一位用户在调用 gpt-image-2 时收到了下面这个报错——这是 2026 年 4 月 gpt-image-2 上线以来开发者社区最高频的报错之一:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
很多人第一反应是「我加个重试就好了」。但这是个错误的反应——同一个 prompt 重试 100 次仍然会被拦截。gpt-image-2 报错 moderation_blocked 的本质是请求根本没有到达模型,而是被前置的安全分类器主动拒绝,重试只是在浪费时间。
本文从这个真实报错案例出发,系统拆解 gpt-image-2 安全审核机制(含两阶段过滤架构)、7 大触发场景全景、5 种 prompt 优化策略,以及工程化降低 gpt-image-2 报错率的生产实践。读完后你能立即对自己的 prompt 模板做合规审计,把违规率降低 80% 以上。

gpt-image-2 报错 moderation_blocked 的本质解读
要解决这个报错,必须先理解它到底是什么。很多开发者把它当成"模型拒绝回答",其实完全不是。
gpt-image-2 报错 moderation_blocked 的关键事实
| 事实 | 说明 | 工程含义 |
|---|---|---|
| HTTP 400(client-side) | 请求级错误,不是服务端故障 | 重试无效,必须改 prompt |
| 请求未达模型 | 被前置分类器拦截 | 不会扣费、不会消耗 token |
code=moderation_blocked |
标准化错误码,可程序化识别 | 适合写自动重写流水线 |
safety_violations=[…] |
数组列出触发的违规类别 | 精准定位需要修改的部分 |
| 同 prompt 100% 复现 | 结果是确定的,不是概率事件 | 必须改写 prompt 才能恢复 |
gpt-image-2 报错的两阶段安全审核机制
理解 gpt-image-2 报错必须先看清 OpenAI 的两阶段安全过滤架构。
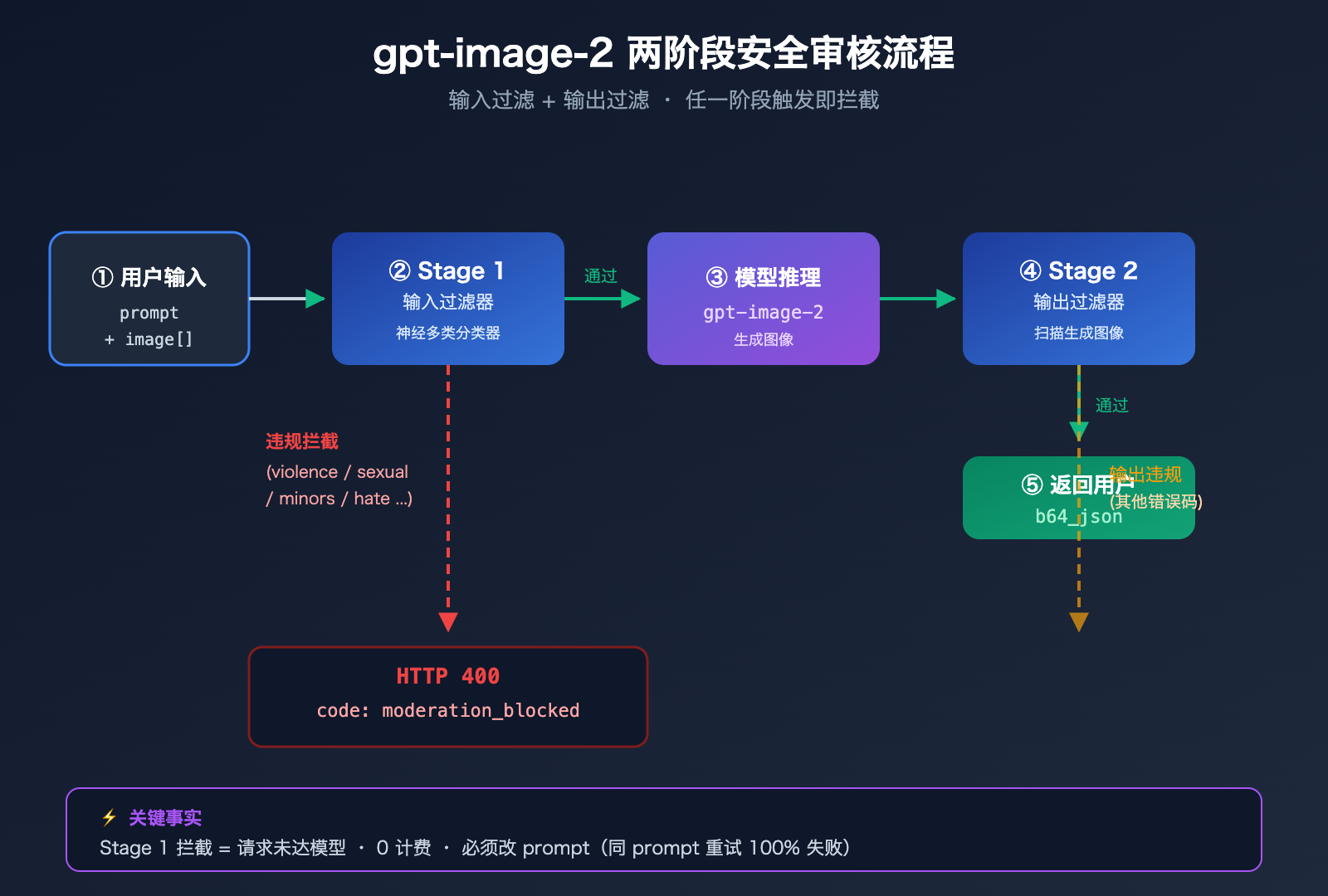
整个安全链路实际上有两道关卡:
Stage 1 · Input Filter(输入过滤器):
- 扫描你的 prompt 文本
- 扫描所有上传的参考图(如果调用
/v1/images/edits) - 使用神经多类分类器(multi-class neural classifier)
- 这就是触发
moderation_blocked的地方
Stage 2 · Output Filter(输出过滤器):
- 扫描模型已经生成的图像
- 如果生成内容违规,仍可能被拦截
- 通常返回不同的错误码(不是
moderation_blocked)
用户提供的案例触发的是 Stage 1 输入过滤,所以根本没有进入模型推理阶段。这也解释了为什么这种错误响应非常快(通常 < 1 秒)——它根本没排队、没占用 GPU。
gpt-image-2 报错的 Backend 差异
一个容易被忽略的事实:不同后端通道的审核严格度不同。OpenAI 直连 vs Azure OpenAI 在相同 prompt 下,触发率会有显著差异,Azure 普遍更严格。这就是为什么用户案例报错信息中显示「contact us at Azure support ticket」——这条请求实际上路由到了 Azure 后端的过滤器。
🎯 通道选择建议:如果你正在为同一个 prompt 在不同渠道测试,遇到部分渠道拦截、部分通过的情况是正常现象。我们建议通过 API易 apiyi.com 的 OpenAI 官转通道进行验证,该通道走 OpenAI 官方过滤策略,触发率与 OpenAI 直连一致,便于做基线对比。
gpt-image-2 报错的 7 大触发场景全景
OpenAI 在公开的 ChatGPT Images 2.0 System Card 中明确列出了 7 类高频触发场景。理解这 7 大场景是写出合规 prompt 的基础。

gpt-image-2 报错触发场景完整对照表
| 类别 | 高风险触发词举例 | 风险等级 |
|---|---|---|
| Violence(暴力) | fight、war、weapon、blood、shoot、punch、kill | 🔴 高 |
| Violence/Graphic(图形化暴力) | gore、gruesome、mutilation、severed | 🔴 极高 |
| Sexual(性内容) | nude、explicit、suggestive、intimate poses | 🔴 极高 |
| Hate Symbols(仇恨符号) | swastika、specific extremist iconography | 🔴 极高 |
| Self-harm(自残) | suicide、cut wrists、harming oneself | 🔴 极高 |
| Minors(未成年人写实描绘) | child + photorealistic 组合 | 🟡 中-高 |
| Public Figures(公众人物) | 政治人物、名人姓名 | 🟡 中 |
| Copyrighted IP(版权 IP) | 迪士尼角色、漫威角色、知名 IP 名字 | 🟡 中 |
| Living Artists(在世艺术家风格) | "in the style of [living artist name]" | 🟡 中 |
gpt-image-2 报错的 violence 子类别拆解
safety_violations=[violence] 实际上对应两个细分类别,行业里很多人会混淆:
violence → 一般暴力描述(动作、冲突、武器存在)
violence/graphic → 图形化、血腥的暴力细节
只要 prompt 触发其中任意一个子类别,都会返回 safety_violations=[violence]。这意味着即使你只是写「a soldier with a rifle」这种相对中性的描述,也可能因为 prompt 整体语境被分类器判为 violence 大类。
用户案例深度解读:violence 报错的根本原因
回到开头的真实报错。safety_violations=[violence] 这个字段告诉我们触发了暴力类拦截,但到底是哪个具体词触发的?下面给出系统化的诊断思路。
gpt-image-2 报错的 violence 触发词清单
根据社区反馈和实测,以下词汇会显著提升 violence 类拦截率(不限于这些):
| 触发词类型 | 高频违规词 | 安全替代方案 |
|---|---|---|
| 武器名词 | gun, rifle, sword, knife, weapon | ceremonial prop, movie prop, decorative blade |
| 暴力动作 | fight, attack, shoot, stab, punch | dynamic cinematic action, dramatic standoff |
| 战争语境 | war, battle, soldier, combat | heroic struggle, historical reenactment |
| 流血/伤害 | blood, wound, scar, gore | red splatter, dramatic shadow, weathered |
| 爆炸破坏 | explosion, destruction, debris | dramatic light burst, swirling particles |
gpt-image-2 报错的诊断流程
如果你的 prompt 触发了 violence 类拦截,按下面的顺序排查:
- 检查显式暴力词:扫描 prompt 中是否含上述触发词
- 检查动词强度:尝试把 fight/attack 这类动作动词替换为状态描述
- 检查参考图(如果是编辑场景):上传的图片本身是否含暴力元素
- 检查整体语境:即使没有单个高危词,整体描述若构成暴力场景仍会触发
- 尝试加入框架声明:在 prompt 开头加 "movie still" / "theatrical scene"
gpt-image-2 报错的请求 ID 用途
报错信息里的 request id: 2026042723155331083492939703753 不是装饰——它是定位日志的唯一凭证。如果通过合规渠道接入,可凭这个 ID 联系平台技术支持核查具体拦截原因。
💡 诊断建议:保存所有 moderation_blocked 报错的 request ID 和原始 prompt,建立内部"违规样本库"用于训练自动重写规则。我们建议通过 API易 apiyi.com 控制台导出请求日志,做月度合规审计,识别出本团队最高频的拦截模式。
gpt-image-2 报错的 5 种 prompt 优化策略
下面给出经过实战验证的 5 种降低 gpt-image-2 报错率的策略。优先级从高到低,建议按顺序应用。
策略 1:gpt-image-2 报错的 Prompt 降敏重写(Desensitization)
