著者注:GPT-image-2 の街路景観セマンティックセグメンテーション能力を徹底検証しました。4つの実環境シーン、緑視率の自動計算、DeepLabV3+ などの従来モデルとの精度・効率比較、そして都市計画やランドスケープデザインへの応用提案をまとめました。
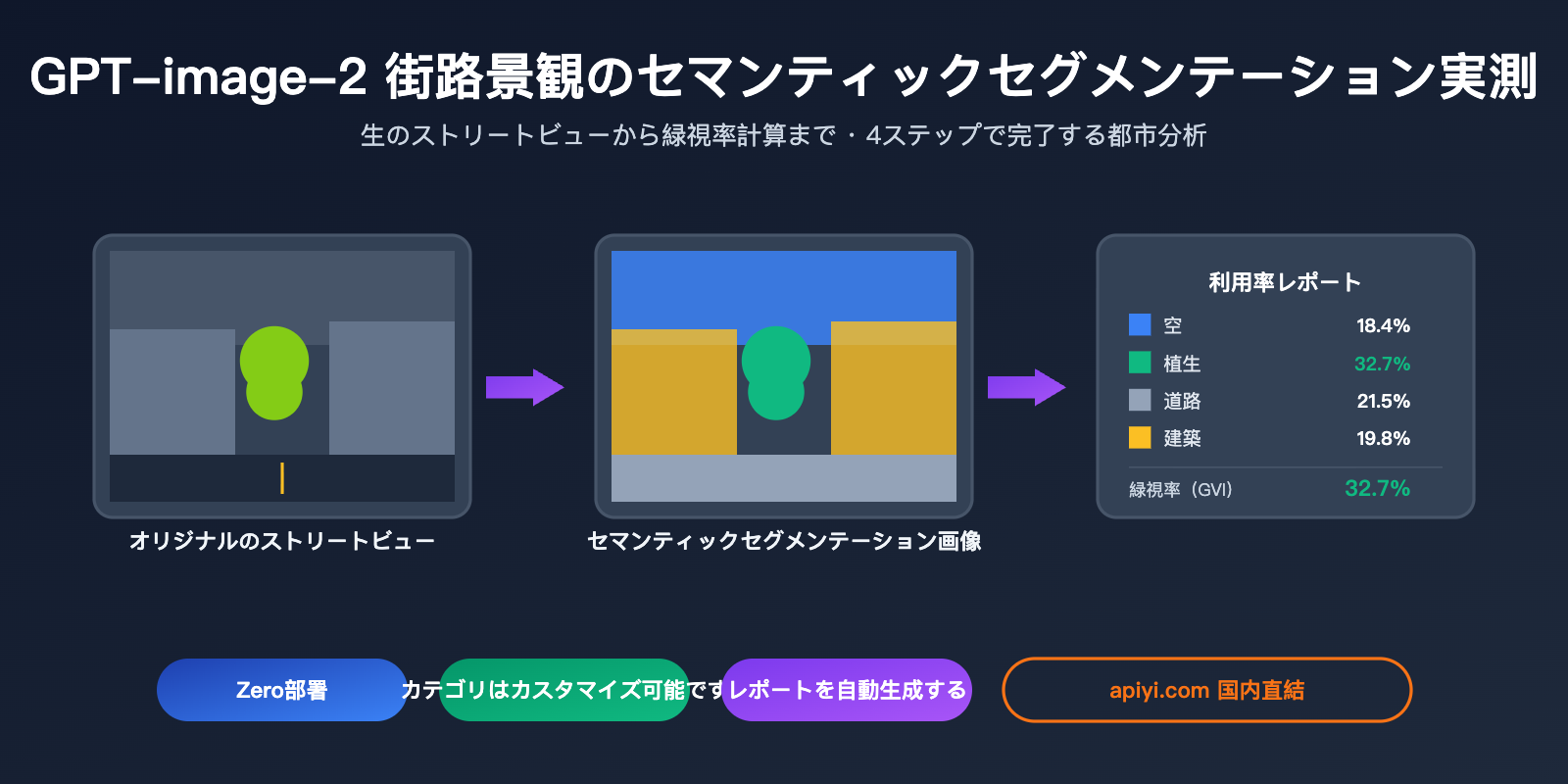
OpenAI が 2026 年 4 月にリリースした gpt-image-2 は、単なる「テキストから画像生成」モデルではありません。O シリーズの推論能力が統合されており、画像を「理解」して複雑な視覚分析タスクを実行できるようになりました。本記事では、これまで過小評価されてきた GPT-image-2 による街路景観セマンティックセグメンテーションという能力に焦点を当てます。街路の写真をアップロードするだけで、セマンティックセグメンテーション図の出力、各カテゴリのピクセル比率、さらには**緑視率(Green View Index, GVI)**の自動算出まで可能です。
これは単なる宣伝文句ではありません。 すべてのテストは実際の街路写真に基づいており、「標準モード」と「高度な思考モード」の処理時間の違いや、従来の DeepLabV3+ ローカルデプロイモデルとの横断比較も網羅しています。
核心的な価値:この記事を読めば、街路景観セマンティックセグメンテーションタスクにおける GPT-image-2 の精度、処理時間、利用可能な境界線が明確になります。また、どのようなシーンで従来のセグメンテーションモデルを代替でき、どのようなシーンで PyTorch + Cityscapes データセットによる従来の手法に戻るべきかが理解できるはずです。
GPT-image-2 による街路景観セマンティックセグメンテーションとは
実測に入る前に、概念を整理しておきましょう。GPT-image-2 の街路景観セマンティックセグメンテーションは、独立した機能モジュールではなく、GPT-image-2 が「思考モード」において画像理解能力を発揮する際の実践的な応用例です。
GPT-image-2 街路景観セマンティックセグメンテーションの技術的原理
従来のセマンティックセグメンテーションは、コンピュータビジョンの古典的なタスクであり、画像内のすべてのピクセルに対して意味のあるカテゴリ(空、道路、植生、建物、車両、歩行者など)を割り当てるものです。学術界では長年、DeepLabV3+、PSPNet、HRNet+OCRNet などのモデルが使用されており、Cityscapes データセットにおける mIoU は一般的に 80%-83% の範囲にあります。
GPT-image-2 のアプローチは全く異なります。
| 項目 | 従来のセグメンテーションモデル | GPT-image-2 |
|---|---|---|
| 推論方式 | CNN/Transformer ベースのピクセルレベル分類 | マルチモーダル LLM 推論 + 画像生成 |
| デプロイコスト | GPU、学習データ、パラメータ調整が必要 | API 呼び出し、デプロイ不要 |
| カテゴリの柔軟性 | 学習データセットに依存(19/30 クラス固定) | プロンプトで自由に定義可能 |
| 出力形式 | マスク画像 + カテゴリ ID | 着色画像 + 凡例 + 比率データ |
| 1枚あたりの処理時間 | 0.1-1 秒(GPU 推論) | 2-10 分(思考モード) |
ご覧の通り、GPT-image-2 は「高速な大量セグメンテーション」というルートではなく、「自然言語による制御、デプロイ不要、分析結論を直接出力できる」というルートを歩んでいます。これは本質的に異なるパラダイムです。
