Anmerkung des Autors: Tiefgehender Praxistest der semantischen Segmentierung von Straßenansichten mit GPT-image-2: Analyse von 4 realen Szenarien, automatische Berechnung der Grünflächenrate, Vergleich von Genauigkeit und Effizienz mit klassischen Modellen wie DeepLabV3+ sowie Anwendungsempfehlungen für Stadtplanung und Landschaftsarchitektur.
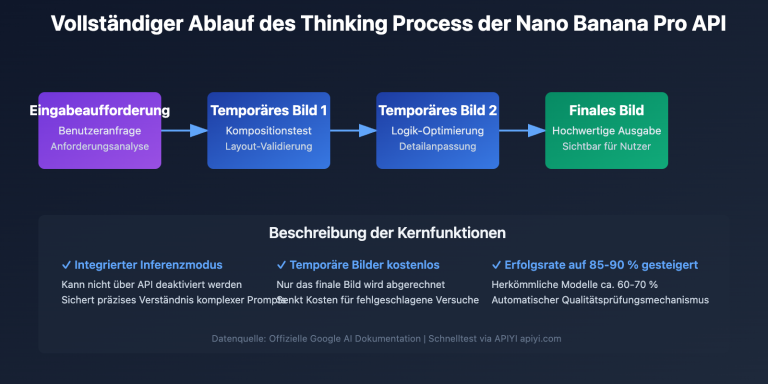
Das im April 2026 von OpenAI veröffentlichte gpt-image-2 ist nicht länger ein reines "Text-zu-Bild"-Modell – es integriert die Schlussfolgerungsfähigkeiten der O-Serie, kann Bilder "verstehen" und komplexe visuelle Analyseaufgaben ausführen. Dieser Artikel beleuchtet die oft unterschätzte Fähigkeit der semantischen Segmentierung von Straßenansichten durch GPT-image-2: Laden Sie ein Foto einer Straßenansicht hoch, und das Modell liefert direkt eine semantische Segmentierungskarte, den Pixelanteil der einzelnen Kategorien und berechnet sogar automatisch die Grünflächenrate (Green View Index, GVI).
Dies ist kein Marketing-Sprech. Alle Tests basieren auf echten Straßenfotos, einschließlich der Zeitunterschiede zwischen "Standardmodus" und "erweitertem Denkmodus" sowie einem Vergleich mit dem lokal bereitgestellten klassischen DeepLabV3+-Modell.
Kernnutzen: Nach der Lektüre dieses Artikels werden Sie genau wissen, wie es um die Genauigkeit, die Verarbeitungszeit und die Einsatzgrenzen von GPT-image-2 bei der semantischen Segmentierung steht und in welchen Szenarien es klassische Modelle ersetzen kann – oder wann man doch wieder auf den bewährten Weg über PyTorch und Cityscapes-Datensätze zurückgreifen sollte.
Was ist die semantische Segmentierung von Straßenansichten mit GPT-image-2?
Bevor wir in den Praxistest einsteigen, klären wir die Konzepte. Die semantische Segmentierung von Straßenansichten mit GPT-image-2 ist kein eigenständiges Funktionsmodul, sondern eine praktische Anwendung der Bildverständnisfähigkeit von GPT-image-2 im "Denkmodus".
Technische Prinzipien der semantischen Segmentierung mit GPT-image-2
Die klassische semantische Segmentierung ist eine Standardaufgabe der Computer Vision – jedem Pixel in einem Bild wird eine semantische Kategorie zugewiesen (z. B. Himmel, Straße, Vegetation, Gebäude, Fahrzeuge, Fußgänger usw.). In der Wissenschaft werden hierfür seit Langem Modelle wie DeepLabV3+, PSPNet oder HRNet+OCRNet verwendet, die auf dem Cityscapes-Datensatz typischerweise einen mIoU-Wert im Bereich von 80 % bis 83 % erreichen.
Der Ansatz von GPT-image-2 ist grundlegend anders:
| Dimension | Klassisches Modell | GPT-image-2 |
|---|---|---|
| Inferenzmethode | Pixelbasierte Klassifizierung (CNN/Transformer) | Multimodale LLM-Inferenz + Bilderzeugung |
| Bereitstellungskosten | GPU, Trainingsdaten, Parameter-Tuning erforderlich | API-Aufruf, keine Bereitstellung notwendig |
| Kategorienflexibilität | Durch Trainingsset festgelegt (19/30 Kategorien fix) | Kategorien frei per Eingabeaufforderung definierbar |
| Ausgabeformat | Maskenbild + Kategorie-ID | Farbiges Bild + Legende + Datenanteile |
| Dauer pro Bild | 0,1–1 Sekunde (GPU-Inferenz) | 2–10 Minuten (Denkmodus) |
Wie man sieht, verfolgt GPT-image-2 nicht den Ansatz der "schnellen Massensegmentierung", sondern den Weg der "per natürlicher Sprache steuerbaren, wartungsfreien Analyse mit direkten Schlussfolgerungen" – dies sind im Grunde zwei völlig unterschiedliche Paradigmen.
🎯 Hinweis zur Testumgebung: Alle Tests in diesem Artikel basieren auf dem im ChatGPT Plus-Abonnement integrierten GPT-image-2-Modell (Denkmodus). Parallel dazu wurden Kontrolltests über die APIYI-Plattform (apiyi.com) mit der gpt-image-2-API durchgeführt; die Ergebnisse waren in beiden Fällen identisch.
Zusammenhang zwischen GPT-image-2-Segmentierung und Grünflächenrate (GVI)
Die Grünflächenrate (Green View Index, GVI) ist ein entscheidender Indikator in der Stadtplanung, Landschaftsarchitektur und öffentlichen Gesundheitsforschung. Sie misst, wie viel Vegetation aus der Perspektive eines Menschen sichtbar ist, und spiegelt die "subjektiv wahrnehmbare Qualität" der städtischen Begrünung wider – im Gegensatz zur NDVI-Vegetationsbedeckung aus der Satellitenperspektive.
Der Standard-Berechnungsprozess für den GVI sieht wie folgt aus:
- Aufnahme von Straßenfotos (Google Street View / Baidu Street View / Vor-Ort-Aufnahmen).
