An interesting discovery! Recently, many developers trying out the M2.7 model released by MiniMax in March 2026 have run into a counterintuitive issue: this flagship model, touted as the "king of code and Agent workflows," doesn't actually support image input. Considering that multimodal capabilities are now standard in Claude 4, GPT-5, and Gemini 3, it's quite surprising that a 230B parameter flagship model can't "see" images. This article dives deep into the product logic behind M2.7's "text-only" positioning, based on official MiniMax documentation, NVIDIA NIM model cards, public specifications from OpenRouter, and observations from actual deployments via APIYI (apiyi.com).
1. Is it true that MiniMax M2.7 doesn't support image input?
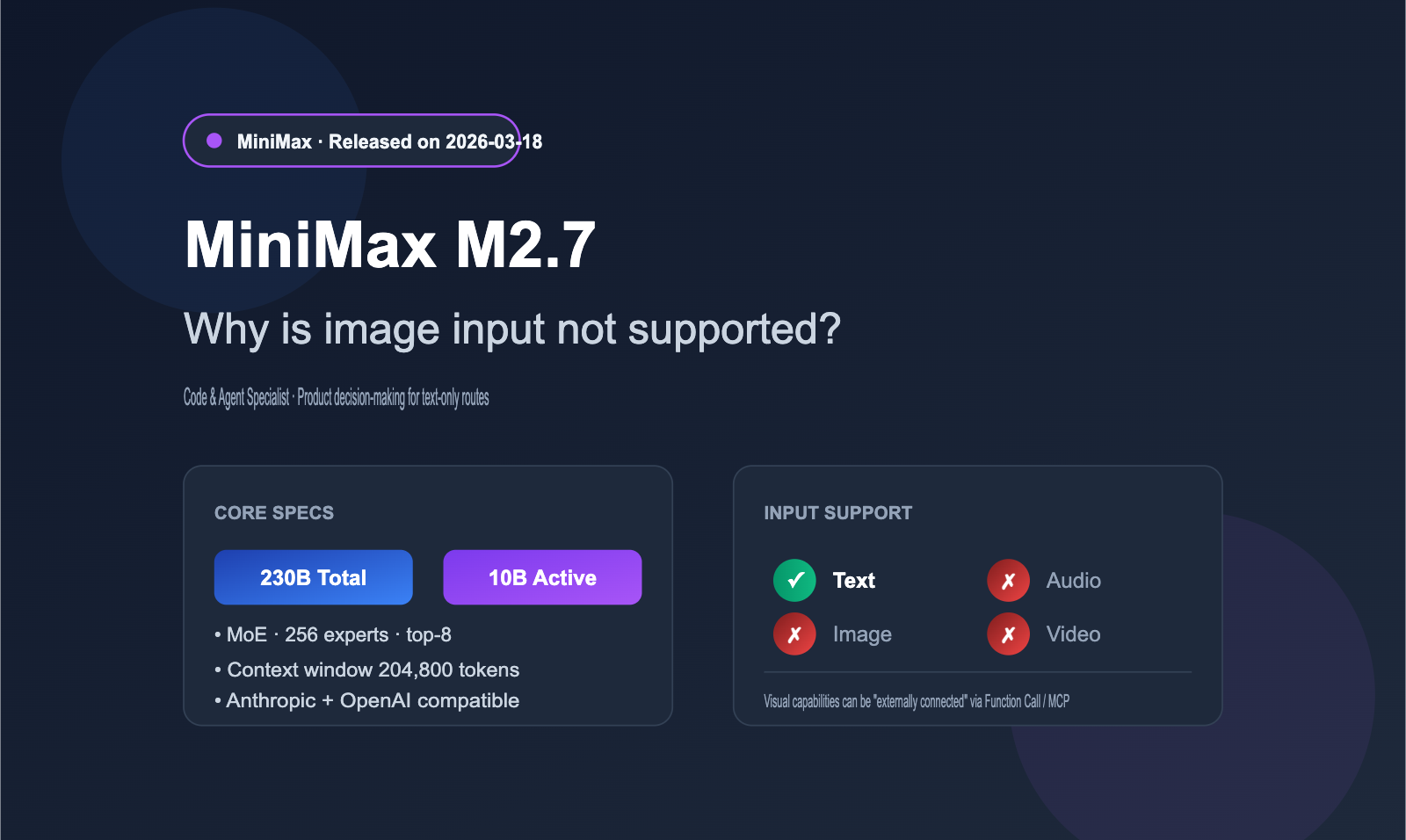
Let's answer the most direct question first: Yes, it's true. According to the official MiniMax platform and NVIDIA NIM model card specifications, M2.7 (including the M2.7-highspeed version) currently only supports text input and cannot directly process images, audio, or video. This is consistent with the text-only positioning of the previous M2.5 generation, but stands in stark contrast to the "native multimodal" mainstream of the Claude 4 Opus, GPT-5, and Gemini 3 series released around the same time.
