Claude Opus 4.7 wurde am 16. April 2026 offiziell veröffentlicht und sorgte bereits einen Tag nach dem Start für kontroverse Diskussionen in der Community. Obwohl offizielle Benchmarks behaupten, dass es in 12 von 14 Tests besser abschneidet als die Version 4.6, beklagen zahlreiche Entwickler auf GitHub und X eine schlechtere Performance. Manche bezeichnen es sogar spöttisch als "eine als neue Version getarnte, überarbeitete 4.6".
Basierend auf offiziellen Anthropic-Daten, unabhängigen Tests und direktem Community-Feedback analysieren wir Claude Opus 4.7 tiefgehend in 8 Dimensionen: Programmierfähigkeit, visuelle Erkennung, langes Kontextfenster, Tokenizer-Änderungen, Task Budgets und mehr. So können Sie entscheiden, ob sich ein sofortiger Wechsel lohnt.
Kernnutzen: Nach diesem Artikel wissen Sie, ob Claude Opus 4.7 für Ihre Geschäftsanwendungsfälle ein Upgrade oder ein Downgrade darstellt und wie Sie Migrationsrisiken minimieren.

Hintergrund und Kerninfos zur Veröffentlichung von Claude Opus 4.7
Claude Opus 4.7 ist das Flaggschiff-Modell, das Anthropic am 16. April 2026 eingeführt hat. Es übernimmt die Preisstruktur von 5 $/25 $ pro Million Token von Opus 4.6 und setzt neue Rekorde in mehreren Benchmarks. Gleichzeitig geht es jedoch mit systemischen Änderungen einher, darunter eine Tokenizer-Umstrukturierung, ein deutlicher Rückgang bei den MRCR-Benchmarks für lange Kontexte und eine neue "xhigh"-Inferenzstufe. Diese Änderungen wirken sich direkt auf die Performance im realen Betrieb aus.
Claude Opus 4.7 auf einen Blick
| Informationspunkt | Details |
|---|---|
| Veröffentlichungsdatum | 16. April 2026 |
| Herausgeber | Anthropic |
| Eingabepreis | 5 $ / Million Token (identisch zu 4.6) |
| Ausgabepreis | 25 $ / Million Token (identisch zu 4.6) |
| Kontextfenster | 1M Token (Standard-Preisgestaltung) |
| Maximale Bildauflösung | 2576px lange Seite / 3,75 Megapixel |
| Neue Inferenzstufe | xhigh (zwischen high und max) |
| Neue experimentelle Funktion | Task Budgets (in der öffentlichen Beta) |
| Verfügbare Kanäle | Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry |
🎯 Technischer Hinweis: Bevor Sie offiziell auf Claude Opus 4.7 umsteigen, empfehlen wir, über die APIYI-Plattform (apiyi.com) parallele Vergleichstests mit 4.6 und 4.7 durchzuführen. Die Plattform bietet eine einheitliche Schnittstelle, bei der Sie nur den Modellparameter ändern müssen, um Leistungsunterschiede schnell zu identifizieren.
Die Kernverbesserungen von Claude Opus 4.7
Die offiziellen Verbesserungen von Anthropic konzentrieren sich hauptsächlich auf vier Bereiche:
- Signifikant verbesserte Software-Engineering-Fähigkeiten: SWE-bench Verified stieg von 80,8 % auf 87,6 %, SWE-bench Pro von 53,4 % auf 64,3 %.
- Sprung bei der visuellen Erkennung: Unterstützung für hochauflösende Bilder mit 3,75 Megapixeln, visuelle Benchmarks stiegen von 54,5 % auf 98,5 %.
- Stärkung der Agentenfähigkeiten: MCP-Atlas-Benchmark erzielte den größten Zuwachs in einer Einzelkategorie, eine Steigerung um 13 Punkte ohne Tools.
- Präzisere Befolgung von Anweisungen: Die Verarbeitung vager Anweisungen ist robuster und die Ausführung gründlicher.
Das tatsächliche Feedback aus der Community zeichnet jedoch ein etwas anderes Bild.
Detaillierte Analyse der Kernfunktionen von Claude Opus 4.7
Die Änderungen an den Kernfunktionen von Claude Opus 4.7 betreffen nicht nur die Modellleistung, sondern auch wichtige Anpassungen bei der Bereitstellung. Das Verständnis dieser Änderungen ist entscheidend für eine korrekte Bewertung der Modellleistung.

Die vier systemischen Änderungen von Claude Opus 4.7
| Funktionsmodul | 4.6 Leistung | 4.7 Änderung | Geschäftsauswirkung |
|---|---|---|---|
| Tokenizer | Ursprüngliche Token-Segmentierung | 1,0–1,35× Token für denselben Text | Tatsächliche Rechnung kann um 35 % steigen |
| Inferenzstufen | low / medium / high / max | Neu: xhigh (Standard bei Claude Code) | Genauere Abstimmung von Tiefe und Latenz |
| Task Budgets | Keine | Public Beta, globale Token-Budgetkontrolle | Agent-Zykluskosten kontrollierbar |
| Visuelle Eingabe | ca. 1,15 Mio. Pixel | ca. 3,75 Mio. Pixel (3×) | Verarbeitung hochauflösender Screenshots/Pläne |
| Langes Kontext-MRCR | 78,3 % | 32,2 % | Deutlicher Rückgang bei Abruf langer Dokumente |
| SWE-bench Verified | 80,8 % | 87,6 % | Deutliche Verbesserung bei echten Code-Aufgaben |
Die versteckten Kosten der Tokenizer-Änderung
Die wichtigste, aber am meisten übersehene Änderung bei Claude Opus 4.7 ist die Neugestaltung des Tokenizers. Die offizielle Dokumentation stellt klar: Derselbe Eingabetext wird in 4.7 auf die 1,0- bis 1,35-fache Token-Anzahl im Vergleich zu 4.6 abgebildet. Das bedeutet:
- Die Länge Ihrer Eingabeaufforderung bleibt gleich, aber die Abrechnung der Input-Token kann um 35 % höher ausfallen.
