Claude Opus 4.7 wurde am 16. April 2026 veröffentlicht. Innerhalb von nur zwei Tagen schlug die Stimmung in der Community von „umfassendes Upgrade“ zu „selektives Upgrade“ um. Das Problem liegt nicht bei den offiziellen Benchmarks, sondern bei einer Erkenntnis, die sich immer wieder bestätigt: Opus 4.7 ist ein Upgrade speziell für „Coding-Agenten“ und für alle anderen Szenarien ein Rückschritt.
Dieser Artikel kommt direkt auf den Punkt und beantwortet die Frage, warum Claude Opus 4.7 nicht ausdauernd ist: Warum leert sich die „Gesundheitsleiste“ des Max Plan 20x-Kontingents sichtbar schneller als am Vortag? Warum ist die Performance bei langen RAG-Dokumenten schlechter als bei 4.6? Warum liefern alte Eingabeaufforderungen zunehmend schlechtere Ergebnisse?
Kernnutzen: Nach dem Lesen dieses Artikels wissen Sie genau, in welchen Szenarien Sie sofort auf 4.7 migrieren sollten, wo Sie bei 4.6 bleiben müssen und wie Sie mit drei Konfigurationsschritten Kosten und Qualität wieder in Einklang bringen.

Die Hauptgründe für die mangelnde Ausdauer von Claude Opus 4.7
Um das Gefühl der „mangelnden Ausdauer“ zu verstehen, muss man zwei Dinge unterscheiden: Modellfähigkeiten und Abrechnung/Kontingente. Opus 4.7 hat in beiden Bereichen Anpassungen vorgenommen, von denen nur eine kleine Gruppe profitiert – nur Nutzer, die tatsächlich „Agenten-Fähigkeiten“ benötigen, ziehen einen positiven Nutzen, während die meisten Alltagsnutzer höhere Kosten tragen.
Die wahren Gewinner des Opus 4.7-Upgrades
Anthropic schreibt im offiziellen Blog, dass Opus 4.7 für Szenarien entwickelt wurde, in denen „Opus 4.6 Unterstützung benötigte“: lang laufende agentische Coding-Workflows, produktionsreife Aufgaben in großen Code-Repositories mit mehreren Dateien, Computer-Use usw.
| Echte Zielgruppe | Upgrade-Umfang | Typisches Szenario |
|---|---|---|
| Claude Code Entwickler | ⭐⭐⭐⭐⭐ | Refactoring über mehrere Dateien, Agent-Schleifen |
| Cursor-Nutzer | ⭐⭐⭐⭐⭐ | Echte Coding-Aufgaben in der IDE |
| Agentic Toolchain-Entwicklung | ⭐⭐⭐⭐ | MCP-Atlas übertrifft alle Modelle |
| Visuelle Dokumentenverarbeitung | ⭐⭐⭐⭐ | 3,75 MP hochauflösende Analyse |
| Schreiben/Copywriting | ⭐ | Kaum spürbares Upgrade |
| RAG lange Dokumente | Rückschritt | MRCR 78,3 % → 32,2 % |
| Web-Recherche/BrowseComp | Rückschritt | 83,7 % → 79,3 % |
| Cybersicherheit | Rückschritt | CyberGym 73,8 % → 73,1 % |
| Kostensensitive Produktion | Rückschritt | Tokenizer-Expansion 0–35 % |
🎯 Migrationsempfehlung: Wenn Sie nicht zu den ersten vier Nutzergruppen gehören, Ihr Unternehmen aber sowohl 4.6 als auch 4.7 aufrufen muss, empfehlen wir das Routing nach Szenario über die APIYI-Plattform (apiyi.com). Diese Plattform unterstützt eine einheitliche Schnittstelle für den Aufruf der gesamten Claude-Modellreihe, um Leistungsrückschritte durch eine „Einheits-Migration“ zu vermeiden.
Drei grundlegende Gründe für die mangelnde Ausdauer von Claude Opus 4.7
Grund 1: Tokenizer-Refactoring führt zu Token-Verbrauchsexplosion
Opus 4.7 verwendet einen völlig neuen Tokenizer. Derselbe Eingabetext wird bei 4.7 in das 1,0- bis 1,35-Fache an Token zerlegt. Dieser Faktor variiert je nach Inhaltstyp deutlich:
- Rein englische Konversation: nahe 1,0×
- Chinesische Inhalte: 1,1–1,2×
- Code-Snippets: 1,15–1,25×
- JSON/strukturierte Daten: 1,2–1,35×
- Gemischte mehrsprachige Szenarien: 1,25–1,35×
Grund 2: Claude Code aktiviert standardmäßig die xhigh-Inferenzstufe
Mit der Einführung von 4.7 hat Claude Code die standardmäßige Inferenzstufe für alle Pakete von „high“ auf „xhigh“ angehoben. „xhigh“ liegt zwischen „high“ und „max“ und verbraucht bei denselben Aufgaben mehr „Denk-Token“ (thinking tokens), die direkt auf Ihre Rechnung gehen.
Grund 3: Das Max Plan 20x-Kontingent wird nach Token berechnet
Obwohl der Max Plan 20x von Anthropic nominell „20-faches Pro-Kontingent“ bedeutet, basiert das zugrunde liegende Limit auf Token und nicht auf der Anzahl der Anfragen. Wenn die Tokenizer-Expansion und die standardmäßige „xhigh“-Einstellung zusammenkommen, verbrauchen dieselben Vorgänge schneller Ihr Token-Guthaben. Mehrere Nutzer berichten: Bei der Nutzung von Opus 4.7 am 17. April schrumpfte die Kontingentleiste des Max Plan deutlich schneller als am 15. April bei der Nutzung von 4.6.
Claude Opus 4.7 – Eine Panorama-Übersicht der Szenarien
Um zu beurteilen, ob Opus 4.7 in Ihrem Anwendungsfall ein Upgrade oder ein Downgrade darstellt, sollten Sie sich nicht nur auf die offiziell ausgewählten Benchmarks verlassen. Dieser Abschnitt bewertet die Performance anhand von 7 realen Einsatzszenarien.
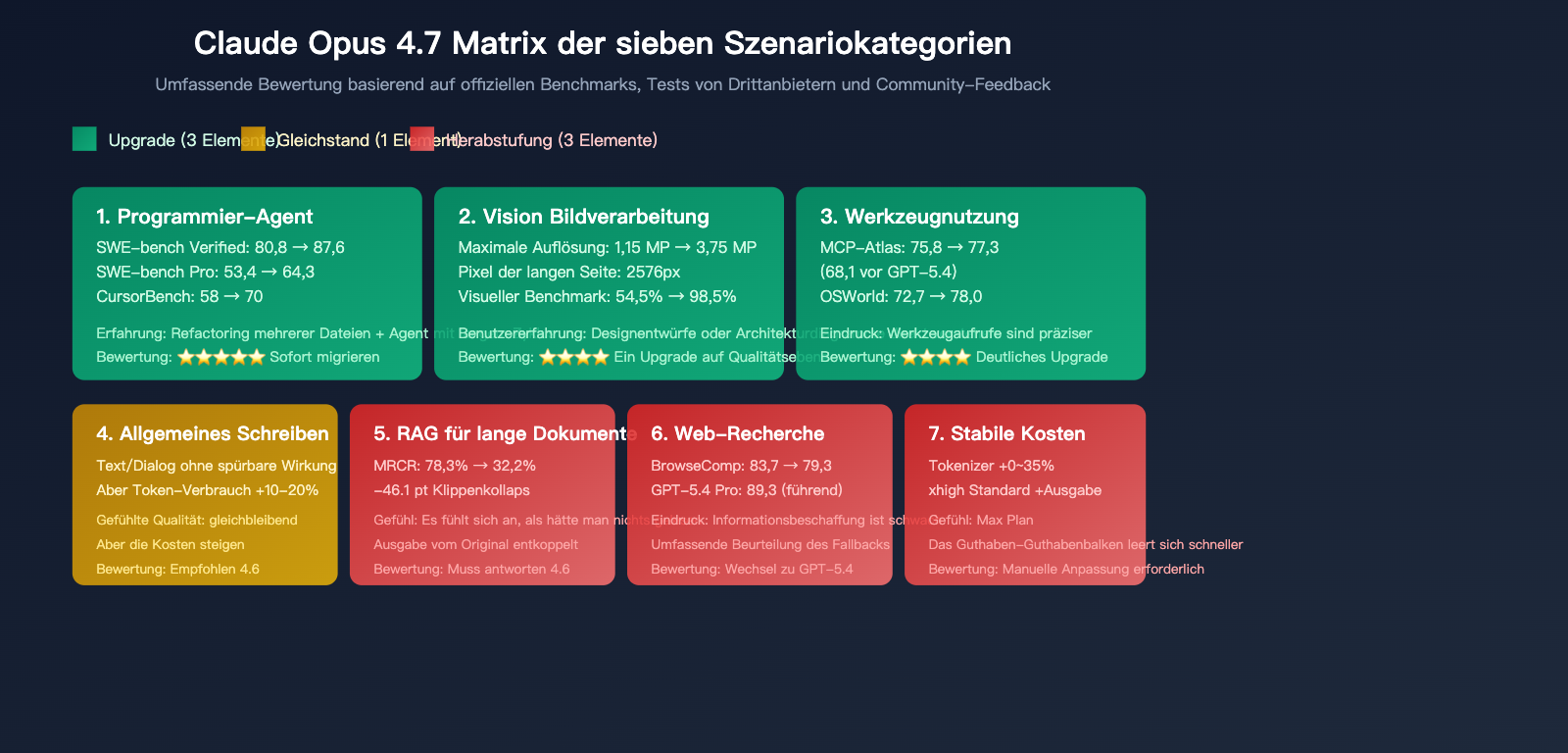
Szenario 1: Coding-Agent (deutliches Upgrade)
Das ist das Heimspiel von Opus 4.7. Zahlreiche Daten bestätigen dies:
| Coding-Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Opus 4.7 Verbesserung |
|---|---|---|---|---|
| SWE-bench Verified | 80,8 % | 87,6 % | n. v. | +6,8 pt |
| SWE-bench Pro | 53,4 % | 64,3 % | 57,7 % | +10,9 pt |
| CursorBench | 58 % | 70 % | n. v. | +12 pt |
| MCP-Atlas | 75,8 % | 77,3 % | 68,1 % | +1,5 pt |
| OSWorld-Verified | 72,7 % | 78,0 % | 75,0 % | +5,3 pt |
In 9 direkt vergleichbaren Benchmarks erzielte Opus 4.7 gegen GPT-5.4 6 Siege, 1 Unentschieden und 2 Niederlagen und holte damit die Spitzenposition für Agentic-Coding erstmals von GPT-5.4 zurück.
🚀 Empfehlung für Agent-Szenarien: Wenn Sie einen produktionsreifen Agenten aufbauen, empfehlen wir, Claude Opus 4.7 direkt über die APIYI-Plattform (apiyi.com) aufzurufen. Diese bietet eine voll kompatible Schnittstelle zur offiziellen Claude-API und unterstützt neue Funktionen wie xhigh-Modus und Task Budgets.
Szenario 2: Vision-Erkennung (qualitativer Sprung)
Vision ist ein weiterer Bereich mit einem echten Upgrade:
- Maximale Bildauflösung: 1,15 MP → 3,75 MP (3×)
- Lange Seite in Pixeln: Von Standard auf 2576 px erweitert
- Vision-Erkennungs-Benchmark: 54,5 % → 98,5 %
Für Szenarien, die das direkte Auslesen von Architekturplänen, Designentwürfen, PDF-Scans oder UI-Screenshots erfordern, ist dies eine spürbare Qualitätsverbesserung.
Szenario 3: Long-Document RAG (klares Downgrade)
Dies ist der häufigste Kritikpunkt in der Community. MRCR (Multi-Round Context Recall) ist das Standard-Benchmark für die Fähigkeit zum Abruf großer Kontexte:
- Opus 4.6: 78,3 %
- Opus 4.7: 32,2 %
- Lücke: -46,1 pt
Diese Zahl erklärt, warum viele Entwickler berichten: "Ich habe 4.7 eine 800-seitige Workflow-Dokumentation gegeben; das Modell behauptet zwar, sie gelesen zu haben, aber der generierte Inhalt hat absolut nichts mit der Dokumentation zu tun."
Wenn Ihr Kerngeschäft aus der Abfrage langer Dokumente, Vertragsanalyse oder der Prüfung großer Code-Repositories besteht, ist Opus 4.7 ein klares Downgrade. Es wird empfohlen, bei 4.6 zu bleiben.
Szenario 4: Web-Recherche und BrowseComp (leichtes Downgrade)
BrowseComp bewertet die Leistung bei Web-Rechercheaufgaben:
- Opus 4.6: 83,7 %
- Opus 4.7: 79,3 %
- GPT-5.4 Pro: 89,3 %
Für Research-Agenten, die tiefgreifendes Web-Browsing und Informationssynthese erfordern, bleibt GPT-5.4 Pro die stärkere Wahl, während Opus 4.7 sogar hinter 4.6 zurückfällt.
Szenario 5: Allgemeine Schreibaufgaben und Dialoge (kaum spürbar)
Bei alltäglichen Schreibaufgaben, dem Erstellen von Texten oder dialogbasierten Aufgaben sind die subjektiven Unterschiede zwischen Opus 4.7 und 4.6 äußerst gering. Aufgrund der Tokenizer-Aufblähung verbrauchen Ihre Dialoge jedoch 10–20 % mehr Token als zu 4.6-Zeiten.
Fazit: Für reine Schreibaufgaben ist 4.6 wirtschaftlicher, da die Leistungssteigerung von 4.7 hier kaum zur Geltung kommt.
Szenario 6: Kompatibilität alter Eingabeaufforderungen (potenzieller Rückschritt)
Die Anweisungsbefolgung von Opus 4.7 ist "buchstäblicher" – es liest nicht mehr so aktiv "zwischen den Zeilen" wie 4.6. Das bedeutet:
- Eingabeaufforderungen (Prompts), die auf impliziten Absichten basieren, liefern eine geringere Qualität.
- Bei vagen Anweisungen wie "Bitte hilf mir, das etwas besser zu schreiben" neigt 4.7 dazu, die Anweisung rein wörtlich auszuführen.
- Implizite Einschränkungen müssen in explizite umgewandelt werden (z. B. "Wortbegrenzung 500 Wörter", "muss Element X enthalten").
Wenn Sie eine umfangreiche Bibliothek an 4.6-Prompts haben, ist vor einer Migration ein systematischer Regressionstest erforderlich.
Szenario 7: Cybersicherheit (leichtes Downgrade)
CyberGym (Benchmark für das Reproduzieren von Cybersicherheitslücken):
- Opus 4.6: 73,8 %
- Opus 4.7: 73,1 %
Anthropic räumt offiziell ein, dass dies der Preis für die neuen Cybersicherheits-Schutzmechanismen ist. Für Teams in der Red-Team-Forschung oder bei Sicherheitsaudits ist dies eine kleine, aber reale Verschlechterung.
