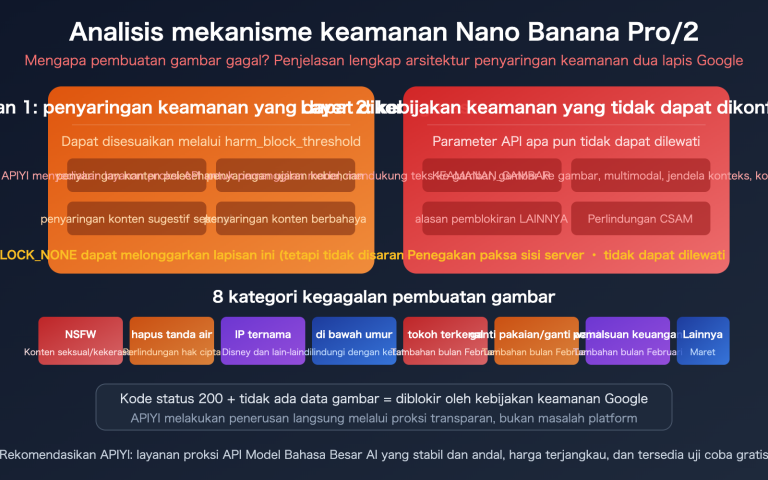
Ada temuan menarik nih~ Belakangan ini, banyak pengembang yang mencoba model M2.7 yang dirilis MiniMax pada Maret 2026, namun mereka menemukan masalah yang cukup kontraintuitif: model unggulan yang dijuluki sebagai "Raja Kode dan Alur Kerja Agen" ini ternyata tidak mendukung input gambar. Mengingat saat ini kemampuan multimodal sudah menjadi standar di Claude 4, GPT-5, dan Gemini 3, cukup mengejutkan melihat model besar dengan 230 miliar parameter tidak bisa mengenali gambar. Artikel ini akan membedah logika produk di balik posisi "khusus teks" pada M2.7, berdasarkan dokumentasi resmi MiniMax, kartu model NVIDIA NIM, spesifikasi publik OpenRouter, serta pengamatan dari penerapan praktis di APIYI apiyi.com.
<rect x="20" y="55" width="130" height="36" rx="8" fill="url(#textGrad)" />
<text x="85" y="78" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" font-weight="700" text-anchor="middle">Total 230B</text>
<rect x="170" y="55" width="130" height="36" rx="8" fill="url(#moeGrad)" />
<text x="235" y="78" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" font-weight="700" text-anchor="middle">10B Aktif</text>
<text x="20" y="115" font-family="Arial, sans-serif" font-size="13" fill="#cbd5e1">• MoE · 256 pakar · top-8</text>
<text x="20" y="138" font-family="Arial, sans-serif" font-size="13" fill="#cbd5e1">• Jendela konteks 204.800 token</text>
<text x="20" y="158" font-family="Arial, sans-serif" font-size="13" fill="#cbd5e1">• Kompatibel dengan Anthropic + OpenAI</text>
<!-- Text ✓ -->
<circle cx="40" cy="75" r="14" fill="url(#okGrad)" />
<text x="40" y="80" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" font-weight="700" text-anchor="middle">✓</text>
<text x="65" y="80" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" font-weight="600">Teks</text>
<!-- Image ✗ -->
<circle cx="40" cy="110" r="14" fill="url(#failGrad)" />
<text x="40" y="115" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" font-weight="700" text-anchor="middle">✗</text>
<text x="65" y="115" font-family="Arial, sans-serif" font-size="14" fill="#94a3b8">Gambar</text>
<!-- Audio ✗ -->
<circle cx="180" cy="75" r="14" fill="url(#failGrad)" />
<text x="180" y="80" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" font-weight="700" text-anchor="middle">✗</text>
<text x="205" y="80" font-family="Arial, sans-serif" font-size="14" fill="#94a3b8">Audio Audio</text>
<!-- Video ✗ -->
<circle cx="180" cy="110" r="14" fill="url(#failGrad)" />
<text x="180" y="115" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" font-weight="700" text-anchor="middle">✗</text>
<text x="205" y="115" font-family="Arial, sans-serif" font-size="14" fill="#94a3b8">Video</text>
<line x1="20" y1="135" x2="300" y2="135" stroke="#334155" stroke-width="1" />
<text x="20" y="158" font-family="Arial, sans-serif" font-size="12" fill="#94a3b8">Melalui Function Call / MCP dapat "menghubungkan" visual secara eksternal</text>
I. Apakah benar MiniMax M2.7 tidak mendukung input gambar?
Mari kita jawab langsung: Benar. Berdasarkan spesifikasi publik dari platform resmi MiniMax dan kartu model NVIDIA NIM, M2.7 (termasuk versi M2.7-highspeed) saat ini hanya mendukung input teks dan tidak dapat memproses gambar, audio, atau video secara langsung. Hal ini konsisten dengan posisi M2.5 sebelumnya yang juga khusus teks, namun sangat kontras dengan arus utama "multimodal asli" seperti Claude 4 Opus, GPT-5, dan seri Gemini 3 yang dirilis pada periode yang sama.
1.1 Sekilas spesifikasi inti MiniMax M2.7
M2.7 resmi membuka akses API pada 18 Maret 2026, menggunakan arsitektur MoE (Mixture of Experts) dengan total 230B parameter dan 10B parameter aktif, yang mengedepankan "performa tinggi + biaya rendah".
| Item Spesifikasi | Parameter Detail |
|---|---|
| Tanggal Rilis | 18-03-2026 |
| Tipe Arsitektur | MoE Transformer (256 pakar, 8 pakar aktif per token) |
| Total Parameter / Parameter Aktif | 230B / 10B |
| Jendela konteks | 204.800 token |
| Output Maksimum | 131.072 token |
| Harga Input | $0,279 / Juta token |
| Harga Output | $1,20 / Juta token |
| Dukungan Multimodal | ❌ Hanya mendukung teks |
| Kompatibilitas API | API Anthropic + API OpenAI |
1.2 Skenario mana yang akan membuat Anda "terjebak"?
Jika aplikasi Anda melibatkan tanya jawab tangkapan layar, analisis tangkapan layar PDF, pemahaman gambar produk, deteksi visual otomatisasi UI, atau pengambilan gambar dalam RAG multimodal, pemanggilan langsung ke M2.7 akan gagal atau menghasilkan output yang tidak berarti. Kami menyarankan untuk melakukan penilaian tipe model di lapisan perutean (seperti LiteLLM, One API, atau gateway proksi API terpadu seperti APIYI apiyi.com) dan mengarahkan permintaan berbasis gambar ke seri Claude, GPT-5, atau Gemini 3 untuk diproses.
二、Mengapa MiniMax M2.7 Memilih Jalur "Teks Murni"
Posisi teks murni pada M2.7 bukanlah karena keterbatasan kemampuan teknis, melainkan keputusan produk yang sangat jelas. MiniMax sebelumnya telah merilis seri model abab yang memiliki kemampuan multimodal, sehingga mereka sebenarnya sangat mampu menambahkan modul visual ke seri M. Namun, mereka memilih untuk mengalokasikan seluruh daya komputasi pelatihan M2.7 ke dua bidang, yaitu "kode + Agent", demi mendapatkan performa maksimal di kedua arah tersebut.
2.1 Kode dan Agent adalah Medan Perang Utama M2.7
Berdasarkan deskripsi README resmi dan blog teknis NVIDIA, M2.7 dioptimalkan secara khusus untuk "pengeditan multi-file, siklus kode-jalankan-perbaiki, perbaikan berbasis pengujian, serta pemanggilan alat rantai panjang lintas Shell/browser/pengambilan data/eksekutor kode". Pada tugas pengodean nyata seperti SWE-bench, Aider Polyglot, dan Terminal Bench, skor M2.7 mendekati Claude 4 Sonnet, namun dengan parameter aktif hanya 10B dan biaya inferensi yang hanya sekitar 1/8 dari model tersebut.