- Bei den Inferenzstufen „xhigh“ oder „max“ können auch die Output-Token deutlich ansteigen.
- Das bisher auf Basis von 4.6 festgelegte
max_tokens-Limit muss umfassend neu getestet werden. - Die Logik zur Token-Schätzung auf Client-Seite basierend auf der Zeichenanzahl muss neu geschrieben werden.
💰 Kostenoptimierung: Für produktive Umgebungen, die empfindlich auf Token-Kosten reagieren, empfehlen wir dringend, vor der Migration zu Claude Opus 4.7 einen Rechnungsvergleich mit echtem Traffic auf der APIYI-Plattform (apiyi.com) durchzuführen. Die Plattform unterstützt flexible Abrechnungsabfragen und Echtzeitüberwachung, um die durch die Migration verursachten tatsächlichen Kostensteigerungen zu quantifizieren.
Strategien zur Nutzung der xhigh-Inferenzstufe
„xhigh“ ist eine neue Inferenzstufe in Opus 4.7, die zwischen „high“ und „max“ angesiedelt ist. Anthropic empfiehlt, für Coding- und Agenten-Aufgaben standardmäßig „xhigh“ zu verwenden; dies ist auch die Standardstufe für alle Claude Code-Tarife.
Geeignete Szenarien für die verschiedenen Inferenzstufen:
| Inferenzstufe | Geeignete Aufgaben | Latenz | Empfohlener Einsatzbereich |
|---|---|---|---|
low |
Einfache Fragen, Formatkonvertierung | Niedrigste | Hohe Parallelität, Aufgaben mit geringer Komplexität |
medium |
Allgemeine Code-Erzeugung | Niedrig | Reguläre Entwicklungsunterstützung |
high |
Komplexer Code, technisches Design | Mittel | Reguläre Agenten-Aufgaben |
xhigh |
Schwieriges Debugging,大規模 Umgestaltung | Mittel bis Hoch | Empfohlen: Coding-Szenarien wie Claude Code |
max |
Extrem komplexe Schlussfolgerungen | Hoch | Forschung, zeitunkritische Aufgaben |
Task Budgets: Das Ende der unkontrollierten Agenten-Zykluskosten
Task Budgets sind eine in Opus 4.7 eingeführte Beta-Funktion, die das langjährige Problem löst, dass Agenten-Zyklen den gesamten Token-Verbrauch nur schwer kontrollieren können. Funktionsweise:
- Entwickler legen vor dem Start eines Agenten-Zyklus ein globales Token-Budget fest.
- Das Modell kann in jeder Antwortrunde den Countdown des Budgets sehen.
- Das Modell passt seine „Denktiefe“ und die Anzahl der Werkzeugaufrufe automatisch an das verbleibende Budget an.
- Bevor das Budget erschöpft ist, priorisiert das Modell den Abschluss der Kernaufgaben und beendet den Prozess elegant.
Diese Funktion, in Kombination mit der neuen UI-Kopfzeile redact-thinking-2026-02-12, stellt eine wesentliche Verbesserung für die Kostenverwaltung von Agenten dar.
Panorama der Messergebnisse von Claude Opus 4.7
Dieser Abschnitt ist das Herzstück dieses Artikels. Wir haben die offiziellen Benchmarks von Anthropic, unabhängige Bewertungen Dritter sowie Daten aus Community-Tests zusammengefasst, um den tatsächlichen Unterschied zwischen Claude Opus 4.7 und 4.6 aufzuzeigen.