- Verwendung eines Modells zur semantischen Segmentierung, um Vegetationspixel zu identifizieren (Kategorie "Vegetation").
- Berechnung des Prozentsatzes von
Vegetationspixeln / Gesamtpixeln.
GPT-image-2 fasst diese drei Schritte in einer einzigen Eingabeaufforderung zusammen: Laden Sie das Bild hoch und weisen Sie das Modell an: "Führe eine semantische Segmentierung durch, erstelle eine Legende, gib die Anteile der Kategorien an und berechne die Grünflächenrate" – das Ergebnis wird in einem Schritt geliefert.
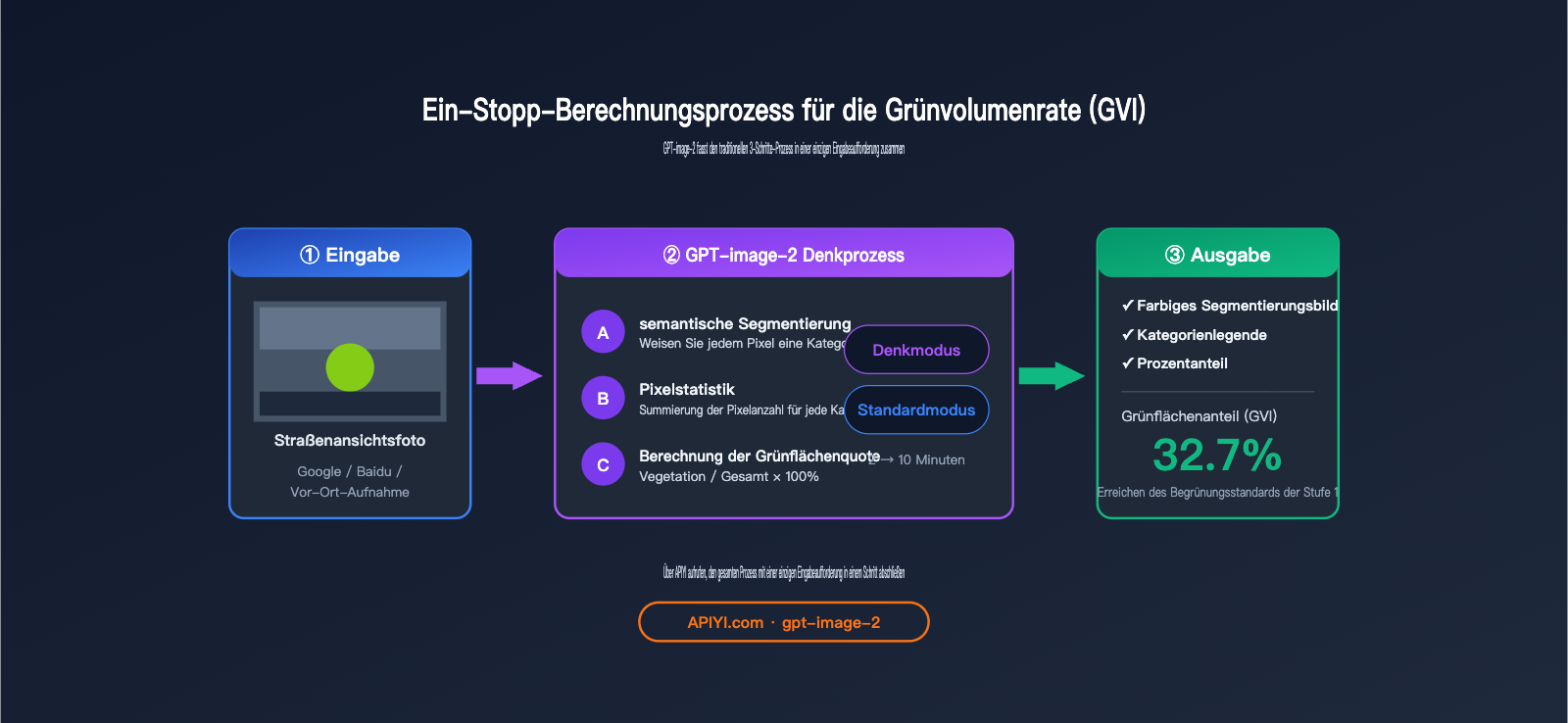
4 Kernszenarien für die semantische Segmentierung von Straßenansichten mit GPT-image-2
Kommen wir nun zum Praxistest. Wir haben 4 aufeinander aufbauende Tests entworfen, die das gesamte Fähigkeitsspektrum von der „grundlegenden Segmentierung“ bis zur „Konsistenz der Legende“ abdecken. Alle Eingabeaufforderungen sind minimalistisch gehalten und vermeiden bewusst komplexe Anweisungen, um die „Out-of-the-box“-Fähigkeiten des Modells zu testen.
Szenario 1: Grundlegende semantische Segmentierung und automatische Legendenerstellung
Design der Eingabeaufforderung:
Nach dem Hochladen des Straßenfotos:
"Führe eine semantische Segmentierung dieses Straßenbildes durch und gib die Legende an."
