Al desarrollar aplicaciones de IA con Qwen3-Max, encontrarse con el error 429 You exceeded your current quota es un dolor de cabeza recurrente para muchos desarrolladores. Este artículo analiza a fondo el mecanismo de límite de velocidad de Qwen3-Max de Alibaba Cloud y ofrece 5 soluciones prácticas para ayudarte a decir adiós a los problemas de cuota insuficiente.
Valor central: Al terminar de leer, comprenderás el funcionamiento de los límites de Qwen3-Max, dominarás varias soluciones y elegirás la mejor forma de realizar llamadas estables a este Modelo de Lenguaje Grande de billones de parámetros.
Descripción general de los problemas de límite de velocidad en Qwen3-Max
Información de error típica
Cuando tu aplicación llama con frecuencia a la API de Qwen3-Max, podrías encontrarte con el siguiente error:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
Este error significa que has activado los límites de cuota de Alibaba Cloud Model Studio.
Impacto de los límites en Qwen3-Max
| Escenario de impacto | Manifestación específica | Severidad |
|---|---|---|
| Desarrollo de Agentes | Interrupciones frecuentes en diálogos | Alta |
| Procesamiento por lotes | Las tareas no se pueden completar | Alta |
| Aplicaciones en tiempo real | Experiencia de usuario degradada | Alta |
| Generación de código | Salida de código largo truncada | Media |
| Pruebas y depuración | Reducción de la eficiencia en el desarrollo | Media |