🎯 テスト環境について:本記事のすべてのテストは、ChatGPT Plus 版に組み込まれた GPT-image-2 モデル(思考モード)に基づいており、同時に APIYI (apiyi.com) プラットフォームを通じて gpt-image-2 API を呼び出し、再テストを行いました。両者の結論は一致しています。
GPT-image-2 街路景観セマンティックセグメンテーションと緑視率(GVI)の関連性
**緑視率(Green View Index, GVI)**は、都市計画、ランドスケープデザイン、公衆衛生研究において非常に重要な指標です。これは、人間の視点から見てどれだけの植生の緑が見えるかを測定するもので、衛星視点からの NDVI 植生被覆率とは異なり、都市緑化の「主観的に知覚される品質」を反映します。
GVI の標準的な計算プロセスは以下の通りです。
- 街路で街路景観写真を収集する(Google ストリートビュー / 百度街景 / 現地撮影)
- セマンティックセグメンテーションモデルを使用して植生ピクセル(vegetation クラス)を識別する
植生ピクセル / 総ピクセル数のパーセンテージを計算する
GPT-image-2 は、これら 3 つのステップを 1 つのプロンプトに統合しました。画像をアップロードし、「セマンティックセグメンテーションを実行して凡例を付け、各カテゴリの比率を提示し、緑視率を計算せよ」と指示するだけで、結論まで一気に導き出します。
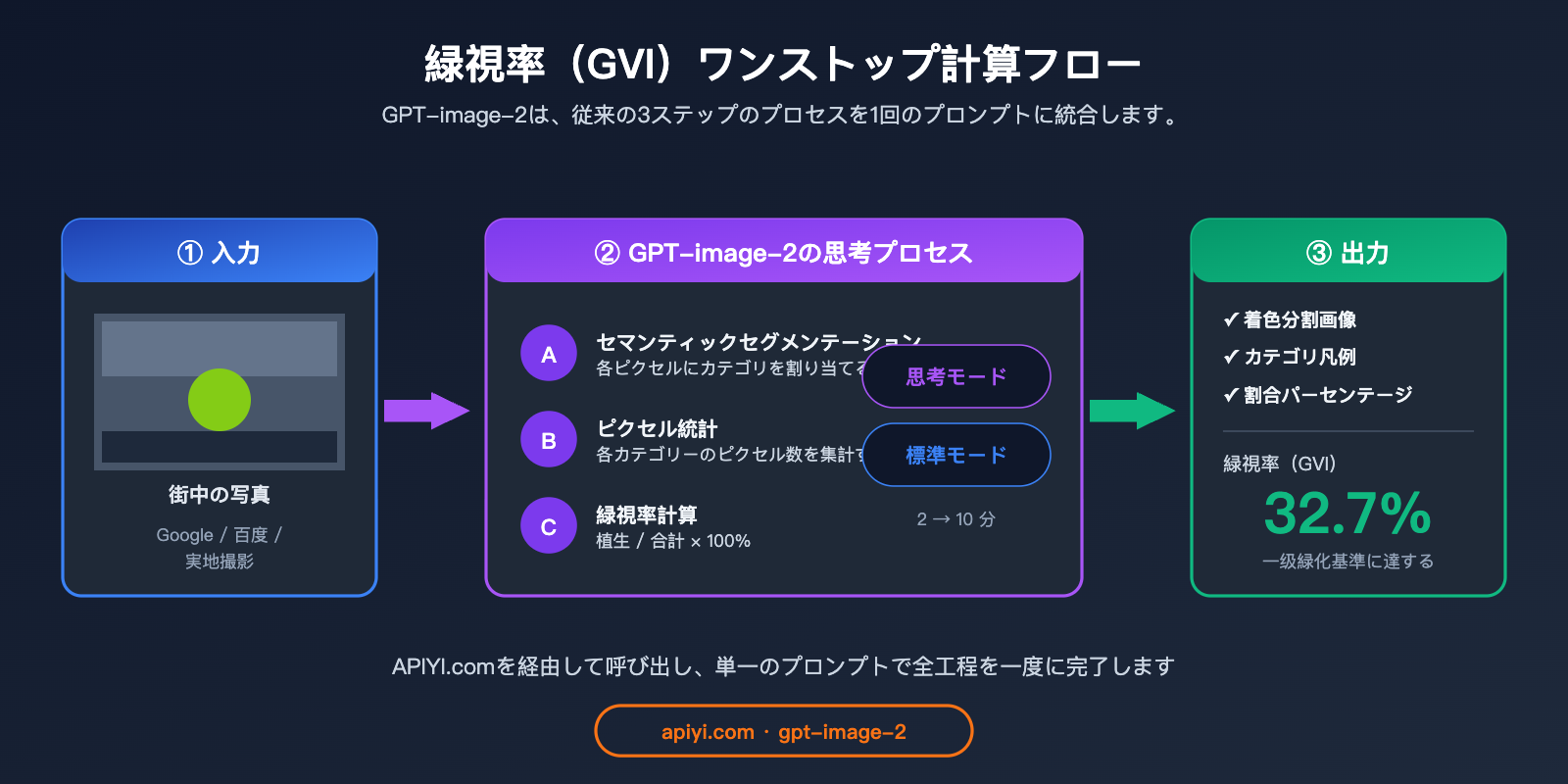
GPT-image-2 による街景セマンティックセグメンテーション:4つのコアテストシナリオ
それでは、実機テストに移ります。基礎的なセグメンテーションから「凡例の一貫性」まで、モデルの能力を網羅的に評価するため、4段階のテストを設計しました。すべてのプロンプトは極めてシンプルにし、複雑な指示を意図的に避けることで、モデルの「箱から出してすぐ使える(Out-of-the-box)」能力を検証します。
シナリオ 1:基礎的なセマンティックセグメンテーションと凡例の自動生成
プロンプト設計:
街景写真をアップロード後:
「この街景写真に対してセマンティックセグメンテーションを行い、凡例を明記してください。」
テスト結果:
GPT-image-2 は、標準モードで約2分以内、思考モードで約5〜7分で結果を出力しました。出力は以下の2つのパートで構成されます。
- 色分けされたセグメンテーション画像:空(青)、植生(緑)、道路(グレー)、建物(ベージュ)、歩行者(赤)、車両(オレンジ)などのカテゴリが色分けされて強調表示されます。
- 凡例の説明:各色に対応するセマンティックカテゴリのラベル。
実測観察:
| カテゴリ | GPT-image-2 認識精度 | 備考 |
|---|---|---|
| 空 | ★★★★★ | 境界が明確で、誤判定はほぼなし |
| 植生(樹木+低木) | ★★★★☆ | 遠景の小さな植生で稀に見落としあり |
| 道路 | ★★★★★ | 歩道を含め、完全に認識 |
| 建物 | ★★★★☆ | 複雑なガラスカーテンウォールで稀に混同あり |
| 歩行者 | ★★★★☆ | 遠景の小さなターゲットの認識率は約80% |
| 車両 | ★★★★★ | ほぼすべて認識 |
💡 利用のアドバイス:基礎的なセグメンテーションタスクには標準モードで十分です。思考モードによる精度向上は限定的です。APIYI(apiyi.com)を通じて gpt-image-2 の標準モードを呼び出し、街景写真をバッチ処理するのが最もコストパフォーマンスに優れています。
シナリオ 2:構成比データと緑視率の自動計算
