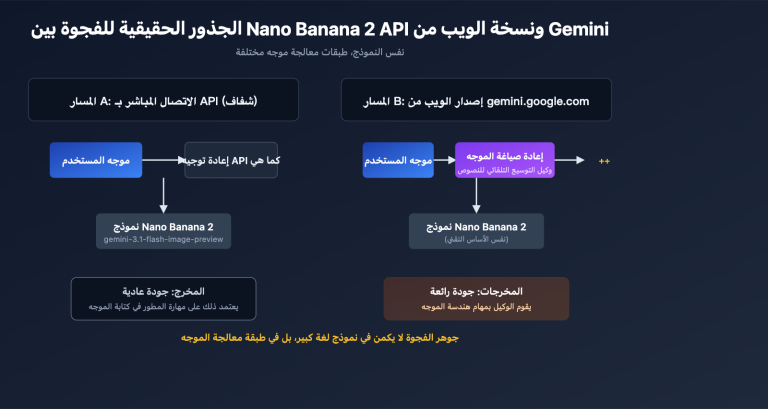
ملاحظة من المؤلف: إجابة على السؤال الأكثر شيوعًا بين المطورين: هل يمكن إرسال ملفات PDF مباشرة إلى واجهة برمجة تطبيقات النماذج اللغوية الكبيرة؟ الجواب هو أن الغالبية العظمى لا تدعم ذلك. تشرح هذه المقالة ثلاث حلول عملية: استخراج النص، فهم الصور، ومعالجة جانب العميل.
"هل يمكنني إرسال ملف PDF مباشرة إلى واجهة برمجة تطبيقات النموذج اللغوي الكبير؟" — هذا أحد الأسئلة الأكثر تكرارًا في مجموعة دعمنا على التطبيقات المراسلة. اعتاد العديد من المطورين على ميزة "سحب وإفلات PDF والدردشة مباشرة" في إصدارات ChatGPT أو Claude على الويب، مما جعلهم يعتقدون أن واجهة برمجة التطبيقات (API) تعمل بنفس الطريقة.
الواقع هو: الغالبية العظمى من واجهات برمجة تطبيقات النماذج اللغوية الكبيرة لا تدعم إدخال ملفات PDF مباشرة. حتى الشركات الرائدة مثل OpenAI وAnthropic، فإن التنسيق الأساسي للإدخال في واجهة برمجة التطبيقات الخاص بهما يظل نصًا وصورًا — PDF ليس ضمن التنسيقات المدعومة بشكل قياسي. والأهم من ذلك، منصات الوكيل الثالثة مثل APIYI لا تدعم أيضًا إرسال PDF مباشرة، لأن البروتوكول الأساسي لا يدعم ذلك.
لكن لا تقلق، هناك بالفعل 3 حلول ناضجة لمعالجة ملفات PDF. ستأخذك هذه المقالة في رحلة لفهم السبب وراء عدم دعم واجهات برمجة التطبيقات للنماذج اللغوية الكبيرة لملفات PDF، وكيفية اختيار الطريقة الأنسب لك.
القيمة الأساسية: بعد قراءة هذه المقالة، ستفهم سبب عدم دعم واجهات برمجة تطبيقات النماذج اللغوية الكبيرة لملفات PDF، وكيفية استخدام 3 حلول معالجة مسبقة لتلبية احتياجات إدخال PDF بكفاءة.