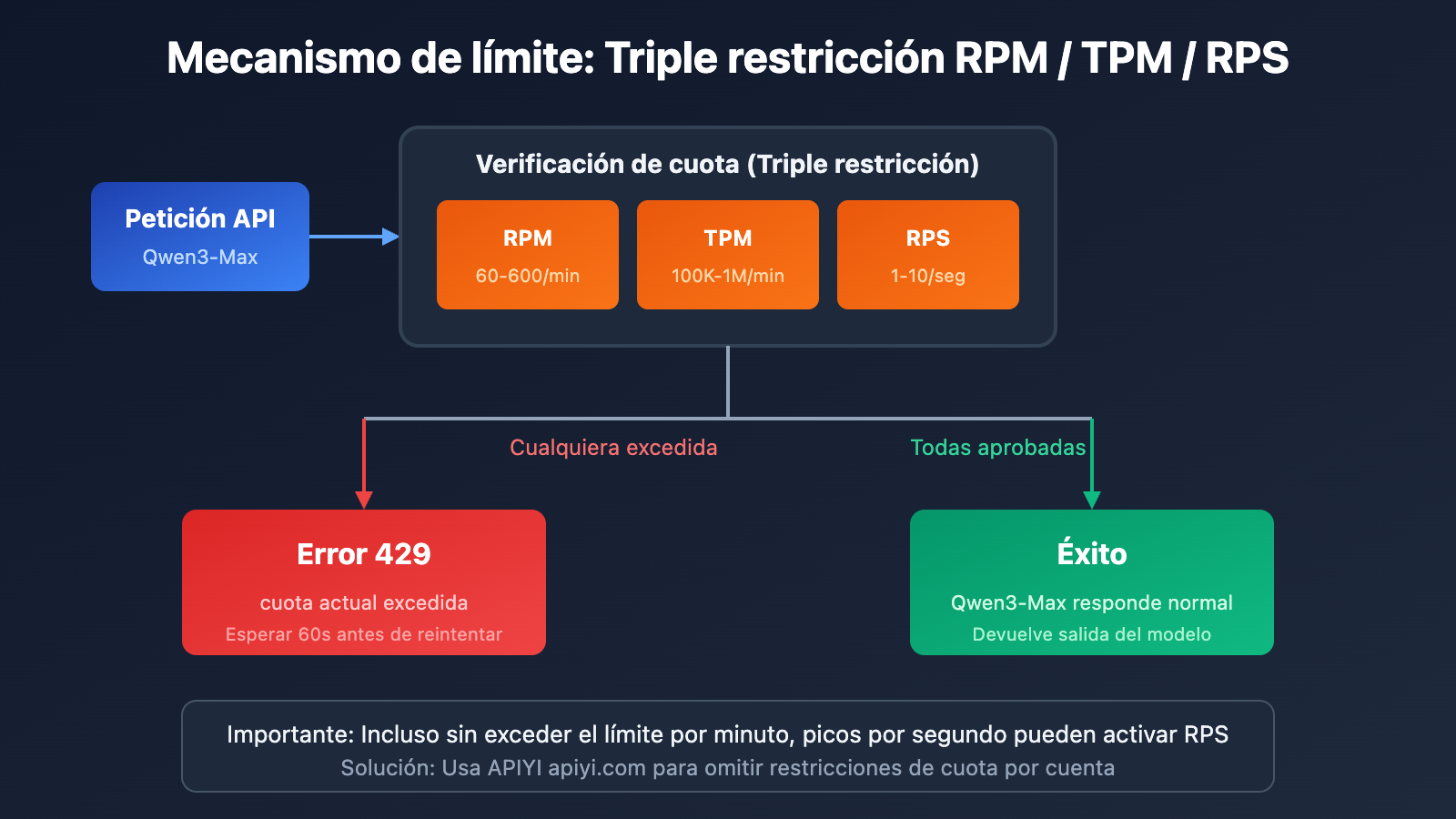
Detalles del mecanismo de límite de velocidad de Qwen3-Max
Restricciones de cuota oficial de Alibaba Cloud
Según la documentación oficial de Alibaba Cloud Model Studio, las restricciones de cuota para Qwen3-Max son las siguientes:
| Versión del modelo | RPM (Peticiones/min) | TPM (Tokens/min) | RPS (Peticiones/seg) |
|---|---|---|---|
| qwen3-max | 600 | 1.000.000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100.000 | 1 |
4 situaciones que activan el límite de velocidad de Qwen3-Max
Alibaba Cloud implementa un mecanismo de doble restricción para Qwen3-Max; si se cumple cualquiera de estas condiciones, se devolverá un error 429:
| Tipo de error | Mensaje de error | Causa de activación |
|---|---|---|
| Frecuencia excedida | Requests rate limit exceeded | RPM/RPS supera el límite |
| Consumo de tokens excedido | You exceeded your current quota | TPM/TPS supera el límite |
| Protección contra picos | Request rate increased too quickly | Aumento súbito de peticiones instantáneas |
| Cuota gratuita agotada | Free allocated quota exceeded | Se ha agotado el saldo de prueba |
Fórmula de cálculo de límites
Límite real = min(Límite RPM, RPS × 60)
= min(Límite TPM, TPS × 60)
Nota importante: Incluso si no se supera el límite a nivel de minuto, las ráfagas de peticiones a nivel de segundo pueden activar el limitador.
5 soluciones para los problemas de límite de velocidad de Qwen3-Max
Resumen comparativo de soluciones
| Solución | Dificultad | Efecto | Coste | Escenario recomendado |
|---|---|---|---|---|
| Servicio API Intermediario | Baja | Resolución total | Más económico | Todos los escenarios |
| Estrategia de suavizado | Media | Mitigación | Gratis | Límite ligero |
| Rotación de cuentas | Alta | Mitigación | Alto | Usuarios corporativos |
| Degradación a modelo de respaldo | Media | Red de seguridad | Medio | Tareas no críticas |
| Solicitar aumento de cuota | Baja | Limitado | Gratis | Usuarios a largo plazo |
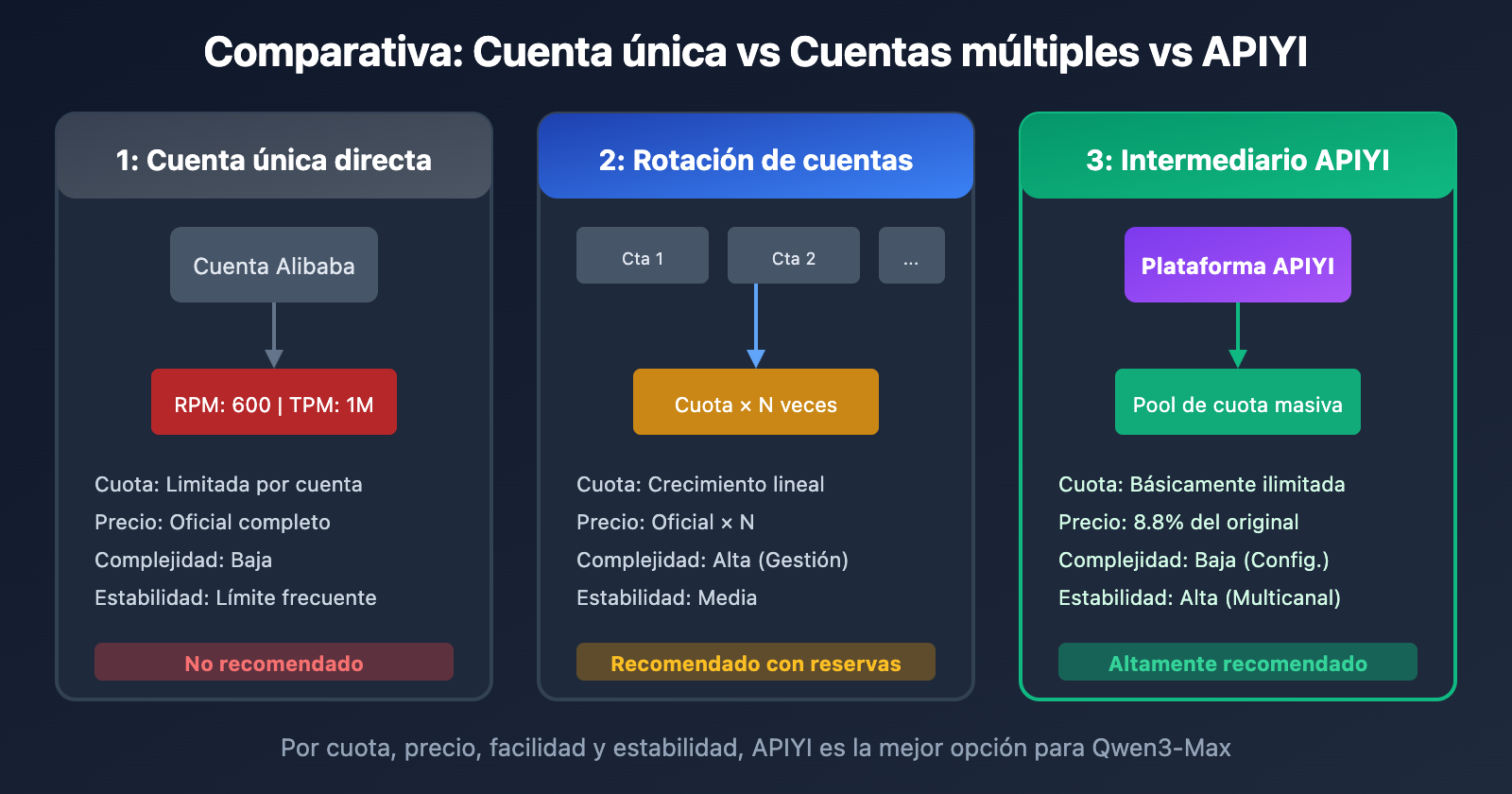
Solución 1: Uso de un servicio API intermediario (Recomendado)
Esta es la solución más directa y eficaz para resolver los límites de Qwen3-Max. Al llamar a través de una plataforma intermediaria (Proxy API), puedes omitir las restricciones de cuota impuestas a nivel de cuenta individual en Alibaba Cloud.
¿Por qué un intermediario de API resuelve el límite?
| Comparativa | Conexión directa Alibaba | Mediante APIYI |
|---|---|---|
| Restricción de cuota | Límite RPM/TPM por cuenta | Pool compartido a nivel de plataforma |
| Frecuencia de bloqueo | Error 429 frecuente | Prácticamente sin límites |
| Precio | Precio oficial | 8.8% del precio original (por defecto) |
| Estabilidad | Sujeto a cuota de cuenta | Garantía multicanal |
Ejemplo de código simplificado
from openai import OpenAI
# Usa el servicio de APIYI para olvidarte de los límites de velocidad
client = OpenAI(
api_key="tu-llave-apiyi",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "Explica cómo funciona la arquitectura MoE"}
]
)
print(response.choices[0].message.content)
🎯 Solución recomendada: Al llamar a Qwen3-Max a través de APIYI (apiyi.com), no solo resuelves por completo el problema del límite de velocidad, sino que también disfrutas de un precio equivalente al 8.8% del oficial. APIYI colabora directamente con los canales de Alibaba Cloud para ofrecer un servicio más estable a un menor coste.
Ver código completo (incluye reintentos y manejo de errores)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Cliente Qwen3-Max a través de APIYI, sin problemas de límites"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Interfaz intermediaria de APIYI
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
Envía un mensaje y obtiene respuesta.
Al usar APIYI, es muy poco probable encontrar límites de velocidad.
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# Con APIYI raramente se activará esta excepción
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Petición limitada, reintentando en {wait_time} segundos...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"Error de API: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""Procesamiento por lotes sin preocuparse por los límites"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# Ejemplo de uso
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="tu-llave-apiyi")
# Llamada única
response = client.chat("Escribe un algoritmo de QuickSort en Python")
print(response)
# Llamadas por lotes - Sin preocupaciones de velocidad con APIYI
questions = [
"Explica qué es la arquitectura MoE",
"Compara Transformer con RNN",
"¿Qué es el mecanismo de atención?"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"Q: {q}\nA: {a}\n")
Solución 2: Estrategia de suavizado de peticiones
Si prefieres seguir usando la conexión directa con Alibaba Cloud, puedes mitigar el problema suavizando la frecuencia de tus peticiones.
Reintento con retroceso exponencial (Exponential Backoff)
import time
import random
def call_with_backoff(func, max_retries=5):
"""Estrategia de reintento con retroceso exponencial"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# Retroceso exponencial + fluctuación aleatoria (jitter)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Límite alcanzado, esperando {wait_time:.2f} segundos para reintentar...")
time.sleep(wait_time)
else:
raise e
Búfer de cola de peticiones
import asyncio
from collections import deque
class RequestQueue:
"""Cola de peticiones para suavizar la frecuencia de llamadas a Qwen3-Max"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # Intervalo entre peticiones
self.last_request = 0
async def throttled_request(self, request_func):
"""Petición con limitación controlada"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
Nota: El suavizado de peticiones solo mitiga el problema, no lo resuelve por completo. Para escenarios de alta concurrencia, se recomienda el uso del servicio intermediario APIYI.
Solución 3: Rotación de múltiples cuentas
Los usuarios empresariales pueden aumentar su cuota total mediante la rotación entre varias cuentas.
from itertools import cycle
class MultiAccountClient:
"""Cliente con rotación de múltiples cuentas"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| Número de cuentas | RPM equivalente | TPM equivalente | Complejidad de gestión |
|---|---|---|---|
| 1 | 600 | 1.000.000 | Baja |
| 3 | 1.800 | 3.000.000 | Media |
| 5 | 3.000 | 5.000.000 | Alta |
| 10 | 6.000 | 10.000.000 | Muy alta |
💡 Sugerencia: La gestión de múltiples cuentas es compleja y costosa. Es mucho más eficiente usar el servicio de APIYI (apiyi.com), donde accedes a un pool de cuota masiva sin tener que administrar cuentas individuales.
Solución 4: Degradación a modelo de respaldo
Cuando Qwen3-Max alcance su límite, el sistema puede cambiar automáticamente a un modelo de respaldo.
class FallbackClient:
"""Cliente Qwen con soporte para degradación (fallback)"""
MODEL_PRIORITY = [
"qwen3-max", # Opción preferida
"qwen-plus", # Respaldo 1
"qwen-turbo", # Respaldo 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Uso de APIYI
)
def chat(self, message: str) -> tuple[str, str]:
"""Devuelve (contenido de la respuesta, modelo realmente utilizado)"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"{model} limitado, intentando degradación...")
continue
raise e
raise Exception("Ningún modelo disponible en este momento")
Solución 5: Solicitar aumento de cuota
Para usuarios con un uso estable a largo plazo, es posible solicitar un aumento de cuota directamente a Alibaba Cloud.
Pasos para la solicitud:
- Inicia sesión en la consola de Alibaba Cloud.
- Ve a la página de gestión de cuotas de Model Studio.
- Envía una solicitud de aumento de cuota.
- Espera la revisión (suele tardar entre 1 y 3 días hábiles).
Requisitos:
- Cuenta con verificación de identidad real.
- Sin registros de deudas pendientes.
- Proporcionar una descripción clara del escenario de uso.
Comparativa de costes frente a los límites de velocidad de Qwen3-Max
Análisis comparativo de precios
| Proveedor | Precio de entrada (0-32K) | Precio de salida | Estado del límite de velocidad |
|---|---|---|---|
| Conexión directa Alibaba Cloud | $1.20/M | $6.00/M | Restricciones estrictas de RPM/TPM |
| APIYI (12% de descuento) | $1.06/M | $5.28/M | Prácticamente sin límites |
| Diferencia | Ahorro del 12% | Ahorro del 12% | – |
Cálculo de coste integral
Asumiendo un volumen de llamadas mensual de 10 millones de tokens (mitad entrada, mitad salida):
| Solución | Coste mensual | Impacto del límite de velocidad | Evaluación general |
|---|---|---|---|
| Conexión directa Alibaba Cloud | $36.00 | Interrupciones frecuentes, requiere reintentos | El coste real es mayor |
| Intermediación con APIYI | $31.68 | Estable y sin interrupciones | Mejor relación calidad-precio |
| Estrategia de múltiples cuentas | $36.00+ | Alto coste de gestión | No recomendado |
💰 Optimización de costes: APIYI (apiyi.com) cuenta con una colaboración de canal con Alibaba Cloud; no solo ofrece un descuento predeterminado del 12% (precio al 0.88), sino que también soluciona por completo los problemas de límite de velocidad. Para escenarios de uso de frecuencia media-alta, el coste integral es significativamente menor.
Preguntas frecuentes
Q1: ¿Por qué me encuentro con límites de velocidad en Qwen3-Max nada más empezar a usarlo?
Alibaba Cloud Model Studio ofrece una cuota gratuita limitada para cuentas nuevas, y la cuota para la nueva versión qwen3-max-2025-09-23 es aún más baja (RPM 60, TPM 100,000). Si estás utilizando una versión snapshot, las restricciones de velocidad suelen ser todavía más estrictas.
Te recomendamos realizar las llamadas a través de APIYI (apiyi.com), lo que te permite evitar las limitaciones de cuota a nivel de cuenta individual.
Q2: ¿Cuánto tiempo tarda en recuperarse el servicio tras alcanzar el límite?
El límite de velocidad de Alibaba Cloud funciona con un mecanismo de ventana deslizante:
- Límite RPM: Se recupera tras esperar unos 60 segundos.