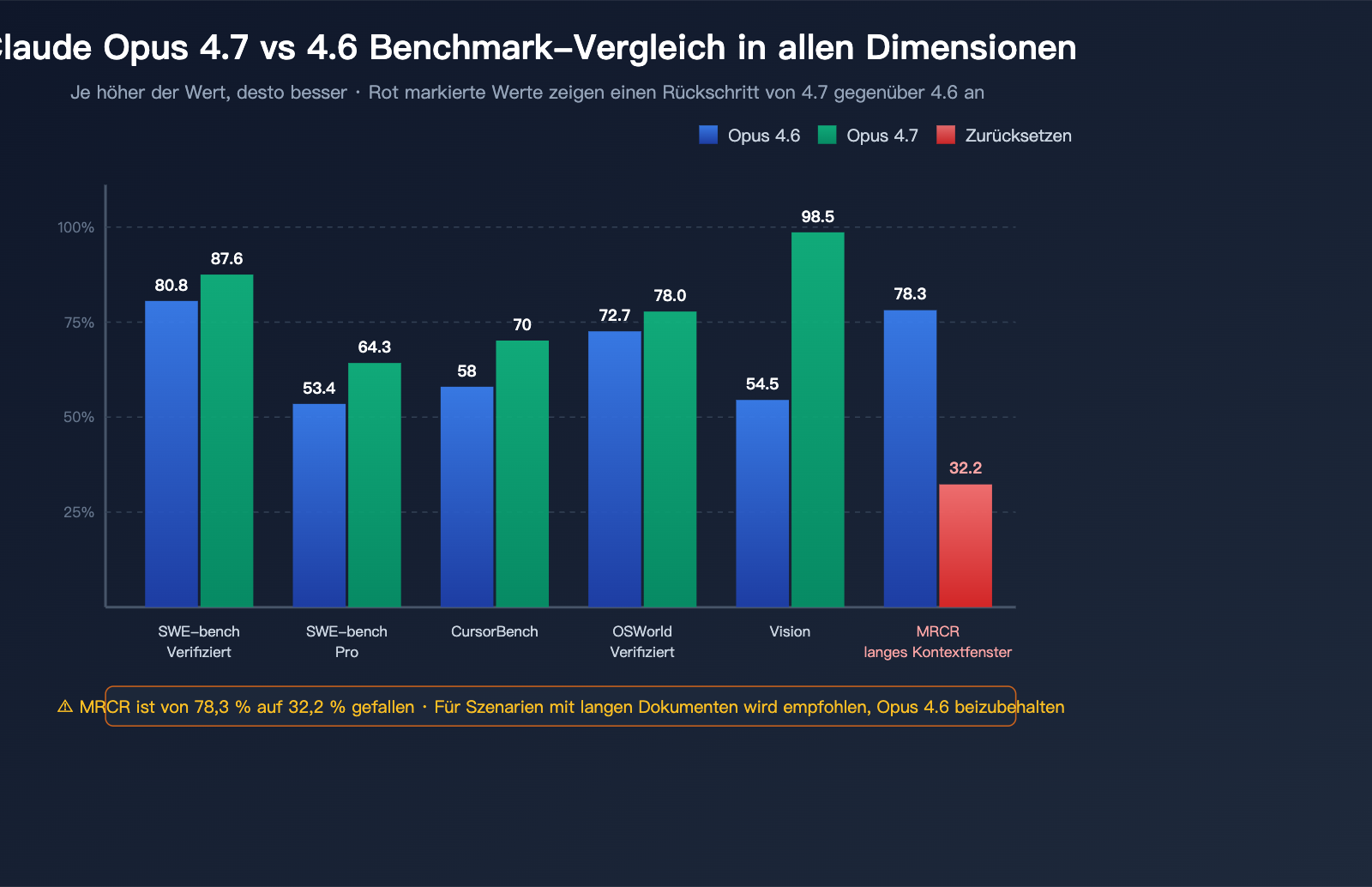
Coding-Benchmark: 4.7 führt auf ganzer Linie
| Coding-Benchmark | Opus 4.6 | Opus 4.7 | Steigerung | Erläuterung |
|---|---|---|---|---|
| SWE-bench Verified | 80,8 % | 87,6 % | +6,8 pt | Echte GitHub-Issue-Korrekturaufgaben |
| SWE-bench Pro | 53,4 % | 64,3 % | +10,9 pt | Schwierigere, mehrsprachige Variante |
| CursorBench | 58 % | 70 % | +12 pt | Echte Coding-Aufgaben in der IDE |
| OSWorld-Verified | 72,7 % | 78,0 % | +5,3 pt | Desktop-Bedienung & Computernutzung |
| MCP-Atlas (ohne Tools) | — | +13 pt | Höchste Einzelsteigerung | Agentische Toolchain-Aufgaben |
| MCP-Atlas (mit Tools) | — | +6 pt | Deutliche Verbesserung | Präzision bei Tool-Aufrufen |
Im Bereich Coding ist Claude Opus 4.7 zweifellos das leistungsfähigste öffentliche Großes Sprachmodell des zweiten Quartals 2026. Mit einem Ergebnis von 64,3 % im SWE-bench Pro erobert es die Spitzenposition bei agentischen Coding-Benchmarks zurück.
🚀 Schnellstart: Wenn Sie die Coding-Fähigkeiten von Claude Opus 4.7 sofort ausprobieren möchten, können Sie diese über die APIYI-Plattform (apiyi.com) direkt nutzen. Die Plattform bietet eine Schnittstelle, die vollständig mit der offiziellen Claude-API kompatibel ist, das einheitliche OpenAI-SDK-Format unterstützt und somit den Migrationsaufwand minimiert.
Benchmarks für Vision und langes Kontextfenster: Ein gespaltenes Bild
| Benchmark | Opus 4.6 | Opus 4.7 | Veränderung | Bewertung |
|---|---|---|---|---|
| Visuelle Erkennung (allgemein) | 54,5 % | 98,5 % | +44 pt | Nahezu ein Quantensprung |
| Maximale Bildauflösung | ~1,15 MP | ~3,75 MP | 3× | Kann 4K-Screenshots verarbeiten |
| MRCR langes Kontextfenster | 78,3 % | 32,2 % | -46,1 pt | Schwerer Rückschritt |
MRCR (Multi-Round Context Recall) ist der Standard-Benchmark zur Bewertung der Abruffähigkeit bei langem Kontextfenster. Opus 4.7 ist hier von 78,3 % auf 32,2 % abgestürzt – das ist keine normale Schwankung, sondern ein struktureller Rückschritt.