2.2 Pertimbangan Jalur Teks Murni vs Jalur Multimodal
Memfokuskan sumber daya pelatihan pada satu arah akan memberikan keuntungan dan kerugian yang pasti. Tabel berikut merangkum poin-poin pertimbangan utama dari kedua jalur tersebut:
| Dimensi | Jalur Teks Murni (M2.7 / DeepSeek-R1) | Jalur Multimodal (Claude/GPT/Gemini) |
|---|---|---|
| Biaya Pelatihan | Terpusat, efisiensi tinggi | Tersebar, biaya data tinggi |
| Harga per token | Lebih rendah ($0,28-2 / Juta) | Lebih tinggi ($3-15 / Juta) |
| Kedalaman penalaran teks/kode | Biasanya lebih kuat | Sedikit lebih lemah tapi cukup |
| Pemahaman gambar/video | Tidak didukung | Didukung secara bawaan |
| Cakupan skenario | Lebih terfokus | Lebih umum |
| Kompleksitas integrasi teknis | Rendah | Rendah-Sedang |
2.3 "Melengkapi" Kemampuan Multimodal melalui Pemanggilan Alat
Meskipun M2.7 sendiri tidak bisa mengenali gambar, ia mendukung MCP (Model Context Protocol) dan Function Calling secara bawaan. Ini berarti pengembang dapat membiarkan M2.7 "mengalihdayakan" tugas pemahaman gambar ke model visual khusus (seperti Claude 4 Opus atau Gemini 3 Vision), sementara ia sendiri hanya bertanggung jawab atas penjadwalan dan penalaran akhir. Arsitektur "pengontrol utama + kolaborasi visual" seperti ini sangat umum dalam sistem Agent.
三、Apakah API Multimodal Benar-benar Standar Industri di Tahun 2026?
Secara intuitif, "multimodal = standar" hampir menjadi konsensus industri pada tahun 2026. Namun, jika diamati lebih dalam pada kubu model utama, kita akan melihat bahwa penilaian ini perlu dipahami secara bertingkat.
3.1 Model Unggulan Tertutup Hampir Semuanya Mendukung Multimodal
Seri Claude 4 dari Anthropic, seri GPT-5 dari OpenAI, dan Gemini 3 Pro/Ultra dari Google telah menjadikan gambar sebagai kemampuan input dasar. Gemini 3 melonjak dari 11,4% pada pengujian ScreenSpot-Pro generasi sebelumnya menjadi 72,7%, yang memungkinkannya untuk langsung "memahami" tangkapan layar dan mengoperasikan UI; Claude 4 juga memperkuat kemampuan pengenalan grafik dan analisis PDF.
3.2 Kubu Sumber Terbuka/Efisiensi Biaya Mengalami Diferensiasi Jelas
