作者注:xAI 旗舰模型 Grok 4.20 Beta 持续迭代,幻觉率 78% 行业最低,原生 4 Agent 多智能体协作,200 万 Token 上下文,支持语音对话和图像视频生成,本文深度分析核心能力和实际价值
Elon Musk 旗下的 xAI 在 2026 年初发布了 Grok 4.20 Beta,此后持续迭代优化。这款模型最独特的标签是"行业最低幻觉率"——在 Artificial Analysis Omniscience 测试中取得 78% 的非幻觉率,同时引入原生 4 Agent 多智能体架构和 200 万 Token 上下文窗口。最新的 4 月更新进一步改进了指令跟随、LaTeX 排版和图像搜索触发准确性。
核心价值: 5 分钟了解 Grok 4.20 Beta 的核心能力、3 种模型变体的区别、多模态能力,以及它与 Claude/GPT 的定位差异。

Grok 4.20 Beta 核心信息速览
| 信息项 | 详情 |
|---|---|
| 发布日期 | 2026 年 2 月 17 日(公测)/ 3 月 10 日(API) |
| 开发方 | xAI (Elon Musk) |
| 核心定位 | 高诚信度 + 多智能体 + 多模态旗舰 |
| 幻觉率 | 78% 非幻觉率(行业最高) |
| 上下文窗口 | 200 万 Token(从 Grok 4 的 256K 提升) |
| 模型变体 | Reasoning / Non-Reasoning / Multi-Agent |
| 输出速度 | 247.8 tok/s(推理模型中位数 68.5) |
| 定价 | 输入 $2/MTok,输出 $6/MTok |
| 多模态 | 文本/图像/视频/语音 输入输出 |
Grok 4.20 Beta 的市场定位
在 AI 大模型竞争格局中,Grok 4.20 Beta 选择了一条差异化路线:不追求在所有评测上做到最高分,而是在诚信度(低幻觉)、速度和多智能体协作三个维度建立独特优势。
Artificial Analysis 智能指数评分 48 分,高于同价位模型中位数 31 分,但与 Claude Opus 4.5 和 GPT-5.4 的顶级评分仍有差距。xAI 的策略是——与其给你一个偶尔惊艳但经常出错的模型,不如给你一个始终可靠的模型。
Grok 4.20 Beta 核心能力详解
能力 1: 行业最低幻觉率
Grok 4.20 Beta 最突出的能力是幻觉控制:
| 评测 | Grok 4.20 | 行业平均 | 说明 |
|---|---|---|---|
| AA-Omniscience 非幻觉率 | 78% | ~60-70% | 行业最高 |
| 指令跟随 | 顶级 | – | 严格提示词遵循 |
| LaTeX 排版 | 持续优化 | – | 4 月更新改进 |
78% 的非幻觉率意味着 Grok 4.20 在回答事实性问题时,每 5 个回答中约有 4 个是准确的——这在所有已测试模型中是最高的。对于需要高度可靠性的场景(如医疗咨询、法律分析、学术研究),低幻觉率可能比更高的"智能指数"更有实际价值。
4 月持续优化: 最新迭代进一步改进了指令跟随能力和 LaTeX 数学公式排版,图像搜索触发的准确性也有提升。
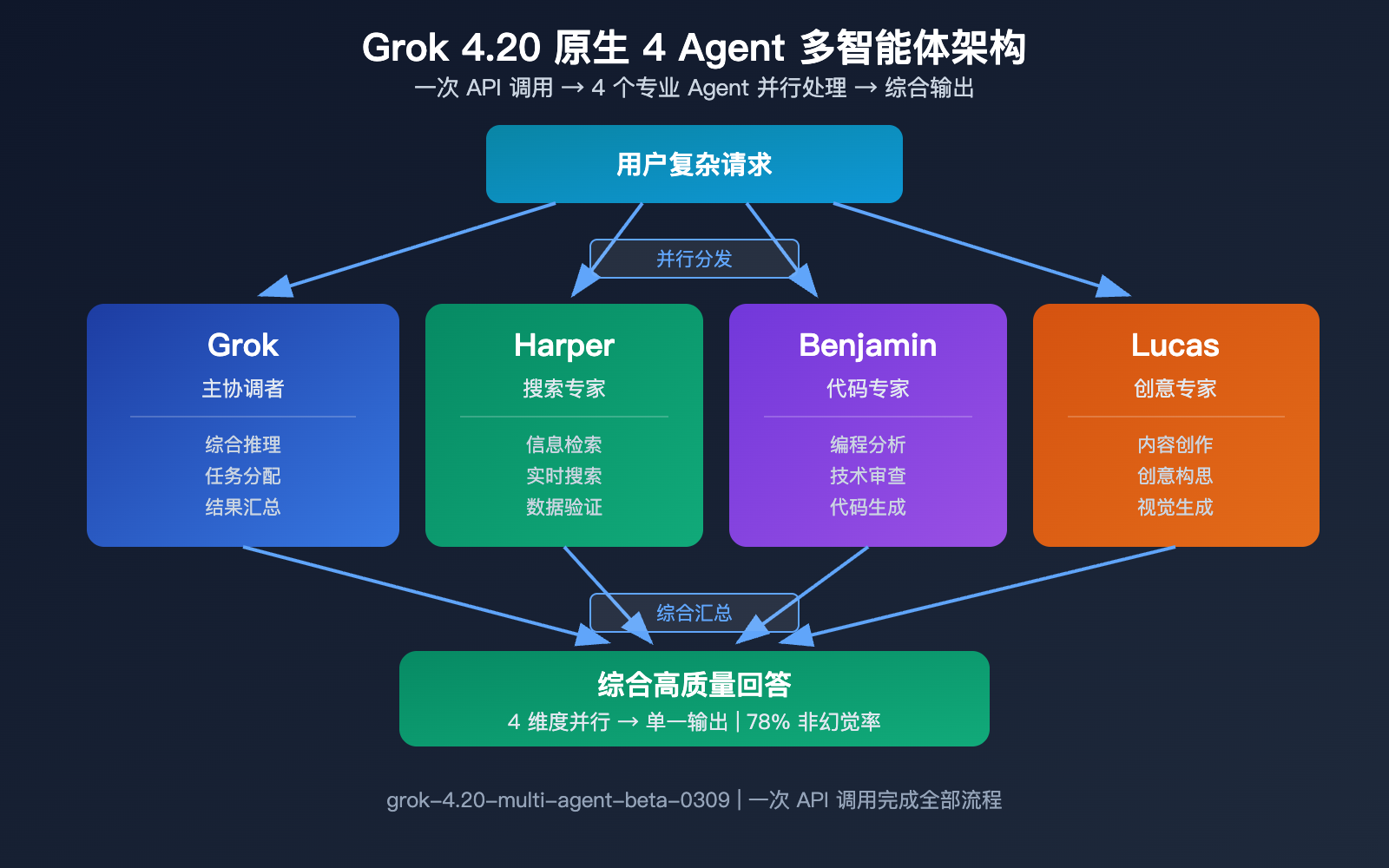
能力 2: 原生 4 Agent 多智能体架构
Grok 4.20 Beta 引入了业界首个原生多智能体 API——一次 API 调用,后台有 4 个专业 Agent 并行处理:
| Agent 名称 | 专长 | 角色 |
|---|---|---|
| Grok | 综合推理和对话 | 主协调者 |
| Harper | 研究和信息检索 | 搜索专家 |
| Benjamin | 编程和技术分析 | 代码专家 |
| Lucas | 创意和内容生成 | 创意专家 |
