LiteLLM 和 Claude Code 都是 2025-2026 年最热门的 AI 开发工具,但它们经常被开发者放在一起比较:哪个更好用?能不能互相替代?LiteLLM 到底支不支持 prompt caching 缓存计费?本文对比 LiteLLM 和 Claude Code,从定位、能力边界和缓存计费支持三个维度给出明确建议。
核心价值: 看完本文,你将明确这两个工具是否真的"二选一",以及如何在不同场景下做出最优选择。

LiteLLM vs Claude Code 核心差异速览
很多人把 LiteLLM 和 Claude Code 当成竞品,但其实它们的定位完全不同,甚至可以组合使用。一句话理解两者的本质区别:
- LiteLLM = LLM 网关 / 中转层,让一份代码调用 100+ 家模型
- Claude Code = Anthropic 官方的 Agentic 编码 CLI,专注"用 Claude 改你的代码库"
| 对比维度 | LiteLLM | Claude Code |
|---|---|---|
| 产品形态 | Python SDK + Proxy 服务器 | 命令行工具 (CLI) |
| 核心定位 | 通用 LLM 网关 / 模型路由 | Agentic 编码助手 |
| 支持模型 | 100+ 家 (OpenAI/Anthropic/Gemini/Bedrock/Vertex 等) | 默认仅 Claude 系列 |
| 典型用户 | 平台工程师、AI 应用开发者 | 个人开发者、编码场景 |
| 是否开源 | ✅ 开源 (BerriAI/litellm) | 闭源 CLI |
| 能不能互相替代 | ❌ 不能 | ❌ 不能 |
| 能不能组合使用 | ✅ 可以 (LiteLLM 在 Claude Code 后面) | ✅ 可以 |
| 最适合的搭档 | 配合 API易 apiyi.com 提供稳定中转 | 配合 LiteLLM 切换底层模型 |
💡 快速结论: 如果你在问"哪个更好用",那大概率你需要的是两个都用 —— Claude Code 当编码 Agent,LiteLLM 当统一入口,再通过 API易 apiyi.com 接入海外模型。这才是 2026 年最主流的栈。
LiteLLM vs Claude Code 五大核心差异
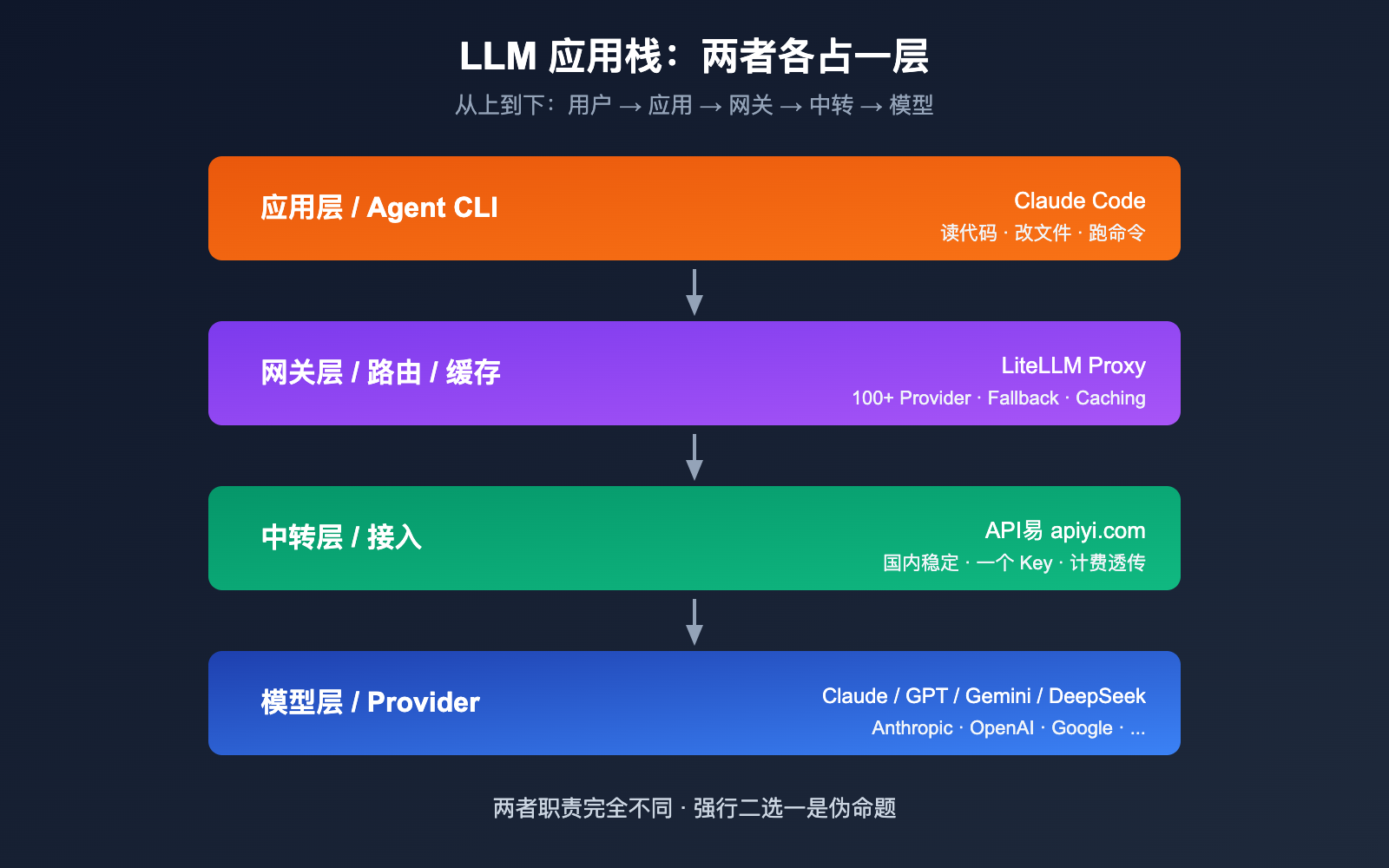
差异 1: 定位完全不同 (网关 vs Agent CLI)
LiteLLM 的定位: 一个开源的 LLM 网关,目标是"用 OpenAI 兼容格式调用任何模型"。它有两种形态:
- Python SDK:
litellm.completion(model="..."),给开发者写应用用 - Proxy 服务器:
litellm --config config.yaml,跑成一个独立服务,团队共享
Claude Code 的定位: Anthropic 官方推出的 Agentic 编码 CLI,目标是"让 Claude 直接在你的终端里读你的代码、改你的代码、跑你的命令"。它是一个应用层产品,下面调用的是 Anthropic 的 Messages API。
一句话:LiteLLM 是"水管",Claude Code 是"装在水管上的水龙头"。
差异 2: 支持的模型范围
| 维度 | LiteLLM | Claude Code |
|---|---|---|
| 默认支持 | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM 等 100+ | 仅 Anthropic Claude 系列 (Opus / Sonnet / Haiku) |
| 自定义端点 | ✅ 任意 OpenAI 兼容端点 | ⚠️ 通过 ANTHROPIC_BASE_URL 接到 LiteLLM |
| 国产模型 | ✅ DeepSeek / Qwen / Kimi / GLM 等 | ❌ 默认不支持 |
注意 Claude Code 也可以通过设置 ANTHROPIC_BASE_URL 指向 LiteLLM Proxy 来"间接"使用其他模型,但这本质上是 LiteLLM 在做翻译工作 —— 这恰恰证明了两者是互补关系。
差异 3: 使用界面与开发体验
LiteLLM 的开发体验:
- 给应用开发者写代码用的 SDK
- 可以集成到任何 Python 项目里
- 提供 OpenAI 兼容的 HTTP 端点,给前端、Node.js、Curl 用
Claude Code 的开发体验:
- 一个独立的 CLI,类似
claude命令 - 直接在终端里和你的代码库对话
- 自带文件读写、Bash 执行、Git 等工具
- 优化的 Tool Use 体验,"边想边改"
差异 4: 部署与运维成本
| 项目 | LiteLLM | Claude Code |
|---|---|---|
| 安装 | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| 是否需要服务 | Proxy 模式需要 | 否,本地 CLI |
| 是否需要 YAML 配置 | Proxy 模式需要 | 一般不需要 |
| 多人共享 | ✅ 一个 Proxy 服务团队共享 | ❌ 每人一份 CLI |
| 计费集中 | ