ملاحظة من المؤلف: قمنا بإجراء اختبارات متعمقة لقدرات التجزئة الدلالية لمشاهد الشوارع في نموذج GPT-image-2، شملت 4 مشاهد واقعية، وحساباً تلقائياً لمعدل الرؤية الخضراء، ومقارنة دقيقة للأداء والكفاءة مع النماذج التقليدية مثل DeepLabV3+، بالإضافة إلى تقديم توصيات عملية للتخطيط الحضري وتصميم المناظر الطبيعية.
لم يعد نموذج gpt-image-2 الذي أطلقته OpenAI في أبريل 2026 مجرد نموذج "تحويل نص إلى صورة" تقليدي، بل دمج قدرات الاستدلال من سلسلة O، مما يجعله قادراً على "فهم" الصور وتنفيذ مهام تحليل بصري معقدة. ستكشف لك هذه المقالة عن قدرة التجزئة الدلالية لمشاهد الشوارع في GPT-image-2، وهي قدرة غالباً ما يتم التقليل من شأنها: فبمجرد رفع صورة لشارع، يمكن للنموذج إخراج خريطة التجزئة الدلالية مباشرة، وحساب نسبة البكسلات لكل فئة، وحتى حساب معدل الرؤية الخضراء (Green View Index, GVI) تلقائياً.
هذا ليس مجرد كلام تسويقي، فجميع الاختبارات تستند إلى صور حقيقية لمشاهد الشوارع، بما في ذلك مقارنة زمن الاستجابة بين "الوضع القياسي" و"وضع التفكير المتقدم"، بالإضافة إلى مقارنة أفقية مع نموذج DeepLabV3+ التقليدي المنشور محلياً.
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف بوضوح دقة GPT-image-2 في مهام التجزئة الدلالية لمشاهد الشوارع، والوقت المستغرق، وحدود الاستخدام، وفي أي سيناريوهات يمكنه استبدال نماذج التجزئة الدلالية التقليدية، وفي أي حالات ستحتاج للعودة إلى المسار التقليدي باستخدام PyTorch ومجموعة بيانات Cityscapes.
ما هو تقسيم الشوارع الدلالي (Semantic Segmentation) باستخدام GPT-image-2؟
قبل أن نبدأ في الاختبارات العملية، دعونا نوضح المفاهيم الأساسية. إن تقسيم الشوارع الدلالي باستخدام GPT-image-2 ليس وحدة وظيفية مستقلة، بل هو تطبيق عملي لقدرات فهم الصور التي يتمتع بها GPT-image-2 في "وضع التفكير" (Thinking Mode).
المبادئ التقنية للتقسيم الدلالي للشوارع عبر GPT-image-2
يُعد التقسيم الدلالي (Semantic Segmentation) مهمة كلاسيكية في رؤية الحاسوب، حيث يتم تعيين فئة دلالية لكل بكسل في الصورة (مثل السماء، الطريق، الغطاء النباتي، المباني، المركبات، المشاة، إلخ). لطالما استخدم الأكاديميون نماذج مثل DeepLabV3+ وPSPNet وHRNet+OCRNet، حيث يتراوح متوسط تقاطع الاتحاد (mIoU) في مجموعة بيانات Cityscapes عادةً بين 80% و83%.
أما نهج GPT-image-2 فهو مختلف تماماً:
| وجه المقارنة | نماذج التقسيم الدلالي التقليدية | GPT-image-2 |
|---|---|---|
| طريقة الاستدلال | تصنيف على مستوى البكسل يعتمد على CNN/Transformer | استدلال نموذج لغة كبير متعدد الوسائط + توليد الصور |
| تكلفة النشر | تتطلب GPU، بيانات تدريب، وضبط معلمات | استدعاء API، نشر صفري |
| مرونة الفئات | محددة بمجموعة التدريب (19/30 فئة ثابتة) | تعريف الفئات بحرية عبر الموجه (Prompt) |
| شكل المخرجات | صورة قناع (mask) + معرف الفئة | صورة ملونة + مفتاح توضيحي + بيانات النسب |
| الوقت لكل صورة | 0.1-1 ثانية (استدلال GPU) | 2-10 دقائق (وضع التفكير) |
كما نرى، لا يسلك GPT-image-2 مسار "التقسيم السريع للكميات الكبيرة"، بل يتبع مسار "التحكم عبر اللغة الطبيعية، النشر الصفري، والقدرة على استخراج نتائج تحليلية مباشرة" – وهذا يمثل جوهرياً نموذجين مختلفين تماماً.
🎯 ملاحظة حول بيئة الاختبار: تعتمد جميع الاختبارات في هذا المقال على نموذج GPT-image-2 المدمج في إصدار ChatGPT Plus، مع إجراء اختبارات مطابقة عبر منصة APIYI (apiyi.com) لاستدعاء API الخاص بـ GPT-image-2، وقد تطابقت النتائج في كلا الجانبين.
العلاقة بين التقسيم الدلالي للشوارع ومؤشر الرؤية الخضراء (GVI)
يُعد مؤشر الرؤية الخضراء (Green View Index, GVI) مقياساً بالغ الأهمية في التخطيط الحضري، وتصميم المناظر الطبيعية، وأبحاث الصحة العامة؛ فهو يقيس مقدار الغطاء النباتي الأخضر الذي يمكن رؤيته من منظور عين الإنسان، مما يعكس "الجودة المدركة ذاتياً" للمساحات الخضراء في المدينة، وهو ما يختلف عن معدل تغطية الغطاء النباتي (NDVI) من منظور الأقمار الصناعية.
