Im Jahr 2026 erstellte ein unabhängiger österreichischer Entwickler in seiner Freizeit ein Open-Source-Projekt, das innerhalb von zwei Monaten 247.000 GitHub-Stars erhielt und sich zu einer KI-Agenten-Plattform entwickelte, die von Unternehmen im Silicon Valley und in China eifrig eingesetzt wird.
Dieses Projekt heißt OpenClaw.
Gleichzeitig tauchte eine Frage auf: In realen Agenten-Szenarien wie OpenClaw, welches KI-Modell erbringt die beste Leistung?
Genau dieses Problem soll PinchBench lösen. Es ist der offizielle Bewertungsmaßstab für OpenClaw, entwickelt vom kilo.ai-Team in Rust, das synthetische Tests durch reale Aufgaben ersetzt und Entwicklern eine verlässliche Grundlage für die Modellauswahl bietet.
Dieser Artikel beginnt mit der Entstehungsgeschichte von OpenClaw, analysiert eingehend das PinchBench-Bewertungssystem, hilft Ihnen, die wahre Bedeutung von KI-Benchmarks zu verstehen und wie Sie basierend auf den Bewertungsdaten das passende Modell für Ihren Agenten-Workflow auswählen.
I. Was ist OpenClaw: Ein Open-Source-Phänomen, das seinen Namen in einem Monat dreimal geändert hat
Die Geburt von OpenClaw und die Namensgebungskontroverse
Die Geschichte von OpenClaw beginnt im November 2025.
Der österreichische Entwickler Peter Steinberger baute in seiner Freizeit eine KI-Agenten-Plattform, die ursprünglich Clawdbot hieß. Die Kernidee des Projekts war einfach: KI soll nicht nur ein Chat-Tool sein, sondern deine digitalen Workflows wirklich übernehmen – E-Mails lesen, Code schreiben, Kalender verwalten, Informationen suchen.
Aber das Konzept des KI-Agenten ist nicht neu. Warum explodierte OpenClaw über Nacht?
Der Schlüssel lag in der doppelten Unterstützung durch Timing und Open Source. Ende Januar 2026, mit der viralen Verbreitung des Moltbook-Projekts, erreichte die Sehnsucht der gesamten Tech-Community, "KI wirklich arbeiten zu lassen", ihren Höhepunkt. Clawdbot nutzte den Schwung und wurde zum Mittelpunkt.
Doch kurz darauf erhielt das Projekt eine Markenwiderspruchsmitteilung von Anthropic – "Clawd" in Clawdbot wurde als Verwechslungsrisiko mit einem internen Produktnamen von Anthropic angesehen. Das Projekt wurde am 27. Januar 2026 eilig in Moltbot umbenannt, als Hommage an das gleichzeitig populäre Moltbook-Projekt.
Drei Tage später gab Steinberger jedoch auf GitHub zu: Der neue Name "rollte nie ganz über die Zunge" ("never quite rolled off the tongue"). Das Projekt wurde erneut in OpenClaw umbenannt und trägt diesen Namen bis heute.
Diese Namensänderungs-Kontroverse wurde stattdessen zur besten "kostenlosen Marketingaktion" für das Projekt und machte OpenClaw in der Entwickler-Community weithin bekannt.
Stand 2. März 2026 hat OpenClaw auf GitHub gesammelt:
- ⭐ 247.000 Sterne (entspricht fast der Hälfte der Sterne des React-Frameworks im gleichen Zeitraum)
- 🍴 47.700 Forks
- 🌍 Wird in großem Umfang in Unternehmen im Silicon Valley, Europa und China eingesetzt
Die Kernarchitektur von OpenClaw
Die Designphilosophie von OpenClaw ist: lokal ausgeführt, modellunabhängig, über Messaging-Anwendungen zugänglich.
Diese drei Merkmale bestimmen den grundlegenden Unterschied zu anderen KI-Agenten-Frameworks.
Lokal ausgeführt bedeutet, dass deine Daten keine Drittanbieter-Server passieren. Im Gegensatz zu den meisten KI-Assistenten in SaaS-Form wird OpenClaw auf den eigenen Geräten des Benutzers bereitgestellt, und Modellaufrufe können auch auf private Endpunkte verweisen.
Modellunabhängig bedeutet, dass OpenClaw selbst nicht an ein bestimmtes Großes Sprachmodell gebunden ist. Es ist eine "Gehirnschale", die die Anbindung an beliebige gängige Modelle wie Claude, GPT, DeepSeek unterstützt. Entwickler können je nach Aufgabentyp und Kostenbudget frei wechseln.
Zugriff über Messaging-Anwendungen ist das charakteristischste Design von OpenClaw – normale Benutzer müssen keine spezielle App öffnen, sondern können direkt Nachrichten in Signal, Telegram, Discord oder WhatsApp senden, um die Fähigkeiten des KI-Agenten zu nutzen. Dies senkt die Nutzungsschwelle erheblich und ermöglicht es auch Nicht-Technikern, davon zu profitieren.
| Design-Dimension | OpenClaw-Wahl | Gängige Alternativen | Erläuterung der Unterschiede |
|---|---|---|---|
| Bereitstellungsort | Lokal ausgeführt | Cloud-SaaS | Stärkere Datenprivatsphäre, erfordert aber eigene Wartung |
| Modellbindung | Völlig unabhängig | An spezifisches Modell gebunden | Flexibler Wechsel, erfordert aber eigene Konfiguration |
| Benutzeroberfläche | Messaging-Anwendung | Dedizierte Web/App | Niedrige Einstiegshürde, Funktionalität durch Messaging-Anwendung begrenzt |
| Berechtigungsbereich | Umfassender Zugriff | Sandbox-Beschränkung | Leistungsstark, aber höheres Sicherheitsrisiko |
| Open-Source-Lizenz | Vollständig Open Source | Closed Source / Teilweise Open Source | Community-gesteuert, aber begrenzte Support-Garantie |
🎯 Nutzungsempfehlung: Für die Bereitstellung von OpenClaw ist ein hochwertiges Großes Sprachmodell-Backend erforderlich.
Wir empfehlen, Claude Sonnet 4.6 oder GPT-5.4 über APIYI apiyi.com anzubinden.
Beide Modelle haben in PinchBench hervorragende Leistungen gezeigt, und APIYI unterstützt einen einheitlichen Schnittstellenwechsel,
was es dir ermöglicht, die Effekte verschiedener Modelle schnell zu vergleichen, ohne die Kernkonfiguration von OpenClaw ändern zu müssen.
Die Fähigkeitsgrenzen von OpenClaw
Das Fähigkeitsspektrum von OpenClaw ist ziemlich breit, aber genau das hat Sicherheitskontroversen ausgelöst:
Zugängliche Datenquellen:
- E-Mail-Konten (Lesen, Klassifizieren, Antworten entwerfen)
- Kalendersysteme (Termine anzeigen, erstellen, ändern)
- Dateisysteme (Dateien durchsuchen, lesen, erstellen, verschieben)
- Code-Repositories (Code lesen, Tests ausführen, Änderungen committen)
- Messaging-Plattformen (Plattformübergreifende Nachrichtenaggregation und -antwort)
- Web-Informationen (Suchen, Zusammenfassen, strukturierte Extraktion)
Typische Anwendungsszenarien:
// Benutzer sendet in Telegram: "Bitte organisiere meine heutigen E-Mails,
// markiere die, die heute beantwortet werden müssen, und entwirf die Antworten."
// OpenClaw Agent Ausführungsablauf:
// 1. E-Mail-Tool aufrufen, ungelesene E-Mails von heute lesen
// 2. Großes Sprachmodell verwenden, um die Dringlichkeit jeder E-Mail zu beurteilen
// 3. Liste der E-Mails filtern, die heute beantwortet werden müssen
// 4. Entwürfe für jede E-Mail generieren
// 5. Organisierte Ergebnisse und Entwurfsvorschau in Telegram zurückgeben
Diese Fähigkeit, "Dinge wirklich zu erledigen", ist der wesentliche Unterschied zwischen OpenClaw und einfachen Chatbots.
Steinberger tritt OpenAI bei und die Zukunft des Projekts
Am 14. Februar 2026 erschütterte eine Nachricht die gesamte Open-Source-Community: Steinberger kündigte auf GitHub an, OpenAI beizutreten, und das Projekt wird an eine unabhängige Open-Source-Stiftung übergeben.
Dies hat doppelte Auswirkungen auf OpenClaw: Einerseits erhielt das Projekt professionellere Betriebs- und Rechtssicherheit; andererseits begann die Öffentlichkeit, die Motive hinter der Übernahme des Gründers durch OpenAI zu spekulieren – war es zur Technologieabsorption oder um potenzielle Konkurrenten zu verhindern?
Derzeit ist die OpenClaw-Stiftung gegründet, und das Projekt bleibt vollständig Open Source. Aber die Prioritäten der Entwicklungs-Roadmap haben sich deutlich verschoben: Sicherheitsfunktionen auf Unternehmensebene und ein Berechtigungssteuerungssystem stehen im Mittelpunkt der nächsten Version.
Sicherheitskontroversen: Risiken durch leistungsstarke Fähigkeiten
OpenClaws umfassender Bedarf an Systemberechtigungen hat von Anfang an die Aufmerksamkeit von Cybersicherheitsforschern auf sich gezogen.
Im März 2026 kündigten die chinesischen Behörden Beschränkungen für staatliche Unternehmen und Regierungsbehörden an, OpenClaw auf Bürocomputern auszuführen. Hauptbedenken sind:
- Daten könnten über Großes Sprachmodell-API-Aufrufe an ausländische Dienstleister weitergegeben werden
- Umfassende Berechtigungen könnten bei falscher Konfiguration zu Angriffspunkten werden
- Sensible interne Unternehmensinformationen könnten vom Agenten systemübergreifend übertragen werden
Dieser Vorfall erinnert alle Unternehmensentwickler daran: Bei der Einführung leistungsstarker Agenten-Tools sind das Prinzip der geringsten Rechte und Audit-Logs unverzichtbare Sicherheitsgrundlagen.
II. Die wahre Rolle von Benchmarks in der KI-Branche: Von der Prüfung zur Praxis
Warum die KI-Branche ohne Benchmarks nicht auskommt
Wenn du jemals die Fähigkeiten zweier KI-Modelle vergleichen wolltest, bist du wahrscheinlich auf ein Dilemma gestoßen: Hersteller behaupten alle, ihr Modell sei "das stärkste". Aber was bedeutet "stark"? Bei welcher Aufgabe? Im Vergleich zu welcher Baseline?
Benchmark (Bewertungsmaßstab) ist ein standardisiertes Testsystem, das genau zur Lösung dieses Problems entwickelt wurde.
In der KI-Branche muss ein guter Benchmark drei Bedingungen erfüllen:
- Reproduzierbarkeit: Jeder, der denselben Testdatensatz verwendet, sollte die gleichen Ergebnisse erzielen.
- Repräsentativität: Der Testinhalt sollte die Fähigkeitsanforderungen realer Anwendungsszenarien widerspiegeln.
- Fairness: Der Testdatensatz sollte nicht durch die Trainingsdaten des Modellentwicklers kontaminiert sein.
Im Jahr 2026 waren branchenweit über 15 gängige Benchmarks aktiv im Einsatz, aber nur etwa 4 davon konnten nach Branchenschätzungen die Leistung in Produktionsumgebungen wirklich vorhersagen.
Drei. PinchBench Tiefenanalyse: OpenClaws offizieller Bewertungsstandard
Hintergrund der Entstehung von PinchBench
PinchBench wurde vom kilo.ai-Team unter Verwendung von Rust entwickelt und ist ein speziell für OpenClaw-Szenarien entwickelter Bewertungs-Benchmark, der auf GitHub (pinchbench/skill-Repository) als Open Source veröffentlicht wurde.
Das Kernproblem, das es löst: Allgemeine Modell-Ranglisten haben eine sehr schwache Vorhersagekraft für die tatsächliche Agent-Leistung.
Studien haben gezeigt, dass ein Modell, das auf MMLU zu den Top 5 % gehört, bei der kombinierten Aufgabe der E-Mail-Klassifizierung und Terminplanung in OpenClaw möglicherweise deutlich schlechter abschneidet als ein Modell, das im MMLU-Ranking nur mittelmäßig ist, aber speziell für die Tool-Nutzung optimiert wurde.
Die Einführung von PinchBench gab Entwicklern zum ersten Mal eine verlässliche Bewertungsgrundlage, die speziell auf Agent-Workflows zugeschnitten ist.
Die 23 Aufgabenkategorien von PinchBench
PinchBench verwendet reale Aufgaben statt synthetischer Probleme und deckt 23 Aufgabenkategorien ab, wobei jede Kategorie einem realen Nutzungsszenario von OpenClaw-Benutzern entspricht:
Kernaufgabenkategorien (6 Hauptkategorien):
| Aufgabenkategorie | Spezifischer Testinhalt | Beteiligte Tools | Bewertungsschwierigkeit |
|---|---|---|---|
| Terminmanagement | Terminplanung, Konfliktlösung, Zeitzonenverwaltung, wiederkehrende Erinnerungen | Kalender-API, Zeitzonen-Tools | ★★★☆☆ |
| Code-Erstellung | Funktionsimplementierung, Bugfixing, Code-Refactoring, Unit-Tests | Code-Ausführung, Dateisystem | ★★★★☆ |
| E-Mail-Verarbeitung | Klassifizierung, Priorisierung, Entwurf automatischer Antworten, Anhangsverwaltung | E-Mail-Client-API | ★★★☆☆ |
| Informationsrecherche | Websuche, Informationsaggregation, Zusammenfassungserstellung, Quellenprüfung | Suchmaschine, Browser | ★★★★☆ |
| Dateiverwaltung | Organisation, Formatkonvertierung, Stapelverarbeitung, Versionskontrolle | Dateisystem, Konvertierungs-Tools | ★★☆☆☆ |
| Multi-Tool-Kollaboration | Plattformübergreifender Datenfluss, Toolchain-Orchestrierung, bedingte Auslösung | Kombination verschiedener Tools | ★★★★★ |
Die Bewertungsmethodik von PinchBench
PinchBench verwendet einen zweifachen Bewertungsmechanismus, der sowohl Objektivität als auch Qualitätsbewertung berücksichtigt:
Automatische Überprüfungen (Automated Checks)
Für überprüfbare objektive Kriterien:
- Ob der Code alle Testfälle besteht
- Ob Dateien korrekt an den angegebenen Ort verschoben wurden
- Ob Kalenderereignisse zur richtigen Zeit erstellt wurden
- Ob API-Aufrufe das erwartete Format zurückgeben
LLM-Richter (LLM Judge)
Für qualitative Bewertungen, die ein subjektives Urteil erfordern:
- Ton und Professionalität der E-Mail-Antworten
- Informationsgenauigkeit und Vollständigkeit von Forschungsberichten
- Genauigkeit des Aufgabenverständnisses (ob die Benutzerabsicht wirklich verstanden wurde)
- Angemessenheit der Strategie zur Behandlung von Randfällen
Diese Kombination berücksichtigt sowohl die Effizienz (automatische Überprüfungen können in großem Maßstab durchgeführt werden) als auch die Qualität (LLM-Richter erfassen Details, die für Menschen schwer zu quantifizieren sind).
Dreidimensionale Bewertungsmetrik-Matrix:
┌─────────────────────────────────────────────────┐
│ PinchBench Dreidimensionales Bewertungssystem │
├─────────────────────────────────────────────────┤
│ Erfolgsrate (Success Rate) │
│ → Umfassende Messung der Qualität der Aufgabenerfüllung │
│ → Hauptdimension für das Ranking │
│ → Kombination aus automatischer Überprüfung + LLM-Richter │
├─────────────────────────────────────────────────┤
│ Geschwindigkeit (Speed) │
│ → Durchschnittliche Zeit zur Aufgabenerfüllung (Sekunden/Minuten) │
│ → Entscheidend für Echtzeit-Reaktionsszenarien │
│ → Beinhaltet API-Latenz und Inferenzzeit │
├─────────────────────────────────────────────────┤
│ Kosten (Cost) │
│ → Token-Kosten (USD) für die Aufgabenerfüllung │
│ → Schlüsselindikator für Szenarien mit hoher Nutzungshäufigkeit │
│ → Hilft bei der Berechnung des ROI und der Modellauswahl │
└─────────────────────────────────────────────────┘
Stand 13. März 2026, PinchBench öffentliche Ranglistendaten:
- 📊 49 Modelle bewertet, abdeckend alle gängigen kommerziellen und Open-Source-Modelle
- 🔄 327 Ausführungsaufzeichnungen, kontinuierlich aktualisiert
- 🌐 Öffentliche Rangliste: pinchbench.com (Echtzeit-Updates)
- 📁 Open-Source-Repository: github.com/pinchbench/skill (Aufgabendefinitionen öffentlich)
🎯 PinchBench Nutzungsempfehlung: Beim Betrachten der Rangliste wird empfohlen, zwischen den drei Ansichten Erfolgsrate, Geschwindigkeit und Kosten zu wechseln, um das am besten geeignete Modell basierend auf Ihren tatsächlichen Anforderungen (Echtzeit vs. Qualität vs. Kosten) auszuwählen. Nach der einheitlichen Anbindung über APIYI apiyi.com können Sie bequem die tatsächlichen Kosten verschiedener Modelle im selben Geschäftsszenario vergleichen.
Vier. Tiefenanalyse der PinchBench-Rangliste und Leitfaden zur Modellauswahl
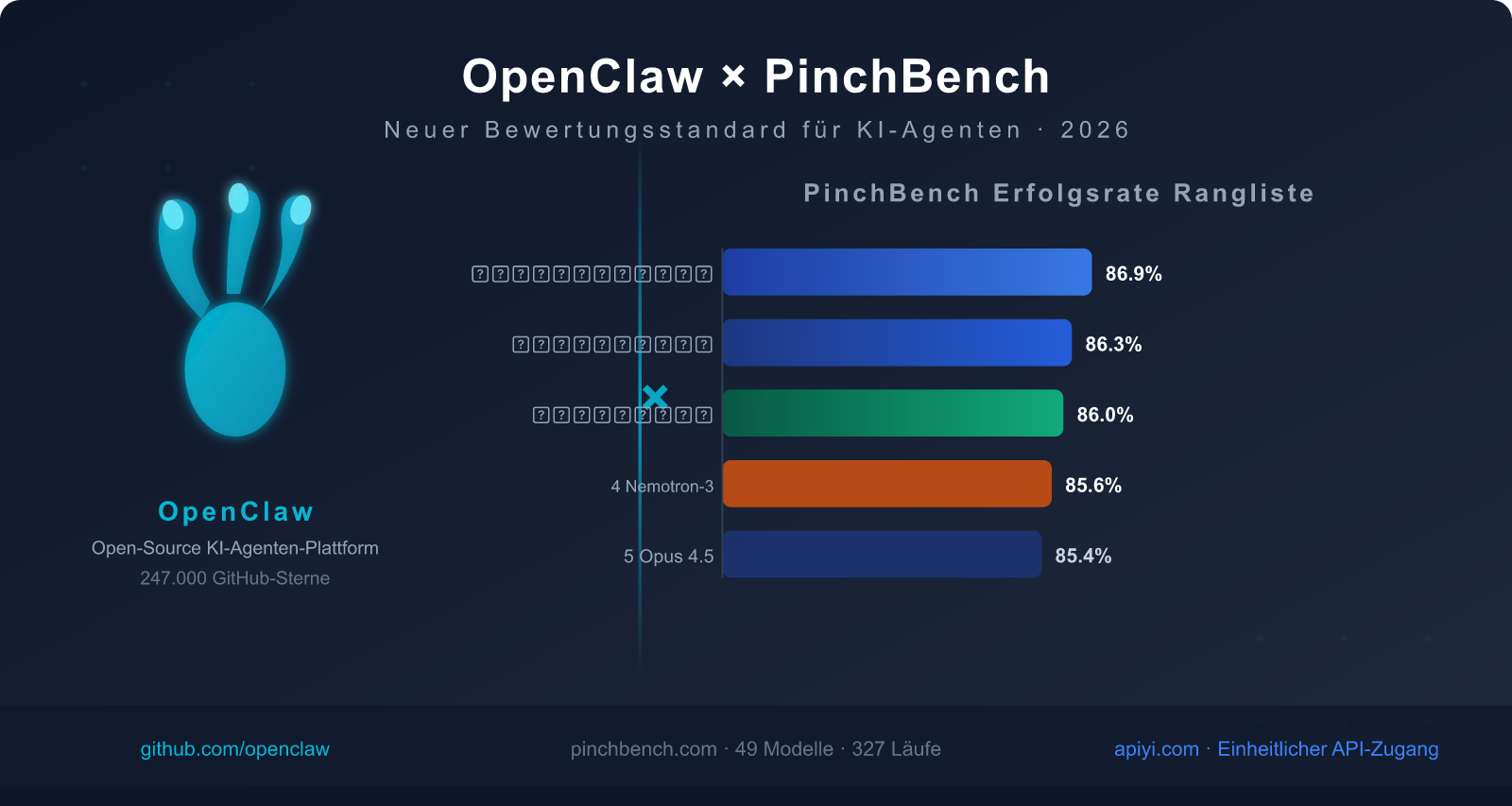
Aktuelles Top 5 Erfolgsraten-Ranking (Daten vom 13. März 2026)
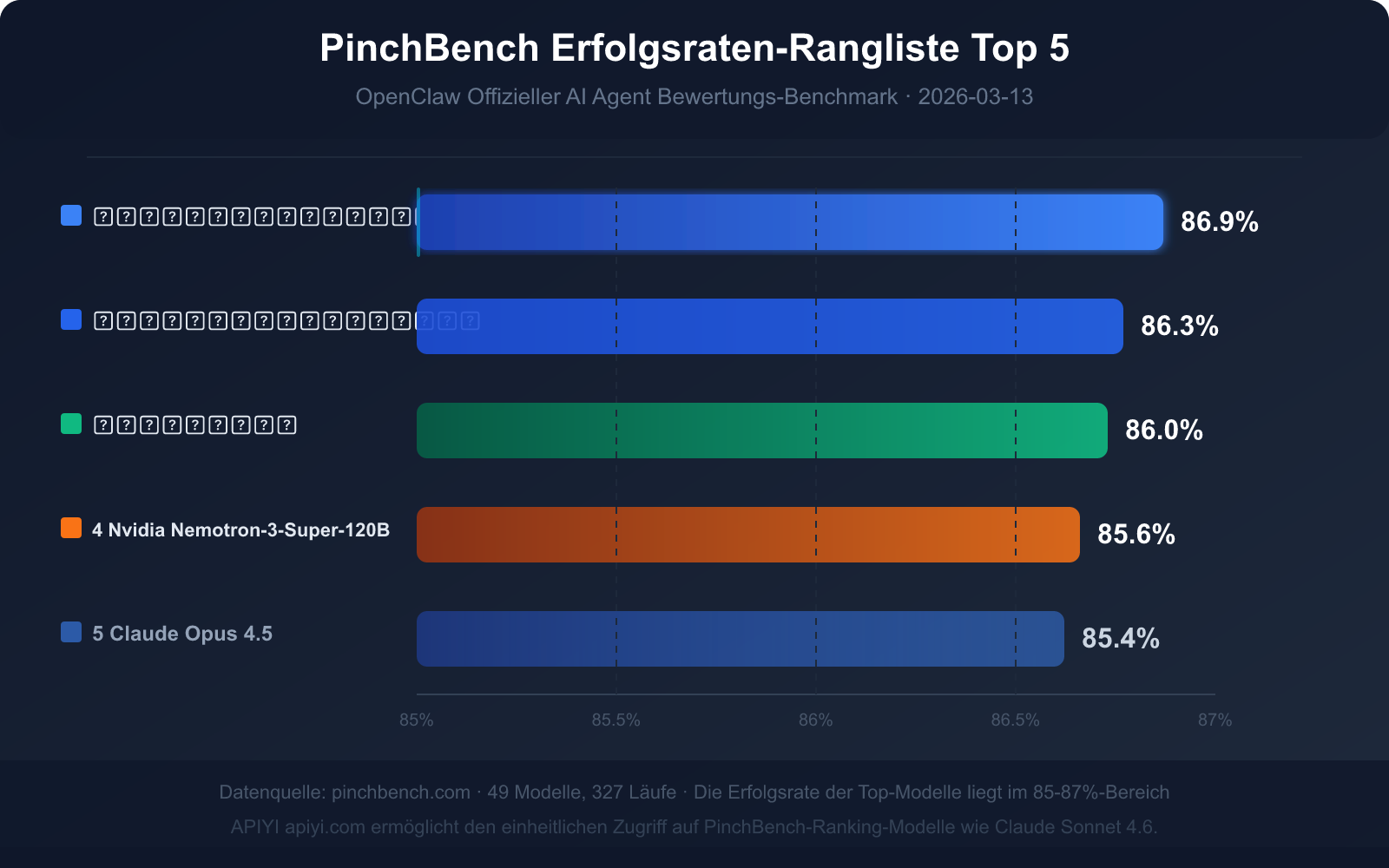
| Rang | Modellname | Erfolgsrate | Modelltyp | Kernvorteil |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | Kommerziell, Closed Source | Höchste Erfolgsrate, ausgewogene Geschwindigkeit und Qualität |
| 🥈 2 | Claude Opus 4.6 | 86.3% | Kommerziell, Closed Source | Stärkste komplexe Inferenzfähigkeit |
| 🥉 3 | GPT-5.4 | 86.0% | Kommerziell, Closed Source | Gute Stabilität bei Tool-Aufrufen |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | Open Source, deploybar | Beste Leistung unter Open-Source-Modellen |
| 5 | Claude Opus 4.5 | 85.4% | Kommerziell, Closed Source | Flaggschiff der vorherigen Generation, immer noch wettbewerbsfähig |
Wichtige Dateneinblicke: Was bedeutet eine Erfolgsrate von 85 %?
Die Erfolgsrate der Top-Modelle auf PinchBench liegt im Bereich von 85 % bis 87 % und nicht nahe der vollen Punktzahl. Diese Zahl selbst sendet drei wichtige Signale aus:
Signal 1: KI-Agent-Aufgaben sind bis heute ein hochkomplexes Problem
Selbst das erstplatzierte Claude Sonnet 4.6 (86,9 %) scheitert bei etwa 13 von 100 Aufgaben. Dies ist kein Mangel an Modellfähigkeiten, sondern die inhärente Komplexität realer Aufgaben – vage Anweisungen, unvollständige Informationen, Randfälle bei Tool-Aufrufen können zu Fehlern führen.
Signal 2: Fehlertolerantes Design ist in der Agent-Entwicklung unerlässlich
Wenn eine Fehlerrate von 13 % als „Spitzenleistung“ gilt, sind vollautomatische Agent-Prozesse ohne menschliche Überprüfung in Produktionsumgebungen mit hohem Risiko verbunden. Die beste Praxis ist: Bei risikoreichen Operationen (z. B. E-Mails senden, Code übermitteln) manuelle Bestätigungsschritte beibehalten.
Signal 3: Die Unterschiede zwischen den Modellen sind minimal, das Aufgabendesign ist wichtiger
Der Unterschied zwischen Rang 1 und Rang 5 beträgt nur 1,5 Prozentpunkte (86,9 % vs. 85,4 %). Das bedeutet: Der Einfluss der Modellauswahl ist weitaus geringer als die Art und Weise, wie die Eingabeaufforderung für die Aufgabe gestaltet wird, wie die Tool-Schnittstellen definiert werden und wie Fehler behandelt werden.
Umfassende Analyse der dreidimensionalen Metriken
Nur die Erfolgsrate zu betrachten, reicht nicht aus. Hier ist ein umfassender Bewertungsrahmen für die drei Dimensionen:
| Anwendungsszenario | Priorisierte Metrik | Sekundäre Metrik | Empfohlene Modellrichtung |
|---|---|---|---|
| Häufige, leichte Aufgaben (E-Mail-Klassifizierung, Erinnerungen) | Geschwindigkeit + Kosten | Erfolgsrate | Leichte Modelle wie Claude Haiku 4.5 |
| Komplexe Ingenieuraufgaben (Code-Refactoring, Forschung) | Erfolgsrate | Geschwindigkeit | Claude Sonnet 4.6 / GPT-5.4 |
| Echtzeit-Reaktionsszenarien (Instant Assistant) | Geschwindigkeit | Erfolgsrate | Top-Modelle der Geschwindigkeitsrangliste |
| Kostensensitive Anwendungen | Kosten | Erfolgsrate | Open-Source-Selbstbereitstellung / API-Modelle mit niedrigen Kosten |
| Unternehmenssicherheit und Compliance | Erfolgsrate + Kontrollierbarkeit | Kosten | Private Bereitstellung von Open-Source-Modellen |
🎯 Umfassende Auswahl-Empfehlung: Basierend auf den PinchBench-Daten ist Claude Sonnet 4.6 die derzeit beste Gesamtwahl mit der höchsten Erfolgsrate für OpenClaw-Szenarien. Für kostensensitive, hochfrequente Szenarien wird empfohlen, zuerst Claude Sonnet 4.6 zu verwenden, um eine Basislinie für die Aufgabenerfolgsrate festzulegen, und dann zu testen, ob leichtere Modelle die Kosten innerhalb einer akzeptablen Erfolgsrate erheblich senken können. Alle diese Tests können über die einheitliche API-Schnittstelle von APIYI apiyi.com durchgeführt werden, ohne separate Konten bei mehreren Anbietern registrieren zu müssen.
Wettbewerbsanalyse von Open-Source-Modellen
Nvidia Nemotron-3-Super-120B belegt mit einer Erfolgsrate von 85,6 % den 4. Platz, nur 1,3 Prozentpunkte hinter dem Erstplatzierten – ein sehr beeindruckendes Ergebnis für ein Open-Source-Modell.
Vorteile von Open-Source-Modellen:
- Datenhoheit: Modell und Daten befinden sich in einer selbstkontrollierten Umgebung und erfüllen Compliance-Anforderungen
- Kostenstruktur: Einmalige GPU-Investition, keine nachfolgenden API-Aufrufgebühren (bei hohem Volumen)
- Anpassungsspielraum: Kann für spezifische Aufgaben feinabgestimmt werden (Fine-tuning)
Einschränkungen von Open-Source-Modellen:
- Bereitstellungskosten: Ein Modell mit 120 Milliarden Parametern benötigt 4-8 A100/H100 GPUs
- Wartungsaufwand: Modellaktualisierungen und Versionsverwaltung erfordern dediziertes Betriebspersonal
- Anfängliche Testkosten: Bevor bestätigt wird, dass ein Open-Source-Modell für das eigene Szenario geeignet ist, ist die Prototyp-Validierung über kommerzielle APIs oft wirtschaftlicher
V. Praxisleitfaden: So konfigurieren Sie das optimale Modell in OpenClaw
Schnelle Integration von Claude Sonnet 4.6 zur Steuerung von OpenClaw
Hier ist ein vollständiges Konfigurationsbeispiel für die Integration des PinchBench-Modells Nummer eins über APIYI:
Schritt 1: API-Schlüssel abrufen
Besuchen Sie die offizielle APIYI-Website apiyi.com, registrieren Sie ein Konto und rufen Sie Ihren API-Schlüssel in der Konsole ab. APIYI bietet OpenAI-kompatible Schnittstellen und unterstützt gleichzeitig das native Anthropic SDK.
Schritt 2: Das Modell-Backend von OpenClaw konfigurieren
# OpenClaw Konfigurationsbeispiel (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # Maximale Anzahl der Ausführungsschritte
tool_timeout: 30 # Timeout für einen einzelnen Tool-Aufruf (Sekunden)
retry_on_error: true # Bei fehlgeschlagenem Tool-Aufruf automatisch wiederholen
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # Hochrisikobetriebe erfordern manuelle Bestätigung
Schritt 3: Konfiguration überprüfen
# Verbindung mit dem Anthropic SDK testen
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Testanfrage senden
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "Bitte nennen Sie 3 Aufgabentypen, die Sie in OpenClaw ausführen können"
}]
)
print(response.content[0].text)
Schritt 4: A/B-Testkonfiguration für mehrere Modelle
# Verschiedene Modelle für dieselbe Aufgabe vergleichen (empfohlen vor der offiziellen Bereitstellung)
models_to_test = [
"claude-sonnet-4-6", # PinchBench Rang 1
"gpt-5.4-turbo", # PinchBench Rang 3 (OpenAI-kompatibles Format)
"claude-opus-4-5", # Flaggschiff der vorherigen Generation, Kostenvergleich als Referenz
]
# APIYI unterstützt die einheitliche API-Aufrufe für alle oben genannten Modelle
# base_url bleibt unverändert, nur der model-Parameter muss geändert werden
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: Erfolgsrate={result.success_rate}, Dauer={result.avg_time}s, Kosten=${result.cost_per_task}")
🎯 Schneller Start: Besuchen Sie APIYI apiyi.com und registrieren Sie sich, um Testguthaben zu erhalten.
Es unterstützt die einheitliche API-Integration von PinchBench-Modellen wie Claude Sonnet 4.6 und GPT-5.4.
Sie müssen nicht separat Zugriffsberechtigungen von mehreren Anbietern beantragen, was die anfängliche Hürde für Modelltests erheblich senkt.
Testen Sie Ihren Agenten selbst mit den 5 Dimensionen von PinchBench
Bevor Sie Ihren Agenten in der Produktion bereitstellen, empfehlen wir Ihnen, Ihre Agentenkonfiguration anhand der folgenden Checkliste zu bewerten:
Vom PinchBench inspirierte Agenten-Selbsttest-Checkliste
□ Dimension 1 - Aufgabenabschlussrate
Geben Sie dem Agenten 10 komplexe Aufgaben mit mehr als 3 Schritten
Notieren Sie die Anzahl der vollständig erfolgreichen / teilweise erfolgreichen / fehlgeschlagenen Aufgaben
Ziel: Vollständige Erfolgsrate ≥ 80 %
□ Dimension 2 - Genauigkeit des Tool-Aufrufs
Überprüfen Sie die Tool-Aufrufprotokolle und zählen Sie die folgenden Fehlertypen:
- Falsche Tool-Auswahl (falsches Tool gewählt)
- Falsches Parameterformat (falscher Parametertyp oder -format)
- Falscher Parameterwert (Parametertyp korrekt, aber Wert unvernünftig)
Ziel: Tool-Fehlerrate ≤ 5 %
□ Dimension 3 - Kohärenz der mehrstufigen Argumentation
Entwerfen Sie eine Langzeitaufgabe, die mehr als 15 Schritte erfordert
Beobachten Sie, ob es zu einer Zielverschiebung kommt (ursprüngliches Ziel vergessen)
Ziel: Keine Zielverschiebung bei Langzeitaufgaben
□ Dimension 4 - Kontextbeibehaltung
Geben Sie in Runde 1 wichtige Informationen an und zitieren Sie diese Informationen in Runde 8
Überprüfen Sie, ob der Agent korrekt zitieren kann
Ziel: Genauigkeit der rundenübergreifenden Zitate ≥ 90 %
□ Dimension 5 - Halluzinationserkennung
Entwerfen Sie Aufgaben, die die Referenzierung realer Daten (Dateiname/Kontakt/Datum) erfordern
Überprüfen Sie, ob der Agent nicht existierende Daten erfindet
Ziel: Halluzinationsrate ≤ 2 %
VI. Die Zukunft von AI Benchmarks: Von der Einzelpunktbewertung zur Ökosystembewertung
Evolutionstrends des aktuellen Benchmark-Systems
Im Jahr 2026 durchläuft der Bereich der AI-Benchmarks einen tiefgreifenden Wandel. Im Mittelpunkt dieses Wandels steht die Erweiterung des Bewertungsgegenstands von einzelnen Modellen auf vollständige Agenten-Systeme.
Die Denkweise traditioneller Benchmarks ist: Dem Modell eine Frage stellen und sehen, ob es richtig antwortet. Doch mit der Verbreitung von Agenten-Plattformen wie OpenClaw wird die wirklich wichtige Frage: Kann das Modell, als "Gehirn" eines Systems, dieses System dazu bringen, seine Arbeit zu erledigen?
Die Antwort auf diese Frage hängt nicht nur vom Wissensstand des Modells ab, sondern auch von:
- Der Fähigkeit des Modells, Tool-Beschreibungen zu verstehen
- Der Entscheidungsstrategie des Modells bei unsicheren Informationen
- Der Fähigkeit des Modells, Fehler zu erkennen und sich davon zu erholen
- Der Fähigkeit des Modells, Benutzerabsichten langfristig zu verfolgen
Der Wert von PinchBench liegt genau darin, dass es diese Dimensionen quantifiziert und öffentlich darstellt.
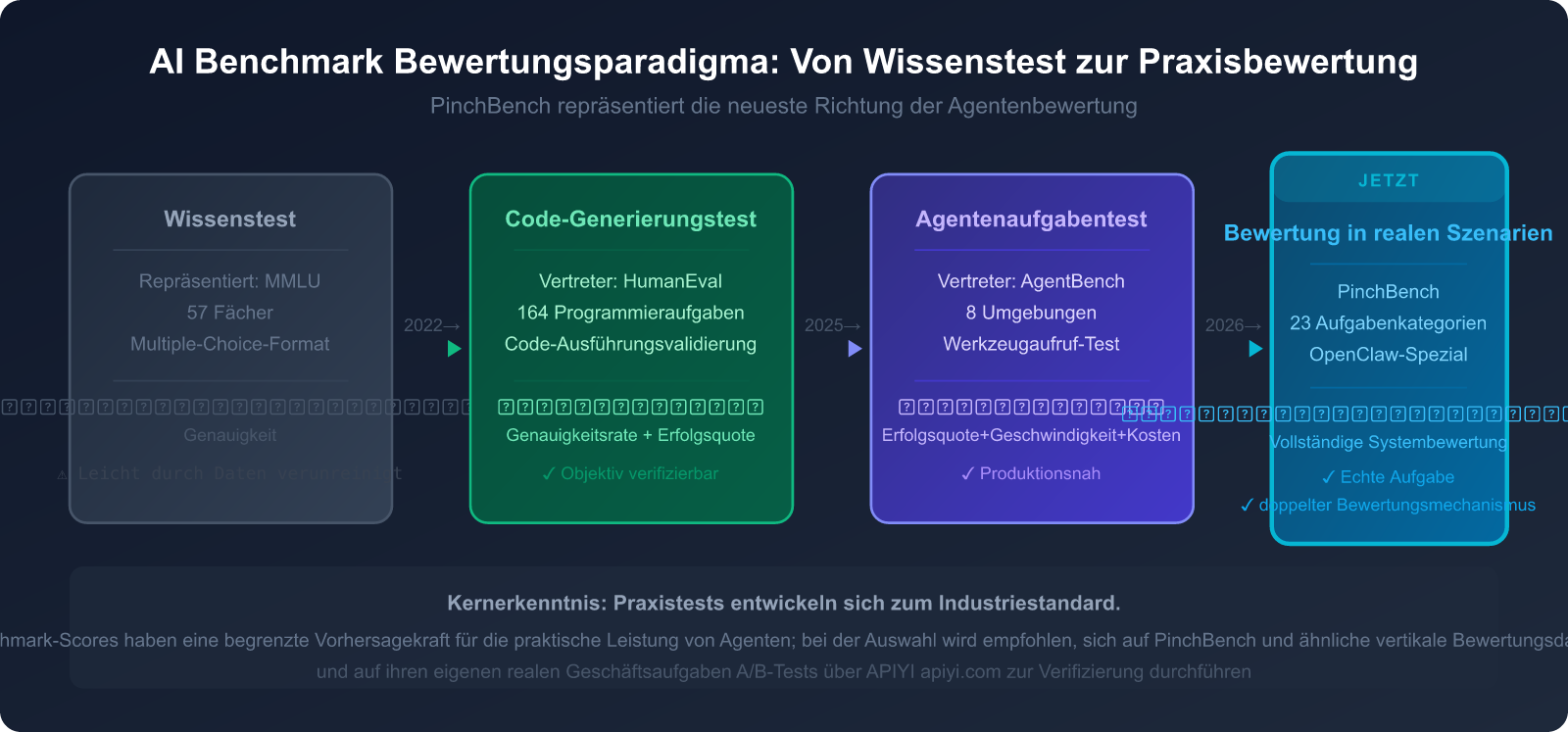
Der richtige Umgang mit AI-Benchmark-Daten
Benchmark-Daten sind wertvoll, können aber auch leicht missbraucht werden. Hier sind einige häufige Missverständnisse und die richtigen Vorgehensweisen:
Missverständnis 1: Das am höchsten platzierte Modell als "immer das Beste" betrachten
Richtige Vorgehensweise: Das Ranking basiert auf einem spezifischen Aufgaben-Set von PinchBench; Ihre Aufgaben könnten eine andere Gewichtungsverteilung haben. Testen Sie zuerst an Ihren eigenen Aufgaben, bevor Sie eine Auswahl treffen.
Missverständnis 2: Nur die Erfolgsrate betrachten und Geschwindigkeit sowie Kosten ignorieren
Richtige Vorgehensweise: Alle drei Dimensionen sind unerlässlich. In Batch-Verarbeitungsszenarien bedeutet ein Geschwindigkeitsunterschied von 50 % eine Kostenersparnis von 50 %; in Echtzeit-Antwortszenarien bedeutet ein Geschwindigkeitsunterschied von 2 Sekunden eine signifikante Verschlechterung der Benutzererfahrung.
Missverständnis 3: Annehmen, dass ein Unterschied von 1 % in der Erfolgsrate unerheblich ist
Richtige Vorgehensweise: Ein Unterschied von 1 % in der Erfolgsrate mag bei kleinen Tests unbedeutend erscheinen, kann aber in hochfrequenten Produktionsszenarien täglich Hunderte von Fehlern verursachen. Sie müssen die tatsächlichen Auswirkungen in Kombination mit Ihrem Aufgabenvolumen bewerten.
Missverständnis 4: Statische Benchmark-Daten für die langfristige Planung verwenden
Richtige Vorgehensweise: AI-Modelle iterieren extrem schnell; im Jahr 2026 veröffentlichen führende Anbieter durchschnittlich einmal pro Quartal wichtige Updates. Es wird empfohlen, die Modellleistungsbewertung in regelmäßige technische Überprüfungen zu integrieren, anstatt "einmal auswählen und für immer festlegen".
Best Practices für die Bewertung von Enterprise-Agenten
Für technische Teams, die OpenClaw oder ähnliche Agenten-Plattformen in Unternehmen einsetzen, ist hier eine Reihe von umsetzbaren Best Practices für die Bewertung:
Schritt 1: Erstellen eines Basis-Aufgaben-Sets
Wählen Sie 20-50 typische Aufgaben aus Ihrem tatsächlichen Geschäft aus, die sowohl alltägliche, häufige Operationen als auch gelegentliche, komplexe Szenarien abdecken. Dieses Aufgaben-Set sollte gemeinsam von der Geschäfts- und Technikseite definiert werden, um Bewertungsabweichungen durch eine rein technische Perspektive zu vermeiden.
Schritt 2: Kontinuierliche Verfolgung dreidimensionaler Metriken
Empfohlene Metrik-System für die interne Agentenbewertung im Unternehmen
Kernmetriken (wöchentlich erfasst):
- Aufgabenabschlussrate: Ziel ≥ 85 % (entspricht dem Niveau der Top-Modelle von PinchBench)
- Fehlerrate bei Tool-Aufrufen: Ziel ≤ 5 %
- Durchschnittliche Aufgabendauer: Definiert gemäß Business-SLA
Sekundäre Metriken (monatlich erfasst):
- Token-Kosten/Aufgabe: Zur Kontrolle der Betriebskosten
- Manuelle Interventionsrate: Anteil der Aufgaben, die manuelle Übernahme erfordern
- Verteilung der Fehlertypen: Zur Analyse von Verbesserungsbereichen
Warnmetriken (Echtzeitüberwachung):
- Fehlerrate bei Hochrisikobetrieben: Sofortige Warnung bei Fehlern wie E-Mail-Versand/Dateilöschung
- Halluzinationsereignisse: Fälle von erfundenen Informationen müssen sofort protokolliert und analysiert werden
Schritt 3: Regelmäßige Neubewertung des Modells
Es wird empfohlen, das aktuell eingesetzte Modell sowie neu veröffentlichte Kandidatenmodelle vierteljährlich mit dem internen Aufgaben-Set neu zu bewerten. Kombinieren Sie dies mit den neuesten öffentlichen Daten von PinchBench, um zu entscheiden, ob ein Upgrade oder ein Modellwechsel erforderlich ist.
Schritt 4: Fachwissen aufbauen
Allgemeine Benchmarks können nicht alle spezifischen Szenarien jedes Unternehmens abdecken. Durch die gesammelte Erfahrung können Sie schrittweise ein Aufgaben-Set und Bewertungsstandards entwickeln, die auf Ihr eigenes Geschäft zugeschnitten sind. Dies wird zu einem wichtigen Auswahlwerkzeug für AI-Anbieter.
🎯 Empfehlung für die Unternehmensauswahl: In der Anfangsphase der Einführung einer Agenten-Plattform wird empfohlen, mehrere Kandidatenmodelle über APIYI apiyi.com auf Pay-as-you-go-Basis zu integrieren.
Führen Sie 3-4 Wochen lang praktische Tests mit Ihrem internen Aufgaben-Set durch, bevor Sie entscheiden, ob Sie zu einem Monatsabonnement wechseln.
APIYI unterstützt eine einheitliche Schnittstelle für gängige Modelle wie Claude, GPT und Gemini.
Während der Testphase ist keine separate Registrierung bei mehreren Anbietern erforderlich, was die Verwaltungskosten für die Bewertung erheblich senkt.
Häufig gestellte Fragen
F: Was ist der Kernunterschied zwischen OpenClaw und AutoGPT, AutoGen?
Der Hauptunterschied von OpenClaw liegt in der Zugangsweise und der Einstiegshürde: Es bietet eine Agent-Oberfläche über Messaging-Apps (Signal, WhatsApp usw.), sodass normale Benutzer keine spezielle App installieren oder technische Details verstehen müssen. Aus technischer Architektursicht ist OpenClaw eher ein "persönlicher KI-Sekretär", während Frameworks wie AutoGen besser für Entwickler geeignet sind, um komplexe Multi-Agenten-Systeme zu erstellen. OpenClaw betont ein "sofort einsatzbereites Verbrauchererlebnis", AutoGen hingegen ein "flexibles Entwicklungsframework für Unternehmen".
🎯 Egal welches Agent-Framework Sie wählen, Sie können über APIYI apiyi.com einheitlich auf Backend-Modelle zugreifen und müssen nicht für jedes Framework separate API-Schlüssel konfigurieren.
F: Wie oft wird das PinchBench-Erfolgsraten-Ranking aktualisiert?
Die PinchBench-Bestenliste wird in Echtzeit aktualisiert – jedes Mal, wenn ein neues Modell bewertet wird, spiegeln sich die Daten sofort auf pinchbench.com wider. Da große Anbieter kontinuierlich neue Versionen veröffentlichen, ändern sich die Rankings häufig. Es wird empfohlen, die neuesten Daten vor einer endgültigen Auswahl zu überprüfen. Die Daten in diesem Artikel basieren auf einem Snapshot vom 13. März 2026 (49 Modelle, 327 Ausführungsaufzeichnungen).
F: Wie wähle ich das am besten geeignete Modell für OpenClaw aus?
Wir empfehlen eine dreistufige Auswahlmethode:
- PinchBench-Erfolgsrate prüfen: Filtern Sie die Top 5 der Aufgabenabschlussraten.
- Geschwindigkeit und Kosten berücksichtigen: Filtern Sie weiter basierend auf Ihrem Aufgabentyp (Echtzeit vs. Batch-Verarbeitung, hohe Frequenz vs. niedrige Frequenz).
- Praktischer A/B-Test: Vergleichen Sie 2-3 Kandidatenmodelle mit Ihren realen Geschäftsaufgaben.
Über APIYI apiyi.com können Sie schnell verschiedene Modelle mit derselben
base_urlwechseln und Ihre endgültige Entscheidung nach Abschluss der A/B-Tests treffen.
F: Können Open-Source-Modelle kommerzielle Modelle, die OpenClaw antreiben, vollständig ersetzen?
Den PinchBench-Daten zufolge beträgt der Unterschied zwischen Nvidia Nemotron-3-Super-120B (85,6 %) und den Top-Kommerzmodellen (86,9 %) etwa 1,3 Prozentpunkte. Für allgemeine Agent-Aufgaben ist dieser Unterschied akzeptabel. Es ist jedoch zu beachten: Die Selbstbereitstellung eines 120B-Parameter-Modells erfordert 4-8 High-End-GPUs, was anfänglich hohe Hardware-Investitionen und Betriebskosten mit sich bringt. Es wird empfohlen, zuerst die Machbarkeit des Agent-Designs mit kommerziellen APIs zu überprüfen und dann zu bewerten, ob sich ein Wechsel zu selbst bereitgestellten Open-Source-Modellen lohnt.
F: Wie können Sicherheitsrisiken bei OpenClaw vermieden werden?
Das Kernprinzip ist die Minimierung der Berechtigungen: Gewähren Sie OpenClaw nur den minimalen Berechtigungsumfang, der zur Erfüllung der Aufgaben erforderlich ist. Konkrete Empfehlungen:
- Nur Lesezugriff auf E-Mails (nicht Vollzugriff zum Lesen, Schreiben, Löschen)
- Nur Lesezugriff auf Code-Repositories + Berechtigung zum Erstellen von Pull Requests (nicht direktes Pushen auf den Hauptzweig)
- Dateisystem auf ein bestimmtes Arbeitsverzeichnis beschränken (nicht das gesamte Dateisystem)
- Hochrisikoreiche Operationen (E-Mails senden, Dateien löschen) müssen einen manuellen Bestätigungsschritt erfordern
Bei der Unternehmensbereitstellung müssen außerdem vollständige Audit-Logs für Operationen konfiguriert werden, um sicherzustellen, dass jede Agent-Operation nachvollziehbar ist.
F: Was ist der Unterschied zwischen PinchBench und anderen Agent-Benchmarks?
Das größte Merkmal von PinchBench ist seine Szenariospezifität: Es wurde speziell für die Anwendungsfälle von OpenClaw entwickelt und ist keine allgemeine Agent-Bewertung. Das bedeutet, dass es für OpenClaw-Benutzer einen höheren Referenzwert hat, aber nicht direkt zur Bewertung der Modellauswahl für andere Agent-Frameworks geeignet ist. Andere bekannte Agent-Benchmarks sind AgentBench (deckt verschiedene Umgebungen ab), SWE-Bench (konzentriert sich auf Code-Aufgaben) usw., die jeweils unterschiedliche Schwerpunkte haben.
Fazit: OpenClaw + PinchBench setzen neue Standards für die Agenten-Ära
OpenClaw hat sich von einem Wochenendprojekt eines österreichischen Entwicklers innerhalb von zwei Monaten zur weltweit beliebtesten KI-Agenten-Plattform entwickelt. Dies spiegelt das starke Verlangen der gesamten Branche wider, dass "KI wirklich etwas tut".
Die Einführung von PinchBench schließt eine entscheidende Lücke im Bereich der Agent-Bewertung: Wir haben endlich ein Werkzeug, das speziell die Fähigkeiten von Agenten misst.
Wichtige Erkenntnisse auf einen Blick:
- Claude Sonnet 4.6 ist derzeit die beste Gesamtwahl für OpenClaw-Szenarien (86,9 % Erfolgsrate, Platz eins im PinchBench-Ranking).
- Die Erfolgsraten der Top-Modelle liegen zwischen 85-87 %, Agent-Aufgaben bleiben eine Herausforderung, fehlertolerantes Design ist unerlässlich.
- Geschwindigkeit und Kosten sind gleichermaßen wichtig, Modelle mit hoher Erfolgsrate sind möglicherweise nicht für alle Szenarien geeignet und erfordern eine dreidimensionale Gesamtbewertung.
- PinchBench repräsentiert die zukünftige Richtung der KI-Bewertung: Reale Szenario-Aufgaben ersetzen synthetische Tests.
- Der Unterschied in der Modellauswahl beträgt etwa 1-2 %, der Einfluss von Aufgabendesign und Eingabeaufforderungs-Engineering ist oft größer.
Für Entwickler und Unternehmen, die tiefer in das OpenClaw-Ökosystem eintauchen möchten, ist jetzt ein ausgezeichneter Zeitpunkt:
Die Open-Source-Community ist aktiv, die Bewertungstools sind ausgereift und die Kosten für den API-Zugriff auf gängige Modelle sinken kontinuierlich. Sie müssen nicht auf die "perfekte Lösung" warten, sondern können ab sofort mit kleinen Aufgaben die Machbarkeit von Agent-Workflows überprüfen.
🎯 Jetzt handeln: Wenn Sie einen auf OpenClaw basierenden KI-Workflow aufbauen, empfehlen wir den einheitlichen Zugriff über APIYI apiyi.com.
Die Plattform unterstützt gängige Modelle wie Claude Sonnet 4.6 (PinchBench Platz eins) und GPT-5.4 (Platz drei).
Mit derselben API-Schnittstelle müssen Sie sich nicht bei mehreren Anbietern separat registrieren, und die nutzungsbasierte Abrechnung ist ideal für den schrittweisen Ausbau, beginnend mit kleinen Tests.
Besuchen Sie die APIYI-Website apiyi.com und registrieren Sie sich, um es auszuprobieren.
Die Daten in diesem Artikel basieren auf öffentlich zugänglichen Informationen vom März 2026. Aktuelle Echtzeitdaten des PinchBench-Rankings finden Sie auf pinchbench.com.
Autor: APIYI Team | Für weitere Informationen zum API-Zugriff auf KI-Modelle besuchen Sie bitte APIYI apiyi.com.