في أبريل 2026، كان نموذجا البرمجة الأكثر تداولاً بين المطورين في الصين هما GLM-5.1 و Claude Sonnet 4.6. الأول أطلقته شركة Z.ai (المعروفة سابقاً بـ Zhipu) مؤخراً بترخيص MIT مفتوح المصدر، حيث حقق 58.4 نقطة على معيار SWE-Bench Pro، متفوقاً بذلك على Claude Opus 4.6 و GPT-5.4 و Gemini 3.1 Pro، ليعتلي صدارة نماذج البرمجة مفتوحة المصدر عالمياً. أما الثاني، فقد وصفته Anthropic بأنه "مستوى رائد في النماذج متوسطة الحجم"، حيث حقق 79.6% على معيار SWE-bench Verified، مقترباً من نسبة 80.8% التي حققها Opus 4.6، مع تكلفة أقل بكثير، ولأول مرة يوفر نافذة سياق تصل إلى 1 مليون توكن لسلسلة Sonnet.
السؤال هنا: بين GLM-5.1 و Claude Sonnet 4.6، أيهما الأقوى في سيناريوهات البرمجة الحقيقية؟ الإجابة ليست بكلمة واحدة، فنقاط القوة لدى كل منهما مختلفة تماماً: يتفوق GLM-5.1 في معيار "إصلاح الأكواد البرمجية في بيئات العمل الحقيقية"، بينما يستعيد Sonnet 4.6 الصدارة في التقييمات الشاملة التابعة لجهات خارجية. ستفكك هذه المقالة الفروقات الحقيقية بينهما عبر 6 أبعاد (معايير الكود، المعرفة، السعر، نافذة السياق، مهام الوكيل (Agent) طويلة المدى، والتوافق مع النظام البيئي)، مع تقديم توصيات واضحة للاختيار بناءً على طبيعة عملك.

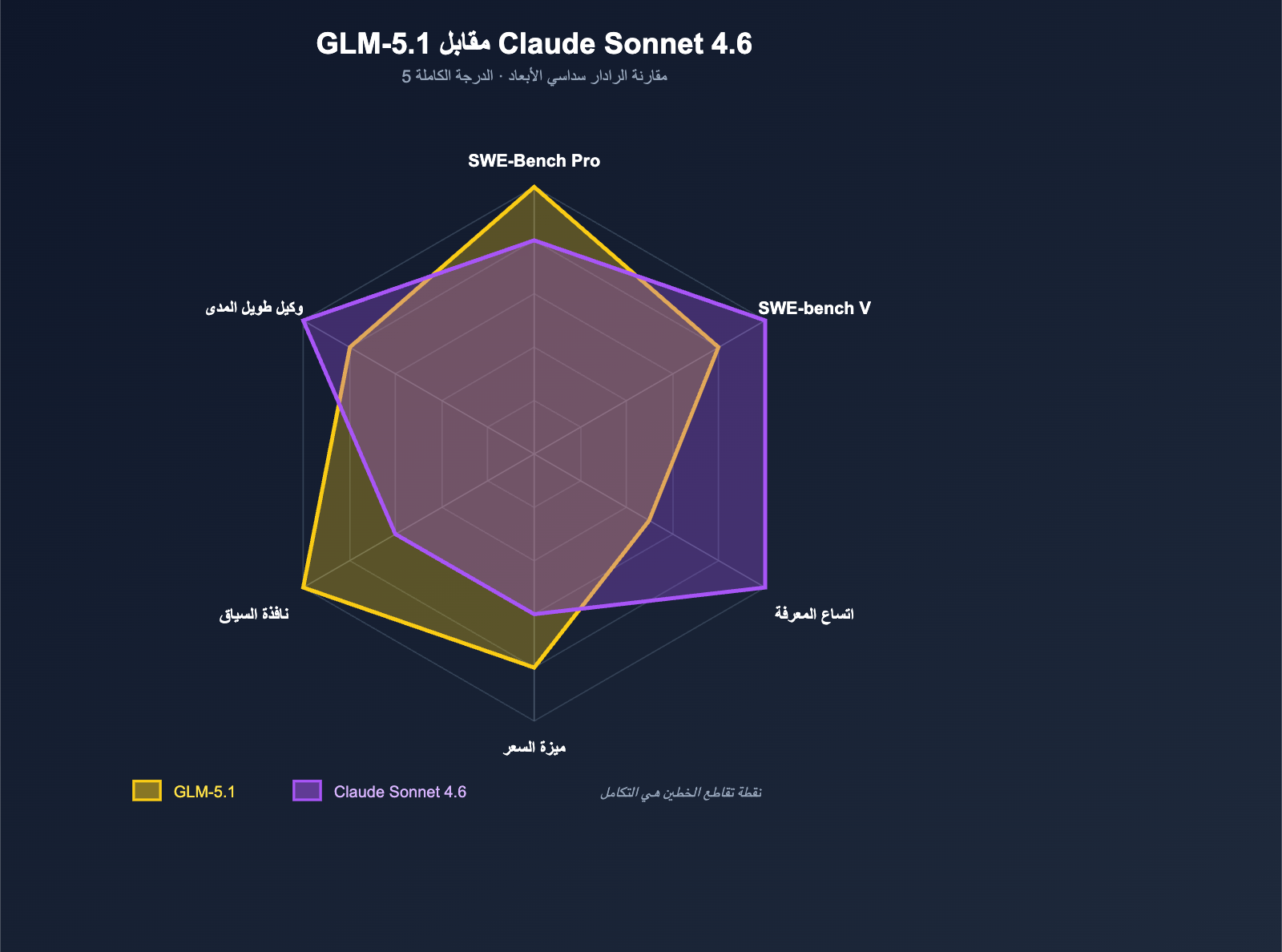
نظرة سريعة على البيانات الأساسية لـ GLM-5.1 و Claude Sonnet 4.6
قبل البدء بالمقارنة العملية، دعنا نضع الحقائق الرئيسية لكل منهما جنباً إلى جنب في جدول واحد. جميع البيانات مستمدة من المعلومات العامة لمنصات BenchLM و Z.ai و Anthropic ومنصات التقييم التابعة لجهات خارجية.
| البعد | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| الشركة المصنعة | Z.ai (سابقاً Zhipu AI) | Anthropic |
| تاريخ الإصدار | 2026-04-07 (مفتوح المصدر) | أوائل 2026 |
| البنية | 754B MoE / 40B تفعيل | غير معلن (مستوى Sonnet متوسط) |
| ترخيص مفتوح المصدر | ✅ MIT | ❌ مغلق المصدر |
| نافذة السياق | 200K (تظهر 203K في بعض المنصات) | 200K → 1M (تجريبي) |
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐ (الأول مفتوح المصدر، تفوق على Opus 4.6) | أقل بقليل من Opus 4.6 |
| متوسط تقييم البرمجة الشامل BenchLM | 58.4 | 66.4 |
| متوسط تقييم المعرفة BenchLM | 52.3 | 73.7 |
| إجمالي نقاط BenchLM | 79 | 80 |
| سعر الإدخال ($/مليون توكن) | $1.00 (مباشر من Z.ai) | $3.00 |
| سعر الإخراج ($/مليون توكن) | $3.20 (مباشر من Z.ai) | $15.00 |
| مهام الوكيل طويلة المدى | حوالي 8 ساعات للمهمة الواحدة | 70% نسبة تفضيل المستخدمين لـ Claude Code |
| الوصول عبر خدمة وكيل API | ✅ متاح https://api.apiyi.com/v1 |
✅ متاح |
| الأدوات المتوافقة | Claude Code / Cline / Cursor / OpenClaw | نفس ما سبق + النظام البيئي الأصلي لـ Anthropic |
🎯 نصيحة سريعة للاختيار: الفرق بينهما ليس في "من الأقوى"، بل في "أي سيناريو يناسب أياً منهما". إذا كنت ترغب في إجراء مقارنة أفقية فورية، فقد أتاحت خدمة وكيل API (APIYI) على apiyi.com كلاً من GLM-5.1 و Claude Sonnet 4.6. ما عليك سوى تعديل حقل
modelللتبديل بينهما في نفس كود العمل الخاص بك، وستتمكن خلال 15 دقيقة من اتخاذ قرار أدق من أي تقييمات عامة بناءً على مهامك الفعلية.
الفروقات الجوهرية بين GLM-5.1 و Claude Sonnet 4.6: ليسا من نفس الفئة
الحقيقة الأولى التي يجب توضيحها هي أن GLM-5.1 و Claude Sonnet 4.6 ليسا "من نفس الفئة" من النماذج بالمعنى الدقيق للكلمة، حيث توجد اختلافات منهجية في أهداف تصميمهما.
الاختلاف في تموضع النماذج
| البعد | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| تموضع الشركة | "مفتوح المصدر متطور + وكيل برمجي طويل المدى" | "رائد متوسط الفئة · الأفضل من حيث القيمة" |
| حجم المعاملات | نموذج لغة كبير (754B MoE) | نموذج متوسط الحجم (المعاملات غير معلنة) |
| هدف التدريب | البرمجة + الوكيل + الاستنتاج الرياضي | عام + برمجة + معرفة + أمان |
| نموذج العمل | مفتوح المصدر (MIT) + API خاص بـ Z.ai | اشتراك مغلق المصدر + API |
| المنافسون الرئيسيون | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
لاحظ هذا السطر — التموضع الداخلي لنموذج GLM-5.1 في Z.ai يستهدف في الواقع Claude Opus 4.6 وليس Sonnet 4.6. وهذا يعني أنه إذا كنت تقارن "الحد الأقصى لقدرات البرمجة"، فإن المقارنة الصحيحة لـ GLM-5.1 يجب أن تكون مع Opus وليس Sonnet. ولكن من حيث "السعر + القدرات الشاملة + القابلية للاستخدام"، فإن Sonnet 4.6 يعد منافساً قوياً جداً في سوق الفئة المتوسطة، لذا فإن مقارنتهما معاً لها قيمة هندسية عملية للغاية.
الوضع الحالي في التقييمات الشاملة من أطراف ثالثة
وفقاً للتصنيف المؤقت الذي أصدرته BenchLM في أبريل 2026:
- النتيجة الإجمالية: Claude Sonnet 4.6 = 80، GLM-5.1 = 79 (فارق نقطة واحدة، تقارب شديد)
- متوسط درجات البرمجة: Claude Sonnet 4.6 = 66.4، GLM-5.1 = 58.4 (يتفوق Sonnet 4.6 بـ 8 نقاط)
- متوسط درجات المعرفة: Claude Sonnet 4.6 = 73.7، GLM-5.1 = 52.3 (يتفوق Sonnet 4.6 بـ 21.4 نقطة، وهو أكبر فارق)
ولكن في معيار تخصصي آخر، انقلبت الآية تماماً:
- SWE-Bench Pro (إصلاح الكود الصناعي الحقيقي): GLM-5.1 = 58.4 ⭐، متجاوزاً Claude Opus 4.6 بـ 57.3 و GPT-5.4 بـ 57.7، وبالطبع يتفوق على Sonnet 4.6.
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%، GLM-5.1 = 77.8%، بفارق 1.8 نقطة مئوية فقط.
من خلال النظر إلى هذه الأرقام، نصل إلى الاستنتاج الأول: GLM-5.1 ليس وحشاً "يتفوق على Sonnet 4.6 في كل شيء"، لكنه حقق المركز الأول في "أصعب مهام إصلاح الكود الصناعي"، بينما لا يزال Sonnet 4.6 يحتفظ بتفوق متوازن في تقييمات البرمجة الشاملة الأوسع.

البعد الأول: مقارنة معايير البرمجة — الفارق الحقيقي بين GLM-5.1 و Sonnet 4.6
تعد القدرة البرمجية جوهر هذه المقارنة، وهي الجزء الأكثر عرضة للتضليل بالأرقام المعيارية. قمنا بدمج جميع المعايير ذات الصلة في جدول واحد، ثم سنقدم تحليلاً من منظور هندسي.
مقارنة كاملة لمعايير البرمجة
| المعيار | GLM-5.1 | Claude Sonnet 4.6 | المتفوق | الفارق |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ نقطة |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| متوسط درجات البرمجة BenchLM | 58.4 | 66.4 | Sonnet 4.6 | 8 نقاط |
| OSWorld (سطح مكتب الوكيل) | غير معلن | 72.5% | Sonnet 4.6 | — |
| معدل تفضيل مستخدمي Claude Code | لم يشارك | 70%(لـ Sonnet 4.5)، 59%(لـ Opus 4.5) | Sonnet 4.6 | — |
| مهام طويلة المدى (8 ساعات) | ✅ ميزة رسمية | مدعوم في Claude Code | تقارب شديد | — |
قراءة من منظور هندسي
بعد قراءة هذا الجدول ثلاث مرات، يمكن استخلاص عدة استنتاجات واضحة حتى لغير المهتمين بالمعايير الصناعية:
- إذا كان عملك هو "إصلاح أخطاء برمجية حقيقية في مستودعات حقيقية": يحتل GLM-5.1 المركز الأول في SWE-Bench Pro، وهو معيار "قريب جداً من المهام اليومية للمهندسين"، مما يعني أن GLM-5.1 هو الأنسب ليكون المحرك الأساسي لوكيل البرمجة (Coding Agent)؛
- إذا كان عملك هو "إصلاح كود قياسي + برمجة عامة": يتفوق Sonnet 4.6 قليلاً في SWE-bench Verified، كما يتفوق بوضوح في متوسط درجات البرمجة الشاملة، فهو أكثر استقراراً من حيث "الشمولية"؛
- إذا كان عملك يتضمن مهاماً طويلة المدى داخل Claude Code / Cursor: يشير معدل تفضيل المستخدمين لـ Sonnet 4.6 البالغ 70% إلى أنه تم التحقق منه في "سير عمل التطوير الفعلي"؛ أما قدرة GLM-5.1 على المهام طويلة المدى لمدة 8 ساعات فهي نقطة البيع الرئيسية لـ Z.ai، لكنك تحتاج لتجربتها بنفسك للتأكد من النتائج؛
- إذا كان عملك يتضمن "مشكلات كثيفة المعرفة" (البحث في الوثائق، كتابة التصاميم، إجراء أبحاث تقنية): الفارق واضح جداً (73.7 لـ Sonnet 4.6 مقابل 52.3 لـ GLM-5.1).
لماذا تظهر هذه "التعارضات في المعايير"؟
يتساءل الكثير من القراء: لماذا يظهر معيار أن GLM-5.1 أقوى، بينما يظهر آخر أن Sonnet 4.6 أقوى؟ الإجابة تكمن في اختلاف تصميم المعايير:
- SWE-Bench Pro يميل إلى "إصلاح الكود الصناعي الحقيقي عالي الصعوبة"، حيث تكون عتبة جودة المهام عالية والعدد قليل، ويتطلب قدرات فائقة في "الاستنتاج طويل المدى + استدعاء الأدوات" — وهو بالضبط ما يركز عليه GLM-5.1؛
- SWE-bench Verified هو "مجموعة مهام إصلاح كود قياسية تم التحقق منها بشرياً"، وهي أقرب إلى "المستوى المتوسط لسيناريوهات التطوير اليومية"، وتتطلب "شمولية + استقرار" أعلى — وهي نقاط قوة Sonnet 4.6؛
- متوسط درجات البرمجة BenchLM يقوم بحساب المتوسط المرجح لعدة معايير، وهو أكثر ملاءمة للنماذج الرائدة متوسطة الحجم التي يمكنها التعامل مع "أنواع مختلفة من المهام".
بمجرد فهم هذا الاختلاف، لن تضللك أي أرقام منعزلة بعد الآن.
🎯 نصيحة لاختيار المعيار: لا تعتمد على معيار واحد فقط لاستخلاص النتائج. الممارسة الأكثر واقعية هي: قم بتجميع 5-10 مهام برمجية حقيقية شائعة في فريقك في مجموعة معايير داخلية، ثم استخدم APIYI (apiyi.com) لاستدعاء كل من GLM-5.1 و Claude Sonnet 4.6 لتجربتهما، واستخدم بياناتك الخاصة للتحقق من أيهما يناسب طبيعة عملك بشكل أفضل.
البعد الثاني: المعرفة والاستنتاج — منطقة التفوق الواضح لـ Sonnet 4.6
إذا كان مستوى البرمجة يشهد "تجاذباً وتنافساً"، فإن Sonnet 4.6 تتفوق بشكل واضح في بُعد المعرفة / الاستنتاج / الفهم العام.
| البعد | GLM-5.1 | Claude Sonnet 4.6 | الفارق |
|---|---|---|---|
| متوسط معرفة BenchLM | 52.3 | 73.7 | 21.4 نقطة |
| فهم المستندات الطويلة | قوي | أقوى (مع نافذة سياق 1M) | |
| الكتابة باللغة الطبيعية | ممتازة بالصينية | متوازنة بلغات متعددة | |
| استنتاج الأمان والامتثال | متوسط | أقوى بشكل ملحوظ (نقطة قوة Anthropic) |
هذا يعني أن Sonnet 4.6 هي الخيار الأكثر أماناً وموثوقية في السيناريوهات التالية:
- كتابة تقارير الأبحاث التقنية / مستندات التصميم / خطط البنية التحتية؛
- تلخيص المستندات متعددة اللغات وتحليل الامتثال؛
- المهام الهجينة التي تتطلب "فهماً للبرمجة والأعمال معاً"؛
- توليد المحتوى الموجه للعملاء مباشرة، حيث تتطلب حواجز حماية أمنية أكثر صرامة.
إن الضعف النسبي لنموذج GLM-5.1 في بُعد المعرفة لا يعني "نقصاً في التدريب"، بل إن بيانات تدريبه وأهدافه تميل أكثر نحو البرمجة + الرياضيات + استخدام الأدوات، وهي أقل توازناً في "المعرفة العامة" مقارنة بـ Sonnet 4.6.
البعد الثالث: مقارنة الأسعار — الورقة الرابحة لـ GLM-5.1
إذا نظرنا إلى عامل واحد فقط، فإن السعر هو السلاح الأكثر فتكاً الذي يمتلكه GLM-5.1 في مواجهة Sonnet 4.6.
مقارنة مباشرة لسعر الـ Token
| البعد | GLM-5.1 (شراء مباشر من Z.ai) | Claude Sonnet 4.6 | ميزة التكلفة لـ GLM-5.1 |
|---|---|---|---|
| الإدخال ($/مليون) | $1.00 | $3.00 | أرخص بـ 3 أضعاف |
| الإخراج ($/مليون) | $3.20 | $15.00 | أرخص بـ ~4.7 ضعف |
| الإجمالي (نسبة 2:1) | ~$1.73 | ~$7.00 | أرخص بـ ~4 أضعاف |
ملاحظات هامة:
- الأسعار التي توفرها منصات الطرف الثالث (مثل BenchLM) لنموذج GLM-5.1 أعلى قليلاً ($1.40 للإدخال / $4.40 للإخراج)، وذلك بسبب عمولة إعادة البيع، بينما السعر الرسمي للشراء المباشر من Z.ai هو $1.00 / $3.20؛
- سعر Sonnet 4.6 البالغ $3 / $15 هو السعر الرسمي من Anthropic، وهو أرخص بالفعل بـ 5 أضعاف من Opus 4.6، ويُعد "ملك القيمة مقابل السعر" في السوق المتوسط؛
- ومع ذلك، لا يزال تفوق GLM-5.1 في تكلفة الـ token للإخراج بمقدار 4-5 أضعاف أمراً بالغ الأهمية لسيناريوهات توليد الأكواد حيث "تتجاوز كمية الإخراج كمية الإدخال".
مثال على التكلفة الفعلية
لتوضيح الفارق بشكل ملموس، لنفترض مهمة نموذجية لـ "وكيل برمجة يومي" (Coding Agent): إدخال 5 آلاف token، وإخراج 20 ألف token، مع 1000 استدعاء يومياً.
| النموذج | تكلفة الإدخال/يوم | تكلفة الإخراج/يوم | الإجمالي/يوم | الإجمالي/شهر |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
الفارق: التكلفة الشهرية لـ Sonnet 4.6 تعادل حوالي 4.5 ضعف تكلفة GLM-5.1.
بالنسبة لشركة SaaS متوسطة الحجم لديها "1000 استدعاء للوكيل يومياً"، فإن تكلفة الـ Token وحدها قد تخلق فارقاً يصل إلى 7000 دولار شهرياً — وهو مبلغ يكفي لتوظيف نصف مهندس إضافي.
🎯 نصيحة لتحسين التكلفة: بالنسبة للفرق التي تستخدم Claude Sonnet 4.6 بالفعل، نقترح البدء بتحويل 20% من حركة المرور إلى GLM-5.1 عبر APIYI (apiyi.com) لإجراء اختبار A/B. إذا كانت النتائج مقبولة، يمكن نقل "توليد الأكواد للمهام غير الحرجة" بالكامل إلى GLM-5.1، والاحتفاظ بـ Sonnet 4.6 للاستدعاءات الحرجة "الموجهة للعملاء" فقط — وبهذه الطريقة يمكنك خفض الفاتورة بشكل كبير دون المساس بالجودة الإجمالية.
البعد الرابع: نافذة السياق — هجوم Sonnet 4.6 المضاد
من حيث السعر، يتفوق GLM-5.1 بوضوح، ولكن في بند نافذة السياق، استعاد Sonnet 4.6 زمام المبادرة.
| البعد | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| السياق القياسي | 200 ألف (203 ألف في بعض المنصات) | 200 ألف |
| سياق تجريبي (Beta) | — | 1 مليون رمز (beta) |
| الحد الأقصى للمخرجات | 128 ألف | أقل |
| ضغط السياق | لا | ✅ ضغط تلقائي للسياق القديم |
يُعد 1 مليون رمز ترقية فارقة لنموذج Sonnet 4.6، فهي تعني أنه يمكنك وضع مستودع برمجيات متوسط الحجم بالكامل داخل الموجه (prompt) دفعة واحدة دون الحاجة إلى استرجاع RAG. بالنسبة لمهام مثل "إعادة هيكلة المستودع بالكامل / تحديد الأخطاء عبر الملفات / فهم قاعدة الكود البرمجي بالكامل"، يكاد يكون Sonnet 4.6 لا يُضاهى في أبريل 2026.
وعلى الرغم من أن 200 ألف رمز في GLM-5.1 كافية بالفعل لـ 90% من السيناريوهات اليومية، إلا أنها تتأخر خطوة في سيناريوهات "السياق الطويل للغاية" القصوى.
البعد الخامس: مهام الوكيل (Agent) طويلة المدى — مواجهة بين نهجين
البعد الخامس هو قدرة مهام الوكيل (Agent) طويلة المدى، وهو الاتجاه الذي تتنافس فيه جميع نماذج البرمجة الرائدة في عام 2026.
مسارات مختلفة لـ "المدى الطويل"
- GLM-5.1: يركز Z.ai على "العمل المستمر لمدة 8 ساعات في مهمة واحدة"، مع التأكيد على دورة شاملة من التخطيط ← التنفيذ ← الاختبار ← الإصلاح ← التحسين الثانوي، معتمداً على عمق الاستنتاج الخاص بالنموذج واستقرار استدعاء الأدوات.
- Claude Sonnet 4.6: تركز Anthropic على "تجربة Claude Code العملية"، حيث يفضل 70% من مستخدمي Sonnet 4.5 نموذج Sonnet 4.6 في الاختبارات الداخلية، معتمداً على سير عمل Claude Code الهندسي + سياق 1 مليون رمز + ضغط السياق.
يمكن تلخيص الأمر كالتالي:
| المسار | الميزة الأساسية | السيناريوهات المناسبة |
|---|---|---|
| GLM-5.1 | عمق الاستنتاج + استقرار استدعاء الأدوات | وكيل الأتمتة في الخلفية / المهام التي لا تتطلب مراقبة |
| Sonnet 4.6 | سير عمل Claude Code + سياق 1 مليون رمز | البرمجة التفاعلية للمطورين / التكامل مع بيئة التطوير (IDE) |
إذا كنت تعمل على سيناريوهات "تشغيل وكيل في الخلفية لتطوير الميزات ذاتياً" دون تدخل بشري، فإن قدرة GLM-5.1 على العمل لمدة 8 ساعات تناسبك طبيعياً؛ أما إذا كنت تعمل على "حوار المهندس مع النموذج داخل بيئة التطوير (IDE) لكتابة الكود"، فإن تجربة تكامل Claude Code في Sonnet 4.6 أكثر نضجاً.
البعد السادس: توافق النظام البيئي — ميزة سلسلة أدوات Sonnet 4.6
البعد الأخير هو النظام البيئي. في هذا الجانب، لا يزال Sonnet 4.6 في موقع ريادي واضح، لكن GLM-5.1 يلحق به بسرعة كبيرة.
| البعد | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| توافق Claude Code | ✅ (مدخل متوافق مع OpenAI) | ✅ أصلي |
| Cline / Cursor | ✅ (مدخل متوافق مع OpenAI) | ✅ أصلي |
| OpenClaw | ✅ | ✅ |
| استدعاء أدوات Anthropic | نمط OpenAI | ✅ أصلي |
| إطارات عمل الوكلاء الخارجية | معظمها يدعم توافق OpenAI | معظمها يدعم أصالة Anthropic |
| مرونة النشر | ✅ استضافة ذاتية MIT / APIYI / Z.ai | APIYI / Anthropic الرسمي |
من الجدير بالذكر أن APIYI (apiyi.com) يدعم التنسيقات الأصلية الثلاثة: OpenAI / Claude Native / Gemini Native في آن واحد، مما يعني أنه بغض النظر عن نمط SDK الذي ترغب في استخدامه لاستدعاء GLM-5.1 و Sonnet 4.6، يمكنك إنجاز ذلك تحت مفتاح API واحد. هذه تفصيلة عملية للغاية في الاختبارات المقارنة بين النموذجين، حيث لن تحتاج إلى إدارة مجموعتين من المصادقة، ومجموعتين من المراقبة، ومجموعتين من الفواتير أثناء فترة الاختبار.
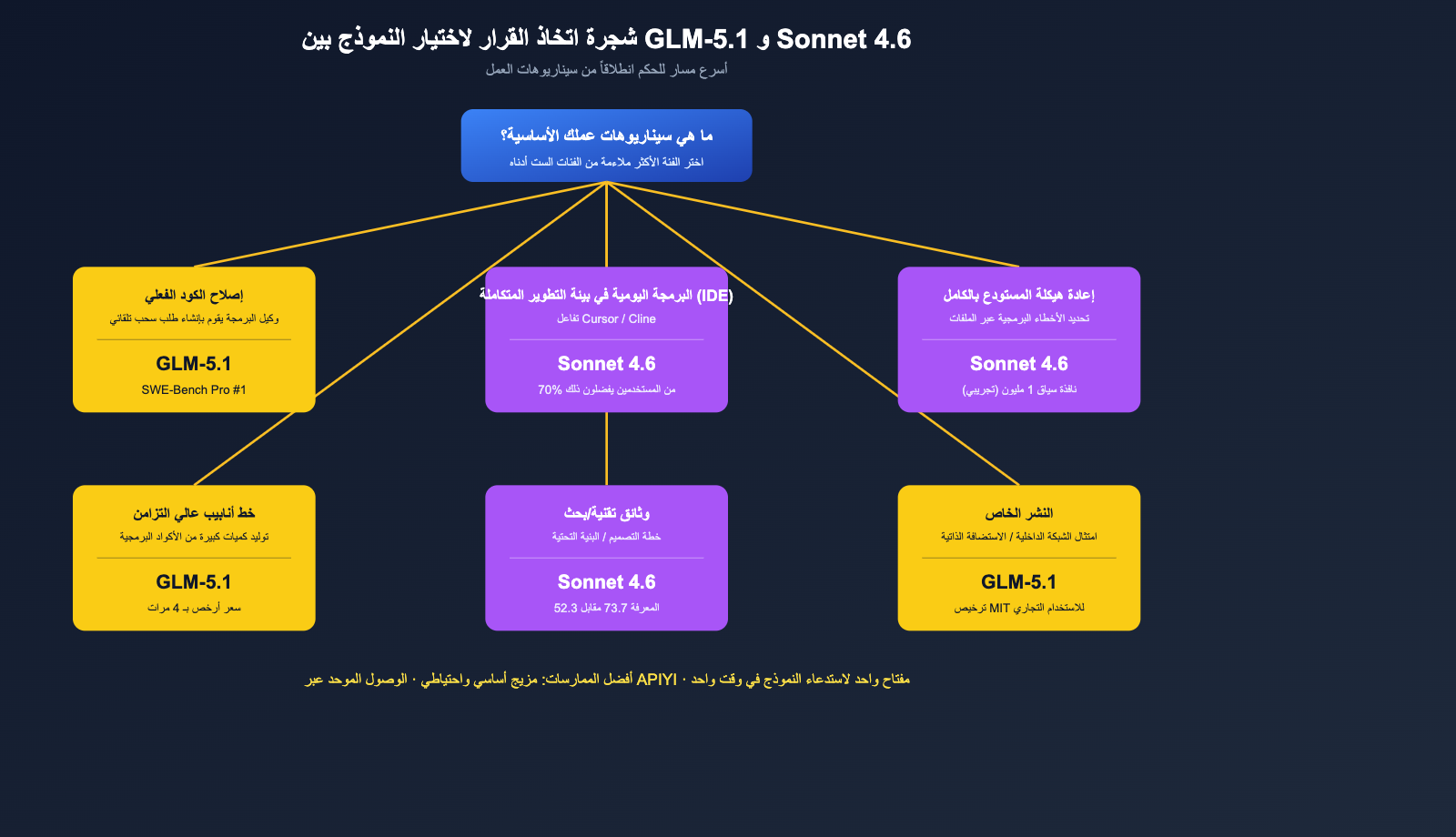
توصيات الاختيار النهائي حسب السيناريو
من خلال ربط الأبعاد الستة معاً، يمكننا تقديم توصيات محددة جداً حول "اختيار النموذج حسب سيناريو العمل".
جدول مقارنة السيناريوهات
| سيناريو العمل | النموذج الموصى به | السبب الرئيسي |
|---|---|---|
| إصلاح الأكواد الصناعية الحقيقية (Agent PR تلقائي) | GLM-5.1 | الأول عالمياً في SWE-Bench Pro + سياق طويل 8 ساعات |
| البرمجة اليومية في IDE (مثل Cursor / Cline) | Claude Sonnet 4.6 | معدل تفضيل مستخدمي Claude Code يصل إلى 70%، سير عمل ناضج |
| إعادة هيكلة المستودع بالكامل / تحديد أخطاء عبر الملفات | Claude Sonnet 4.6 | نافذة سياق 1M (تجريبي) هي السلاح الأساسي |
| توليد الأكواد القياسية + استدعاءات عالية التزامن | GLM-5.1 | أرخص بـ 4 مرات، مناسب للإنتاج المتسلسل |
| البحوث التقنية / وثائق التصميم / خطط البنية | Claude Sonnet 4.6 | تفوق كبير في توزيع المعرفة 73.7 مقابل 52.3 |
| الاستدلال الرياضي / مسابقات الخوارزميات | GLM-5.1 | AIME 2026 بنتيجة 95.3 + GPQA-Diamond بنتيجة 86.2 |
| وحدة توليد الأكواد في SaaS الموجه للعملاء | Sonnet 4.6 (أساسي) + GLM-5.1 (احتياطي) | Sonnet للعمليات الأساسية، GLM للنسخ الاحتياطي، خفض التكاليف مع ضمان الجودة |
| النشر الخاص / الامتثال للشبكة الداخلية | GLM-5.1 | ترخيص MIT + قابل للاستضافة الذاتية |
| التفاعل البرمجي باللغة الصينية | GLM-5.1 | النموذج المحلي أكثر ودية مع الموجهات (Prompts) باللغة الصينية |
| استدلال عالي الصعوبة لمرة واحدة + استدعاء أدوات طويل | تعادل، يتطلب اختباراً ذاتياً | كلاهما قادر على الأداء، الفرق أقل من 5% |
استراتيجية الدمج الموصى بها
بالنسبة للغالبية العظمى من الفرق المتوسطة، نوصي باستراتيجية "الدمج بين الأساسي والاحتياطي" بدلاً من "الاختيار بينهما":
- النموذج الأساسي: اختر واحداً بناءً على سيناريوهات عملك الأكثر تكراراً (GLM-5.1 لإصلاح الأكواد، Sonnet 4.6 لتكامل IDE).
- النموذج الاحتياطي: قم بتفعيل الآخر، لاستخدامه في التحقق من A/B والتبديل التدريجي للأعمال الحساسة.
- طبقة الوصول الموحدة: استخدم مفتاح API واحد لاستدعاء كليهما عبر APIYI (apiyi.com)، حيث يحتاج كود العمل فقط إلى تغيير حقل النموذج، دون الحاجة لصيانة منطقين للمصادقة.
- مراقبة التكاليف: راقب فواتير النموذجين بشكل منفصل في لوحة تحكم APIYI، وقرر دورياً أي نموذج يقدم "أفضل قيمة مقابل السعر" لعملك، وقم بتعديل نسبة حركة المرور ديناميكياً.
🎯 نصيحة لتطبيق استراتيجية الدمج: على منصة APIYI (apiyi.com)، يمكنك التبديل بسلاسة بين GLM-5.1 و Claude Sonnet 4.6 باستخدام نفس مفتاح API، ويحتاج كود عملك فقط إلى تغيير سلسلة نصية واحدة. نقترح توجيه 70% من حركة مرور "توليد الأكواد غير الحساسة" إلى GLM-5.1، وترك 30% من حركة مرور "العمليات الموجهة للعملاء + الاستدلال عالي الصعوبة" لـ Sonnet 4.6، مما يتيح لك الاستفادة من ميزة السعر لـ GLM-5.1 وضمان استقرار السيناريوهات الحرجة.
الأسئلة الشائعة حول المقارنة بين GLM-5.1 و Claude Sonnet 4.6
س1: هل تفوق نموذج GLM-5.1 فعلياً على Claude Sonnet 4.6 في البرمجة؟
يتفوق في جوانب، ويبقى متأخراً في أخرى. في معيار SWE-Bench Pro (الذي يقيس إصلاح الأكواد في بيئات العمل الحقيقية)، وهو الاختبار الأصعب، حقق GLM-5.1 نتيجة 58.4 ليحتل المرتبة الأولى عالمياً، متجاوزاً بذلك Claude Opus 4.6 الذي حقق 57.3 و GPT-5.4 الذي حقق 57.7، وبالطبع متفوقاً على Sonnet 4.6. ولكن في اختبار SWE-bench Verified (إصلاح الأكواد المعياري)، لا يزال Sonnet 4.6 متقدماً بنسبة 79.6% مقابل 77.8% لنموذج GLM-5.1، بفارق 1.8 نقطة مئوية. أما في متوسط درجات البرمجة الشاملة BenchLM، يتفوق Sonnet 4.6 بـ 66.4 نقطة مقابل 58.4 لـ GLM-5.1. الخلاصة: تفوق GLM-5.1 في "ذروة الصعوبة"، لكنه لا يزال متأخراً في "توازن النطاق".
س2: ما مدى توفير التكلفة عند استخدام GLM-5.1 مقارنة بـ Claude Sonnet 4.6؟
وفقاً للأسعار الرسمية المباشرة من Z.ai، فإن تكلفة GLM-5.1 هي 1.00 دولار للمدخلات / 3.20 دولار للمخرجات، بينما Claude Sonnet 4.6 تبلغ 3.00 دولار / 15.00 دولار؛ أي أن المدخلات أرخص بـ 3 مرات، والمخرجات أرخص بنحو 4.7 مرة. في سيناريو نموذجي يتضمن "1000 استدعاء لوكيل برمجي يومياً + 5 آلاف رمز للمدخلات / 20 ألف رمز للمخرجات"، تكون فاتورة Sonnet 4.6 الشهرية أعلى بنحو 4.5 مرة من GLM-5.1. إذا كانت طبيعة عملك تعتمد على "مخرجات أكبر بكثير من المدخلات"، فإن ميزة التكلفة في GLM-5.1 ستكون أكثر وضوحاً.
س3: أيهما يمتلك نافذة سياق أكبر، GLM-5.1 أم Sonnet 4.6؟
Claude Sonnet 4.6 أكبر. يمتلك GLM-5.1 نافذة سياق بحجم 200 ألف (تظهر في بعض المنصات كـ 203 ألف)، بينما Sonnet 4.6 يوفر 200 ألف وصولاً إلى 1 مليون رمز (تجريبي). تعني نافذة الـ 1 مليون رمز أن Sonnet 4.6 يمكنه قراءة مستودع أكواد متوسط الحجم دفعة واحدة، وهذا هو سلاحه الأساسي في مهام "إعادة هيكلة المستودع بالكامل / تحديد الأخطاء عبر ملفات متعددة". إذا كانت مهامك تتطلب سياقاً طويلاً جداً، فإن Sonnet 4.6 هو الخيار الأكثر أماناً.
س4: أستخدم حالياً Claude Sonnet 4.6 مع Cursor / Cline، هل يستحق الانتقال إلى GLM-5.1؟
يعتمد ذلك على ما يزعجك. إذا كانت "الفاتورة" هي أولويتك القصوى، فإن GLM-5.1 يمكنه خفض التكاليف للنصف أو أكثر، لذا يستحق الانتقال. أما إذا كنت تهتم بـ "استقرار تجربة البرمجة اليومية"، فإن تفضيل 70% من المستخدمين لـ Sonnet 4.6 يشير إلى أنه تم التحقق منه على نطاق واسع في سير عمل Claude Code، وقد تكون مخاطر الانتقال أكبر من فوائده. الطريقة الأكثر أماناً هي استخدام خدمة وكيل API عبر APIYI (apiyi.com) لتحويل 20% من حركة المرور إلى GLM-5.1 لإجراء اختبار A/B، ثم اتخاذ قرار بشأن زيادة النسبة بعد أسبوع.
س5: هل يمكن استدعاء كل من GLM-5.1 و Sonnet 4.6 عبر APIYI؟
نعم، كلاهما متاح. تدعم منصة APIYI (apiyi.com) ثلاثة تنسيقات أصلية (OpenAI / Claude Native / Gemini Native). ما عليك سوى تغيير base_url في حزمة تطوير البرمجيات (SDK) الخاصة بـ OpenAI إلى https://api.apiyi.com/v1 والتبديل بين glm-5.1 و claude-sonnet-4-6 (أو معرف مشابه) في حقل model لتشغيل كليهما في نفس الكود، مما يجعل كفاءة المقارنة الأفقية عالية جداً.
س6: كمطور مستقل، أيهما يجب أن أختار؟
إذا كان عليك اختيار واحد فقط، انظر إلى سير عملك: إذا كنت تعمل على وكيل برمجي (Coding Agent) / أتمتة الخلفية / توليد كميات كبيرة من الأكواد → اختر GLM-5.1. إذا كنت تعمل على البرمجة التفاعلية داخل بيئة التطوير (IDE) / إعادة هيكلة المستودع بالكامل / توليد محتوى موجه للعملاء → اختر Sonnet 4.6. إذا كنت لا ترغب في الاختيار الصعب، فإن ربط كليهما وإدارتهما مركزياً عبر APIYI هو أفضل ممارسة لمطوري عام 2026؛ حيث ستتحسن الفاتورة تلقائياً مع اختيار النموذج الأمثل، ولن تكون مقيداً بمزود واحد.
الخلاصة: الحكم النهائي بين GLM-5.1 و Claude Sonnet 4.6
بدمج أبعاد المقارنة الستة، يمكن تلخيص الحكم النهائي بين GLM-5.1 و Claude Sonnet 4.6 في العبارة التالية: يتمتع GLM-5.1 بميزة هيكلية في "إصلاح الأكواد الصناعية عالية الصعوبة + السعر + المصدر المفتوح المحلي + الوكلاء طويلي المدى"، بينما يحتفظ Claude Sonnet 4.6 بالصدارة في "توازن النطاق + عمق المعرفة + نافذة سياق 1 مليون + نضج سير العمل في بيئات التطوير". العلاقة بينهما ليست علاقة "استبدال"، بل هما أداتان متكاملتان لسيناريوهات عمل مختلفة.
بالنسبة لفرق التطوير في الصين في أواخر عام 2026، فإن الاستراتيجية الأذكى ليست "إما هذا أو ذاك"، بل "الدمج بين الأساسي والاحتياطي + طبقة وصول موحدة": اجعل GLM-5.1 يتولى المهام الحساسة للتكلفة، والأتمتة طويلة المدى، والامتثال للخصوصية، بينما يتولى Sonnet 4.6 المهام الموجهة للمستخدم، والسياقات المعقدة، والكتابة التقنية. من خلال خدمة وكيل API مثل APIYI، يمكنك وضع كليهما تحت مفتاح API واحد، وتعديل نسب حركة المرور ديناميكياً بناءً على بيانات الفاتورة الفعلية، مما يتيح لك تقليص الفاتورة الشهرية بشكل كبير دون التضحية بالجودة.
🎯 نصيحة أخيرة: كل من GLM-5.1 و Claude Sonnet 4.6 متاحان الآن على APIYI (apiyi.com). ننصحك بإنشاء مفتاح API على apiyi.com اليوم، وتغيير
base_urlالخاص بـ OpenAI إلىhttps://api.apiyi.com/v1، وتشغيل 5 مهام باستخدام GLM-5.1، ثم تشغيل نفس المهام باستخدام Sonnet 4.6 بنفس الموجه (prompt)، للتحقق بنفسك من جميع استنتاجات هذا المقال. لا يوجد تقييم يغني عن تجربتك الشخصية، وهذا الاختبار السريع لمدة 30 دقيقة سيمنحك شعوراً حقيقياً بأقوى نموذجين للبرمجة في عام 2026.
المؤلف: فريق APIYI | تابعونا لمتابعة أحدث نماذج اللغة الكبيرة وتقييم أدوات البرمجة، للمزيد من المقارنات وتجارب الاستدعاء، تفضلوا بزيارة APIYI على apiyi.com.