当你通过 Multi-Agent API 发送一个复杂查询时,4 个 Agent 会同时并行工作,各自发挥专长,最后由 Grok 综合汇总。这种架构在处理需要多维度能力的复杂任务时效率更高。
能力 3: 200 万 Token 上下文
Grok 4.20 的上下文窗口从前代 Grok 4 的 256K 直接跳升至 200 万 Token——这是目前所有主流 API 模型中最长的:
| 模型 | 上下文窗口 | 对比 |
|---|---|---|
| Grok 4.20 Beta | 200 万 Token | 行业最长 |
| GPT-5.4 (扩展) | 100 万 Token | Grok 2 倍 |
| Claude Opus 4.5 | 200K Token | Grok 10 倍 |
| Gemini 2.5 Pro | 100 万 Token | Grok 2 倍 |
200 万 Token 约等于 150 万中文字或 300 万英文单词,足以容纳一整本长篇小说或一个大型代码仓库。
🎯 开发者建议: Grok 4.20 Beta 在幻觉控制和上下文长度上有独特优势。通过 API易 apiyi.com 可以同时接入 Grok 4.20 和 Claude、GPT,在你的实际任务中对比不同模型的可靠性和准确性。
Grok 4.20 Beta 3 种模型变体
Grok 4.20 模型家族
xAI 发布了 3 种不同的 Grok 4.20 变体,定价完全相同但能力各异:
| 变体 | 模型 ID | 核心能力 | 适用场景 |
|---|---|---|---|
| Non-Reasoning | grok-4.20-beta-0309-non-reasoning | 快速直接回答 | 日常对话、简单任务 |
| Reasoning | grok-4.20-beta-0309-reasoning | 深度推理链 | 复杂分析、数学 |
| Multi-Agent | grok-4.20-multi-agent-beta-0309 | 4 Agent 并行 | 复杂多维度任务 |
Grok 4.20 定价分析
| 定价项 | Grok 4.20 | Grok 4 (前代) | 变化 |
|---|---|---|---|
| 输入 | $2/MTok | $3/MTok | 降 33% |
| 输出 | $6/MTok | $15/MTok | 降 60% |
| 三个变体 | 价格相同 | – | 按需选择 |
Grok 4.20 的定价非常有竞争力:输入 $2、输出 $6,比前代 Grok 4 降了 33-60%。与竞品对比:GPT-5.4 标准版 $2.5/$15,Claude Opus 4.5 更贵。在同等价位的模型中,Grok 4.20 的幻觉率最低、速度最快(247.8 tok/s)。
Grok 4.20 Rapid Learning 快速学习架构
Grok 4.20 的一项独特技术是 Rapid Learning(快速学习)架构:模型会基于真实用户使用数据每周自动更新能力,无需手动发布新版本。这意味着你使用的 Grok 4.20 会随着时间持续变得更好——4 月的 Grok 4.20 已经比 2 月的版本更强。
💡 差异化优势: Rapid Learning 是 Grok 独有的——其他模型更新需要发布新版本号,而 Grok 4.20 在同一版本内持续进化。这就是为什么"4 月持续迭代"对 Grok 用户格外重要。
Grok 4.20 Beta 多模态能力
Grok 4.20 完整多模态矩阵
| 模态 | 输入 | 输出 | 说明 |
|---|---|---|---|
| 文本 | ✓ | ✓ | 核心能力 |
| 图像 | ✓ | ✓ | Grok Imagine API |
| 视频 | ✓ | ✓ | 端到端视频生成 |
| 语音 | ✓ | ✓ | Grok Voice 低延迟 |
