Anmerkung des Autors: GPT-5.4 oder Claude Opus 4.6? Im Jahr 2026 treffen die beiden wichtigsten Flaggschiff-KI-Modelle im direkten Duell aufeinander. Dieser Artikel fasst die neuesten Testergebnisse von Chatbot Arena, SWE-bench, ARC-AGI-2 sowie OpenClaw PinchBench zusammen und bietet klare Empfehlungen in den vier Dimensionen Programmierung, logisches Denken (Reasoning), Agenten-Aufgaben und Preis-Leistungs-Verhältnis.

GPT-5.4 vs. Claude Opus 4.6: Die wichtigsten Unterschiede im Überblick
Bei der Auswahl eines Flaggschiff-KI-Modells sind die entscheidenden Dimensionen auf einen Blick ersichtlich:
| Vergleichsdimension | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Veröffentlichungsdatum | Ende 2025 | Februar 2026 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| KI-Gesamtintelligenz-Index | 57 | 53 |
| API-Eingabepreis | $2.50/M Tokens | $5.00/M Tokens |
| API-Ausgabepreis | $15.00/M Tokens | $25.00/M Tokens |
| Kontextfenster | ~1M Tokens | 200K (1M Beta) |
| Maximale Ausgabelänge | — | 128K Tokens |
| Status | Aktiv | Aktiv |
Fazit: GPT-5.4 weist einen höheren Gesamtintelligenz-Index auf und ist etwa 50 % günstiger. Claude Opus 4.6 belegt weltweit Platz 1 bei der Nutzerzufriedenheit in der Chatbot Arena und glänzt bei komplexer Programmierung sowie Agenten-Aufgaben.
🎯 Schnelle Empfehlung: Wenn Sie ein preisbewusster Entwickler sind, bietet GPT-5.4 das bessere Preis-Leistungs-Verhältnis. Falls Ihr Projekt jedoch komplexe Code-Generierung oder die Verarbeitung langer Dokumente erfordert, ist Opus 4.6 die Investition wert. Wir empfehlen, beide Modelle über APIYI (apiyi.com) zu testen. Die Plattform unterstützt den schnellen Wechsel über eine einheitliche API-Schnittstelle.
Autoritative Benchmarks: GPT-5.4 vs. Claude Opus 4.6 im umfassenden Vergleich
Vergleich der Schlussfolgerungs- und Wissensfähigkeiten
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Beschreibung |
|---|---|---|---|
| GPQA Diamond (Wissenschaft auf Graduiertenniveau) | 93.2% | 91.3% | GPT-5.4 Sieg |
| MMLU (Enzyklopädisches Wissen) | 89.6% | 91.1% | Opus 4.6 Sieg |
| ARC-AGI-2 (Abstraktes Denken) | 52.9% | 68.8% | Opus 4.6 deutlich führend |
| BigLaw Bench (Rechtswissenschaften) | — | 90.2% | Spezialisierter Vorteil für Opus 4.6 |
| MRCR v2 (1M langer Kontext) | — | 76% | Opus 4.6 führend bei ultralangen Dokumenten |
| GDPval-AA ELO (Fachspezifische Aufgaben) | 1462 | 1606 | Opus 4.6 deutlich überlegen |
Interpretation: GPT-5.4 hat einen minimalen Vorteil beim wissenschaftlichen Denken (GPQA Diamond). Claude Opus 4.6 ist jedoch beim abstrakten Denken (16 Prozentpunkte Vorsprung bei ARC-AGI-2), bei professioneller Wissensarbeit und der Verarbeitung langer Kontexte durchweg stärker.