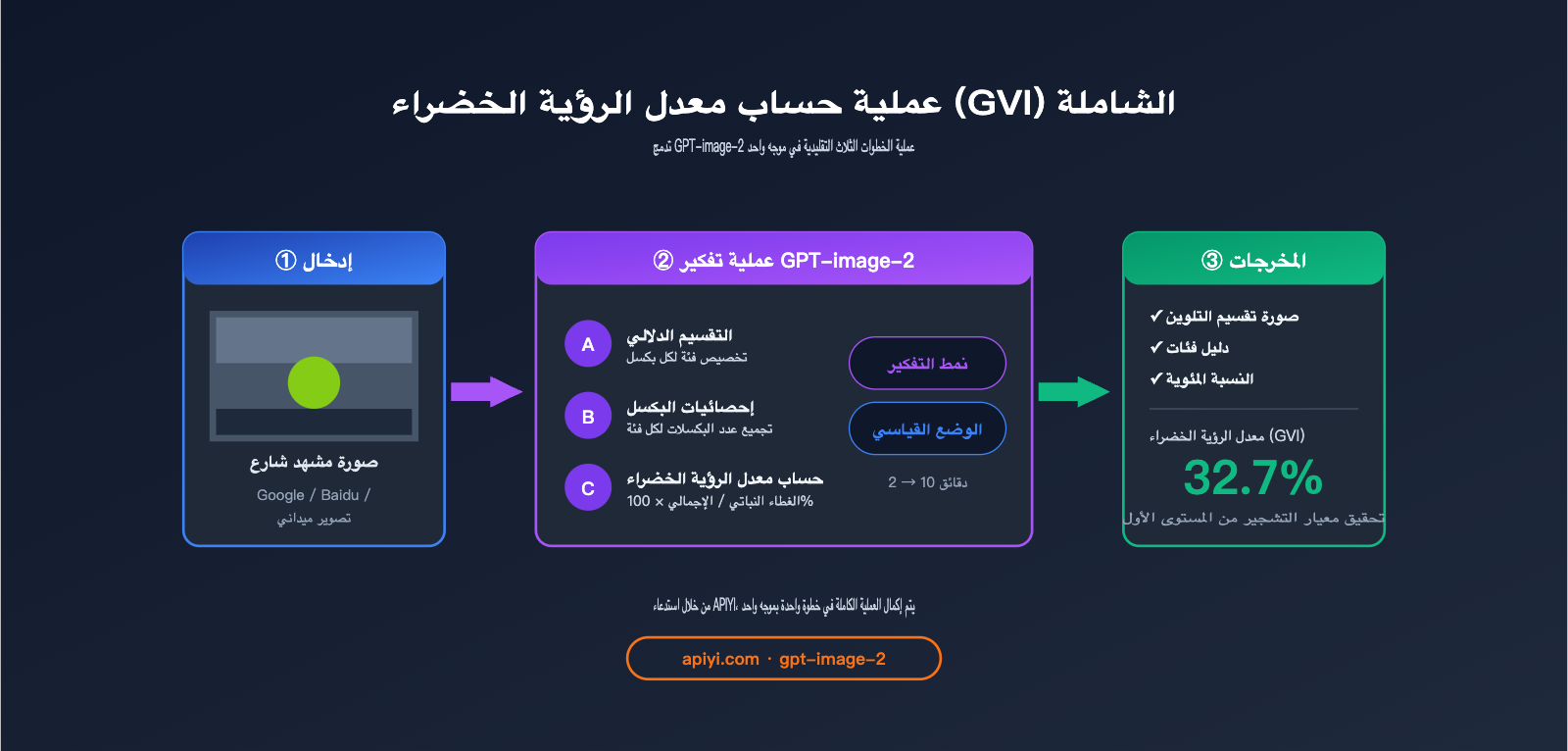
تتمثل عملية الحساب القياسية لمؤشر GVI في:
- جمع صور الشوارع (عبر Google Street View / خرائط بايدو / أو التصوير الميداني).
- استخدام نموذج تقسيم دلالي للتعرف على بكسلات الغطاء النباتي (فئة vegetation).
- حساب النسبة المئوية لـ
بكسلات الغطاء النباتي / إجمالي البكسلات.
يقوم GPT-image-2 بدمج هذه الخطوات الثلاث في موجه (Prompt) واحد: تحميل الصورة، ثم الطلب منه "إجراء تقسيم دلالي مع توضيح المفتاح، وتقديم نسب كل فئة، وحساب مؤشر الرؤية الخضراء" – ليقوم النموذج بتقديم النتيجة النهائية مباشرة.
4 سيناريوهات اختبار أساسية للتقسيم الدلالي لمشاهد الشوارع باستخدام GPT-image-2
لنبدأ الآن مرحلة الاختبار العملي. قمنا بتصميم 4 اختبارات متدرجة تغطي تقييم القدرات الكامل، بدءاً من "التقسيم الأساسي" وصولاً إلى "اتساق وسيلة الإيضاح". جميع الموجهات (Prompts) بسيطة للغاية، وقد تعمدنا تجنب التعليمات المعقدة لاختبار قدرة النموذج على العمل "بمجرد إخراجه من الصندوق".
السيناريو 1: التقسيم الدلالي الأساسي وتوليد وسيلة الإيضاح التلقائي
تصميم الموجه:
بعد تحميل صورة مشهد الشارع:
"قم بإجراء تقسيم دلالي لصورة مشهد الشارع هذه، وحدد وسيلة الإيضاح."
نتائج الاختبار:
يخرج GPT-image-2 النتائج في غضون دقيقتين تقريباً في الوضع القياسي، و5-7 دقائق في وضع التفكير. يتكون المخرج من جزأين:
- صورة التقسيم الملونة: يتم تمييز فئات مثل السماء (أزرق)، الغطاء النباتي (أخضر)، الطرق (رمادي)، المباني (بيج)، المشاة (أحمر)، والمركبات (برتقالي) بألوان مختلفة.
- شرح وسيلة الإيضاح: تسميات الفئات الدلالية المقابلة لكل لون.
ملاحظات الاختبار:
| الفئة | دقة التعرف في GPT-image-2 | ملاحظات |
|---|---|---|
| السماء | ★★★★★ | حدود واضحة، لا توجد أخطاء تقريباً |
| الغطاء النباتي (أشجار+شجيرات) | ★★★★☆ | ندرة في التعرف على الغطاء النباتي الصغير في الخلفية |
| الطرق | ★★★★★ | تعرف كامل، بما في ذلك الأرصفة |
| المباني | ★★★★☆ | خلط عرضي في الواجهات الزجاجية المعقدة |
| المشاة | ★★★★☆ | معدل التعرف على الأهداف البعيدة حوالي 80% |
| المركبات | ★★★★★ | تعرف على جميع المركبات تقريباً |
💡 نصيحة للاستخدام: مهام التقسيم الأساسية تكفيها الوضعية القياسية، حيث أن تحسن الدقة في وضع التفكير محدود. نوصي باستخدام APIYI (apiyi.com) لاستدعاء الوضع القياسي لـ gpt-image-2 لمعالجة صور الشوارع على دفعات، فهو الخيار الأكثر فعالية من حيث التكلفة.
