Google DeepMind lanzó oficialmente el Gemini 3.1 Flash-Lite Preview el 3 de marzo de 2026. Este es el modelo más rápido y de menor costo de la serie Gemini 3. Basado en la arquitectura Gemini 3 Pro, su velocidad de salida alcanza aproximadamente 380 tokens/s, siendo 2.5 veces más rápido en la respuesta del primer token que Gemini 2.5 Flash y con una velocidad de salida 45% mayor.
Valor central: Este artículo te ayudará a comprender completamente este nuevo modelo ligero recién lanzado, evaluando si es adecuado para tus escenarios de negocio, desde 5 dimensiones: rendimiento de referencia, comparación de costos, características funcionales, casos de uso y acceso a la API.

Vista rápida de los parámetros clave de Gemini 3.1 Flash-Lite Preview
A continuación se presentan los parámetros técnicos clave extraídos de la documentación oficial de Google AI y la ficha técnica de DeepMind:
| Parámetro | Gemini 3.1 Flash-Lite Preview | Descripción |
|---|---|---|
| ID del Modelo | gemini-3.1-flash-lite-preview |
Usa este ID para invocar la API |
| Arquitectura Base | Gemini 3 Pro | Hereda la arquitectura multimodal de nivel Pro |
| Ventana de Contexto | 1,048,576 tokens (1M) | Aprox. 1,500 páginas de documento A4 |
| Salida Máxima | 65,536 tokens (64K) | Soporta generación de texto largo |
| Velocidad de Salida | ~380 tokens/s | Posición #2 entre 132 modelos |
| Precio de Entrada | $0.25 / millón de tokens | El más bajo de la serie Gemini 3 |
| Precio de Salida | $1.50 / millón de tokens | 1/8 del precio de la versión Pro |
| Corte de Conocimiento | Enero 2025 | Coincide con Gemini 3 Pro |
| Estado | Vista previa (Preview) | Versión preliminar, lanzamiento oficial pendiente |
Es importante destacar que Gemini 3.1 Flash-Lite Preview está construido sobre la arquitectura Gemini 3 Pro, lo que significa que, en un tamaño "reducido", conserva las capacidades de comprensión multimodal de nivel Pro. Google lo posiciona como el modelo preferido para "tareas frecuentes y ligeras".
🎯 Recomendación de acceso: Gemini 3.1 Flash-Lite Preview ya está disponible en APIYI apiyi.com, con precios idénticos a los oficiales de Google. Recarga desde 100 USD y recibe 10 USD de bonificación, con descuentos de hasta el 20%. Accede de forma unificada a más de 400 Modelos de Lenguaje Grande.
5 Ventajas Principales de Gemini 3.1 Flash-Lite Preview
Ventaja 1: Inferencia Ultrarrápida — Velocidad de Salida de 380 tok/s
La velocidad de salida de Gemini 3.1 Flash-Lite Preview alcanza aproximadamente 380 tokens/s. Según los datos de evaluación de Artificial Analysis, ocupa el puesto 2 entre 132 modelos principales. En comparación con los 249 tok/s de la generación anterior, Gemini 2.5 Flash, el rendimiento mejora en aproximadamente un 45%.
El Tiempo de Respuesta del Primer Token (TTFT) es aún más destacado: 2.5 veces más rápido que Gemini 2.5 Flash. Esta mejora es significativa para escenarios de aplicación que requieren retroalimentación instantánea, como chatbots o traducción en tiempo real.
Ventaja 2: Costo Extremadamente Bajo — Solo $0.25/M tokens de Entrada
Dentro de la serie Gemini 3, Flash-Lite cuesta solo 1/8 del precio de la versión Pro. Específicamente:
| Modelo | Precio de Entrada | Precio de Salida | Tarifa Mixta (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25/M | $1.50/M | $0.56/M |
| Gemini 3 Pro | $2.00/M | $12.00/M | $4.50/M |
| Claude 4.5 Haiku | $1.00/M | $5.00/M | $2.00/M |
| GPT-5 mini | $0.15/M | $0.60/M | $0.26/M |
Flash-Lite logra un equilibrio excepcional entre precio y rendimiento. Aunque no es el más barato en términos absolutos, su relación costo-rendimiento es extremadamente alta considerando su velocidad de salida de 380 tok/s y su ventana de contexto de 1M tokens.
