Примечание автора: глубокое тестирование возможностей семантической сегментации уличных сцен с помощью GPT-image-2: 4 реальных сценария, автоматический расчет индекса озеленения, сравнение точности и эффективности с классическими моделями вроде DeepLabV3+, а также рекомендации по применению в городском планировании и ландшафтном дизайне.
Выпущенная OpenAI в апреле 2026 года модель gpt-image-2 — это уже не просто инструмент «текст-в-изображение». Она интегрировала возможности рассуждения серии O, что позволяет ей «понимать» изображения и выполнять сложные задачи визуального анализа. В этой статье мы подробно разберем семантическую сегментацию уличных сцен в GPT-image-2 — функцию, которую многие недооценивают. Загрузите фотографию улицы, и модель выдаст карту семантической сегментации, процентное соотношение пикселей для каждого класса и даже автоматически рассчитает индекс озеленения (Green View Index, GVI).
Это не просто маркетинговые лозунги. Все тесты основаны на реальных фотографиях улиц, включая сравнение времени обработки в «стандартном режиме» и «режиме глубокого мышления», а также сопоставление с традиционной моделью DeepLabV3+, развернутой локально.
Ключевая ценность: прочитав эту статью, вы будете четко понимать точность, время отклика и границы применимости GPT-image-2 в задачах семантической сегментации, а также поймете, в каких случаях она может заменить традиционные модели, а когда все же придется вернуться к проверенному пути: PyTorch + набор данных Cityscapes.
Что такое семантическая сегментация уличных сцен в GPT-image-2
Прежде чем переходить к тестам, давайте разберемся с понятиями. Семантическая сегментация уличных сцен в GPT-image-2 — это не отдельный функциональный модуль, а практическое применение возможностей модели по пониманию изображений в «режиме размышления» (thinking mode).
Технические принципы семантической сегментации в GPT-image-2
Традиционная семантическая сегментация (Semantic Segmentation) — это классическая задача компьютерного зрения, где каждому пикселю изображения присваивается семантическая категория (например, небо, дорога, растительность, здания, транспорт, пешеходы и т.д.). В академической среде долгое время использовались такие модели, как DeepLabV3+, PSPNet, HRNet+OCRNet, которые на наборе данных Cityscapes обычно показывают mIoU в диапазоне 80%-83%.
Подход GPT-image-2 кардинально отличается:
| Измерение | Традиционные модели сегментации | GPT-image-2 |
|---|---|---|
| Метод вывода | Попиксельная классификация (CNN/Transformer) | Мультимодальный LLM-вывод + генерация изображений |
| Стоимость развертывания | Требует GPU, обучающих данных, настройки | API-вызов, нулевое развертывание |
| Гибкость категорий | Зависит от обучающего набора (фиксированные 19/30 классов) | Свободное определение категорий через промпт |
| Формат вывода | Маска + ID категории | Цветная карта + легенда + данные о доле |
| Время на кадр | 0.1–1 сек (вывод на GPU) | 2–10 минут (режим размышления) |
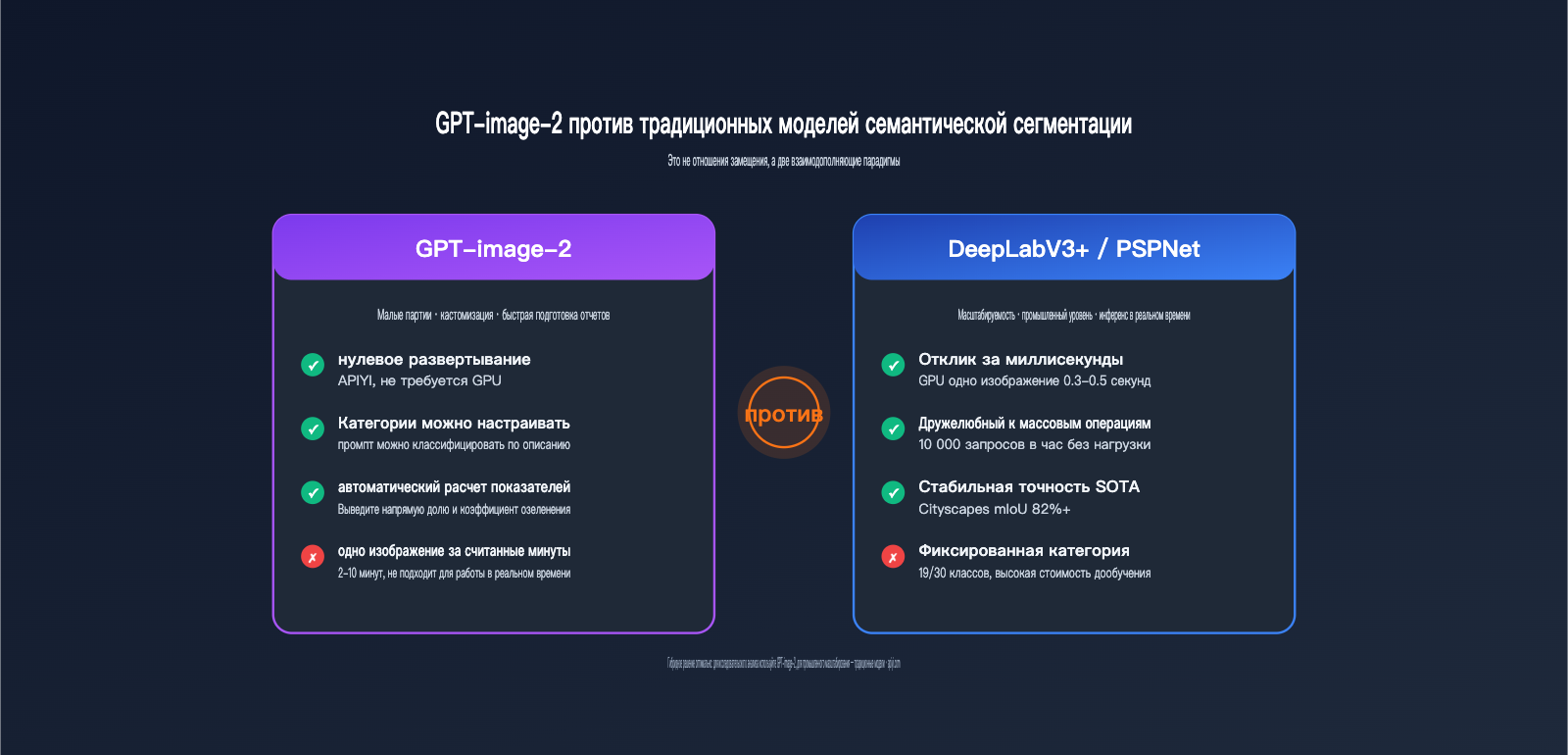
Как видите, GPT-image-2 идет не по пути «быстрой пакетной сегментации», а по пути «управляемости на естественном языке, отсутствия развертывания и получения готовых аналитических выводов». По сути, это две разные парадигмы.