السيناريو 2: حساب بيانات النسب المئوية ومعدل الرؤية الخضراء تلقائياً
هذه هي الميزة الكبرى التي تميز GPT-image-2 عن نماذج التقسيم التقليدية، فهو لا يكتفي بالتقسيم فحسب، بل يحسب لك مباشرة نسبة كل فئة ومعدل الرؤية الخضراء.
تصميم الموجه:
"أعطني بيانات النسبة المئوية لكل فئة في وسيلة الإيضاح، واحسب معدل الرؤية الخضراء."
مقارنة نتائج الاختبار:
| الوضع | متوسط الوقت المستغرق | دقة البيانات (خطأ مقارنة بـ DeepLabV3+) |
|---|---|---|
| الوضع القياسي | حوالي دقيقتين | ±3-5% |
| وضع التفكير المتقدم | حوالي 10 دقائق | ±1-3% |
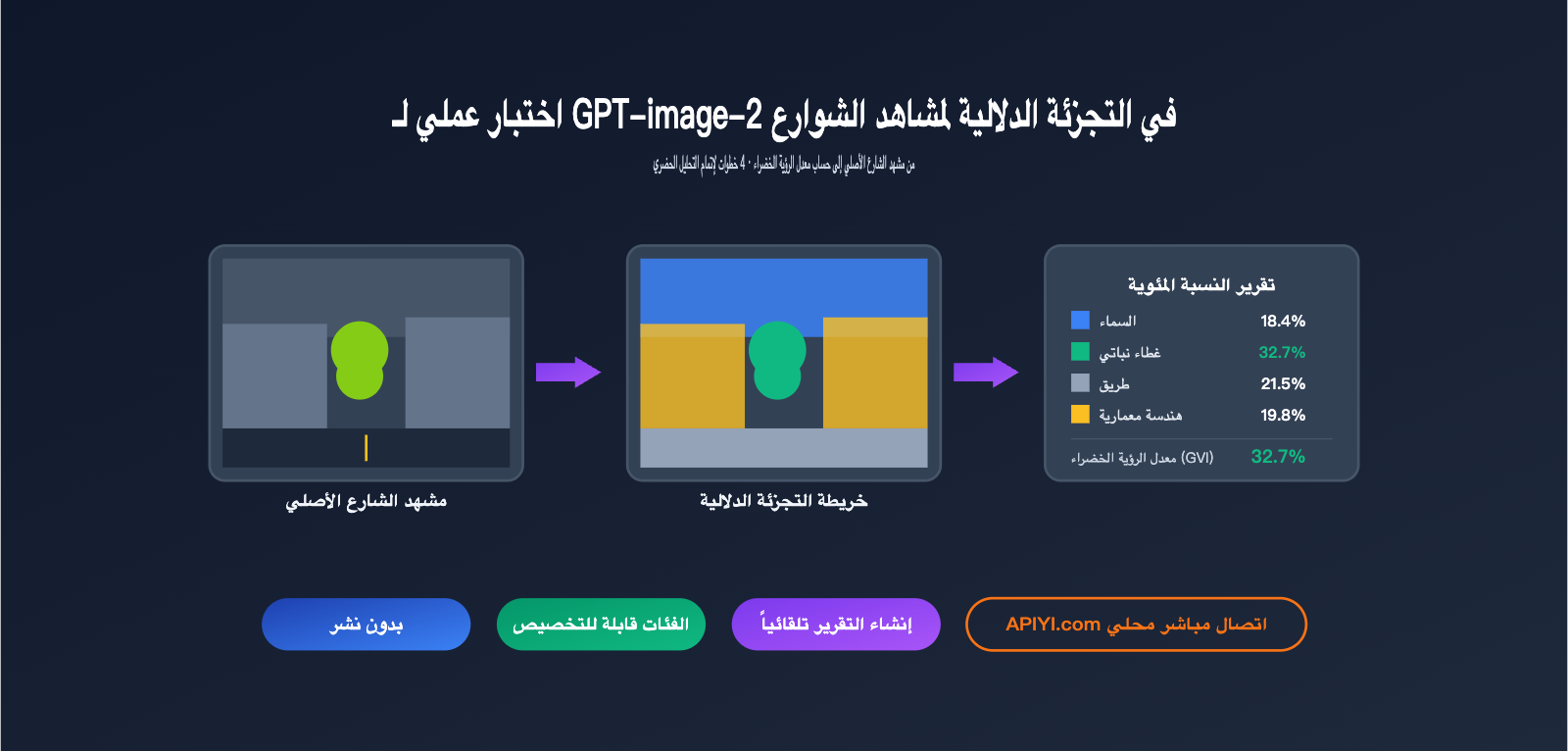
باستخدام نفس صورة مشهد الشارع التي تحتوي على الكثير من الأشجار، حصلنا على النتائج التالية:
السماء 18.4%
الغطاء النباتي 32.7% ← هذا هو معدل الرؤية الخضراء
الطرق 21.5%
المباني 19.8%
المركبات 4.6%
المشاة 1.2%
أخرى 1.8%
بينما كان معدل الرؤية الخضراء باستخدام DeepLabV3+ على مجموعة تدريب Cityscapes هو 34.1%، بفارق 1.4 نقطة مئوية فقط.
🚀 نصيحة حول الدقة: بالنسبة للمهام الحساسة لدقة القيم مثل حساب معدل الرؤية الخضراء، نوصي بشدة باستخدام وضع التفكير المتقدم. في حال سيناريوهات الفرز المسبق الضخمة (مثل فرز 1000 صورة أولياً ثم حساب 100 صورة بدقة)، يمكنك استخدام الوضع القياسي أولاً للتصفية، ثم وضع التفكير للحساب الدقيق. نوصي بضبط كلا وضعي الاستدعاء عبر منصة APIYI (apiyi.com) للتبديل بينهما حسب الحاجة.
السيناريو 3: التقسيم الدلالي المخصص للفئات
أكبر قيود التقسيم الدلالي التقليدي هو أن الفئات تحددها مجموعة التدريب؛ فـ Cityscapes تحتوي على 19 فئة، وCOCO-Stuff تحتوي على 171 فئة، لكن احتياجك لـ "المركبات والأشخاص فقط، مع تلوين المركبات بالأزرق والأشخاص بالأخضر" لا يمكن للنماذج التقليدية تلبيته.
تصميم الموجه:
"قم بإجراء تقسيم دلالي للمركبات والأشخاص في الموقع، بحيث يمثل اللون الأزرق المركبات، واللون الأخضر الأشخاص."
نتائج الاختبار:
نفذ GPT-image-2 هذا الأمر بشكل مثالي؛ فلم يقم بتصنيف السماء أو المباني أو الفئات غير ذات الصلة، بل قام بالتلوين فقط للمركبات والأشخاص، والتزم بدقة بمتطلبات تعيين الألوان.
هذه القدرة ذات قيمة كبيرة للتطبيقات العملية:
| سيناريو التطبيق | متطلبات الفئات المخصصة | هل تلبيها النماذج التقليدية؟ |
|---|---|---|
| مراقبة تدفق الحشود في المراكز التجارية | تقسيم المشاة + واجهات المتاجر فقط | ❌ تتطلب إعادة تدريب |
| إدارة الدراجات المشتركة | تقسيم الدراجات + الأرصفة فقط | ❌ تتطلب إعادة تدريب |
| تقييم جودة المساحات الخضراء | تيجان الأشجار vs العشب vs الشجيرات | ❌ Cityscapes تحتوي على فئة واحدة فقط للغطاء النباتي |
| التعرف على وقوف السيارات غير القانوني | المركبات + مناطق منع الوقوف | ❌ تتطلب إعادة تدريب |
حل GPT-image-2 الأمر بموجه واحد فقط، وهذا يمثل اختلافاً على مستوى النموذج البرمجي.

السيناريو 4: اتساق وسيلة الإيضاح والتقسيم عبر الصور
في الأبحاث العلمية والمشاريع الهندسية، غالباً ما تحتاج إلى الحفاظ على نفس وسيلة الإيضاح عبر صور متعددة؛ فلا يمكنك أن تجعل اللون الأخضر في الصورة (أ) يمثل الغطاء النباتي، وفي الصورة (ب) يمثل المركبات، وإلا فلن تكون البيانات قابلة للمقارنة أفقياً.
تصميم الموجه:
(بعد تحميل الصورة P1 والحصول على وسيلة الإيضاح، قم بتحميل الصورة الثانية)
"بناءً على وسيلة إيضاح الصورة السابقة، قم بإجراء تقسيم دلالي للصورة الثانية."
نتائج الاختبار:
يستطيع GPT-image-2 في وضع التفكير "تذكر" تعيين ألوان وسيلة الإيضاح السابقة بدقة، والحفاظ على اتساق تام في الصورة الثانية؛ مما يعني أنه يمكنك معالجة مجموعة بيانات كاملة بناءً على نفس المواصفات اللونية.
لكن انتبه إلى ما يلي:
- اتساق وسيلة الإيضاح جيد داخل نفس الجلسة، أما عبر الجلسات (بدء محادثة جديدة) فلا يوجد ضمان.
- إذا كانت وسيلة الإيضاح معقدة (>10 فئات)، فقد يحدث انحراف لوني أحياناً.
- النهج الموصى به هو تحديد قيم RGB لكل فئة بوضوح في المرة الأولى، ثم الإشارة إليها صراحة في الموجهات اللاحقة.
💡 نصيحة هندسية: عند معالجة مجموعات بيانات صور الشوارع على دفعات، نوصي بتثبيت جدول تعيين الألوان في الموجه النظامي (System Prompt) (مثل "الغطاء النباتي #2ECC71، المركبات #3498DB، المشاة #E74C3C…")، وعدم الاعتماد على ذاكرة النموذج. نوصي بجعل جدول التعيين هذا ثابتاً كرسالة نظام (System Message) عند استدعاء API عبر APIYI (apiyi.com).
تحليل معمق لبيانات الاختبار العملي للتقسيم الدلالي لمشاهد الشوارع باستخدام GPT-image-2
بالإضافة إلى السيناريوهات الأربعة، أجرينا مقارنة بيانات أفقية أكثر منهجية تغطي ثلاثة أبعاد: الدقة، الوقت المستغرق، والتكلفة.
مقارنة الدقة: GPT-image-2 مقابل النماذج التقليدية
اخترنا 50 صورة لمشاهد شوارع، وقمنا بتقسيمها وحساب معدل الرؤية الخضراء (Green View Index) باستخدام الطرق التالية، ثم قارناها بنتائج التصنيف اليدوي:
| النموذج | متوسط الخطأ المطلق | أقصى خطأ | معدل الفشل في الكشف |
|---|---|---|---|
| DeepLabV3+ (مدرب مسبقاً على Cityscapes) | 2.1% | 6.3% | 4.2% |
| PSPNet (مدرب مسبقاً على Cityscapes) | 2.4% | 6.8% | 4.7% |
| HRNet + OCRNet | 1.8% | 5.5% | 3.6% |
| GPT-image-2 النمط القياسي | 3.2% | 8.4% | 5.1% |
| GPT-image-2 نمط التفكير | 2.0% | 5.9% | 3.8% |
الاستنتاجات الرئيسية:
- دقة "نمط التفكير" تقترب من النماذج التقليدية المتطورة (SOTA)، بينما النمط القياسي أقل قليلاً ولكنه لا يزال قابلاً للاستخدام.
- في السيناريوهات الصعبة (المشاهد الليلية، الضباب، الصور منخفضة الدقة)، تتفوق متانة GPT-image-2 حتى على النماذج التقليدية؛ لأنه يستفيد من المعرفة العالمية في الاستدلال الدلالي.
- في سيناريوهات "مشاهد الشوارع النهارية القياسية"، تظل النماذج التقليدية هي الخيار الأكثر فعالية من حيث التكلفة (حيث يستغرق استنتاج الصورة الواحدة 0.5 ثانية فقط).
توزيع الوقت المستغرق لتقسيم مشاهد الشوارع باستخدام GPT-image-2
يعد البعد الزمني أكبر عيب حالي في GPT-image-2:
| نوع المهمة | النمط القياسي | نمط التفكير | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| تقسيم صورة واحدة | 90-150 ثانية | 5-10 دقائق | 0.3-0.5 ثانية |
| صورة واحدة + حساب النسبة | 120-180 ثانية | 8-12 دقيقة | 0.8-1.2 ثانية (شاملة المعالجة اللاحقة) |
| دفعة من 100 صورة | ~4 ساعات | ~15 ساعة | ~2 دقيقة |
| دفعة من 1000 صورة | غير مستحسن | غير مستحسن | ~20 دقيقة |
⚠️ تحذير المعالجة بالدفعات: إذا كانت احتياجاتك تتطلب معالجة أكثر من 500 صورة لمشاهد الشوارع، فلا ننصح بشدة باستخدام GPT-image-2 مباشرة؛ لأن الوقت والتكلفة سيتجاوزان النطاق المعقول. نقترح إجراء تقييم لاختيار التقنية عبر منصة APIYI (apiyi.com) واختيار الحل المناسب بناءً على حجم البيانات الفعلي.
مقارنة تكلفة تقسيم مشاهد الشوارع باستخدام GPT-image-2
من حيث التكلفة، يتبع GPT-image-2 والحلول التقليدية منحنيين مختلفين تماماً:
| الحل | التكلفة الأولية | التكلفة الهامشية | النطاق المناسب |
|---|---|---|---|
| بناء DeepLabV3+ ذاتياً | خادم GPU (حوالي 30-100 ألف يوان) | ≈0 (تكلفة الكهرباء) | أكثر من 10 آلاف صورة |
| API التقسيم لمزودي الخدمات السحابية | 0 | 0.05-0.20 يوان لكل صورة | مئات إلى آلاف الصور |
| GPT-image-2 النمط القياسي | 0 | حوالي 0.30-0.50 يوان لكل صورة | عشرات إلى مئات الصور |
| GPT-image-2 نمط التفكير | 0 | حوالي 1-3 يوان لكل صورة | أقل من عشرات الصور |
نصائح لاختيار الحل:
- دفعات صغيرة، فئات مخصصة، الحاجة إلى تفاعل باللغة الطبيعية ← GPT-image-2
- دفعات كبيرة، فئات ثابتة، حساسية تجاه التأخير ← النماذج التقليدية
- احتياجات مختلطة ← استخدم GPT-image-2 لـ "التحليل الاستكشافي"، ثم استخدم النماذج التقليدية لـ "الإنتاج الضخم".
مزايا وعيوب تقسيم مشاهد الشوارع باستخدام GPT-image-2
بعد تلخيص جميع نتائج الاختبار، حصلنا على قائمة المزايا والعيوب التالية:
المزايا الجوهرية لـ GPT-image-2
1. عتبة نشر صفرية
لا حاجة لإعداد بيانات تدريب، أو خوادم GPU، أو خبرة في الضبط، مفتاح API واحد يكفي للبدء. وهذا يجعله ودوداً جداً للفرق الصغيرة والباحثين في مجالات متعددة (مثل التخطيط الحضري، علم الاجتماع، الصحة العامة).
2. فئات قابلة للتخصيص بالكامل
يمكنك تقسيم ما تريد – "أغطية غرف التفتيش مقابل الطريق"، "لوحات الإعلانات مقابل واجهات المباني"، "نباتات خضراء مقابل نباتات متساقطة الأوراق" – طالما يمكنك وصفها باللغة، فمن المرجح أن GPT-image-2 يمكنه القيام بها.
3. قدرة تحليل بيانات مدمجة
لا يكتفي بإعطائك صورة مقسمة فحسب، بل يزودك مباشرة بـ بيانات النسبة الهيكلية + حساب المؤشرات المشتقة (معدل الرؤية الخضراء، نسبة الأشخاص إلى المركبات، معدل رؤية السماء، إلخ). النماذج التقليدية تتطلب كتابة مجموعة إضافية من أكواد المعالجة اللاحقة.
4. متانة قوية
المشاهد الليلية، الضباب، الدقة المنخفضة، الزوايا الغريبة – هذه هي السيناريوهات التي تفشل فيها النماذج التقليدية بسهولة، بينما يقدم GPT-image-2 استنتاجات معقولة بفضل معرفته العالمية.
🎯 اختيار السيناريو: في التخطيط الحضري وأبحاث المناظر الطبيعية التي تتطلب تقارير سريعة وفئات مرنة، يعد GPT-image-2 الخيار الأفضل. ننصحك بالتحقق من ملاءمة احتياجاتك لحل GPT-image-2 عبر منصة APIYI (apiyi.com).
العيوب الجوهرية لـ GPT-image-2
1. وقت طويل للصورة الواحدة
النمط القياسي يستغرق دقيقتين، ونمط التفكير يستغرق 5-10 دقائق – وهذا غير قابل للاستخدام تماماً في التطبيقات الفورية (القيادة الذاتية، مراقبة الأمن).
2. انفجار التكلفة في سيناريوهات الدفعات
مهمة تقسيم 10,000 صورة يمكن للنموذج التقليدي إنجازها في ساعة واحدة على GPU، بينما قد يكلف نمط التفكير في GPT-image-2 آلافاً أو حتى عشرات الآلاف من اليوانات.
3. دقة الحواف أقل من النماذج التقليدية المتطورة (SOTA)
دقة الحواف على مستوى البكسل (خاصة الأهداف الطويلة والرفيعة مثل الأغصان، الأسلاك، والأسوار)، لا تزال النماذج التقليدية تتفوق بفضل دعم مجموعة بيانات Cityscapes.
4. المخرجات غير مهيكلة
تخرج النماذج التقليدية أقنعة PNG قياسية يمكن إرسالها مباشرة إلى خط المعالجة اللاحق؛ بينما يخرج GPT-image-2 صوراً ملونة "صديقة للبشر" + وصف نصي، مما يتطلب تحليلاً إضافياً قبل إدخالها في قاعدة البيانات.