Kubu sumber terbuka justru menunjukkan diferensiasi yang jelas: satu sisi adalah model "multimodal tumpukan penuh" seperti Llama 3.2 Vision, Qwen3-VL, dan InternVL; sisi lainnya adalah model "spesialis teks/penalaran" seperti DeepSeek-R1 dan MiniMax M2.7, yang mendapatkan keunggulan efisiensi biaya melalui fokus. Kedua jenis model ini bukanlah sekadar "tinggi atau rendah", melainkan pilihan berbeda yang disesuaikan dengan bentuk aplikasi yang berbeda pula.
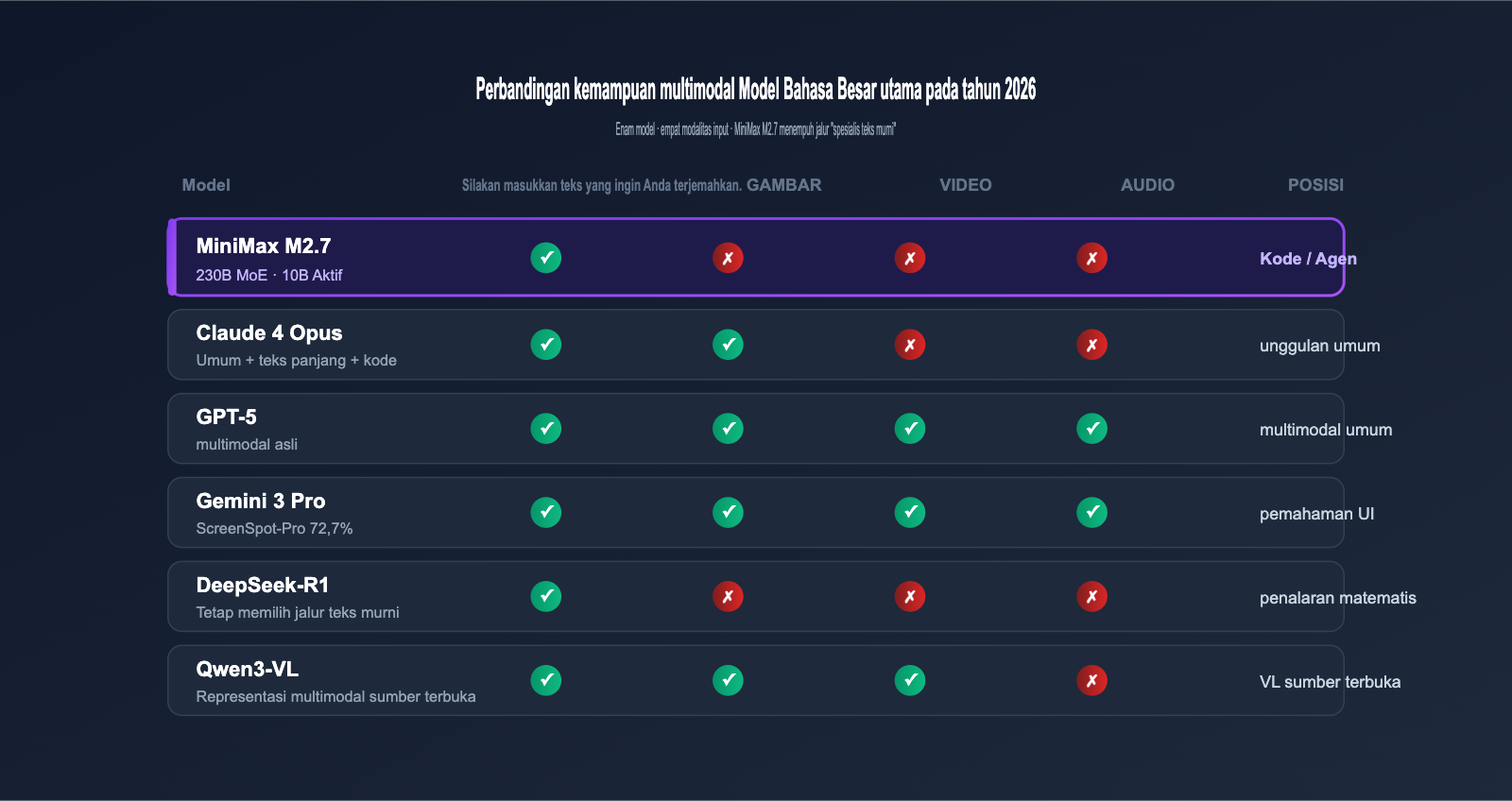
3.3 Perbandingan Kemampuan Multimodal Model Utama
Tabel berikut merangkum perbedaan kemampuan multimodal dari model bahasa besar utama pada Mei 2026, yang memungkinkan Anda melihat posisi M2.7 dalam industri dengan cepat:
| Model | Input Gambar | Input Video | Input Audio | Posisi Utama |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | Penalaran Kode/Agent |
| Claude 4 Opus | ✅ | ❌ | ❌ | Umum + Teks Panjang + Kode |
| GPT-5 | ✅ | ✅ | ✅ | Multimodal Umum |
| Gemini 3 Pro | ✅ | ✅ | ✅ | Multimodal + Pemahaman UI |
| DeepSeek-R1 | ❌ | ❌ | ❌ | Penalaran Matematika |
| Qwen3-VL | ✅ | ✅ | ❌ | Multimodal Sumber Terbuka |
Dapat dilihat bahwa "standar multimodal" terutama terkonsentrasi pada kubu unggulan tertutup. Di kubu sumber terbuka dan efisiensi biaya, spesialisasi teks tetap menjadi jalur diferensiasi yang efektif.
IV. Tanpa Visi Asli, Bagaimana Cara Membuat MiniMax M2.7 Memproses Gambar
Meskipun M2.7 sendiri tidak dapat membaca gambar, melalui pemanggilan alat (tool calling) + perutean, Anda dapat membangun arsitektur hibrida "M2.7 sebagai pengendali utama + kolaborasi model visual". Dengan cara ini, Anda tetap bisa menikmati biaya rendah M2.7 tanpa mengorbankan pengalaman multimodal.
4.1 Arsitektur Pemanggilan Hibrida yang Direkomendasikan
Cara yang paling umum adalah: menggunakan gateway terpadu (seperti perutean multi-model yang disediakan oleh APIYI apiyi.com) untuk mendistribusikan permintaan berdasarkan jenis konten. Permintaan teks/kode diarahkan ke M2.7, sedangkan permintaan gambar diarahkan ke Claude 4 atau Gemini 3, kemudian teks hasil dari model visual dikirim kembali ke M2.7 untuk penalaran dan pengambilan keputusan akhir. Arsitektur ini transparan bagi sisi front-end dan tidak perlu mengubah cara pemanggilan SDK di sisi bisnis.