النقاط الأساسية لإدخال PDF في واجهات برمجة تطبيقات نماذج اللغة الكبيرة
| النقطة | الشرح | التأثير |
|---|---|---|
| واجهات برمجة التطبيقات لا تقبل PDF مباشرة | المدخلات القياسية لنماذج مثل GPT وDeepSeek وLlama وQwen هي النصوص والصور | يتطلب ذلك سير معالجة مسبق |
| النسخة الويب ≠ واجهة برمجة التطبيقات | تحميل PDF في ChatGPT وClaude على الويب يتم من خلال معالجة مسبقة في الواجهة الأمامية قبل استدعاء API | لا تعتبر تجربة الويب مماثلة لقدرات API |
| المنصات الخارجية لا تدعم أيضًا | منصات مثل APIYI تنقل بروتوكول API الأصلي، وإذا لم يدعمه الأساسي فلا تدعمه المنصة | لا تتوقع أن تقوم المنصات الوسيطة بمعالجة PDF إضافية |
| 3 حلول للمعالجة المسبقة ناضجة وموثوقة | استخراج النص، فهم الصور، معالجة جانب العميل – لكل منها سيناريوهات مناسبة | اختيار الحل المناسب أكثر واقعية من البحث عن "API يدعم PDF" |
لماذا لا تدعم واجهات برمجة تطبيقات نماذج اللغة الكبيرة إدخال PDF؟
يتساءل الكثير من المطورين: إذا كان بإمكاني تحميل PDF على النسخة الويب، فلماذا لا يدعم API ذلك؟ السبب بسيط – وظيفة "تحميل PDF" في النسخة الويب لا تتم معالجتها بواسطة النموذج نفسه، بل تتم معالجة مسبقة في الواجهة الأمامية/الخلفية دون أن تراها:
- استخراج النص: تقوم الواجهة الأمامية باستخراج النص من PDF وتحويله إلى نص عادي قبل إرساله للنموذج
- عرض الصفحات: يتم عرض كل صفحة من PDF كصورة، لفهم النموذج من خلال قدرات الرؤية
- استرجاع RAG: تحويل محتوى PDF إلى تمثيلات متجهة، واسترجاع الأجزاء ذات الصلة فقط أثناء المحادثة وإرسالها للنموذج
يتم تضمين خطوات المعالجة المسبقة هذه في منتجات النسخة الويب، ولا يدركها المستخدم. ولكن عند استدعاء API مباشرة، يجب عليك إكمال هذه المعالجة المسبقة بنفسك.
نظرة سريعة على دعم PDF في واجهات برمجة تطبيقات نماذج اللغة الكبيرة
| النموذج | إرسال PDF مباشرة عبر API | تنسيق الإدخال القياسي | اقتراح معالجة PDF |
|---|---|---|---|
| GPT-4o / GPT-4.1 | غير مدعوم | نص + صور (Base64) | استخراج النص أولاً أو تحويله إلى صور |
| Claude | مدعوم جزئيًا (نسخة تجريبية) | نص + صور | يوصى باتباع سير المعالجة المسبقة لتحقيق استقرار أكبر |
| Gemini | مدعوم جزئيًا | نص + صور | يوصى باتباع سير المعالجة المسبقة لتحقيق تحكم أفضل |
| DeepSeek | غير مدعوم | نص عادي فقط | يجب استخراج النص أولاً |
| Llama / Qwen | غير مدعوم | نص (بعضها يدعم الصور) | يجب استخراج النص أولاً |
| APIYI وغيرها من المنصات الخارجية | غير مدعوم | تمرير البروتوكول الأصلي | يجب إجراء المعالجة المسبقة بنفسك قبل الاستدعاء |
🎯 ملاحظة مهمة: على الرغم من أن وثائق API الرسمية لـ Claude و Gemini تذكر دعم إدخال PDF، إلا أن هذه الوظيفة تعاني من عدم اليقين بشأن التوافق والاستقرار، ولا تدعم إرسال PDF مباشرة عند الاستدعاء عبر منصات وسيطة مثل APIYI. نوصي باتباع حل المعالجة المسبقة الموحد لتحقيق أفضل توافق واستقرار.
حل معالجة PDF لواجهات برمجة تطبيقات نماذج اللغة الكبيرة 1: استخراج النص مسبقًا
هذا هو الحل الأكثر عمومية والأقل تكلفة والأكثر توافقًا مع جميع النماذج. الفكرة الأساسية: استخدام مكتبات Python لتحويل PDF إلى Markdown أو نص عادي أولاً، ثم إرسال النص كموجه إلى API.