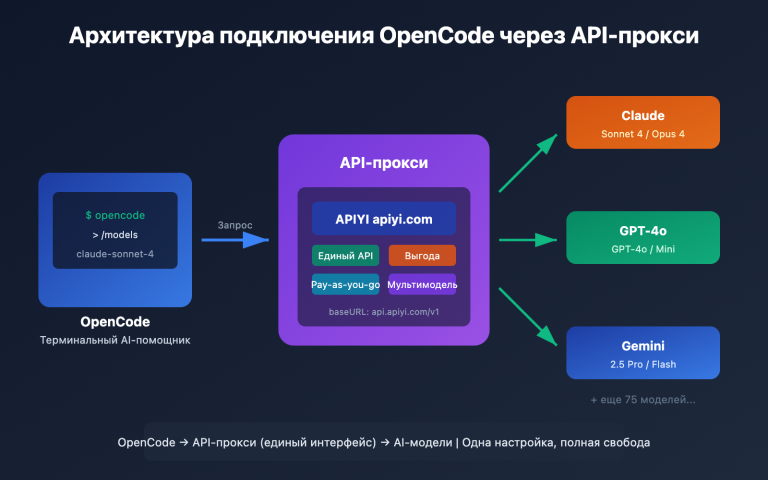
🎯 Примечание о тестовой среде: Все тесты в этой статье основаны на модели GPT-image-2 (режим размышления), встроенной в ChatGPT Plus. Также была проведена повторная проверка через API-ключ gpt-image-2 на платформе APIYI (apiyi.com), результаты в обоих случаях совпали.
Связь семантической сегментации GPT-image-2 и индекса зеленого обзора (GVI)
Индекс зеленого обзора (Green View Index, GVI) — это важнейший показатель в городском планировании, ландшафтном дизайне и исследованиях общественного здравоохранения. Он измеряет, сколько растительности видит человеческий глаз, отражая «субъективно воспринимаемое качество» озеленения города, в отличие от NDVI-индекса растительного покрова, который рассчитывается по спутниковым снимкам.
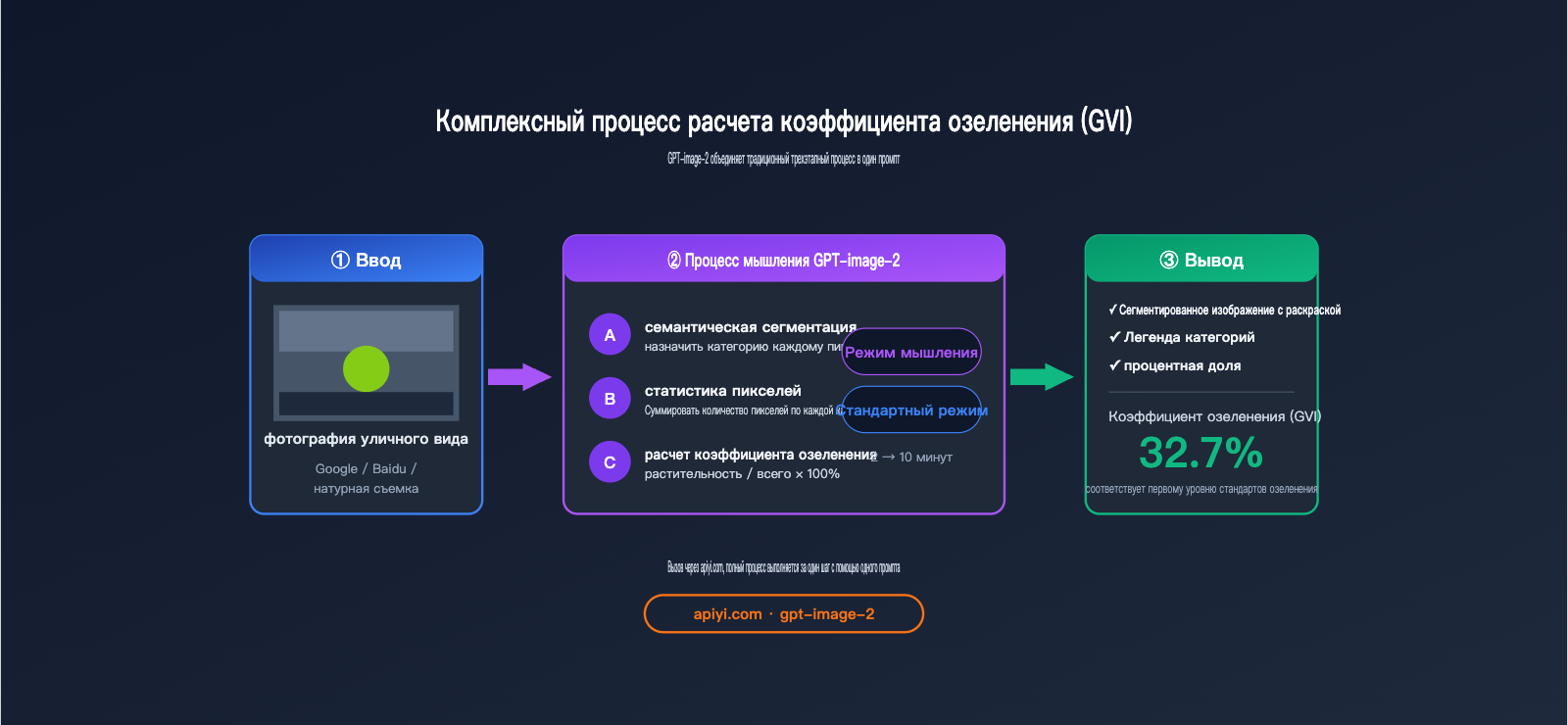
Стандартный процесс расчета GVI выглядит так:
- Сбор фотографий уличных сцен (Google Street View / Baidu Street View / съемка на месте).