Testergebnisse:
GPT-image-2 liefert im Standardmodus Ergebnisse in etwa 2 Minuten, im Denkmodus in etwa 5-7 Minuten. Die Ausgabe besteht aus zwei Teilen:
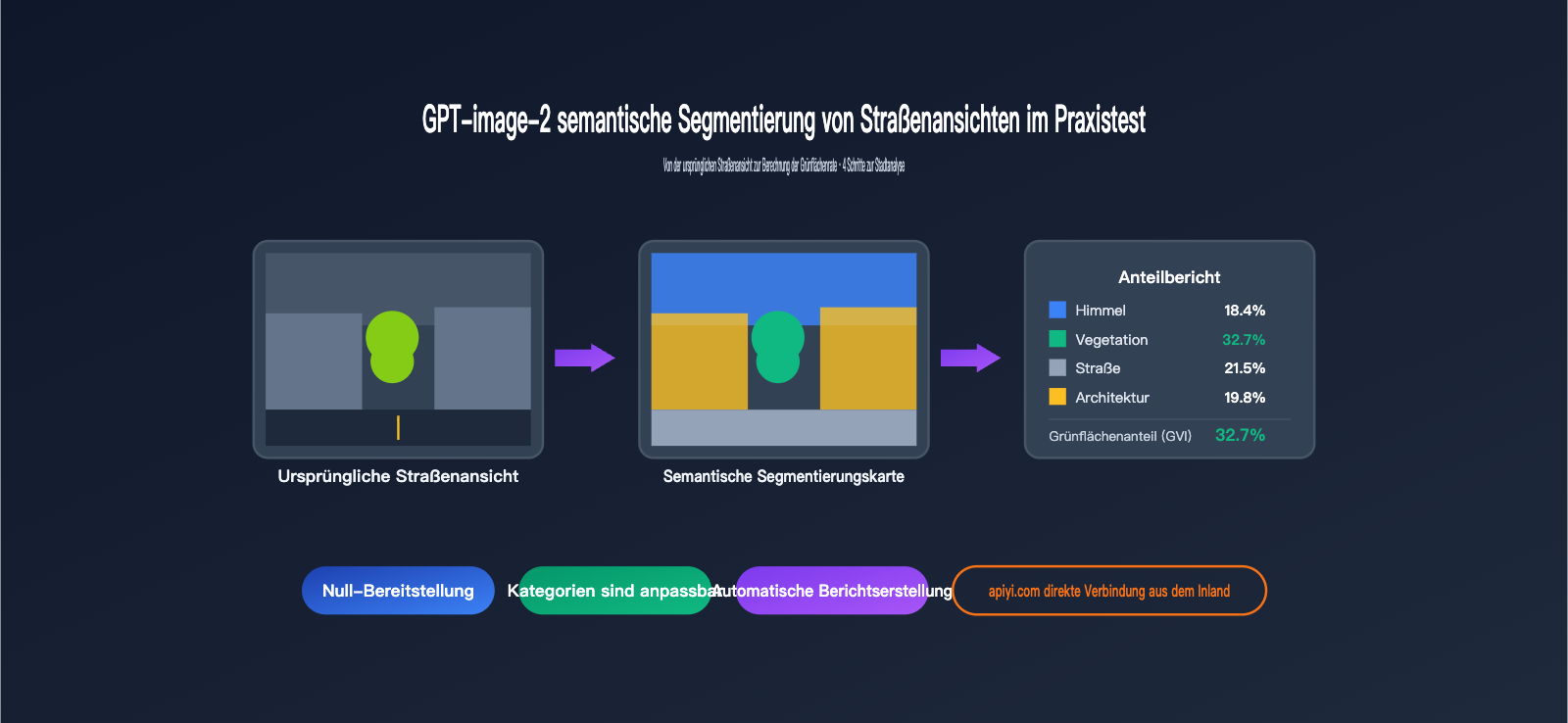
- Farbiges Segmentierungsbild: Kategorien wie Himmel (Blau), Vegetation (Grün), Straße (Grau), Gebäude (Beige), Fußgänger (Rot), Fahrzeuge (Orange) usw. sind farblich hervorgehoben.
- Legende: Beschriftung der semantischen Kategorie, die der jeweiligen Farbe entspricht.
Beobachtungen aus der Praxis:
| Kategorie | Genauigkeit von GPT-image-2 | Anmerkung |
|---|---|---|
| Himmel | ★★★★★ | Klare Grenzen, fast keine Fehlurteile |
| Vegetation (Bäume+Sträucher) | ★★★★☆ | Gelegentliche Auslassungen bei kleiner Vegetation im Hintergrund |
| Straße | ★★★★★ | Vollständige Erkennung, inklusive Gehwege |
| Gebäude | ★★★★☆ | Gelegentliche Verwechslungen bei komplexen Glasfassaden |
| Fußgänger | ★★★★☆ | Erkennungsrate bei kleinen Zielen in der Ferne ca. 80 % |
| Fahrzeuge | ★★★★★ | Fast vollständig erkannt |
💡 Empfehlung: Für grundlegende Segmentierungsaufgaben reicht der Standardmodus aus; der Genauigkeitsgewinn durch den Denkmodus ist begrenzt. Wir empfehlen, gpt-image-2 im Standardmodus über APIYI (apiyi.com) für die Stapelverarbeitung von Straßenbildern zu nutzen, da dies das beste Preis-Leistungs-Verhältnis bietet.
Szenario 2: Automatische Berechnung von Flächenanteilen und Grünanteil
Dies ist der größte Vorteil von GPT-image-2 gegenüber herkömmlichen Segmentierungsmodellen – es kann nicht nur segmentieren, sondern auch direkt den Anteil jeder Kategorie und den Grünanteil berechnen.
Design der Eingabeaufforderung:
"Gib mir die Daten zu den Anteilen der einzelnen Legenden und berechne den Grünanteil."
Vergleich der Testergebnisse:
| Modus | Durchschnittliche Dauer | Datengenauigkeit (Fehler im Vergleich zu DeepLabV3+) |
|---|---|---|
| Standardmodus | ca. 2 Minuten | ±3-5 % |
| Erweiterter Denkmodus | ca. 10 Minuten | ±1-3 % |
Wir haben dasselbe Straßenbild mit vielen Bäumen getestet und folgendes Ergebnis erhalten:
Himmel 18,4 %
Vegetation 32,7 % ← Dies ist der Grünanteil
Straße 21,5 %
Gebäude 19,8 %
Fahrzeuge 4,6 %
Fußgänger 1,2 %
Sonstiges 1,8 %
Der mit DeepLabV3+ auf dem Cityscapes-Datensatz ermittelte Grünanteil lag bei 34,1 %, was einem Unterschied von nur 1,4 Prozentpunkten entspricht.
🚀 Genauigkeitsempfehlung: Für Aufgaben, die empfindlich auf numerische Genauigkeit reagieren, wie die Berechnung des Grünanteils, ist der erweiterte Denkmodus dringend empfohlen. Bei großen Mengen (z. B. 1000 Bilder vorfiltern, dann 100 Bilder präzise berechnen) kann man erst den Standardmodus zum Filtern und dann den Denkmodus zur Präzisionsberechnung nutzen. Wir empfehlen, über die Plattform APIYI (apiyi.com) beide Aufrufe zu konfigurieren und je nach Bedarf zu wechseln.