4.2 Mengintegrasikan Model Visual ke dalam Function Calling
Jika aplikasi Anda menggunakan Function Calling, Anda dapat mendaftarkan alat analyze_image untuk M2.7, yang secara internal memanggil antarmuka visual Claude/GPT/Gemini, lalu mengembalikan hasil identifikasi dalam format JSON. M2.7 akan secara otomatis menentukan kapan harus memanggil alat ini berdasarkan permintaan pengguna, tanpa perlu penilaian eksplisit di lapisan prompt. Pola ini sangat cocok untuk kerangka kerja agen (seperti LangGraph, CrewAI, atau OpenAI Agents SDK).
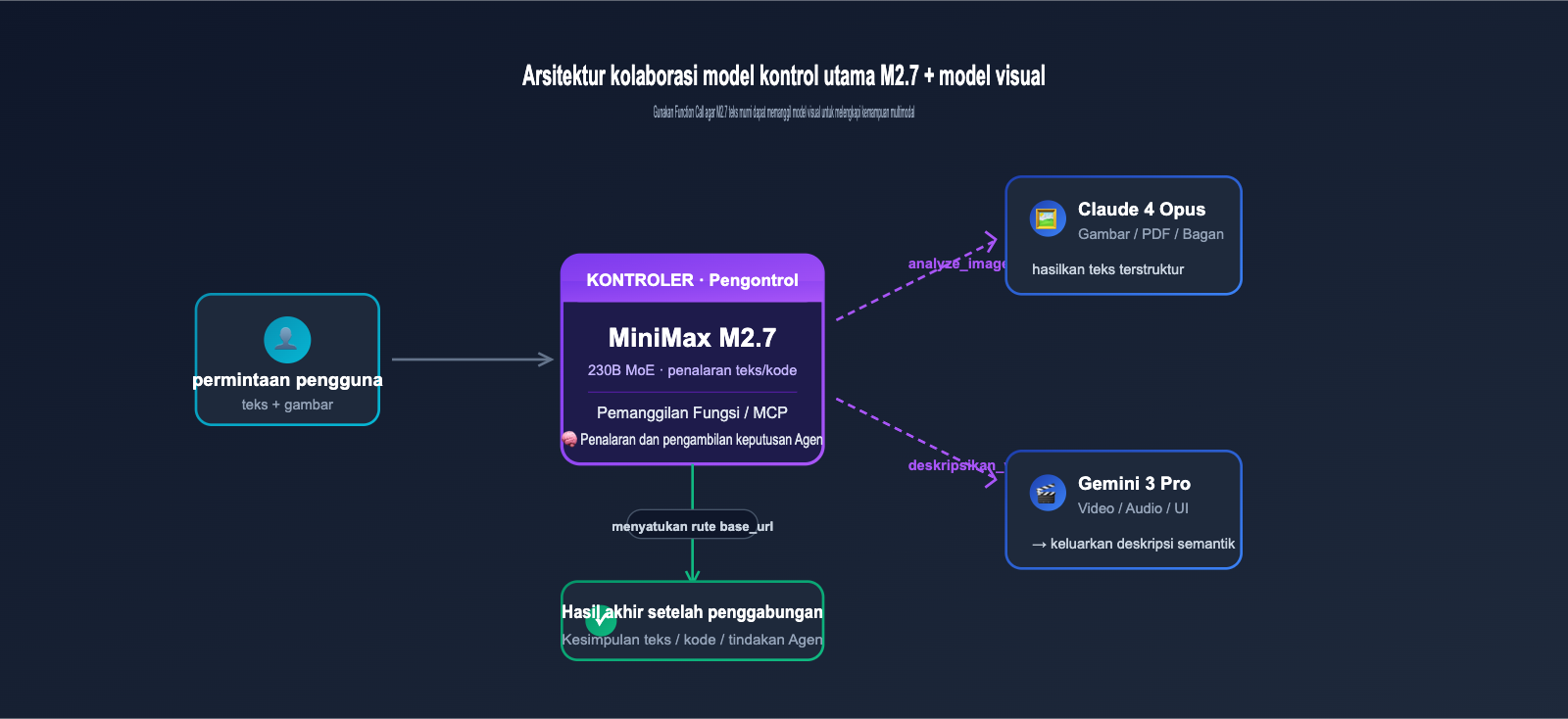
🎯 Saran Integrasi: Kami menyarankan untuk menggunakan satu
base_urldari APIYI apiyi.com guna mengakses M2.7 dan model multimodal (seperti Claude 4 Opus, Gemini 3 Pro) secara bersamaan. Anda tidak perlu lagi mengelola SDK dan kunci API terpisah untuk setiap vendor, yang dapat mengurangi kompleksitas teknis arsitektur hibrida secara signifikan, serta memudahkan pemantauan penggunaan token dan biaya secara terpusat.