- Использование модели семантической сегментации для распознавания пикселей растительности (класс vegetation).
- Расчет процента:
пиксели растительности / общее количество пикселей.
GPT-image-2 объединяет эти три этапа в один промпт: вы загружаете изображение и просите модель «выполнить семантическую сегментацию, добавить легенду, указать процентное соотношение категорий и рассчитать индекс зеленого обзора» — модель выдает итоговый результат за один проход.
4 ключевых сценария тестирования семантической сегментации уличных сцен с GPT-image-2
Переходим к практическим испытаниям. Мы разработали 4 последовательных теста, которые охватывают полный спектр возможностей: от базовой сегментации до обеспечения согласованности легенды. Все промпты максимально лаконичны — мы намеренно избегали сложных инструкций, чтобы проверить способность модели работать «из коробки».
Сценарий 1: Базовая семантическая сегментация и автоматическая генерация легенды
Дизайн промпта:
После загрузки фотографии уличной сцены:
"Выполни семантическую сегментацию этого изображения и добавь легенду."
Результаты тестирования:
GPT-image-2 выдает результат примерно за 2 минуты в стандартном режиме и за 5–7 минут в режиме рассуждения. Вывод состоит из двух частей:
- Цветная карта сегментации: категории, такие как небо (синий), растительность (зеленый), дорога (серый), здания (бежевый), пешеходы (красный), транспорт (оранжевый) и другие, выделены разными цветами.
- Легенда: описание семантической категории для каждого цвета.
Наблюдения:
| Категория | Точность распознавания GPT-image-2 | Примечание |
|---|---|---|
| Небо | ★★★★★ | Четкие границы, практически без ошибок |
| Растительность (деревья+кусты) | ★★★★☆ | Редкие пропуски мелкой растительности на дальнем плане |
| Дорога | ★★★★★ | Полное распознавание, включая тротуары |
| Здания | ★★★★☆ | Иногда путается со сложными стеклянными фасадами |
| Пешеходы | ★★★★☆ | Распознавание мелких объектов вдалеке около 80% |
| Транспорт | ★★★★★ | Распознает практически всё |
💡 Совет по использованию: для базовых задач сегментации достаточно стандартного режима, так как прирост точности в режиме рассуждения невелик. Мы рекомендуем использовать APIYI (apiyi.com) для пакетной обработки уличных сцен в стандартном режиме — это наиболее экономически выгодный вариант.
Сценарий 2: Расчет долей и автоматический подсчет индекса озеленения (Green View Index)
Это главное преимущество GPT-image-2 перед традиционными моделями сегментации — она не просто сегментирует, но и сразу рассчитывает долю каждого класса и индекс озеленения.
Дизайн промпта:
"Предоставь данные о доле каждого элемента в легенде и рассчитай индекс озеленения."
