"Warum hängt Gemini 3.1 Pro Preview schon wieder?" "Was bedeutet dieser 429 RESOURCE_EXHAUSTED Fehler eigentlich?" – Wenn Sie in letzter Zeit die neueste Gemini 3.1 Pro Preview API von Google verwenden, begegnen Ihnen diese beiden Fragen wahrscheinlich täglich. Die Time-to-First-Token (TTFT) beträgt bis zu 41 Sekunden, 429-Fehler treten selbst bei zahlenden Nutzern häufig auf, und die global geteilten Quoten für Preview-Modelle verschärfen den Ressourcenkampf zusätzlich.
Das Problem liegt nicht in Ihrem Code, sondern ist ein verbreitetes Phänomen in der aktuellen Phase von Gemini 3.1 Pro Preview. In den Google AI Developer-Foren und auf GitHub Issues wimmelt es von ähnlichen Feedback-Beiträgen.
Der Kernnutzen: Dieser Artikel bietet kein "Allheilmittel" – denn das gibt es derzeit nicht. Stattdessen zerlegen wir die 5 Hauptursachen für die Verzögerungen und 429-Fehler auf technischer Ebene und teilen 7 von der Community validierte Lösungsansätze, um Ihnen zu helfen, dieses wirklich leistungsstarke Modell in der aktuellen Phase besser zu nutzen.

Wie leistungsstark ist Gemini 3.1 Pro Preview wirklich? Schauen wir uns die Daten an
Bevor wir auf die Probleme eingehen, lohnt es sich zu verstehen, warum dieses Modell die Mühe wert ist. Gemini 3.1 Pro Preview wurde am 19. Februar 2026 veröffentlicht und ist derzeit Googles leistungsstärkstes Reasoning-Modell.
| Metrik | Gemini 3.1 Pro Preview | Vergleichsmaßstab |
|---|---|---|
| ARC-AGI-2 Score | 77,1% (validiert) | Mehr als das Doppelte von Gemini 3 Pro |
| GPQA Diamond | 94,3% | Höchster jemals erreichter Score in diesem Benchmark |
| Benchmark-Ranking | Platz 1 in 12+ von 18 Benchmarks | Codierung, Reasoning, Agenten-Aufgaben |
| Kontextfenster | 1.048.576 Tokens (1M) | Branchenführend |
| Maximale Ausgabe | 65.536 Tokens (64K) | Deutlich höher als bei den meisten Konkurrenten |
| Eingabemodalitäten | Text + Bild + Audio + Video + Code | Nativ multimodal |
| Ausgabegeschwindigkeit | ~108 Tokens/Sekunde | Mittleres Niveau |
| TTFT (First Token) | ~41,54 Sekunden | Median bei vergleichbaren Modellen nur 2,65 Sekunden |
| Preis (Eingabe) | 2,00 $/M Tokens | Mittleres bis hohes Niveau |
| Preis (Ausgabe) | 12,00 $/M Tokens | Höheres Niveau |
| Intelligenz-Index | 57 Punkte | Deutlich über dem Median von 31 Punkten |
Datenquellen: Artificial Analysis (artificialanalysis.ai), offizieller Google-Blog
Zusammengefasst: Gemini 3.1 Pro Preview ist eines der intelligentesten öffentlich verfügbaren Modelle, aber auch eines der langsamsten. Das ist nicht unbedingt ein Nachteil – seine "Langsamkeit" ist teilweise eine bewusste Designentscheidung.