1.1 Quick Overview of MiniMax M2.7 Specifications
M2.7 officially opened its API on March 18, 2026. It uses a MoE (Mixture of Experts) architecture with 230B total parameters and 10B active parameters, focusing on "high performance + low cost."
| Specification | Details |
|---|---|
| Release Date | 2026-03-18 |
| Architecture Type | MoE Transformer (256 experts, 8 active per token) |
| Total / Active Parameters | 230B / 10B |
| Context Window | 204,800 tokens |
| Max Output | 131,072 tokens |
| Input Price | $0.279 / M tokens |
| Output Price | $1.20 / M tokens |
| Multimodal Support | ❌ Text only |
| API Compatibility | Anthropic API + OpenAI API |
1.2 Where you might "hit a snag"
If your application involves screenshot Q&A, PDF screenshot parsing, product image understanding, UI automation visual inspection, or image retrieval in multimodal RAG, calling M2.7 directly will result in failure or meaningless output. We recommend implementing model type detection at the routing layer (using tools like LiteLLM, One API, or a unified API proxy service like APIYI) to route image-based requests to the Claude, GPT-5, or Gemini 3 series for processing.
II. Why MiniMax M2.7 Chose the "Text-Only" Path
The text-only positioning of M2.7 isn't due to a lack of technical capability, but rather a very clear product decision. MiniMax has previously released the abab series of models with multimodal capabilities, so they were perfectly capable of adding a vision module to the M series. However, they chose to dedicate all of M2.7's training compute to the "Code + Agent" domains to achieve peak performance in these areas.
2.1 Code and Agents: The Core Battleground for M2.7
According to the official README and NVIDIA technical blog, M2.7 is specifically optimized for "multi-file editing, code-run-fix loops, test-driven repair, and long-chain tool calls across shells, browsers, retrieval systems, and code runners." On real-world coding tasks like SWE-bench, Aider Polyglot, and Terminal Bench, M2.7's performance approaches that of Claude 4 Sonnet, yet it has only 10B active parameters and an inference cost that is roughly 1/8th of the latter.
2.2 The Trade-off: Text-Only vs. Multimodal
Focusing training resources on a single direction brings both definitive gains and losses. The table below summarizes the core trade-offs between the two routes:
| Dimension | Text-Only Route (M2.7 / DeepSeek-R1) | Multimodal Route (Claude/GPT/Gemini) |
|---|---|---|
| Training Cost | Concentrated, high efficiency | Distributed, high data cost |
| Price per Token | Lower ($0.28-2 / M) | Higher ($3-15 / M) |
| Text/Code Reasoning Depth | Generally stronger | Slightly weaker but sufficient |
| Image/Video Understanding | Not supported | Native support |
| Breadth of Application | Focused | More general-purpose |
| Engineering Integration Complexity | Low | Low-to-Medium |
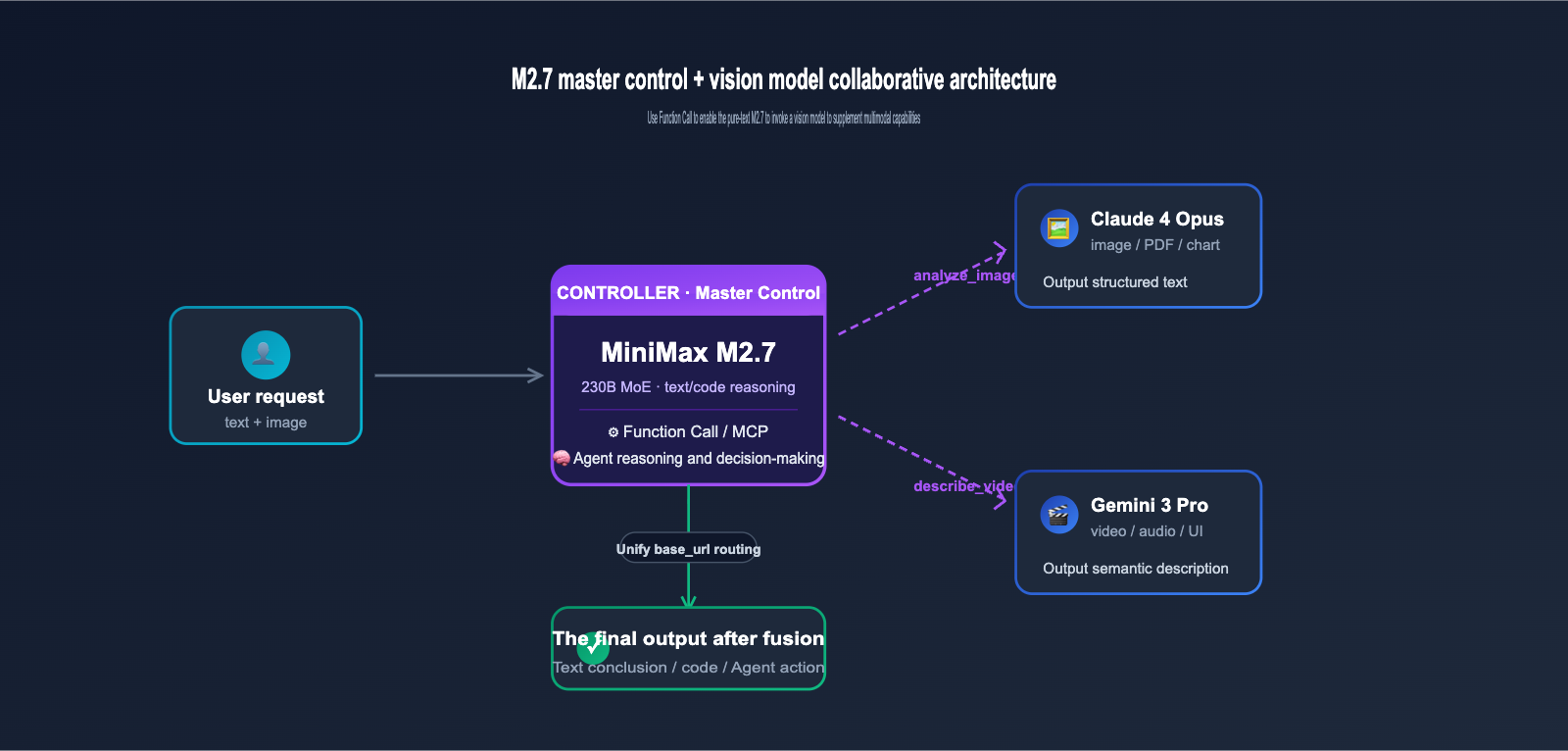
2.3 "Completing" Multimodal Capabilities via Tool Calling
Although M2.7 cannot "see" images itself, it natively supports MCP (Model Context Protocol) and Function Calling. This means developers can let M2.7 "outsource" image understanding tasks to specialized vision models (like Claude 4 Opus or Gemini 3 Vision), while it focuses solely on orchestration and final reasoning. This "controller + vision collaborator" architecture is very common in agent systems.
III. Is Multimodal API Really an Industry Standard in 2026?
At first glance, it seems like "multimodal = standard" has become the industry consensus for 2026. However, a deeper look at the mainstream model landscape reveals that this judgment needs to be understood in layers.
3.1 Mainstream Closed-Source Flagships All Support Multimodality
Anthropic's Claude 4 series, OpenAI's GPT-5 series, and Google's Gemini 3 Pro/Ultra have all made images a foundational input capability. Gemini 3 jumped from 11.4% in the previous generation to 72.7% on the ScreenSpot-Pro test, allowing it to "understand" screenshots and operate UIs directly; Claude 4 has also strengthened its chart recognition and PDF parsing capabilities.