Сравнение результатов:
| Режим | Среднее время | Точность данных (погрешность относительно DeepLabV3+) |
|---|---|---|
| Стандартный | ~2 минуты | ±3-5% |
| Продвинутый (рассуждение) | ~10 минут | ±1-3% |
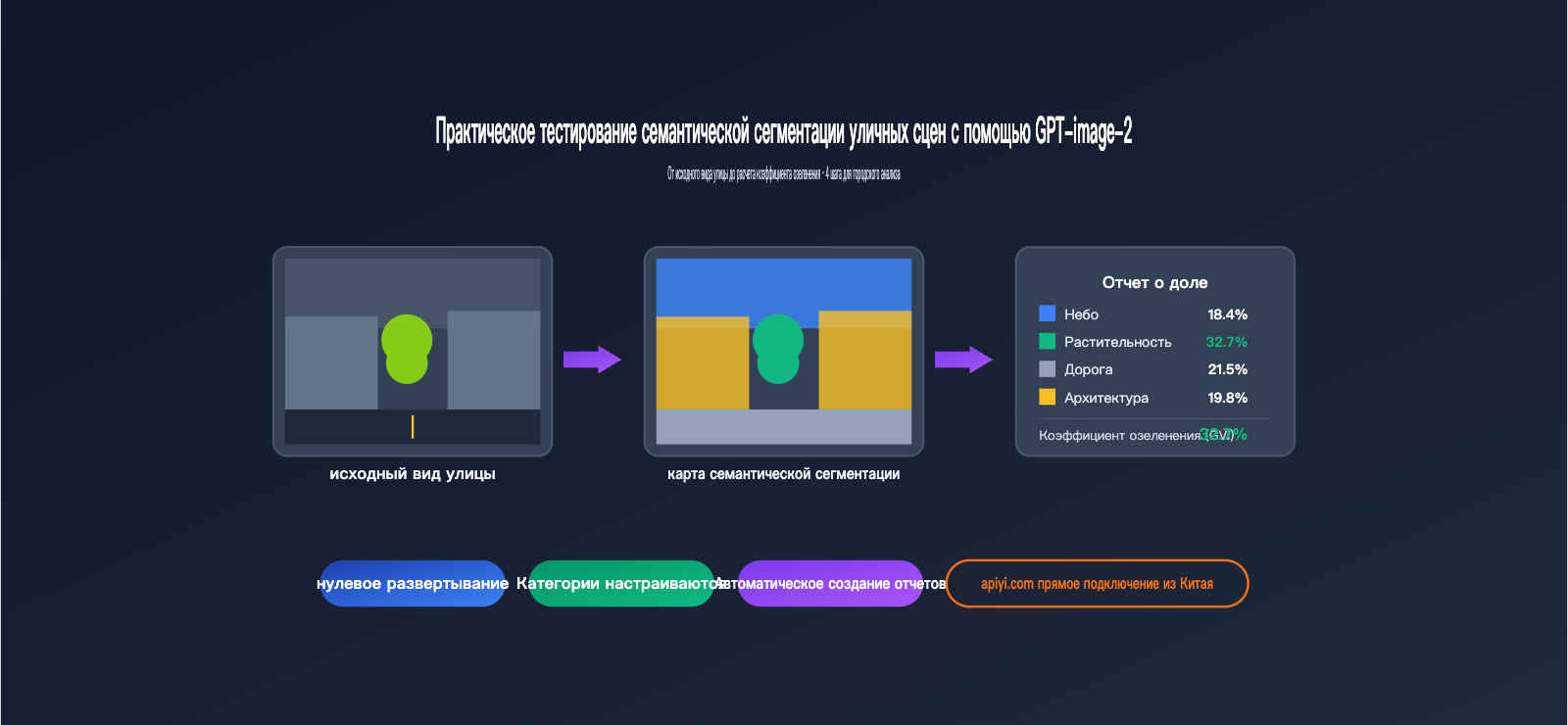
При тестировании на одном и том же снимке с обилием деревьев мы получили следующие данные:
Небо 18.4%
Растительность 32.7% ← Это и есть индекс озеленения
Дорога 21.5%
Здания 19.8%
Транспорт 4.6%
Пешеходы 1.2%
Другое 1.8%
Для сравнения: DeepLabV3+, обученная на наборе данных Cityscapes, показала индекс озеленения 34.1%, разница составила всего 1.4 процентных пункта.
🚀 Совет по точности: для задач, чувствительных к числовым значениям (таких как расчет индекса озеленения), настоятельно рекомендуется использовать режим рассуждения. Если речь идет о массовой предварительной фильтрации (например, отсеять 1000 снимков, а затем детально обработать 100), сначала используйте стандартный режим, а затем — режим рассуждения. Рекомендуем настроить оба типа вызовов через платформу APIYI (apiyi.com) и переключаться между ними по мере необходимости.
Сценарий 3: Локальная семантическая сегментация по заданным категориям
Главное ограничение традиционных моделей — жесткая привязка категорий к обучающей выборке (Cityscapes — 19 классов, COCO-Stuff — 171 класс). Если вам нужно «только машины и люди, причем машины синим, а люди зеленым», традиционные модели с этим не справятся.
Дизайн промпта:
"Выполни семантическую сегментацию транспорта и людей на площадке. Синий цвет — для транспорта, зеленый — для людей."
Результаты тестирования:
GPT-image-2 идеально выполнила инструкцию: она не стала размечать небо, здания и другие нерелевантные объекты, сосредоточившись только на транспорте и людях, строго соблюдая заданную цветовую схему.
Ценность такого подхода для реальных задач огромна:
| Сценарий применения | Требование к категориям | Справятся ли традиционные модели? |
|---|---|---|
| Мониторинг потока в ТЦ | Только пешеходы + витрины | ❌ Требуется переобучение |
| Управление велопрокатом | Только велосипеды + тротуары | ❌ Требуется переобучение |
| Оценка качества озеленения | Кроны деревьев vs газоны vs кусты | ❌ В Cityscapes только 1 класс растительности |
| Выявление нарушений парковки | Транспорт + зоны запрета | ❌ Требуется переобучение |
GPT-image-2 решает это одним промптом — это смена парадигмы.
Сценарий 4: Согласованность легенды и кросс-изображенческая сегментация
В научных и инженерных задачах часто требуется, чтобы несколько изображений использовали одну и ту же легенду — нельзя допустить, чтобы на снимке А зеленый цвет означал растительность, а на снимке Б — транспорт, иначе данные нельзя будет сопоставить.
Дизайн промпта:
(После загрузки первого изображения P1 и получения легенды, загрузите второе изображение)
"Используя легенду с предыдущего изображения, выполни семантическую сегментацию второго снимка."
Результаты тестирования:
GPT-image-2 в режиме рассуждения точно «запоминает» соответствие цветов из предыдущего запроса и применяет его ко второму изображению. Это означает, что вы можете обрабатывать весь набор данных, придерживаясь единого стандарта визуализации.
Однако стоит учесть:
- Согласованность легенды лучше всего работает в рамках одной сессии, в новых диалогах она не гарантируется.
- При сложной легенде (>10 классов) иногда возможен «дрейф» цветов.
- Рекомендуемый подход: заранее четко прописать RGB-значения для всех категорий, а в последующих промптах явно ссылаться на них.
💡 Инженерный совет: при пакетной обработке наборов данных уличных сцен рекомендуется зафиксировать карту соответствия цветов в системном промпте (например, «Растительность #2ECC71, Транспорт #3498DB, Пешеходы #E74C3C…»), не полагаясь на память модели. Мы рекомендуем при вызове API через APIYI (apiyi.com) сохранять эту таблицу соответствий в качестве
system message.
Глубокий анализ данных семантической сегментации уличных сцен с помощью GPT-image-2
Помимо четырех основных сценариев, мы провели более систематическое сравнительное тестирование, охватывающее три ключевых измерения: точность, время выполнения и стоимость.
Сравнение точности: GPT-image-2 против традиционных моделей
Мы отобрали 50 фотографий уличных сцен, выполнили их сегментацию для расчета коэффициента озеленения (green view index) и сравнили результаты с ручной разметкой:
| Модель | Средняя абсолютная ошибка | Макс. ошибка | Процент пропусков |
|---|---|---|---|
| DeepLabV3+ (предобученная на Cityscapes) | 2.1% | 6.3% | 4.2% |
| PSPNet (предобученная на Cityscapes) | 2.4% | 6.8% | 4.7% |
| HRNet + OCRNet | 1.8% | 5.5% | 3.6% |
| GPT-image-2 (стандартный режим) | 3.2% | 8.4% | 5.1% |
| GPT-image-2 (режим размышления) | 2.0% | 5.9% | 3.8% |
Ключевые выводы:
- Режим размышления по точности приближается к традиционным SOTA-моделям, стандартный режим чуть слабее, но вполне пригоден для работы.
- В сложных условиях (ночная съемка, туман, низкое разрешение) надежность GPT-image-2 даже выше, чем у традиционных моделей, так как она использует «мировые знания» для семантического вывода.
- Для «стандартных дневных уличных сцен» традиционные модели остаются оптимальным выбором по соотношению цена/качество (ведь вывод одной картинки занимает всего 0.5 секунды).
Распределение времени выполнения сегментации в GPT-image-2
Временные затраты — на данный момент самое слабое место GPT-image-2:
| Тип задачи | Стандартный режим | Режим размышления | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| Сегментация одного фото | 90-150 сек | 5-10 мин | 0.3-0.5 сек |
| Фото + расчет доли | 120-180 сек | 8-12 мин | 0.8-1.2 сек (с пост-обработкой) |
| Пакет из 100 фото | ~4 часа | ~15 часов | ~2 мин |
| Пакет из 1000 фото | Не рекомендуется | Не рекомендуется | ~20 мин |
⚠️ Предупреждение по пакетной обработке: Если вам нужно обработать более 500 снимков уличных сцен, категорически не рекомендуется использовать GPT-image-2 напрямую — время и стоимость выйдут за рамки разумного. Мы советуем сначала провести оценку выбора технологии на платформе APIYI (apiyi.com) и подобрать подходящее решение исходя из реального объема данных.
Сравнение стоимости сегментации уличных сцен
В плане затрат GPT-image-2 и традиционные решения работают по совершенно разным кривым:
| Решение | Единовременные затраты | Предельные затраты | Масштаб применения |
|---|---|---|---|
| Собственный DeepLabV3+ | GPU-сервер (ок. ¥30K-100K) | ≈0 (электричество) | От 10 000 фото |
| API сегментации облачных провайдеров | 0 | ¥0.05-0.20 за фото | Сотни-тысячи фото |
| GPT-image-2 (стандартный режим) | 0 | ок. ¥0.30-0.50 за фото | Десятки-сотни фото |
| GPT-image-2 (режим размышления) | 0 | ок. ¥1-3 за фото | До нескольких десятков |
Рекомендации по выбору:
- Малые партии, кастомные категории, необходимость общения на естественном языке → GPT-image-2.
- Большие партии, фиксированные категории, чувствительность к задержкам → Традиционные модели.
- Смешанные задачи → Используйте GPT-image-2 для «исследовательского анализа», а традиционные модели — для «промышленной пакетной обработки».
Преимущества и недостатки семантической сегментации в GPT-image-2
Собрав все результаты тестов, мы составили список плюсов и минусов:
Ключевые преимущества GPT-image-2
1. Нулевой порог входа
Не нужно готовить обучающие данные, настраивать GPU-серверы или обладать опытом дообучения — достаточно одного API-ключа. Для небольших команд и междисциплинарных исследователей (городское планирование, социология, общественное здравоохранение) это преимущество перед традиционными моделями неоценимо.
2. Полностью настраиваемые категории
Вы можете сегментировать что угодно — «крышки люков против дорожного покрытия», «рекламные щиты против фасадов зданий», «вечнозеленые растения против листопадных» — если это можно описать словами, GPT-image-2 с высокой вероятностью справится.
3. Встроенные возможности анализа данных
Вы получаете не просто маску сегментации, а структурированные данные о долях объектов + расчет производных показателей (коэффициент озеленения, соотношение людей и машин, индекс видимости неба и т.д.). Для традиционных моделей пришлось бы писать отдельный код пост-обработки.
