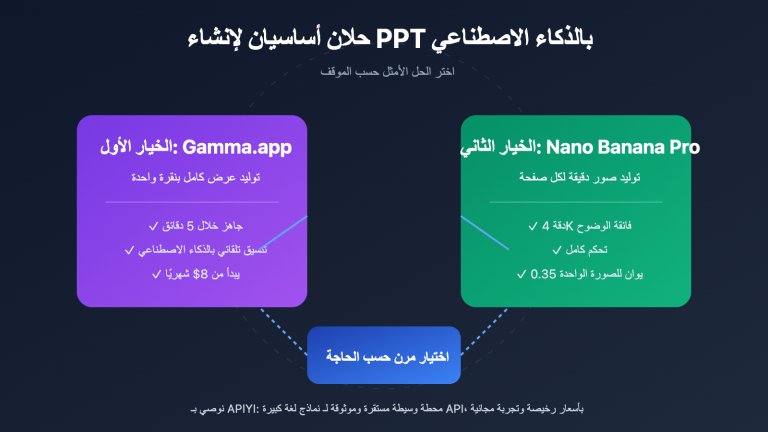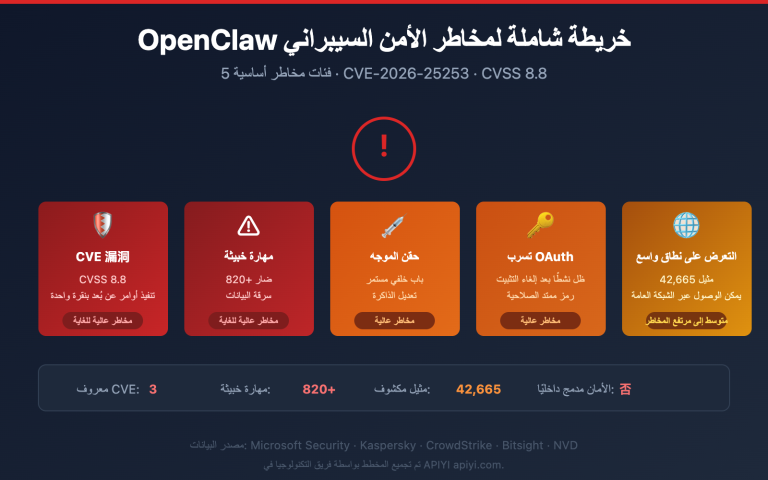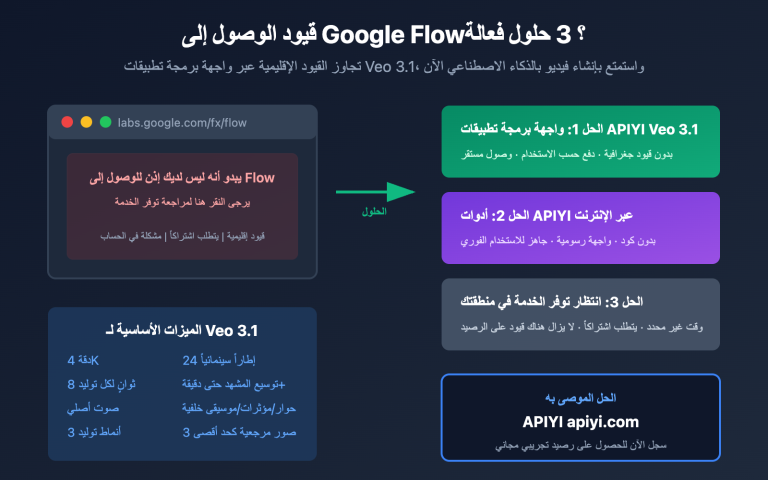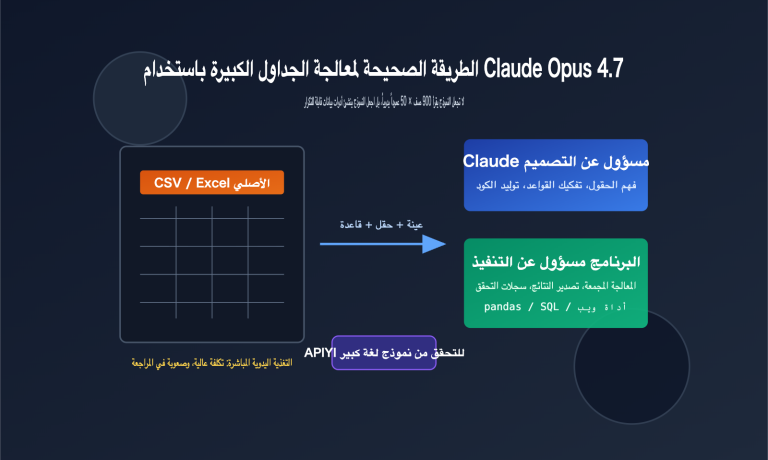
اكتسب مشروع مفتوح المصدر على GitHub يحمل اسم ARIS-Code شهرة واسعة مؤخراً، حيث حصد أكثر من 8400 نجمة و783 فرعاً (Fork). تم تطوير هذا المشروع بواسطة المبرمج wanshuiyin بناءً على النسخة مفتوحة المصدر من Claude Code، واسمه الكامل هو "Auto-Research-In-Sleep"، والذي يعني حرفياً "إجراء البحوث العلمية أثناء النوم". هذا ليس مجرد شعار تسويقي، بل هو أداة تسمح لـ Claude Code بتنفيذ التجارب، والبحث في المراجع، وتعديل الأوراق البحثية تلقائياً أثناء نومك، لتستيقظ في اليوم التالي وتجد أن سير العمل قد تقدم بشكل ملحوظ.