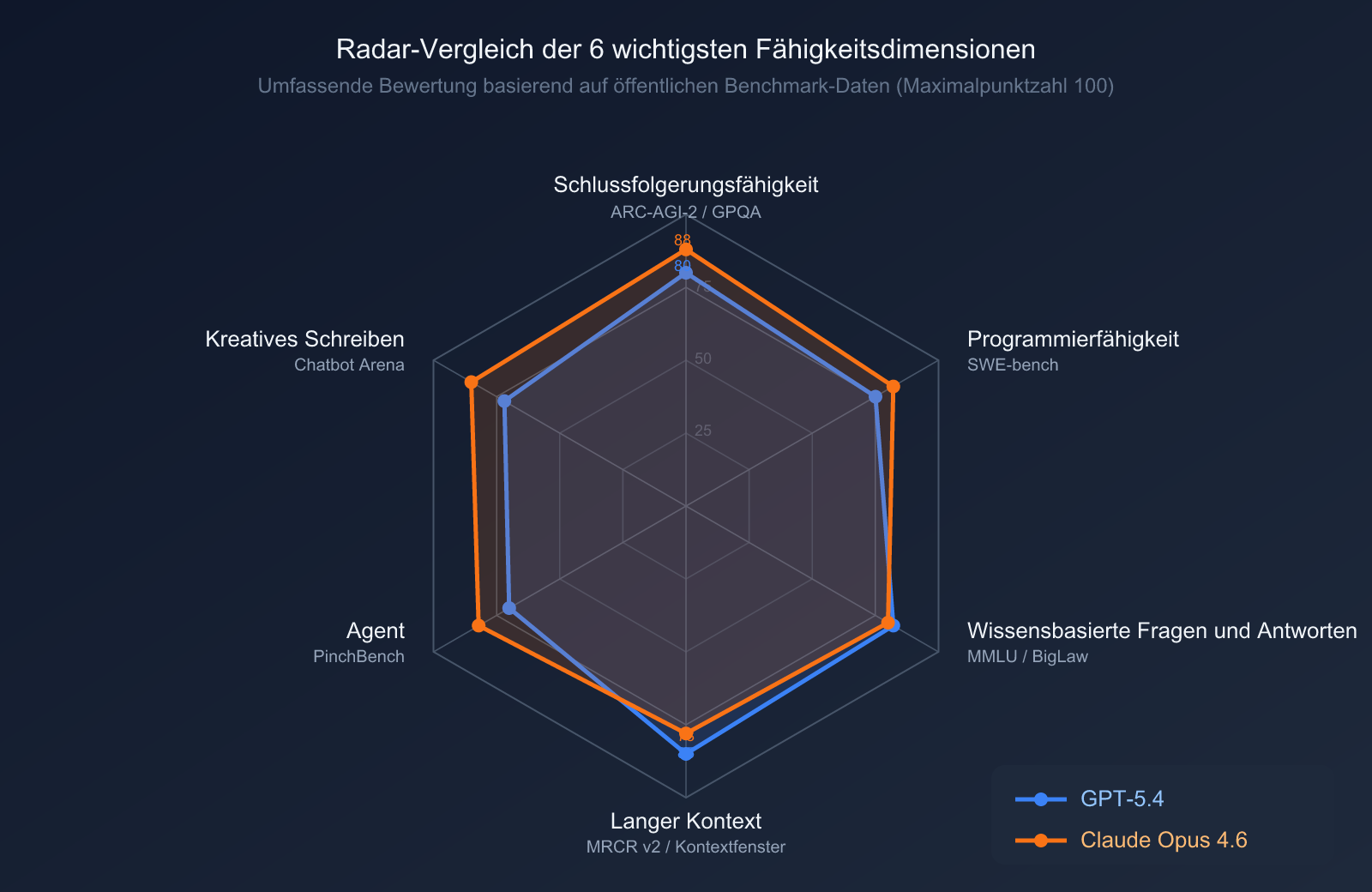
Vergleich der Programmier- und Agenten-Fähigkeiten
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Beschreibung |
|---|---|---|---|
| SWE-bench Verified (Reale Code-Fehlerbehebung) | ~77.2% | 80.8% | Opus 4.6 Sieg |
| SWE-bench Pro (Professioneller Code) | 57.7% | ~45% | GPT-5.4 Sieg |
| Terminal-Bench 2.0 (Terminal-Operationen) | 64.7% | 65.4% | Opus 4.6 knapper Sieg |
| OSWorld (Computersteuerung) | 75.0% | 72.7% | GPT-5.4 knapper Sieg |
| BrowseComp (Websuche & Recherche) | 77.9% | 84.0% | Opus 4.6 Sieg |
| OpenRCA (Ursachenanalyse) | — | 34.9% | Spezialisierter Vorteil für Opus 4.6 |
Interpretation: Beide Modelle setzen unterschiedliche Schwerpunkte in der Programmierung. Bei SWE-bench Verified (alltägliche Code-Fehlerbehebung) ist Opus 4.6 stärker; bei SWE-bench Pro (komplexer Unternehmenscode) führt GPT-5.4. Bei der Computersteuerung liegt GPT-5.4 leicht vorn, während Opus 4.6 bei der Web-Recherche und Ursachenanalyse herausragt.
💡 Entwickler-Tipp: Für Aufgaben zur Code-Generierung in der Produktion empfehlen wir, beide Modelle über die einheitliche Schnittstelle von APIYI (apiyi.com) zu testen. So können Sie basierend auf den Besonderheiten Ihrer Codebasis entscheiden – bei Kosten, die nur etwa 60–80 % der offiziellen APIs von Anthropic oder OpenAI betragen.
OpenClaw AI-Agent in der Praxis: Aktuelle PinchBench-Testergebnisse
Was sind OpenClaw und PinchBench?
OpenClaw ist eine quelloffene, selbst hostbare AI-Agent-Plattform (ähnlich wie Claude Code), die Terminal-Zugriff, das Bearbeiten mehrerer Dateien sowie die Integration mit über 50 Tools wie WhatsApp, Telegram und Slack unterstützt. Sie wurde im November 2025 vom österreichischen Entwickler Peter Steinberger ins Leben gerufen und verzeichnet derzeit ein rasantes Wachstum auf GitHub.
PinchBench ist ein speziell für OpenClaw-Agents entwickelter Benchmark von Kilo.ai. Im Gegensatz zu herkömmlichen Benchmarks, die lediglich einzelne Fragen und Antworten prüfen, testet PinchBench die Leistung von Modellen in realen, mehrstufigen Aufgaben:
- Termine vereinbaren und Kalender verwalten
- Programmierung von Projekten mit mehreren Dateien
- Kategorisierung von E-Mails und Dateiverwaltung
- Web-Recherche und Informationssynthese
Dies ist derzeit einer der Tests, der den tatsächlichen Einsatzszenarien von AI-Agents am nächsten kommt.
PinchBench Rangliste (13. März 2026, 47 Modelle, 277 Durchläufe)
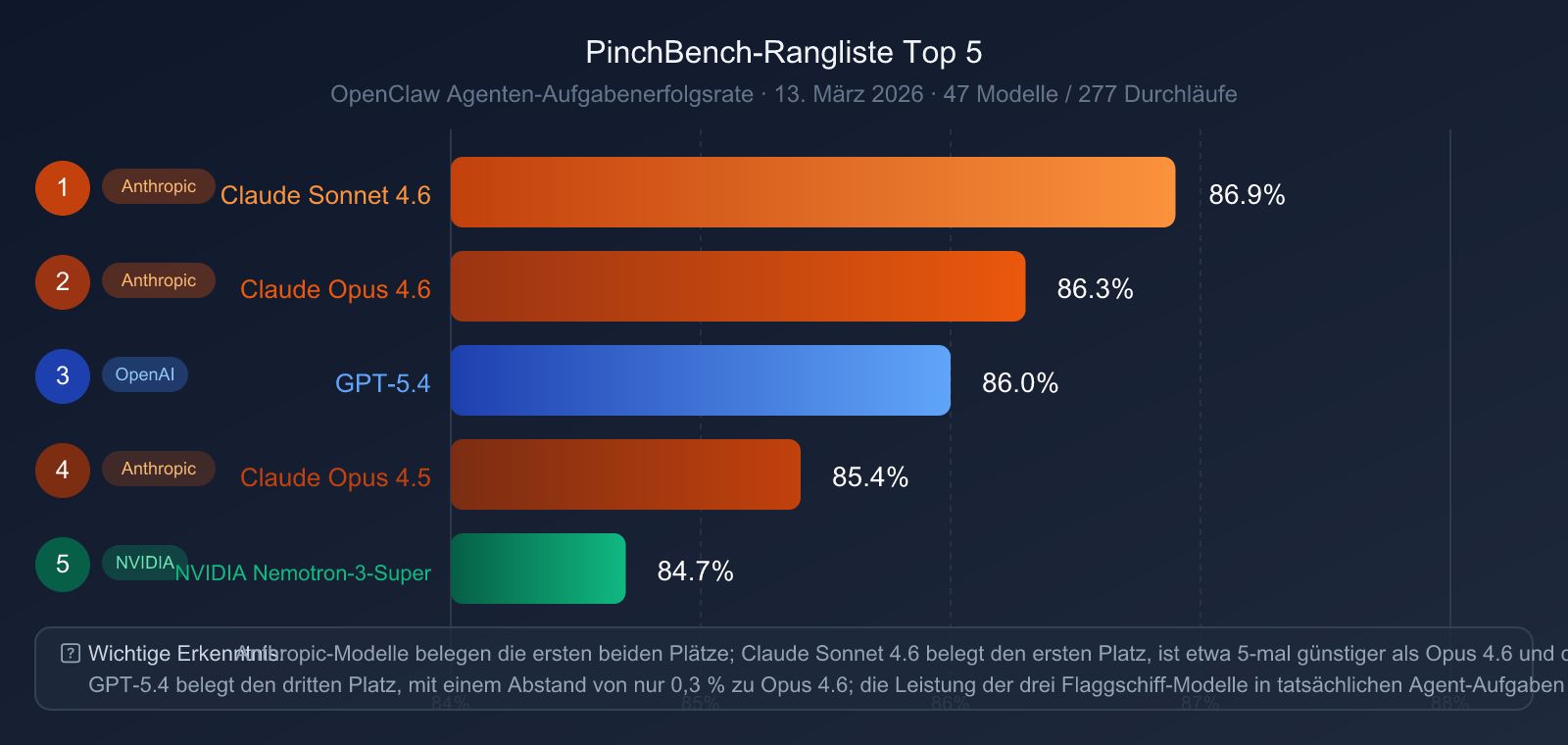
| Rang | Modell | PinchBench Erfolgsquote |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86,9 % |
| 🥈 2 | Claude Opus 4.6 | 86,3 % |
| 🥉 3 | GPT-5.4 | 86,0 % |
| 4 | Claude Opus 4.5 | 85,4 % |
| 5 | NVIDIA Nemotron-3-Super | 84,7 % |
Wichtige Erkenntnisse:
- Claude-Serie dominiert die Spitze: Sonnet 4.6 und Opus 4.6 belegen die Plätze eins und zwei, was den systematischen Vorteil von Anthropic im Bereich Agent-Engineering unterstreicht.
- GPT-5.4 auf Platz drei: Mit einem Rückstand von nur 0,3 Prozentpunkten auf Opus 4.6 ist der Abstand extrem gering.
- Preis-Leistungs-Highlight: Claude Sonnet 4.6 (etwa 5-mal günstiger als Opus 4.6) schneidet bei PinchBench sogar besser ab. Das zeigt: Teurer bedeutet nicht automatisch besser.
- Claude Sonnet 4.6 als Geheimtipp: Für Aufgaben im Stil von OpenClaw-Agents ist Sonnet 4.6 derzeit die effizienteste Wahl.
🔍 Projekt-Empfehlung für Agents: Wenn Sie einen AI-Agent auf Basis von OpenClaw entwickeln, liegen die Top-Drei-Modelle (Sonnet 4.6, Opus 4.6, GPT-5.4) weniger als 1 % auseinander. Wir empfehlen den Zugriff über den API-Proxy-Dienst APIYI (apiyi.com). So können Sie je nach Aufgabentyp dynamisch zwischen den Modellen wechseln, Kosten senken und gleichzeitig eine hohe Erfolgsquote beibehalten.
Chatbot Arena ELO: Die stärksten Modelle, gewählt von echten Nutzern
Die Chatbot Arena (ehemals LMSYS) ist derzeit die renommierteste Rangliste für Nutzerpräferenzen bei KI-Modellen. Die ELO-Scores basieren auf Millionen von Blindtests in echten Dialogen.
Aktuelles Ranking Februar 2026 (Top 5):
| Rang | Modell | ELO-Score |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 liegt mit einem Vorsprung von 40 ELO-Punkten vor GPT-5.4. Besonders in den Bereichen Multi-Turn-Dialoge, Stilkontrolle und kreatives Schreiben sticht es hervor. Dieser Abstand gilt im Bewertungssystem der Chatbot Arena als signifikanter Vorteil.
GPT-4.5 (historische Referenz): Das im Februar 2025 von OpenAI veröffentlichte GPT-4.5 (Codename „Orion“) konzentrierte sich auf emotionale Intelligenz und Dialogqualität und stand kurz nach der Veröffentlichung kurzzeitig an der Spitze der Chatbot Arena. Dieses Modell wurde jedoch bereits am 14. Juli 2025 aus der API entfernt und im August 2025 auch vollständig aus ChatGPT zurückgezogen. GPT-5.4 ist der aktuelle Nachfolger und übertrifft es in allen Belangen.
API-Preise und Preis-Leistungs-Verhältnis: Die richtige Wahl für kostensensible Projekte
| Kostenpunkt | GPT-5.4 | Claude Opus 4.6 | Differenz |
|---|---|---|---|
| Eingabepreis (pro Mio. Tokens) | $2.50 | $5.00 | Opus 4.6 ist 2x teurer |
| Ausgabepreis (pro Mio. Tokens) | $15.00 | $25.00 | Opus 4.6 ist 1,67x teurer |
| Kontextfenster | ~1M Tokens | 200K (1M Beta) | GPT-5.4 gewinnt |
| Maximale Ausgabelänge | — | 128K Tokens | Opus 4.6 gewinnt |
| Multimodale Unterstützung | ✅ Bildeingabe | ✅ Bildeingabe | Gleichwertig |
Kostenschätzung (tägliche Verarbeitung von 1 Mio. Eingabe-Tokens + 200K Ausgabe-Tokens):
- GPT-5.4: ca. $5.50/Tag (monatlich ca. $165)
- Claude Opus 4.6: ca. $10.00/Tag (monatlich ca. $300)
💰 Kosteneffizienz-Strategie: Für Projekte mit hoher Parallelität oder begrenztem Budget empfehlen wir, auf APIYI (apiyi.com) Claude Sonnet 4.6 für Routineaufgaben zu nutzen und den Modellaufruf von Opus 4.6 nur dann zu tätigen, wenn maximale Reasoning-Fähigkeiten erforderlich sind. So lassen sich die API-Kosten um 60-75 % senken. APIYI unterstützt die einheitliche Abrechnung mehrerer Modelle über ein einziges Konto, was ein präzises Kostenmanagement erleichtert.
Szenario-Empfehlung: GPT-5.4 vs. Claude Opus 4.6 – Welches Modell ist die richtige Wahl?
Wann Sie GPT-5.4 bevorzugen sollten
✅ Kosteneffiziente Allround-Aufgaben
- Begrenztes Budget bei gleichzeitigem Bedarf an Flaggschiff-Leistung.
- Tägliche Content-Erstellung, Kundenservice-Bots, Informationsextraktion.
- Signifikante Kosteneinsparungen, wenn die monatlichen Gebühren für den Modellaufruf 500 $ übersteigen.
✅ Wissenschaftliche Forschung und technische Fragen
- Führend bei GPQA Diamond; stärker bei wissenschaftlichem Denken auf Promotionsniveau.
- Fachspezifische Fragen in Bereichen wie Chemie, Physik und Biologie.
✅ Komplexe Programmierung auf Unternehmensebene (führend bei SWE-bench Pro)
- Durchführung von Architektur-Anpassungen in extrem großen Codebases.
- Refactoring-Aufgaben, die ein tiefes Verständnis komplexer Abhängigkeiten erfordern.
✅ Szenarien mit extrem langem Kontext
- Verarbeitung von Dokumenten oder Code-Repositorys mit fast 1 Mio. Token.
- Der 1M-Kontext von Opus 4.6 befindet sich derzeit noch in der Beta-Phase.
Wann Sie Claude Opus 4.6 bevorzugen sollten
✅ Code-Generierung und Bugfixing auf Produktionsniveau
- SWE-bench Verified 80,8 %: Zuverlässiger für tägliche Bugfixes und Feature-Entwicklung.
- BrowseComp 84 %: Starke Web-Recherche-Fähigkeiten, ideal für RAG-gestützte Anwendungen.
✅ Agenten-Projekte im Stil von OpenClaw
- Top-2-Platzierung bei PinchBench: Anthropic-Modelle sind bei realen Agent-Aufgaben systematisch überlegen.
✅ Produkte mit hohen Anforderungen an die Dialogqualität
- Chatbot Arena ELO 1503: Weltweit führend bei der Nutzerzufriedenheit.
- Bessere Kohärenz in Multi-Turn-Dialogen und höhere Anpassungsfähigkeit an verschiedene Stile.
✅ Professionelle Wissensarbeit
- 16 Prozentpunkte Vorsprung bei ARC-AGI-2: Stärkere abstrakte Logik.
- BigLaw Bench 90,2 %: Zuverlässiger für Recht, Compliance und Dokumentenanalyse.
✅ Lange Dokumentenausgabe
- 128K maximaler Output: Geeignet für die Erstellung vollständiger Berichte und langer Dokumente.
🎯 Empfehlung zur Entscheidungsfindung: Beide Modelle haben ihre Stärken, und die Unterschiede zeigen sich vor allem in spezifischen Aufgaben. Wir empfehlen, vor dem offiziellen Rollout A/B-Tests über die Plattform APIYI (apiyi.com) durchzuführen. Die Plattform bietet eine einheitliche Schnittstelle für den schnellen Modellwechsel, damit Sie die optimale Wahl für Ihr Business-Szenario finden.
Schneller Einstieg: Beide Modelle über eine einheitliche API nutzen
Sie müssen keine separaten Konten bei OpenAI und Anthropic registrieren. Über APIYI können Sie mit einer einheitlichen Schnittstelle auf alle gängigen Modelle zugreifen:
from openai import OpenAI
# Über die einheitliche Schnittstelle von APIYI, unterstützt GPT-5.4 und Claude Opus 4.6
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Einheitliche APIYI-Zugriffsadresse
)
# Aufruf von Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Bitte hilf mir, potenzielle Bugs im folgenden Code zu analysieren..."}
],
max_tokens=4096
)
# Aufruf von GPT-5.4 (gleiche Schnittstelle, nur Modellname ändern)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "Bitte hilf mir, potenzielle Bugs im folgenden Code zu analysieren..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 Hinweis zum Anschluss: Setzen Sie die
base_urlaufhttps://vip.apiyi.com/v1und ersetzen Sie denapi_keydurch Ihren bei APIYI (apiyi.com) beantragten Schlüssel. So können Sie mit einem Klick wechseln. Bei der ersten Aufladung gibt es ein Bonusguthaben, ideal um die Unterschiede der beiden Modelle vor dem Live-Gang zu testen.
Modellnamen im Vergleich:
| Modell | API-Aufrufname | Monatliche Durchschnittskosten (100 Mio. Token/Monat) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
ca. 500 $+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
ca. 100 $+ |
| GPT-5.4 | gpt-5-4 |
ca. 250 $+ |
Häufig gestellte Fragen (FAQ)
F: Sind GPT-4.5 und GPT-5.4 dasselbe Modell?
Nein. GPT-4.5 (Codename „Orion“) war ein Übergangsmodell, das OpenAI im Februar 2025 veröffentlichte. Es konzentrierte sich primär auf emotionale Intelligenz und Dialogqualität bei extrem hohen Preisen (75 $ / 150 $ pro 1 Mio. Token) und wurde am 14. Juli 2025 offiziell aus der API entfernt. GPT-5.4 ist das aktuelle Flaggschiff-Modell von OpenAI. Seine Fähigkeiten übertreffen GPT-4.5 in allen Belangen, während der Preis deutlich auf 2,50 $ / 15 $ pro 1 Mio. Token gesunken ist. Wenn Sie das leistungsstärkste OpenAI-Modell nutzen möchten, sollten Sie GPT-5.4 wählen, das über APIYI (apiyi.com) zugänglich ist.
F: Was ist OpenClaw? Wie unterscheidet es sich von Cursor oder Claude Code?
OpenClaw ist eine Open-Source-Plattform für KI-Agenten, die selbst gehostet werden kann. Sie unterstützt Terminal-Zugriff, die Bearbeitung von Code über mehrere Dateien hinweg sowie die Integration von über 50 Tools wie WhatsApp, Telegram und Slack. Zudem besitzt OpenClaw eine „selbst-evolvierende“ Fähigkeit, um neue Skills automatisch zu generieren. Im Vergleich zu Cursor (ein kommerzielles IDE-Plugin) und Claude Code (das offizielle CLI von Anthropic) liegt der Hauptvorteil von OpenClaw in der vollständigen Open-Source-Natur und der Möglichkeit zur privaten Bereitstellung – ideal für Unternehmen mit hohen Anforderungen an die Datensicherheit. PinchBench ist der Benchmark, der speziell die Leistung von KI-Modellen bei Aufgaben innerhalb von OpenClaw-Agenten bewertet.
F: Welches Modell eignet sich am besten für KI-Schreibaufgaben?
Laut dem Chatbot Arena ELO-Rating belegt Claude Opus 4.6 mit 1503 Punkten weltweit den ersten Platz in Nutzertests. Es glänzt besonders bei kreativem Schreiben, mehrstufigen Dialogen und der Anpassung an verschiedene Schreibstile. GPT-5.4 ist ebenfalls hervorragend im Schreiben, liegt jedoch bei der Nutzerzufriedenheit etwas dahinter. Wir empfehlen, Ihre spezifischen Schreibszenarien über APIYI (apiyi.com) individuell zu testen, da verschiedene Stile und Textarten unterschiedliche Ergebnisse liefern können.
F: Wie groß ist der Unterschied zwischen Claude Sonnet 4.6 und Claude Opus 4.6?
Betrachtet man den PinchBench-Agenten-Test, liegt Sonnet 4.6 (86,9 %) sogar leicht vor Opus 4.6 (86,3 %). Im Chatbot Arena ELO-Ranking erreicht Sonnet 4.6 etwa 1438 Punkte, während Opus 4.6 bei 1503 liegt – ein Unterschied von etwa 65 Punkten. Für die meisten Programmier- und Analyseaufgaben ist Sonnet 4.6 die wirtschaftlichere Wahl (der Preis beträgt etwa 20 % von Opus 4.6). Ein Upgrade auf Opus 4.6 lohnt sich nur bei komplexem logischem Schlussfolgern, der Verarbeitung extrem langer Dokumente oder Szenarien mit extremen Präzisionsanforderungen.
Fazit: Welches Flaggschiff-Modell sollten Sie 2026 wählen?
| Szenario | Empfohlenes Modell | Hauptgrund |
|---|---|---|
| Tägliche Entwicklung + Kostenkontrolle | GPT-5.4 | 50 % günstiger, starke Allround-Fähigkeiten |
| Komplexe Code-Fehlerbehebung (SWE-bench) | Claude Opus 4.6 | 80,8 % – führt vor GPT-5.4 (77,2 %) |
| KI-Agenten-Aufgaben (OpenClaw) | Claude Sonnet 4.6 | Platz 1 im PinchBench, günstiger als Opus |
| Dialogprodukte / Nutzerzufriedenheit | Claude Opus 4.6 | Chatbot Arena ELO #1 (1503) |
| Wissenschaftliche Forschung / Akademische Fragen | GPT-5.4 | GPQA Diamond 93,2 % – knapper Vorsprung |
| Analyse extrem langer Dokumente | Claude Opus 4.6 | 128K Output + MRCR v2 76 % |
| Abstraktes Denken / AGI-Aufgaben | Claude Opus 4.6 | ARC-AGI-2 68,8 % vs. 52,9 % |
Wichtige Zusammenfassung:
- GPT-5.4 bietet das beste Preis-Leistungs-Verhältnis. Der allgemeine KI-Intelligenzindex (57 vs. 53) ist leicht überlegen, während der Preis nur etwa halb so hoch ist wie der von Opus 4.6.
- Claude Opus 4.6 ist das Modell mit der weltweit höchsten Nutzerzufriedenheit (ELO 1503) und bietet deutliche Vorteile bei komplexem Code, autonomen Agenten und abstraktem Denken.
- Für die meisten realen Projekte ist Claude Sonnet 4.6 die optimalste Lösung – es belegt den ersten Platz im PinchBench und ist weitaus günstiger als Opus 4.6.
Es gibt kein „objektiv bestes“ Modell, nur das Modell, das am besten zu Ihrem spezifischen Anwendungsfall passt.
🚀 Jetzt testen: Auf der Plattform APIYI (apiyi.com) können Sie mit einem einzigen API-Schlüssel gleichzeitig auf GPT-5.4, Claude Opus 4.6 und Claude Sonnet 4.6 zugreifen. Vergleichen Sie die Leistung und Kosten der drei Modelle direkt mit Ihren eigenen Geschäftsdaten. Neue Nutzer erhalten bei der Registrierung ein Testguthaben, um vor dem Live-Gang die beste Entscheidung zu treffen.
Datenquellen: Offizielle Dokumentationen von Anthropic und OpenAI, Chatbot Arena Ranking (Februar 2026), PinchBench Ranking (13. März 2026), Artificial Analysis Modellvergleich, DigitalApplied Technik-Review. Daten können sich durch Modell-Updates ändern; bitte beachten Sie die jeweils aktuellsten offiziellen Dokumente.
Autor: APIYI Team | Veröffentlicht auf AI123.dev