Ventaja 3: Ventana de Contexto de un Millón de Tokens
Una ventana de contexto de 1,048,576 tokens significa que puedes procesar en una sola solicitud:
- Aproximadamente 1,500 páginas de documentos A4
- Repositorios de código completos
- Contenido de audio/vídeo de varias horas de duración
Esta es una configuración muy poco común en modelos ligeros. En comparación, GPT-5 mini solo admite 128K y Claude 4.5 Haiku admite 200K.
Ventaja 4: Soporte para Entrada Multimodal Completa
Aunque se posiciona como un modelo ligero, Gemini 3.1 Flash-Lite Preview admite 5 modalidades de entrada:
- Texto: Capacidad central
- Imagen: Análisis y comprensión del contenido de imágenes
- Audio: Transcripción y análisis de voz
- Vídeo: Comprensión del contenido de vídeo
- PDF: Análisis y resumen de documentos
En cuanto a la salida, solo admite texto, pero esto es suficiente para la mayoría de las tareas de procesamiento y análisis de datos.
Ventaja 5: Soporte para Thinking Mode
Como modelo ligero, Gemini 3.1 Flash-Lite Preview sorprendentemente admite el Thinking Mode (Modo de Pensamiento Extendido), algo casi único entre modelos de su categoría. Al habilitarlo, el modelo realiza un razonamiento paso a paso, mejorando significativamente la precisión en tareas como conocimiento científico o cálculos matemáticos.
🎯 Recomendación de Plataforma: ¿Quieres probar rápidamente el rendimiento del Thinking Mode de Gemini 3.1 Flash-Lite Preview? Puedes invocarlo directamente a través de APIYI apiyi.com, que ofrece una interfaz unificada para más de 400 Modelos de Lenguaje Grande principales.
Datos de Pruebas de Referencia de Gemini 3.1 Flash-Lite Preview
A continuación, se presentan los datos de evaluación de la ficha técnica de Google DeepMind y Artificial Analysis:
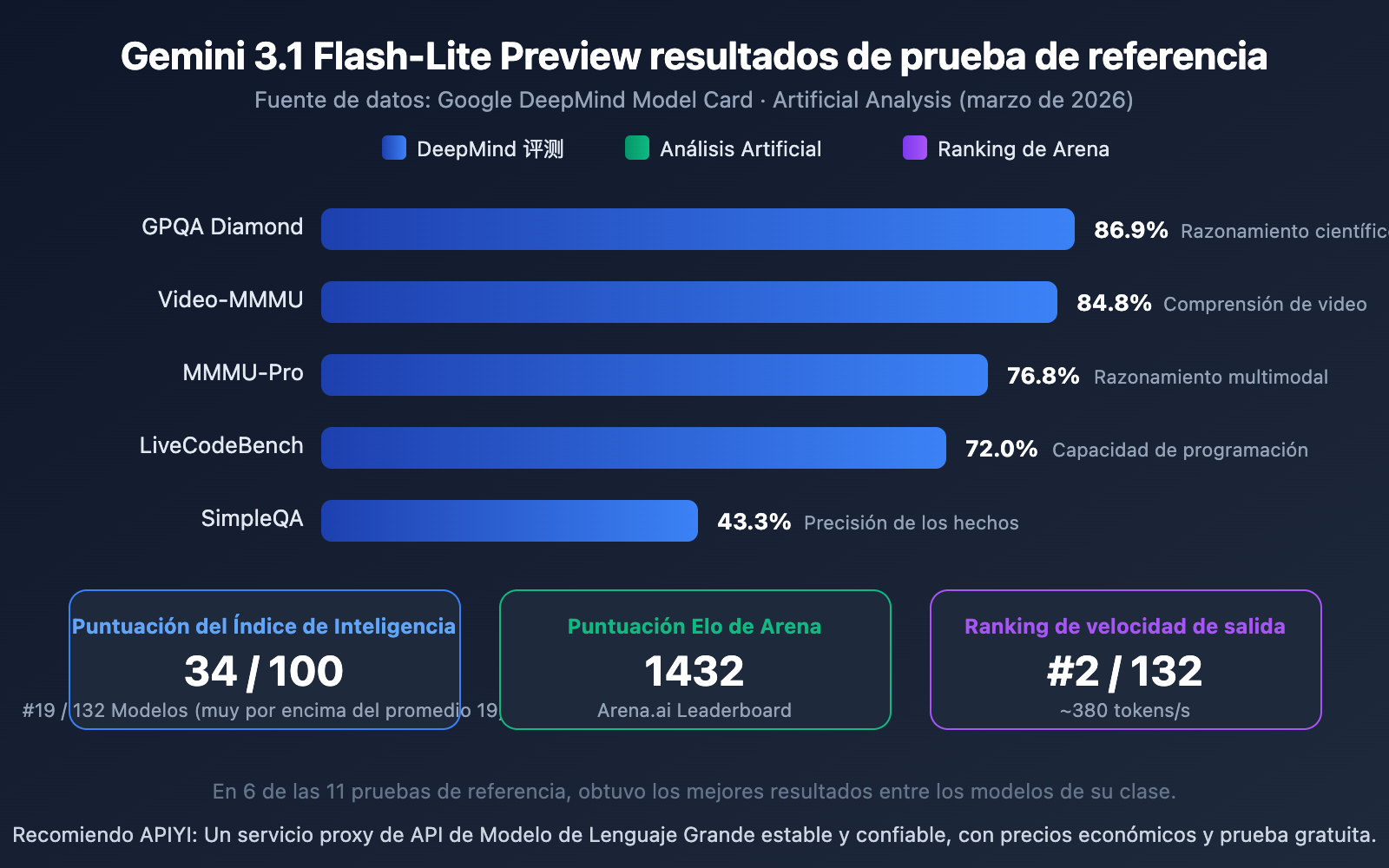
Interpretación de las Pruebas de Referencia de Gemini 3.1 Flash-Lite Preview
Según los datos, el rendimiento de Flash-Lite entre los modelos ligeros es bastante destacado:
- GPQA Diamond 86.9%: Su capacidad de razonamiento de conocimiento científico lidera entre modelos de su categoría.
- Video-MMMU 84.8%: Refleja su ventaja multimodal en comprensión de vídeo.
- MMMU-Pro 76.8%: Excelente rendimiento en razonamiento multimodal.
- Arena Elo 1432: Obtiene una puntuación alta en el ranking de Arena.ai, lo que demuestra una buena experiencia de uso real.
- Índice de Inteligencia 34/100: Muy por encima del promedio de 19 para modelos de su categoría, ocupando el puesto 19 entre 132 modelos.
En 11 pruebas de referencia, Flash-Lite logró los mejores resultados en su categoría en 6 de ellas, un desempeño sobresaliente para un modelo ligero.
🎯 Recomendación para Pruebas Reales: Los datos de las pruebas de referencia son solo una referencia; la efectividad real varía según el escenario. Se recomienda realizar pruebas en escenarios reales a través de APIYI apiyi.com. La plataforma ofrece créditos gratuitos y permite comparar rápidamente múltiples modelos.
