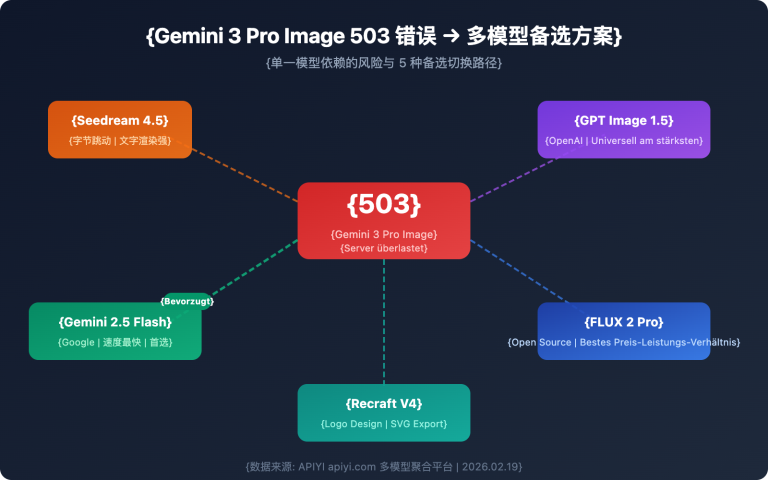
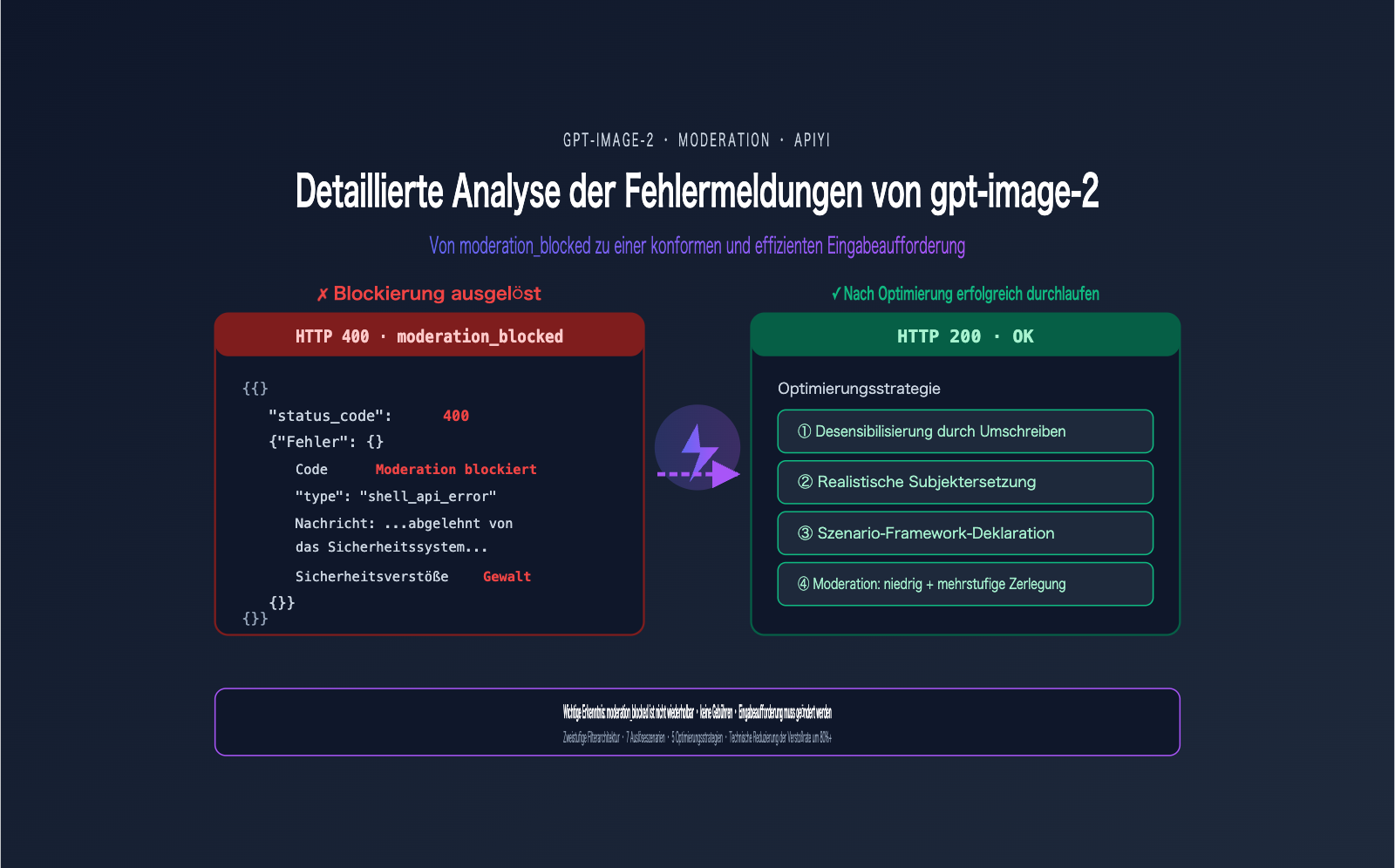
Ein Nutzer erhielt beim Aufruf von gpt-image-2 die folgende Fehlermeldung – eine der häufigsten Fehlermeldungen in der Entwickler-Community seit dem Start von gpt-image-2 im April 2026:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
Viele reagieren instinktiv mit: „Ich füge einfach einen Retry hinzu.“ Aber das ist eine falsche Reaktion – selbst nach 100 Wiederholungen mit demselben Prompt wird die Anfrage erneut blockiert. Der Fehler moderation_blocked bei gpt-image-2 bedeutet im Kern, dass die Anfrage das Modell gar nicht erst erreicht, sondern von einem vorgeschalteten Sicherheitsklassifikator aktiv abgelehnt wurde. Ein erneuter Versuch ist reine Zeitverschwendung.
Dieser Artikel analysiert den realen Fehlerfall, erläutert das Sicherheitsprüfungs-System von gpt-image-2 (einschließlich der Zwei-Phasen-Filterarchitektur), die 7 Hauptszenarien für Auslöser, 5 Strategien zur Optimierung von Eingabeaufforderungen sowie Best Practices für die technische Reduzierung der Fehlerrate in der Produktion. Nach dem Lesen können Sie Ihre Prompt-Vorlagen einer Compliance-Prüfung unterziehen und die Fehlerquote um über 80 % senken.
Interpretation des Fehlers moderation_blocked bei gpt-image-2
Um diesen Fehler zu beheben, müssen Sie zunächst verstehen, was er eigentlich ist. Viele Entwickler halten ihn für eine „Verweigerung des Modells“, was jedoch nicht der Fall ist.
Fakten zum Fehler moderation_blocked bei gpt-image-2
| Fakt | Erklärung | Technische Bedeutung |
|---|---|---|
| HTTP 400 (client-side) | Fehler auf Anfrageebene, kein Serverfehler | Retry ist wirkungslos, Prompt muss geändert werden |
| Anfrage erreichte Modell nicht | Vom vorgeschalteten Klassifikator blockiert | Keine Kosten, kein Token-Verbrauch |
code=moderation_blocked |
Standardisierter Fehlercode, programmatisch erkennbar | Ideal für automatisierte Rewrite-Pipelines |
safety_violations=[…] |
Array listet die verletzten Kategorien auf | Präzise Lokalisierung der zu ändernden Teile |
| 100% Reproduzierbarkeit | Deterministisches Ergebnis, kein Zufallsereignis | Prompt muss umgeschrieben werden |
Die Zwei-Phasen-Sicherheitsprüfung von gpt-image-2
Um den Fehler zu verstehen, muss man die Zwei-Phasen-Sicherheitsfilter-Architektur von OpenAI kennen.
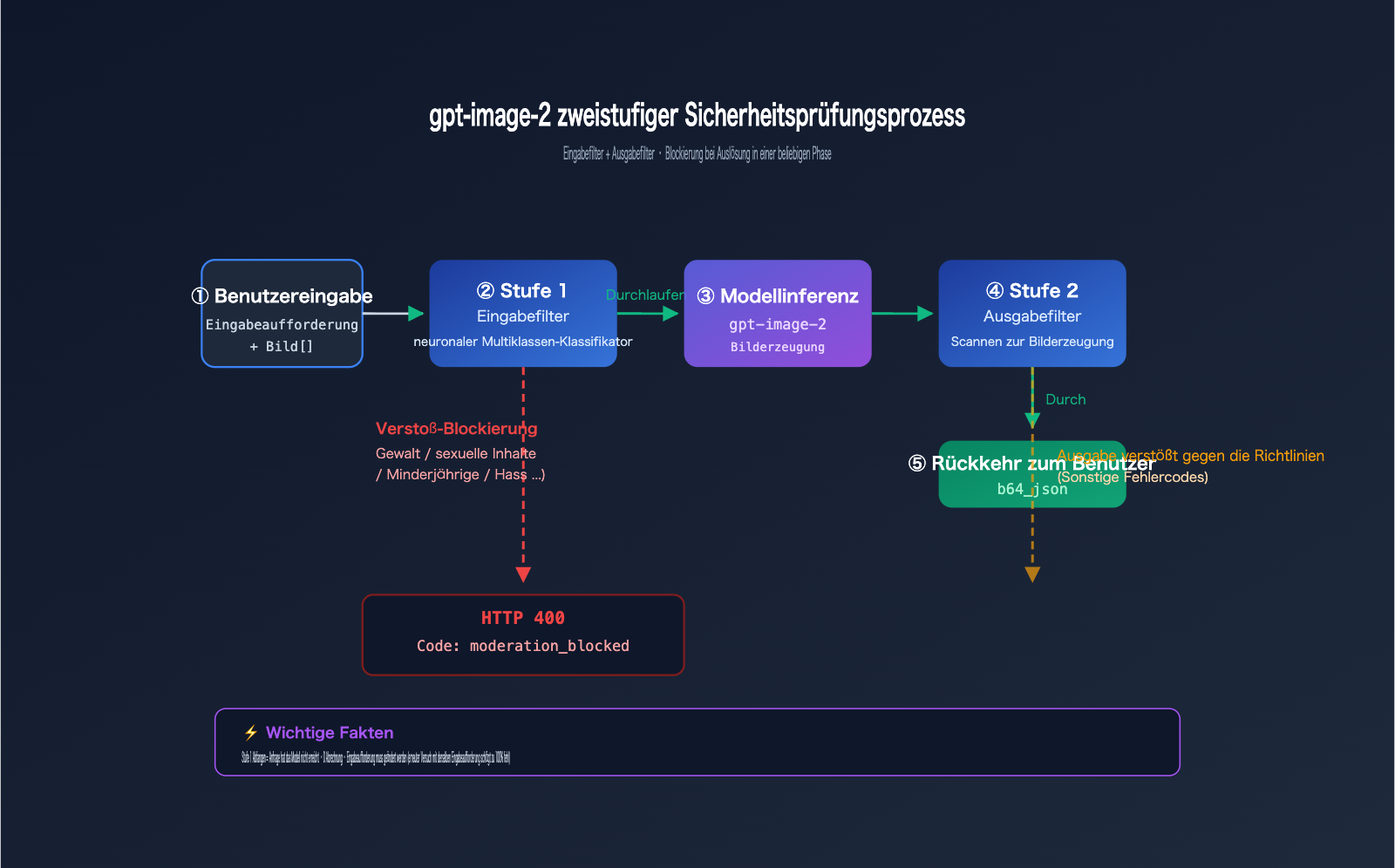
Die gesamte Sicherheitskette besteht aus zwei Stufen:
Stufe 1 · Input Filter (Eingabefilter):
- Scannt Ihren Prompt-Text.
- Scannt alle hochgeladenen Referenzbilder (beim Aufruf von
/v1/images/edits). - Verwendet einen neuronalen Multiklassen-Klassifikator.
- Hier wird
moderation_blockedausgelöst.
Stufe 2 · Output Filter (Ausgabefilter):
- Scannt die bereits vom Modell generierten Bilder.
- Wenn der Inhalt gegen Richtlinien verstößt, kann er dennoch blockiert werden.
- Gibt normalerweise andere Fehlercodes zurück (nicht
moderation_blocked).
Der vom Nutzer gemeldete Fall löste den Stufe 1 Eingabefilter aus, weshalb die Anfrage gar nicht erst in die Modell-Inferenz gelangte. Dies erklärt auch, warum die Fehlermeldung so schnell erfolgt (meist < 1 Sekunde) – die Anfrage wurde nicht in die Warteschlange gestellt und verbrauchte keine GPU-Ressourcen.
Backend-Unterschiede bei gpt-image-2 Fehlern
Ein oft übersehener Fakt: Die Strenge der Prüfung unterscheidet sich je nach Backend-Kanal. Bei identischem Prompt gibt es signifikante Unterschiede zwischen OpenAI-Direktzugriff und Azure OpenAI; Azure ist generell strenger. Deshalb enthält die Fehlermeldung des Nutzers den Hinweis „contact us at Azure support ticket“ – die Anfrage wurde tatsächlich an den Filter des Azure-Backends geleitet.
🎯 Empfehlung zur Kanalauswahl: Wenn Sie denselben Prompt über verschiedene Kanäle testen, ist es normal, dass einige blockiert werden und andere durchgehen. Wir empfehlen, die Validierung über den OpenAI-Proxy-Dienst von APIYI (apiyi.com) durchzuführen. Dieser Kanal nutzt die offiziellen Filterstrategien von OpenAI, was die Fehlerrate mit der von OpenAI-Direktverbindungen konsistent macht und einen einfachen Basisvergleich ermöglicht.
Die 7 Szenarien für Fehlermeldungen bei gpt-image-2 im Überblick
OpenAI hat in der offiziellen System Card für ChatGPT Images 2.0 sieben häufige Auslöseszenarien klar definiert. Das Verständnis dieser sieben Bereiche ist die Grundlage für das Erstellen regelkonformer Eingabeaufforderungen.

Vergleichstabelle der Auslöseszenarien für gpt-image-2-Fehlermeldungen
| Kategorie | Beispiele für risikoreiche Begriffe | Risikostufe |
|---|---|---|
| Violence (Gewalt) | fight, war, weapon, blood, shoot, punch, kill | 🔴 Hoch |
| Violence/Graphic (Grafische Gewalt) | gore, gruesome, mutilation, severed | 🔴 Sehr hoch |
| Sexual (Sexuelle Inhalte) | nude, explicit, suggestive, intimate poses | 🔴 Sehr hoch |
| Hate Symbols (Hasssymbole) | swastika, spezifische extremistische Ikonografie | 🔴 Sehr hoch |
| Self-harm (Selbstverletzung) | suicide, cut wrists, harming oneself | 🔴 Sehr hoch |
| Minors (Darstellung von Minderjährigen) | child + photorealistic Kombination | 🟡 Mittel-Hoch |
| Public Figures (Personen des öffentlichen Lebens) | Politische Persönlichkeiten, Namen von Prominenten | 🟡 Mittel |
| Copyrighted IP (Urheberrechtlich geschützte IP) | Disney-Figuren, Marvel-Charaktere, bekannte IP-Namen | 🟡 Mittel |
| Living Artists (Stil lebender Künstler) | "in the style of [Name des lebenden Künstlers]" | 🟡 Mittel |
Aufschlüsselung der Unterkategorie „Violence“ bei gpt-image-2
safety_violations=[violence] entspricht in der Praxis zwei Unterkategorien, was in der Branche häufig zu Verwirrung führt:
violence → Allgemeine Gewaltbeschreibung (Aktionen, Konflikte, Vorhandensein von Waffen)
violence/graphic → Grafische, blutige Gewaltdetails
Sobald die Eingabeaufforderung eine dieser Unterkategorien auslöst, wird safety_violations=[violence] zurückgegeben. Das bedeutet: Selbst wenn Sie nur eine relativ neutrale Beschreibung wie „ein Soldat mit einem Gewehr“ verwenden, kann dies aufgrund des gesamten Kontextes der Eingabeaufforderung vom Klassifikator der Kategorie „Gewalt“ zugeordnet werden.
Anwender-Fallstudie: Die Grundursache für violence-Fehlermeldungen
Kommen wir zurück zur ursprünglichen Fehlermeldung. Das Feld safety_violations=[violence] signalisiert uns, dass eine Sperre aufgrund von Gewaltinhalten ausgelöst wurde. Aber welches spezifische Wort hat dies verursacht? Im Folgenden finden Sie einen systematischen Diagnoseansatz.
Liste der Auslöser für violence-Fehler bei gpt-image-2
Basierend auf Community-Feedback und Praxistests erhöhen die folgenden Begriffe die Wahrscheinlichkeit einer Sperre durch die Gewalt-Kategorie signifikant (die Liste ist nicht abschließend):
| Art des Auslöseworts | Häufige Verstöße | Sichere Alternativen |
|---|---|---|
| Waffenbegriffe | gun, rifle, sword, knife, weapon | ceremonial prop, movie prop, decorative blade |
| Gewaltaktionen | fight, attack, shoot, stab, punch | dynamic cinematic action, dramatic standoff |
| Kriegskontext | war, battle, soldier, combat | heroic struggle, historical reenactment |
| Blut/Verletzung | blood, wound, scar, gore | red splatter, dramatic shadow, weathered |
| Explosion/Zerstörung | explosion, destruction, debris | dramatic light burst, swirling particles |
Diagnoseprozess für gpt-image-2-Fehler
Wenn Ihr Prompt eine Sperre der Kategorie „violence“ auslöst, gehen Sie bei der Fehlersuche wie folgt vor:
- Explizite Gewaltbegriffe prüfen: Scannen Sie den Prompt auf die oben genannten Auslöser.
- Intensität der Verben prüfen: Versuchen Sie, Aktionsverben wie „fight“ oder „attack“ durch Zustandsbeschreibungen zu ersetzen.
- Referenzbild prüfen (bei Bearbeitungsszenarien): Enthält das hochgeladene Bild selbst gewalttätige Elemente?
- Gesamtkontext prüfen: Selbst ohne einzelne Hochrisikowörter kann die Gesamtdarstellung einer Gewaltszene die Sperre auslösen.
- Rahmenbedingungen hinzufügen: Fügen Sie am Anfang des Prompts Begriffe wie „movie still“ oder „theatrical scene“ hinzu.
Zweck der Request-ID bei gpt-image-2-Fehlern
Die request id: 2026042723155331083492939703753 in der Fehlermeldung ist keine Dekoration – sie ist der einzige Nachweis zur Lokalisierung des Protokolls. Bei einer Anbindung über offizielle Kanäle können Sie sich mit dieser ID an den technischen Support der Plattform wenden, um den genauen Grund der Sperre zu prüfen.
💡 Diagnose-Tipp: Speichern Sie alle
moderation_blocked-Fehler inklusive Request-ID und dem ursprünglichen Prompt. Erstellen Sie eine interne „Datenbank für Verstöße“, um Regeln für die automatische Umschreibung zu trainieren. Wir empfehlen, die Anfrageprotokolle über das APIYI-Dashboard (apiyi.com) zu exportieren, um monatliche Compliance-Audits durchzuführen und die häufigsten Sperrmuster Ihres Teams zu identifizieren.
5 Strategien zur Prompt-Optimierung bei gpt-image-2-Fehlern
Hier sind 5 praxiserprobte Strategien, um die Fehlerrate bei gpt-image-2 zu senken. Die Priorisierung erfolgt von hoch nach niedrig, wir empfehlen die Anwendung in dieser Reihenfolge.
Strategie 1: Entschärfung (Desensitization) bei gpt-image-2-Fehlern
Dies ist die gängigste und effektivste Strategie: Ersetzen Sie risikoreiche Wörter durch visuell äquivalente, neutrale Beschreibungen. Das Kernprinzip lautet: Visuelle Wirkung beibehalten, Gewaltbezug entfernen.
# ✗ Löst violence-Sperre aus
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ Nach Entschärfung erfolgreich
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
Änderungen:
fighting→dramatic standoffswords→ceremonial bladesblood splatter→red light reflectionswar scene→theatrical scene
Strategie 2: Austausch der realen Subjekte bei gpt-image-2-Fehlern
Vermeiden Sie direkte Verweise auf reale Personen des öffentlichen Lebens, Prominente oder urheberrechtlich geschützte Charaktere. Verwenden Sie stattdessen Beschreibungen visueller Merkmale.
# ✗ Löst public_figures oder copyrighted_ip-Sperre aus
- "A portrait of [Name des Stars] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ Sichere Beschreibung
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
Hinweis: Rein „stilistische Beschreibungen“ können bei urheberrechtlich geschützten Charakteren dennoch Sperren auslösen – der Filter bewertet die visuelle Ähnlichkeit, nicht nur den Textabgleich. Es empfiehlt sich, ausreichend „originelle“ Merkmale hinzuzufügen.
Strategie 3: Angabe eines Szenenrahmens bei gpt-image-2-Fehlern
Fügen Sie am Anfang des Prompts einen klaren künstlerischen oder kreativen Rahmen hinzu, um dem Klassifikator zu signalisieren, dass es sich um eine künstlerische Darstellung und nicht um die Realität handelt.
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
Gängige Rahmenbegriffe:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
Strategie 4: Mehrstufige Zerlegung bei gpt-image-2-Fehlern
Komplexe oder risikoreiche Szenen können in mehrere Schritte unterteilt werden:
# Schritt 1: "Stil-Referenzbild" generieren (ohne sensible Elemente)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# Schritt 2: Endbild mit Stilbeschreibung + neutralem Inhalt generieren
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
Dieser Workflow („erst Stil, dann Inhalt“) kann die Sensitivität eines einzelnen Prompts signifikant reduzieren.
Strategie 5: Anpassung des Moderationsparameters bei gpt-image-2-Fehlern
Die API bietet einen moderation-Parameter zur Steuerung der Sensitivität (nur für Bildmodelle der OpenAI-Serie):
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # Standard ist auto, kann auf low gesetzt werden
size="1024x1024",
quality="medium"
)
Wichtiger Hinweis:
moderation: "low"schaltet die Prüfung nicht ab, sondern lockert lediglich die Schwellenwerte.- Extrem gefährliche Inhalte (sexuelle Gewalt, Selbstverletzung, realistische Darstellungen von Minderjährigen, Hasssymbole) werden auch bei „low“ blockiert.
- Wenn nach der Umstellung auf „low“ weiterhin
moderation_blockedauftritt, ist die Grenze definitiv überschritten und der Prompt muss angepasst werden. - Bei Produkten für Endkunden (C-Ende) ist Vorsicht bei der Nutzung von „low“ geboten (Compliance-Risiko).
🚀 Tipp für den schnellen Einstieg: Versuchen Sie zuerst die Strategien 1-3 (Umschreiben + Ersetzen + Rahmenangabe), damit lassen sich über 80 % der
moderation_blocked-Fehler lösen. Wir empfehlen, über die einheitliche Schnittstelle von APIYI (apiyi.com) zunächst mitmoderation: autozu prüfen, ob der Prompt tatsächlich regelkonform ist, bevor Sie entscheiden, ob eine Senkung auf „low“ erforderlich ist.
Praxisvergleich: Optimierung von Fehlermeldungen bei gpt-image-2
Im Folgenden zeigen wir anhand von vier realen Szenarien, wie sich die Optimierung der Eingabeaufforderung konkret auf die Ergebnisse auswirkt.

gpt-image-2 Fehleroptimierung Fall 1: Filmplakat
# ✗ Vor der Optimierung (löst Gewalt-Filter aus)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ Nach der Optimierung
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
gpt-image-2 Fehleroptimierung Fall 2: Charakter-Artwork für Spiele
# ✗ Vor der Optimierung (löst Gewalt-Filter aus)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ Nach der Optimierung
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
gpt-image-2 Fehleroptimierung Fall 3: Historische Bildungsillustration
# ✗ Vor der Optimierung (löst Gewalt-Filter aus)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ Nach der Optimierung
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
gpt-image-2 Fehleroptimierung Fall 4: Werbekonzept
# ✗ Vor der Optimierung (löst Filter für öffentliche Personen aus)
- "[Name der berühmten Person] holding our coffee product in his usual style"
# ✓ Nach der Optimierung
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
Best Practices: Engineering-Ansatz zur Reduzierung von Fehlerraten bei gpt-image-2
Wenn Ihr Projekt täglich Tausende von Aufrufen an gpt-image-2 sendet, ist eine manuelle Überprüfung der Eingabeaufforderung nicht praktikabel. Hier sind einige technische Ansätze, um die Fehlerrate bei gpt-image-2 effektiv zu senken.
Pre-Check-Workflow für gpt-image-2-Fehler
Bevor Sie die Bild-API aufrufen, führen Sie eine Vorabprüfung mit der Moderations-API durch:
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# Schritt 1: Vorabprüfung
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"Eingabeaufforderung löste Vorabprüfung aus: {offending}")
# Schritt 2: Tatsächlicher Modellaufruf
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
Die Vorabprüfung kann 60-70 % der hochriskanten Anfragen abfangen und so ineffektive Aufrufe vermeiden.
Automatisierte Rewrite-Pipeline für gpt-image-2-Fehler
Für die Eingabeaufforderungs-Vorlagen in Ihrer Produktionsumgebung können Sie einen leichtgewichtigen Rewriter erstellen:
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
Intelligentes Retry-Wrapping für gpt-image-2-Fehler
Für eine spezielle Wiederholungsstrategie bei moderation_blocked gilt: Nicht einfach wiederholen, die Eingabeaufforderung muss zuerst umgeschrieben werden:
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # Andere 400-Fehler sollten nicht wiederholt werden
print(f"[{attempt+1}/{max_attempts}] Moderation ausgelöst, wende Entschärfung an...")
current = desensitize(current)
if attempt == max_attempts - 1:
# Letzter Versuch mit moderation: low
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("Alle Rewrite-Strategien sind fehlgeschlagen")
Compliance-Monitoring-Dashboard für gpt-image-2-Fehler
In der Produktionsumgebung müssen die wichtigsten Kennzahlen für jeden Verstoß protokolliert werden:
| Kennzahl | Zweck |
|---|---|
| Verstoßrate (Blockierungen/Gesamtanfragen) | Gesamte Systemgesundheit |
Verteilung der safety_violations-Kategorien |
Identifikation häufigster Verstöße |
| Top 10 der auslösenden Eingabeaufforderungen | Optimierung problematischer Vorlagen |
| Erfolgsrate nach Rewrite | Bewertung der Effektivität des Rewriters |
🎯 Empfehlung für die Produktion: Betrachten Sie die Verstoßrate als zentrale SLO-Kennzahl. Bei einem gesunden System sollte die Verstoßrate < 2 % liegen; Werte > 5 % deuten auf systematische Probleme in den Vorlagen hin. Wir empfehlen, die Anforderungsprotokolle der APIYI-Konsole (apiyi.com) für tägliche Analysen zu nutzen, um häufig betroffene Vorlagen gezielt zu überarbeiten.
FAQ zu gpt-image-2-Fehlern
F1: Werden gpt-image-2-Fehler vom Typ moderation_blocked berechnet?
Nein. Der Sicherheitsfilter blockiert die Anfrage, bevor sie das Modell erreicht, es werden also keine Token oder GPU-Zeit verbraucht. Sowohl OpenAI als auch APIYI befolgen diese Regel. Sollten Sie dennoch Kosten auf Ihrer Abrechnung sehen, kontaktieren Sie umgehend den Plattform-Support. Wir empfehlen, die Kosten für jede request_id über die APIYI-Konsole (apiyi.com) zu prüfen, um sicherzustellen, dass blockierte Anfragen mit 0 berechnet werden.
F2: Warum ist eine Wiederholung mit derselben Eingabeaufforderung bei gpt-image-2 wirkungslos?
Da der Sicherheitsfilter deterministisch arbeitet – das Klassifizierungsergebnis für denselben Input ist stabil und nicht zufällig wie beim Generierungsmodell. 100 Wiederholungen führen zu 100 identischen Blockierungen. Die einzige Lösung ist die Anpassung der Eingabeaufforderung.
F3: Kann moderation: low bei gpt-image-2 die Prüfung vollständig deaktivieren?
Nein. low senkt lediglich den Schwellenwert für die Sensitivität und ist bei moderat sensiblen Inhalten toleranter. Extrem riskante Inhalte (sexuelle Inhalte, Selbstverletzung, realistische Darstellungen von Minderjährigen, Hasssymbole, politische Führungspersönlichkeiten usw.) werden auch bei low blockiert. Es ist ein Irrtum, low als "Ausschalter" zu betrachten.
F4: Warum wurde meine Eingabeaufforderung blockiert, obwohl sie harmlos aussieht?
Dafür gibt es drei Möglichkeiten:
- Kontextuelle Verletzung: Einzelne Wörter sind harmlos, aber die Kombination bildet ein verbotenes Szenario.
- Mehrdeutigkeit: Wörter wie "shoot a photo" können fälschlicherweise als gewalttätig interpretiert werden.
- Backend-Unterschiede: Das Azure-Backend ist oft strenger als die direkte OpenAI-Schnittstelle.
Für den zweiten Fall hilft das Hinzufügen eines Kontextrahmens (z. B. "professional photography session"). Wir empfehlen, solche "Fehlinterpretationen" über APIYI (apiyi.com) in Ihrer internen Wissensdatenbank zu sammeln, um sie als Material für die Iteration Ihrer Vorlagen zu nutzen.
F5: Kann ich sehen, welches spezifische Wort bei gpt-image-2 den Fehler ausgelöst hat?
Die API gibt keine spezifischen Auslösewörter zurück, sondern nur die Kategorie (z. B. [violence]). Dies ist eine bewusste Entscheidung von OpenAI, um die Erstellung von "Umgehungsanleitungen" zu verhindern. Um das auslösende Wort zu finden, hilft eine binäre Suche: Teilen Sie die Eingabeaufforderung in zwei Hälften und testen Sie diese separat.
F6: Was tun bei Verstößen gegen das Referenzbild (Szenarien der Bildbearbeitung)?
Der Endpunkt /v1/images/edits scannt in Stufe 1 sowohl den Text der Eingabeaufforderung als auch alle hochgeladenen Referenzbilder. Wenn das Referenzbild selbst gegen Richtlinien verstößt:
- Prüfen Sie das Bild auf Gewalt, sexuelle Anspielungen oder urheberrechtlich geschützte Charaktere.
- Bearbeiten Sie das Referenzbild lokal vor (Zuschneiden, Unschärfe bei sensiblen Bereichen).
- Bei Fotos von echten Personen: Stellen Sie sicher, dass keine Richtlinien zu Persönlichkeiten des öffentlichen Lebens verletzt werden.
F7: Sind die Kategorien bei gpt-image-2 identisch mit denen der OpenAI Moderations-API?
Sie sind weitgehend ähnlich, aber nicht identisch. Die Moderations-API bietet detailliertere Kategorien (11), während die Bildgenerierung gröber filtert (7-9). Nutzen Sie die Moderations-API als Vorab-Tool, aber gehen Sie nicht davon aus, dass die Ergebnisse zu 100 % deckungsgleich sind – manchmal lässt die Moderations-API eine Eingabeaufforderung durch, während die Bild-API sie blockiert.
F8: Kann man gegen gpt-image-2-Fehler Einspruch einlegen?
Ja, aber mit begrenztem Erfolg. Die request_id in der Fehlermeldung kann verwendet werden, um den technischen Support zu kontaktieren. Praxiserfahrung: Bei echten Fehlinterpretationen (z. B. neutrale Inhalte für medizinische/pädagogische Zwecke) kann eine Whitelist-Aufnahme erfolgen; bei tatsächlichen Verstößen ist ein Einspruch wirkungslos. Wir empfehlen, Einsprüche über das APIYI-Ticketsystem (apiyi.com) unter Angabe der vollständigen request_id und des Geschäftsszenarios einzureichen, um die Bearbeitung zu beschleunigen.
Zusammenfassung: Von der gpt-image-2-Fehlermeldung zur regelkonformen und effizienten Eingabeaufforderung
Nachdem Sie die 7 Kapitel dieses Artikels durchgearbeitet haben, sollten Sie das vollständige System zur Fehlerbehandlung bei gpt-image-2 beherrschen:
- ✅ Das Wesen verstehen ——
moderation_blockedist ein 400-Fehler auf Anforderungsebene, der nicht berechnet wird und nicht wiederholt werden kann. - ✅ Die Architektur beherrschen —— Zweistufige Sicherheitsprüfung (Stufe 1: Eingabefilterung + Stufe 2: Ausgabefilterung).
- ✅ Auslöseszenarien kennen —— 7 Hauptkategorien für Verstöße sowie Details zu Unterkategorien wie Gewalt.
- ✅ Verstöße diagnostizieren —— Präzise Lokalisierung durch das Feld
safety_violations. - ✅ 5 Optimierungsstrategien —— Entschärfung durch Umschreiben, Austausch von Subjekten, Rahmenbedingungen definieren, mehrstufige Zerlegung, Moderationsparameter.
- ✅ Engineering-Lösungen —— Vorabprüfung, automatisches Umschreiben, intelligentes Retry-Verhalten, Compliance-Monitoring.
Die wichtigste Erkenntnis: Die Fehlermeldung moderation_blocked bei gpt-image-2 ist kein Fehler (Bug), sondern die Compliance-Grenze des Produkts. Anstatt sich über die Strenge zu beschweren, sollten Sie "Compliance-Prompt-Engineering" als produktive Fähigkeit begreifen – dies ist eine der Kernkompetenzen für den erfolgreichen Einsatz von KI-Produkten im Endkundenbereich.
Wenn Ihr Team häufig mit moderation_blocked-Fehlern konfrontiert ist, einen Compliance-Audit-Prozess für Eingabeaufforderungen in der Produktionslinie etablieren muss oder die Fehlerrate durch technische Lösungen senken möchte, empfehlen wir, direkt über APIYI (apiyi.com) einen Test-API-Schlüssel zu beantragen. Führen Sie die Code-Vorlagen für Vorabprüfung und automatisches Umschreiben aus diesem Artikel aus. Alle Beispiele basieren auf dem offiziellen SDK und dem API-Proxy-Dienst von APIYI (die Felder sind zu 100 % mit OpenAI identisch), was eine hohe Kompatibilität gewährleistet und eine direkte Übernahme in Ihre eigenen Projekte ermöglicht.
Referenzen
-
OpenAI ChatGPT Images 2.0 System Card: Offizielle Erläuterung der Sicherheitsrichtlinien und Blockierungsmechanismen.
- Link:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - Hinweis: Enthält die zweistufige Filterarchitektur und eine vollständige Liste der Verstoßkategorien.
- Link:
-
OpenAI Moderations API Dokumentation: Offizieller Leitfaden für Vorabprüfungstools.
- Link:
developers.openai.com/api/docs/guides/moderation - Hinweis: 11 Verstoßkategorien und Methoden für den API-Aufruf.
- Link:
-
OpenAI Usage Policies: Verbindliche Erläuterung der Nutzungsrichtlinien.
- Link:
openai.com/policies/usage-policies/ - Hinweis: Verbotene Verwendungszwecke, Haftung und Compliance-Anforderungen.
- Link:
-
OpenAI GPT Image Models Prompting Guide: Offizielle Best Practices für Eingabeaufforderungen.
- Link:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - Hinweis: Enthält regelkonforme Schreibweisen für Eingabeaufforderungen und Fallbeispiele.
- Link:
-
APIYI gpt-image-2 Integrationsdokumentation: Vollständiger Leitfaden zur Integration (auf Chinesisch).
- Link:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - Hinweis: Enthält detaillierte Erklärungen zu Moderationsparametern und Fehlercodes.
- Link:
Autor: APIYI Technik-Team
Veröffentlichungsdatum: 27. April 2026
Schlagworte: gpt-image-2 Fehler, moderation_blocked, safety_violations, Inhaltsprüfung, Prompt-Optimierung, APIYI, OpenAI Compliance