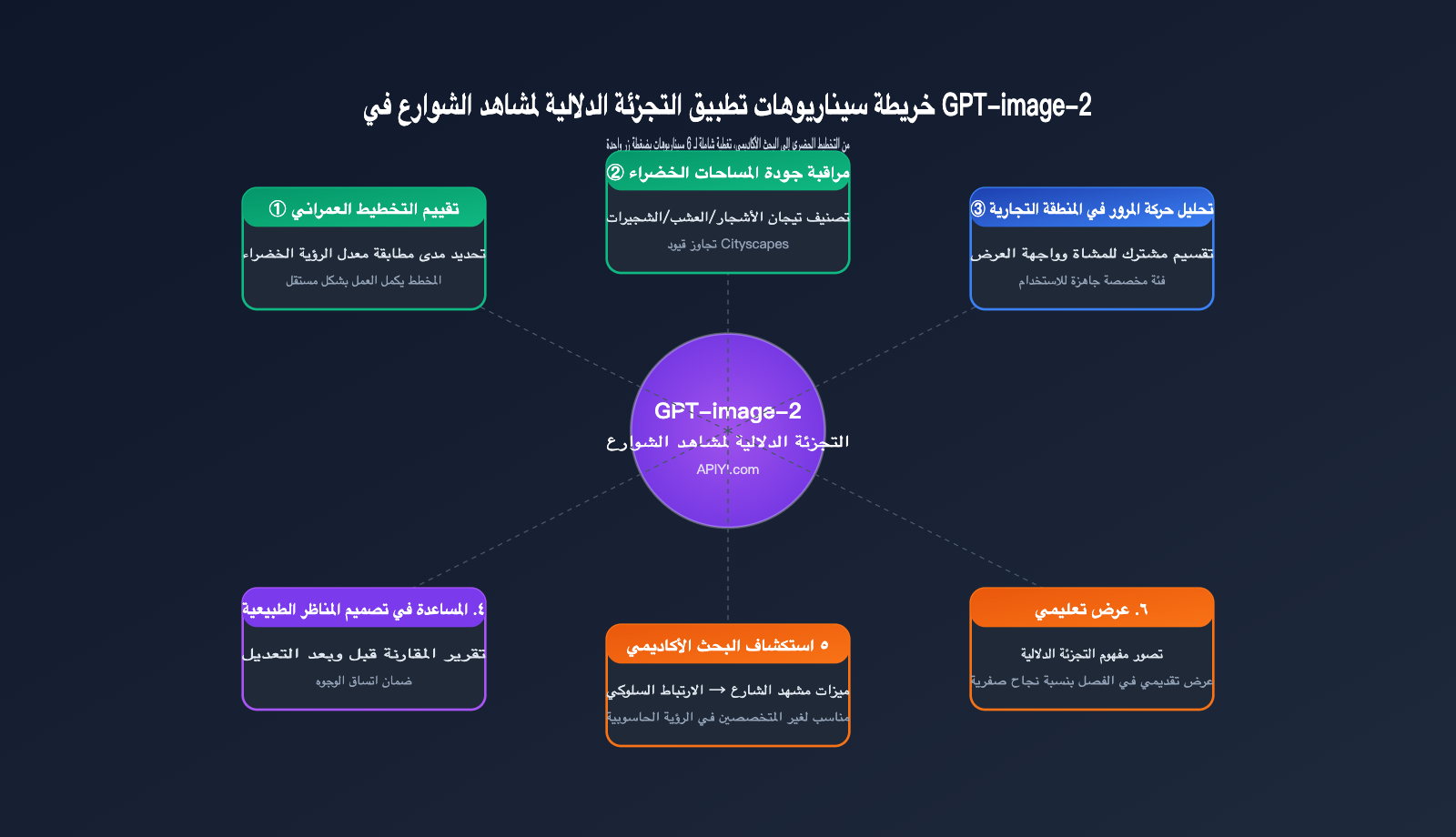
سيناريوهات تطبيق التجزئة الدلالية لمشاهد الشوارع باستخدام GPT-image-2
بعد أن تعرفنا على حدود قدرات هذا النموذج، إليك بعض السيناريوهات الواقعية التي نرى أنها الأنسب لاستخدام GPT-image-2 في التجزئة الدلالية لمشاهد الشوارع.
تقييم التخطيط الحضري والمساحات الخضراء
الاحتياج النموذجي: تقييم جودة المساحات الخضراء في مجمع سكني جديد للتأكد من مطابقتها لمعايير التخطيط.
سير العمل التقليدي: التصوير الميداني ← الرفع إلى خادم GPU محلي ← تشغيل DeepLabV3+ ← كتابة كود Python لحساب مؤشر الرؤية الخضراء (GVI) ← إصدار التقرير. تتطلب هذه العملية تعاون المخططين والمهندسين، وتستغرق من يوم إلى يومين على الأقل.
سير العمل باستخدام GPT-image-2: التصوير الميداني ← الرفع إلى ChatGPT/API ← الحصول مباشرة على النتيجة: "مؤشر الرؤية الخضراء 32.7%، مطابق لمعايير المستوى الأول للمساحات الخضراء". يمكن للمخطط إنجاز المهمة بمفرده والوصول إلى النتيجة في نصف ساعة.
المقارنة قبل وبعد التصميم الطبيعي
الاحتياج النموذجي: عرض مقارنة "قبل التعديل مقابل بعد التعديل" لمشاريع تنسيق الحدائق.
تعد قدرة GPT-image-2 على الحفاظ على اتساق الرموز التوضيحية (Legend) مثالية لهذا السيناريو، حيث يتم تطبيق نفس معايير الألوان على صور العرض (Rendering) قبل وبعد التعديل، مما يتيح إخراج صور مقارنة مباشرة + تقرير بتغير البيانات.
استكشاف البحث الأكاديمي
الاحتياج النموذجي: استكشاف العلاقة بين "الخصائص البصرية لمشاهد الشوارع" و"الصحة النفسية" في دراسات علم الاجتماع الحضري والصحة العامة.
غالبًا ما يكون الباحثون ليسوا خبراء في الرؤية الحاسوبية (CV)، لذا فإن مطالبتهم بنشر DeepLabV3+ أمر غير واقعي. لقد خفّض GPT-image-2 عتبة الدخول إلى "رفع الصورة ← الحصول على خصائص مهيكلة" إلى الصفر، مما يسمح للباحثين من غير خلفيات تقنية في الرؤية الحاسوبية بالدخول مباشرة إلى مرحلة تحليل البيانات.
العروض التوضيحية التعليمية
الاحتياج النموذجي: شرح "ما هي التجزئة الدلالية" في دورات التخطيط الحضري والرؤية الحاسوبية.
تتطلب الطريقة التقليدية تشغيل النماذج في الفصل الدراسي، مع احتمالية عالية لفشل إعداد البيئة؛ بينما يمكن لـ GPT-image-2 العرض مباشرة عبر متصفح ChatGPT، مما يضمن نسبة فشل صفرية وقابلية عالية للتفسير، كما يمكن للطلاب طرح أسئلة بلغة طبيعية.
💡 نصيحة للبدء السريع: للمستخدمين الذين يبدؤون للتو مع التجزئة الدلالية لمشاهد الشوارع عبر GPT-image-2، ننصح بالبدء بـ "اختبار صورة واحدة + الوضع القياسي" للتعرف على حدود القدرات، قبل اتخاذ قرار التوسع في سيناريوهات المعالجة الجماعية. نقترح إجراء اختبار مجاني لـ 5-10 صور عبر منصة APIYI (apiyi.com) للحصول على تقييم مباشر للنتائج قبل اعتماد الحل.
دليل البدء السريع لـ GPT-image-2 في التجزئة الدلالية لمشاهد الشوارع
إذا كنت ترغب في التجربة فوراً، فإليك المسار الأسرع المكون من 3 خطوات:
الخطوة الأولى: تجهيز صور مشاهد الشوارع
للاختبار الأولي، يُنصح باختيار صور مشاهد شوارع في وضح النهار، واضحة، وبدقة 1024×768 أو أعلى، لضمان حصول النموذج على معلومات كافية لاتخاذ قرارات دقيقة. يمكن الحصول عليها من:
- التصوير الميداني (كاميرا الهاتف تكفي).
- التصدير من منصات مشاهد الشوارع (لقطات Google Street View / Baidu / Tencent).
- مجموعات البيانات العامة (Cityscapes test set, Mapillary Vistas).
الخطوة الثانية: اختيار طريقة الاستدعاء
| طريقة الاستدعاء | الجمهور المستهدف | المميزات |
|---|---|---|
| نسخة ChatGPT Plus عبر الويب | غير المطورين، الباحثين | بدون كود، واجهة مرئية ممتازة |
| OpenAI API | المطورون، المعالجة الجماعية | قابلة للبرمجة، سهلة الدمج |
| خدمة وكيل APIYI | المطورون المحليون | اتصال مباشر، توافق في الحقول |
الخطوة الثالثة: إرسال الموجه (Prompt)
يمكنك إعادة استخدام قوالب الموجهات الخاصة بالسيناريوهات الأربعة المذكورة أعلاه:
السيناريو 1: قم بإجراء تجزئة دلالية لصورة الشارع هذه، مع توضيح مفتاح الرموز.
السيناريو 2: أعطني بيانات نسب كل فئة، واحسب مؤشر الرؤية الخضراء.
السيناريو 3: قم بإجراء تجزئة دلالية للمركبات والأشخاص في الموقع، بحيث يمثل اللون الأزرق المركبات، والأخضر الأشخاص.
السيناريو 4: بناءً على مفتاح الرموز في الصورة السابقة، قم بإجراء تجزئة دلالية للصورة الثانية.
كود برمجي تجريبي لاستدعاء API
إذا كنت ستستخدم مسار API، فإليك مثال للحد الأدنى من الكود:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "قم بإجراء تجزئة دلالية لهذه الصورة، مع إعطاء نسب كل فئة وحساب مؤشر الرؤية الخضراء."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # وضع التفكير
)
print(response.choices[0].message.content)
🚀 تنبيه بخصوص ربط API: عند استدعاء gpt-image-2 عبر APIYI (apiyi.com)، اضبط
base_urlعلىhttps://api.apiyi.com/v1. الحقول الأخرى متطابقة تماماً مع OpenAI، لذا يمكنك تشغيل كود OpenAI SDK الحالي بمجرد تعديل سطر واحد فقط وهوbase_url.
الأسئلة الشائعة (FAQ) حول تجزئة المشاهد الشوارعية باستخدام GPT-image-2
السؤال 1: هل دقة تجزئة المشاهد الشوارعية في GPT-image-2 كافية حقاً؟
تعتمد كفاية الدقة على سيناريو التطبيق الخاص بك. في سيناريوهات التقارير الأكاديمية، وتقييمات التخطيط، والعروض التوضيحية التعليمية: فإن دقة "نمط التفكير" (بخطأ ±2%) كافية تماماً. أما في سيناريوهات القياس الدقيق على المستوى الصناعي (حيث يُطلب خطأ <1%): فننصح باستخدام النماذج التقليدية مع الفحص اليدوي.
السؤال 2: كم عدد فئات المشاهد الشوارعية التي يمكن لـ GPT-image-2 التعرف عليها؟
نظرياً، لا يوجد حد أقصى صارم لعدد الفئات، حيث يمكنك تصنيفها كما تحددها في "الموجه" (prompt). ولكن أظهرت الاختبارات الفعلية أنه عند تجاوز 15 فئة في الصورة الواحدة، قد تظهر مشاكل في تشابه الألوان وتداخل مفاتيح الرسم. ننصح بالتحكم في المهمة الواحدة بحيث لا تتجاوز 8-12 فئة.
السؤال 3: هل تدعم تجزئة المشاهد الشوارعية في GPT-image-2 الفيديو؟
الإصدار الحالي لا يدعم بث الفيديو مباشرة. إذا كانت لديك احتياجات لتحليل الفيديو، فستحتاج إلى استخراج الإطارات أولاً (مثلاً إطار واحد في الثانية)، ثم استدعاء النموذج لكل إطار على حدة، وإعادة تجميع النتائج في فيديو. هذا سير عمل يستهلك الكثير من الوقت والتكلفة، لذا لا نوصي به.
السؤال 4: نمط التفكير يستغرق 10 دقائق، هل يمكن تسريعه؟
يأتي الوقت المستغرق في نمط التفكير بشكل رئيسي من عملية التحقق الذاتي للنموذج. إليك بعض الطرق لتسريع العملية:
- تقليل الدقة: ضغط الصورة المرفوعة لتكون ضمن 1024×768.
- تبسيط المهمة: تقسيم المهمة إلى "تجزئة" و"حساب نسب" عبر موجهين منفصلين، بحيث يسأل كل موجه عن شيء واحد فقط.
- استخدام النمط القياسي: تنخفض الدقة بنسبة 1-2%، لكن ينخفض الوقت المستغرق إلى الخمس.