3.2 Clear Divergence in the Open-Source/Cost-Effective Camp
The open-source camp shows a clear split: one side consists of "full-stack multimodal" models like Llama 3.2 Vision, Qwen3-VL, and InternVL; the other side consists of "text/reasoning-focused" models like DeepSeek-R1 and MiniMax M2.7, which gain cost-effectiveness through focus. These two types of models aren't just a simple "high vs. low" distinction, but rather differentiated choices for different application forms.
3.3 Comparison of Multimodal Capabilities in Mainstream Models
The table below summarizes the differences in multimodal capabilities among mainstream large models as of May 2026, allowing you to quickly see M2.7's positioning:
| Model | Image Input | Video Input | Audio Input | Primary Positioning |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | Code/Agent Reasoning |
| Claude 4 Opus | ✅ | ❌ | ❌ | General + Long Context + Code |
| GPT-5 | ✅ | ✅ | ✅ | General Multimodal |
| Gemini 3 Pro | ✅ | ✅ | ✅ | Multimodal + UI Understanding |
| DeepSeek-R1 | ❌ | ❌ | ❌ | Mathematical Reasoning |
| Qwen3-VL | ✅ | ✅ | ❌ | Open-Source Multimodal |
As you can see, "standardized multimodality" is primarily concentrated in the closed-source flagship camp. In the open-source and cost-effective camp, specializing in text remains an effective differentiation strategy.

IV. How to Handle Images with MiniMax M2.7 (Without Native Vision)
Although M2.7 doesn't process images natively, you can easily build a "M2.7 Controller + Vision Model" hybrid architecture using tool calling and routing. This allows you to enjoy M2.7's cost-efficiency without sacrificing the multimodal experience.
4.1 Recommended Hybrid Calling Architecture
The most common approach is to use a unified gateway (such as the multi-model routing provided by APIYI at apiyi.com) to distribute requests based on content type. Text/code requests are routed to M2.7, while image requests are sent to Claude 4 or Gemini 3. The output text from the vision model is then passed back to M2.7 for final reasoning and decision-making. This architecture is transparent to the frontend, meaning you don't need to modify your existing SDK implementation.
4.2 Integrating Vision Models via Function Calling
If your application uses Function Calling, you can register an analyze_image tool for M2.7. Internally, this tool calls the vision API of Claude, GPT, or Gemini and returns the recognition results as JSON. M2.7 will automatically determine when to invoke this tool based on user requests, eliminating the need for explicit logic in your prompt. This pattern is ideal for Agent frameworks (such as LangGraph, CrewAI, or the OpenAI Agents SDK).
🎯 Integration Tip: We recommend using a single
base_urlvia APIYI (apiyi.com) to access both M2.7 and multimodal models (like Claude 4 Opus or Gemini 3 Pro). This avoids the need to manage separate SDKs and API keys for each provider, significantly reducing the engineering complexity of your hybrid architecture while making it easier to track token usage and costs.
4.3 Recommended Inference Parameters
MiniMax officially recommends using relatively high sampling parameters for M2.7: temperature=1.0, top_p=0.95, and top_k=40. This differs from the low-temperature settings recommended for many other models. In practice, we've found that these parameters yield higher-quality, more creative code completions in coding and Agent scenarios. If your previous prompt templates defaulted to temperature=0, you might find the output on M2.7 to be rigid or repetitive, so you'll likely need to re-tune those settings.
V. MiniMax M2.7 vs. Multimodal Model Selection Strategy
When should you choose M2.7 versus a flagship multimodal model? The core decision depends on whether your application is "text/code-driven" or "multimodal-driven," rather than just comparing parameter counts.
5.1 Choose M2.7 for Text/Code-Driven Scenarios
If over 90% of your product's requests are text-based (code generation, document Q&A, Agent orchestration, long-form summarization), M2.7 is currently one of the most cost-effective choices available. Its 230B parameter capacity approaches the performance ceiling of Claude 4 Sonnet, but at a fraction of the cost per token, making it exceptionally friendly for high-concurrency SaaS backends.
5.2 Choose Claude / Gemini for High-Frequency Multimodal Scenarios
If your core use cases involve image understanding (OCR, UI automation, product recognition, medical imaging assistance), video analysis, or audio processing, opting for Claude 4 Opus, GPT-5, or Gemini 3 Pro directly is simpler and more reliable than a hybrid architecture of "M2.7 + a vision model." This approach reduces latency and failure rates associated with cross-model invocations.
