Author's Note: A deep dive comparing Claude Opus 4.6 and Sonnet 4.6 across five dimensions—price, performance, context, coding, and use cases—to help developers choose the right model.
Choosing between Claude Opus 4.6 and Sonnet 4.6 is a practical dilemma many developers face. While Sonnet 4.6 is priced at just 60% of Opus, Opus holds a clear lead in deep reasoning and long-context processing. This article compares them across five dimensions: Price, Performance Benchmarks, Context Handling, Coding Capabilities, and Use Cases to help you make the best choice.
Core Value: By the end of this post, you'll know exactly when to reach for Opus 4.6 versus Sonnet 4.6, and how to slash your costs further with top-up discounts.

Core Comparison: Claude Opus 4.6 vs. Sonnet 4.6
In February 2026, Anthropic released Claude Opus 4.6 (Feb 5) and Sonnet 4.6 (Feb 17) in quick succession. Each model has its own strengths. The table below provides a direct comparison across five key dimensions.
| Dimension | Claude Opus 4.6 | Claude Sonnet 4.6 | Key Difference |
|---|---|---|---|
| Input Price | $15 / Million Tokens | $3 / Million Tokens | Sonnet is 80% cheaper |
| Output Price | $75 / Million Tokens | $15 / Million Tokens | Sonnet is 80% cheaper |
| SWE-bench | 80.8% | 79.6% | Virtually identical |
| GPQA Diamond | 91.3% | — | Opus leads in scientific reasoning |
| Long Context (MRCR v2) | 76% | ~18.5% (4.5 data) | Opus has a massive advantage |
Detailed Price Comparison: Claude Opus 4.6 vs. Sonnet 4.6
Price is often the most immediate factor when choosing a model. Both models are available on the APIYI platform, which supports top-up discount promotions.
| Pricing Item | Opus 4.6 Official | Sonnet 4.6 Official | APIYI Discounted Price (Approx. 15% off) |
|---|---|---|---|
| Input Tokens | $15 / Million | $3 / Million | Get 10% bonus from $100 top-up |
| Output Tokens | $75 / Million | $15 / Million | Higher top-ups, bigger discounts |
| Context >200K Input | $30 / Million | $6 / Million | Also eligible for top-up discounts |
| Batch API | 50% Discount | 50% Discount | Top choice for batch tasks |
| Prompt Caching | 0.1x Base Price | 0.1x Base Price | Money-saver for repeated calls |
Let's look at a typical API call scenario: 2000 input tokens + 500 output tokens, called 1,000 times:
- Opus 4.6: Input $0.03 + Output $0.0375 = Approx. $0.068 / 1k calls
- Sonnet 4.6: Input $0.006 + Output $0.0075 = Approx. $0.014 / 1k calls
Sonnet 4.6's per-call cost is only about 20% of Opus's. For mid-to-high frequency scenarios, that cost gap widens fast.
🎯 Money-Saving Tip: Topping up $100 or more at APIYI (apiyi.com) gets you a 10% bonus. That's an extra discount on top of already lower prices, bringing your total cost down to about 85% of the official rate.
Claude Opus 4.6 vs. Sonnet 4.6: Performance Benchmark Comparison
Price is just one side of the coin; performance benchmarks determine whether a model is actually up to the task. Here's how the two models stack up across mainstream evaluations.