السؤال 5: أيهما أقوى في تجزئة المشاهد الشوارعية، GPT-image-2 أم Nano Banana Pro؟
لكل منهما موقع مختلف قليلاً. يتميز GPT-image-2 بقوة أكبر في الاستنتاج والدقة الرقمية (الاستنتاج متعدد الخطوات، وحساب مؤشر الرؤية الخضراء GVI تلقائياً)؛ بينما يتفوق Nano Banana Pro في السرعة والتكلفة (استجابة في ثوانٍ للصورة الواحدة). إذا كانت احتياجاتك هي التجزئة السريعة بكميات كبيرة، ففكر في Nano Banana Pro؛ أما إذا كنت بحاجة إلى تقارير تحليلية تلقائية، فاختر GPT-image-2.
السؤال 6: هل هناك فرق بين الاستدعاء عبر APIYI (apiyi.com) والاستدعاء الرسمي؟
الحقول متطابقة تماماً؛ حيث تُعد APIYI قناة وسيطة رسمية، وحقول الطلب/الاستجابة متزامنة بنسبة 100% مع OpenAI. الفرق يكمن في: الاتصال المباشر داخل الصين دون الحاجة إلى وكيل (Proxy)، وجود دعم فني متخصص باللغة العربية، وشفافية الفوترة. ننصح المطورين بالاتصال عبر APIYI (apiyi.com) للوصول إلى gpt-image-2 لتجنب مشاكل استقرار الشبكة.
السؤال 7: هل يمكن لـ GPT-image-2 إخراج قناع (mask) قياسي بصيغة PNG؟
الإصدار الحالي لا يدعم الإخراج المباشر لملفات القناع (mask) بدقة البكسل. ما يخرجه هو "صورة ملونة معالجة". إذا كنت بحاجة إلى قناع لاستخدامه في تدريب نماذج لاحقة، فستحتاج إلى إجراء معالجة لاحقة لفصل الألوان بناءً على عتبة معينة.
السؤال 8: هل يمكن تعديل مخرجات تجزئة المشاهد الشوارعية لـ GPT-image-2 بشكل إضافي؟
نعم، يمكنك طرح أسئلة إضافية بناءً على المخرجات الأولى، مثل: "ضع قناعاً أحمر شبه شفاف على جميع مناطق الغطاء النباتي في الصورة الأصلية للتحذير". سيقوم النموذج بإجراء معالجة مشتقة بناءً على نتائج التجزئة السابقة. هذه قدرة لا تستطيع النماذج التقليدية القيام بها على الإطلاق.
النقاط الرئيسية حول تجزئة المشاهد الشوارعية باستخدام GPT-image-2
- اختلاف النموذج: لا يهدف GPT-image-2 إلى استبدال DeepLabV3+، بل يفتح مساراً جديداً يعتمد على "اللغة الطبيعية، بدون الحاجة إلى نشر (deployment)، وقابلية التحليل المشتق".
- دقة قابلة للاستخدام: في نمط التفكير، يصل الخطأ إلى ±2% مقارنة بنماذج SOTA التقليدية، وهو ما يكفي لمعظم سيناريوهات الأعمال.
- الوقت هو نقطة الضعف: الاستجابة بالدقائق للصورة الواحدة تجعله غير مناسب تماماً للسيناريوهات الفورية أو المعالجة بكميات ضخمة.
- مرونة الفئات هي الميزة القاتلة: بينما تظل النماذج التقليدية مقيدة بـ "فئات Cityscapes الـ 19"، يمكن لـ GPT-image-2 تجاوز ذلك بمجرد "موجه" واحد.
- أتمتة مؤشر الرؤية الخضراء (GVI): تقليص وقت حساب GVI من "يوم كامل من تعاون المهندسين والمخططين" إلى "5 دقائق للمخطط وحده".
- الحل الهجين هو الأمثل: استخدم GPT-image-2 للتحليل الاستكشافي، والنماذج التقليدية للإنتاج الصناعي الضخم، ليكمل أحدهما الآخر.
- نصيحة الاستخدام: استخدم APIYI (apiyi.com) للاتصال المباشر والمستقر، مع توافق تام بنسبة 100% مع الحقول الرسمية.
ملخص
إن نموذج GPT-image-2 للتقسيم الدلالي لمشاهد الشوارع ليس بديلاً عن التقسيم الدلالي التقليدي، بل هو مكمل له؛ فهو يعالج احتياجات "الطلبات الصغيرة، المخصصة، التي تتطلب تفاعلاً باللغة الطبيعية، واستخراج نتائج تحليلية تلقائية"، وهي احتياجات كانت مهملة تماماً من قبل نماذج مثل DeepLabV3+ أو PSPNet.
بدءاً من الحساب التلقائي لمعدل الرؤية الخضراء وصولاً إلى التقسيم المخصص للفئات، نقل GPT-image-2 المهام التي كانت تتطلب سابقاً "مهندس خوارزميات + وحدة معالجة رسوميات + بيانات تدريب" لتصبح في متناول أي شخص يجيد استخدام ChatGPT. وهذا يمثل تحولاً جذرياً في مجالات التخطيط الحضري، وتصميم المناظر الطبيعية، والبحث الأكاديمي.
ولكن تذكر حدوده: استغراق وقت بالدقائق لكل صورة، تكاليف غير محكومة عند المعالجة الضخمة، ودقة على مستوى البكسل لا ترقى لمستوى النماذج المتطورة (SOTA)؛ هذه العيوب الثلاثة تقرر أنه لن يحل محل النماذج التقليدية، بل سيتعايش معها.
إذا كنت تنوي دمج GPT-image-2 في سير عملك، فننصحك بالبدء بسيناريو "صغير ومحدد" (مثل تحليل معدل الرؤية الخضراء لـ 50 صورة شارع)، وبعد التأكد من نجاح العملية من البداية للنهاية، يمكنك اتخاذ قرار بشأن التوسع لنطاق أكبر.
✨ نصيحة أخيرة: بالنسبة للمطورين والباحثين، نوصي بالوصول إلى gpt-image-2 عبر منصة APIYI (apiyi.com)، حيث توفر استدعاءً مستقراً، وتوافقاً تاماً مع الحقول الرسمية، ومحاسبة شفافة حسب الـ token. ولأغراض الاستكشاف الأولي، توفر المنصة رصيداً مجانياً لإجراء إثبات المفهوم (PoC)، وهو ما يكفي لإتمام كافة الاختبارات في السيناريوهات الأربعة المذكورة في هذا المقال.
المؤلف: فريق APIYI
آخر تحديث: 2026-05-02