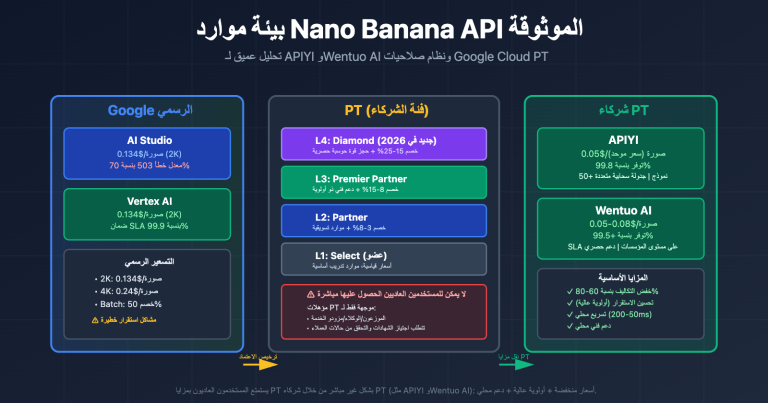
أصبحت نماذج التضمين (Embedding) حجر الزاوية في أنظمة الاسترجاع المعزز بالتوليد (RAG)، والبحث الدلالي، وأنظمة التوصية. ويبرز text-embedding-v4، كأحدث إصدار تجاري من سلسلة Qwen3-Embedding، كأحد الخيارات الأساسية للمطورين عند بناء أنظمة استرجاع المتجهات، وذلك بفضل توفيره لـ 8 أبعاد اختيارية (2048، 1536، 1024، 768، 512، 256، 128، 64) وأدائه الرائد في اختبارات MTEB متعددة اللغات.
ومع ذلك، يواجه العديد من الفرق سؤالاً شائعاً عند التطبيق العملي: ما هي أبعاد المتجهات بالضبط؟ وما الفرق بين 2048 و64 بعداً؟ وكيف أختار الأنسب؟ إن اختيار البعد الخاطئ قد يؤدي في أحسن الأحوال إلى إهدار 30 ضعفاً من تكاليف التخزين، وفي أسوئها إلى انخفاض معدل الاسترجاع من 70 إلى 50 نقطة.
سنقوم في هذا المقال، بناءً على بيانات الاختبارات الرسمية لـ MTEB / CMTEB، بتفكيك الاختلافات بين الأبعاد الثمانية لنموذج text-embedding-v4، وتقديم إطار عمل لاختيار الأبعاد يمكن تطبيقه مباشرة، بالإضافة إلى أمثلة كاملة لاستدعاء API.
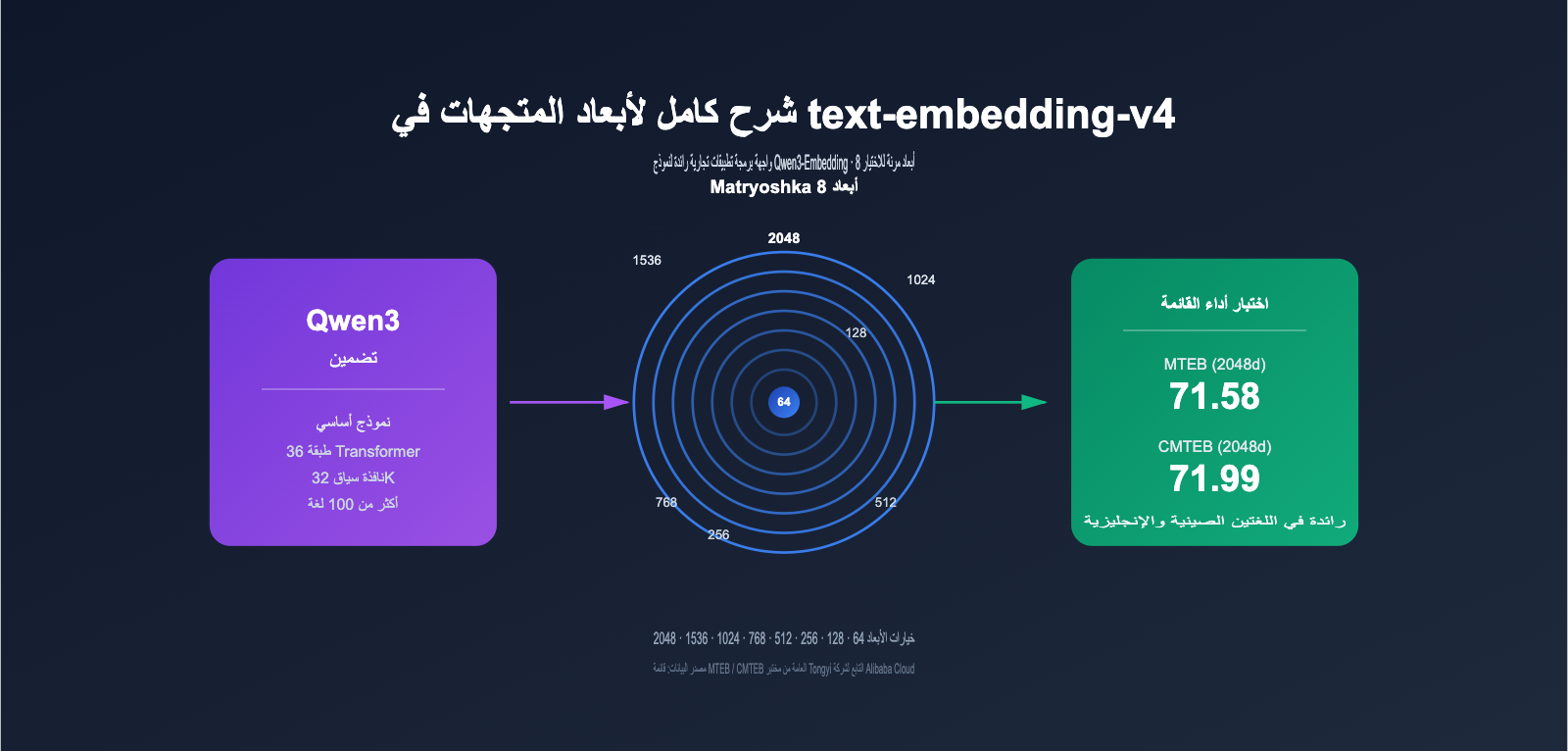
أولاً: ما هو text-embedding-v4: الرائد التجاري لنماذج Qwen3-Embedding
يُعد text-embedding-v4 الجيل الأحدث من نماذج تضمين النصوص (Text Embedding) التي طورتها مختبرات "علي بابا تونغ يي" (Alibaba Tongyi Lab) استناداً إلى نموذج اللغة الكبير Qwen3، ويتم توفيره كخدمة API عبر منصة DashScope. ينتمي هذا النموذج إلى سلسلة Qwen3-Embedding، التي تصدرت باستمرار قوائم النماذج مفتوحة المصدر في تصنيف MTEB متعدد اللغات لعام 2026، حيث حقق Qwen3-Embedding-8B درجة عالية بلغت 80.68 في فئة الأكواد البرمجية (Code) ضمن MTEB.
1.1 الخصائص الجوهرية لـ text-embedding-v4
مقارنة بإصدار v3، شهد text-embedding-v4 ترقيات ملحوظة في الأبعاد التالية:
| بُعد القدرة | text-embedding-v3 | text-embedding-v4 | نسبة التحسن |
|---|---|---|---|
| الدرجة الإجمالية لـ MTEB (1024 بُعد) | 63.39 | 68.36 | +4.97 |
| استرجاع MTEB (1024 بُعد) | 55.41 | 59.30 | +3.89 |
| الدرجة الإجمالية لـ CMTEB (1024 بُعد) | 68.92 | 70.14 | +1.22 |
| استرجاع CMTEB (1024 بُعد) | 73.23 | 73.98 | +0.75 |
| أقصى بُعد للمتجهات | 1024 | 2048 | الضعف |
| أقصى طول للإدخال | 8K | 32K Tokens | 4 أضعاف |
| دعم اللغات | 50+ | 100+ | توسع ملحوظ |
كما نرى، لم يقتصر التحسن على المهام العامة التقليدية (MTEB) فحسب، بل حقق النموذج تقدماً كبيراً في مهام الاسترجاع باللغة الصينية (CMTEB) والبرمجية. بالنسبة للفرق التي تسعى للحصول على أدق نتائج استرجاع، فإن إصدار v4 بأبعاد 2048 هو الخيار الأمثل حالياً في منظومة علي بابا.
💡 نصيحة لتجربة سريعة: إذا كنت ترغب في مقارنة الأداء الفعلي بين v3 وv4 فوراً، نوصي باستخدام منصة APIYI (apiyi.com) للاتصال المباشر، حيث قامت المنصة بتوحيد معايير واجهات البرمجة للعديد من نماذج التضمين الرئيسية، مما يتيح لك استخدام نفس الكود للتبديل بين النماذج والتحقق من النتائج بسرعة.
1.2 العلاقة بين text-embedding-v4 وسلسلة Qwen3-Embedding مفتوحة المصدر
يخلط العديد من المطورين بين text-embedding-v4 (واجهة API تجارية) و Qwen3-Embedding (أوزان مفتوحة المصدر)، وإليك توضيح العلاقة بينهما:
- سلسلة Qwen3-Embedding مفتوحة المصدر: تتضمن أحجام 0.6B / 4B / 8B، وتوفر أوزان Hugging Face، ويمكن نشرها محلياً.
- text-embedding-v4: تعتمد على نفس حزمة التقنيات، ولكنها خضعت لتحسينات هندسية إضافية، وتعزيز للبيانات، وتوسيع لدعم اللغات، وتتوفر فقط عبر DashScope API.
- الاختلاف الجوهري: النسخة مفتوحة المصدر تتطلب بناء استنتاج (Inference) على GPU خاص بك؛ بينما نسخة API تُحاسب بناءً على عدد الرموز (Tokens) ولا تتطلب صيانة.
بالنسبة لغالبية الفرق الصغيرة والمتوسطة، يعد استخدام API أكثر جدوى من حيث التكلفة والتعقيد الهندسي مقارنة ببناء بنية تحتية للاستنتاج على GPU.
ثانياً: ما هو بُعد المتجه (Vector Dimension): لماذا الفارق بين 64 و2048 كبير جداً؟
لفهم خيارات الأبعاد الثمانية في text-embedding-v4، يجب أولاً توضيح مفهوم "بُعد المتجه".
2.1 جوهر بُعد المتجه: إلى كم رقم يتم ضغط النص؟
عند إدخال نص (مثل "كيفية إعداد API لـ GPT-5") إلى نموذج التضمين، يقوم النموذج بإخراج سلسلة من الأرقام العشرية (متجه)، على سبيل المثال:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
طول هذه السلسلة هو بُعد المتجه. كلما زاد البُعد، فهذا يعني:
- معلومات دلالية أغنى: يمكن لكل بُعد التقاط سمة دلالية دقيقة.
- تكلفة تخزين أعلى: متجه واحد بـ 2048 بُعداً (float32) يشغل 8 كيلوبايت، بينما يشغل 1024 بُعداً 4 كيلوبايت.
- حسابات استرجاع أبطأ: تضاعف الأبعاد يعني تقريباً تضاعف حجم حسابات الضرب النقطي/جيب التمام للمتجهات.
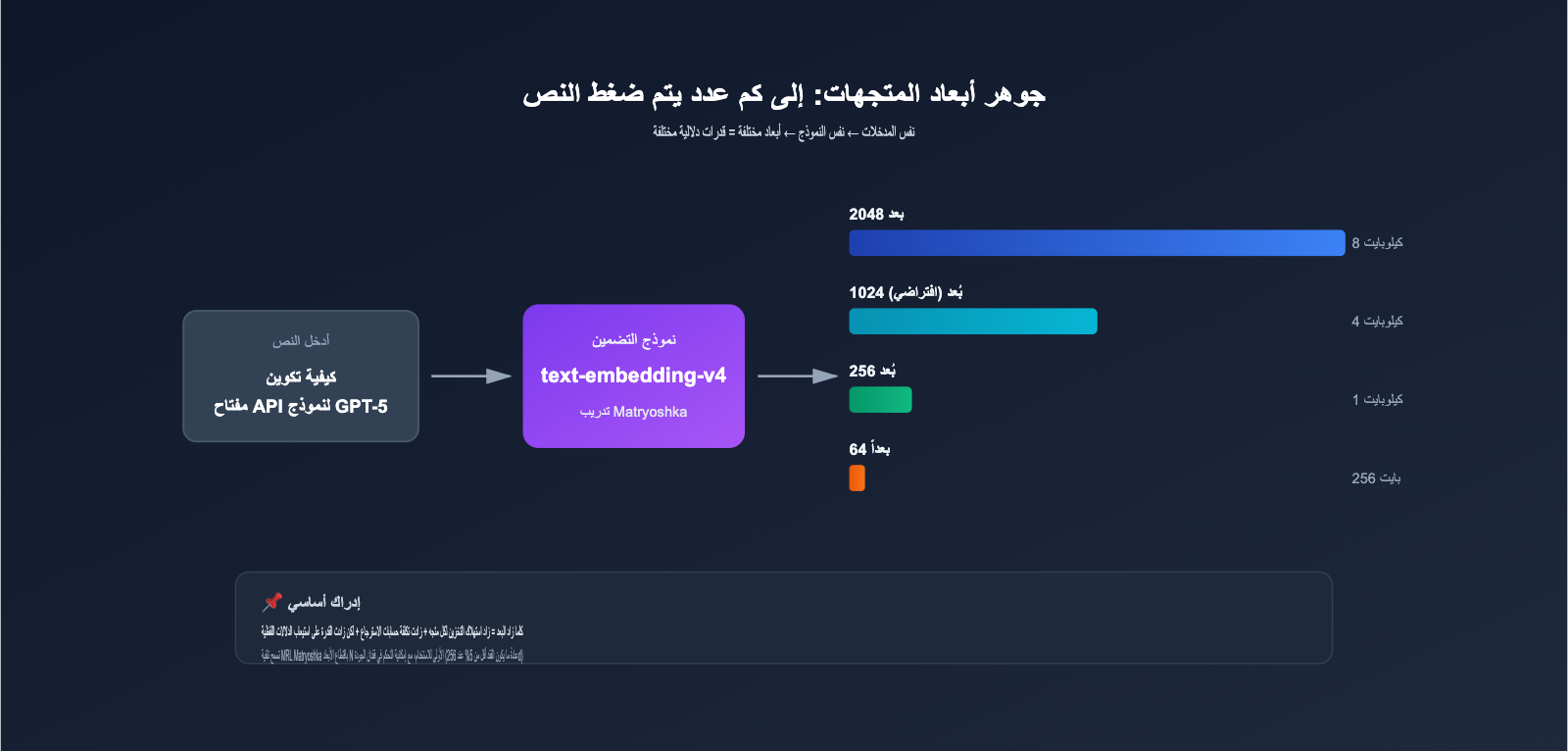
2.2 لماذا يوفر text-embedding-v4 ثمانية خيارات للأبعاد؟
هذا يتعلق بتقنية أساسية تُسمى تعلم التمثيل بنظام "الماتريوشكا" (Matryoshka Representation Learning – MRL).