أثار ARIS-Code نقاشات واسعة في الأوساط الأكاديمية؛ حيث أظهرت ثلاث حالات دراسية لأوراق بحثية نشرها مؤلف المشروع أن المسودات الأولية التي أنتجتها الأداة حصلت على تقييمات تتراوح بين 7 و8 من 10 من قبل مراجعي الذكاء الاصطناعي، وتم تقديمها بالفعل إلى مؤتمرات علوم الحاسوب المرموقة، ومؤتمر AAAI 2026، ومجلة IEEE TGRS. وهذا يعني أن البحث العلمي المؤتمت بالكامل بواسطة الذكاء الاصطناعي لم يعد مجرد نموذج تجريبي، بل أصبح قادراً فعلياً على إنتاج مسودات صالحة للنشر.
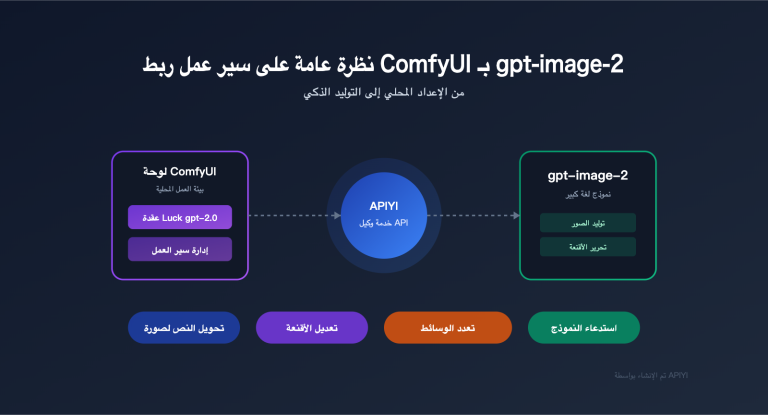
في هذا المقال، سنقوم بتحليل معمق للبنية الأساسية لـ ARIS-Code، ومهاراته الـ 42 المدمجة، بالإضافة إلى كيفية ربطه بنماذج Claude عبر خدمة وكيل API خارجية في البيئة المحلية، لمساعدتك في تقييم ما إذا كانت هذه الأداة مناسبة لسير عملك البحثي.
🎯 تنبيه خاص: نظراً لأن ARIS-Code يعتمد على النسخة مفتوحة المصدر من Claude Code، فإن منفذ الأوامر الخاص به يدعم فقط نماذج عائلة Claude (Sonnet/Opus/Haiku)، ولا يدعم نماذج GPT أو Gemini كمنفذ رئيسي. نوصي باستخدام منصة APIYI (apiyi.com) للوصول إلى نماذج Claude، حيث تتوافق المنصة مع البروتوكول الأصلي لشركة Anthropic، وتوفر وصولاً مستقراً داخل البلاد مع نظام دفع حسب الاستخدام، دون الحاجة إلى بطاقة ائتمان دولية.
ما هو مشروع ARIS-Code: Auto-Research-In-Sleep؟
يُعد ARIS (اختصار لـ Auto-Research-In-Sleep) نظام سير عمل بحثي ذاتي موجه للباحثين في مجالات تعلم الآلة والذكاء الاصطناعي. رابط المشروع على GitHub هو: github.com/wanshuiyin/Auto-claude-code-research-in-sleep. هدفه التصميمي واضح جداً: تمكين الباحثين من إكمال دورة البحث الكاملة — بدءاً من "مراجعة الأدبيات ← توليد الأفكار ← تنفيذ التجارب ← كتابة الورقة البحثية ← الرد على المراجعات" — بأقل قدر من التدخل البشري، مما يحرر الباحثين من المهام الروتينية المتكررة.
جوهر ARIS-Code هو مكتبة منهجية، حيث تتكون المجموعة الكاملة للنظام من ملفات Markdown (SKILL.md) فقط، دون الحاجة لتثبيت أطر عمل معقدة، أو صيانة قواعد بيانات، أو إعداد حاويات Docker. كل "مهارة" (Skill) هي عبارة عن وصف لسير عمل يمكن لأي وكيل ذكاء اصطناعي (LLM Agent) قراءته. لذا، يمكنك تبديل منفذ الأوامر من Claude Code إلى أي أداة تدعم وضع الوكيل مثل Codex CLI أو OpenClaw أو Cursor أو Trae، وسيظل سير العمل فعالاً.
هذا التصميم الذي يتميز بـ "صفر اعتماديات، صفر قيود" هو الميزة الأكبر التي تميز ARIS-Code عن أدوات الذكاء الاصطناعي البحثية الأخرى؛ فهو في جوهره يحول العملية البحثية إلى "هندسة موجهات" (Prompt Engineering) قابلة للتنفيذ، بدلاً من حصرها في أداة مغلقة. وهذا أمر بالغ الأهمية للباحثين، لأنه يعني أن سير العمل قابل للقراءة والتعديل والنقل، وليس رهينة لمنتج تجاري معين.