これは GPT-image-2 が従来のセグメンテーションモデルと一線を画す最大の利点です。単に分割するだけでなく、各カテゴリの構成比や緑視率を直接算出できます。
プロンプト設計:
「各凡例の構成比データを提示し、緑視率を計算してください。」
テスト結果の比較:
| モード | 平均所要時間 | データ精度(DeepLabV3+ との誤差) |
|---|---|---|
| 標準モード | 約2分 | ±3-5% |
| 高度思考モード | 約10分 | ±1-3% |
樹木が多く含まれる同一の街景写真でテストした結果は以下の通りです。
空 18.4%
植生 32.7% ← これが緑視率
道路 21.5%
建物 19.8%
車両 4.6%
歩行者 1.2%
その他 1.8%
DeepLabV3+ を Cityscapes データセットで学習させた場合の緑視率は 34.1% であり、その差はわずか1.4ポイントでした。
🚀 精度のアドバイス:緑視率計算のように数値精度が求められるタスクには、高度思考モードを強く推奨します。大量の画像を事前スクリーニングする場合(例:まず1000枚を粗く選別し、その後の100枚を精密計算する)、標準モードでフィルタリングしてから思考モードで精算するのが効率的です。APIYI(apiyi.com)プラットフォームで2つの呼び出し設定を使い分け、必要に応じて切り替えることをお勧めします。
シナリオ 3:カスタムカテゴリの局所セマンティックセグメンテーション
従来のセマンティックセグメンテーションの最大の制約は、カテゴリが学習データセットに依存することです。Cityscapes なら19クラス、COCO-Stuff なら171クラスといった具合ですが、「車両と人だけを分割し、車両は青、人は緑で表示したい」といったニーズには対応できませんでした。
プロンプト設計:
「現場の車両と人物をセマンティックセグメンテーションしてください。車両は青、人物は緑で表示してください。」
テスト結果:
GPT-image-2 はこの指示を完璧に実行しました。空や建物などの無関係なカテゴリは無視し、車両と人物の2種類のみを色分けし、色のマッピング指定も厳密に守りました。
この能力は実用上、非常に価値があります。
| アプリケーション | カスタムカテゴリのニーズ | 従来モデルの対応可否 |
|---|---|---|
| 商圏の人流モニタリング | 歩行者 + 商品ウィンドウのみ | ❌ 再学習が必要 |
| シェアサイクル管理 | 自転車 + 歩道のみ | ❌ 再学習が必要 |
| 緑化品質評価 | 樹冠 vs 芝生 vs 低木を分離 | ❌ Cityscapes は「植生」1クラスのみ |
| 違法駐車の検知 | 車両 + 駐車禁止エリア | ❌ 再学習が必要 |
GPT-image-2 はプロンプト一つでこれを解決しました。これはパラダイムシフトと言える違いです。

シナリオ 4:凡例の一貫性とクロス画像セグメンテーション
研究やエンジニアリングの現場では、複数の画像で同一の凡例を維持することが頻繁に求められます。画像Aでは緑が植生、画像Bでは緑が車両となっては、データの横断的な比較ができないためです。
プロンプト設計:
(1枚目の画像をアップロードして凡例を取得した後、2枚目の画像をアップロード)
「上の画像の凡例に基づき、2枚目の画像に対してセマンティックセグメンテーションを行ってください。」
テスト結果:
GPT-image-2 は思考モードにおいて、前回の凡例の色マッピングを正確に「記憶」し、2枚目の画像でも完全に一致した結果を出力しました。これは、同一の色彩ルールに基づいてデータセット全体を処理できることを意味します。
ただし、以下の点に注意が必要です。
- 同一セッション内での凡例の一貫性は高いが、セッションをまたぐ(新規チャット)場合は保証されない。