النماذج التقليدية للتضمين تخرج أبعاداً ثابتة فقط. على سبيل المثال، نموذج ada-002 من OpenAI يخرج 1536 بُعداً بشكل ثابت، وعليك إما استخدامه بالكامل أو إجراء تقليل الأبعاد بنفسك عبر PCA (مما يؤدي لفقدان الكثير من المعلومات).
أما تقنية MRL فتسمح للنموذج أثناء التدريب بتوزيع المعلومات وفقاً لأهميتها عبر نطاقات أبعاد مختلفة:
- أول 64 بُعداً: تحمل المعلومات الدلالية الأكثر جوهرية وأهمية.
- من 65 إلى 128 بُعداً: تكمل السمات الدلالية الثانوية.
- من 129 إلى 256 بُعداً: تواصل إضافة سمات أكثر تفصيلاً.
- … وهكذا وصولاً إلى 2048 بُعداً.
هذا يشبه "دمى الماتريوشكا" الروسية، حيث كل طبقة هي متجه كامل وقابل للعمل بشكل مستقل. يمكنك اقتطاع أول N بُعد واستخدامها دون أن تنهار جودة النتائج بشكل مفاجئ.
🎯 الفائدة الفعلية من MRL: وفقاً للورقة البحثية الأصلية لـ MRL والاختبارات العملية المتعددة، فإن استخدام 256 بُعداً بدلاً من 2048 بُعداً يوفر عادةً حوالي 8 أضعاف في مساحة التخزين و7-8 أضعاف في سرعة الاسترجاع، مع بقاء فقدان الدقة عادةً ضمن حدود 5%. وهذا أمر لا يمكن تحقيقه أبداً باستخدام PCA التقليدي.
ثالثاً: الفروق الجوهرية بين أبعاد المتجهات الثمانية لـ text-embedding-v4
سنقوم فيما يلي بمقارنة منهجية للأبعاد الثمانية لنموذج text-embedding-v4 بناءً على بيانات التصنيف الرسمية لـ MTEB / CMTEB.
3.1 جدول مقارنة أداء أبعاد text-embedding-v4
| أبعاد المتجه | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | حجم المتجه الفردي | سيناريوهات موصى بها |
|---|---|---|---|---|---|---|
| 2048 بُعد | 71.58 | 61.97 | 71.99 | 75.01 | 8 كيلوبايت | أولوية الدقة القصوى |
| 1536 بُعد | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 كيلوبايت | توافق مع بيئة OpenAI |
| 1024 بُعد (افتراضي) | 68.36 | 59.30 | 70.14 | 73.98 | 4 كيلوبايت | سيناريوهات التوازن العام |
| 768 بُعد | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 كيلوبايت | توافق مع BGE-base |
| 512 بُعد | 64.73 | 56.34 | 68.79 | 73.33 | 2 كيلوبايت | استرجاع متوسط وصغير الحجم |
| 256 بُعد | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 كيلوبايت | إنتاجية عالية على نطاق واسع |
| 128 بُعد | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 بايت | تخزين بيانات ضخمة |
| 64 بُعد | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 بايت | سيناريوهات الضغط الأقصى |
💡 القيم الملحوظة بـ
*هي تقديرات منطقية مبنية على قوانين تلاشي MRL؛ أما القيم غير الملحوظة فهي مستمدة من القوائم الرسمية المعلنة.
يمكن استخلاص ثلاث نتائج رئيسية من الجدول:
- 1024 بُعد هو الحل الأمثل من حيث التكلفة والأداء: الأبعاد تمثل نصف أبعاد 2048، بينما خسارة الأداء طفيفة جداً (حوالي -3.2 نقطة في MTEB)، وهو الخيار الافتراضي الموصى به من قبل علي بابا.
- 2048 بُعد يوفر مكاسب واضحة: مقارنة بـ 1024 بُعد، يتحسن مؤشر CMTEB Retrieval بمقدار نقطة واحدة، وهو خيار يستحق الاستخدام في السيناريوهات الحساسة جداً للدقة.
- استخدم 64-128 بُعد بحذر: تنخفض جودة الاسترجاع بشكل ملحوظ في الأبعاد المنخفضة، وهي مناسبة فقط للسيناريوهات التي تفضل "توفير التكاليف على حساب دقة الاسترجاع".