4. Высокая надежность
Ночные сцены, туман, низкое разрешение, необычные ракурсы — в тех «краевых» случаях, где традиционные модели часто ошибаются, GPT-image-2 выдает логичные выводы благодаря своим «мировым знаниям».
🎯 Выбор сценария: В городском планировании, ландшафтных исследованиях и других задачах, где нужно быстро подготовить отчет и работать с гибкими категориями, GPT-image-2 — лучший выбор. Рекомендуем использовать платформу APIYI (apiyi.com) для быстрой проверки того, подходит ли ваше решение под GPT-image-2.
Ключевые недостатки GPT-image-2
1. Долгое время обработки одного изображения
Стандартный режим — 2 минуты, режим размышления — 5-10 минут. Это абсолютно неприемлемо для задач реального времени (автопилоты, системы видеонаблюдения).
2. Взрывной рост стоимости при пакетной обработке
Для задачи сегментации 10 000 изображений традиционной модели на GPU потребуется 1 час, тогда как GPT-image-2 в режиме размышления может «сжечь» тысячи или даже десятки тысяч юаней.
3. Точность границ ниже, чем у традиционных SOTA
В плане точности на уровне пикселей (особенно для тонких объектов: веток, проводов, заборов) традиционные модели, обученные на датасете Cityscapes, по-прежнему имеют преимущество.
4. Неструктурированный вывод
Традиционные модели выдают стандартные PNG-маски, которые можно сразу подавать в конвейер (pipeline). GPT-image-2 выдает «дружелюбную для человека» цветную картинку + текстовое описание, что требует дополнительного парсинга перед записью в базу данных.
Применение семантической сегментации уличных видов с помощью GPT-image-2
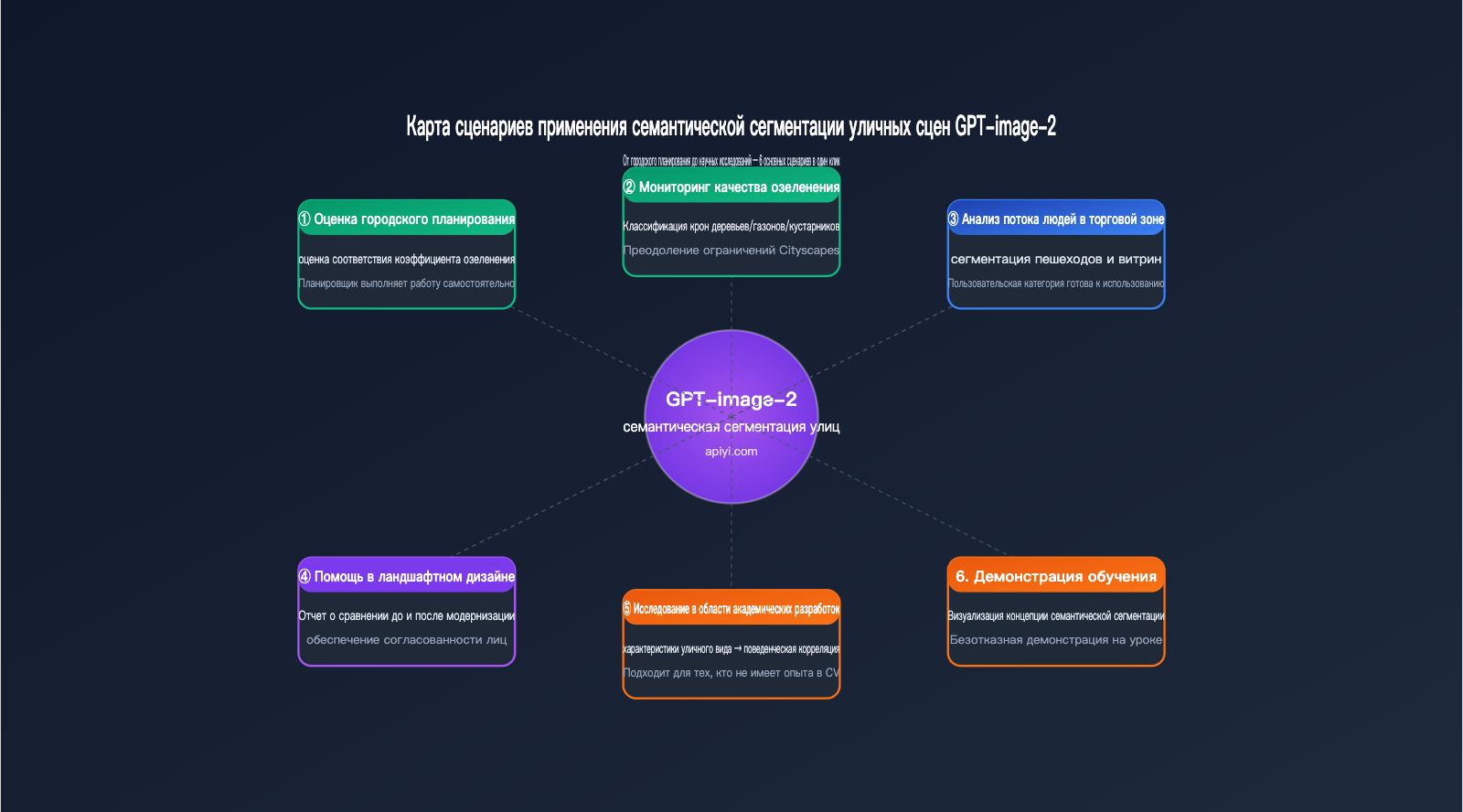
Разобравшись с возможностями модели, давайте рассмотрим несколько реальных сценариев, где GPT-image-2 для семантической сегментации уличных видов подходит лучше всего.
