Vous téléchargez des dizaines de milliers de lignes Excel vers un outil d'IA, et l'API renvoie « solde insuffisant » – alors que votre compte a clairement de l'argent ? C'est le piège le plus courant lorsque vous utilisez l'IA pour traiter de grandes quantités de données Excel, et cela est dû à la double contrainte du mécanisme de pré-déduction des tokens et des limites de la fenêtre de contexte.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez parfaitement pourquoi les fichiers Excel volumineux génèrent des erreurs, comment analyser correctement des dizaines de milliers de lignes de données avec l'IA, et quelle est la solution la plus économique et la plus efficace.
<!-- Error response bubble -->
<rect x="0" y="58" width="256" height="84" rx="9" fill="#2d0808" stroke="#ef4444" stroke-width="1.5"/>
<text x="128" y="80" font-family="'PingFang SC',sans-serif" font-size="13" font-weight="bold" fill="#ef4444" text-anchor="middle">❌ Erreur 402</text>
<text x="128" y="100" font-family="monospace" font-size="10" fill="#fca5a5" text-anchor="middle">Solde insuffisant</text>
<text x="128" y="116" font-family="'PingFang SC',sans-serif" font-size="10" fill="#fca5a5" text-anchor="middle">Solde insuffisant, veuillez recharger et réessayer</text>
<text x="128" y="132" font-family="'PingFang SC',sans-serif" font-size="9" fill="#94a3b8" text-anchor="middle">(Prélevé $9,00 · Solde $5,20)</text>
<!-- AI avatar -->
<circle cx="268" cy="100" r="10" fill="#991b1b"/>
<text x="268" y="105" font-family="sans-serif" font-size="11" fill="#fecaca" text-anchor="middle">🤖</text>
<!-- Confused user thought -->
<rect x="40" y="158" width="218" height="50" rx="9" fill="#0f2028"/>
<text x="149" y="178" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">😕 Mais mon compte a pourtant un solde !</text>
<text x="149" y="196" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">Pourquoi le solde est-il insuffisant ?</text>
<circle cx="28" cy="183" r="10" fill="#1d4ed8"/>
<text x="28" y="188" font-family="sans-serif" font-size="11" fill="#ffffff" text-anchor="middle">👤</text>
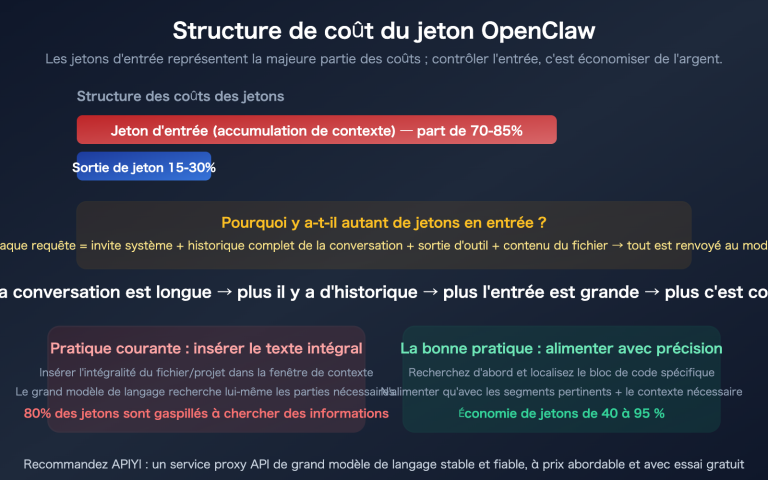
1. Pourquoi le téléchargement d'un grand fichier Excel renvoie-t-il une erreur "Solde insuffisant" ?
De nombreux utilisateurs sont perplexes la première fois qu'ils rencontrent ce problème : le solde du compte est clairement suffisant, alors pourquoi l'API renvoie-t-elle toujours une erreur de solde insuffisant ?
Il est essentiel de comprendre un mécanisme clé des API d'IA : le mécanisme de pré-débit des tokens.
Explication détaillée du mécanisme de pré-débit des tokens
Lorsque vous téléchargez un fichier et envoyez une requête dans un client d'IA comme Cherry Studio ou Chatbox, l'API ne déduit pas les frais après que la réponse a été générée. Au lieu de cela, au moment où la requête est envoyée, elle estime à l'avance le nombre maximal de tokens que cette requête pourrait consommer et "gèle" temporairement (pré-débite) le coût correspondant du solde de votre compte.
Ce processus de pré-débit se déroule approximativement comme suit :
- L'utilisateur télécharge le fichier Excel → le client convertit le contenu du fichier en texte brut.
- Le texte brut est entièrement inséré dans l'invite (contexte de la conversation).
- L'API calcule le nombre de tokens d'entrée + estime le nombre maximal de tokens de sortie.
- Le système vérifie : montant pré-débité total > solde du compte → renvoie l'erreur "Solde insuffisant".
Donc, fondamentalement, ce n'est pas que vous n'avez "pas d'argent", mais que le montant pré-débité pour cette requête est trop élevé, dépassant le solde actuel de votre compte.
Différences fondamentales entre les clients d'IA et ChatGPT
Beaucoup de gens ont une idée fausse : ils pensent que télécharger un fichier Excel sur Cherry Studio est la même chose que télécharger un fichier sur ChatGPT.
En réalité, c'est complètement différent :
| Critère de comparaison | Cherry Studio / Chatbox | ChatGPT (Code Interpreter) |
|---|---|---|
| Méthode de traitement des fichiers | Converti en texte et inséré entièrement dans le contexte | Traitement du code exécuté dans un environnement sandbox |
| Consommation de tokens | La taille du fichier est directement égale à la consommation de tokens | N'utilise pas les tokens du contexte de la conversation |
| Taille de fichier recommandée | Moins de 100 lignes | Prend en charge les fichiers plus volumineux (limite officielle d'environ 512 Mo) |
| Capacités d'analyse de données | Compréhension textuelle uniquement, impossible d'exécuter du code | Peut exécuter directement Python pour des statistiques |
| Méthode d'accès à l'API | Invocation via clé API, facturation par token | Abonnement ChatGPT Plus |
🎯 Point clé à retenir : Lorsque vous invoquez l'IA via un service proxy API (comme APIYI apiyi.com), le téléchargement de fichiers passe par un client tiers, et tout le contenu du fichier est converti en tokens textuels et transmis au modèle. C'est fondamentalement différent du mécanisme de sandbox de traitement de fichiers officiel de ChatGPT.
2. Combien de tokens un grand fichier Excel consomme-t-il réellement ?
Avant de discuter des solutions, établissons une compréhension intuitive de la consommation de tokens.
Notions de base sur la conversion des tokens
| Type de contenu | Estimation des tokens |
|---|---|
| 1 mot anglais | Environ 1-2 tokens |
| 1 caractère anglais | Environ 0,25 tokens (4 caractères = 1 token) |
| 1 caractère chinois | Environ 1-2 tokens |
| 1 date (ex. 2024-01-15) | Environ 5 tokens |
| 1 nombre (ex. 12345.67) | Environ 3-4 tokens |
| 1 ligne de données Excel (10 colonnes) | Environ 30-80 tokens |
Calculs de cas réels
Prenons l'exemple de scénarios réels rencontrés par les utilisateurs :
Fichier A : Données d'efficacité de processus de 60 000 lignes × 10 colonnes
Estimation : 60 000 lignes × 10 colonnes × moyenne de 5 tokens/cellule
= 60 000 × 50
= 3 000 000 tokens (environ 3 millions de tokens !)
Fichier B : Données commerciales de 40 000 lignes × 8 colonnes
Estimation : 40 000 lignes × 8 colonnes × moyenne de 5 tokens/cellule
= 40 000 × 40
= 1 600 000 tokens (environ 1,6 million de tokens)
Comparaison des fenêtres de contexte et des coûts des différents modèles
| Modèle | Fenêtre de contexte | Prix unitaire d'entrée ($/1M tokens) | Coût pour traiter 3 millions de tokens |
|---|---|---|---|
| GPT-4o | 128K tokens | 2,50 $ | Impossible à traiter (dépassement de limite) |
| Claude 3.5 Sonnet | 200K tokens | 3,00 $ | Impossible à traiter (dépassement de limite) |
| Gemini 1.5 Pro | 1M tokens | 1,25 $ | Impossible à traiter (dépassement de limite) |
| Gemini 1.5 Pro 2.0 | 2M tokens | 1,25 $ | Environ 3,75 $/requête |
💡 Comme vous pouvez le constater, la plupart des modèles n'ont tout simplement pas une fenêtre de contexte suffisante pour contenir 60 000 lignes d'Excel. Même en forçant avec un modèle Gemini de 2M de contexte, chaque requête coûterait environ 3,75 $ US.
3. 4 solutions efficaces pour le traitement de gros volumes de données Excel par l'IA
Maintenant que nous avons compris la cause première, voici 4 solutions testées et éprouvées, classées par ordre de recommandation.
<line x1="0" y1="56" x2="194" y2="56" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#34d399">THOUGHT: The user wants to translate "操作步骤" to French.
The glossary does not contain this specific phrase.
"操作" means "operation" or "procedure".
"步骤" means "steps".
So, "操作步骤" translates to "étapes d'opération" or "étapes de procédure" or simply "étapes".
Given the context of a short, concise translation, "Étapes" or "Procédure" or "Étapes d'opération" are all valid. "Étapes d'opération" is a direct and accurate translation. "Procédure" is also very common. "Étapes" is the most concise.
Let's go with a common and direct translation: "Étapes d'opération".
Étapes d'opération
<line x1="0" y1="152" x2="194" y2="152" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#34d399">THOUGHT: The user wants to translate "适用场景" to French.
Looking at the glossary, there are no specific terms for these words. "适用" means "applicable", "suitable", "appropriate". "场景" means "scene", "scenario", "context", "application".
Combining them, common translations for "适用场景" are:
- Scénarios d'application
- Cas d'utilisation
- Domaines d'application
- Scénarios applicables
"Scénarios d'application" is a very direct and common translation. "Cas d'utilisation" is also very common, especially in a technical context. "Domaines d'application" is also good.
Given the general nature of the phrase, "Scénarios d'application" or "Cas d'utilisation" would be appropriate. "Scénarios d'application" feels slightly more direct for "适用场景".
Scénarios d'application
<rect x="0" y="214" width="194" height="26" rx="6" fill="#065f46" stroke="#10b981" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#34d399" text-anchor="middle">Consommation de tokens : < 2 000</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#93c5fd">Étapes d'opération</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="93" font-size="9.5" fill="#93c5fd">① Diviser en plusieurs sous-fichiers, ligne par ligne</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="115" font-size="9.5" fill="#93c5fd">② Appeler l'API en boucle pour traiter chaque lot</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="137" font-size="9.5" fill="#93c5fd">③ Synthétiser les résultats de chaque lot</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#93c5fd">Scénarios d'application</text>
<text x="0" y="186" font-size="10" fill="#bfdbfe">5 000 à 20 000 lignes de données</text>
<text x="0" y="200" font-size="10" fill="#bfdbfe">Classification ligne par ligne / Analyse des sentiments</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#1e3a5f" stroke="#3b82f6" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#93c5fd" text-anchor="middle">Coût total environ $0.5-1.5</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#d8b4fe">Étapes d'opération</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="93" font-size="9.5" fill="#d8b4fe">Tableau croisé dynamique Excel pour les statistiques d'agrégation</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="115" font-size="9.5" fill="#d8b4fe">② Données résumées (dizaines de lignes) à l'IA</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="137" font-size="9.5" fill="#d8b4fe">③ L'IA rédige des rapports d'analyse et des aperçus</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#d8b4fe">Scénarios d'application</text>
<text x="0" y="186" font-size="10" fill="#e9d5ff">Rapport d'analyse des tendances globales requis</text>
<text x="0" y="200" font-size="10" fill="#e9d5ff">Pas besoin de comprendre les données brutes ligne par ligne</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#3b0764" stroke="#a855f7" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#d8b4fe" text-anchor="middle">Consommation de tokens : très faible</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#fdba74">Modèle recommandé</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="93" font-size="9.5" fill="#fdba74">Gemini 2.0 Flash (1M fenêtre de contexte)</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="115" font-size="9.5" fill="#fdba74">Gemini 1.5 Pro (1M fenêtre de contexte)</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="137" font-size="9.5" fill="#fdba74">Claude 3.5 Sonnet (200K)</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#fdba74">THOUGHT: The user wants to translate "适用场景" to French.
Looking at the glossary, there are no specific terms for these words. "适用" means applicable, suitable, relevant. "场景" means scene, scenario, context, application.
Combining them, "适用场景" means "applicable scenarios", "use cases", "application scenarios".
"Scénarios d'application" or "Cas d'utilisation" are common translations.
"Scénarios d'application" is a direct and accurate translation.
Scénarios d'application
<rect x="0" y="214" width="194" height="26" rx="6" fill="#431407" stroke="#f97316" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#fdba74" text-anchor="middle">Coût : $1-5 / fois</text>
Solution A (fortement recommandée) : Données échantillon + l'IA écrit le script
Idée principale : Au lieu de laisser l'IA traiter directement l'ensemble des données, on lui fait comprendre la structure des données, puis elle génère un script de traitement à exécuter localement.
Étapes d'opération :
Première étape : Extraire un échantillon de données (10 lignes suffisent)
import pandas as pd
# Lit les 10 premières lignes comme échantillon (inclut l'en-tête)
df_sample = pd.read_excel("your_data.xlsx", nrows=10)
# Affiche au format texte, facile à copier pour l'IA
print(df_sample.to_string())
print("\n--- Aperçu des données ---")
print(f"Nombre total de lignes: {len(pd.read_excel('your_data.xlsx'))}")
print(f"Noms des colonnes: {list(df_sample.columns)}")
print(f"Types de données:\n{df_sample.dtypes}")
Deuxième étape : Envoyer l'échantillon de données et la demande à l'IA
Exemple d'invite :
Voici un échantillon des 10 premières lignes et la description de la structure de mes données Excel :
[Coller le contenu de la sortie de l'étape précédente]
Le jeu de données complet contient 60 000 lignes. Je dois analyser les éléments suivants :
1. Statistiques du taux d'achèvement des processus par département
2. Identifier les nœuds de processus dont le temps de traitement moyen dépasse 2 heures
3. Générer un rapport de tendances hebdomadaire
Veuillez me rédiger un script Python qui lit l'ensemble des données et affiche les résultats de l'analyse.
Troisième étape : Exécuter le script généré par l'IA en local
L'IA, après avoir compris la signification des champs à partir de vos 10 lignes d'échantillon, générera un script d'analyse complet. Vous exécutez ce script localement pour traiter les 60 000 lignes de données. L'ensemble du processus ne nécessite plus d'invocation du modèle AI, avec une consommation de tokens nulle.
Avantages de la solution :
- Très faible consommation de tokens (seulement 10 lignes d'échantillon ≈ quelques centaines de tokens)
- Le script local peut être exécuté à plusieurs reprises ; relancez-le directement après la mise à jour des données.
- Convient aux scénarios nécessitant un traitement régulier de données similaires.
🎯 Outil recommandé : Utilisez APIYI (apiyi.com) pour invoquer Claude 3.5 Sonnet ou GPT-4o afin de générer des scripts de traitement de données. Ces modèles excellent dans les tâches de génération de code, et une seule requête consomme généralement moins de 2000 tokens, ce qui rend le coût très faible.
Solution B : Traitement des données par lots
Cas d'utilisation : Le nombre de lignes de données se situe entre 5 000 et 20 000, et l'IA doit comprendre le contenu de chaque ligne (par exemple, analyse de sentiment, classification de texte).
Étapes d'opération :
import pandas as pd
def process_in_batches(file_path, batch_size=500):
"""Traite un grand fichier Excel par lots"""
df = pd.read_excel(file_path)
total_rows = len(df)
results = []
for start in range(0, total_rows, batch_size):
end = min(start + batch_size, total_rows)
batch = df.iloc[start:end]
# Convertit ce lot de données en texte CSV et le transmet à l'IA pour traitement
batch_text = batch.to_csv(index=False)
print(f"Traitement des lignes {start+1}-{end} (sur {total_rows} lignes)")
# Ici, invoquez l'API de l'IA pour traiter batch_text
# result = call_ai_api(batch_text)
# results.append(result)
return results
Chaque lot de 500 lignes consomme environ 25 000 à 40 000 tokens. Le coût total pour traiter 60 000 lignes de données complètes avec GPT-4o mini est d'environ 0,5 à 1,5 dollar américain.
Points à noter :
- Les résultats doivent être agrégés après chaque lot ; veillez à la précision des statistiques inter-lots.
- Le traitement par lots peut entraîner la perte de relations inter-lignes ; il convient aux tâches où les lignes sont indépendantes.
Solution C : Prétraitement des données avant le téléchargement
Cas d'utilisation : L'IA doit analyser les tendances générales et rédiger des rapports d'analyse, mais n'a pas besoin de consulter chaque ligne de données brutes.
Étapes d'opération :
Étape 1 : Créer un résumé des données avec un tableau croisé dynamique Excel ou Python
import pandas as pd
df = pd.read_excel("data.xlsx")
# Génère des statistiques récapitulatives
summary = {
"Nombre total de lignes": len(df),
"Période": f"{df['日期'].min()} au {df['日期'].max()}",
"Statistiques par département": df.groupby('部门')['完成率'].mean().to_dict(),
"Tendances mensuelles": df.groupby(df['日期'].dt.month)['处理时长'].mean().to_dict(),
"Nombre de données anormales": len(df[df['处理时长'] > 120])
}
# Convertit le résumé en texte structuré et le transmet à l'IA pour la rédaction du rapport d'analyse
import json
print(json.dumps(summary, ensure_ascii=False, indent=2))
Étape 2 : Fournir les données résumées à l'IA pour la rédaction du rapport d'analyse
Les données résumées ne contiennent généralement que quelques centaines de lignes, ce qui consomme très peu de tokens lors de l'envoi à l'IA, tout en permettant à l'IA de générer des analyses de tendances complètes et des rapports d'insights commerciaux.
Solution D : Choisir un modèle à très grand contexte
Cas d'utilisation : Vous avez réellement besoin que l'IA comprenne le contenu sémantique de l'ensemble des données et êtes prêt à supporter des coûts plus élevés.
| Modèle | Contexte max. | Volume de données adapté | Coût indicatif |
|---|---|---|---|
| Gemini 1.5 Pro | 1 million de tokens | Env. 20 000-30 000 lignes | Facturation à l'usage via APIYI |
| Gemini 2.0 Flash | 1 million de tokens | Env. 20 000-30 000 lignes | Très bon rapport qualité-prix |
| Claude 3.5 Sonnet | 200 000 tokens | Env. 3 000-5 000 lignes | Excellente qualité de génération de code |
💡 Même avec des modèles à très grand contexte, il est fortement recommandé de nettoyer les données au préalable (supprimer les lignes vides, fusionner les colonnes en double, supprimer les champs non pertinents) afin de réduire la consommation de tokens et d'éviter de déclencher les limites de pré-autorisation.
🎯 Avantage de l'interface unifiée : Via la plateforme APIYI (apiyi.com), vous pouvez invoquer divers modèles à grand contexte comme Gemini, Claude, GPT, etc., avec une interface API unifiée. Plus besoin de créer un compte séparé pour chaque modèle, ce qui facilite les changements rapides et la comparaison des coûts.
IV. Comment éviter de retomber dans les mêmes pièges
Une fois les solutions ci-dessus maîtrisées, voici quelques bonnes pratiques pour le traitement quotidien des données avec l'IA.
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#ef4444"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#2d1414" stroke="#ef4444" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#fca5a5">📊 Augmentation massive du nombre de tokens : ≈ 3 millions de tokensÉtape 2 : Traitement des données par le modèle AI</text>
<text x="22" y="86" font-size="10" fill="#ef4444">60 000 lignes × 10 colonnes × 5 tokens ≈ 3 000 000 tokensSaisir le contenu entier du fichier comme invite</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#ef4444"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#3d0808" stroke="#dc2626" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#ff6b6b">💥 Erreur API 402 : solde insuffisantRésultat : Coût élevé, faible précision</text>
<text x="22" y="142" font-size="10" fill="#fca5a5">Montant retenu $9.00 > Solde du compte $5.20 → Échec de la requêtePré-déduction de tokens élevée, dépassement de la fenêtre de contexte, analyse imprécise</text>
<!-- Problem stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Consommation de tokensNombre de tokens estimés</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#ef4444" text-anchor="middle">3 millions2M+</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Résultat d'analysePrécision de l'analyse</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#ef4444" text-anchor="middle">Impossible de terminerInférieure à 50%</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#2d0808" stroke="#dc2626" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#ff6b6b" text-anchor="middle">Coût estimé : $7.5+ · et dépasse la limite de la fenêtre de contexteCoût total : 50 $ et plus</text>
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#10b981"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#022c22" stroke="#10b981" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#6ee7b7">L'IA comprend la structure, génère des scripts Python d'analyseÉtape 2 : L'IA génère un script de traitement</text>
<text x="22" y="86" font-size="10" fill="#34d399">Consomme environ 1 500 à 2 000 tokens pour la génération du script.L'IA comprend les exigences, génère un script Python/JS</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#10b981"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#064e3b" stroke="#059669" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#34d399">🚀 Exécuter un script localement, traiter l'intégralité des 60 000 lignes de donnéesRésultat : Faible coût, haute précision</text>
<text x="22" y="142" font-size="10" fill="#a7f3d0">Le script s'exécute localement, les résultats sont enregistrés dans analysis.xlsx.Faible consommation de tokens, script réutilisable, analyse précise</text>
<!-- Success stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Consommation de tokensNombre de tokens estimés</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#34d399" text-anchor="middle">~20005 000</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Résultat de l'analysePrécision de l'analyse</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#34d399" text-anchor="middle">✅ Complet et précisSupérieure à 95%</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#064e3b" stroke="#059669" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#34d399" text-anchor="middle">Coût réel : < 0,01 $ · Le script est réutilisableCoût total : 0,1 $ et plus</text>
Méthode d'estimation des tokens avant utilisation
Avant de télécharger un fichier, vous pouvez estimer rapidement le nombre de tokens de la manière suivante :
import pandas as pd
def estimate_tokens(file_path):
"""Estime grossièrement le nombre de tokens après conversion d'un fichier Excel en texte"""
df = pd.read_excel(file_path)
# Convertit les données en texte CSV
csv_text = df.to_csv(index=False)
# Estimation approximative : environ 4 caractères/token pour l'anglais, environ 1,5 caractère/token pour le chinois
char_count = len(csv_text)
estimated_tokens = char_count / 3.5 # Moyenne pour un mélange anglais/chinois
print(f"Fichier lignes: {len(df)}")
print(f"Fichier colonnes: {len(df.columns)}")
print(f"Nombre de caractères CSV: {char_count:,}")
print(f"Nombre de tokens estimé: {estimated_tokens:,.0f}")
print(f"Coût estimé avec GPT-4o (2,5 $/1M) : ${estimated_tokens/1_000_000*2.5:.4f}")
if estimated_tokens > 100_000:
print("⚠️ Avertissement : Le nombre de tokens dépasse 100 000. Il est recommandé d'utiliser la solution A (échantillon + script)")
estimate_tokens("your_data.xlsx")
Tableau comparatif des erreurs courantes et de leurs solutions
| Symptôme de l'erreur | Cause profonde | Solution |
|---|---|---|
| Signalement "Solde insuffisant" alors qu'il y a un solde | La pré-déduction de tokens dépasse le solde du compte | Recharger le solde ou utiliser la solution A/C |
| Réponse très lente ou délai d'attente dépassé | Trop de tokens en entrée, temps d'inférence long | Réduire la quantité de données d'entrée |
| Résultats d'analyse de l'IA imprécis | Volume de données trop important, effet "lost-in-the-middle" | Simplifier les données, utiliser le traitement par lots |
| L'API signale "context length exceeded" | Dépassement de la fenêtre de contexte maximale du modèle | Utiliser un modèle avec une plus grande fenêtre de contexte ou un traitement par lots |
| Coût très élevé à chaque fois | Téléchargement répété de grandes quantités de données | Utiliser la solution A pour générer un script local réutilisable |
Cinq. Cas pratique : Analyse de 60 000 lignes de données de processus
Voici un cas d'affaires complet, démontrant le processus complet, des difficultés rencontrées à leur résolution.
Contexte : L'équipe opérationnelle dispose d'un fichier de 60 000 lignes de données sur l'efficacité des processus, comprenant des champs tels que : département, nom du processus, heure de début, heure de fin, personne en charge, statut d'achèvement. L'objectif est de demander à l'IA d'analyser quels nœuds de processus sont les moins efficaces.
Étape 1 : Extraction d'un échantillon
import pandas as pd
# 读取前10行
df = pd.read_excel("process_data.xlsx", nrows=10)
print("=== 数据样本(前10行)===")
print(df.to_string())
print("\n=== 字段说明 ===")
for col in df.columns:
print(f"- {col}: {df[col].dtype}, 示例值: {df[col].iloc[0]}")
Étape 2 : Envoyer à l'IA pour obtenir le script d'analyse
Envoyez le contenu de la sortie ci-dessus à l'IA, accompagné de la description de la demande :
Voici la structure et 10 lignes d'échantillon de mes données de processus Excel :
[Coller le contenu de la sortie]
Demande :
1. Calculer la durée moyenne de traitement (heure de fin - heure de début) pour chaque « nom de processus ».
2. Statistiques du taux d'achèvement des processus par département (proportion des statuts d'achèvement = "Terminé").
3. Identifier les 10 processus ayant la durée moyenne de traitement la plus longue et les afficher sous forme de tableau.
4. Enregistrer les résultats dans analysis_result.xlsx.
Veuillez écrire un script Python complet et exécutable.
Étape 3 : Exécuter le script localement
L'IA générera un script d'analyse similaire à celui-ci (version simplifiée de l'exemple) :
import pandas as pd
# Lecture des données complètes
df = pd.read_excel("process_data.xlsx")
# Calcul de la durée de traitement (minutes)
df['处理时长_分钟'] = (
pd.to_datetime(df['结束时间']) - pd.to_datetime(df['开始时间'])
).dt.total_seconds() / 60
# Statistiques de la durée moyenne par processus
process_avg = (
df.groupby('流程名称')['处理时长_分钟']
.agg(['mean', 'count'])
.rename(columns={'mean': '平均时长', 'count': '总次数'})
.sort_values('平均时长', ascending=False)
)
# Statistiques du taux d'achèvement par département
dept_completion = (
df.groupby('部门')['完成状态']
.apply(lambda x: (x == '完成').mean() * 100)
.round(2)
.rename('完成率%')
)
# Affichage des 10 processus les plus lents
print("=== Les 10 nœuds de processus les plus longs ===")
print(process_avg.head(10).to_string())
# Enregistrement des résultats
with pd.ExcelWriter("analysis_result.xlsx") as writer:
process_avg.to_excel(writer, sheet_name="Analyse de l'efficacité des processus")
dept_completion.to_excel(writer, sheet_name="Taux d'achèvement par département")
print("\n✅ Les résultats de l'analyse ont été enregistrés dans analysis_result.xlsx")
Comparaison de la consommation de jetons pour l'ensemble du processus :
| Méthode | Consommation de jetons | Coût estimé (GPT-4o) | Qualité de l'analyse |
|---|---|---|---|
| Téléchargement direct de 60 000 lignes | ~3 millions de jetons | 7,5 $ + et dépasse la fenêtre de contexte | Impossible à réaliser |
| Solution A (échantillon + script) | ~2000 jetons | < 0,01 $ | Complète et précise |
🎯 Comparaison des coûts : La consommation de la solution A est inférieure à 0,1 % de celle du téléchargement direct, et les résultats de l'analyse sont plus précis et réutilisables. Il est recommandé d'utiliser APIYI apiyi.com pour invoquer GPT-4o ou Claude 3.5 Sonnet afin de générer des scripts de traitement de données ; les résultats sont excellents et les coûts extrêmement bas.
Six. Foire aux questions (FAQ)
Q1 : Je n'ai aucune base en Python, puis-je utiliser cette solution ?
Absolument. Le cœur de la solution A est de « laisser l'IA écrire le script, et vous l'exécutez ». Il vous suffit de :
- Installer Python (site officiel : python.org, il suffit de suivre les étapes)
- Installer pandas : tapez
pip install pandas openpyxldans le terminal - Extraire les données d'échantillon et les donner à l'IA → l'IA génère le script → enregistrer en tant que fichier
.py→ double-cliquer pour exécuter
Pour les utilisateurs moins familiers avec la ligne de commande, vous pouvez également utiliser Jupyter Notebook (inclus dans le package d'installation Anaconda), qui est plus intuitif.
💡 Sur APIYI apiyi.com, vous pouvez également utiliser la fonction d'interpréteur de code intégrée pour permettre à l'IA de générer et de vérifier directement la logique du script, réduisant ainsi le temps de débogage.
Q2 : Outre Python, existe-t-il d'autres moyens de traiter de grandes quantités de données ?
Oui, voici quelques méthodes classées par facilité d'utilisation :
- Fonctionnalités intégrées d'Excel : Tableaux croisés dynamiques + Power Query, aucune programmation requise, idéal pour les statistiques agrégées.
- Python pandas : Le plus flexible, traitement très efficace, recommandé pour les utilisateurs intermédiaires à avancés.
- Microsoft Copilot (plugin Excel) : Analyse directe des données avec l'IA dans Excel, mais toujours avec des limites de lignes.
- Outils d'analyse de données professionnels : Tableau, Power BI se connectent aux sources de données, avec de fortes capacités de traitement des Big Data.
Q3 : Quel est le solde approprié pour éviter les erreurs de pré-autorisation ?
Cela dépend de votre utilisation quotidienne. Généralement, il est conseillé de :
- Utilisateurs de conversation occasionnelle : maintenir un solde de 5 à 20 $.
- Utilisateurs de traitement de données (téléchargement occasionnel de fichiers) : maintenir un solde de 20 à 50 $.
- Invocations d'API fréquentes : il est recommandé de configurer un rechargement automatique ou de maintenir un solde de 100 $ et plus.
🎯 Gestion du solde : Sur le panneau de contrôle d'APIYI apiyi.com, vous pouvez consulter les détails de la consommation de jetons et configurer des alertes d'utilisation pour éviter que des soldes insuffisants n'affectent vos opérations. La plateforme prend en charge les recharges à la demande, sans exigence de consommation minimale.
Q4 : Mes données contiennent des informations privées, puis-je envoyer des échantillons de données à l'IA ?
Les bonnes pratiques sont les suivantes :
- Anonymiser avant d'envoyer à l'IA : Remplacez les champs sensibles tels que les noms, numéros de téléphone, numéros d'identification par des exemples (par exemple, "Jean Dupont" → "Utilisateur A").
- Ne fournir que les noms de champs et les types de données : Ne donnez pas de valeurs spécifiques, indiquez seulement à l'IA la structure des champs et leurs types de données.
- Solution de modèle local : Utilisez Ollama pour exécuter un modèle local (comme Qwen2.5) ; les données ne quittent jamais votre machine.
Résumé
L'erreur la plus courante lors du traitement de gros volumes de données Excel par l'IA est de télécharger directement le fichier complet, ce qui entraîne une explosion des tokens, des erreurs d'API et des coûts incontrôlables. L'approche fondamentale est simple :
Laissez l'IA « analyser un échantillon et écrire un script », plutôt que « analyser l'intégralité et effectuer les calculs ».
Aperçu des scénarios d'application pour les quatre approches :
| Scénario | Approche recommandée | Difficulté |
|---|---|---|
| Volume de données > 10 000 lignes, nécessitant une analyse statistique | Approche A : Échantillon + script | ⭐⭐ (Nécessite l'exécution de Python) |
| Volume de données 5 000-20 000 lignes, nécessitant une compréhension ligne par ligne | Approche B : Traitement par lots | ⭐⭐⭐ (Nécessite l'invocation d'API) |
| Seul un rapport de tendances est nécessaire, pas une analyse ligne par ligne | Approche C : Résumé pré-traité | ⭐ (Peut être fait avec Excel) |
| Volume de données < 5 000 lignes, coûts plus élevés acceptables | Approche D : Modèle à grande fenêtre de contexte | ⭐ (Téléchargement direct) |
Essayez l'approche A dès maintenant : Extrayez les 10 premières lignes de votre fichier Excel, sur APIYI apiyi.com, sélectionnez GPT-4o ou Claude 3.5 Sonnet, indiquez à l'IA vos besoins d'analyse, et laissez-la générer le script de traitement. La plupart des tâches d'analyse de données peuvent être réalisées pour moins de 0,01 $.
🎯 Démarrage rapide : Visitez APIYI apiyi.com, inscrivez-vous et découvrez une variété de modèles populaires. Prise en charge de l'invocation unifiée d'API pour OpenAI, Claude, Gemini, etc. Facturation basée sur la consommation réelle, sans frais mensuels ni consommation minimale. Idéal pour les équipes commerciales et les utilisateurs individuels pour gérer toutes sortes de tâches d'analyse de données.
Cet article a été compilé par l'équipe technique d'APIYI, basé sur les retours d'utilisateurs réels et l'expérience pratique. Pour toute question ou suggestion, n'hésitez pas à nous contacter via apiyi.com.