Diese Zahl erklärt, warum sich viele Entwickler beschweren: "Man füttert das Modell mit 800 Zeilen Workflow-Dokumentation, es behauptet, sie gelesen zu haben, aber die Ausgabe hat absolut nichts mit dem Dokument zu tun."
Benchmarks vs. echte Erfahrung: Warum ist die Bewertung so gespalten?
Gute Benchmark-Ergebnisse bedeuten nicht automatisch eine bessere Leistung im realen Betrieb. Opus 4.7 stößt in der Community auf viel negatives Feedback, unter anderem aufgrund von:
- Tokenizer-Aufblähung: Der Token-Verbrauch steigt bei gleichen Aufgaben, aber die Leistungssteigerung rechtfertigt nicht immer die Kosten.
- Zu wörtliche Befolgung von Anweisungen: Während 4.6 die "Absicht verstand", führt 4.7 Anweisungen strikt wörtlich aus, wodurch bestehende Eingabeaufforderungen (Prompts) möglicherweise nicht mehr funktionieren.
- MRCR-Einbruch: Die Fähigkeit zum Abruf aus langen Dokumenten hat nachgelassen, was bei großen Code-Repositories oder Vertragsdokumenten zu deutlichen Problemen führt.
- Claude Code Fehlalarme: Einige Entwickler berichten, dass 4.7 normalen Code fälschlicherweise als bösartig einstuft und die Bearbeitung verweigert.
💡 Empfehlung: Ob Sie Claude Opus 4.7 wählen oder bei 4.6 bleiben sollten, hängt stark von Ihrem spezifischen Anwendungsfall ab. Wir empfehlen, beide Versionen über die APIYI-Plattform (apiyi.com) einem parallelen Belastungstest zu unterziehen, bevor Sie eine Entscheidung treffen. Die Plattform unterstützt einheitliche Schnittstellen für mehrere Modelle, was den schnellen Vergleich und Wechsel erleichtert.
Claude Opus 4.7 – Echte Nutzungserfahrungen
Abseits der Benchmark-Daten liefern Anthropic und die Entwickler-Community grundverschiedene Rückmeldungen zur Leistung von Opus 4.7 im realen Arbeitsablauf.
Offizielle Position von Anthropic
In der Ankündigung hebt Anthropic vier Kernverbesserungen von Opus 4.7 gegenüber 4.6 hervor:
- Stärkere Performance in technischen Workflows: Nutzer können komplexe Aufgaben, die früher eine strenge Überwachung erforderten, getrost 4.7 überlassen.
- Bessere Handhabung vager Probleme: Höhere Robustheit bei unpräzise definierten Anforderungen.
- Gründlichere Problemlösung: Das Modell bricht Aufgaben nicht mehr vorzeitig ab.
- Präzisere Befolgung von Anweisungen: Strengere Einhaltung von Detailvorgaben.
Boris Cherny, Leiter von Claude Code, äußerte nach der Veröffentlichung, dass Opus 4.7 „intelligenter, fähiger als Agent und präziser“ als 4.6 sei, räumte jedoch ein, dass eine Eingewöhnungszeit nötig ist, um die neuen Fähigkeiten voll auszuschöpfen.
Echtes Feedback aus der Entwickler-Community
Auf Plattformen wie GitHub, Hacker News und X fällt das Feedback der Entwickler deutlich negativer aus:
Beschwerde 1: Token-Verbrauch explodiert
Aufgrund des neuen Tokenizers wird derselbe Input in Opus 4.7 in deutlich mehr Tokens zerlegt. Zusammen mit dem erhöhten Output-Token-Verbrauch bei der Einstellung „xhigh“ berichten einige Nutzer von einer Kostensteigerung um bis zu 40 %. Dies wird scherzhaft als „KI-Schrumpflation“ bezeichnet.
Beschwerde 2: Katastrophe bei der Verarbeitung langer Dokumente
Mehrere Entwickler berichten: Nach der Eingabe langer Dokumente in Opus 4.7 behauptet das Modell, diese gelesen zu haben, generiert dann aber Inhalte, die keinen inhaltlichen Bezug zum Dokument haben. Dies deckt sich mit dem Einbruch des MRCR von 78,3 % auf 32,2 %.
Beschwerde 3: Claude Code stuft Code fälschlicherweise als bösartig ein
Im Issue #47483 berichten mehrere Ingenieure: Claude Opus 4.7 markiert normale Code-Abschnitte für Dateivorgänge als Malware und verweigert die grundlegenden Bearbeitungsanfragen.
Beschwerde 4: Abnehmende Prompt-Kompatibilität
Prompts, die unter 4.6 einwandfrei funktionierten, liefern nach der Migration auf 4.7 eine schlechtere Qualität. Der Grund: 4.7 führt Anweisungen streng wörtlich aus, während 4.6 automatisch „zwischen den Zeilen lesen“ konnte.