💡 Empfehlung zur Modellauswahl: Die Entscheidung zwischen Opus 4.7 und 4.6 hängt maßgeblich von Ihrem spezifischen Anwendungsfall und den Qualitätsanforderungen ab. Wir empfehlen, die Plattform APIYI (apiyi.com) für reale Testvergleiche zu nutzen, da sie eine einheitliche Schnittstelle für verschiedene führende Modelle bietet und so ein schnelles Wechseln und Validieren ermöglicht.
Praxistest zum Verbrauch des Claude Opus 4.7 Max-Plans
In diesem Abschnitt gehen wir gezielt auf die Frage ein: „Warum leert sich die Kapazitätsanzeige so viel schneller?“
Mechanismus des Kapazitätsverbrauchs im Max-Plan (20x)
Der Claude Max-Plan (20x) basiert grundlegend auf einer Token-Messung. Die Kernbeschränkungen fallen in zwei Kategorien:
- 5-Stunden-Gleitfenster-Limit: Um übermäßige Aufrufe innerhalb kurzer Zeit zu verhindern.
- Wöchentliches Nachrichten-Limit: Schutz des Gesamtkontingents.
Seit der Einführung von Opus 4.7 haben sich die absoluten Grenzwerte für diese Limits zwar nicht geändert, aber aufgrund des neuen Tokenizers und der standardmäßigen "xhigh"-Einstellung ist der durchschnittliche Token-Verbrauch pro Nachricht deutlich gestiegen.
Drei Quellen der Token-Verbrauchsausweitung
| Ursache der Ausweitung | Wirkungsbereich | Geschätzte Rate |
|---|---|---|
| Neuer Tokenizer | Alle Eingaben | 0% – 35% (je nach Inhaltstyp) |
| xhigh Standard-Stufe | Ausgaben bei Schlussfolgerungsaufgaben | 20% – 60% (relativ zu "high") |
| Gründlichere Problemlösung | Agenten-Schleifen | 10% – 30% (mehr Arbeitsschritte) |
Das reale Gefühl nach Kombination dieser drei Faktoren: Nach Abschluss derselben Aufgabe mit Claude Code verbraucht die Version 4.7 zwischen 30 % und 80 % mehr Kapazität als 4.6. Das ist die mathematische Erklärung dafür, warum sich die „Lebensenergie-Anzeige“ spürbar schneller leert.
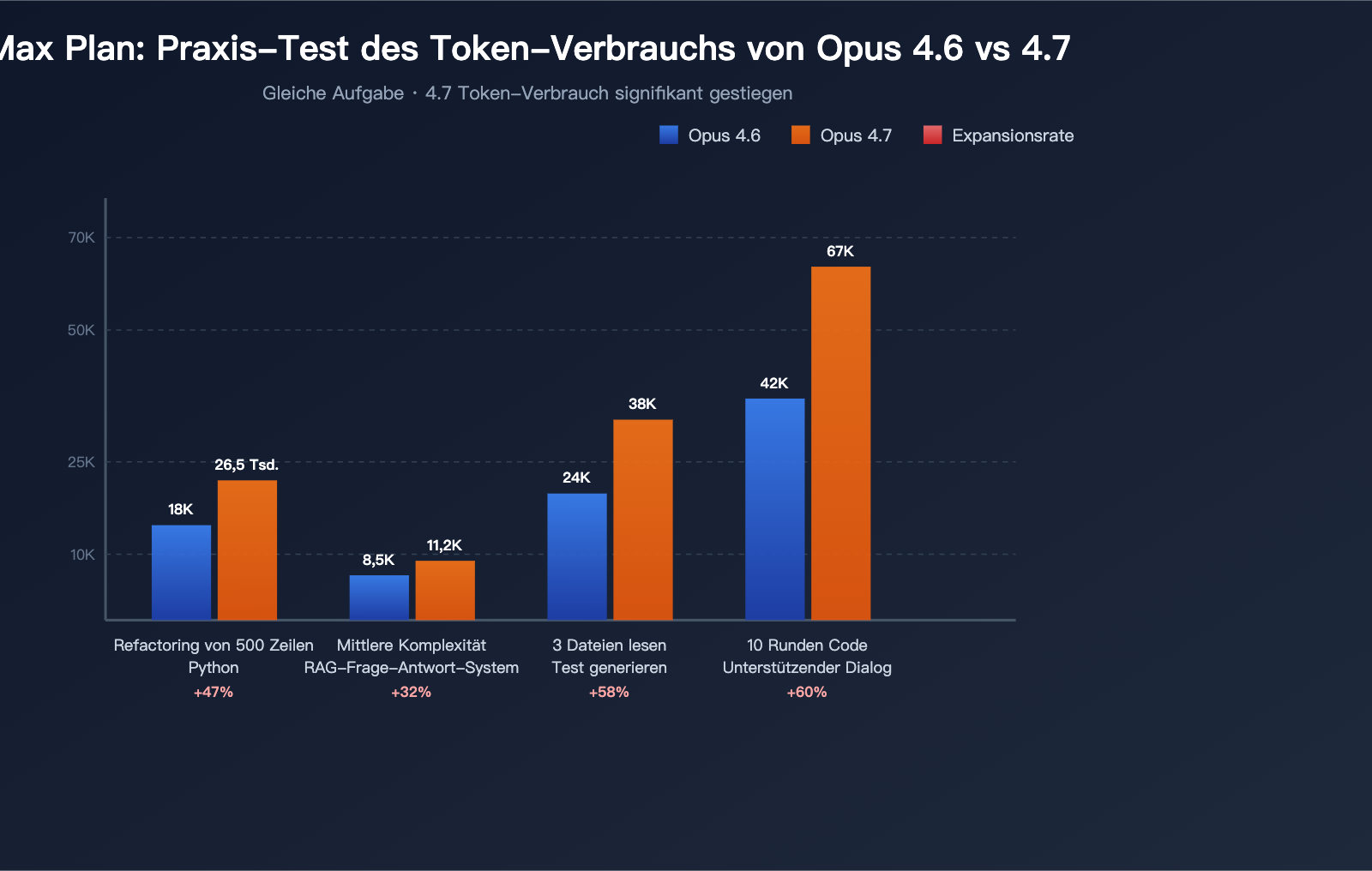
Testergebnisse (3 typische Aufgaben)
Zusammenfassung basierend auf Feedback aus der Community:
| Testaufgabe | Token-Verbrauch 4.6 | Token-Verbrauch 4.7 | Steigerungsrate |
|---|---|---|---|
| Refactoring eines 500-Zeilen-Python-Moduls | ~18.000 | ~26.500 | +47% |
| Beantwortung einer komplexen RAG-Frage | ~8.500 | ~11.200 | +32% |
| Lesen von 3 Dateien & Testgenerierung | ~24.000 | ~38.000 | +58% |
| 10 Runden Code-Assistenz im langen Chat | ~42.000 | ~67.000 | +60% |
Diese Daten verdeutlichen: Die „geringere Ergiebigkeit“ von Opus 4.7 ist keine Einbildung, sondern eine systemische Änderung, die quantifizierbar ist.
Warum behauptet Anthropic, die Preise seien „unverändert“?
Anthropic gab in der Ankündigung klar an:
- Input-Preis: 5 $ / Million Token (unverändert)
- Output-Preis: 25 $ / Million Token (unverändert)
Dies stimmt auf Ebene der Stückpreise zwar exakt, ist jedoch ein klassisches „Preis-Wording“ – der Stückpreis bleibt gleich, aber da die Anzahl der für dieselbe Aufgabe benötigten Token gestiegen ist, steigt die Endabrechnung unweigerlich. Analyseplattformen für Drittkosten wie Finout nennen dieses Phänomen: „Die wahre Kostengeschichte hinter dem unveränderten Preisschild“.
💰 Tipp zur Kostenkontrolle: Für produktive Umgebungen, in denen Token-Kosten kritisch sind, empfehlen wir dringend, vor einer Migration einen Abgleich der tatsächlichen Rechnung bei Echtzeit-Traffic über die APIYI-Plattform (apiyi.com) durchzuführen. Die Plattform unterstützt detaillierte Statistiken zu Modellaufrufen und Kostenanalysen, um die Auswirkungen der Migration auf das Budget präzise zu quantifizieren.
Drei Strategien gegen den hohen Token-Verbrauch bei Claude Opus 4.7
Falls du bereits auf 4.7 aktualisiert hast oder ein Downgrade vorerst nicht möglich ist, gibt es drei Sofortmaßnahmen, um die Kosten wieder in den Griff zu bekommen.
Maßnahme 1: „Reasoning-Effort“ manuell auf medium oder high senken
Dass Claude Code xhigh als Standard setzt, ist für „hochkomplexe Programmieraufgaben“ gedacht. Für die meisten alltäglichen Aufgaben sind medium oder high völlig ausreichend.
Dies lässt sich direkt im API-Aufruf festlegen:
import openai
client = openai.OpenAI(
api_key="DEIN_API_SCHLÜSSEL",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refactore diesen Code"}],
extra_headers={
"reasoning-effort": "medium"
}
)
Token-Verbrauch im Vergleich: Die verschiedenen Effort-Stufen
import time
import openai
client = openai.OpenAI(
api_key="DEIN_API_SCHLÜSSEL",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
Bitte analysiere den folgenden Code auf Performance-Probleme und gib Optimierungsvorschläge.
(Hier 200 Zeilen Python-Code einfügen)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
Empfehlung: Für die tägliche Code-Unterstützung reicht high, für einfache Anfragen medium. Nutze xhigh nur bei extrem komplexen Refactoring-Aufgaben über mehrere Dateien hinweg.