- Límite TPM: Se recupera tras esperar unos 60 segundos.
- Protección contra ráfagas (Burst): Puede requerir un tiempo de espera mayor.
Utilizar la plataforma APIYI para tus llamadas evita estas esperas frecuentes, mejorando la eficiencia del desarrollo.
Q3: ¿Cómo se garantiza la estabilidad del servicio de intermediación de APIYI?
APIYI mantiene una relación de colaboración de canal con Alibaba Cloud y utiliza un modelo de cuota de "gran pool" a nivel de plataforma:
- Equilibrio de carga multicanal.
- Conmutación por error automática (failover).
- Garantía de disponibilidad del 99.9%.
En comparación con las restricciones de cuota de una cuenta personal, el servicio a nivel de plataforma es mucho más estable y fiable.
Q4: ¿Es necesario modificar mucho código para usar APIYI?
Casi nada. APIYI es totalmente compatible con el formato del SDK de OpenAI; solo necesitas modificar dos líneas:
# Antes (Conexión directa con Alibaba Cloud)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# Después (Intermediación con APIYI)
client = OpenAI(
api_key="tu-apiyi-key", # Cambia por tu clave de APIYI
base_url="https://api.apiyi.com/v1" # Cambia por la dirección de APIYI
)
El nombre del modelo y el formato de los parámetros son exactamente iguales, por lo que no se requieren otros cambios.
Q5: Además de Qwen3-Max, ¿qué otros modelos admite APIYI?
La plataforma APIYI admite la llamada unificada a más de 200 modelos de IA principales, incluyendo:
- Serie Qwen completa: qwen3-max, qwen-plus, qwen-turbo, qwen-vl, etc.
- Serie Claude: claude-3-opus, claude-3-sonnet, claude-3-haiku.
- Serie GPT: gpt-4o, gpt-4-turbo, gpt-3.5-turbo.
- Otros: Gemini, DeepSeek, Moonshot, entre otros.
Todos los modelos utilizan una interfaz unificada, permitiéndote acceder a todos ellos con una sola API Key.
Resumen de soluciones para problemas de límite de velocidad en Qwen3-Max
Árbol de decisión para elegir una solución
Error 429 en Qwen3-Max
│
├─ Solución definitiva → Usar el intermediario de APIYI (Recomendado)
│
├─ Límite de velocidad leve → Suavizado de peticiones + Retroceso exponencial
│
├─ Uso empresarial a gran escala → Rotación de cuentas o APIYI Enterprise
│
└─ Tareas no críticas → Degradación a modelo de reserva (Fallback)
Resumen de puntos clave
| Punto clave | Descripción |
|---|---|
| Causa del límite | Triple restricción de Alibaba Cloud: RPM/TPM/RPS |
| Mejor solución | Servicio intermediario de APIYI, solución definitiva |
| Ventaja en costos | Tarifas de 0.88x, más económico que la conexión directa |
| Coste de migración | Solo requiere modificar base_url y api_key |
Te recomendamos usar APIYI (apiyi.com) para resolver rápidamente los problemas de límite de velocidad de Qwen3-Max, disfrutando de un servicio estable y precios preferenciales.
Referencias
-
Documentación de Rate Limits de Alibaba Cloud: Explicación oficial de los límites de velocidad.
- Enlace:
alibabacloud.com/help/en/model-studio/rate-limit
- Enlace:
-
Documentación de Error Codes de Alibaba Cloud: Detalle de los códigos de error.
- Enlace:
alibabacloud.com/help/en/model-studio/error-code
- Enlace:
-
Documentación del modelo Qwen3-Max: Especificaciones técnicas oficiales.
- Enlace:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- Enlace:
Soporte técnico: Si tienes alguna duda sobre el uso de Qwen3-Max, puedes obtener soporte técnico a través de APIYI en apiyi.com.