Городское планирование и оценка озеленения
Типичная задача: Оценить, соответствует ли качество озеленения в новом жилом комплексе стандартам планирования.
Традиционный процесс: Полевая съемка → загрузка на локальный GPU-сервер → запуск DeepLabV3+ → написание Python-скрипта для расчета GVI (индекса зеленого вида) → подготовка отчета. Весь процесс требует участия планировщика и инженера, занимая минимум 1–2 дня.
Процесс с GPT-image-2: Полевая съемка → загрузка в ChatGPT/API → мгновенный результат: «Коэффициент озеленения 32,7%, соответствует первому классу стандартов». Планировщик справляется самостоятельно, получая заключение за полчаса.
Сравнение ландшафтного дизайна «до и после»
Типичная задача: Демонстрация сравнения проекта благоустройства «до реконструкции vs после».
Способность GPT-image-2 сохранять согласованность лиц (и объектов) делает этот сценарий особенно удобным — одна и та же цветовая схема применяется к рендерам до и после, сразу выдавая сравнительное изображение + отчет об изменениях данных.
Академические исследования
Типичная задача: Исследование связи «визуальные характеристики уличного вида → психическое здоровье» в урбанистике и общественном здравоохранении.
Исследователи часто не являются экспертами в компьютерном зрении (CV), поэтому развертывание DeepLabV3+ для них нереалистично. GPT-image-2 снижает порог входа до нуля: «загрузил картинку — получил структурированные признаки», что позволяет ученым без профильного бэкграунда сразу переходить к анализу данных.
Учебные демонстрации
Типичная задача: Демонстрация того, что такое «семантическая сегментация» на курсах по городскому планированию или компьютерному зрению.
Традиционный подход требует запуска модели прямо на занятии, где высок риск сбоев конфигурации окружения. GPT-image-2 позволяет проводить демонстрацию прямо в браузере через ChatGPT: нулевая вероятность сбоя, высокая интерпретируемость, а студенты могут задавать уточняющие вопросы на естественном языке.
💡 Совет для быстрого старта: Тем, кто только начинает работать с семантической сегментацией уличных видов в GPT-image-2, рекомендуем сначала освоить границы возможностей модели на «тесте одного изображения в стандартном режиме», а затем решать, стоит ли переходить к пакетной обработке. Советуем протестировать 5–10 изображений бесплатно через платформу APIYI apiyi.com, чтобы получить наглядное представление о качестве перед выбором рабочего процесса.
Быстрый старт: семантическая сегментация уличных видов с GPT-image-2
Если вы хотите попробовать прямо сейчас, вот кратчайший путь — всего 3 шага.
Шаг 1: Подготовьте изображения уличных видов
Для первого теста рекомендуем выбирать дневные, четкие снимки с разрешением от 1024×768, чтобы у модели было достаточно информации для точного анализа. Источники могут быть любыми:
- Полевая съемка (достаточно камеры смартфона)
- Экспорт с платформ (Google Street View, Яндекс Панорамы и др.)
- Открытые датасеты (Cityscapes, Mapillary Vistas)
Шаг 2: Выберите способ вызова
| Способ вызова | Целевая аудитория | Преимущества |
|---|---|---|
| Веб-версия ChatGPT Plus | Неразработчики, исследователи | Без кода, отличная визуализация |
| OpenAI API | Разработчики, пакетная обработка | Программируемость, интеграция |
| Сервис-прокси APIYI | Российские разработчики | Прямое подключение, полная совместимость |
Шаг 3: Отправьте промпт
Можете использовать готовые шаблоны промптов для наших 4 сценариев:
Сценарий 1: Выполни семантическую сегментацию этого уличного вида и укажи легенду.
Сценарий 2: Дай данные по доле каждого элемента в легенде и рассчитай коэффициент озеленения.
Сценарий 3: Выполни семантическую сегментацию автомобилей и людей на площадке: синий цвет для авто, зеленый для людей.
Сценарий 4: Используя легенду с предыдущего изображения, выполни семантическую сегментацию второго изображения.
Пример кода для вызова API
Если вы работаете через API, вот минимальный пример вызова:
from openai import OpenAI
import base64
# Инициализация клиента через сервис-прокси APIYI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "Выполни семантическую сегментацию этого уличного вида, укажи долю каждого класса и рассчитай коэффициент озеленения."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # Режим рассуждения
)
print(response.choices[0].message.content)
🚀 Напоминание по API: При вызове gpt-image-2 через APIYI apiyi.com установите
base_urlнаhttps://api.apiyi.com/v1. Остальные поля полностью соответствуют официальному API OpenAI, поэтому существующий код на базе OpenAI SDK заработает после замены всего одной строки сbase_url.
FAQ по семантической сегментации городских пейзажей с помощью GPT-image-2
Вопрос 1: Достаточно ли высока точность семантической сегментации городских пейзажей в GPT-image-2?
Все зависит от ваших задач. Для академических отчетов, планирования и демонстрационных материалов точности режима «мышления» (погрешность ±2%) вполне достаточно. Если же речь идет о промышленно-точных измерениях (где требуется погрешность <1%), мы все же рекомендуем использовать традиционные модели в связке с выборочной проверкой человеком.
Вопрос 2: Сколько категорий городских объектов может распознать GPT-image-2?
Теоретически жесткого лимита на количество категорий нет — модель классифицирует объекты так, как вы опишете их в промпте. Однако на практике при обработке более 15 категорий на одном изображении могут возникать проблемы с путаницей в цветах и легенде. Рекомендуем ограничиваться 8–12 категориями за один проход.
Вопрос 3: Поддерживает ли GPT-image-2 сегментацию видео?
Текущая версия не поддерживает прямую обработку видеопотока. Если вам нужен анализ видео, придется сначала разбить его на кадры (например, 1 кадр/сек), обрабатывать каждый по отдельности, а затем собирать результат обратно в видео. Такой рабочий процесс требует много времени и ресурсов, поэтому мы его не рекомендуем.
Вопрос 4: Режим «мышления» занимает 10 минут, можно ли его ускорить?
Задержка в режиме «мышления» в основном связана с процессом самопроверки модели. Вот несколько способов ускорения:
- Снижение разрешения: сожмите исходное изображение до 1024×768 пикселей.
- Упрощение задачи: разделите сегментацию и расчет долей на два разных промпта, чтобы модель решала по одной задаче за раз.
- Использование стандартного режима: точность снизится на 1–2%, зато время обработки сократится в 5 раз.
Вопрос 5: Кто лучше в сегментации городских пейзажей: GPT-image-2 или Nano Banana Pro?
У них разные ниши. GPT-image-2 сильнее в способности к рассуждению и числовой точности (многошаговые выводы, автоматический расчет GVI). Nano Banana Pro выигрывает в скорости и стоимости (отклик за секунды). Если вам нужна массовая быстрая сегментация, выбирайте Nano Banana Pro; если нужно автоматическое создание аналитических отчетов — ваш выбор GPT-image-2.
Вопрос 6: Есть ли разница при вызове через APIYI (apiyi.com) по сравнению с официальным API?
Поля запросов и ответов идентичны — APIYI выступает в роли прокси-сервиса, обеспечивая 100% совместимость с OpenAI. Основные преимущества: прямое подключение из РФ без прокси, специализированная техническая поддержка на русском языке и прозрачная тарификация. Мы рекомендуем разработчикам подключаться к gpt-image-2 через APIYI (apiyi.com), чтобы избежать проблем со стабильностью сети.
Вопрос 7: Может ли GPT-image-2 выводить стандартную PNG-маску?
Текущая версия не поддерживает прямой вывод пиксельно-точных файлов масок. Модель выдает «отрендеренное цветное изображение». Если вам нужна маска для обучения других моделей, потребуется дополнительная постобработка с разделением по цветовым порогам.
Вопрос 8: Можно ли редактировать результаты сегментации GPT-image-2?
Да, вы можете задавать уточняющие вопросы на основе первого результата. Например: «Наложи на исходное изображение полупрозрачную красную маску на все зоны с растительностью для привлечения внимания». Модель выполнит производную обработку, основываясь на предыдущем результате сегментации. Это возможности, недоступные для традиционных моделей.
Ключевые выводы по семантической сегментации в GPT-image-2
- Новая парадигма: GPT-image-2 не пытается заменить DeepLabV3+, а открывает новый путь: «управление на естественном языке, отсутствие необходимости в развертывании, возможность производного анализа».
- Достаточная точность: в режиме «мышления» погрешность составляет всего ±2% по сравнению с традиционными SOTA-моделями, что подходит для большинства бизнес-задач.
- Слабое место — скорость: обработка одного изображения занимает минуты, поэтому модель совершенно не подходит для задач реального времени и массовой обработки.
- Гибкость категорий — главный козырь: там, где традиционные модели ограничены «19 категориями Cityscapes», GPT-image-2 справляется одним промптом.
- Автоматизация GVI: расчет индекса озеленения (GVI) сокращается с «целого дня работы инженера и планировщика» до «5 минут работы одного планировщика».
- Оптимальное решение — гибридное: используйте GPT-image-2 для исследовательского анализа, а традиционные модели — для промышленной массовой обработки. Они отлично дополняют друг друга.
- Рекомендация по доступу: используйте APIYI (apiyi.com) для стабильного прямого подключения и полной совместимости с официальными спецификациями.
Итоги
Семантическая сегментация уличных сцен с помощью GPT-image-2 — это не замена традиционной сегментации, а её дополнение. Она закрывает потребности в «малых объемах, кастомизации, взаимодействии на естественном языке и автоматическом получении аналитических выводов» — то есть задачи, которые раньше полностью игнорировались такими моделями, как DeepLabV3+ или PSPNet.
От автоматического расчета коэффициента озеленения до сегментации по пользовательским категориям: GPT-image-2 переносит работу, для которой раньше требовались «инженер по алгоритмам + GPU + обучающие данные», в руки любого, кто умеет пользоваться ChatGPT. Это настоящий сдвиг парадигмы для городского планирования, ландшафтного дизайна, научных исследований и других областей.
Однако помните об ограничениях: время обработки одной картинки составляет минуты, стоимость при массовой обработке непредсказуема, а точность на уровне пикселей уступает SOTA-решениям. Эти три минуса предопределяют, что GPT-image-2 не заменит традиционные модели, а будет существовать параллельно с ними.
Если вы планируете внедрить GPT-image-2 в свой рабочий процесс, рекомендую начать с «маленького, но важного» сценария (например, анализ озеленения 50 снимков улиц). После того как отладите весь процесс от начала до конца, можно будет решать, стоит ли масштабировать его на большие объемы.
✨ Совет напоследок: отечественным разработчикам и исследователям мы рекомендуем подключаться к GPT-image-2 через платформу APIYI (apiyi.com). Это обеспечит стабильный вызов модели, полную совместимость полей с официальным API и прозрачную тарификацию по токенам. Для первых шагов на платформе предусмотрены бесплатные лимиты, которых хватит для проведения PoC-тестирования и проверки всех 4 сценариев из этой статьи.
Автор: Команда APIYI
Последнее обновление: 02.05.2026