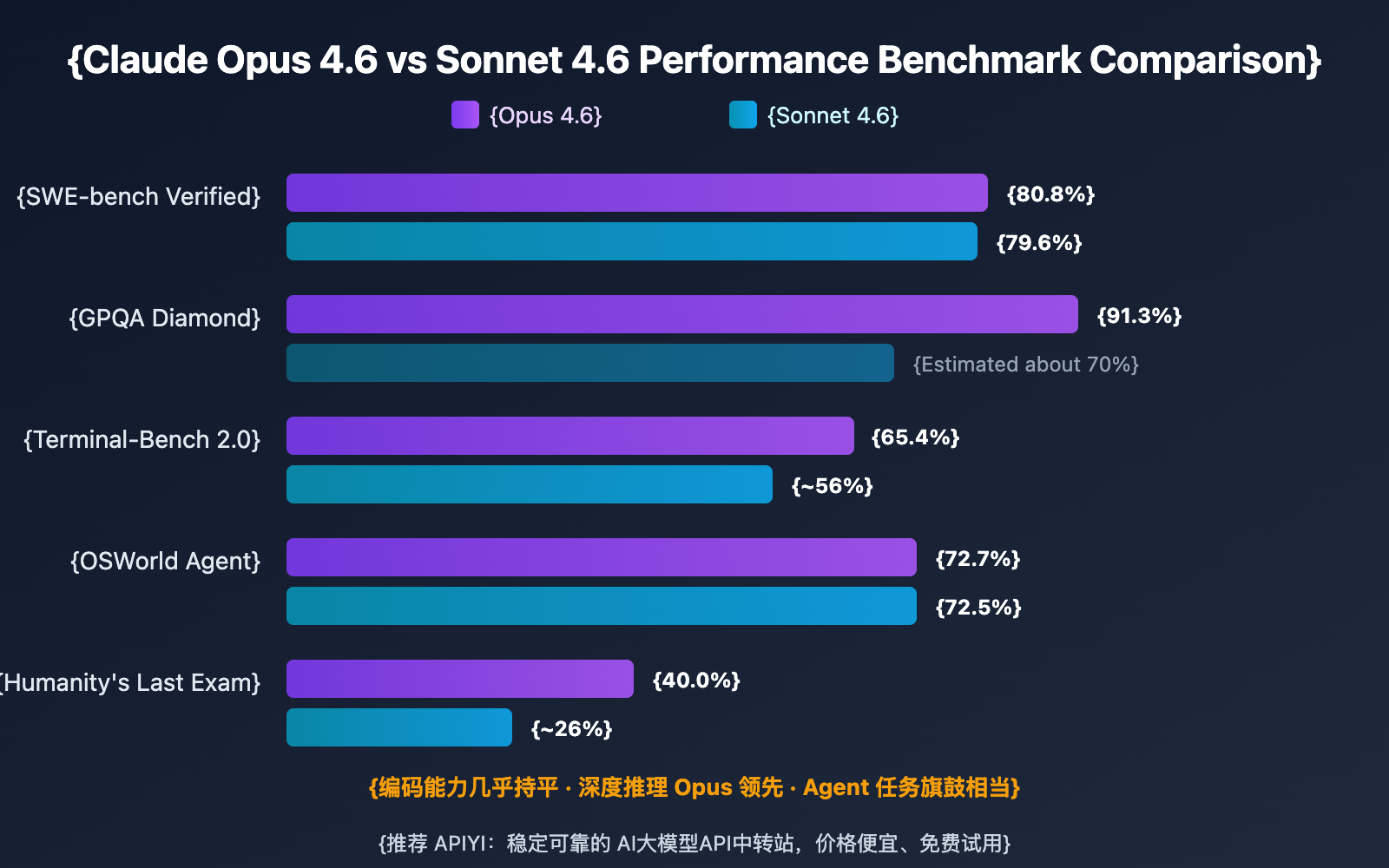
| Benchmark | Opus 4.6 | Sonnet 4.6 | Insights |
|---|---|---|---|
| SWE-bench Verified | 80.8% | 79.6% | Coding capabilities are nearly identical |
| GPQA Diamond | 91.3% | — | Opus leads in scientific reasoning |
| Terminal-Bench 2.0 | 65.4% | ~56% | Opus is stronger in terminal operations |
| OSWorld Agent | 72.7% | 72.5% | Agent capabilities are on par |
| Humanity's Last Exam | 40.0% | ~26% | Opus crushes complex reasoning |
| GDPval-AA | ~144 Elo lead over GPT-5.2 | — | #1 for knowledge-work tasks |
Key Findings: In everyday coding (SWE-bench) and Agent tasks (OSWorld), Sonnet 4.6 is already nipping at the heels of Opus 4.6. However, in scenarios requiring deep reasoning—like Humanity's Last Exam (college-level interdisciplinary puzzles) and GPQA Diamond (graduate-level science questions)—Opus 4.6 shows a significant performance gap.
🎯 Testing Tip: We recommend using APIYI (apiyi.com) to call both models simultaneously for A/B testing. The platform supports switching models via a unified interface, allowing you to compare results with a single API Key.
Core Capability Differences: Claude Opus 4.6 vs. Sonnet 4.6
Beyond the benchmarks, there are several core differences in real-world usage worth noting.
Exclusive Advantages of Claude Opus 4.6
1. Adaptive Thinking
Opus 4.6 is Anthropic's first model to support Adaptive Thinking. It automatically adjusts its reasoning depth based on task complexity. Developers can even use the /effort parameter to manually control the trade-off between quality, speed, and cost. It gives quick answers to simple questions and deep thought to complex ones.
2. 1 Million Token Context Window (Beta)
Opus 4.6 is the first in the Opus family to support a 1-million-token context window. In MRCR v2 (8-needle 1-million-token version) tests, it scored 76%, compared to just 18.5% for the previous generation. This means you can process 10-15 full papers or massive codebases in one go.
3. Agent Teams Parallel Capabilities
Within Claude Code, Opus 4.6 supports "Agent Teams," allowing it to schedule multiple sub-tasks in parallel. This significantly boosts efficiency for scenarios like code reviews and refactoring in large-scale projects.
Core Advantages of Claude Sonnet 4.6
1. Ultimate Cost-Performance Ratio
Sonnet 4.6 costs only 20% of what Opus does for the same task. In the SWE-bench coding evaluation, it trailed by only 1.2 percentage points despite the 5x price difference. For most daily coding and chat tasks, this offers the best ROI.
2. Faster Response Times
Sonnet 4.6 clearly outperforms Opus 4.6 in terms of inference speed, making it ideal for latency-sensitive production environments. Sonnet is the go-to choice for batch processing and real-time interactive applications.
3. World Leader for Office and Finance Agents
Sonnet 4.6 ranks #1 globally in office productivity, finance Agent tasks, and large-scale tool-calling benchmarks. If your use case leans toward structured data processing and tool integration, Sonnet 4.6 is the better choice.
Claude Opus 4.6 vs. Sonnet 4.6: Recommended Scenarios

| Use Case | Recommended Model | Reason |
|---|---|---|
| Daily Coding & Code Completion | Sonnet 4.6 | SWE-bench gap is only 1.2%, with 80% lower costs |
| Large Codebase Refactoring | Opus 4.6 | Agent Teams + 1M context window |
| Scientific Research Paper Analysis | Opus 4.6 | GPQA 91.3% + read long docs in one go |
| Batch Content Generation | Sonnet 4.6 | Batch API at half price + faster speeds |
| Customer Service Chatbots | Sonnet 4.6 | Low latency, low cost, and high enough quality |
| Legal/Financial Compliance | Opus 4.6 | Ranked #1 globally on GDPval-AA |
| Office Automation Agents | Sonnet 4.6 | Ranked #1 globally in office productivity benchmarks |
| Complex Math/Scientific Reasoning | Opus 4.6 | HLE 40%, far outperforming competitors |
🎯 Recommendation: Sonnet 4.6 is more than enough for 80% of your daily developer tasks. Only switch to Opus 4.6 when you need deep reasoning, an ultra-long context window, or the absolute highest quality output. We recommend enabling both models via APIYI so you can call them flexibly based on your needs.
Claude Opus 4.6 and Sonnet 4.6 Quick Start
Both models are compatible with the OpenAI SDK format and can be called via a unified interface through the APIYI platform.
Minimal Example
The following code demonstrates how to switch between Opus and Sonnet using the same API Key:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Use Sonnet 4.6 for daily tasks (low cost)
response = client.chat.completions.create(
model="claude-sonnet-4-6-20260217",
messages=[{"role": "user", "content": "Help me write a Python quicksort"}]
)
print("Sonnet:", response.choices[0].message.content)
# Switch to Opus 4.6 for complex reasoning (high quality)
response = client.chat.completions.create(
model="claude-opus-4-6-20260205",
messages=[{"role": "user", "content": "Analyze the methodological flaws in this paper..."}]
)
print("Opus:", response.choices[0].message.content)
View full implementation code (including automatic model routing)
import openai
from typing import Optional
def smart_call(
prompt: str,
complexity: str = "normal",
api_key: str = "YOUR_API_KEY"
) -> str:
"""
Automatically select the model based on task complexity
Args:
prompt: User input
complexity: Task complexity - simple/normal/complex
api_key: API Key
Returns:
Model response content
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Automatic routing based on complexity
model_map = {
"simple": "claude-sonnet-4-6-20260217",
"normal": "claude-sonnet-4-6-20260217",
"complex": "claude-opus-4-6-20260205"
}
model = model_map.get(complexity, "claude-sonnet-4-6-20260217")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=4096
)
return response.choices[0].message.content
# Daily coding → Automatically use Sonnet (saves money)
result = smart_call("Write a CRUD example for a REST API", complexity="normal")
# Complex reasoning → Automatically use Opus (quality first)
result = smart_call("Analyze the time complexity of this code and optimize it", complexity="complex")
Pro Tip: Get your API Key through APIYI (apiyi.com). One account lets you call both Opus 4.6 and Sonnet 4.6. The platform supports OpenAI-compatible formats, so you won't need to change your existing code.
FAQ
Q1: Is there a big gap in coding ability between Sonnet 4.6 and Opus 4.6?
The gap is minimal. In the SWE-bench Verified evaluation, Opus scored 80.8% vs Sonnet's 79.6%—a difference of only 1.2 percentage points. For most coding tasks, Sonnet 4.6 is more than enough and costs only 20% of Opus. Opus only shows a significant advantage in large-scale codebase refactoring or when you need parallel Agent Teams.
Q2: How does Opus 4.6’s 1-million-token context window actually perform?
It's incredibly powerful. In the MRCR v2 8-needle 1M token test, it scored 76%, while the previous generation only managed 18.5%. In practice, it can handle about 10-15 academic papers or the entire codebase of a medium-sized project at once. If your task involves ultra-long documents, Opus 4.6 is currently the best choice. Both models are available for testing on APIYI (apiyi.com).
Q3: How do I use these two models on APIYI?
- Visit APIYI (apiyi.com) to register an account.
- Top up your balance (get a 10% bonus on payments of $100 or more).
- Get your API Key from the console.
- Use
claude-opus-4-6-20260205orclaude-sonnet-4-6-20260217as the model name. - The interface is fully compatible with the OpenAI format, so you can reuse your existing code directly.
Summary
Key Takeaways: Claude Opus 4.6 vs. Sonnet 4.6:
- 5x Price Difference: Sonnet 4.6 costs $3/$15 per million tokens, while Opus 4.6 is $15/$75. For 80% of daily tasks, Sonnet handles them just fine.
- Coding Ability is Neck-and-Neck: With only a 1.2% difference on the SWE-bench, Sonnet 4.6 is the undisputed king of price-to-performance for coding scenarios.
- Opus Wins in Deep Reasoning: Scoring 91.3% on GPQA, 40% on HLE, and 76% on MRCR, Opus remains irreplaceable for scientific research and complex reasoning.
- Scenario-Based Choice: Choose Sonnet for daily development and batch tasks; opt for Opus for research, long documents, and complex logic.
We recommend using both models through APIYI (apiyi.com). You'll get a 10% bonus on top-ups of $100 or more, effectively giving you a 15% discount compared to official prices. The platform supports a unified interface, allowing you to switch between models with a single API key to find the perfect balance between performance and cost.
📚 References
⚠️ Link Format Note: All external links use the
Resource Name: domain.comformat for easy copying. They are not clickable to avoid SEO weight loss.
-
Anthropic Official Release – Claude Opus 4.6: Core capabilities and technical specs of Opus 4.6
- Link:
anthropic.com/news/claude-opus-4-6 - Description: Official announcement including full benchmark data.
- Link:
-
Anthropic Official Release – Claude Sonnet 4.6: Sonnet 4.6 release info and evaluation
- Link:
anthropic.com/news/claude-sonnet-4-6 - Description: Official technical specifications and capability overview.
- Link:
-
Claude API Pricing Page: Latest official API pricing
- Link:
platform.claude.com/docs/en/about-claude/pricing - Description: Anthropic's official pricing standards.
- Link:
-
VentureBeat Comparative Analysis: Performance analysis of Sonnet 4.6
- Link:
venturebeat.com/technology/anthropics-sonnet-4-6-matches-flagship-ai-performance-at-one-fifth-the-cost - Description: Independent third-party evaluation perspective.
- Link:
Author: Tech Team
Tech Exchange: Feel free to join the discussion in the comments. For more resources, visit the APIYI (apiyi.com) tech community.