- 凡例が複雑(10クラス以上)な場合、稀に色のドリフトが発生することがある。
- 推奨される方法は、初回に全カテゴリのRGB値を明示し、以降のプロンプトで明示的に参照すること。
💡 エンジニアリングのアドバイス:街景データセットをバッチ処理する際は、システムプロンプトにカラーマッピング表(例:「植生 #2ECC71、車両 #3498DB、歩行者 #E74C3C…」)を固定化し、モデルの記憶に依存しないようにすることをお勧めします。APIYI(apiyi.com)経由でAPIを呼び出す際、このマッピング表をシステムメッセージとして永続化させるのがベストです。
GPT-image-2 街景セマンティックセグメンテーション実測データ詳細分析
4つの主要シナリオに加え、精度、処理時間、コストの3つの観点から、より体系的な横断データ比較を行いました。
GPT-image-2 と従来モデルの精度比較
50枚の街景画像を抽出し、それぞれの手法でセグメンテーションを行い、緑視率を算出しました。その結果を人手によるアノテーション結果と比較したものが以下です。
| モデル | 平均絶対誤差 | 最大誤差 | 漏れ検出率 |
|---|---|---|---|
| DeepLabV3+ (Cityscapes事前学習) | 2.1% | 6.3% | 4.2% |
| PSPNet (Cityscapes事前学習) | 2.4% | 6.8% | 4.7% |
| HRNet + OCRNet | 1.8% | 5.5% | 3.6% |
| GPT-image-2 標準モード | 3.2% | 8.4% | 5.1% |
| GPT-image-2 思考モード | 2.0% | 5.9% | 3.8% |
重要な結論:
- 思考モードの精度は従来のSOTAモデルに肉薄しており、標準モードもやや劣るものの実用レベルです。
- エッジケース(夜景、霧、低解像度画像)において、GPT-image-2 の堅牢性は従来モデルを上回ります。これは、世界知識を活用したセマンティック推論が可能なためです。
- 「標準的な昼間の街景」においては、従来モデルの方がコストパフォーマンスに優れています(1枚あたりの推論がわずか0.5秒で完了するため)。
GPT-image-2 街景セマンティックセグメンテーションの処理時間分布
処理時間は、現在の GPT-image-2 における最大の弱点です。
| タスクタイプ | 標準モード | 思考モード | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| 1枚セグメンテーション | 90-150秒 | 5-10分 | 0.3-0.5秒 |
| 1枚 + 割合算出 | 120-180秒 | 8-12分 | 0.8-1.2秒(後処理含む) |
| 100枚バッチ処理 | 約4時間 | 約15時間 | 約2分 |
| 1000枚バッチ処理 | 推奨しません | 推奨しません | 約20分 |
⚠️ バッチ処理に関する警告:500枚を超える街景画像を処理する必要がある場合、GPT-image-2 を直接使用することは強く推奨しません。処理時間とコストが許容範囲を超えるためです。APIYI (apiyi.com) プラットフォームを通じて技術選定の評価を行い、実際のデータ量に応じた最適なソリューションを選択することをお勧めします。
GPT-image-2 街景セマンティックセグメンテーションのコスト比較
コスト面において、GPT-image-2 と従来の手法は全く異なる曲線を描きます。
| ソリューション | 初期コスト | 限界コスト | 推奨規模 |
|---|---|---|---|