Maßnahme 2: Modell-Routing je nach Szenario
Du musst nicht alles auf 4.7 umstellen. Eine effiziente Routing-Strategie sieht so aus:
| Anwendungsszenario | Empfohlenes Modell | Grund |
|---|---|---|
| Agentic Coding (multimodale Dateien) | Opus 4.7 (xhigh) | Stärke der Agenten |
| Single-File Code-Generierung | Opus 4.7 (high) | Deutlicher Mehrwert |
| Hochauflösende Bildanalyse | Opus 4.7 (high) | Qualitativer Sprung bei der Sicht |
| Langdokument-RAG | Opus 4.6 | Vermeidung von MRCR-Einbrüchen |
| Web-Research-Agent | GPT-5.4 Pro | Führend bei BrowseComp |
| Standard-Texte / Copywriting | Opus 4.6 oder Sonnet | Günstigerer Tokenizer |
| Einfache Unterhaltungen | Haiku / Sonnet | Höchstes Preis-Leistungs-Verhältnis |
Maßnahme 3: Aktivierung von „Task Budgets“ zur Limitierung des Verbrauchs
Die neu eingeführten Task Budgets (Public Beta) für Opus 4.7 sind ideal, um die Kosten der Agenten-Loops zu kontrollieren:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Schließe die gesamte Refactoring-Aufgabe ab"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
Das Modell erkennt in jeder Antwortrunde das verbleibende Budget und passt seine Strategie automatisch an – bei knappem Budget wird der Fokus auf Kernaufgaben gelegt, bei ausreichendem Budget geht es tiefer in die Details.
🎯 Fazit: Für Teams, die auf ihr Token-Budget achten, empfiehlt sich eine zentrale Verwaltung über die Plattform APIYI (apiyi.com). Sie bietet Echtzeit-Überwachung und intelligentes Modell-Routing, um den "hohen Verbrauch" in eine kontrollierte Kostenkurve zu verwandeln.
Claude Opus 4.7 vs. GPT-5.4 xhigh im Vergleich
In Anwender-Feedbacks heißt es oft: „In meinen Tests scheint Opus 4.7 immer noch nicht ganz an GPT-5.4 xhigh heranzureichen.“ Das hängt stark vom jeweiligen Anwendungsfall ab.

Die 9 Benchmarks im direkten Vergleich
| Benchmark | Opus 4.7 | GPT-5.4 | Gewinner |
|---|---|---|---|
| SWE-bench Pro | 64,3% | 57,7% | Opus 4.7 (+6,6) |
| MCP-Atlas | 77,3% | 68,1% | Opus 4.7 (+9,2) |
| CyberGym | — | — | Opus 4.7 (+6,8) |
| OSWorld-Verified | 78,0% | 75,0% | Opus 4.7 (+3,0) |
| GDPVal-AA (Unternehmenswissen) | Elo 1753 | Elo 1674 | Opus 4.7 |
| Visuelle Erkennung | 98,5% | — | Opus 4.7 |
| BrowseComp (Web-Recherche) | 79,3% | 89,3% | GPT-5.4 Pro (+10,0) |
| Langkontext-RAG | 32,2% | kein Abbruch | GPT-5.4 |
| Token-Kosten | 1,0–1,35× | stabil | GPT-5.4 |
Opus 4.7 gewinnt 6 von 9 Kategorien, doch je nach Schwerpunkt verschiebt sich das Bild:
- Bei Web-Recherche-lastigen Szenarien (z. B. Research Agent, Browser-Automatisierung) liegt GPT-5.4 xhigh bei BrowseComp um 10 Prozentpunkte vorn.
- Bei RAG-Aufgaben mit langen Dokumenten leidet GPT-5.4 nicht unter MRCR-Einbrüchen.
- Bei stabileren Token-Kosten punktet GPT-5.4, da der Tokenizer unverändert blieb.
Entscheidungsmatrix zur Modellauswahl
| Deine Priorität | Primäres Modell | Sekundäres Modell |
|---|---|---|
| Multimodales Coding (Agenten) | Opus 4.7 xhigh | Opus 4.6 |
| Coding im IDE | Opus 4.7 high | GPT-5.4 |
| Research Agent (Web) | GPT-5.4 Pro | Opus 4.7 |
| Unternehmenswissen | Opus 4.7 | GPT-5.4 |
| RAG (Langdokumente) | Opus 4.6 | GPT-5.4 |
| Hochauflösende Bildanalyse | Opus 4.7 | Gemini 3.1 Pro |
| Kostensensitivität | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 Multi-Modell-Empfehlung: Moderne KI-Anwendungen benötigen selten nur ein einziges Modell. Über die Plattform APIYI (apiyi.com) kannst du bequem auf Claude, GPT und Gemini zugreifen und je nach Anwendungsfall intelligent routen. Ein einziger API-Schlüssel für alle führenden Modelle minimiert den Implementierungsaufwand massiv.
FAQ zur "geringeren Effizienz" von Claude Opus 4.7
Q1: Ist Claude Opus 4.7 wirklich weniger effizient als 4.6?
Ja, aber man muss diese "geringere Effizienz" in zwei Dimensionen betrachten:
-
Kontingente: Definitiv weniger effizient. Eine Tokenizer-Expansion von 0–35 % sowie die Standardeinstellung "xhigh" bei Claude Code führen zu einem um 30–80 % höheren Token-Verbrauch. Nutzer mit einem Max Plan 20x berichten in der Praxis üblicherweise, dass ihr Kontingent deutlich schneller aufgebraucht ist.