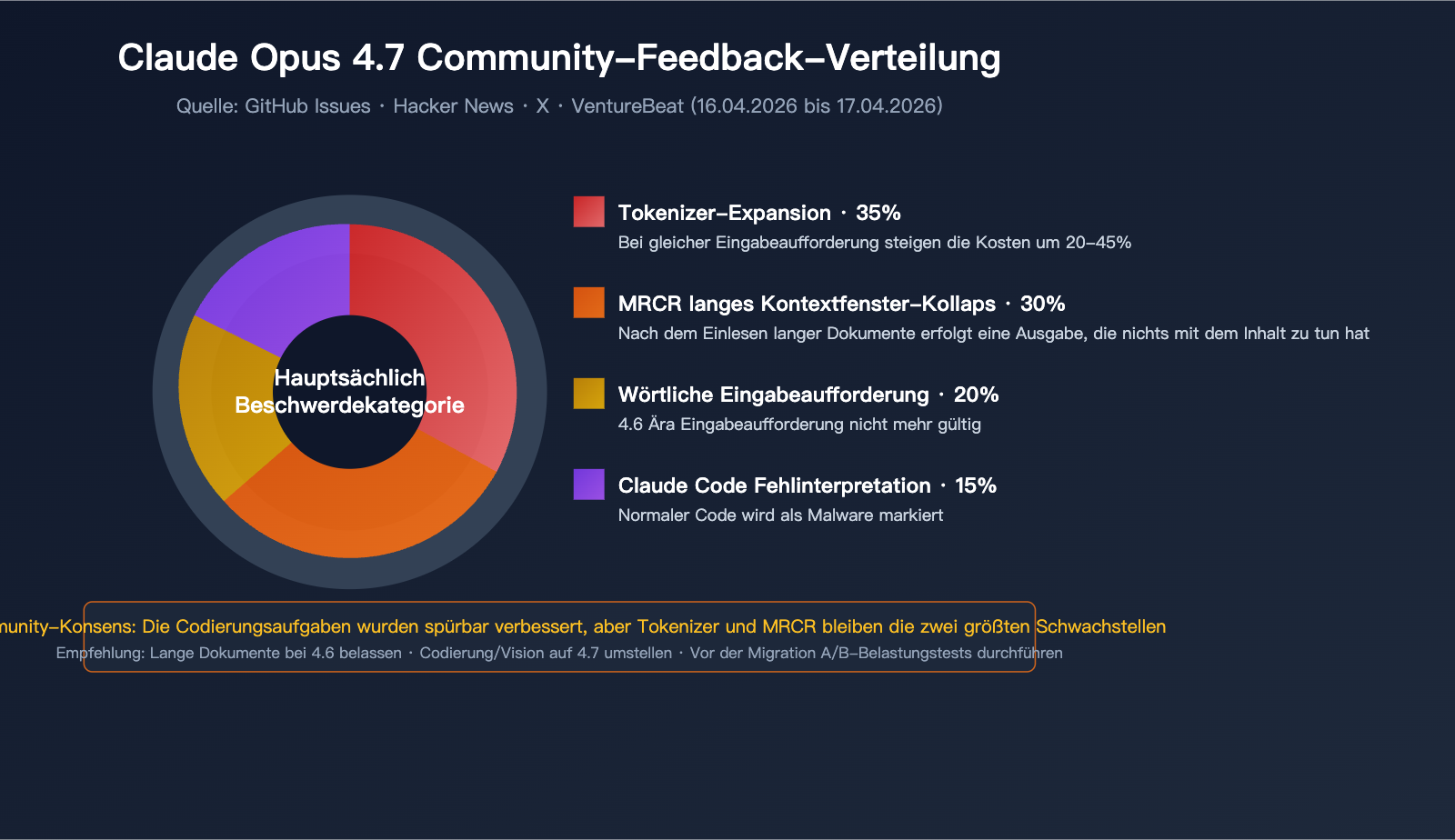
Bewertung von Claude Opus 4.7 nach Szenarien
Basierend auf Messdaten und Community-Feedback haben wir die Leistung von Opus 4.7 in verschiedenen Szenarien bewertet:
| Nutzungsszenario | Bewertung 4.6 | Bewertung 4.7 | Änderung | Empfehlung |
|---|---|---|---|---|
| Refactoring (kurz/mittel) | 8/10 | 9/10 | ↑ | Sofort migrieren |
| Komplexe Agentic-Workflows | 7,5/10 | 9/10 | ↑ | Sofort migrieren |
| Code-Reviews (große Repos) | 8/10 | 6,5/10 | ↓ | Bei 4.6 bleiben |
| Zusammenfassung/QA (lang) | 8,5/10 | 5/10 | ↓↓ | Bei 4.6 bleiben |
| Verständnis von HD-Bildern | 6,5/10 | 9,5/10 | ↑↑ | Sofort migrieren |
| Dialog & Schreiben | 9/10 | 9/10 | → | Beliebig |
| Kostensensible Produktion | 9/10 | 7/10 | ↓ | Bei 4.6 bleiben |
| Prototyping & Experimente | 8/10 | 8,5/10 | ↑ | Migrieren |
Tiefergehende Analyse: Vor- und Nachteile von Claude Opus 4.7
Nach dem Vergleich von Daten und Erfahrungen können wir eine klare Zusammenfassung der Vor- und Nachteile geben.
Die vier Kernvorteile von Claude Opus 4.7
Vorteil 1: Signifikante Steigerung der echten Kodierfähigkeit
SWE-bench Verified (87,6 %) und SWE-bench Pro (64,3 %) sind keine Benchmarking-Spielereien, sondern basieren auf echten GitHub-Issue-Fixes. Das bedeutet, Opus 4.7 kann bei kleinen bis mittleren Aufgaben tatsächlich mehr menschliche Arbeit ersetzen.
Vorteil 2: Qualitätssprung beim visuellen Verständnis
Der Input hochauflösender Bilder (3,75 Megapixel) ermöglicht es Opus 4.7, 4K-Screenshots, Designdokumente und PDF-Scans direkt zu verarbeiten. Ein großer Durchbruch für die Claude-Serie.
Vorteil 3: Task Budgets lösen das Kostenkontrollproblem bei Agents
Lange Zeit war der außer Kontrolle geratene Token-Verbrauch in Agent-Schleifen ein Haupthindernis für den Unternehmenseinsatz. Mit Task Budgets erhalten Entwickler erstmals eine präzise globale Budgetkontrolle.
Vorteil 4: xhigh-Stufe bietet feinere Balance zwischen Schlussfolgerung und Latenz
Eine zusätzliche Wahlmöglichkeit zwischen „high“ und „max“ gibt Entwicklern mehr Flexibilität, um je nach SLA-Anforderung feinabzustimmen.
Die vier Haupteinschränkungen von Claude Opus 4.7
Einschränkung 1: Höhere Kosten durch Token-Inflation
Selbst bei gleichem Preis führen 35 % Token-Expansion plus der höhere Output bei „xhigh“ zu einer 20–45 % höheren Rechnung als bei 4.6.
Lösung: Vor der Migration alle Codepfade mit dem Token-Zählungs-API neu testen.
Einschränkung 2: MRCR-Einbruch bei langen Kontexten
Das kritischste Problem. Bei langen Dokumenten, großen Codebasen oder langen Dialogen sinkt die Abrufgenauigkeit drastisch.
Lösung: Für Langdokument-Szenarien bei Opus 4.6 bleiben oder RAG + Chunking-Strategie nutzen.
Einschränkung 3: Zu wörtliche Befolgung von Anweisungen
Vorhandene Prompts können unerwartete Ergebnisse liefern.
Lösung: Prompts systematisch umschreiben, implizite Absichten entfernen und explizite Einschränkungen nutzen.
Einschränkung 4: Zunahme von Fehlurteilen und Halluzinationen
Fehlinterpretation von Code durch Claude Code und Halluzinationen in Langdokumenten wurden aus der Community häufig gemeldet.
Lösung: Bei Kernaufgaben manuelle Prüfung einplanen und für kritische Logik eine Kreuzvalidierung mit verschiedenen Modellen verwenden.
🎯 Migrations-Tipp: Falls Ihre Anwendung sowohl kurze Kodieraufgaben als auch lange Dokumente umfasst, empfehlen wir die Nutzung der Plattform APIYI (apiyi.com), um je nach Szenario zwischen den Claude-Versionen zu routen. Die Plattform unterstützt den einheitlichen Modellaufruf und ermöglicht eine flexible Kombination von Opus 4.6 (für Kontext) und 4.7 (für Code/Vision), um Performance-Einbußen durch eine pauschale Migration zu vermeiden.
Claude Opus 4.7 API-Aufruf in der Praxis
Neben theoretischen Analysen präsentieren wir Ihnen hier einen praxistauglichen Code, der Ihnen den schnellen Einstieg in Claude Opus 4.7 ermöglicht.
Minimalistisches Beispiel (OpenAI SDK-kompatibel)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Bitte schreibe ein Beispiel für einen parallelen Web-Crawler in Python"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Vollständigen Code anzeigen (inkl. xhigh-Argumentationsstufe, Task Budgets und Fehlerbehandlung)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Vollständige Kapselung für den Claude Opus 4.7-Aufruf"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""Aufruf von Claude Opus 4.7 mit Unterstützung für neue Funktionen"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"Ratenbegrenzung erreicht, warte {wait}s...")
time.sleep(wait)
except openai.APIError as e:
print(f"API-Fehler: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("Maximale Anzahl an Wiederholungsversuchen überschritten")
def compare_versions(self, prompt: str) -> dict:
"""Gleichzeitiger Aufruf von 4.6 und 4.7 zum Vergleich"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="YOUR_API_KEY")
result = client.generate(
prompt="Refaktoriere diesen Python-Code, damit er asynchrone Nebenläufigkeit unterstützt",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 Schnellstart: Der
base_url-Parameter im obigen Code verweist auf die APIYI-Plattform (apiyi.com). Diese bietet eine voll kompatible Schnittstelle zum offiziellen Claude-Standard und unterstützt den parallelen Aufruf von Claude Opus 4.7 und 4.6, was A/B-Tests während der Migrationsphase erleichtert.
Wichtige Checkliste für die Migration
Notwendige Schritte beim Wechsel von Opus 4.6 auf 4.7:
# 1. max_tokens-Limit neu testen (Tokenizer-Änderungen)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Kern-Prompt mit beiden Modellen aufrufen und Token-Verbrauch protokollieren
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": YOUR_PROMPT}],
max_tokens=4096
)
print(f"{model}: input={resp.usage.prompt_tokens}, output={resp.usage.completion_tokens}")
# 2. Lange Dokumente neu testen (MRCR-Abfall)
# Es empfiehlt sich, Aufgaben mit langen Dokumenten auf 4.6 zu belassen oder RAG-Chunking zu verwenden
# 3. Implizite Prompt-Absichten prüfen
# 4.7 führt Anweisungen streng wörtlich aus; "Intuition" des Modells sollte durch explizite Einschränkungen ersetzt werden
Häufig gestellte Fragen zu Claude Opus 4.7
Q1: Ist Claude Opus 4.7 wirklich besser als 4.6?
Das hängt vom Anwendungsfall ab:
- Kurze bis mittlere Programmieraufgaben: 4.7 ist deutlich besser (SWE-bench Verified +6,8 Punkte, CursorBench +12 Punkte).
- Hochauflösende visuelle Aufgaben: 4.7 übertrifft 4.6 bei weitem (visueller Benchmark von 54,5 % auf 98,5 %).
- Agenten-Toolchain: 4.7 ist leistungsfähiger (MCP-Atlas Steigerung um 13 Punkte).
- Abruf langer Kontexte: 4.6 ist deutlich besser (MRCR 78,3 % vs. 32,2 %).
- Kostensensible Projekte: 4.6 ist effizienter (4.7 weist eine Token-Expansion von bis zu 35 % auf).
Wenn Sie beide Versionen parallel nutzen müssen, empfehlen wir die APIYI-Plattform, um Modelle je nach Geschäftsanforderung zu routen. Sie erlaubt den Zugriff auf die gesamte Claude-Familie mit einem einzigen API-Schlüssel.
Q2: Warum behaupten manche, Claude Opus 4.7 sei schlechter als 4.6?
Dies liegt hauptsächlich an vier Gründen:
- Tokenizer-Refaktorierung: Bei gleichen Aufgaben kann der Token-Verbrauch um bis zu 35 % steigen, was die Leistungssteigerung nicht immer rechtfertigt.
- Abfall bei MRCR-Langkontexten: Der Wert fällt von 78,3 % auf 32,2 %, was eine deutliche Verschlechterung bei langen Dokumenten bedeutet.
- Zu wörtliche Befolgung von Anweisungen: Prompts, bei denen 4.6 die "Absicht" des Nutzers gut interpretierte, funktionieren bei 4.7 oft weniger gut.
- Gelegentliche Fehlinterpretationen bei Claude Code: Einige Entwickler berichten, dass korrekter Code fälschlicherweise als bösartig markiert wurde.
Diese Beobachtungen sind keine Einbildung, sondern strukturelle Unterschiede.
Q3: Wie migriere ich sicher von Opus 4.6 auf 4.7?
Drei-Schritte-Migrationsmethode:
- Parallele Lasttests: Führen Sie für 5–10 % des Produktionsverkehrs beide Modelle parallel aus und vergleichen Sie Ergebnisqualität, Latenz und Kosten.
- Szenario-Routing: Lange Dokumente und große Code-Projekte bleiben bei 4.6; Aufgaben für Coding und Bildanalyse wechseln zu 4.7.
- Schrittweise Skalierung: Steigerung von 10 % → 30 % → 50 % → 100 % mit einer Beobachtungsphase von jeweils 3–7 Tagen.
Wir empfehlen für diese Tests die Plattform APIYI (apiyi.com), die flexibles Modell-Routing und Traffic-Verteilung unterstützt.
Q4: Wann sollte die xhigh-Einstellung bei Claude Opus 4.7 verwendet werden?
Anthropic empfiehlt xhigh standardmäßig für Programmieraufgaben und Agenten-Workflows. Geeignete Szenarien:
- Komplexe Code-Refaktorierung
- Debugging über mehrere Dateien hinweg
- Generierung umfangreicher Unit-Tests
- Mehrstufige Agenten-Toolchain-Aufgaben
Nicht empfohlen für:
- Einfache Frage-Antwort-Spiele (hier reicht
medium) - Hochperformante Anfragen (xhigh weist eine höhere Latenz auf)
- Kostensensible Aufgaben (xhigh erhöht die Anzahl der Output-Tokens signifikant)
Q5: Wie funktionieren Task Budgets und wofür eignen sie sich?
Task Budgets sind ein öffentliches Beta-Feature und werden über den HTTP-Header übergeben:
task-budget-tokens: 50000
Anwendungsbereiche:
- Langlaufende Agenten-Schleifen (zur Kostenkontrolle)
- Multi-Mandanten-SaaS (Budgetbegrenzung pro Nutzer)
- Automatisierte CI/CD-Aufgaben (Token-Obergrenze pro Job)
Das Modell passt die Denktiefe automatisch an das verbleibende Budget an und schließt Aufgaben elegant ab, bevor das Budget erschöpft ist, um Fehler zu vermeiden.
Q6: Sind die visuellen Fähigkeiten von Claude Opus 4.7 wirklich so stark?
Ja, das ist eines der wichtigsten Upgrades von 4.7:
- Maximale Auflösung: Steigerung von 1,15 Megapixel auf 3,75 Megapixel (3-fache Verbesserung).
- Visueller Benchmark: Sprung von 54,5 % auf 98,5 %.
- Praktische Fähigkeiten: Kann 4K-Screenshots, Architekturdiagramme, UI-Entwürfe und PDF-Scans direkt interpretieren.
Für Teams in der Frontend-Entwicklung, beim Design-Prototyping oder der Digitalisierung von Dokumenten ist dies ein Game-Changer.
Für wen ist Claude Opus 4.7 geeignet? Entscheidungshilfen
Basierend auf einer umfassenden Analyse geben wir Ihnen klare Empfehlungen für den Einsatz:
Szenarien für den sofortigen Wechsel zu Claude Opus 4.7
- ✅ Programmierung und Refactoring kurzer bis mittellanger Dateien: Die Daten von SWE-bench und CursorBench sprechen für sich.
- ✅ Komplexe agentenbasierte Workflows: Profitieren Sie von der zweifachen Stärke durch MCP-Atlas und Task Budgets.
- ✅ Hochauflösende Bildverarbeitung: Die visuelle Leistungsfähigkeit von 3,75 MP stellt einen qualitativen Sprung dar.
- ✅ Schnelle Prototypenentwicklung: Die Stufe "xhigh" überzeugt bei Aufgaben mittlerer Komplexität.
Szenarien, in denen Sie bei Claude Opus 4.6 bleiben sollten
- 🔒 Zusammenfassung und Q&A bei langen Dokumenten: Der MRCR-Einbruch ist hier nicht zu umgehen.
- 🔒 Code-Reviews auf Repository-Ebene: Die Abruffähigkeit bei langem Kontext ist hier stabiler.
- 🔒 Hohe Token-Kostensensibilität: Der Tokenizer von 4.6 ist wirtschaftlicher.
- 🔒 Stabile Produktionsumgebungen: Wir raten davon ab, nur aus Neugier Migrationsrisiken einzugehen.
Empfohlene Strategie für den Mischbetrieb
Für die meisten Teams ist ein szenariobasiertes Routing sinnvoller als eine vollständige Umstellung:
- Aufgaben mit langen Dokumenten → Opus 4.6
- Programmierung / Bildverarbeitung / Agenten → Opus 4.7
- Nutzen Sie ein einheitliches Gateway für beide Versionen, um das Migrationsrisiko zu minimieren.
💡 Abschließende Empfehlung: Ob Sie auf Claude Opus 4.7 umsteigen oder bei 4.6 bleiben sollten, hängt stark von Ihrem spezifischen Anwendungsfall ab. Wir empfehlen, praktische Vergleichstests über die Plattform APIYI (apiyi.com) durchzuführen. Sie unterstützt den einheitlichen Modellaufruf für verschiedene führende Modelle und ermöglicht Ihnen schnelles Vergleichen und Wechseln, was Ihnen während der Migration maximale Flexibilität sichert.
Fazit
Claude Opus 4.7 ist ein typisches "Upgrade mit Kompromissen": Es erzielt enorme Fortschritte bei der Programmierung, der visuellen Wahrnehmung und den agentenbasierten Fähigkeiten, fordert jedoch Tribut bei der Abrufleistung im langen Kontext, der Token-Effizienz und der Kompatibilität der Eingabeaufforderung.
Die Diskussionen in der Community zum Start sind berechtigt – Opus 4.7 ist ein leistungsstarkes neues Modell, aber auch eine Architekturumstellung mit Begleiterscheinungen. Für Entwickler stellt sich daher nicht die Frage "Ob migrieren", sondern "In welchen Szenarien migrieren".
- Wenn Sie komplexe Coding-Aufgaben oder hochauflösende visuelle Analysen durchführen, ist 4.7 die beste Wahl für das zweite Quartal 2026.
- Wenn Ihr Kerngeschäft auf der Verarbeitung langer Dokumente basiert oder kostenorientiert ist, behalten Sie vorerst 4.6 bei.
- Wir empfehlen dringend parallele Lasttests während der Migration, um versteckte Leistungseinbußen durch eine voreilige Komplettumstellung zu vermeiden.
Testen Sie Claude Opus 4.7 und 4.6 schnell und unkompliziert über die Plattform APIYI (apiyi.com). Diese bietet eine einheitliche Schnittstelle, Echtzeit-Kostenüberwachung und Modell-Routing – die ideale Lösung für Migrations-Tests und produktive Anwendungen.
Referenzmaterialien
-
Offizielle Ankündigung von Anthropic: Vorstellung von Claude Opus 4.7
- Link:
anthropic.com/news/claude-opus-4-7 - Beschreibung: Offizielle Erläuterung der Kernfunktionen und Preisgestaltung.
- Link:
-
Offizielle Claude API-Dokumentation: Migrationsleitfaden für Claude Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Beschreibung: Offizielle Migrationshinweise und Informationen zu Änderungen am Tokenizer.
- Link:
-
AWS Bedrock Blog: Claude Opus 4.7 jetzt auf Amazon Bedrock verfügbar
- Link:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - Beschreibung: Hinweise zur Bereitstellung auf Cloud-Plattformen von Drittanbietern.
- Link:
-
Vellum AI Benchmark-Analyse: Detaillierte Interpretation der Benchmarks von Claude Opus 4.7
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Beschreibung: Unabhängige Benchmark-Bewertung durch Dritte.
- Link:
-
GitHub Issue #47483: Community-Feedback zur Rückkehr von Claude Opus
- Link:
github.com/anthropics/claude-code/issues/47483 - Beschreibung: Erfahrungsberichte aus erster Hand von Entwicklern.
- Link:
Autor: APIYI Technisches Team
Veröffentlichungsdatum: 17.04.2026
Geeignete Modelle: Claude Opus 4.7 / Claude Opus 4.6
Technischer Austausch: Besuchen Sie APIYI unter apiyi.com, um Testguthaben zu erhalten und die Unterschiede zwischen den Claude-Versionen selbst zu vergleichen.