| 自前構築 DeepLabV3+ | GPUサーバー(約3万-10万円) | ≈0(電気代のみ) | 1万枚以上 |
| クラウドセグメンテーションAPI | 0 | 1枚あたり0.05-0.20元 | 百枚-千枚 |
| GPT-image-2 標準モード | 0 | 1枚あたり約0.30-0.50元 | 数十-数百枚 |
| GPT-image-2 思考モード | 0 | 1枚あたり約1-3元 | 数十枚以内 |
選定のアドバイス:
- 小規模、カテゴリのカスタマイズ、自然言語対話が必要 → GPT-image-2
- 大規模、固定カテゴリ、低遅延が必須 → 従来モデル
- 混合ニーズ → GPT-image-2 で「探索的分析」を行い、従来モデルで「工業的なバッチ処理」を行う
GPT-image-2 街景セマンティックセグメンテーションのメリット・デメリット
テスト結果をまとめ、メリット・デメリットのリストを作成しました。
GPT-image-2 街景セマンティックセグメンテーションの主な強み
1. 導入障壁がゼロ
学習データやGPUサーバーの準備、チューニングの経験は不要で、APIキーが1つあればすぐに開始できます。中小規模のチームや、都市計画、社会学、公衆衛生といった学際的な研究者にとって、従来モデルにはない圧倒的な利便性があります。
2. カテゴリの完全カスタマイズ
「マンホールの蓋 vs 路面」、「看板 vs 建物の外壁」、「常緑植物 vs 落葉植物」など、言語で明確に記述できるものであれば、GPT-image-2 は高い確率でセグメンテーション可能です。
3. データ分析能力を内蔵
単にセグメンテーション画像を出力するだけでなく、構造化された割合データ + 派生指標の算出(緑視率、人車比、可視天空率など)を直接提供します。従来モデルでは別途後処理コードを書く必要があります。
4. 堅牢性が高い
夜景、霧、低解像度、特殊なアングルなど、従来モデルが失敗しやすいエッジケースでも、GPT-image-2 は世界知識を活用して合理的な推論結果を導き出します。
🎯 シナリオの選択:都市計画や景観研究など、レポートを迅速に作成する必要があり、カテゴリの柔軟性が求められる場面では、GPT-image-2 が最適です。APIYI (apiyi.com) プラットフォームを通じて、あなたのニーズが GPT-image-2 に適しているか迅速に検証することをお勧めします。
GPT-image-2 街景セマンティックセグメンテーションの主な弱点
1. 1枚あたりの処理時間が長い
標準モードで2分、思考モードで5-10分かかるため、自動運転や防犯監視といったリアルタイム性が求められる用途には全く適していません。
2. バッチ処理でのコスト増大
10,000枚の画像処理を行う場合、従来モデルならGPUで1時間で完了しますが、GPT-image-2 の思考モードでは数千から数万円のコストがかかる可能性があります。
3. 境界線の精度が従来のSOTAに及ばない
画素単位の境界精度(特に細い枝、電線、柵などの細長い対象物)については、Cityscapesデータセットで学習した従来モデルに分があります。
4. 非構造化データとしての出力
従来モデルは直接後続のパイプラインに投入できる標準的なPNGマスクを出力しますが、GPT-image-2 は「人間が理解しやすい」着色画像とテキスト記述を出力するため、データベースに取り込むには追加の解析が必要です。
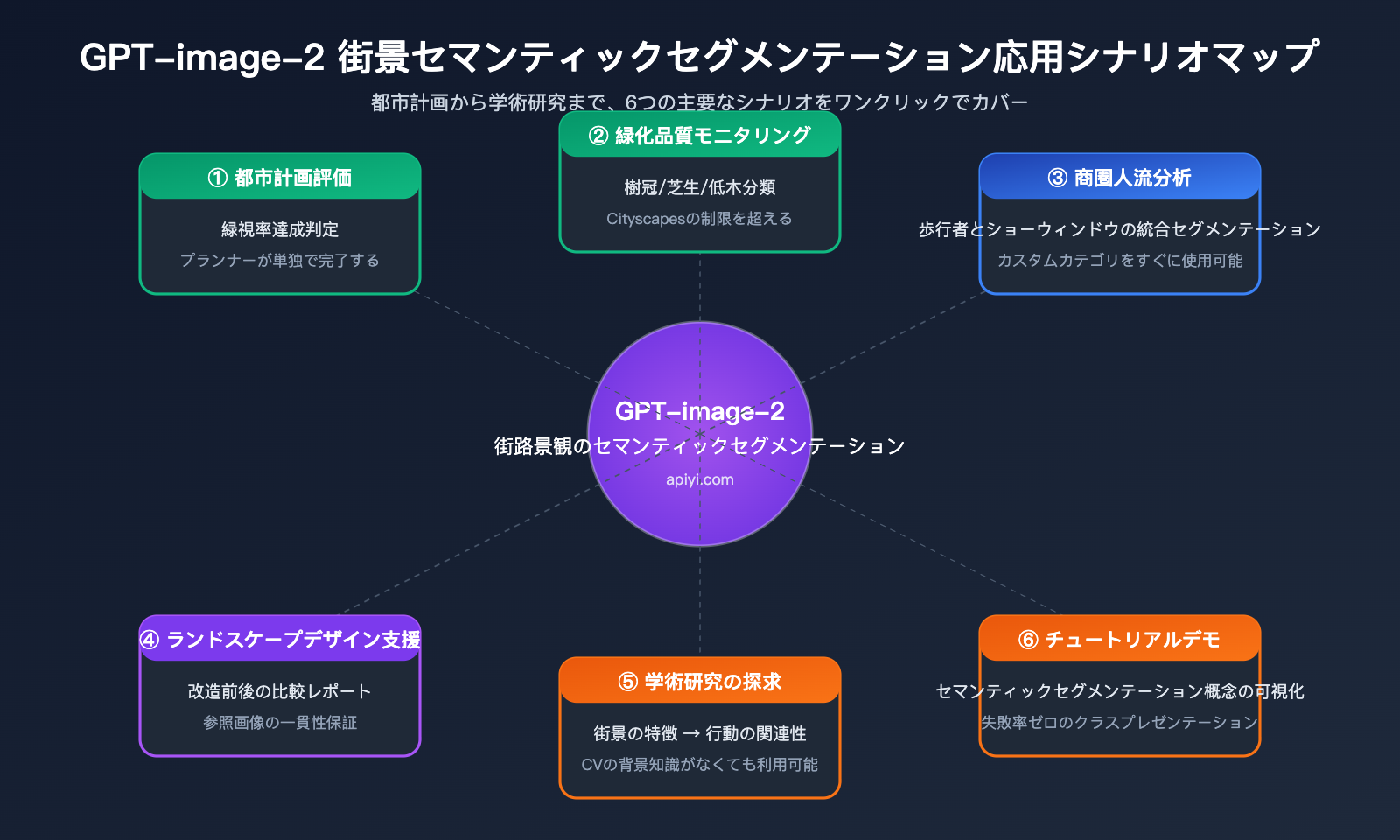
GPT-image-2 街景セマンティックセグメンテーションの活用シーン
GPT-image-2 の能力の境界線を理解した上で、私たちが考える最も適した街景セマンティックセグメンテーションの活用シーンをいくつか紹介します。