مقارنة أدوات استخراج النص من PDF
| الأداة | السرعة | أفضل سيناريو | الميزات |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14 ثانية/مستند | استخراج النص العام + الجداول | أفضل توازن بين السرعة والجودة، إخراج Markdown |
| pdfplumber | متوسطة | استخراج بيانات الجداول | دقة عالية لاستخراج الجداول على مستوى الإحداثيات |
| Marker-PDF | ~11 ثانية/مستند | تحويل تخطيطات معقدة مع الحفاظ على الدقة | أفضل حفظ للهيكل، أبطأ سرعة |
| PyPDF2 | سريعة | PDF نصي بسيط | خفيفة الوزن، مناسبة للاستخراج الأساسي |
مثال على كود استخراج النص من PDF
فيما يلي الحل الأكثر استخدامًا، استخراج نص PDF ثم إرساله إلى واجهة برمجة تطبيقات نموذج اللغة الكبير:
import pymupdf4llm
import openai
# الخطوة 1: تحويل PDF إلى Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# الخطوة 2: إرسال النص العادي إلى أي نموذج لغة كبير
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"يرجى تلخيص النقاط الأساسية لهذا التقرير:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
سيناريوهات التطبيق: العقود، الأوراق البحثية، التقارير، المستندات التقنية التي تعتمد بشكل أساسي على النص. طالما أن PDF يحتوي على طبقة نص مدمجة (وليس مستندًا ممسوحًا ضوئيًا)، فإن تأثير الاستخراج يكون جيدًا.
اقتراح: حل استخراج النص متوافق مع جميع نماذج اللغة الكبيرة – GPT وClaude وDeepSeek وLlama وQwen. احصل على مفتاح API من APIYI apiyi.com، حيث يمكن لمفتاح واحد استدعاء جميع النماذج لإجراء اختبارات مقارنة.
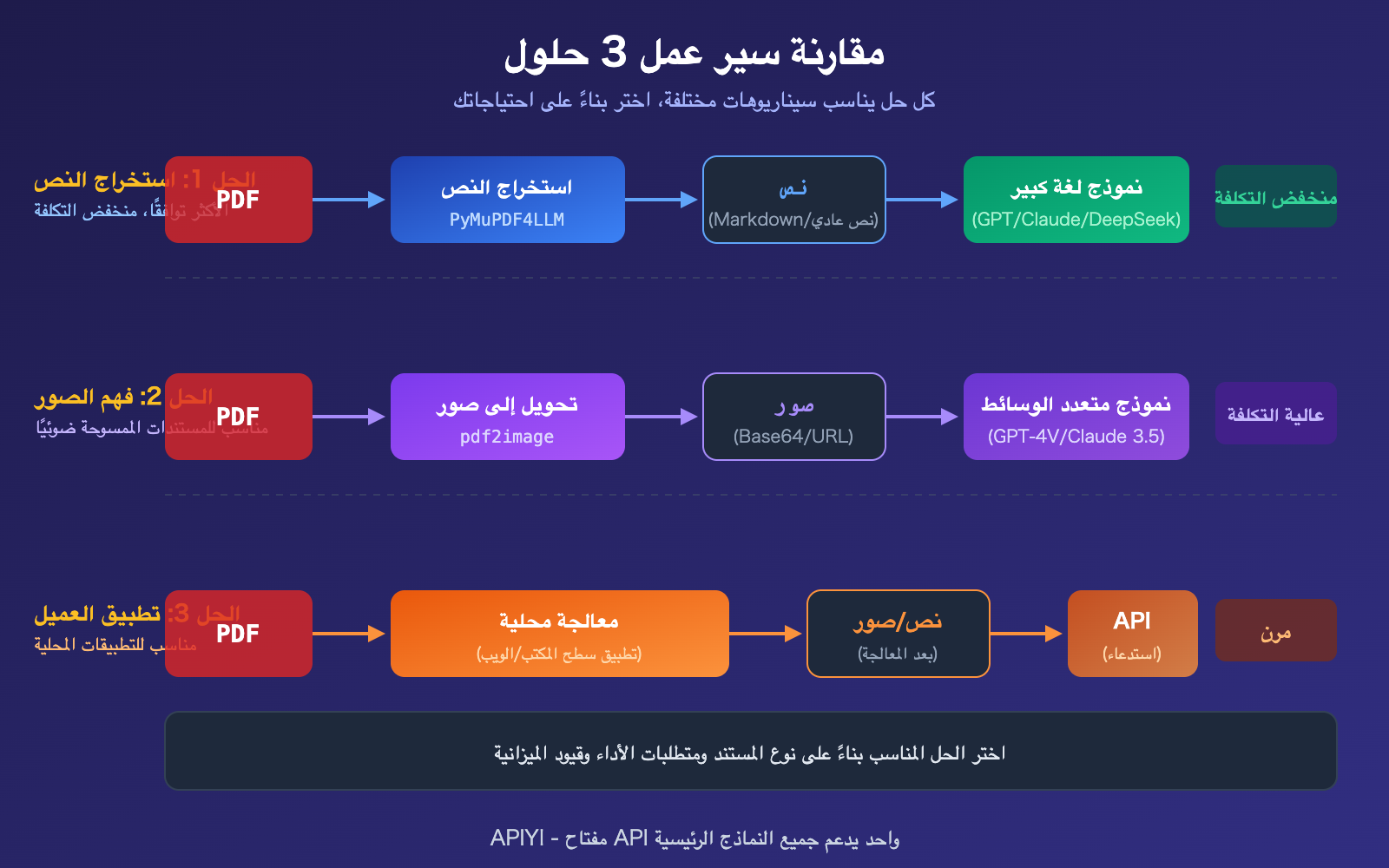
حلول معالجة ملفات PDF باستخدام واجهات برمجة تطبيقات النماذج اللغوية الكبيرة: الخيار الثاني – التحويل إلى صور + الفهم البصري
عندما يحتوي ملف PDF على رسوم بيانية أو مستندات ممسوحة ضوئيًا أو تنسيقات معقدة، فإن استخراج النص الخالص يفقد هذه المحتويات. في هذه الحالة، نحتاج إلى تحويل كل صفحة من ملف PDF إلى صورة، ثم استخدام نموذج يدعم الرؤية الحاسوبية لفهم الصور.