تجدر الإشارة إلى أن مستودع ARIS-Code قد جمع بالفعل 719 التزاماً (commits)، ولا يزال المشروع في حالة تطوير سريع. ففي الأشهر الثلاثة الماضية، تمت إضافة العديد من المهارات عالية القيمة مثل paper-talk (توليد نصوص العروض التقديمية للمؤتمرات)، وresubmit-pipeline (سير عمل إعادة التقديم بعد الرفض)، وkill-argument (توليد حجج مضادة)، مما يجعل النظام البيئي للمشروع نشطاً للغاية.
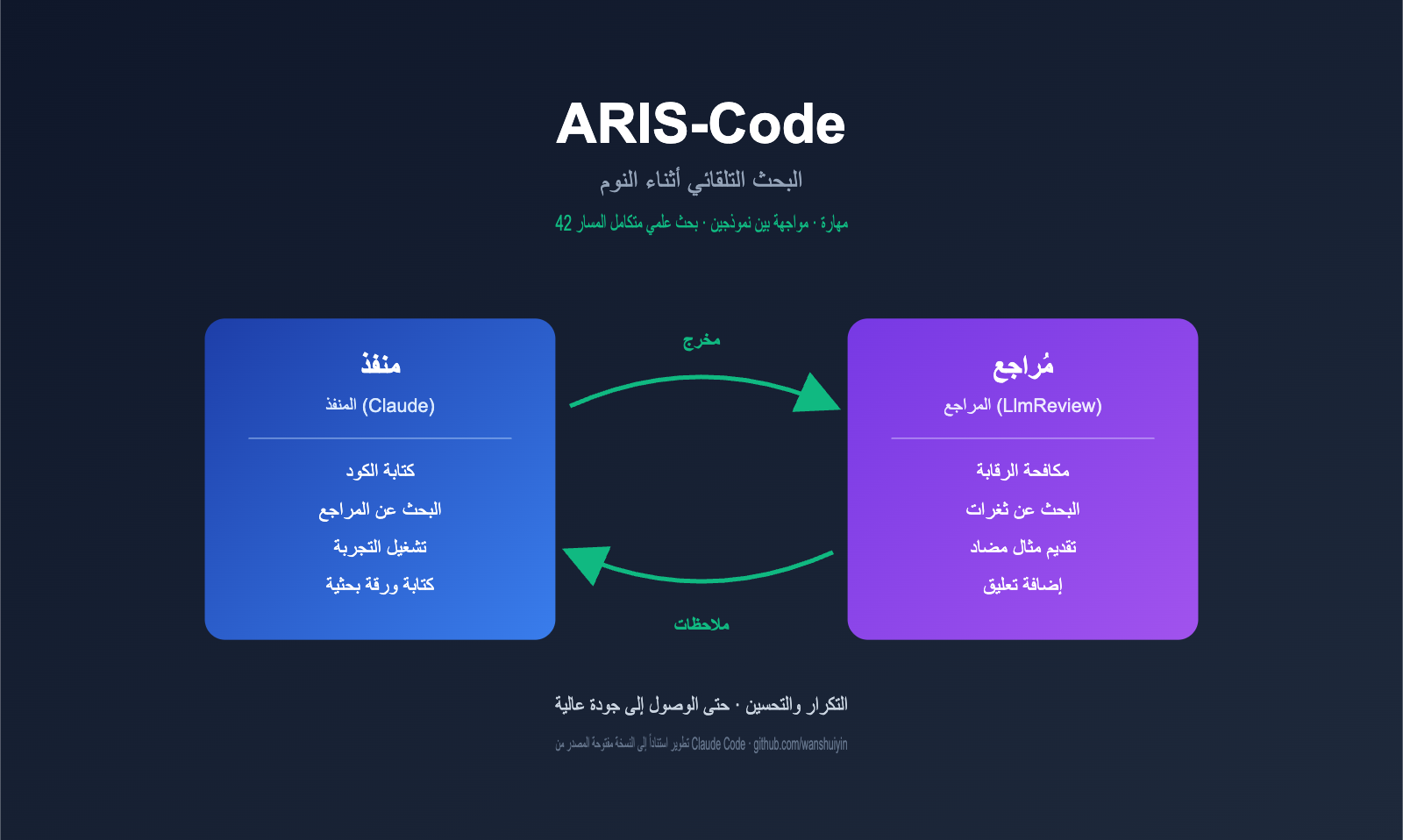
البنية الأساسية لـ ARIS-Code: نظام المراجعة التنافسي بين نموذجين (Executor-Reviewer)
تكمن القيمة الهندسية الأهم في مشروع ARIS-Code في بنيته التنافسية القائمة على نموذجين، وهو ما يجعله مختلفاً جوهرياً عن مساعدي البحث العلمي الآخرين المتاحين في السوق. يقدم مؤلف المشروع ملاحظة عميقة في ملف الـ README الخاص به: "إن المراجعة الذاتية للنموذج الواحد تعاني من نقاط ضعف هيكلية؛ فعندما يقوم نفس النموذج بتنفيذ المهمة وتقييم مخرجاته في آن واحد، فإنه يكرر بشكل منهجي نقاط عمائه الخاصة، مما يؤدي إلى الوقوع في فخ الحلول المثالية محلياً".
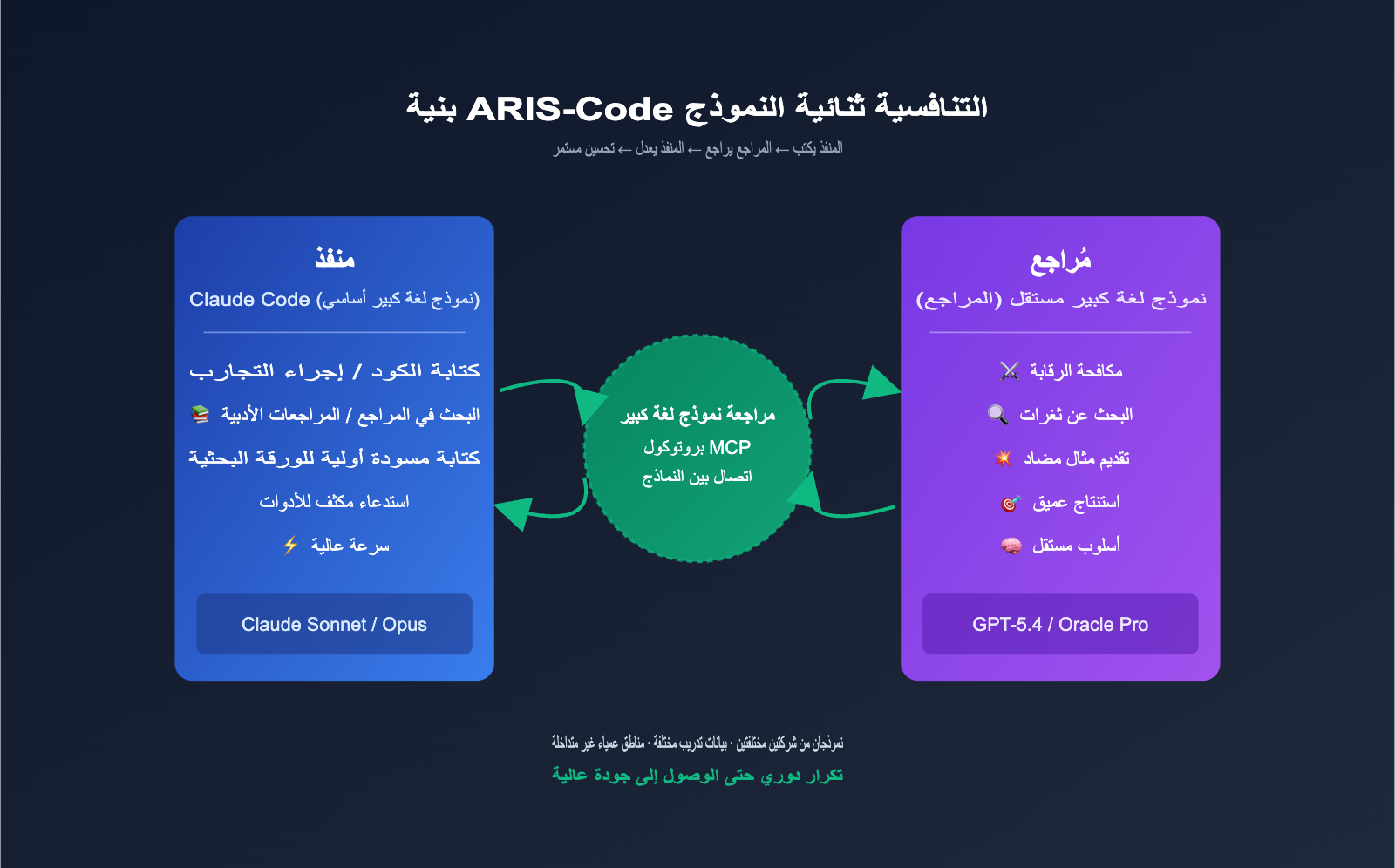
يتمثل حل ARIS-Code في تفويض سلطة المراجعة لنموذج مستقل تماماً. وفيما يلي تقسيم الأدوار:
| الدور | اختيار النموذج | المسؤولية | القدرات الموصى بها |
|---|---|---|---|
| Executor (المنفذ) | Claude Sonnet / Opus | التنفيذ الرئيسي: كتابة الكود، مراجعة الأدبيات، إجراء التجارب، صياغة الأوراق البحثية | سرعة عالية، نافذة سياق كبيرة، استدعاء أدوات مستقر |
| Reviewer (المراجع) | GPT-5.4 (Codex MCP) / Oracle Pro | المراجعة التنافسية: البحث عن الثغرات، التشكيك في النتائج، تقديم أمثلة مضادة | استنتاج عميق، تفكير نقدي، أسلوب مستقل |
| آلية التنسيق | سلسلة أدوات LlmReview | التواصل بين النماذج، استمرارية الحالة | نقل شفاف عبر بروتوكول MCP |
يمكن تلخيص سير العمل في حلقة بسيطة: المنفذ يكتب ← المراجع يقيم ← المنفذ يعدل ← تكرار التقييم والتعديل حتى يمنح المراجع الموافقة. تنجح هذه الحلقة لأن النموذجين يأتيان من شركات مختلفة، وتدربا على بيانات مختلفة، ويمتلكان أساليب استنتاج متباينة، مما يضمن عدم تداخل نقاط العمى لديهما.