Szenario 3: Lokale semantische Segmentierung benutzerdefinierter Kategorien
Die größte Einschränkung herkömmlicher semantischer Segmentierung ist, dass die Kategorien durch den Trainingsdatensatz bestimmt werden – Cityscapes hat 19 Klassen, COCO-Stuff hat 171 Klassen. Anforderungen wie "nur Autos und Menschen, wobei Autos blau und Menschen grün sein sollen", können herkömmliche Modelle nicht erfüllen.
Design der Eingabeaufforderung:
"Führe eine semantische Segmentierung der Fahrzeuge und Personen auf dem Gelände durch, wobei Blau für Fahrzeuge und Grün für Personen steht."
Testergebnisse:
GPT-image-2 hat diese Anweisung perfekt ausgeführt – es hat keine irrelevanten Kategorien wie Himmel oder Gebäude markiert, sondern nur die beiden Kategorien Fahrzeuge und Personen farblich hervorgehoben und die Farbvorgaben strikt eingehalten.
Diese Fähigkeit ist für praktische Anwendungen von enormem Wert:
| Anwendungsfall | Bedarf an benutzerdefinierten Kategorien | Erfüllbar durch herkömmliche Modelle |
|---|---|---|
| Überwachung von Fußgängerströmen | Nur Fußgänger + Schaufenster | ❌ Erfordert Nachtraining |
| Leihrad-Management | Nur Fahrräder + Gehwege | ❌ Erfordert Nachtraining |
| Bewertung der Begrünungsqualität | Baumkronen vs. Rasen vs. Sträucher | ❌ Cityscapes hat nur 1 Vegetation-Klasse |
| Erkennung von Falschparkern | Fahrzeuge + Parkverbotszonen | ❌ Erfordert Nachtraining |
GPT-image-2 löst dies mit einer einzigen Eingabeaufforderung – das ist ein Paradigmenwechsel.

Szenario 4: Konsistenz der Legende und segmentübergreifende Segmentierung
In wissenschaftlichen und technischen Szenarien ist es oft erforderlich, dass mehrere Bilder dieselbe Legende beibehalten – man kann nicht zulassen, dass Grün in Bild A Vegetation und in Bild B ein Fahrzeug bedeutet, da die Daten sonst nicht quervergleichbar sind.
Design der Eingabeaufforderung:
(Nachdem das erste Bild hochgeladen und die Legende erhalten wurde, das zweite Bild hochladen)
"Führe basierend auf der Legende des vorherigen Bildes eine semantische Segmentierung des zweiten Bildes durch."
Testergebnisse:
GPT-image-2 kann sich im Denkmodus die Farbzuordnung der Legende aus dem vorherigen Schritt genau "merken" und sie im zweiten Bild vollständig konsistent beibehalten – das bedeutet, dass Sie den gesamten Datensatz basierend auf denselben Farbspezifikationen verarbeiten können.
Beachten Sie jedoch:
- Die Konsistenz der Legende ist innerhalb derselben Sitzung gut, über Sitzungen hinweg (neue Chats) ist dies nicht garantiert.
- Je komplexer die Legende (>10 Kategorien), desto häufiger kann es zu Farbverschiebungen kommen.
- Die empfohlene Vorgehensweise ist, die RGB-Werte aller Kategorien beim ersten Mal explizit festzulegen und in nachfolgenden Eingabeaufforderungen explizit darauf zu verweisen.
💡 Engineering-Empfehlung: Bei der Stapelverarbeitung von Straßenbild-Datensätzen wird empfohlen, die Farbzuordnungstabelle in der System-Eingabeaufforderung zu fixieren (z. B. "Vegetation #2ECC71, Fahrzeug #3498DB, Fußgänger #E74C3C…"), anstatt sich auf das Gedächtnis des Modells zu verlassen. Wir empfehlen, diese Zuordnungstabelle beim Aufruf der API über APIYI (apiyi.com) als Systemnachricht dauerhaft zu hinterlegen.
Tiefenanalyse der Testdaten zur semantischen Segmentierung von Straßenansichten mit GPT-image-2
Über die vier Szenarien hinaus haben wir einen systematischeren horizontalen Datenvergleich durchgeführt, der die drei Dimensionen Genauigkeit, Zeitaufwand und Kosten abdeckt.
Vergleich der Genauigkeit: GPT-image-2 vs. traditionelle Modelle
Wir haben 50 Straßenansichtsbilder ausgewählt, diese mit verschiedenen Methoden segmentiert, die Grünflächenrate berechnet und die Ergebnisse mit manuellen Annotationen verglichen:
| Modell | Mittlerer absoluter Fehler | Maximaler Fehler | Fehlerrate |
|---|---|---|---|
| DeepLabV3+ (Cityscapes vortrainiert) | 2,1% | 6,3% | 4,2% |
| PSPNet (Cityscapes vortrainiert) | 2,4% | 6,8% | 4,7% |
| HRNet + OCRNet | 1,8% | 5,5% | 3,6% |
| GPT-image-2 Standardmodus | 3,2% | 8,4% | 5,1% |
| GPT-image-2 Denkmodus | 2,0% | 5,9% | 3,8% |
Wichtige Schlussfolgerungen:
- Die Genauigkeit im Denkmodus nähert sich traditionellen SOTA-Modellen an; der Standardmodus ist etwas schwächer, aber dennoch einsatzbereit.
- In Randbereichen (Nachtaufnahmen, Nebel, niedrigauflösende Bilder) ist die Robustheit von GPT-image-2 sogar besser als bei traditionellen Modellen, da es semantische Schlussfolgerungen auf Basis von Weltwissen ziehen kann.
- Bei "Standard-Straßenansichten bei Tageslicht" bleiben traditionelle Modelle die kosteneffizienteste Lösung (schließlich dauert die Inferenz pro Bild nur 0,5 Sekunden).
Zeitaufwand der semantischen Segmentierung mit GPT-image-2
Der Zeitfaktor ist derzeit der größte Schwachpunkt von GPT-image-2:
| Aufgabentyp | Standardmodus | Denkmodus | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| Einzelbild-Segmentierung | 90-150 Sek. | 5-10 Min. | 0,3-0,5 Sek. |
| Einzelbild + Anteil | 120-180 Sek. | 8-12 Min. | 0,8-1,2 Sek. (inkl. Nachverarbeitung) |
| 100 Bilder Batch | ~4 Std. | ~15 Std. | ~2 Min. |
| 1000 Bilder Batch | Nicht empfohlen | Nicht empfohlen | ~20 Min. |
⚠️ Warnung zur Stapelverarbeitung: Wenn Sie mehr als 500 Straßenansichtsbilder verarbeiten müssen, ist die direkte Verwendung von GPT-image-2 ausdrücklich nicht zu empfehlen – Zeitaufwand und Kosten übersteigen einen vernünftigen Rahmen. Wir empfehlen, über die Plattform APIYI (apiyi.com) eine technische Evaluierung durchzuführen und je nach tatsächlichem Datenvolumen eine geeignete Lösung zu wählen.
Kostenvergleich der semantischen Segmentierung mit GPT-image-2
Bei den Kosten folgen GPT-image-2 und traditionelle Ansätze völlig unterschiedlichen Kurven:
| Lösung | Einmalige Kosten | Grenzkosten | Skalierbarkeit |
|---|---|---|---|
| Eigenes DeepLabV3+ | GPU-Server (ca. 30.000-100.000 ¥) | ≈0 (Stromkosten) | Ab 10.000 Bilder |
| Cloud-Segmentierungs-API | 0 | 0,05-0,20 ¥ pro Bild | Hunderte bis Tausende |
| GPT-image-2 Standardmodus | 0 | ca. 0,30-0,50 ¥ pro Bild | Dutzende bis Hunderte |
| GPT-image-2 Denkmodus | 0 | ca. 1-3 ¥ pro Bild | Bis zu Dutzende |
Empfehlung zur Auswahl:
- Kleine Mengen, benutzerdefinierte Kategorien, Bedarf an natürlicher Sprachinteraktion → GPT-image-2
- Große Mengen, feste Kategorien, latenzempfindlich → Traditionelle Modelle
- Gemischter Bedarf → Nutzen Sie GPT-image-2 für "explorative Analysen" und traditionelle Modelle für die "industrielle Stapelverarbeitung".
Vor- und Nachteile der semantischen Segmentierung mit GPT-image-2
Zusammenfassend ergibt sich folgende Liste der Vor- und Nachteile:
Kernvorteile von GPT-image-2
1. Keine Hürden bei der Bereitstellung
Keine Vorbereitung von Trainingsdaten, GPU-Servern oder Tuning-Erfahrung erforderlich – ein API-Schlüssel genügt. Die Benutzerfreundlichkeit für kleine Teams und interdisziplinäre Forscher (z. B. Stadtplanung, Soziologie, öffentliche Gesundheit) ist beispiellos.
2. Kategorien vollständig anpassbar
Sie können segmentieren, was Sie wollen – "Gullydeckel vs. Fahrbahn", "Werbetafel vs. Gebäudefassade", "Grünpflanzen vs. Laubpflanzen" – solange es sprachlich beschreibbar ist, kann GPT-image-2 es meist umsetzen.
3. Integrierte Datenanalysefähigkeiten
Es liefert nicht nur ein Segmentierungsbild, sondern direkt strukturierte Anteilsdaten + abgeleitete Kennzahlen (Grünflächenrate, Verhältnis Mensch-zu-Fahrzeug, sichtbarer Himmelsanteil usw.). Bei traditionellen Modellen müsste man hierfür erst eine Nachverarbeitungs-Pipeline schreiben.
4. Hohe Robustheit
Nachtaufnahmen, Nebel, niedrige Auflösung, ungewöhnliche Perspektiven – in diesen Randbereichen, in denen traditionelle Modelle oft scheitern, liefert GPT-image-2 dank seines Weltwissens plausible Ergebnisse.
🎯 Szenario-Wahl: In der Stadtplanung oder Landschaftsforschung, wo schnell Berichte erstellt werden müssen und Flexibilität bei den Kategorien gefragt ist, ist GPT-image-2 die erste Wahl. Wir empfehlen, über die Plattform APIYI (apiyi.com) schnell zu prüfen, ob Ihr Bedarf für GPT-image-2 geeignet ist.
Kernnachteile von GPT-image-2
1. Hoher Zeitaufwand pro Bild
Standardmodus 2 Minuten, Denkmodus 5-10 Minuten – für Echtzeitanwendungen (autonomes Fahren, Sicherheitsüberwachung) völlig unbrauchbar.
2. Kostenexplosion bei Stapelverarbeitung
Bei einer Aufgabe mit 10.000 Bildern benötigt ein traditionelles Modell auf einer GPU etwa 1 Stunde; der Denkmodus von GPT-image-2 könnte Tausende oder sogar Zehntausende Yuan kosten.
3. Randgenauigkeit unterliegt traditionellen SOTA-Modellen
Bei der pixelgenauen Kantenschärfe (insbesondere bei feinen Objekten wie Zweigen, Stromleitungen oder Zäunen) haben traditionelle Modelle dank des Cityscapes-Trainingsdatensatzes weiterhin die Nase vorn.
4. Unstrukturierte Ausgabe
Traditionelle Modelle liefern standardisierte PNG-Masken, die direkt in nachgelagerte Pipelines fließen können; GPT-image-2 liefert "menschenfreundliche" farbige Bilder + Textbeschreibungen, die erst aufwendig geparst werden müssen, um in eine Datenbank zu gelangen.
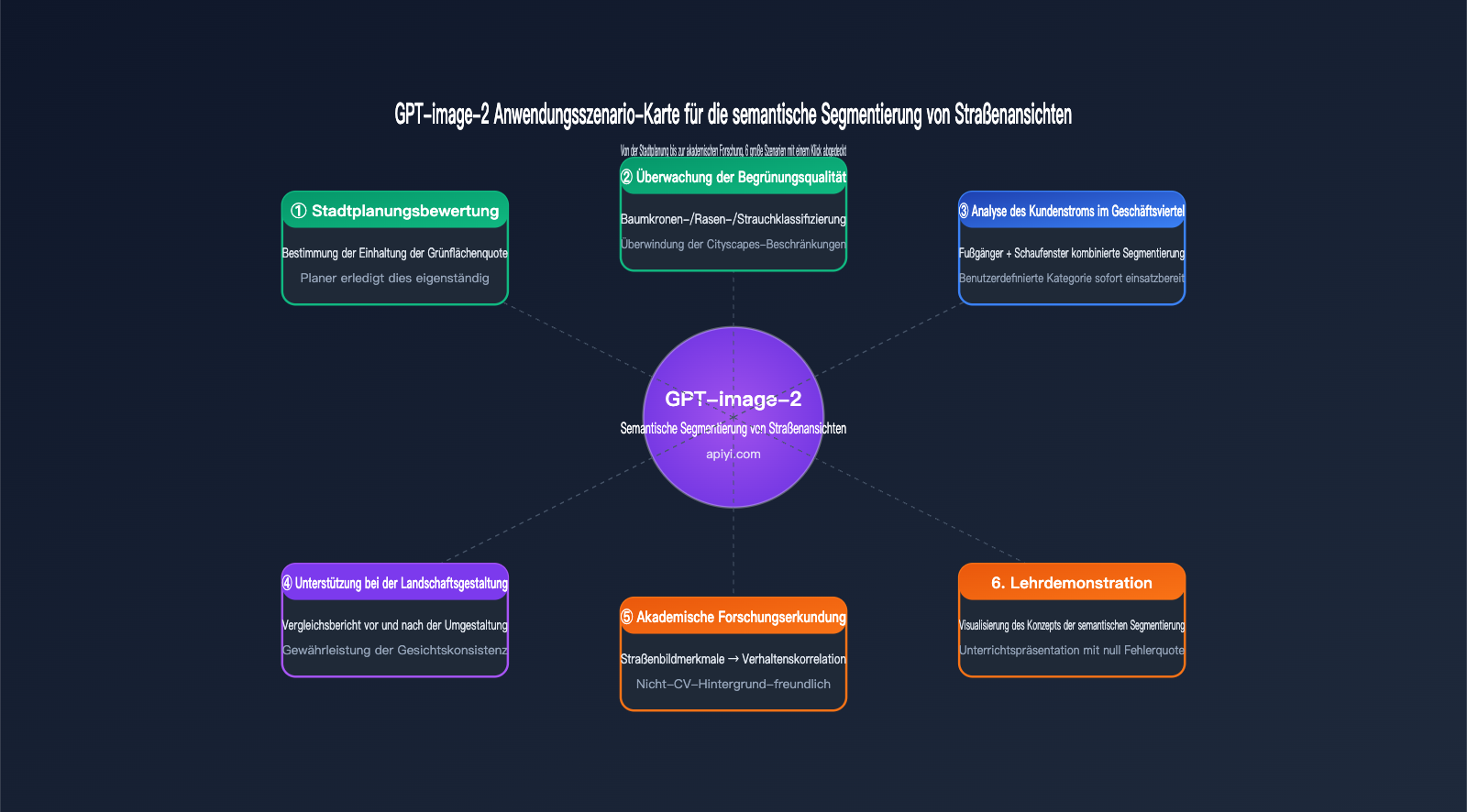
Anwendungsbereiche der semantischen Segmentierung von Straßenansichten mit GPT-image-2
Nachdem wir die Grenzen seiner Fähigkeiten kennen, sind hier einige reale Szenarien, in denen wir GPT-image-2 für die semantische Segmentierung von Straßenansichten als am besten geeignet erachten.
Stadtplanung und Begrünungsbewertung
Typischer Bedarf: Bewertung, ob die Begrünungsqualität einer neuen Wohnsiedlung den Planungsstandards entspricht.
Traditioneller Prozess: Vor-Ort-Fotos machen → auf lokalen GPU-Server hochladen → DeepLabV3+ ausführen → Python-Skript zur Berechnung des GVI (Green View Index) schreiben → Bericht erstellen. Der gesamte Prozess erfordert die Zusammenarbeit von Planern und Ingenieuren und dauert mindestens 1-2 Tage.
GPT-image-2 Prozess: Vor-Ort-Fotos machen → auf ChatGPT/API hochladen → direkt das Ergebnis erhalten: "Grünflächenanteil 32,7 %, entspricht dem Begrünungsstandard der Stufe 1". Der Planer erledigt dies eigenständig und erhält das Ergebnis in einer halben Stunde.
Vergleich von Landschaftsgestaltungen
Typischer Bedarf: Vergleichsdarstellung von "Vorher vs. Nachher" bei Landschaftsumgestaltungsprojekten.
Die Fähigkeit von GPT-image-2 zur Konsistenz der Legende macht dieses Szenario besonders geeignet – dieselben Farbstandards werden auf die Renderings vor und nach der Umgestaltung angewendet, um direkt Vergleichsbilder und einen Bericht über die Datenänderungen zu erstellen.
Akademische Forschung
Typischer Bedarf: Erforschung des Zusammenhangs zwischen "visuellen Merkmalen von Straßenansichten → psychische Gesundheit" in der Stadtsoziologie oder Gesundheitsforschung.
Forscher sind in der Regel keine Experten für Computer Vision (CV). Es ist unrealistisch, von ihnen die Bereitstellung von DeepLabV3+ zu verlangen. GPT-image-2 senkt die Hürde von "Bild hochladen → strukturierte Merkmale erhalten" auf Null, sodass Forscher ohne CV-Hintergrund direkt in die Datenanalyse einsteigen können.
Lehre und Demonstration
Typischer Bedarf: Demonstration des Konzepts "Was ist semantische Segmentierung" in Kursen für Stadtplanung oder Computer Vision.
Bei der traditionellen Methode muss das Modell live im Unterricht ausgeführt werden, was oft an der Umgebungskonfiguration scheitert. GPT-image-2 kann direkt über die ChatGPT-Webseite demonstriert werden – null Ausfallrate, hohe Erklärbarkeit und die Studierenden können zudem Fragen in natürlicher Sprache stellen.
💡 Tipp für den schnellen Einstieg: Nutzern, die zum ersten Mal mit der semantischen Segmentierung von Straßenansichten durch GPT-image-2 in Berührung kommen, empfehlen wir, zunächst mit "Einzelbildtests + Standardmodus" zu beginnen, um die Leistungsgrenzen kennenzulernen, bevor eine Ausweitung auf Batch-Szenarien erfolgt. Wir empfehlen, die Plattform APIYI (apiyi.com) zu nutzen, um zunächst 5-10 Bilder kostenlos zu testen, bevor Sie nach einer intuitiven Einschätzung der Ergebnisse über das weitere Vorgehen entscheiden.
Schnelleinstieg in die semantische Segmentierung von Straßenansichten mit GPT-image-2
Wenn Sie es sofort ausprobieren möchten, finden Sie hier den minimalen Pfad – in 3 Schritten erledigt.
Schritt 1: Straßenansicht-Bilder vorbereiten
Für den ersten Test empfehlen wir klare Straßenansicht-Bilder bei Tageslicht mit einer Auflösung von mindestens 1024×768 Pixeln, damit das Modell über genügend Informationen für eine präzise Beurteilung verfügt. Diese können stammen aus:
- Vor-Ort-Aufnahmen (Handykamera reicht aus)
- Exporten von Straßenansicht-Plattformen (Google Street View Screenshots / Baidu Street View / Tencent Street View)
- Öffentlichen Datensätzen (Cityscapes Test-Set, Mapillary Vistas)
Schritt 2: Aufrufmethode wählen
| Aufrufmethode | Zielgruppe | Vorteile |
|---|---|---|
| ChatGPT Plus Webversion | Nicht-Entwickler, Forscher | Kein Code, gute Visualisierung |
| OpenAI API | Entwickler, Batch-Verarbeitung | Programmierbar, integrierbar |
| APIYI API-Proxy-Dienst | Entwickler in China | Direkte Verbindung, konsistente Felder |
Schritt 3: Eingabeaufforderung (Prompt) senden
Verwenden Sie einfach die Prompt-Vorlagen aus den 4 Szenarien dieses Artikels:
Szenario 1: Führe eine semantische Segmentierung für dieses Straßenbild durch und gib die Legende an.
Szenario 2: Gib mir die Daten zum Anteil der einzelnen Legendenkategorien und berechne den Grünflächenanteil.
Szenario 3: Führe eine semantische Segmentierung der Fahrzeuge und Personen auf dem Gelände durch; Blau steht für Fahrzeuge, Grün für Personen.
Szenario 4: Führe basierend auf der obigen Legende eine semantische Segmentierung für das zweite Bild durch.
Beispielcode für den API-Aufruf
Wenn Sie den API-Weg wählen, finden Sie hier ein minimales Aufrufbeispiel:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "Führe eine semantische Segmentierung für dieses Straßenbild durch, gib die Anteile der Kategorien an und berechne den Grünflächenanteil."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # Denkmodus
)
print(response.choices[0].message.content)
🚀 Hinweis zur API-Anbindung: Wenn Sie gpt-image-2 über APIYI (apiyi.com) aufrufen, setzen Sie die
base_urlaufhttps://api.apiyi.com/v1. Alle anderen Felder sind identisch mit der offiziellen OpenAI-API. Bestehender OpenAI-SDK-Code kann durch Ändern derbase_urlsofort verwendet werden.
GPT-image-2 FAQ zur semantischen Segmentierung von Straßenansichten
Frage 1: Ist die Genauigkeit der semantischen Segmentierung von Straßenansichten mit GPT-image-2 wirklich ausreichend?
Das hängt stark von Ihrem Anwendungsfall ab. Für akademische Berichte, Planungsbewertungen und Demonstrationen in der Lehre ist die Genauigkeit des Denkmodus (Fehlertoleranz ±2 %) absolut ausreichend. Für industrielle Präzisionsmessungen (Anforderung an die Fehlertoleranz <1 %) empfehlen wir weiterhin den Einsatz traditioneller Modelle in Kombination mit manuellen Stichprobenkontrollen.
Frage 2: Wie viele Kategorien von Straßenansichten kann GPT-image-2 erkennen?
Theoretisch gibt es keine harte Obergrenze für die Anzahl der Kategorien – Sie definieren diese einfach über Ihre Eingabeaufforderung. In der Praxis zeigt sich jedoch, dass bei mehr als 15 Kategorien pro Bild Probleme mit ähnlichen Farben und unübersichtlichen Legenden auftreten können. Wir empfehlen, sich pro Aufgabe auf 8 bis 12 Kategorien zu beschränken.
Frage 3: Unterstützt die semantische Segmentierung von Straßenansichten mit GPT-image-2 Videos?
Die aktuelle Version unterstützt keine direkten Videoströme. Wenn Sie eine Videoanalyse benötigen, müssen Sie das Video zunächst in Einzelbilder zerlegen (z. B. 1 Bild/Sekunde), diese nacheinander verarbeiten und die Ergebnisse anschließend wieder zu einem Video zusammenfügen. Dieser Arbeitsablauf ist zeit- und kostenintensiv und wird daher nicht empfohlen.
Frage 4: Der Denkmodus dauert 10 Minuten – kann man das beschleunigen?
Die Dauer des Denkmodus resultiert hauptsächlich aus dem Selbstprüfungsprozess des Modells. Hier sind einige Methoden zur Beschleunigung:
- Auflösung reduzieren: Komprimieren Sie hochgeladene Bilder auf maximal 1024×768 Pixel.
- Aufgaben vereinfachen: Teilen Sie Segmentierung und Flächenanteilsberechnung in zwei separate Eingabeaufforderungen auf, bei denen jeweils nur eine Sache abgefragt wird.
- Standardmodus verwenden: Die Genauigkeit sinkt zwar um 1–2 %, aber die Verarbeitungszeit reduziert sich auf ein Fünftel.
Frage 5: Wer ist bei der Segmentierung von Straßenansichten besser – GPT-image-2 oder Nano Banana Pro?