مثال على كود تحويل PDF إلى صور
import fitz # PyMuPDF
import base64
import openai
# الخطوة 1: تحويل كل صفحة من PDF إلى صورة PNG
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
عرض الكود الكامل: إرسال الصور إلى Vision API
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""تحويل PDF إلى صور ثم إرسالها إلى Vision API"""
doc = fitz.open(pdf_path)
# بناء رسالة متعددة الصور (انتبه لعدد الصفحات لتجنب تجاوز حد الرموز)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# مثال للاستخدام
result = pdf_to_vision(
"financial_report.pdf",
"يرجى تحليل الرسوم البيانية في هذا التقرير المالي وتلخيص البيانات الأساسية",
max_pages=5 # التحكم في عدد الصفحات، كل صفحة تستهلك حوالي 765 رمزًا
)
print(result)
حالات الاستخدام المناسبة: تقارير تحتوي على رسوم بيانية، مستندات ممسوحة ضوئيًا، فواتير، مخططات معمارية، وغيرها من ملفات PDF الغنية بالمعلومات المرئية.
تذكير بالتكلفة: كل صفحة صورة تستهلك حوالي 765 رمزًا (دقة قياسية لـ GPT-4o)، 10 صفحات من PDF تعادل حوالي 7,650 رمزًا تكلفة للصور، بالإضافة إلى تكلفة النص والسؤال والإجابة قد تتجاوز 10,000 رمز. تأكد من التحكم في عدد الصفحات.
🎯 نصيحة للتحكم في التكلفة: لا ترسل جميع صفحات ملف PDF دفعة واحدة. استخدم الخيار الأول أولاً لاستخراج النص وإجراء تصفية أولية، ثم حدد الصفحات المهمة واستخدم الخيار الثاني لفهم الصور للصفحات المحددة. يمكنك مراقبة استهلاك الرموز في الوقت الفعلي من خلال لوحة الاستخدام في APIYI apiyi.com.
حلول معالجة ملفات PDF باستخدام واجهات برمجة تطبيقات النماذج اللغوية الكبيرة: الخيار الثالث – المعالجة بواسطة عميل الذكاء الاصطناعي
إذا كنت لا ترغب في كتابة كود، وتحتاج فقط إلى "سؤال عن محتويات ملف PDF" في المحادثات اليومية، فإن استخدام عميل الذكاء الاصطناعي هو أسهل طريقة.
آلية معالجة ملفات PDF في عملاء مثل Cherry Studio
هذه العملاء تقوم تلقائيًا بما تقوم به الخيارات الأولى والثانية:
- التجهيز المتجه التلقائي: استخراج محتويات PDF وتقسيمها إلى أجزاء صغيرة، ثم تخزينها في قاعدة بيانات متجهة محلية
- الاسترجاع الدلالي: عند طرح سؤال، يقوم العميل أولاً باسترجاع أجزاء المحتوى الأكثر صلة
- الإرسال الدقيق: إرسال الأجزاء ذات الصلة فقط (وليس النص الكامل) إلى واجهة برمجة تطبيقات النموذج اللغوي الكبير
- توفير الرموز: تقليل كمية المحتوى المرسلة إلى النموذج بشكل كبير من خلال استرجاع RAG
ملاحظات عند معالجة ملفات PDF بواسطة العميل
- تكوين مفتاح API: أدخل مفتاح API الخاص بـ APIYI apiyi.com في العميل، لتتمكن من الوصول إلى جميع النماذج باستخدام مفتاح واحد
- التحكم في حجم الملف: قد يستغرق تجهيز ملفات PDF كبيرة جدًا (مئات الصفحات) وقتًا طويلاً، يُنصح بتقسيمها قبل المعالجة
- انتبه لتكلفة الرموز: على الرغم من أن RAG يقوم بضغط المحتوى، إلا أن المستندات الطويلة قد تزال تنتج تكلفة عالية
- اختيار النموذج المناسب: يمكن استخدام النماذج الأرخص (مثل GPT-4o-mini) للأسئلة البسيطة، والنماذج المتطورة للتحليلات المعقدة
مقارنة 3 طرق لمعالجة PDF باستخدام واجهات برمجة تطبيقات النماذج اللغوية الكبيرة

| الطريقة | تكلفة الرموز (Tokens) | دعم المخططات والرسوم | صعوبة التطوير | توافق النماذج | أفضل سيناريو |
|---|---|---|---|---|---|
| استخراج نصي | الأقل (300-1500/صفحة) | غير مدعوم | متوسط | جميع النماذج | ملفات PDF نصية خالصة، كميات كبيرة |
| تحويل إلى صورة لفهمها | مرتفعة نسبياً (~765/صفحة) | دعم كامل | متوسط | يتطلب نماذج رؤية (Vision) | المخططات، المستندات الممسوحة |
| معالجة من جانب العميل | متوسطة (ضغط باستخدام RAG) | يعتمد على العميل | بدون برمجة | جميع النماذج | المحادثات اليومية، للمستخدمين غير المطورين |
توضيح المقارنة: الطرق الثلاث ليست متنافية، وغالبًا ما تُستخدم مجتمعة في المشاريع العملية. على سبيل المثال، يمكن استخدام الطريقة الأولى أولاً لاستخراج النص وإجراء فرز أولي، ثم استخدام الطريقة الثانية لفهم الصور للصفحات المهمة. من خلال APIYI (apiyi.com) يمكنك الوصول إلى جميع النماذج بشكل موحد.
الأسئلة الشائعة
س1: لماذا يمكن لنسخة ChatGPT على الويب رفع ملفات PDF، بينما واجهة برمجة التطبيقات لا تدعم ذلك؟
تتولى ميزة "رفع PDF" في النسخة الويب معالجة مسبقة للملف نيابة عنك في الواجهة الأمامية للمنتج – مثل استخراج النص، وعرض الصور، وإنشاء فهرس للبحث – ثم تستدعي واجهة برمجة التطبيقات الأساسية. تنسيق الإدخال الأساسي لواجهة برمجة التطبيقات نفسها هو النص والصورة، وتنسيق PDF كحاوية مستندات معقدة ليس ضمن التنسيقات المدعومة بشكل قياسي. عند استدعاء واجهة برمجة التطبيقات، يتعين عليك إكمال خطوات المعالجة المسبقة هذه بنفسك.
س2: هل يمكن لمنصات الوكيل الطرف الثالث مثل APIYI مساعدتي في معالجة ملفات PDF؟
لا، لا يمكنها ذلك. جوهر منصات الوكيل مثل APIYI هو تمرير طلبات واجهة برمجة التطبيقات، فإذا لم يدعم البروتوكول الأساسي ملفات PDF، فل تتمكن المنصة من معالجتها. يجب عليك إكمال المعالجة المسبقة لملف PDF (استخراج النص أو تحويله إلى صورة) بنفسك قبل استدعاء واجهة برمجة التطبيقات، ثم إرسال النص أو الصورة المعالجة عبر APIYI (apiyi.com) إلى نموذج اللغة الكبير.
س3: كيف يمكن التحكم في تكلفة الرموز (Tokens) عند معالجة ملفات PDF؟
إليك بعض النصائح العملية:
- استخدم الخيار الأول (استخراج النص) أولاً، فهو الأقل تكلفة.
- قم بمعالجة الصفحات المطلوبة فقط، ولا ترسل المستند كاملاً مرة واحدة.
- استخدم تقنية RAG لتقسيم النص والبحث، وأرسل فقط الأجزاء ذات الصلة إلى النموذج.
- استخدم النماذج الأرخص (مثل GPT-4o-mini) للأسئلة البسيطة، والنماذج المتطورة للتحليلات المعقدة.
- راقب الاستهلاك في الوقت الفعلي عبر لوحة الاستخدام في APIYI (apiyi.com).
الخلاصة
النقاط الأساسية لإدخال ملفات PDF إلى واجهة برمجة التطبيقات الخاصة بنماذج اللغة الكبيرة:
- معظم واجهات برمجة التطبيقات لا تدعم إدخال PDF مباشرًا: المدخلات الأساسية لنماذج اللغة الكبيرة هي النص والصورة، ويتطلب ملف PDF معالجة مسبقة قبل استخدامه.
- المنصات الطرف الثالثة لا تدعم ذلك أيضًا: منصات الوكيل مثل APIYI تمرر البروتوكول الأصلي ولا يمكنها معالجة ملفات PDF بشكل إضافي.
- اختر من بين 3 خيارات حسب الحاجة: استخدم استخراج النص لملفات PDF النصية البحتة (الأكثر توفيرًا)، وتحويل الصور لملفات PDF التي تحتوي على صور (الأكثر دقة)، واستخدام العميل للاستخدام اليومي (الأكثر سهولة).
لا داعي للقلق بشأن "أي واجهة برمجة تطبيقات تدعم PDF"، بل ركز جهودك على اختيار خيار المعالجة المسبقة الصحيح – فهذه هي الطريقة الصحيحة للتفكير.
نوصي بالحصول على رصيد مجاني عبر APIYI (apiyi.com)، ومعالجة ملف PDF مسبقًا، ثم استخدام مفتاح API واحد لاستدعاء جميع النماذج الرئيسية مثل GPT وClaude وDeepSeek لإجراء مقارنات واختبارات.
📚 مراجع
-
وثائق PyMuPDF4LLM: أداة استخراج نص PDF
- الرابط:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - الشرح: أسرع أداة لتحويل PDF إلى Markdown، الخيار الموصى به
- الرابط:
-
وثائق pdfplumber: أداة متخصصة لاستخراج الجداول
- الرابط:
github.com/jsvine/pdfplumber - الشرح: الأداة الأكثر دقة لاستخراج بيانات الجداول من PDF
- الرابط:
-
Cherry Studio: عميل AI مفتوح المصدر
- الرابط:
github.com/CherryHQ/cherry-studio - الشرح: عميل مجاني يدعم سحب وإفلات PDF في المحادثة، ويمكن تكوينه لاستخدام APIYI كخلفية
- الرابط:
-
وثائق منصة APIYI: واجهة موحدة للوصول إلى واجهات برمجة التطبيقات للنماذج الكبيرة
- الرابط:
docs.apiyi.com - الشرح: الحصول على مفتاح API، قائمة النماذج وأمثلة الاستدعاء
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بالنقاش في قسم التعليقات، للمزيد من الموارد يمكن زيارة مركز وثائق APIYI docs.apiyi.com