这是最常用、效果最好的策略——把高风险词替换为视觉等价的中性描述。核心原则是保留视觉效果,去除暴力指向。
# ✗ 触发 violence 拦截
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ 降敏重写后通过
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
变化点:
fighting→dramatic standoffswords→ceremonial bladesblood splatter→red light reflectionswar scene→theatrical scene
策略 2:gpt-image-2 报错的真实主体替换
避免直接引用真实公众人物、名人、版权角色,改用视觉特征描述。
# ✗ 触发 public_figures 或 copyrighted_ip 拦截
- "A portrait of [明星姓名] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ 安全描述
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
注意:完全的"风格描述"在版权角色场景仍可能触发——审核器会基于视觉相似度判断,不只是文字匹配。建议加入足够的"原创"特征。
策略 3:gpt-image-2 报错的场景框架声明
在 prompt 开头加上明确的艺术/创作框架,向分类器表明这是创作而非现实。
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
常用的框架词:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
策略 4:gpt-image-2 报错的多步分解
复杂、高风险场景可以拆分成多个步骤完成:
# 第一步:生成"风格参考图"(不含敏感元素)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# 第二步:用风格描述 + 中性内容生成最终图
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
这种「先风格、后内容」的工作流能显著降低单次 prompt 的敏感度。
策略 5:gpt-image-2 报错的 moderation 参数调整
API 提供了 moderation 参数控制敏感度(仅适用于 OpenAI 系图像模型):
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # 默认 auto,可降为 low
size="1024x1024",
quality="medium"
)
重要提醒:
moderation: "low"不是关闭审核,只是放宽阈值- 极端高危内容(性、自残、未成年人写实、仇恨符号)即使 low 也会被拦截
- 调到 low 后仍触发
moderation_blocked说明真的越线了,必须改 prompt - 在面向 C 端用户的产品中慎用 low(合规风险)
🚀 快速上手建议:先尝试策略 1-3(重写 + 替换 + 框架声明)能解决 80% 以上的 moderation_blocked 报错。我们建议通过 API易 apiyi.com 的统一接口先用
moderation: auto验证 prompt 是否真的合规,再决定是否需要降到 low。
gpt-image-2 报错优化前后的实战对比
下面用 4 个真实场景演示 prompt 优化的具体效果。

gpt-image-2 报错优化案例 1:电影宣传海报
# ✗ 优化前(触发 violence)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ 优化后
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
gpt-image-2 报错优化案例 2:游戏角色立绘
# ✗ 优化前(触发 violence)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ 优化后
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
gpt-image-2 报错优化案例 3:历史教育插图
# ✗ 优化前(触发 violence)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ 优化后
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
gpt-image-2 报错优化案例 4:商业广告概念图
# ✗ 优化前(触发 public_figures)
- "[名人姓名] holding our coffee product in his usual style"
# ✓ 优化后
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
工程化降低 gpt-image-2 报错率的最佳实践
如果你的项目每天调用 gpt-image-2 数千次,靠人工审 prompt 不现实。下面是几种工程化降低 gpt-image-2 报错率的做法。
gpt-image-2 报错的预校验流程
在调用图像 API 之前,先用 Moderations API 做一次预校验:
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# Step 1: 预校验
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"prompt 触发预校验: {offending}")
# Step 2: 实际调用
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
预校验能拦下 60-70% 的高危请求,避免无效调用。
gpt-image-2 报错的自动重写流水线
针对生产线的 prompt 模板,可以构建一个轻量重写器:
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
gpt-image-2 报错的智能重试封装
针对 moderation_blocked 的特殊重试策略——不能原样重试,必须先重写 prompt:
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # 其他 400 错误不应重试
print(f"[{attempt+1}/{max_attempts}] 触发审核,应用降敏重写...")
current = desensitize(current)
if attempt == max_attempts - 1:
# 最后一次尝试加 moderation: low
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("所有重写策略均失败")
gpt-image-2 报错的合规监控看板
生产环境必须记录每次违规的关键指标:
| 指标 | 用途 |
|---|---|
| 违规率(拦截数/总请求数) | 整体健康度 |
各 safety_violations 类别分布 |
识别最高频违规类型 |
| 触发违规的 prompt Top 10 | 优化最痛点的模板 |
| 重写后通过率 | 评估重写器效果 |
🎯 生产部署建议:建议把违规率作为核心 SLO 指标。健康生产线的违规率通常应 < 2%,> 5% 说明 prompt 模板存在系统性问题。我们建议通过 API易 apiyi.com 控制台的请求日志做日级分析,定位违规高发模板进行集中重写。
关于 gpt-image-2 报错的常见问题 FAQ
Q1:gpt-image-2 报错 moderation_blocked 会扣费吗?
不会。安全分类器在请求到达模型之前就拦截了,没有消耗任何 token 或 GPU 时间。OpenAI 和 APIYI 都遵循这一规则。如果你看到账单里出现了对应的扣费,应该立即联系平台核实。我们建议通过 API易 apiyi.com 控制台对每个 request_id 核对扣费记录,确保被拦截请求 0 计费。
Q2:gpt-image-2 报错为什么相同 prompt 重试无效?
因为安全分类器是确定性的——同一段输入的分类结果是稳定的,不像生成模型那样有随机性。重试 100 次会得到 100 次相同的拦截。唯一解法是修改 prompt。
Q3:gpt-image-2 报错的 moderation: low 能完全关闭审核吗?
不能。low 只是降低敏感度阈值,对中等敏感内容更宽容,但极端高危内容(性、自残、未成年人写实、仇恨符号、政治领袖等)即使 low 也会被拦截。把 low 当作"开关"是错误的认知。
Q4:gpt-image-2 报错为什么我的 prompt 看起来很无害也被拦了?
可能性有三:
- 整体语境构成违规:单个词无害,但组合形成了违规场景
- 多义词触发:例如 "shoot a photo" 可能被误判为暴力词
- 后端差异:Azure 后端比 OpenAI 直连更严格
针对第 2 种情况,加场景框架声明("professional photography session")能很好缓解。我们建议通过 API易 apiyi.com 把这类 "误判" 样本沉淀到内部知识库,作为 prompt 模板的迭代素材。
Q5:gpt-image-2 报错时我能看到具体被哪个词触发吗?
API 不会返回具体的触发词,只返回类别(如 [violence])。这是 OpenAI 的设计选择——避免被用来做"绕过指南"。要定位具体触发词,需要自己做二分搜索:把 prompt 拆成两半分别测试。
Q6:gpt-image-2 报错处理参考图(编辑场景)的违规该怎么办?
/v1/images/edits 端点的 Stage 1 同时扫描 prompt 文本 + 上传的所有参考图。如果是参考图本身违规:
- 检查参考图是否含暴力、性暗示、版权角色等元素
- 用本地工具预处理参考图(裁剪、模糊敏感区域)
- 如果是真人照片,确认没有违反公众人物政策
Q7:gpt-image-2 报错的违规类别和 OpenAI Moderations API 的类别一致吗?
基本一致但有差异。Moderations API 返回的类别更细(11 个),图像生成的拦截类别相对粗粒度(7-9 个)。建议把 Moderations API 用作预校验工具,但不要假设两者结果完全等价——有时 Moderations 通过的 prompt,图像端仍会拦截。
Q8:gpt-image-2 报错可以申诉吗?
可以但效果有限。报错信息里的 request_id 可用于联系平台技术支持核查。实践经验:如果是误判(例如医学/教育用途的中性内容),平台可能加白名单;如果是真的越线,申诉无效。我们建议通过 API易 apiyi.com 工单系统提交申诉时附上完整 request_id 和业务场景说明,提高处理效率。
总结:从 gpt-image-2 报错到合规高效的 Prompt
走完本文 7 个章节,你应该已经掌握了完整的 gpt-image-2 报错处理体系:
- ✅ 理解本质 ——
moderation_blocked是请求级 400 错误,不扣费、不可重试 - ✅ 掌握架构 —— 两阶段安全审核(Stage 1 输入过滤 + Stage 2 输出过滤)
- ✅ 熟悉触发场景 —— 7 大违规类别 + violence 子类别细节
- ✅ 诊断违规 —— 通过
safety_violations字段精准定位 - ✅ 5 种优化策略 —— 降敏重写、主体替换、框架声明、多步分解、moderation 参数
- ✅ 工程化方案 —— 预校验、自动重写、智能重试、合规监控
最关键的一条认知:gpt-image-2 报错 moderation_blocked 不是 bug,是产品的合规边界。与其抱怨过严,不如把"合规 prompt 工程"当作生产能力来建设——这恰恰是 AI 产品在 C 端落地的核心竞争力之一。
如果你的团队正面临高频 moderation_blocked 报错、需要为生产线建立 prompt 合规审计流程、或者想用工程化方案降低违规率,建议直接通过 API易 apiyi.com 申请测试 Key,跑一遍本文的预校验 + 自动重写代码模板。所有示例都基于官方 SDK + APIYI 官转通道(字段与 OpenAI 100% 一致),通用性极高,能直接复用到自己的项目。
参考资料
-
OpenAI ChatGPT Images 2.0 System Card:官方安全策略和拦截机制说明
- 链接:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - 说明: 含两阶段过滤架构、违规类别完整列表
- 链接:
-
OpenAI Moderations API 文档:预校验工具的官方使用指南
- 链接:
developers.openai.com/api/docs/guides/moderation - 说明: 11 个违规类别、API 调用方法
- 链接:
-
OpenAI Usage Policies:使用政策权威说明
- 链接:
openai.com/policies/usage-policies/ - 说明: 禁止用途、责任承担、合规要求
- 链接:
-
OpenAI GPT Image Models Prompting Guide:官方提示词最佳实践
- 链接:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - 说明: 含合规 prompt 写法和案例
- 链接:
-
APIYI gpt-image-2 接入文档:中文版完整接入指南
- 链接:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - 说明: 含 moderation 参数详解、错误码处理
- 链接:
作者: APIYI 技术团队
发布日期: 2026 年 4 月 27 日
关键词: gpt-image-2 报错、moderation_blocked、safety_violations、内容审核、prompt 优化、APIYI、OpenAI 合规