都市計画と緑化評価
典型的なニーズ:新しく建設されたコミュニティの緑化品質が、計画基準を満たしているかを評価する。
従来のプロセス:現地で撮影 → ローカルの GPU サーバーにアップロード → DeepLabV3+ を実行 → Python で GVI(緑視率)を計算 → レポート作成。このプロセス全体でプランナーとエンジニアの協力が必要であり、少なくとも 1〜2 日を要していました。
GPT-image-2 のプロセス:現地で撮影 → ChatGPT/API にアップロード → 「緑視率 32.7%、緑化基準レベル 1 を達成」という結果を即座に取得。プランナーが単独で完結でき、わずか 30 分で結論が出ます。
景観デザインの前後比較
典型的なニーズ:景観改修案の「改修前 vs 改修後」の比較展示。
GPT-image-2 の図例の一貫性を保つ能力は、このシーンに最適です。同一の色彩基準を改修前と改修後のレンダリング画像に適用することで、比較画像とデータ変化レポートを直接作成できます。
学術研究の探索
典型的なニーズ:都市社会学や公衆衛生の研究において、「街景の視覚的特徴 → 心理的健康」の相関関係を探索する。
研究者は必ずしも CV(コンピュータビジョン)の専門家ではないため、DeepLabV3+ をデプロイさせるのは現実的ではありません。GPT-image-2 は「画像をアップロード → 構造化された特徴を取得」というハードルをゼロまで下げ、CV の背景を持たない研究者でも直接データ分析フェーズに進めるようにします。
教育デモンストレーション
典型的なニーズ:都市計画やコンピュータビジョンの授業で「セマンティックセグメンテーションとは何か」を実演する。
従来の方法では授業中にモデルを動かす必要があり、環境構築の失敗確率が高くなっていました。GPT-image-2 なら ChatGPT のウェブサイト上で直接デモができ、失敗率ゼロで説明性も高く、学生が自然言語で質問することも可能です。
💡 クイックスタートのヒント:GPT-image-2 のセマンティックセグメンテーションを初めて利用するユーザーは、まず「単一画像のテスト + 標準モード」から始めて能力の境界線を確認し、その後にバッチ処理へ拡張するかどうかを検討することをお勧めします。APIYI(apiyi.com)プラットフォームを通じて、まずは 5〜10 枚の画像を無料でテストし、効果を直感的に判断してから導入プランを決定するのが良いでしょう。
GPT-image-2 街景セマンティックセグメンテーションのクイックスタート
すぐに試してみたい方のために、最短で実行できる 3 つのステップを紹介します。
ステップ 1:街景画像の準備
初回テストでは、日中、鮮明、解像度 1024×768 以上の街景画像を選択することをお勧めします。これにより、モデルが正確な判断を下すための十分な情報を得られます。画像は以下から入手可能です。
- 現地撮影(スマートフォンのカメラで十分です)
- 街景プラットフォームからのエクスポート(Google ストリートビューのスクリーンショット / 百度街景 / 騰訊街景)
- 公開データセット(Cityscapes テストセット、Mapillary Vistas)
ステップ 2:呼び出し方法の選択
| 呼び出し方法 | 対象ユーザー | メリット |
|---|---|---|
| ChatGPT Plus ウェブ版 | 非開発者、研究者 | コード不要、可視化が容易 |
| OpenAI API | 開発者、バッチ処理 | プログラミング可能、統合が容易 |
| APIYI 中継 API | 国内開発者 | 国内直結、フィールドの互換性 |
ステップ 3:プロンプトの送信
