
print(process_avg.head(10).to_string())
# حفظ النتائج
with pd.ExcelWriter("analysis_result.xlsx") as writer:
process_avg.to_excel(writer, sheet_name="流程效率分析")
dept_completion.to_excel(writer, sheet_name="部门完成率")
print("\n✅ تم حفظ نتائج التحليل في analysis_result.xlsx")
مقارنة استهلاك التوكنات للعملية بأكملها:
| الطريقة | استهلاك التوكنات | التكلفة التقديرية (GPT-4o) | جودة التحليل |
|---|---|---|---|
| الرفع المباشر لـ 60 ألف سطر | ~3 ملايين توكن | $7.5+ ويتجاوز نافذة السياق | لا يمكن إنجازه |
| الخطة أ (عينة + نص برمجي) | ~2000 توكن | < $0.01 | كامل ودقيق |
🎯 مقارنة التكلفة: استهلاك الخطة أ أقل من 0.1% من طريقة الرفع المباشر، كما أن نتائج التحليل أكثر دقة وقابلية لإعادة الاستخدام. نوصي باستخدام APIYI apiyi.com لاستدعاء GPT-4o أو Claude 3.5 Sonnet لإنشاء نصوص معالجة البيانات، فالنتائج ممتازة والتكلفة منخفضة للغاية.
سادساً: أسئلة متكررة (FAQ)
س1: ليس لدي أساس في بايثون، هل يمكنني استخدام هذه الخطة؟
بالتأكيد. جوهر الخطة أ هو "دع الذكاء الاصطناعي يكتب النص البرمجي، وأنت تقوم بتشغيله". كل ما عليك فعله هو:
- تثبيت بايثون (الموقع الرسمي: python.org، فقط اتبع خطوات التثبيت).
- تثبيت مكتبة pandas: اكتب في الطرفية
pip install pandas openpyxl - استخراج بيانات العينة وتقديمها للذكاء الاصطناعي ← يقوم الذكاء الاصطناعي بإنشاء النص البرمجي ← حفظه كملف
.py← تشغيله بالنقر المزدوج.
بالنسبة للمستخدمين غير المعتادين على سطر الأوامر، يمكنهم أيضاً استخدام Jupyter Notebook (المرفق مع حزمة تثبيت Anaconda)، وهو أكثر سهولة.
💡 على APIYI apiyi.com، يمكنك أيضاً استخدام ميزة مفسر الأكواد المدمج، مما يتيح للذكاء الاصطناعي إنشاء منطق النص البرمجي والتحقق منه مباشرة، مما يقلل من وقت التصحيح.
س2: بخلاف بايثون، هل توجد طرق أخرى لمعالجة البيانات الضخمة؟
نعم، فيما يلي عدة طرق مرتبة حسب سهولة الاستخدام:
- ميزات Excel المدمجة: الجداول المحورية (Pivot Tables) و Power Query، لا تتطلب برمجة، ومناسبة للإحصاءات التجميعية.
- مكتبة Python pandas: الأكثر مرونة، وكفاءة عالية في المعالجة، يوصى بها للمستخدمين المتوسطين والمتقدمين.
- Microsoft Copilot (إضافة لـ Excel): تحليل مباشر بالذكاء الاصطناعي داخل Excel، ولكن لا يزال هناك قيود على عدد الأسطر.
- أدوات تحليل البيانات المتخصصة: Tableau و Power BI تتصل بمصادر البيانات، ولديها قدرات قوية في معالجة البيانات الضخمة.
س3: ما هو الرصيد المناسب في الحساب لتجنب أخطاء الخصم المسبق؟
يعتمد ذلك على سيناريو استخدامك اليومي. بشكل عام، يُنصح بما يلي:
- مستخدمو المحادثات العادية: الاحتفاظ برصيد يتراوح بين 5 و 20 دولاراً.
- مستخدمو معالجة البيانات (الذين يرفعون الملفات أحياناً): الاحتفاظ برصيد يتراوح بين 20 و 50 دولاراً.
- مستخدمو استدعاءات API المتكررة: يُنصح بإعداد إعادة الشحن التلقائي، أو الاحتفاظ برصيد يزيد عن 100 دولار.
🎯 إدارة الرصيد: في لوحة تحكم APIYI apiyi.com، يمكنك عرض تفاصيل استهلاك التوكنات، وتعيين تنبيهات الاستخدام، لتجنب تأثير نقص الرصيد على العمليات. تدعم المنصة إعادة الشحن حسب الحاجة، ولا توجد متطلبات للحد الأدنى للإنفاق.
س4: بياناتي تتضمن خصوصية، هل يمكنني إرسال بيانات العينة إلى الذكاء الاصطناعي؟
الممارسات المعقولة هي:
- إزالة الحساسية قبل إرسالها إلى الذكاء الاصطناعي: استبدال الحقول الحساسة مثل الأسماء وأرقام الهواتف وبطاقات الهوية بقيم أمثلة (مثل "张三" ← "المستخدم أ").
- تقديم أسماء الحقول وأنواع البيانات فقط: عدم تقديم قيم محددة، بل إخبار الذكاء الاصطناعي بهيكل الحقول وأنواع البيانات فقط.
- حل النموذج المحلي: استخدام Ollama لتشغيل نموذج محلي (مثل Qwen2.5)، حيث لا تغادر البيانات الجهاز على الإطلاق.
ملخص
الخطأ الشائع الأكثر عند معالجة الذكاء الاصطناعي لبيانات Excel الضخمة هو الرفع المباشر للملفات الكاملة، مما يؤدي إلى انفجار الرموز (tokens)، وأخطاء الواجهة البرمجية (API)، وخروج التكاليف عن السيطرة. الفكرة الأساسية للحل بسيطة:
دع الذكاء الاصطناعي "يرى العينات ويكتب السكربتات"، بدلاً من "رؤية البيانات الكاملة وإجراء الحسابات".
نظرة عامة على سيناريوهات استخدام الحلول الأربعة:
| السيناريو | الحل الموصى به | الصعوبة |
|---|---|---|
| حجم البيانات > 10 آلاف سطر، يتطلب تحليلاً إحصائياً | الحل أ: عينة + سكربت | ⭐⭐ (يتطلب تشغيل بايثون) |
| حجم البيانات 5000-20 ألف سطر، يتطلب فهماً لكل سطر | الحل ب: معالجة على دفعات | ⭐⭐⭐ (يتطلب استدعاء API) |
| يتطلب تقارير اتجاهات فقط، لا يتطلب تحليلاً لكل سطر | الحل ج: ملخص المعالجة المسبقة | ⭐ (يمكن استخدام Excel فقط) |
| حجم البيانات < 5000 سطر، يمكن تحمل تكلفة أعلى | الحل د: نموذج لغة كبير ذو سياق واسع | ⭐ (رفع مباشر) |
جرب الحل أ الآن: استخرج أول 10 صفوف من ملف Excel الخاص بك، وعلى APIYI apiyi.com، اختر GPT-4o أو Claude 3.5 Sonnet، وأخبر الذكاء الاصطناعي باحتياجاتك التحليلية، ودعه يولد سكربت المعالجة — معظم مهام تحليل البيانات، يمكن إنجازها بأقل من 0.01 دولار.
🎯 ابدأ بسرعة: قم بزيارة APIYI apiyi.com، وسجل لتجربة مجموعة متنوعة من النماذج الرائدة. يدعم استدعاء واجهة برمجية موحدة لـ OpenAI و Claude و Gemini وغيرها، ويتم الفوترة بناءً على الاستهلاك الفعلي، بدون رسوم شهرية أو حد أدنى للإنفاق. مناسب لفرق العمل والمستخدمين الأفراد لمعالجة مختلف مهام تحليل البيانات.
تم إعداد هذه المقالة بواسطة الفريق التقني لـ APIYI، استناداً إلى ملاحظات المستخدمين الحقيقية وتجارب الاختبار الفعلية. لأي أسئلة أو اقتراحات، نرحب بتواصلكم معنا عبر apiyi.com.