-
Leistungsfähigkeit: Szenarioabhängig. Bei Coding-Agenten, Vision-Aufgaben und Tool-Use ist das Modell eindeutig stärker; bei RAG mit langen Dokumenten, Web-Recherchen und allgemeinem Schreiben ist es schwächer oder gleichwertig.
Wenn Sie diese speziellen Agenten-Aufgaben nicht nutzen, ist Opus 4.7 für Sie schlichtweg "teurer".
Q2: Warum sagt Anthropic, der „Preis habe sich nicht geändert“, aber meine Rechnung ist höher?
Offiziell wurde nur der Stückpreis beibehalten: 5 $ pro Million Eingabe-Token, 25 $ pro Million Ausgabe-Token. Da der neue Tokenizer von Opus 4.7 jedoch für denselben Text 1,0–1,35-mal mehr Token verbraucht und die xhigh-Ausgabe die Token-Anzahl zusätzlich aufbläht, ist eine Rechnung, die 20–50 % über dem Niveau von 4.6 liegt, ein häufiges Ergebnis.
Um die Kosten zu kontrollieren, können Sie über die Plattform APIYI (apiyi.com) echte Traffic-Vergleichstests durchführen. Die Plattform unterstützt parallele Aufrufe der gesamten Claude-Serie und bietet detaillierte Statistiken zum Modellaufruf.
Q3: Das Max Plan 20x Kontingent schwindet schnell – was kann ich tun?
Drei sofort umsetzbare Maßnahmen:
- Effort auf "high" oder "medium" senken: Deaktivieren Sie manuell die xhigh-Standardeinstellung in den Claude Code-Einstellungen; für tägliche Aufgaben reicht "high" völlig aus.
- Unnötige Denkschritte deaktivieren: Bei einfachen Fragen in langen Dialogen sollten Sie das Modell explizit anweisen, tiefgründige Schlussfolgerungen zu überspringen.
- Für Nicht-Agenten-Aufgaben zu Sonnet oder Opus 4.6 wechseln: Schreiben, einfache Fragen und Übersetzungen erfordern kein Opus 4.7.
Diese drei Schritte zusammen können den Verbrauch Ihres Max Plan-Kontingents wieder auf das Niveau von 4.6 oder sogar darunter senken.
Q4: Ich bin bereits auf Opus 4.7 migriert – lohnt sich ein Downgrade auf 4.6?
Das hängt von Ihrem Kern-Workflow ab:
- Hauptfokus auf Multi-File-Agent-Coding: Führen Sie kein Downgrade durch, 4.7 ist hier wirklich stärker.
- Hauptfokus auf RAG mit langen Dokumenten / Vertragsanalyse: Sofortiges Downgrade auf 4.6, da der MRCR-Wert hier stark einbricht.
- Gemischte Szenarien: Sie müssen nicht komplett zurückkehren, sondern können je nach Szenario routen – schwere Agenten-Aufgaben mit 4.7, alles andere mit 4.6 oder Sonnet.
Ein Downgrade bei API-Aufrufen ist einfach: Ändern Sie den model-Parameter von claude-opus-4-7 zurück auf claude-opus-4-6.
Q5: Ist Opus 4.7 in allen Szenarien stärker als GPT-5.4 xhigh?
Nein. Offizielle Daten zeigen, dass Opus 4.7 in 9 direkt vergleichbaren Benchmarks 6 Siege, 1 Unentschieden und 2 Niederlagen erzielt hat. Die beiden Niederlagen betreffen jedoch kritische Bereiche:
- BrowseComp (Web-Recherche): GPT-5.4 Pro 89,3 % vs. Opus 4.7 79,3 %.
- Long-Context RAG: Bei GPT-5.4 tritt kein vergleichbarer MRCR-Einbruch auf.
Daher ist die Aussage von Nutzern, dass "Opus 4.7 in meinen Tests immer noch nicht an GPT-5.4 xhigh heranreicht", durchaus glaubwürdig – vorausgesetzt, Ihr Hauptfokus liegt auf Web-Recherchen oder langen Dokumenten.
Über die Plattform APIYI (apiyi.com) können Sie im selben Projekt gleichzeitig Claude und GPT aufrufen und je nach Szenario routen – das ist derzeit die pragmatischste Vorgehensweise.
Q6: Meine alten Eingabeaufforderungen liefern mit Opus 4.7 schlechtere Ergebnisse – was tun?
Dies ist ein Nebeneffekt der "wörtlicheren" Befolgung von Anweisungen bei 4.7. Prinzipien für die Überarbeitung:
- Implizite Absichten in explizite Einschränkungen umwandeln: Statt "Schreibe professioneller" → "Verwende zwingend Fachterminologie und vermeide umgangssprachliche Ausdrücke".
- Vage Einschränkungen in harte Zahlenwerte umwandeln: Statt "Nicht zu lang" → "Auf maximal 300 Wörter begrenzen".
- Gegenbeispiele hinzufügen: Geben Sie dem Modell vor, welche Ausgaben inakzeptabel sind.
Der Arbeitsaufwand ist nicht zu unterschätzen. Für große Bibliotheken an Eingabeaufforderungen empfiehlt es sich, zuerst A/B-Tests durchzuführen, um zu identifizieren, welche Eingabeaufforderungen angepasst werden müssen.
Zusammenfassung der Vor- und Nachteile von Claude Opus 4.7
Echte Vorteile (Wo es glänzt)
- Sprung bei Coding-Agent-Fähigkeiten: SWE-bench Pro 64,3 %, CursorBench 70 % – übertrifft GPT-5.4.
- Qualitativer Sprung bei Vision: 3,75 MP hohe Auflösung, 98,5 % bei visuellen Benchmarks.
- Stärkste MCP-Atlas-Toolchain: 77,3 %, führt vor allen anderen öffentlichen Modellen.
- Präzisere Befolgung von Anweisungen: Bei Eingabeaufforderungen mit vollständigen Einschränkungen ist die Ausgabe besser steuerbar.
- Task Budgets ermöglichen Kostenkontrolle bei Agenten.
Echte Einschränkungen (Wo es schwächelt)
- Tokenizer-Expansion um 0–35 %: Das Marketing zum Preis verschleiert den tatsächlichen Kostenanstieg.
- xhigh-Standardeinstellung erhöht Token-Verbrauch: Max Plan 20x Kontingent wird spürbar knapper.
- MRCR-Einbruch bei langem Kontext: Von 78,3 % auf 32,2 % – RAG mit langen Dokumenten ist kaum nutzbar.
- Rückschritt bei BrowseComp: Unterliegt GPT-5.4 Pro bei Web-Recherchen.
- Leichter Rückschritt bei CyberGym: Leichte Einbußen bei sicherheitsrelevanten Aufgaben.
- Kompatibilitätsprobleme mit alten Eingabeaufforderungen: Eingabeaufforderungen, die auf impliziten Absichten basieren, müssen neu geschrieben werden.
Zusammenfassung
Claude Opus 4.7 ist ein typisches Beispiel für ein „spezialisiertes“ Upgrade. Alle Verbesserungen zielen auf ein einziges Ziel ab: Anthropic soll im Bereich des agentenbasierten Codings (Agentic Coding) wieder die Spitzenposition einnehmen. Dieses Ziel wurde erreicht, allerdings zu einem Preis: Nutzer in „allen anderen Szenarien“ zahlen nun indirekt für dieses Upgrade mit.
Wenn Sie Agenten entwickeln oder ein intensiver Nutzer von Claude Code oder Cursor sind, lohnt sich der sofortige Umstieg auf Opus 4.7. Wenn Ihr Schwerpunkt jedoch auf Schreiben, RAG, Web-Recherche oder kostensensitiver Produktion liegt, empfehlen wir:
- Behalten Sie Opus 4.6 für Nicht-Agenten-Aufgaben bei.
- Senken Sie den Standard-Effort von Claude Code von „xhigh“ auf „high“.
- Nutzen Sie modellbasiertes Routing je nach Szenario, anstatt pauschal alles zu aktualisieren.
„Der Preis bleibt gleich“ ist nie die ganze Geschichte. Die wahren Kosten verbergen sich im Tokenizer, den Standardeinstellungen und der Inferenz-Tiefe. Opus 4.7 ist nicht schlecht, aber es ist kein Allrounder – wenn Sie das verstehen, können Sie das Modell gezielt für den richtigen Mehrwert einsetzen.
Wir empfehlen die Verwaltung Ihrer Claude-Modellaufrufe über die Plattform APIYI (apiyi.com). Sie bietet intelligentes Multi-Modell-Routing, Echtzeit-Überwachung des Guthabens und eine vollständig kompatible API – das pragmatischste Werkzeug, um die „Spezialisierung“ von Opus 4.7 effizient zu handhaben.
Referenzen
-
Offizielle Ankündigung von Anthropic: Vorstellung von Claude Opus 4.7
- Link:
anthropic.com/news/claude-opus-4-7 - Hinweis: Offizielle Definition der Fähigkeiten und empfohlene Einsatzszenarien.
- Link:
-
Offizielle Dokumentation von Anthropic: Migrationsleitfaden für Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Hinweis: Änderungen am Tokenizer und Erläuterung von „xhigh“.
- Link:
-
Finout Kostenanalyse: Die wahren Kosten hinter dem unveränderten Preisschild
- Link:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - Hinweis: Kostenanalyse durch Dritte und Aufschlüsselung der Abrechnung.
- Link:
-
Artificial Analysis Vergleich: GPT-5.4 xhigh vs. Claude Opus im Vergleich
- Link:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - Hinweis: Unabhängige Vergleichsdaten für verschiedene Modelle.
- Link:
-
GitHub Issue #23706: Feedback zum Token-Verbrauch bei Max-Plan-Nutzern
- Link:
github.com/anthropics/claude-code/issues/23706 - Hinweis: Erfahrungsberichte aus erster Hand von Claude Code Max-Plan-Nutzern.
- Link:
Autor: APIYI Technik-Team
Veröffentlichungsdatum: 18.04.2026
Betroffene Modelle: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
Technischer Austausch: Holen Sie sich Testguthaben für verschiedene Modelle über APIYI (apiyi.com) und testen Sie selbst die realen Unterschiede in verschiedenen Szenarien.