Beide Modelle haben unterschiedliche Schwerpunkte. GPT-image-2 ist stärker bei Denkfähigkeit und numerischer Präzision (mehrstufige Schlussfolgerungen, automatische GVI-Berechnung). Nano Banana Pro punktet bei Geschwindigkeit und Kosten (Reaktionszeit im Sekundenbereich pro Bild). Wenn Sie große Mengen schnell segmentieren müssen, ist Nano Banana Pro die bessere Wahl; benötigen Sie hingegen automatisch erstellte Analyseberichte, ist GPT-image-2 vorzuziehen.
Frage 6: Gibt es Unterschiede bei der Nutzung über APIYI (apiyi.com) im Vergleich zum offiziellen Anbieter?
Die Felder sind identisch – APIYI fungiert als offizieller Proxy-Dienst, wobei die Anfrage- und Antwortfelder zu 100 % mit dem OpenAI-Standard synchronisiert sind. Die Vorteile liegen auf der Hand: Direktverbindung ohne Proxy in China, spezieller technischer Support auf Chinesisch und transparente Abrechnung. Wir empfehlen Entwicklern in China, GPT-image-2 über APIYI (apiyi.com) einzubinden, um Probleme mit der Netzwerkstabilität zu vermeiden.
Frage 7: Kann GPT-image-2 eine standardmäßige PNG-Maske ausgeben?
Die aktuelle Version unterstützt keine direkte Ausgabe von pixelgenauen Maskendateien. Das Modell liefert eine "gerenderte Farbkarte". Wenn Sie eine Maske für das Training nachgelagerter Modelle benötigen, ist eine Nachbearbeitung mittels Farbschwellenwert-Trennung erforderlich.
Frage 8: Können die Ausgaben der GPT-image-2-Segmentierung nachträglich bearbeitet werden?
Ja – Sie können auf Basis der ersten Ausgabe weiterführende Fragen stellen. Zum Beispiel: "Lege eine halbtransparente rote Maske über alle Vegetationsbereiche im Originalbild zur Warnung." Das Modell führt die abgeleitete Verarbeitung basierend auf dem vorherigen Segmentierungsergebnis aus. Dies ist eine Fähigkeit, die traditionelle Modelle nicht bieten können.
GPT-image-2: Wichtige Erkenntnisse zur semantischen Segmentierung von Straßenansichten
- Neues Paradigma: GPT-image-2 soll DeepLabV3+ nicht ersetzen, sondern eröffnet einen neuen Weg durch "natürliche Sprache, null Implementierungsaufwand und ableitbare Analysen".
- Praktische Genauigkeit: Im Denkmodus liegt die Abweichung zu traditionellen SOTA-Modellen bei nur ±2 %, was für die meisten Geschäftsszenarien ausreicht.
- Zeitaufwand als Schwachstelle: Die Antwortzeit liegt im Minutenbereich pro Bild und ist daher absolut ungeeignet für Echtzeit- oder Massenverarbeitungsszenarien.
- Flexibilität bei Kategorien als Trumpf: Während traditionelle Modelle durch die "19 Cityscapes-Kategorien" limitiert sind, durchbricht GPT-image-2 diese Grenze mit einer einfachen Eingabeaufforderung.
- Automatisierung der Grünflächenrate (GVI): Die GVI-Berechnung wird von einem "ganztägigen Prozess für Ingenieure und Planer" auf "5 Minuten für einen Planer" komprimiert.
- Optimale Hybridlösung: Nutzen Sie GPT-image-2 für explorative Analysen und traditionelle Modelle für industrielle Massenverarbeitung – beide ergänzen sich ideal.
- Empfehlung für die Nutzung in China: Verwenden Sie APIYI (apiyi.com) für eine stabile Direktverbindung, die zu 100 % mit den offiziellen Feldern kompatibel ist.
Zusammenfassung
Die semantische Segmentierung von Straßenansichten mit GPT-image-2 ist kein Ersatz für die klassische semantische Segmentierung, sondern eine wertvolle Ergänzung. Sie adressiert Anforderungen wie „kleine Chargen, hohe Anpassbarkeit, Interaktion in natürlicher Sprache und automatisierte Analyseergebnisse“ – Bereiche, die von Modellen wie DeepLabV3+ oder PSPNet bisher völlig vernachlässigt wurden.
Von der automatischen Berechnung des Grünflächenanteils bis hin zur benutzerdefinierten Klassensegmentierung: GPT-image-2 demokratisiert Aufgaben, für die früher „Algorithmik-Ingenieure, GPUs und umfangreiche Trainingsdaten“ erforderlich waren, und macht sie für jeden zugänglich, der ChatGPT bedienen kann. Dies stellt einen Paradigmenwechsel für Stadtplanung, Landschaftsdesign und akademische Forschung dar.
Beachten Sie jedoch die Grenzen: Minutenlange Verarbeitungszeit pro Bild, unvorhersehbare Kosten bei großen Mengen und eine pixelgenaue Präzision, die nicht an den aktuellen Stand der Technik (SOTA) heranreicht. Diese drei Faktoren sorgen dafür, dass es klassische Modelle nicht ersetzen, sondern lediglich neben ihnen existieren wird.
Wenn Sie planen, GPT-image-2 in Ihren Arbeitsablauf zu integrieren, empfehle ich, mit einem „kleinen, aber feinen“ Szenario zu beginnen (z. B. die Analyse des Grünflächenanteils von 50 Straßenbildern). Sobald der End-to-End-Prozess steht, können Sie entscheiden, ob eine Skalierung sinnvoll ist.
✨ Abschließender Rat: Für Entwickler und Forscher im Inland empfehlen wir den Zugriff auf gpt-image-2 über die Plattform APIYI (apiyi.com). Dies ermöglicht stabile Modellaufrufe, bietet eine identische Feldstruktur wie das Original und eine transparente Abrechnung nach Token. Für erste Erkundungen bietet die Plattform zudem kostenlose Kontingente für Ihre PoC-Validierung, die für alle vier in diesem Artikel beschriebenen Testszenarien ausreichen.
Autor: APIYI Team
Letzte Aktualisierung: 02.05.2026