5.3 Selection Recommendations by Scenario
| Application Scenario | Preferred Model | Alternative Solution |
|---|---|---|
| Code Generation / Refactoring | MiniMax M2.7 | Claude 4 Sonnet |
| Agent Tool Calling | MiniMax M2.7 | GPT-5 |
| Long Document Q&A (within 200K) | MiniMax M2.7 | Claude 4 Opus |
| Image OCR / Screenshot Q&A | Gemini 3 Pro | Claude 4 Opus |
| Video Analysis | Gemini 3 Pro | GPT-5 |
| Multimodal RAG | Claude 4 Opus | Gemini 3 Pro |
| Hybrid Tasks (Text-driven + minor images) | M2.7 + Vision Model combo | Claude 4 Opus (Single model) |
🎯 Selection Tip: Choosing a model isn't really about "who is stronger," but "who better matches your request distribution." We recommend using the APIYI (apiyi.com) platform to run A/B tests with real traffic, comparing the cost and quality of different models for the same tasks before finalizing your primary model stack.
VI. MiniMax M2.7 FAQ
6.1 Can M2.7 really not handle images at all?
That's correct. If you pass image files (base64 or URLs) directly into the messages, the API will reject them or return an error. The only viable workaround is to use a separate vision model to convert the image into a text description first, then pass that description to M2.7 for subsequent reasoning.
6.2 What is the difference between M2.7 and M2.7-highspeed?
Both produce identical output results; the only difference is response speed. M2.7-highspeed is optimized for latency-sensitive scenarios (like real-time IDE code completion), while the standard M2.7 version is better suited for large-scale asynchronous tasks. You can switch between these versions in the APIYI (apiyi.com) console by changing the model name; the API parameters are fully compatible.
6.3 Is M2.7 an open-source model, and can it be deployed locally?
Yes, M2.7 is an open-weights model that can be downloaded from HuggingFace and self-hosted. However, you'll need at least 8 A100/H100 GPUs to fully utilize the 200K context window. Local deployment costs are significantly higher than API invocation, so unless you have strict data compliance requirements, self-hosting is generally not recommended.
6.4 Is M2.7 compatible with official Anthropic / OpenAI SDKs?
It's fully compatible. You can use the official anthropic or openai SDKs directly by simply pointing the base_url to an API proxy service (such as the unified endpoint provided by APIYI at apiyi.com) and updating the model name. There's no need to rewrite any of your business logic, making this the easiest way to implement a hybrid architecture.
6.5 Should teams with heavy multimodal needs avoid M2.7?
Not necessarily. Even in multimodal applications, text reasoning and orchestration often account for a large volume of requests. We suggest leaving the multimodal tasks to Claude/Gemini while delegating text orchestration and decision-making to M2.7; this can significantly lower your overall inference costs. If you need a customized hybrid solution, feel free to contact the APIYI (apiyi.com) business team for architectural advice.
7. Conclusion: Multimodal is the Trend, but "Specialization" Remains a Winning Strategy
The fact that MiniMax M2.7 doesn't support image input is both a reality and a deliberate product strategy. In 2026, at a point where multimodal capabilities have become the standard for closed-source flagship models, MiniMax has chosen to concentrate all its training resources on the two most differentiated tracks: coding and Agents. This trade-off has yielded coding capabilities approaching those of Claude 4 Sonnet, at a significantly lower inference cost.
For developers, this means that selecting a model is no longer a simple comparison of "who is more versatile," but rather "who best matches your request distribution." In scenarios dominated by text or code, M2.7 remains one of the most cost-effective choices available today. Meanwhile, high-frequency multimodal tasks should be left to specialists like Claude 4 Opus, GPT-5, or Gemini 3. By combining these models through a unified gateway, you can often achieve the optimal balance between cost and performance.
If you need to integrate M2.7 alongside various multimodal flagships under a single base_url, you can visit the official APIYI documentation at apiyi.com to view the complete model list and integration examples.
Author: APIYI Team — Continuously providing stable and efficient API proxy services and multi-model routing for AI developers worldwide. Visit apiyi.com for more details.