4.3 Parameter Inferensi yang Direkomendasikan
MiniMax secara resmi merekomendasikan penggunaan parameter pengambilan sampel yang relatif tinggi untuk M2.7: temperature=1.0, top_p=0.95, top_k=40. Ini berbeda dengan saran suhu rendah pada kebanyakan model lain. Berdasarkan pengujian, dalam skenario pengodean dan agen, rangkaian parameter ini menghasilkan pelengkapan kode dengan kualitas yang lebih tinggi dan lebih kreatif. Jika templat prompt Anda sebelumnya menggunakan temperature=0 secara default, Anda mungkin mendapatkan output yang kaku dan berulang pada M2.7, sehingga perlu dilakukan penyesuaian kembali.
V. Pengambilan Keputusan: MiniMax M2.7 vs Model Multimodal
Kapan sebaiknya Anda memilih M2.7 dan kapan harus menggunakan model multimodal unggulan? Kuncinya terletak pada apakah aplikasi Anda lebih dominan di "teks/kode" atau "multimodal", bukan sekadar membandingkan jumlah parameter.
5.1 Skenario Dominan Teks/Kode: Pilih M2.7
Jika lebih dari 90% permintaan produk Anda bersifat tekstual (pembuatan kode, tanya jawab dokumen, orkestrasi Agent, ringkasan teks panjang), M2.7 adalah salah satu pilihan dengan rasio harga-performa terbaik saat ini. Dengan total 230B parameter, batas kemampuan yang dihasilkan mendekati Claude 4 Sonnet, namun harga per token hanya sebagian kecil dari harga model tersebut. Ini sangat ramah untuk backend SaaS dengan konkurensi tinggi.
5.2 Skenario Multimodal Frekuensi Tinggi: Pilih Claude / Gemini
Jika skenario utama Anda adalah pemahaman gambar (OCR, otomatisasi UI, identifikasi produk, bantuan citra medis), analisis video, atau pemrosesan audio, memilih Claude 4 Opus, GPT-5, atau Gemini 3 Pro secara langsung akan jauh lebih ringkas dan andal dibandingkan arsitektur campuran "M2.7 + model visual". Hal ini juga mengurangi latensi dan tingkat kegagalan akibat pemanggilan lintas model.
5.3 Saran Pemilihan untuk Berbagai Skenario
| Skenario Aplikasi | Model Prioritas | Alternatif |
|---|---|---|
| Pembuatan / Refactoring Kode | MiniMax M2.7 | Claude 4 Sonnet |
| Pemanggilan Alat Agent | MiniMax M2.7 | GPT-5 |
| Tanya Jawab Dokumen Panjang (dalam 200K) | MiniMax M2.7 | Claude 4 Opus |
| OCR Gambar / Tanya Jawab Tangkapan Layar | Gemini 3 Pro | Claude 4 Opus |
| Analisis Video | Gemini 3 Pro | GPT-5 |
| RAG Multimodal | Claude 4 Opus | Gemini 3 Pro |
| Tugas Campuran (Teks + sedikit gambar) | Kombinasi M2.7 + model visual | Model tunggal Claude 4 Opus |
🎯 Saran Pemilihan: Memilih model pada dasarnya bukan tentang "siapa yang lebih kuat", melainkan "siapa yang paling sesuai dengan distribusi permintaan Anda". Kami menyarankan untuk melakukan A/B testing dengan trafik nyata melalui platform APIYI apiyi.com, membandingkan biaya dan kualitas antar model untuk tugas yang sama, sebelum menentukan kombinasi model utama Anda.
VI. Tanya Jawab Umum MiniMax M2.7
6.1 Apakah M2.7 benar-benar tidak bisa memproses gambar?
Benar, jika Anda langsung memasukkan file gambar (base64 atau URL) ke dalam messages, antarmuka akan menolak atau mengembalikan error. Satu-satunya cara yang bisa dilakukan adalah dengan menggunakan model visual lain untuk mengubah gambar menjadi deskripsi teks, lalu mengirimkan deskripsi tersebut ke M2.7 untuk penalaran lebih lanjut.