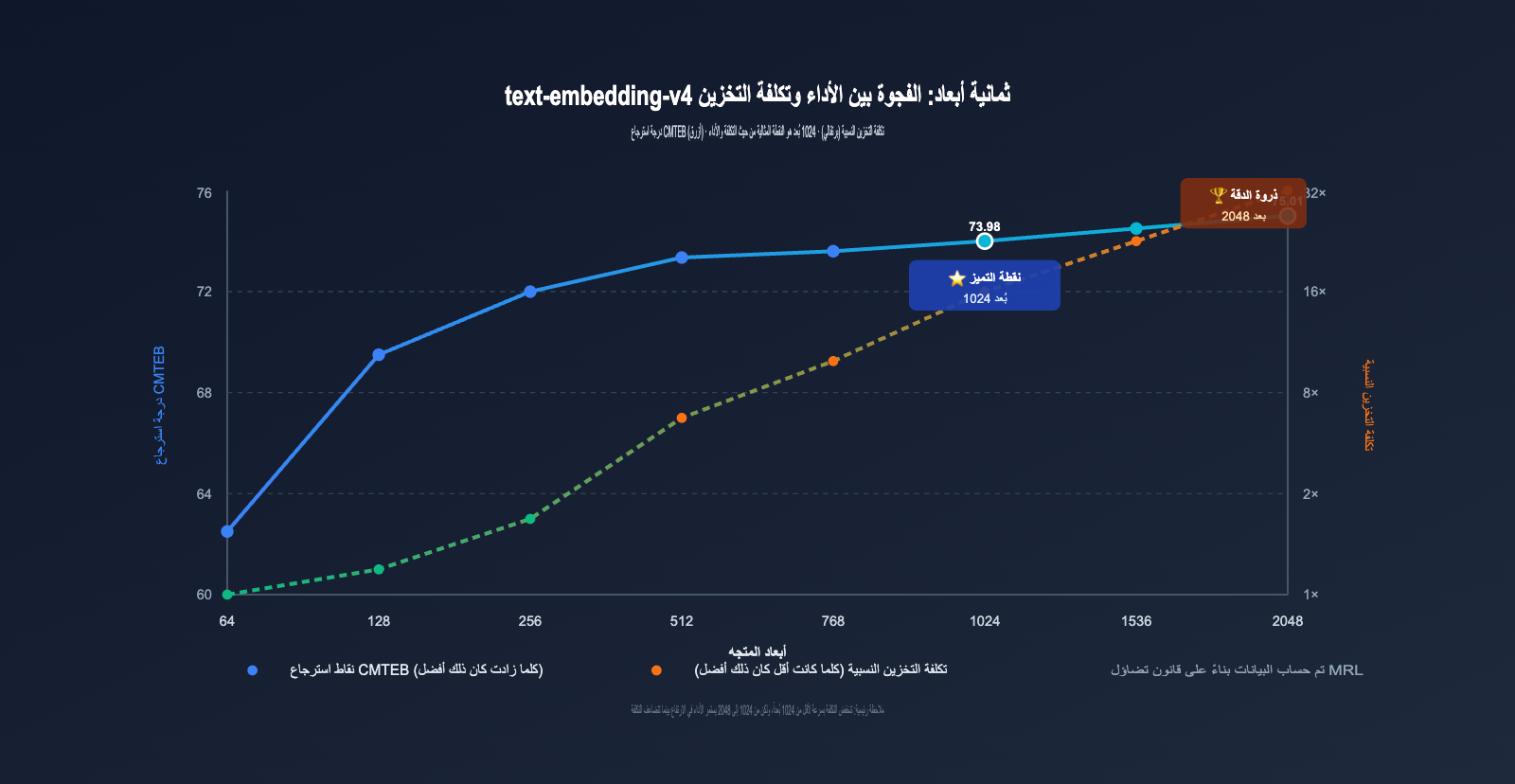
3.2 قانون تلاشي أداء الأبعاد في text-embedding-v4
بمراقبة البيانات الموضحة في الرسم البياني أعلاه، يمكننا استنتاج نمط هام جداً:
- من 2048 إلى 1024 بُعد: ينخفض مؤشر MTEB بمقدار 3.22 نقطة فقط (حوالي 4.5%)، بينما تنخفض مساحة التخزين للنصف ⭐️ نوصي به بشدة.
- من 1024 إلى 512 بُعد: ينخفض مؤشر MTEB بمقدار 3.63 نقطة (حوالي 5.3%)، مع انخفاض إضافي في التخزين للنصف 👍 مقبول.
- من 512 إلى 256 بُعد: ينخفض مؤشر MTEB بمقدار نقطتين تقريباً (حوالي 3.0%)، مع انخفاض إضافي في التخزين للنصف ⚠️ يعتمد على السيناريو.
- من 256 إلى 128 بُعد: ينخفض مؤشر MTEB بمقدار 2.5 نقطة تقريباً (حوالي 4.0%)، ولا يزال قابلاً للاستخدام ⚠️ يتطلب اختباراً كافياً.
- من 128 إلى 64 بُعد: ينخفض مؤشر MTEB بمقدار 2.5 نقطة، لكن مؤشر الاسترجاع (Retrieval) الفرعي يهبط بشكل حاد بمقدار 6 نقاط ❌ لا ننصح به في بيئة الإنتاج.
هذا يوضح أن "نطاق التلاشي الآمن" لـ MRL يقع بشكل أساسي فوق 256 بُعد، بينما يعتبر 64 بُعد منطقة ضغط قصوى.
رابعاً: دور أبعاد المتجهات: 3 تأثيرات جوهرية
يؤثر اختيار الأبعاد المختلفة على النظام بشكل شامل، ولا يقتصر الأمر على دقة الاسترجاع فقط. فيما يلي تفصيل للأبعاد الثلاثة الأكثر أهمية:
4.1 تأثير أبعاد المتجهات على دقة الاسترجاع
الدقة هي البعد الأكثر وضوحاً. لنأخذ نظام RAG يحتوي على مليون مستند كمثال:
- استخدام 2048 بُعداً: معدل استرجاع Top-10 يبلغ حوالي 91%
- استخدام 1024 بُعداً: معدل استرجاع Top-10 يبلغ حوالي 88%
- استخدام 256 بُعداً: معدل استرجاع Top-10 يبلغ حوالي 84%
- استخدام 64 بُعداً: معدل استرجاع Top-10 يبلغ حوالي 75%
🎯 نصيحة للاختيار: إذا كان عملك حساساً للغاية تجاه معدل الاسترجاع (مثل الاسترجاع القانوني أو الاستشارات الطبية)، فامنح الأولوية لاختيار 1024 أو 2048 بُعداً. نوصي بإجراء جولة اختبار للمقارنة بين 1024 و 2048 باستخدام نفس مجموعة البيانات الاختبارية على منصة APIYI (apiyi.com) قبل اتخاذ القرار النهائي.