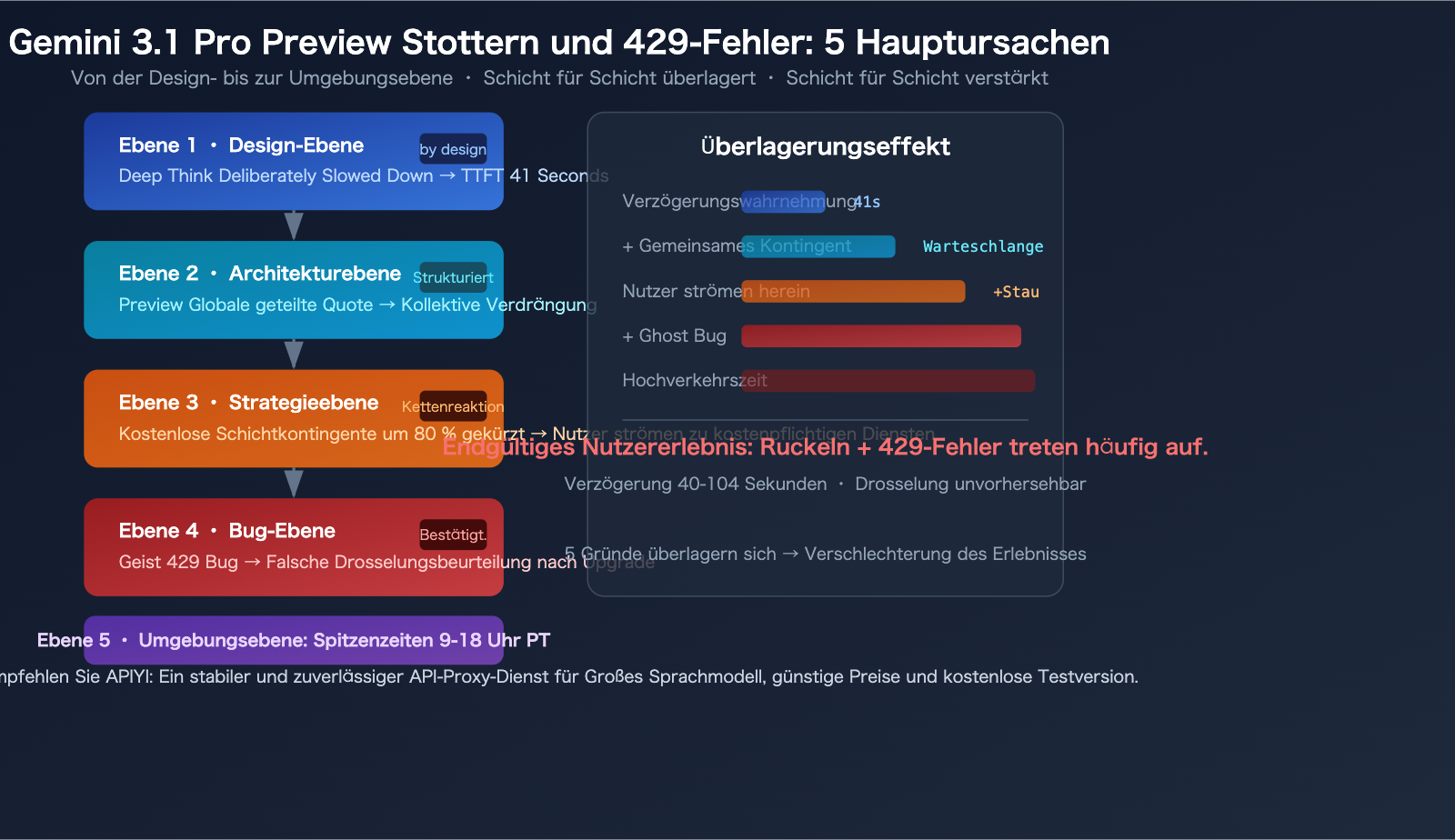
5 Hauptgründe für Verzögerungen bei Gemini 3.1 Pro Preview
Grund 1: Deep Think (Tiefes Nachdenken) – Langsamkeit ist "absichtlich"
Gemini 3.1 Pro Preview führt die "Deep Think"-Funktion ein – das Modell verlangsamt sich bewusst, um tiefergehendes Reasoning zu ermöglichen. Google bietet den Parameter thinking_level mit 4 Stufen an: low, medium (neu), high, max.
Standardmäßig tendiert das Modell dazu, höhere Denkstufen zu verwenden, was direkt zu einer TTFT von 41,54 Sekunden führt – während der Median vergleichbarer Modelle bei nur 2,65 Sekunden liegt, ein Unterschied von über dem 15-fachen.
Anders gesagt: Die 40 Sekunden, die Sie warten, verbringt das Modell nicht mit "Hängen", sondern mit "Denken".