6.2 Apa perbedaan antara M2.7 dan M2.7-highspeed?
Keduanya menghasilkan output yang identik, perbedaannya hanya pada kecepatan respons. M2.7-highspeed cocok untuk skenario yang sensitif terhadap latensi (seperti pelengkapan otomatis kode di IDE), sedangkan M2.7 versi standar cocok untuk tugas asinkron dalam jumlah besar. Kedua versi dapat dialihkan melalui nama model di konsol APIYI apiyi.com, dan parameter antarmukanya sepenuhnya kompatibel.
6.3 Apakah M2.7 merupakan model open-source, bisakah di-deploy secara lokal?
Bisa, M2.7 adalah model dengan bobot terbuka (open-weights) yang dapat diunduh di HuggingFace dan di-host sendiri. Namun, Anda memerlukan setidaknya 8 unit A100 / H100 untuk menjalankan jendela konteks 200K secara penuh. Biaya deployment lokal jauh lebih tinggi daripada pemanggilan API. Kecuali Anda memiliki persyaratan kepatuhan data yang ketat, kami tidak menyarankan untuk membangun infrastruktur sendiri.
6.4 Apakah M2.7 kompatibel dengan SDK resmi Anthropic / OpenAI?
Sepenuhnya kompatibel. Anda dapat langsung menggunakan SDK resmi anthropic atau openai, cukup arahkan base_url ke gateway layanan proksi API (seperti endpoint akses terpadu APIYI apiyi.com) dan ubah nama modelnya. Anda tidak perlu menulis ulang logika bisnis apa pun. Ini adalah cara paling efisien untuk mengintegrasikan arsitektur campuran.
6.5 Apakah tim dengan kebutuhan multimodal tinggi tidak perlu mempertimbangkan M2.7?
Belum tentu. Bahkan dalam aplikasi multimodal, penalaran teks dan orkestrasi masih memakan porsi permintaan yang besar. Kami menyarankan untuk menyerahkan bagian multimodal kepada Claude/Gemini, sementara bagian orkestrasi teks dan pengambilan keputusan diserahkan kepada M2.7. Hal ini dapat menurunkan biaya inferensi secara keseluruhan secara signifikan. Jika Anda memerlukan solusi campuran yang disesuaikan, silakan hubungi tim bisnis APIYI apiyi.com untuk mendapatkan saran arsitektur.
VII. Kesimpulan: Multimodal adalah Tren, namun "Spesialisasi" Tetap Menjadi Jalur yang Efektif
Fakta bahwa MiniMax M2.7 tidak mendukung input gambar bukanlah sebuah kebetulan, melainkan strategi produk yang disengaja. Di tahun 2026, di mana kemampuan multimodal telah menjadi standar bagi model unggulan (closed-source), MiniMax memilih untuk memusatkan seluruh sumber daya pelatihannya pada dua bidang yang paling berbeda, yaitu kode dan Agent. Hasilnya, mereka berhasil mencapai kemampuan coding yang mendekati Claude 4 Sonnet dengan biaya inferensi yang jauh lebih rendah.
Bagi pengembang, ini berarti pemilihan model tidak lagi sekadar membandingkan "siapa yang paling serba bisa", melainkan "siapa yang paling sesuai dengan distribusi permintaan Anda". Untuk skenario yang didominasi oleh teks/kode, M2.7 tetap menjadi salah satu pilihan dengan efisiensi biaya terbaik saat ini. Sementara itu, untuk skenario multimodal dengan frekuensi tinggi, tugas tersebut sebaiknya diserahkan kepada pemain spesialis seperti Claude 4 Opus, GPT-5, atau Gemini 3. Mengombinasikan keduanya melalui gateway terpadu sering kali memberikan keseimbangan terbaik antara biaya dan hasil.
Jika Anda perlu mengakses M2.7 dan berbagai model unggulan multimodal lainnya di bawah satu base_url yang sama, Anda dapat mengunjungi dokumentasi resmi APIYI di apiyi.com untuk melihat daftar lengkap model dan contoh integrasinya.
Penulis: Tim APIYI — Terus menyediakan layanan proksi API dan perutean multi-model yang stabil dan efisien bagi pengembang AI global. Kunjungi apiyi.com untuk informasi lebih lanjut.