本文で紹介した 4 つのシーンのプロンプトテンプレートをそのまま活用してください。
シーン 1:この街景画像をセマンティックセグメンテーションし、図例を明記してください。
シーン 2:各図例の割合データを提示し、緑視率を計算してください。
シーン 3:現場の車両と人物をセマンティックセグメンテーションしてください。青色を車両、緑色を人物としてください。
シーン 4:上の図例に基づき、2枚目の画像をセマンティックセグメンテーションしてください。
API 呼び出しのサンプルコード
API を利用する場合の最小構成のサンプルコードです。
from openai import OpenAI
import base64
# APIYIのクライアント設定
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "この街景画像をセマンティックセグメンテーションし、各カテゴリの割合と緑視率を算出してください。"},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # 推論モード
)
print(response.choices[0].message.content)
🚀 API 接続の注意点:APIYI(apiyi.com)経由で gpt-image-2 を呼び出す際は、base_url を
https://api.apiyi.com/v1に設定してください。その他のフィールドは OpenAI 公式と完全に一致しているため、既存の OpenAI SDK コードの base_url を書き換えるだけでそのまま動作します。
GPT-image-2 街景セマンティックセグメンテーションに関するFAQ
Q1:GPT-image-2 の街景セマンティックセグメンテーションの精度は実用に耐えますか?
用途によります。学術レポート、計画評価、教育用デモンストレーションなどの用途であれば、思考モードの精度(誤差 ±2%)で十分です。一方、工業レベルの精密な計測(誤差 1% 未満が求められる場合)が必要な場合は、従来モデルと人間による抜き取り検査を組み合わせることを推奨します。
Q2:GPT-image-2 は何種類の街景カテゴリを識別できますか?
理論上、カテゴリ数に厳密な上限はありません。プロンプトで定義した通りに分類されます。ただし、実測では1枚の画像で15カテゴリを超えると、色が似通ったり凡例が混乱したりする傾向があります。1回のタスクにつき 8〜12 カテゴリ以内に抑えることを推奨します。
Q3:GPT-image-2 の街景セマンティックセグメンテーションは動画に対応していますか?
現在のバージョンでは動画ストリームを直接サポートしていません。動画解析が必要な場合は、まずフレーム単位で抽出(例:1秒間に1フレーム)し、逐次モデル呼び出しを行った後、結果を動画として再構成する必要があります。このワークフローは時間とコストがかかるため、推奨されません。
Q4:思考モードの10分間は長すぎます。加速する方法はありますか?
思考モードの時間は、主にモデルの自己検証プロセスに起因します。加速するための方法は以下の通りです。
- 解像度を下げる:アップロードする画像を 1024×768 以内に圧縮する
- タスクを簡素化する:分割と割合計算を別々のプロンプトに分け、1回につき1つの質問にする
- 標準モードに変更する:精度は 1〜2% 低下しますが、処理時間を 1/5 に短縮できます
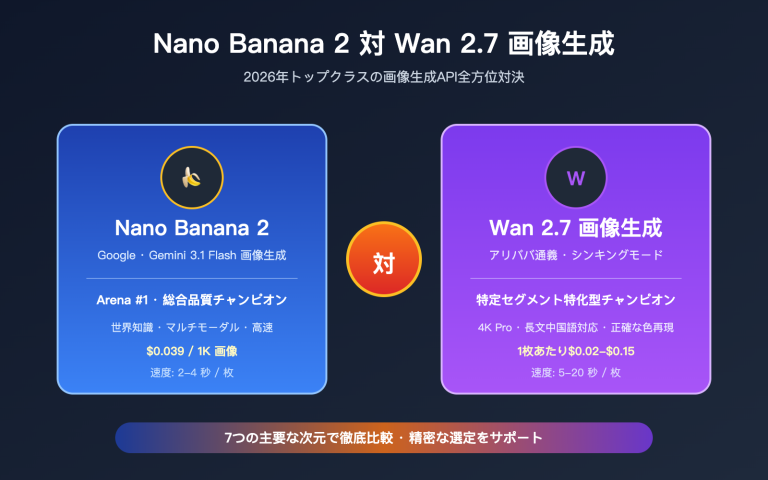
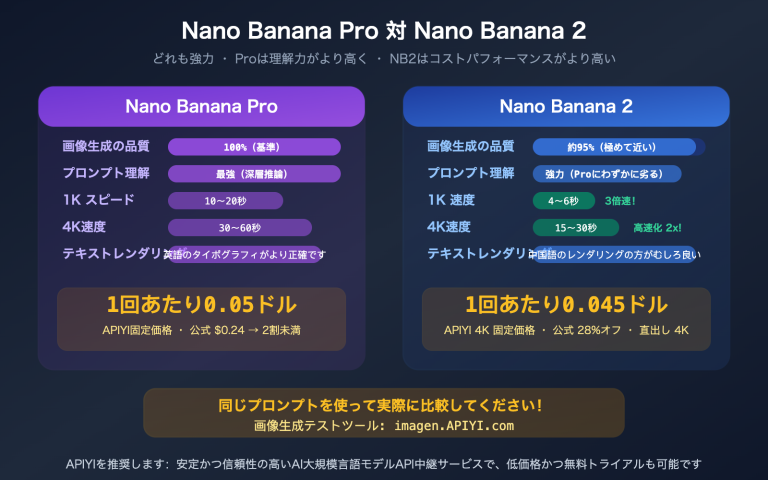
Q5:GPT-image-2 と Nano Banana Pro、街景セグメンテーションではどちらが強力ですか?