ولمنع تلوث النتائج العلمية بهلوسات نماذج اللغة الكبيرة، صمم ARIS-Code سلسلة تدقيق أدلة متعددة الطبقات: experiment-audit (سلامة الكود) ← result-to-claim (النتائج مقابل الادعاءات) ← paper-claim-audit (تدقيق ادعاءات الورقة البحثية) ← citation-audit (التحقق من المراجع). كل طبقة تمتلك ملف JSON خاص بالقرار (verdict) وبصمة SHA256 للتحقق من إمكانية إعادة الإنتاج، وهي دقة هندسية نادرة في أدوات الذكاء الاصطناعي العلمية.
🔧 نصيحة للإعداد: إذا كنت ترغب في إعادة بناء بنية ARIS-Code ذات النموذجين بالكامل، نوصي في البيئة المحلية باستخدام منصة APIYI (apiyi.com) للحصول على مفاتيح API لكل من نماذج Claude وGPT في آن واحد. توفر المنصة واجهتين برمجيتين متكاملتين، مما يغنيك عن الحاجة لفتح حسابات خارجية أو ربط بطاقات ائتمانية دولية بشكل منفصل.
خط إنتاج البحث العلمي المتكامل ARIS-Code مع 42 مهارة مدمجة
أكثر ما يثير الإعجاب في ARIS-Code هو احتوائه على أكثر من 42 مهارة (Skills) مدمجة. هذه المهارات ليست مجرد أدوات صغيرة منعزلة، بل هي خط إنتاج يغطي دورة حياة البحث العلمي بالكامل. قمت بتصنيفها حسب مراحل سير العمل كما يلي:
| مرحلة سير العمل | المهارات الأساسية (Skills) | القدرات الجوهرية |
|---|---|---|
| مرحلة اختيار الموضوع (Idea Discovery) | research-lit / novelty-check / idea-creator / idea-discovery | البحث في مصادر متعددة، التحقق من الحداثة عبر نماذج متعددة، توليد 8-12 فكرة مرشحة |
| مرحلة التجريب (Experimentation) | experiment-bridge / experiment-queue / run-experiment | مراجعة الكود ← نشر على GPU ← جدولة متعددة البذور ← معالجة تلقائية لخطأ OOM |
| المراجعة التلقائية (Auto Review) | auto-review-loop / research-review / experiment-audit | 4 جولات من التحسين التكراري، مراجعة الأقران المهيكلة، التحقق من سلامة الكود |
| كتابة الورقة البحثية (Paper Writing) | paper-writing / paper-claim-audit / proof-checker / citation-audit | السرد ← LaTeX ← PDF، تدقيق الادعاءات، التحقق من البراهين، تدقيق المراجع |
| الرد على المراجعات (Rebuttal) | rebuttal | تحليل ملاحظات المراجعين ← صياغة الرد ← اختبار الضغط |
| القدرات الفائقة (Meta-Skills) | research-wiki / meta-optimize / deepxiv | قاعدة معرفية دائمة، تحسين الحلقة الخارجية، مصادر مراجع بديلة |
أكثر المهارات قيمة من الناحية العملية هي experiment-bridge، التي تربط "مراجعة الكود ← النشر عن بُعد على GPU ← بدء التجربة ← استعادة النتائج" في خط إنتاج واحد. عندما يقترح المراجع "إجراء تجربة استئصال (Ablation Study) هنا"، يقوم المنفذ (Executor) تلقائياً بكتابة السكريبت، ونقله عبر rsync إلى عقدة GPU، وبدء التدريب، ومراقبة السجلات، وجمع النتائج؛ دون تدخل يدوي من الباحث.
مهارة أخرى تستحق الاهتمام هي citation-audit، التي تقضي على أكبر مشكلة عند استخدام نماذج اللغة الكبيرة في كتابة الأوراق البحثية، وهي "هلوسة المراجع"، وذلك من خلال الربط بقواعد بيانات DBLP وCrossRef الحقيقية. كل مرجع BibTeX يأتي من قاعدة بيانات فعلية وليس من تأليف النموذج. هذا مطلب أساسي في الكتابة الأكاديمية، حيث أن أي مرجع وهمي قد يؤدي إلى رفض الورقة فوراً.
كما يقدر الباحثون مهارة research-wiki، وهي قاعدة معرفية دائمة عابرة للجلسات، حيث تراكم ملاحظات قراءة الأوراق البحثية، ومسودات الأفكار، وسجلات التجارب الفاشلة عبر مشاريع متعددة، لتشكل ذاكرة بحثية شخصية متنامية. عندما تعود لمسار بحثي معين بعد ثلاثة أشهر، لن تحتاج لإعادة قراءة جميع الأوراق ذات الصلة؛ فالمساعد الذكي قد احتفظ بالسياق نيابةً عنك.
💡 نصيحة للاستخدام: استدعاء أي مهارة يستهلك كمية كبيرة من رموز (Tokens) واجهة برمجة تطبيقات Claude، خاصة في مهام توليد النصوص الطويلة مثل paper-writing. ننصح بالوصول إلى نماذج Claude عبر apiyi.com، حيث تدعم المنصة الدفع حسب الاستخدام وتوفر مراقبة كاملة لاستهلاك الرموز، مما يسهل عليك تقدير تكلفة كل ورقة بحثية.
خطة الإعداد الكاملة لربط ARIS-Code بـ APIYI
بما أن منفذ ARIS-Code مبني على نسخة Claude Code مفتوحة المصدر، فهو يقبل فقط بروتوكول API الخاص بـ Anthropic، مما يعني أن نماذج GPT وGemini لا يمكن استخدامها كمنفذ (Executor). هذا قيد تقني صارم، وهو أيضاً أكبر نقطة حيرة للمطورين عند النشر لأول مرة.
خطوات إعداد الوصول إلى نماذج Claude عبر APIYI بسيطة للغاية، ويمكن تلخيصها في 5 خطوات:
# الخطوة 1: استنساخ مستودع المشروع
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# الخطوة 2: تثبيت المهارات في دليل إعدادات Claude Code المحلي
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# الخطوة 3: إعداد عنوان خدمة وكيل APIYI (خطوة جوهرية)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="مفتاح APIYI الخاص بك"
# الخطوة 4: تشغيل Claude Code
claude
# الخطوة 5: استدعاء أي مهارة داخل Claude Code
# مثال: /research-pipeline "factorized gap in discrete diffusion LMs"
النقطة الأكثر أهمية هنا هي الخطوة الثالثة، وهي ضبط متغير البيئة ANTHROPIC_BASE_URL؛ حيث يخبر هذا المتغير Claude Code بعدم طلب نقطة النهاية الرسمية لـ Anthropic، بل التوجه إلى بوابة الوكيل. واجهة هذه البوابة متوافقة تماماً مع بروتوكول Anthropic الأصلي، ولا تحتاج المهارات المدمجة في ARIS-Code إلى أي تعديل في الكود، حيث يتم تمرير جميع الميزات بما في ذلك استدعاء الأدوات، والمخرجات المتدفقة، وسلسلة التفكير (thinking) بشفافية كاملة.
إذا كنت بحاجة أيضاً إلى نشر جانب المراجع (Codex MCP)، فالعملية هي:
# تثبيت Codex MCP لجانب المراجعة
npm install -g @openai/codex
codex setup # يمكنك هنا أيضاً إدخال عنوان الوكيل لنماذج GPT
claude mcp add codex -s user -- codex mcp-server
بالنسبة للباحثين الذين يتطلعون إلى محاكاة نتائج ARIS-Code بمستوى الأوراق البحثية المنشورة، يوفر المشروع خيار ربط Oracle MCP بنموذج GPT-5.4 Pro كمراجع متقدم. هذا الخيار مفيد جداً في مراحل كتابة الورقة النهائية، حيث يتميز إصدار Pro بعمق نقدي وقدرة على بناء أمثلة مضادة تتفوق بشكل واضح على الإصدارات الأساسية.
🚀 خطة وصول موحدة: تدعم منصة APIYI (apiyi.com) في الوقت نفسه عائلة نماذج Claude (Sonnet 4.5/Opus 4)، وعائلة GPT (GPT-5/o4)، وعائلة Gemini (Gemini 3 Pro) وغيرها من النماذج الرائدة. مفتاح واحد يكفي لتشغيل كل من المنفذ (Executor) والمراجع (Reviewer) في ARIS-Code، مما يسهل إدارة التكاليف وتجميع سجلات الاستدعاء للفرق البحثية.
توفر ARIS-Code أربعة مستويات من مستوى الجهد (Effort Level) لموازنة التكلفة والجودة، وهو تصميم هندسي بامتياز. تختلف متطلبات العمق بشكل كبير باختلاف مراحل البحث؛ ففي مرحلة الاستكشاف الأولية لا داعي لاستهلاك الكثير من الـ tokens، بينما في مرحلة وضع اللمسات الأخيرة قبل التقديم، نحتاج إلى دفع الجودة إلى أقصى حدودها.

| مستوى الجهد | مضاعف الـ Token | سيناريوهات الاستخدام | التقدير لكل استدعاء |
|---|---|---|---|
| lite | 0.4× | استكشاف سريع، التحقق من الأفكار | منخفض جداً |
| balanced | 1.0× | سير عمل البحث اليومي الافتراضي | قياسي |
| max | 2.5× | مرحلة تجارب الأوراق البحثية الجادة | متوسط إلى مرتفع |
| beast | 5-8× | سباق المؤتمرات الكبرى، وضع التقديم | مرتفع |
توفر ARIS-Code أيضاً 4 خيارات لتكوين وحدة معالجة الرسومات (GPU)، لتناسب كلاً من الباحثين الذين يستخدمون أجهزة محلية أو السحابة:
| تكوين GPU | سيناريوهات الاستخدام | خصائص التكلفة |
|---|---|---|
| local | الباحثون الذين يمتلكون بطاقات رسومية محلياً | تكلفة أجهزة لمرة واحدة |
| remote | خوادم SSH الخاصة بالمختبر | موارد جامعية مجانية |
| vast | تدريب مكثف قصير المدى | محاسبة بالساعة، مرونة عالية |
| modal | مهام دورية خفيفة | بدون خادم (Serverless)، رصيد مجاني 30 دولار |
💰 نصيحة للتحكم في التكلفة: إذا كنت قد بدأت للتو في تجربة ARIS-Code، فمن المستحسن البدء بوضع lite + local لتشغيل سير العمل، واستخدام خدمة وكيل API مثل apiyi.com لتسهيل حساب استهلاك الـ tokens. بمجرد استقرار سير العمل، يمكنك الترقية إلى وضع max أو beast لإجراء أبحاث جادة؛ فهذا يجنبك هدر تكاليف الـ tokens المرتفعة بسبب أخطاء الإعداد في البداية.
سير عمل ARIS-Code العملي: من فكرة عابرة إلى ورقة بحثية
أكثر ما يثير الإعجاب في ARIS-Code هو خط أنابيب العمل الشامل /research-pipeline؛ حيث تقوم هذه المهارة بربط جميع المراحل المذكورة أعلاه في أمر واحد. كل ما عليك فعله هو تقديم وصف لاتجاه البحث، وسيقوم النظام تلقائياً بإنتاج مسودة أولية خلال 8 إلى 24 ساعة.
طريقة الاستدعاء النموذجية تكون كالتالي:
# السيناريو 1: اتجاه بحثي جديد تماماً، من الصفر
/research-pipeline "factorized gap in discrete diffusion LMs"
# السيناريو 2: تحسين ورقة بحثية موجودة
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# السيناريو 3: الرد على المراجعات (Rebuttal) فقط
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
عند التشغيل الفعلي، يتبع ARIS-Code خطوات منظمة: مراجعة الأدبيات ← توليد الأفكار ← فحص الحداثة ← تصميم التجارب ← جدولة وحدات معالجة الرسوميات (GPU) ← استرجاع النتائج ← كتابة الورقة ← تدقيق المراجع ← التنسيق النهائي. عند مواجهة نقاط قرار غامضة، سيتوقف النظام وينتظر تدخلاً بشرياً (checkpoint)، وفي الإعدادات الافتراضية، يتيح لك خيار --AUTO_PROCEED false التدخل يدوياً بعد كل جولة من ملاحظات المراجعين.
يوفر ARIS-Code أيضاً معامل style-ref مفيداً للغاية، حيث يمكنك تحديد ورقة بحثية كمرجع للأسلوب (على سبيل المثال، أفضل ورقة تاريخية في نفس المؤتمر)، وسيقوم النظام بمحاكاة هيكلها التنظيمي وإيقاع السرد، دون نسخ فقرات محددة. بالنسبة للباحثين الذين يسعون لزيادة "معدل قبول الأوراق"، يعد هذا تفوقاً نوعياً، لأن المتطلبات الضمنية للمحكمين في المؤتمرات الكبرى غالباً ما تكون أصعب في الضبط من المحتوى نفسه.
من التفاصيل الهندسية الأخرى الجديرة بالذكر أن ARIS-Code يتكامل مع أنظمة خارجية متعددة مثل المزامنة الثنائية مع Overleaf، ومراقبة منحنيات التدريب عبر W&B، والتنبيهات عبر تطبيق Lark. عندما تصل التجارب على وحدة معالجة الرسوميات إلى نقطة تحول حاسمة، يمكنك تلقي إشعار فوراً على هاتفك، مما يحقق فعلياً مفهوم "إجراء الأبحاث أثناء النوم".
📊 بيانات الأداء: أظهرت 3 حالات لأوراق بحثية مجتمعية نشرها مؤلف المشروع أن الأوراق التي أنتجها ARIS-Code حصلت على تقييمات 7-8/10 من قبل أنظمة تقييم الذكاء الاصطناعي (مؤتمرات علوم الحاسب، AAAI 2026، IEEE TGRS). ومع ذلك، يشير المؤلف بوضوح إلى أن المراجعين البشريين يقدمون وجهات نظر لا تستطيع أنظمة التقييم بالذكاء الاصطناعي التقاطها، لذا لا يمكن استبدال المراجعة البشرية بالكامل.
الأسئلة الشائعة حول ARIS-Code
س1: لماذا لا يمكن لـ ARIS-Code استخدام GPT-5 كمنفذ (Executor)؟
لأن ARIS-Code مشتق من نسخة Claude Code مفتوحة المصدر، وطبقة التنفيذ فيه مرتبطة تماماً ببروتوكول API الخاص بـ Anthropic، بما في ذلك تنسيق استدعاء الأدوات، وتنسيق المخرجات المتدفقة، وتنسيق سلسلة التفكير، وكلها مرتبطة بعمق بنماذج Claude. إذا كنت ترغب في تغيير المنفذ، ستحتاج إلى استخدام OpenClaw أو إصدارات Codex CLI، لكنها لن تكون ARIS-Code الأصلية. ننصح بالوصول المباشر لنماذج Claude عبر APIYI.com، فهو الحل الأكثر سهولة.
س2: كم عدد الرموز (Tokens) المطلوبة لتشغيل ورقة بحثية كاملة؟
في وضع "beast"، يستهلك تشغيل /research-pipeline بالكامل ما بين 5 إلى 15 مليون رمز (إدخال + إخراج)، وهو ما يعادل تكلفة تتراوح بين بضع عشرات إلى مئات اليوانات عند استخدام Claude Sonnet. يمكن تقليل ذلك إلى 2-5 ملايين رمز في وضع "balanced". تعتمد التكلفة الفعلية على تعقيد التجربة وعدد جولات التكرار.
س3: هل يمكن استخدام ARIS-Code بدون وحدة معالجة رسوميات (GPU) محلية؟
بالتأكيد. صمم ARIS-Code وضعي "vast" و "modal" للحوسبة السحابية، حيث يوفر modal رصيداً مجانياً بقيمة 30 دولاراً، وهو أكثر من كافٍ لتشغيل تجارب خفيفة. إذا كنت تعمل فقط على أوراق نظرية (/proof-writer + /formula-derivation)، فلن تحتاج إلى GPU على الإطلاق.
س4: هل يجب استخدام GPT-5.4 كمراجع في بنية النموذج المزدوج؟
ليس إلزامياً. يدعم المشروع الاستبدال بأي نموذج متوافق مع بروتوكول OpenAI مثل GLM أو MiniMax أو Kimi. ننصح بالحصول على نماذج مراجعين متنوعة عبر منصات تجميع مثل APIYI.com لتسهيل اختبارات A/B واختيار النموذج الأكثر نقداً وملاءمة لمجالك. أفاد بعض الباحثين أن Gemini 3 Pro كان مراجعاً ممتازاً بشكل مفاجئ في الأوراق البحثية المتعلقة بالاستنتاج الرياضي، بينما يظل GPT-5.4 الخيار الأول لأوراق التحسين الهندسي.
س5: هل ARIS-Code مناسب لطلاب البكالوريوس أو المبتدئين؟
هو أكثر ملاءمة لطلاب الدراسات العليا ومن لديهم خبرة بحثية معينة. السبب هو أن جودة مخرجاته تعتمد بشكل كبير على قدرة الباحث على الحكم على المجال؛ فعلى سبيل المثال، عندما يقدم المراجع مثالاً مضاداً، يجب أن تقرر ما إذا كان هذا ثغرة جوهرية أم مجرد تفاصيل جانبية غير ذات صلة. المبتدئون تماماً قد يسهل تضليلهم من قبل الذكاء الاصطناعي.
س6: ماذا أفعل إذا كان الاتصال بـ ARIS-Code غير مستقر داخل البلاد؟
الاتصال المباشر بواجهة Anthropic الرسمية قد يواجه أحياناً إعادة تعيين للاتصال أو انتهاء المهلة، مما يؤدي إلى فشل مهام /research-pipeline الطويلة. الحل الأمثل هو تغيير ANTHROPIC_BASE_URL إلى بوابة خدمة وكيل API مستضافة محلياً، مما يضمن استمرار مهام ARIS-Code في وضع "النوم" لمدة 8 ساعات متواصلة دون انقطاع بسبب تذبذب الشبكة، وهو أمر حيوي خاصة للتجارب المستمرة في وضع "beast".
ملخص
يؤكد ظهور ARIS-Code على اتجاه هام: أدوات الإنتاجية البحثية في عصر نماذج اللغة الكبيرة تتحول من "المساعدة الفردية" إلى "الأتمتة الكاملة لسير العمل". إن بنية النموذج المزدوج (Executor-Reviewer)، و42 مهارة (Skills) لسير العمل، وتصميم Markdown الذي لا يعتمد على أي مكتبات خارجية، تشكل معاً إطاراً منهجياً ناضجاً للغاية.
بالنسبة للباحثين، فإن أكبر عقبة أمام استخدام ARIS-Code ليست منحنى التعلم التقني، بل استقرار استدعاء نماذج Claude. ننصح بالوصول إلى سلسلة نماذج Claude عبر منصة APIYI، مع الحصول في الوقت نفسه على نماذج GPT المقابلة لاستخدامها في جانب المراجع (Reviewer). بهذه الطريقة، يمكن لمنصة واحدة تغطية احتياجات النماذج لسير عمل ARIS-Code بالكامل، مما يجعل تسوية التكاليف وتجميع سجلات الاستدعاء أكثر سهولة. كما تضمن استقرار نقاط اتصال مراكز البيانات (IDC) المحلية عدم انقطاع سيناريو "تشغيل التجارب أثناء النوم" بسبب مشاكل الشبكة.
إذا كنت تستعد لتقديم ورقة بحثية لمؤتمر مرموق، أو كان لديك اتجاه بحثي ترغب في التحقق منه ولكن ليس لديك الوقت للتكرار اليدوي، فإن ARIS-Code يستحق قضاء عطلة نهاية الأسبوع في تجربته بجدية؛ فإذا استيقظت ووجدت مسودة أولية جاهزة بالفعل، فإن هذا الاستثمار في الوقت سيكون مجدياً للغاية.
📌 المؤلف: فريق APIYI — نتابع عن كثب خدمات واجهة برمجة تطبيقات نماذج اللغة الكبيرة (AI) ونظام المطورين البيئي. لمزيد من حالات استخدام نماذج Claude/GPT/Gemini، يرجى مراجعة مركز التوثيق في apiyi.com.