4.2 تأثير أبعاد المتجهات على تكاليف التخزين والاسترجاع
هذا هو المؤشر الأكثر أهمية عند التطبيق على مستوى المؤسسات. لنفترض أن النظام يخزن 100 مليون متجه:
| أبعاد المتجه | إجمالي التخزين (float32) | تكلفة التخزين الشهرية (تقديرية) | تأخير الاسترجاع الفردي (تقديري) |
|---|---|---|---|
| 2048 بُعد | 800 جيجابايت | مرتفعة | بطيء |
| 1024 بُعد | 400 جيجابايت | متوسطة | متوسط |
| 512 بُعد | 200 جيجابايت | منخفضة | سريع نسبياً |
| 256 بُعد | 100 جيجابايت | منخفضة | سريع |
| 128 بُعد | 50 جيجابايت | منخفضة جداً | سريع جداً |
| 64 بُعد | 25 جيجابايت | منخفضة جداً | سريع جداً |
كما نرى، عند الانتقال من 2048 إلى 256 بُعداً، تنخفض تكلفة التخزين إلى الثُمن، وتزداد سرعة الاسترجاع بمقدار 6-8 أضعاف (اعتماداً على خوارزمية فهرسة ANN). بالنسبة لأحجام البيانات التي تتجاوز المليار، يؤثر اختيار الأبعاد بشكل مباشر على تكاليف البنية التحتية.
4.3 تأثير أبعاد المتجهات على التوافق وتكاليف الترحيل
تشعر العديد من الفرق بالقلق من أن عدم توافق أبعاد المتجهات سيؤدي إلى إتلاف الفهارس القديمة عند الانتقال من OpenAI أو BGE أو Cohere إلى نموذج text-embedding-v4. توفر خيارات الأبعاد الثمانية في v4 مسار ترحيل مرناً للغاية:
| النموذج القديم | الأبعاد القديمة | الأبعاد الموصى بها لـ text-embedding-v4 | ملاحظات الترحيل |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 بُعداً | توافق في الأبعاد، يمكن إعادة استخدام هيكل الفهرس |
| OpenAI text-embedding-3-small | 1536 | 1536 بُعداً | توافق تام |
| OpenAI text-embedding-3-large | 3072 | 2048 بُعداً | أقل قليلاً ولكن الدقة لا تزال متفوقة |
| BGE-large | 1024 | 1024 بُعداً | توافق تام، يمكن الاستبدال بسلاسة |
| BGE-base | 768 | 768 بُعداً | توافق تام |
| Cohere embed-multilingual-v3 | 1024 | 1024 بُعداً | توافق تام |
| نموذج صغير مدرب ذاتياً | 256/512 | 256/512 بُعداً | توافق في الأبعاد |
💼 نصيحة للمؤسسات عند الترحيل: تعتمد العديد من قواعد بيانات المتجهات في الأنظمة القديمة (مثل Milvus / Qdrant / pgvector) على جداول ذات أبعاد ثابتة. ابدأ باختيار نسخة من
text-embedding-v4تتطابق تماماً مع الأبعاد القديمة للاستبدال السلس، ثم قم بالترقية تدريجياً إلى أبعاد أعلى حسب الحاجة؛ فهذا هو المسار الأقل مقاومة. كما نوفر في وثائق APIYI (apiyi.com) أمثلة برمجية للربط مع قواعد بيانات المتجهات الرئيسية.
خامساً: البدء السريع مع text-embedding-v4: استدعاء API ومعلمات الأبعاد
بعد شرح المبادئ التقنية، لننتقل إلى الكود مباشرة. فيما يلي أبسط نموذج للاستدعاء، يغطي كلاً من بروتوكول التوافق مع OpenAI وبروتوكول DashScope الأصلي.
5.1 استخدام بروتوكول التوافق مع OpenAI لاستدعاء text-embedding-v4
توفر منصة DashScope من علي بابا نقاط نهاية متوافقة مع OpenAI، مما يسهل الأمر على الفرق التي لديها كود تكامل جاهز مع OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # نقطة الوصول الموحدة لـ APIYI
)
# استدعاء text-embedding-v4، مع تحديد 1024 بُعداً
response = client.embeddings.create(
model="text-embedding-v4",
input="كيف يتم تكوين أبعاد المتجهات لنموذج text-embedding-v4؟",
dimensions=1024 # اختياري: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"الأبعاد: {len(vector)}") # المخرجات: الأبعاد: 1024
print(f"أول 5 أبعاد: {vector[:5]}")
⚙️ شرح المعلمات:
dimensionsهي المعلمة الجديدة الرئيسية في v4، وهي مدعومة منذ v3 ولكن تم توسيعها في v4 لتشمل 8 خيارات. عند حذف هذه المعلمة، يتم استخدام 1024 بُعداً افتراضياً.
5.2 الاستدعاء الجماعي: التزامن وتحديد السرعة لـ text-embedding-v4
في بيئات الإنتاج الفعلية، غالباً ما تحتاج إلى معالجة البيانات بشكل جماعي. يدعم text-embedding-v4 ما يصل إلى 25 مدخلاً في الاستدعاء الواحد:
texts = [
"الدور الجوهري لأبعاد المتجهات هو الموازنة بين الدقة والتكلفة",
"يدعم text-embedding-v4 ثمانية أبعاد تتراوح من 64 إلى 2048",
"تعلم التمثيل بنمط 'الماتريوشكا' (Matryoshka) هو التقنية الأساسية",
# ... بحد أقصى 25 نصاً
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"عدد المتجهات المجمعة: {len(vectors)}")
5.3 الترميز غير المتماثل للاستعلام والمستند
يدعم text-embedding-v4 ميزات متقدمة غير متوفرة في بروتوكول OpenAI: التمييز بين استعلام البحث (query) والمستند المراد استرجاعه (document) عبر text_type لتحسين دقة الاسترجاع بشكل أكبر. تتطلب هذه الميزة استخدام بروتوكول DashScope الأصلي أو التغليف المتوافق مع منصة APIYI:
# ترميز جانب المستند (عند بناء الفهرس)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["يوفر text-embedding-v4 ثمانية خيارات لأبعاد المتجهات"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# ترميز جانب الاستعلام (عند البحث)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["ما هي الأبعاد التي يدعمها v4؟"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 قيمة الترميز غير المتماثل: بعد استخدام الترميز المتميز بين الاستعلام والمستند، يمكن أن يرتفع معدل استرجاع Top-1 بنسبة 2-3% في سيناريوهات البحث عن مستندات طويلة باستخدام استعلامات قصيرة. نوصي بشدة بتفعيل هذه الميزة في بيئة الإنتاج.
5.4 ربط text-embedding-v4 بقواعد بيانات المتجهات
يعد إدخال المتجهات في قاعدة البيانات خطوة أساسية في بناء نظام RAG. فيما يلي مثال باستخدام Qdrant، وهو خيار شائع في الصناعة، لعرض العملية الكاملة من تضمين النص إلى إدخال المتجهات:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# تهيئة العميل
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# هام: يجب أن تتطابق أبعاد المجموعة (collection) مع أبعاد التضمين (embedding dimensions)
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# التضمين الجماعي والإدخال في قاعدة البيانات
texts = ["text-embedding-v4 هو أحدث نموذج تضمين من علي بابا", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ تنبيه هام: يجب أن يتطابق حقل
sizeفي قاعدة بيانات المتجهات بدقة معdimensions. إذا أردت ترقية الأبعاد لاحقاً، يجب إعادة بناء المجموعة (collection) وإعادة تضمين البيانات بالكامل.
5.5 دمج text-embedding-v4 مع LangChain / LlamaIndex
تدعم أطر عمل RAG الرئيسية بالفعل الوصول إلى التضمين عبر بروتوكول التوافق مع OpenAI، والإعداد بسيط للغاية:
# مثال على دمج LangChain
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# التكامل السلس مع قاعدة بيانات المتجهات في LangChain
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("كيف تختار الأبعاد؟")
من خلال الوصول عبر بروتوكول التوافق مع OpenAI، يمكن تحويل جميع مشاريع RAG التي كانت تعتمد على OpenAI ada-002 / 3-large إلى text-embedding-v4 دون الحاجة لتعديل الكود، حيث يتطلب الأمر فقط تغيير اسم النموذج (model) وعنوان القاعدة (base_url).
6. استراتيجية اختيار أبعاد نموذج text-embedding-v4: 5 سيناريوهات نموذجية
بعد أن استعرضنا الجوانب النظرية وواجهات البرمجة، إليك إطار عمل لاختيار الأبعاد يمكنك تطبيقه مباشرة.
6.1 السيناريو أ: قاعدة معارف المؤسسة (RAG) (ملايين الوثائق)
المتطلب الأساسي: دقة الاسترجاع > التكلفة
الإعداد الموصى به:
- الأبعاد: 1024 بُعداً (القيمة الافتراضية، الأفضل من حيث التكلفة مقابل الأداء)
- تفعيل الترميز غير المتماثل (Asymmetric) للاستعلام/الوثيقة
- قاعدة بيانات المتجهات المقترحة: Milvus / Qdrant / pgvector
- إعادة الترتيب (Reranking): يُنصح باستخدام Qwen3-Reranker
6.2 السيناريو ب: البحث عن منتجات التجارة الإلكترونية (ملايين الوحدات SKU)
المتطلب الأساسي: سرعة البحث > الدقة
الإعداد الموصى به:
- الأبعاد: 512 بُعداً (متوازن) أو 256 بُعداً (للسرعة القصوى)
- استخدام ترميز الاستعلام لعناوين المنتجات، وترميز الوثيقة للتفاصيل
- فهرس ANN المقترح: مزيج من HNSW + IVF
6.3 السيناريو ج: إزالة التكرار في سجلات البيانات الضخمة (مئات الملايين من السجلات)
المتطلب الأساسي: تكلفة التخزين > الدقة
الإعداد الموصى به:
- الأبعاد: 128 بُعداً
- استخدام التكميم الثنائي (Binary Quantization) لضغط البيانات بمقدار 32 ضعفاً
- الاختبارات العملية تظهر بقاء معدل الاسترجاع فوق 85%
6.4 السيناريو د: البحث عالي الدقة (القانوني / الطبي)
المتطلب الأساسي: الدقة أولاً، التكلفة غير حساسة
الإعداد الموصى به:
- الأبعاد: 2048 بُعداً
- تفعيل الترميز غير المتماثل (Asymmetric) للاستعلام/الوثيقة
- من الضروري إضافة إعادة ترتيب (Reranker)
6.5 السيناريو هـ: البحث المحلي على الأجهزة المحمولة / الحافة
المتطلب الأساسي: استهلاك الذاكرة < 50 ميجابايت
الإعداد الموصى به:
- الأبعاد: 64 بُعداً أو 128 بُعداً
- استخدام تكميم int8 (لضغط إضافي بمقدار 4 أضعاف)
- مناسب لقواعد المعرفة المحلية / مساعدي الأسئلة والأجوبة دون اتصال بالإنترنت
🎯 نصيحة لاتخاذ القرار: تغطي هذه السيناريوهات الخمسة معظم احتياجات التطبيق العملي. ننصحك بالبدء بالقيمة الافتراضية 1024 بُعداً لتجربة مجموعة بيانات الاختبار الخاصة بك، ثم التعديل صعوداً (2048) أو نزولاً (512/256/128) بناءً على احتياجاتك الفعلية من حيث الدقة، التكلفة، والسرعة. تدعم منصة APIYI (apiyi.com) التبديل بين معلمات الأبعاد بضغطة زر، مما يسهل إجراء اختبارات A/B السريعة.
6.6 عملية اتخاذ قرار اختيار الأبعاد
يمكن تلخيص العملية أعلاه في خطوات تنفيذية:
-
الخطوة الأولى: تقييم حجم البيانات
- أقل من مليون سجل ← يمكن استخدام أبعاد عالية (1024+)
- من مليون إلى 100 مليون سجل ← أبعاد متوسطة (256-1024)
- أكثر من 100 مليون سجل ← يجب التفكير في الأبعاد المنخفضة (128-512)
-
الخطوة الثانية: تقييم مدى تحمل انخفاض الدقة
- الحساسية لكل 1% في معدل الاسترجاع ← اختر 2048
- قبول انخفاض 5% في معدل الاسترجاع ← ابدأ بـ 1024
- قبول انخفاض 10% في معدل الاسترجاع ← يكفي 256-512
-
الخطوة الثالثة: تقييم قيود الأجهزة
- البحث عبر GPU سحابي ← يمكن استخدام أبعاد عالية
- البحث عبر CPU فقط ← حافظ على الأبعاد ضمن 1024
- الأجهزة المحمولة / الحافة ← التزام صارم بـ 64-256 بُعداً + التكميم
-
الخطوة الرابعة: إجراء اختبارات التحقق
- اختر 100-500 استعلام حقيقي من عملك كمجموعة تقييم
- احسب معدل استرجاع Top-10 تحت أبعاد مختلفة
- اختر أقل بُعد يسبق "نقطة التحول" في معدل الاسترجاع
💡 نصيحة للكفاءة: تتضمن العملية أعلاه استدعاءات متكررة لواجهة برمجة التطبيقات (API) وتبديل المعلمات، لذا نوصي بإتمامها عبر منصة موحدة، حيث يمكنك الحصول على سجلات طلبات كاملة ومراقبة للاستهلاك، مما يسهل على الفريق التعاون في المقارنة واختيار النموذج الأنسب.
7. مقارنة أفقية بين text-embedding-v4 ونماذج التضمين السائدة
لنضع نموذج text-embedding-v4 في سياق الصناعة لتسهيل اختيارك التقني.
| النموذج | الشركة المصنعة | الحد الأقصى للأبعاد | مرونة الأبعاد | تقييم MTEB | القدرة باللغة الصينية | طول السياق | سعر API |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | Alibaba Tongyi | 2048 | ⭐⭐⭐⭐⭐ (8 أنواع) | 71.58 | قوية جداً | 32K | متوسط |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (اختياري) | 64.6 | متوسطة | 8K | مرتفع |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (اختياري) | 62.3 | متوسطة | 8K | منخفض |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 أنواع) | 70.3 | قوية | 128K | متوسط-مرتفع |
| BGE-M3 | BAAI | 1024 | ⭐⭐ (ثابت) | 65.5 | قوية | 8K | نشر ذاتي |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 أنواع) | 67.1 | متوسطة | 32K | متوسط |
| Qwen3-Embedding-8B (مفتوح المصدر) | Alibaba Tongyi | 4096 | ⭐⭐⭐⭐⭐ (اختياري) | 70.58 | قوية جداً | 32K | نشر ذاتي |
من جدول المقارنة هذا، يمكن استخلاص عدة استنتاجات رئيسية:
- سيناريوهات اللغة الصينية والإنجليزية: حقق نموذج text-embedding-v4 درجة 71.99 في تقييم CMTEB، ليحتل المرتبة الأولى بين جميع واجهات برمجة التطبيقات التجارية.
- مرونة الأبعاد: توفر الأبعاد الثمانية الموصى بها رسمياً في v4 مرونة أكبر من معظم النماذج الأخرى، مما يجعل الانتقال إليها سهلاً للغاية.
- التكلفة مقابل الأداء: يقع سعر API الخاص بـ v4 في مستوى متوسط بين النماذج التجارية السائدة، لكن دقتها تضاهي نموذج OpenAI text-embedding-3-large.
📌 نصيحة للربط: إذا كان فريقك يحتاج إلى استخدام نماذج متعددة مثل OpenAI وClaude وQwen في آن واحد، فنحن نوصي بالربط عبر منصة موحدة مثل APIYI (apiyi.com). هذا يجنبك عناء إدارة مفاتيح API متعددة والتعامل مع مشاكل الوصول داخل الصين، كما توفر الوثائق أمثلة لاستدعاء v4 بالتوازي مع نماذج التضمين السائدة الأخرى.
ثامناً: الأسئلة الشائعة (FAQ) حول text-embedding-v4
س1: ما هو البعد الافتراضي لـ text-embedding-v4؟
البعد الافتراضي لـ text-embedding-v4 هو 1024 بُعداً. إذا لم تقم بتمرير معامل dimensions بشكل صريح عند استدعاء الـ API، فسيتم إرجاع متجه بـ 1024 بُعداً. وهذا هو البعد الذي توصي به "علي بابا" رسمياً كأفضل توازن بين الأداء والتكلفة.
س2: هل يمكنني ترقية الفهرس الذي تم إنشاؤه بـ 1024 بُعداً إلى 2048 بُعداً؟
تحتاج إلى إعادة بناء قاعدة بيانات المتجهات بالكامل. تضمن آلية "ماتريوشكا" (MRL) أن "المتجه عالي الأبعاد مع اقتطاع أول N بُعد" يساوي "المتجه منخفض الأبعاد"، ولكن العكس، أي "رفع الأبعاد المنخفضة إلى عالية عن طريق إضافة أصفار"، غير فعال. عند الترقية، يُنصح بالآتي:
- الاحتفاظ بالفهرس القديم (1024 بُعداً) يعمل عبر الإنترنت.
- إعادة تضمين المستندات بالكامل باستخدام v4 بـ 2048 بُعداً.
- التحقق من تحسن الدقة عبر تحويل تدريجي لحركة المرور (Gray release).
- إيقاف الفهرس القديم بعد اكتمال العملية.
س3: هل يمكن استدعاء text-embedding-v4 مباشرة داخل الصين؟
نعم، نقطة النهاية الرسمية لـ text-embedding-v4 تقع في dashscope.aliyuncs.com (بكين)، والاتصال مباشر داخل الصين. يحتاج المطورون فقط إلى تسجيل حساب في "علي بابا كلاود" أو استخدام منصة وكيل API مثل APIYI (apiyi.com) للحصول على مفتاح API، دون الحاجة إلى أي إعدادات شبكة إضافية.
س4: كيف تختار بين text-embedding-v4 والنسخة مفتوحة المصدر Qwen3-Embedding؟
| عامل القرار | اختيار نسخة API (v4) | اختيار النسخة مفتوحة المصدر (Qwen3-Embedding-8B) |
|---|---|---|
| حساسية البيانات | حساسية عادية | حساسية فائقة (مالية/طبية) |
| حجم الاستدعاء الشهري | أقل من مليار Token | أكثر من مليار Token |
| موارد GPU للفريق | لا يوجد | امتلاك مجموعة A100/H100 |
| القدرات الهندسية | فرق صغيرة ومتوسطة | وجود فريق MLOps |
| التوصية العامة | ✅ نوصي بـ v4 API | ✅ نوصي بالنشر الذاتي |
س5: هل سيظهر خطأ في النموذج إذا تم ضبط البعد بشكل خاطئ؟
يقبل text-embedding-v4 فقط القيم الموجودة في القائمة [64, 128, 256, 512, 768, 1024, 1536, 2048]. تمرير قيم أخرى (مثل 333 أو 500) سيؤدي مباشرة إلى خطأ في المعاملات. إذا كنت بحاجة إلى أبعاد غير قياسية، يمكنك اختيار أقرب بُعد رسمي ثم إجراء اقتطاع أو حشو (Padding).
س6: كيف يمكنني تقييم البعد المناسب لعملي الحالي؟
نوصي باتباع نهج الخطوات الثلاث:
- تشغيل خط الأساس: ابدأ بالبعد الافتراضي 1024 لتشغيل سير عملك، وسجل معدل الاسترجاع، وزمن الاستجابة، وتكاليف التخزين.
- التجربة نحو الأسفل: انتقل تدريجياً إلى 512، 256، 128 بُعداً، ولاحظ مدى انخفاض معدل الاسترجاع.
- تحديد النقطة المثالية: ابحث عن البعد الذي يحقق "انخفاضاً مقبولاً في الاسترجاع + أكبر انخفاض في التكلفة"، وعادة ما يكون 256 أو 512 بُعداً.
س7: هل سيتم إتاحة text-embedding-v4 كمصدر مفتوح؟
استراتيجية "علي بابا" الحالية هي الموازاة بين نسخة API والنسخة مفتوحة المصدر: يستمر تطوير API التجاري لـ text-embedding-v4 مع الاستفادة من أحدث التحسينات الهندسية وتعزيز البيانات، بينما يتم إصدار سلسلة Qwen3-Embedding مفتوحة المصدر للمجتمع. كلاهما يشترك في نفس التكنولوجيا ولكن بأشكال منتجات مختلفة، ومن غير المتوقع أن يتم فتح مصدر v4 بشكل منفصل في المستقبل.
س8: هل الأبعاد الأعلى أفضل دائماً؟
لا. اختيار البعد هو في جوهره مقايضة ثلاثية بين الدقة، التخزين، والسرعة:
- أبعاد أعلى ← سقف دقة أعلى، ولكن مع تناقص في العوائد الهامشية.
- أبعاد أعلى ← زيادة خطية أو حتى فائقة الخطية في تكاليف التخزين والاسترجاع.
- أبعاد أعلى ← قد تنخفض الدقة في فهارس ANN بسبب "لعنة الأبعاد".
من واقع الخبرة، يُعد نطاق 256-1024 بُعداً هو منطقة العمل المثالية لمعظم الأعمال، ولا يستحق تجاوز 1024 بُعداً إلا إذا كانت هناك حاجة واضحة ومحددة لتحسين الدقة.
س9: كيف هو أداء text-embedding-v4 مع النصوص الطويلة؟
يدعم text-embedding-v4 طول إدخال يصل إلى 32 ألف Token، لكن أداء الاسترجاع الفعلي ينخفض مع زيادة طول النص. نوصي باتباع المبادئ التالية:
- النصوص القصيرة (< 512 Token): التضمين المباشر للفقرة كاملة يعطي أفضل النتائج.
- الطول المتوسط (512-4K Token): فكر في استخدام التضمين عبر نافذة منزلقة (Sliding window).
- المستندات الطويلة (> 4K Token): يجب تقسيمها إلى أجزاء (Chunks) قبل التضمين، ويُفضل أن يكون حجم الجزء 256-512 Token.
- المستندات الطويلة جداً: يمكن دمجها مع الاسترجاع الهرمي (خشن ثم دقيق) لتحسين الكفاءة.
س10: هل يمكن خلط أبعاد مختلفة؟
لا. يجب أن تكون جميع المتجهات في نفس قاعدة بيانات المتجهات / الفهرس بنفس الأبعاد، وإلا فإن حساب التشابه سيكون بلا معنى. إذا كانت طبيعة العمل تتطلب استراتيجية "مستندات ذات أولوية عالية بـ 2048 بُعداً + مستندات عادية بـ 512 بُعداً"، فنحن نوصي بإنشاء مجموعتين (Collections) مستقلتين وإدارتهما بشكل منفصل، ثم دمج النتائج على مستوى التطبيق.
س11: هل يؤثر معامل البعد على فواتير الـ API؟
تعتمد فواتير text-embedding-v4 بالكامل على عدد الـ Tokens المدخلة، ولا علاقة لها ببعد المخرجات. وهذا يعني أنه سواء اخترت 64 بُعداً أو 2048 بُعداً، فإن تكلفة معالجة 1000 Token هي نفسها. وهذا يعني أنه يمكنك اختيار أبعاد عالية في مرحلة استدعاء الـ API دون قلق، حيث تظهر فروق التكلفة الحقيقية بشكل أساسي في مراحل التخزين والاسترجاع اللاحقة.
س12: كيف يمكن التعامل مع فشل التضمين / قيود المعدل (Rate Limiting)؟
عند استدعاء text-embedding-v4 في بيئة الإنتاج، نوصي بإضافة معالجة المتانة التالية:
- آلية إعادة المحاولة: تنفيذ إعادة محاولة مع تراجع أسي لأخطاء 5xx (نوصي بـ 3 مرات).
- معالجة قيود المعدل: مراقبة أخطاء 429، وعند حدوثها، قم بتقليل التزامن أو التبديل إلى قناة وصول أخرى.
- حجم الدفعة: الحد الأقصى للطلب الواحد هو 25 نصاً، ويجب التقسيم التلقائي إذا تجاوزت ذلك.
- إعدادات المهلة: بالنسبة لتضمين النصوص الطويلة، يُنصح بضبط المهلة لأكثر من 60 ثانية.
- خطة التراجع: يمكن تكوين نموذج احتياطي (مثل v3 1024 بُعداً) كخيار بديل.
تاسعاً: ملخص: النقاط الجوهرية لاختيار أبعاد المتجهات في text-embedding-v4
بالنظر إلى المقال كاملاً، إليك النقاط الجوهرية حول أبعاد المتجهات الثمانية في text-embedding-v4:
- text-embedding-v4 هو المنتج التجاري الرائد لسلسلة Qwen3-Embedding، بأداء رائد في السيناريوهات ثنائية اللغة (العربية/الإنجليزية).
- الأبعاد الثمانية هي في جوهرها نتاج تقنية "ماتريوشكا"، ويمكن استخدام أول N بُعد منها مع خسارة جودة يمكن التحكم فيها.
- 1024 بُعداً هو القيمة الافتراضية الموصى بها، والتي تحقق التوازن الأمثل بين الدقة والتكلفة.
- 2048 بُعداً مناسب لسيناريوهات الدقة القصوى، حيث يحقق تحسناً بمقدار نقطة واحدة في استرجاع CMTEB مقارنة بـ 1024.
- 256-512 بُعداً مناسب للنطاق المتوسط + السيناريوهات الحساسة للتكلفة، وهي النقطة المثالية لمعظم أنظمة RAG.
- 64-128 بُعداً يوصى به فقط للأجهزة الطرفية / سيناريوهات التخزين المحدودة، مع ضرورة اختبار انخفاض معدل الاسترجاع.
- اختيار البعد ليس قراراً نهائياً لا رجعة فيه، ونوصي بشدة بتشغيل مجموعة اختبارات العمل قبل اتخاذ القرار النهائي.
- عند الانتقال من نماذج أخرى إلى v4، اختر الإصدار الذي يطابق الأبعاد لضمان انتقال سلس.
🎯 التوصية النهائية: إذا كنت تختار نموذج تضمين لمشروع جديد، ابدأ مباشرة بـ text-embedding-v4 + 1024 بُعداً؛ وإذا كان عملك حساساً للغاية تجاه معدل الاسترجاع، فارفع البعد إلى 2048 مع إضافة Reranker. نوصي بالوصول عبر منصة APIYI (apiyi.com)، حيث توفر المنصة واجهة متوافقة مع OpenAI، وتبديلاً سهلاً للأبعاد، ووثائق ربط كاملة، مما يقلل بشكل كبير من تكاليف الربط الهندسي ويسمح للفريق بالتركيز على تحسين أداء الأعمال بدلاً من تكييف الـ API.
تتطور تقنية تضمين المتجهات بسرعة، من عصر الأبعاد الثابتة في OpenAI إلى اليوم حيث يطبق text-embedding-v4 تقنية MRL في 8 أبعاد رسمية، مما يمنح المطورين مرونة غير مسبوقة. إن إتقان جوهر أبعاد المتجهات واستراتيجيات الاختيار هو مهارة أساسية لكل فريق يبني أنظمة RAG / البحث الدلالي / أنظمة التوصية.
المؤلف: فريق APIYI التقني | نركز على التطبيق العملي لنماذج الذكاء الاصطناعي الكبيرة، لمزيد من المحتوى التقني تفضل بزيارة APIYI apiyi.com