Comparación de Gemini 3.1 Flash-Lite Preview con la competencia

| Dimensión de comparación | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| Velocidad de salida | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| Precio de entrada | $0.25/M | $1.00/M | $0.15/M ⚡ |
| Precio de salida | $1.50/M | $5.00/M | $0.60/M ⚡ |
| Ventana de contexto | 1M tokens ⚡ | 200K tokens | 128K tokens |
| Entrada multimodal | 5 tipos ⚡ | 2 tipos | 2 tipos |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
Resumen de la comparación:
- Prioridad velocidad: Los 380 tok/s de Flash-Lite son 3.5 veces más que Haiku y 5.4 veces más que GPT-5 mini.
- Prioridad costo: GPT-5 mini tiene un precio absoluto más bajo, pero la ventaja de velocidad de Flash-Lite puede compensar la diferencia de costo.
- Prioridad funcionalidad: Flash-Lite lidera claramente en longitud de contexto (1M) y soporte multimodal (5 tipos).
🎯 Recomendación de elección: Qué modelo ligero elegir depende del escenario específico. Te recomendamos realizar pruebas de comparación práctica a través de APIYI apiyi.com, ya que la plataforma soporta una interfaz unificada para todos los modelos anteriores, facilitando el cambio rápido y la evaluación.
Inicio rápido con Gemini 3.1 Flash-Lite Preview
Ejemplo mínimo
Aquí tienes el código más simple para invocar Gemini 3.1 Flash-Lite Preview a través de la plataforma APIYI, listo para ejecutar en 10 líneas:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "Explica la computación cuántica en una oración"}]
)
print(response.choices[0].message.content)
Ver código de implementación completo (incluye Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Invoca Gemini 3.1 Flash-Lite Preview
Args:
prompt: Entrada del usuario
system_prompt: Indicación del sistema
max_tokens: Número máximo de tokens de salida
enable_thinking: Si habilitar el Thinking Mode
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Ejemplo de uso
result = call_flash_lite(
prompt="Analiza la complejidad temporal del siguiente código y da sugerencias de optimización",
system_prompt="Eres un ingeniero de algoritmos senior"
)
print(result)
Recomendación: Obtén una clave API y créditos de prueba gratuitos a través de APIYI apiyi.com para verificar rápidamente el rendimiento de Gemini 3.1 Flash-Lite Preview en tu escenario. Recarga de $100 USD o más y recibe $10 USD de regalo, con descuentos de hasta el 20%.
Escenarios de aplicación de Gemini 3.1 Flash-Lite Preview
Escenarios de uso recomendados
| Escenario | Descripción | ¿Por qué elegir Flash-Lite? |
|---|---|---|
| Traducción a gran escala | Flujos de trabajo de traducción de contenido multilingüe | Salida ultrarrápida de 380 tok/s + bajo costo |
| Moderación de contenido | Clasificación y filtrado de contenido generado por usuarios | Invocaciones de alta frecuencia + costos controlables |
| Extracción de datos | Extracción y organización de datos estructurados | Admite salida con JSON Schema |
| Enrutamiento para Agentes | Como capa de enrutamiento para distribuir solicitudes | Latencia ultrabaja + Function Calling |
| Procesamiento de documentos | Análisis y resumen de PDFs/documentos largos | Ventana de contexto de 1M + entrada multimodal |
| Transcripción de audio | Conversión de voz a texto y análisis | Admite entrada de audio nativa |
Escenarios no recomendados
- Escritura creativa compleja: Los modelos de nivel Pro tienen más ventajas en creación en profundidad.
- Generación de imágenes/audio: Flash-Lite solo admite salida de texto.
- Diálogo en tiempo real con streaming: No es compatible con Live API.
- Necesidad de la máxima precisión de razonamiento: Para escenarios que requieren una precisión extrema, se recomienda usar Gemini 3.1 Pro.
🎯 Recomendación de escenario: ¿No estás seguro de qué modelo es el más adecuado para tu caso de uso? A través de APIYI apiyi.com puedes cambiar y comparar rápidamente entre Gemini 3.1 Flash-Lite, Claude Haiku y GPT-5 mini para encontrar la solución óptima.
Preguntas frecuentes
P1: ¿Cuál es la diferencia entre Gemini 3.1 Flash-Lite Preview y Gemini 2.5 Flash?
La diferencia clave radica en la arquitectura y el rendimiento: Flash-Lite se basa en la arquitectura de Gemini 3 Pro (no en la de Gemini 2), con una respuesta del primer token 2.5 veces más rápida y una velocidad de salida mejorada en un 45%, alcanzando ~380 tok/s. Además, añade funciones avanzadas como el Modo de Pensamiento (Thinking Mode) y la ejecución de código.
P2: ¿Qué tan estable es la versión Preview? ¿Es adecuada para entornos de producción?
Las funciones y el rendimiento de la versión Preview pueden ajustarse en la versión final. Se recomienda probarla primero en tareas no críticas y establecer un plan de contingencia para las críticas. Al invocarla a través de APIYI apiyi.com, puedes cambiar fácilmente entre modelos, implementando una estrategia de contingencia flexible.
P3: ¿Cómo puedo comenzar a probar Gemini 3.1 Flash-Lite Preview rápidamente?
Se recomienda realizar pruebas a través de una plataforma de agregación de API que admita múltiples modelos:
- Visita APIYI apiyi.com y regístrate para obtener una cuenta.
- Obtén tu clave API y el crédito gratuito.
- Utiliza los ejemplos de código de este artículo, configurando el parámetro
modelcomogemini-3.1-flash-lite-preview. - Con una recarga de 100 USD o más, recibes 10 USD de bonificación y puedes disfrutar de descuentos de hasta el 20%.
Resumen
Puntos clave de Gemini 3.1 Flash-Lite Preview:
- Rendimiento ultrarrápido: Velocidad de salida de ~380 tokens/s, clasificado 2º entre 132 modelos. El tiempo de respuesta del primer token es 2.5 veces más rápido que el de Gemini 2.5 Flash.
- Alta relación costo-eficacia: Entrada a $0.25/M, salida a $1.50/M, solo 1/8 del costo de Gemini 3 Pro. Ideal para invocaciones de alta frecuencia y a gran escala.
- Funcionalidad completa: Ventana de contexto de 1M + 5 modalidades de entrada + Modo Thinking + Function Calling. La configuración más completa entre los modelos ligeros.
- ADN de nivel Pro: Basado en la arquitectura de Gemini 3 Pro, con un rendimiento sobresaliente en pruebas de referencia como GPQA Diamond (86.9%).
Para escenarios de aplicaciones de IA que requieren gran escala, bajo costo y alta velocidad, Gemini 3.1 Flash-Lite Preview es actualmente uno de los modelos ligeros más destacados a considerar.
Se recomienda probarlo rápidamente a través de APIYI (apiyi.com). Los precios de la plataforma son idénticos a los oficiales de Google, con un bono de $10 por recarga mínima de $100 y descuentos de hasta el 20%. Accede de manera integral a más de 400 Modelos de Lenguaje Grande.
📚 Referencias
-
Documentación oficial de modelos de Google AI: Especificaciones técnicas completas de Gemini 3.1 Flash-Lite Preview
- Enlace:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - Descripción: Documentación oficial de la API, incluye la lista más reciente de parámetros y funciones.
- Enlace:
-
Model Card de Google DeepMind: Datos de pruebas de referencia y evaluación de seguridad
- Enlace:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - Descripción: Model Card oficial, incluye resultados detallados de pruebas de referencia e información de entrenamiento.
- Enlace:
-
Evaluación de Artificial Analysis: Análisis independiente de rendimiento y precios
- Enlace:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - Descripción: Incluye datos de evaluación independiente sobre velocidad de salida, TTFT, índice de inteligencia, etc.
- Enlace:
-
Blog oficial de Google: Anuncio del lanzamiento de Gemini 3.1 Flash-Lite
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - Descripción: Artículo oficial de lanzamiento, presenta el posicionamiento del producto y sus características principales.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Bienvenidos a discutir en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com.