| 代码 | ✓ | ✓ | Benjamin Agent 专长 |
| 搜索 | – | ✓ | 实时网络搜索 |
Grok Voice 语音能力
Grok Voice 是 Grok 4.20 中最具差异化的多模态能力之一:
- 低延迟语音: 支持数十种语言的实时语音对话
- 工具调用: 语音模式下可触发工具调用和搜索
- 实时数据: 语音对话中可访问实时网络数据
- Agent API: 可通过 API 集成到第三方应用
这使得 Grok 4.20 不仅是一个文字模型,更是一个可以"听、说、看、搜"的全模态 AI 助手。
Grok Imagine 图像与视频生成
xAI 在 Grok 4.20 中推出了 Grok Imagine API——统一的端到端视频和音频生成套件。支持从文字描述生成图片和视频,图像搜索触发准确性在 4 月更新中得到进一步提升。

Grok 4.20 Beta 与竞品对比
Grok 4.20 vs GPT-5.4 vs Claude Opus 4.5
| 对比维度 | Grok 4.20 Beta | GPT-5.4 | Claude Opus 4.5 |
|---|---|---|---|
| 幻觉率 | 78% (最低) | ~65% | ~70% |
| 智能指数 | 48 | ~55+ | ~55+ |
| 上下文 | 200 万 Token | 272K-1M | 200K |
| 输出速度 | 247.8 tok/s | ~100 tok/s | ~80 tok/s |
| 输入价格 | $2/MTok | $2.5/MTok | 更高 |
| 输出价格 | $6/MTok | $15/MTok | 更高 |
| 多智能体 | 原生 4 Agent | 无 | 无 |
| 语音对话 | 原生支持 | 有限 | 无 |
| 电脑操控 | 无 | 原生支持 | 有限 |
| 编程评测 | 中上 | 顶级 | 顶级 |
Grok 4.20 的优势领域: 幻觉控制、速度、定价、上下文长度、多智能体、语音
Grok 4.20 的劣势领域: 纯智能/推理评测、编程专项评测
选型建议: 如果你最看重回答的准确性和可靠性,Grok 4.20 是首选。如果你最看重编程能力和复杂推理,Claude/GPT 更强。
🚀 对比建议: 通过 API易 apiyi.com 可以同时接入 Grok 4.20、GPT-5.4 和 Claude,一个 API Key 在三大模型间自由切换,快速找到最适合你场景的模型。
Grok 4.20 Beta API 接入
通过 API易 快速接入
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Non-Reasoning 模式 (快速回答)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[{"role": "user", "content": "解释量子计算的基本原理"}]
)
print(response.choices[0].message.content)
查看 Reasoning 和 Multi-Agent 模式调用
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Reasoning 模式 (深度推理)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[{"role": "user", "content": "分析全球AI芯片供应链的风险点"}]
)
# Multi-Agent 模式 (4 Agent 并行)
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[{
"role": "user",
"content": "写一篇关于量子计算商业化前景的研究报告"
}]
)
# 4 个 Agent (Grok/Harper/Benjamin/Lucas) 并行处理
print(response.choices[0].message.content)
💰 成本优势: Grok 4.20 的 $2/$6 定价是当前旗舰模型中最低之一。通过 API易 apiyi.com 调用可以进一步优化成本,同时支持在 Grok、Claude、GPT、Gemini 之间按需切换。
常见问题
Q1: Grok 4.20 的三个变体该选哪个?
日常对话选 Non-Reasoning(最快),复杂分析选 Reasoning(更深入),多维度复杂任务选 Multi-Agent(4 Agent 并行)。三个变体定价相同($2/$6 MTok),可以根据任务自由切换。通过 API易 apiyi.com 一个 Key 即可调用全部变体。
Q2: Grok 4.20 的幻觉率最低意味着什么?
78% 非幻觉率意味着在事实性回答中,Grok 比其他模型更不容易"编造"信息。对于需要高可靠性的场景(医疗、法律、学术、企业决策),这比更高的"智能指数"更有实际价值。但在创意写作和头脑风暴场景,适度的"幻觉"反而可能是优势。
Q3: Grok 4.20 会继续更新吗?
会。Grok 4.20 采用 Rapid Learning 架构,基于用户使用数据每周自动优化。4 月的更新已改进了指令跟随、LaTeX 排版和图像搜索。同一个模型 ID 下的能力会持续提升,无需等待新版本号。通过 API易 apiyi.com 调用时,你会自动享受到最新的优化。
总结
Grok 4.20 Beta 的核心价值判断:
- 行业最低幻觉率: 78% 非幻觉率,在需要高可靠性的场景中具有独特优势
- 原生多智能体: 4 Agent(Grok/Harper/Benjamin/Lucas)并行协作,复杂任务效率更高
- 200 万 Token 超长上下文: 主流 API 模型中最长,配合 247.8 tok/s 的速度优势
- 持续进化: Rapid Learning 每周自动更新,4 月版本已强于 2 月首发
Grok 4.20 Beta 走了一条差异化路线——不追求全面最强,而是在诚信度、速度和多智能体三个维度做到业界领先。推荐通过 API易 apiyi.com 同时接入 Grok 4.20 和 Claude、GPT,一个 Key 在多模型间对比,找到最适合你场景的方案。
📚 参考资料
-
xAI 官方 Grok 4.20 动态: 最新更新和功能公告
- 链接:
x.ai/news - 说明: 包含 Grok 4.20 的持续迭代日志和功能更新
- 链接:
-
Artificial Analysis – Grok 4.20 评测: 独立第三方评测和数据
- 链接:
artificialanalysis.ai/models/grok-4-20 - 说明: 包含智能指数、幻觉率、速度和定价的详细分析
- 链接:
-
Grok 4.20 多智能体详解: 4 种模型变体的完整对比
- 链接:
help.apiyi.com/en/grok-4-20-beta-4-models-multi-agent-reasoning-api-guide-en.html - 说明: 包含 Reasoning/Non-Reasoning/Multi-Agent 的详细使用场景
- 链接:
-
Grok 4.20 Beta 全面解读: 架构和功能深度分析
- 链接:
buildfastwithai.com/blogs/grok-4-20-beta-explained-2026 - 说明: 包含 Rapid Learning 架构和多模态能力详解
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区分享你使用 Grok 4.20 的体验,更多 AI 模型接入资料可访问 API易 docs.apiyi.com 文档中心