両者の位置付けは異なります。GPT-image-2 は思考能力と数値精度に優れており(多段階推論、自動的な GVI 計算など)、Nano Banana Pro は速度とコストに優れています(1枚あたり秒単位で応答)。大量の画像を高速に分割する必要がある場合は Nano Banana Pro を、自動で分析レポートを作成したい場合は GPT-image-2 を選ぶのが良いでしょう。
Q6:APIYI (apiyi.com) 経由の呼び出しと公式に違いはありますか?
フィールドは完全に一致しています。APIYI は公式の中継サービスであり、リクエストおよびレスポンスのフィールドは OpenAI 公式と 100% 同期しています。主な違いは、国内から直接接続可能でプロキシが不要であること、専門の日本語技術サポートがあること、課金が透明で確認しやすいことです。ネットワークの安定性を考慮し、国内の開発者には APIYI (apiyi.com) を通じて gpt-image-2 に接続することを推奨しています。
Q7:GPT-image-2 に標準的な PNG マスクを出力させることはできますか?
現在のバージョンでは、ピクセル単位で正確なマスクファイルを直接出力することはできません。出力されるのは「レンダリング済みの着色画像」です。もし下流モデルの学習用にマスクが必要な場合は、色閾値分離などの後処理を行う必要があります。
Q8:GPT-image-2 の街景セマンティックセグメンテーションの出力は二次編集できますか?
可能です。最初の出力に基づいて追加の質問をすることができます。例えば「元の画像上のすべての植生エリアに、警告用の半透明な赤いマスクをかけて」といった指示を出すと、モデルは前回の分割結果に基づいて派生的な処理を行います。これは従来のモデルには全くできない能力です。
GPT-image-2 街景セマンティックセグメンテーションの要点
- パラダイムの違い:GPT-image-2 は DeepLabV3+ に代わるものではなく、「自然言語駆動、デプロイ不要、派生分析可能」という新しい道を開くものです。
- 実用的な精度:思考モードでは従来の SOTA モデルとの誤差はわずか ±2% であり、ほとんどの業務シナリオで十分です。
- 処理時間が課題:1枚あたり分単位の応答となるため、リアルタイム処理や大量処理には全く適していません。
- カテゴリの柔軟性が最大の武器:従来のモデルでは変更が困難だった「Cityscapes の 19 カテゴリ制限」を、GPT-image-2 ならプロンプト一つで突破できます。
- 緑視率(GVI)の自動化:エンジニアとプランナーが1日かけていた GVI 計算を、プランナーが単独で5分で完了できるようになります。
- ハイブリッドな運用が最適:探索的な分析には GPT-image-2 を、工業的な大量処理には従来モデルを使用し、両者を補完し合うのが理想的です。
- 国内からの呼び出し:APIYI (apiyi.com) を経由することで、国内から安定して接続でき、公式と 100% 同一のフィールドを利用可能です。
まとめ
GPT-image-2 による街路景観のセマンティックセグメンテーションは、従来のセマンティックセグメンテーションに取って代わるものではなく、それを補完する存在です。これは、「小規模、カスタマイズが必要、自然言語による対話が求められる、自動的に分析結果を出力したい」といった、DeepLabV3+ や PSPNet などの従来モデルでは完全に無視されてきたニーズに応えるものです。
緑視率の自動計算からカスタムカテゴリのセグメンテーションまで、GPT-image-2 はこれまで「アルゴリズムエンジニア、GPU、学習データ」が必要だった作業を、ChatGPT を使える人なら誰でも行えるレベルまで引き下げました。これは都市計画、ランドスケープデザイン、学術研究などの分野において、パラダイムシフトとも言える解放をもたらします。
ただし、その限界も理解しておく必要があります。**「1枚あたり数分かかる処理時間」「バッチ処理時のコスト管理の難しさ」「ピクセル単位の精度が SOTA(最先端モデル)に及ばない」**という3つの欠点は、このモデルが従来モデルを置き換えるのではなく、共存していく存在であることを示しています。
もし GPT-image-2 をワークフローに導入しようと考えているなら、まずは「小さく美しく」始められるシナリオ(例えば、50枚の街路景観写真の緑視率分析など)から着手し、エンドツーエンドのプロセスを確立してから、より大規模な展開を検討することをお勧めします。
✨ 最後のアドバイス: 国内の開発者や研究者の皆様には、APIYI (apiyi.com) プラットフォーム経由で gpt-image-2 を利用することをお勧めします。安定した呼び出しが可能で、フィールド構成も公式と完全に一致しており、トークン単位での透明性の高い課金が可能です。初期の探索段階では、PoC(概念実証)を完了するための無料枠も用意されており、本記事で紹介した4つのシナリオをすべてテストするのに十分な容量があります。
著者: APIYI Team
最終更新: 2026年5月2日