Ein Entwickler hat auf Medium einen Artikel mit dem Titel veröffentlicht: "Gemini 3.1 Pro Isn't Faster, It's Deeper" (Gemini 3.1 Pro ist nicht schneller, sondern tiefer). Es handelt sich um einen philosophischen Kompromiss – Google hat sich entschieden, Geschwindigkeit gegen Reasoning-Tiefe einzutauschen.
Grund 2: Globale, gemeinsam genutzte Quoten für Preview-Modelle
Dies ist der am häufigsten übersehene, aber wirkungsvollste Faktor.
Preview-Modelle verwenden "dynamische, gemeinsam genutzte Quoten" (Dynamic Shared Quota) – alle Nutzer teilen sich einen globalen Kapazitätspool. Das bedeutet, selbst wenn Ihre persönliche Nutzung weit unter Ihrem Limit liegt, können Sie gedrosselt werden, wenn die Gesamtzahl der Anfragen aller anderen Nutzer weltweit zu hoch ist.
Wichtige Unterschiede zwischen Preview- und GA-Modellen (General Availability/Produktionsversion):
| Vergleichsaspekt | Preview-Modell | GA-Modell (Produktionsversion) |
|---|---|---|
| Serverkapazität | Geringer, begrenzte Zuweisung | Ausreichend, bedarfsgerecht skalierbar |
| Quotenmechanismus | Dynamische, gemeinsam genutzte Quote | Individuelle Quote |
| Stabilitätsgarantie | Keine, kann sich jederzeit ändern | Mit SLA garantiert |
| Drosselungsverhalten | Wird auch bei globaler Überlastung ausgelöst | Wird nur bei Überschreitung der persönlichen Quote ausgelöst |
| Verfügbarkeitszeitraum | Kann jederzeit eingestellt werden | Langfristige Wartung |
Dies erklärt eine häufige Verwirrung: "Ich habe mein Limit doch gar nicht überschritten, warum bekomme ich dann einen 429-Fehler?" – Weil die Quote nicht nur Ihre persönliche Nutzung berücksichtigt.
Grund 3: Googles drastische Kürzung der Free-Tier-Limits Ende 2025
Im Dezember 2025 hat Google die Limits für die kostenlose Nutzungsschicht (Free Tier) der Gemini API um bis zu 80 % gekürzt. Obwohl Gemini 3.1 Pro Preview selbst keinen Zugang über die Free Tier bietet (nur für zahlende Nutzer), hat diese Kürzung indirekt dazu geführt, dass viele Entwickler auf die Preview-Modelle der kostenpflichtigen Schichten ausweichen, was den Wettbewerb um Ressourcen verschärft.
Aktuelle Limits der Free Tier (Daten von März 2026):
| Modell | RPM (Anfragen pro Minute) | RPD (Anfragen pro Tag) | TPM (Tokens pro Minute) |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250.000 |
| Gemini 2.5 Flash | 10 | 250 | 250.000 |
| Flash-Lite | 15 | 1.000 | 250.000 |
| Gemini 3.1 Pro Preview | Nicht verfügbar | Nicht verfügbar | Nicht verfügbar |
Zum Vergleich: Bezahlter Tier 1: Gemini 2.5 Flash springt von 10 RPM auf 2.000 RPM – ein Unterschied vom 200-fachen. Aber selbst in der kostenpflichtigen Schicht fühlen sich die tatsächlichen Limits für 3.1 Pro Preview oft "strenger an, als in der Dokumentation angegeben".
Grund 4: Der "Geister-429"-Bug – bekannt, aber nicht vollständig behoben
In den Google Developer Forums wird ein viel diskutierter Bug besprochen: "Ghost 429".
Die Symptome sind: Innerhalb von 24-48 Stunden nach dem Upgrade von der Free Tier auf den bezahlten Tier 1 treten häufig 429 RESOURCE_EXHAUSTED-Fehler auf, selbst wenn das Dashboard eine Nutzung von null oder nahe null anzeigt.
Google hat die Existenz dieses Bugs in den Developer Forums bestätigt und erklärt, dass er durch eine falsche Berechnung des Quotensystems nach einem Account-Upgrade verursacht wird. Die vorübergehende Lösung besteht darin, 24-48 Stunden zu warten, bis sich das System neu kalibriert hat.
Dieser Bug betrifft hauptsächlich:
- Nutzer, die kürzlich von der Free Tier auf Tier 1 upgegradet sind
- Nutzer, die kürzlich ein neues Projekt erstellt und die Abrechnung aktiviert haben
Grund 5: Serverüberlastung zu Stoßzeiten
Gemäß Community-Feedback sind Latenz und 429-Fehlerrate bei Gemini 3.1 Pro Preview in folgenden Zeitfenstern deutlich höher:
- 9:00 AM – 6:00 PM Pacific Time (1:00 – 10:00 Uhr am nächsten Tag, Peking-Zeit)
- Dies fällt genau mit den Hauptarbeitszeiten in den USA zusammen
Während der Stoßzeiten kann die Latenz bei einigen Anfragen sogar 104 Sekunden erreichen, und 503 Service-Unavailable-Fehler treten ebenfalls gelegentlich auf. GitHub Issue #22160 dokumentiert das Problem "extrem hohe Latenz oder keine Antwort bei Verwendung des gemini-3.1-pro-Modells".
🎯 Praktische Erfahrung: Wenn Sie in China die Gemini API nutzen und häufige Verzögerungen erleben, ist neben den oben genannten Gründen auch die Netzwerklatenz ein Faktor. Der Aufruf über Aggregator-Plattformen wie APIYI (apiyi.com) kann optimierte Netzwerkrouten nutzen und einen Teil der Übertragungslatenz reduzieren.
7 Lösungen für Latenz und 429-Fehler bei Gemini 3.1 Pro Preview
Hinweis: Die folgenden Lösungen basieren auf Erfahrungen aus der Entwickler-Community und sind keine offiziellen Google-Empfehlungen. Die Wirksamkeit kann je nach Anwendungsfall variieren, eine vollständige Problemlösung wird nicht garantiert.
Lösung 1: Den thinking_level-Parameter anpassen
Dies ist der direkteste Weg, um die Geschwindigkeit zu erhöhen. Das Setzen von thinking_level auf low kann die TTFT (Time To First Token) erheblich verkürzen:
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI Unified Interface
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "user", "content": "Erkläre Quantencomputing in 3 Sätzen"}
],
extra_body={
"thinking_level": "low" # Optionen: low / medium / high / max
}
)
print(response.choices[0].message.content)
| thinking_level | Geschätzte TTFT | Denktiefe | Anwendungsfall |
|---|---|---|---|
| low | 5-10 Sekunden | Grundlegende Schlussfolgerung | Einfache Fragen, Zusammenfassung, Klassifizierung |
| medium | 15-25 Sekunden | Mittlere Schlussfolgerung | Alltägliche Programmierung, Inhaltsgenerierung |
| high | 30-45 Sekunden | Tiefe Schlussfolgerung | Komplexe Analyse, mathematische Beweise |
| max | 45-100+ Sekunden | Tiefste Schlussfolgerung | Extrem schwierige Aufgaben, Forschungsaufgaben |
Abwägung: low ist schneller, aber die Qualität der Schlussfolgerungen nimmt ab. Wenn du 3.1 Pro gerade wegen seiner tiefen Denkfähigkeit nutzt, könnte die Reduzierung von thinking_level kontraproduktiv sein.
Lösung 2: Client-Seitige Timeouts erhöhen
Die meisten HTTP-Clients und SDKs haben einen Standard-Timeout von 30 Sekunden – aber die normale TTFT von Gemini 3.1 Pro Preview kann bereits über 40 Sekunden betragen. Es wird empfohlen, den Timeout auf mindestens 120 Sekunden zu setzen:
import httpx
import openai
# Timeout auf 120 Sekunden setzen
http_client = httpx.Client(timeout=120.0)
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1",
http_client=http_client
)
Lösung 3: Stoßzeiten vermeiden
Wenn deine Aufgabe keine Echtzeit-Antwort erfordert, versuche, die API zu diesen Zeiten aufzurufen:
- Pazifische Zeit 18:00 – 09:00 Uhr (Peking-Zeit 10:00 Uhr – 01:00 Uhr am nächsten Tag)
- Wochenenden sind in der Regel stabiler als Werktage
- Das RPD (Requests Per Day)-Kontingent wird um Mitternacht Pazifischer Zeit zurückgesetzt
Lösung 4: Downgrade auf Gemini 2.5 Pro / 2.5 Flash
Nicht alle Aufgaben benötigen die Denktiefe von 3.1 Pro. Für Routineaufgaben sind die Gemini 2.5-Modelle immer noch eine zuverlässige Wahl:
- Gemini 2.5 Flash: 10 RPM im Free-Tier, bis zu 2.000 RPM im Paid-Tier, deutlich schneller
- Gemini 2.5 Pro: 5 RPM im Free-Tier, immer noch sehr leistungsfähig
Bei häufigen 429-Fehlern mit 3.1 Pro ist die 2.5-Serie die naheliegendste Downgrade-Option.
Lösung 5: Auf Selbstheilung des "Phantom-429"-Bugs warten
Wenn du gerade vom Free-Tier auf Tier 1 upgegradet oder ein neues Projekt mit aktivierter Abrechnung erstellt hast:
- Warte 24-48 Stunden, bis das Kontingentsystem neu kalibriert ist
- Nutze in der Zwischenzeit andere Modelle oder Plattformen
- Falls das Problem nach 48 Stunden weiterhin besteht, erstelle ein Issue im Google AI Developer Forum
Lösung 6: Modellvariante wechseln, um Drosselung zu umgehen
Ein im Google Developer Forum verifizierter Trick: Auf eine andere Variante derselben Modellreihe wechseln kann manchmal den betroffenen Kontingentpfad umgehen.
Beispiel:
- Falls
gemini-3.1-pro-preview429 meldet, versuche es mitgemini-3.1-flash-preview(falls verfügbar) - Unterschiedliche Modellvarianten können unterschiedliche Kontingentberechnungspfade nutzen
Lösung 7: Drittanbieter-API-Aggregator-Plattform nutzen
Plattformen von Drittanbietern haben in der Regel eigene Kontingentpools, die nicht den globalen, gemeinsam genutzten Kontingentbeschränkungen der offiziellen Google API unterliegen. Dies ist eine Lösung, die in der Community zunehmend von Entwicklern genutzt wird.
Vollständigen Code anzeigen (mit automatischem Downgrade und Wiederholungslogik)
import openai
import time
# Aufruf über APIYI Aggregator-Plattform, unabhängiger Kontingentpool
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# Modell-Fallback-Kette: Stärkstes Modell zuerst, bei 429 automatisch downgraden
model_fallback = [
"gemini-3.1-pro-preview",
"gemini-2.5-pro",
"gemini-2.5-flash",
]
def call_with_fallback(prompt, max_retries=3):
for model in model_fallback:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=120
)
return {
"model": model,
"content": response.choices[0].message.content,
"attempt": attempt + 1
}
except openai.RateLimitError:
wait = 2 ** attempt
print(f"[{model}] 429 Rate Limit, warte {wait}s vor erneutem Versuch...")
time.sleep(wait)
except openai.APITimeoutError:
print(f"[{model}] Timeout, versuche nächstes Modell...")
break
return {"error": "Alle Modelle nicht verfügbar"}
result = call_with_fallback("Analysiere die Rechenkomplexität des Transformer-Attention-Mechanismus")
print(f"Verwendetes Modell: {result.get('model')}")
print(f"Antwort: {result.get('content', result.get('error'))}")
🚀 Empfohlene Lösung: Der Aufruf von Gemini 3.1 Pro Preview und anderen Google-Modellen über die Plattform APIYI (apiyi.com) nutzt deren unabhängige Kontingentpools und Multi-Channel-Routing, um die Wahrscheinlichkeit von 429-Fehlern zu verringern. Bei der Registrierung gibt es kostenloses Guthaben, gleichzeitig wird der einheitliche Aufruf von Modellen mehrerer Anbieter wie Claude, GPT und Gemini unterstützt.

Eine unbeantwortete Frage: Sind Preview-Modelle wirklich sinnvoll einzusetzen?
Eine Frage ohne Standardantwort, aber es lohnt sich für jeden Entwickler, darüber nachzudenken.
Argumente für die Nutzung:
- 3.1 Pro Preview belegt in 12+ von 18 Benchmarks den ersten Platz
- GPQA Diamond mit 94,3 % ist die höchste je erreichte Punktzahl
- Die durch Deep Think ermöglichte Denktiefe ist wirklich einzigartig
- Frühe Anpassung an das neueste Modell verschafft einen First-Mover-Vorteil bei der Veröffentlichung der GA-Version
Argumente gegen die Nutzung:
- TTFT von 41 Sekunden ist für Echtzeit-Interaktionsszenarien ungeeignet
- Häufige 429-Fehler, instabil für Produktionsumgebungen
- Preview-Modelle können jederzeit geändert oder eingestellt werden (Gemini 3 Pro Preview wurde am 09.03.2026 eingestellt)
- Keine SLA-Garantie, bei Problemen bleibt man auf sich allein gestellt
Mittelweg: Verwenden Sie 3.1 Pro Preview in der Entwicklungs- und Testphase, um die Ergebnisse zu validieren. In der Produktionsumgebung setzen Sie die 2.5-Serie oder andere stabile Modelle ein und wechseln erst auf 3.1 Pro, wenn die offizielle Version (GA) veröffentlicht wird.
💡 Praktischer Rat: Wenn Ihre Anwendung tiefgehende Schlussfolgerungen benötigt und hohe Latenzzeiten akzeptabel sind, ist 3.1 Pro Preview einen Versuch wert. Wenn Sie Stabilität und Geschwindigkeit brauchen, ist 2.5 Flash die pragmatischere Wahl. Wir empfehlen, über APIYI apiyi.com mehrere Gemini-Modellversionen gleichzeitig zu integrieren und basierend auf einem Vergleich in realen Szenarien eine Entscheidung zu treffen.
Häufig gestellte Fragen
Q1: Bedeutet der 429 RESOURCE_EXHAUSTED Fehler, dass mein kostenloses Kontingent aufgebraucht ist?
Nicht unbedingt. Der 429-Fehler kann verschiedene Ursachen haben: persönliche Überschreitung der Limits (RPM/RPD/TPM), Überlastung des globalen Shared-Quota-Pools oder der "Phantom-429"-Bug. Insbesondere bei Preview-Modellen, die dynamische Shared-Quotas verwenden, kann es zu Drosselungen kommen, selbst wenn Ihre persönliche Nutzung weit unter dem Limit liegt, aber global Engpässe bestehen. Es wird empfohlen, zunächst in Google AI Studio Ihren tatsächlichen Verbrauch zu prüfen, um zu bestätigen, ob Sie wirklich über dem Limit liegen. Wenn das Dashboard einen sehr niedrigen Verbrauch anzeigt, Sie aber weiterhin 429-Fehler erhalten, liegt die Ursache höchstwahrscheinlich beim Shared-Quota oder einem Bug.
Q2: Löst ein Upgrade auf die kostenpflichtige Tier 1 Stufe das 429-Problem?
Es lindert das Problem, löst es aber nicht vollständig. Die Limits der kostenpflichtigen Stufen sind zwar deutlich höher (z.B. Flash von 10 RPM auf 2.000 RPM), aber der Shared-Quota-Mechanismus für 3.1 Pro Preview gilt auch in den kostenpflichtigen Stufen. Zudem kann es direkt nach dem Upgrade zum "Phantom-429"-Bug kommen, der sich erst nach 24-48 Stunden stabilisiert. Für Szenarien, die höhere Kontingente benötigen, kann die Nutzung von Aggregator-Plattformen wie APIYI apiyi.com helfen, da diese unabhängige Quota-Pools nutzen und so die Wahrscheinlichkeit einer Drosselung verringern.
Q3: Wann wird die offizielle Version (GA) von Gemini 3.1 Pro veröffentlicht?
Google hat noch kein konkretes Datum bekannt gegeben. Geht man nach dem historischen Rhythmus, dauert es von der Preview- bis zur GA-Version normalerweise 2-4 Monate. 3.1 Pro Preview wurde am 19. Februar 2026 veröffentlicht, daher ist optimistisch geschätzt mit der GA-Version Ende Q2 bis Q3 2026 zu rechnen. Die GA-Version wird ein eigenes, nicht geteiltes Kontingent (Non-Shared), SLA-Garantien und eine bessere Serverkapazität bieten. Aktuell können Sie über APIYI apiyi.com kostenlos die Aufrufeffekte der gesamten Gemini-Modellreihe testen.
Zusammenfassung: Mit den "Unvollkommenheiten" von Gemini 3.1 Pro Preview leben
Gemini 3.1 Pro Preview ist ein sehr leistungsfähiges, aber "anspruchsvolles" Modell. Seine Ergebnisse von 94,3 % im GPQA Diamond und 77,1 % im ARC-AGI-2 beweisen, dass seine Denkfähigkeiten derzeit tatsächlich zur Spitze gehören. Allerdings machen eine TTFT von 41 Sekunden und häufige 429-Fehler die tägliche Nutzung zu einer Herausforderung.
Hauptgründe: Designkompromisse bei Deep Think, global geteilte Kontingente für Preview-Modelle und die ökologischen Kettenreaktionen, die durch Googles drastische Kürzungen der kostenlosen Kontingente ausgelöst wurden.
Pragmatischer Umgang:
- Für Aufgaben, die keine tiefgehende Denkleistung erfordern,
thinking_level: "low"setzen oder auf die 2.5-Serie zurückgreifen. - Timeout auf 120+ Sekunden erhöhen, um Fehlinterpretationen als Timeout zu vermeiden.
- Unabhängige Kontingentpools über Drittanbieter-Plattformen (wie APIYI apiyi.com) beziehen.
- Die Verwendung in Produktionsumgebungen auf die Veröffentlichung der GA-Version verschieben.
Diese Probleme werden sich mit hoher Wahrscheinlichkeit in der GA-Version verbessern. Bis dahin können wir nur eines tun: Seine Eigenheiten verstehen und es auf die richtige Art und Weise nutzen.
Autor: APIYI Team | Einheitlicher API-Aufruf für die gesamte Modellreihe von Gemini, Claude und GPT. Besuchen Sie APIYI apiyi.com, um kostenlose Testkontingente zu erhalten.
📚 Referenzen
-
Google offiziell – Gemini API Rate-Limit-Dokumentation: Details zu den Modellkontingenten
- Link:
ai.google.dev/gemini-api/docs/rate-limits - Beschreibung: Vergleichstabelle der RPM/RPD/TPM-Limits für kostenlose und kostenpflichtige Tarife
- Link:
-
Google AI Developer Forum – Diskussionsfaden zu 429-Fehlern: Zusammenfassung der Community-Rückmeldungen
- Link:
discuss.ai.google.dev - Beschreibung: Enthält Bestätigung des "Geister-429"-Bugs und temporäre Lösungsansätze
- Link:
-
GitHub Issue #22160 – Extrem hohe Latenz bei Gemini 3.1 Pro: Entwickler-Feedback
- Link:
github.com/google-gemini/gemini-cli/issues/22160 - Beschreibung: Latenzdaten und Community-Diskussion
- Link:
-
Artificial Analysis – Gemini 3.1 Pro Preview Review: Unabhängige Benchmark-Tests
- Link:
artificialanalysis.ai/models/gemini-3-1-pro-preview - Beschreibung: Objektive Daten zu TTFT, Ausgabegeschwindigkeit, Intelligenzindex usw.
- Link:
-
Vertex AI offizielle Dokumentation – Erklärung des 429-Fehlercodes: Fehlerbehandlung auf der Google Cloud Platform
- Link:
docs.cloud.google.com/vertex-ai/generative-ai/docs/provisioned-throughput/error-code-429 - Beschreibung: Offizielle Klassifizierung der Fehlerursachen und empfohlene Lösungswege
- Link: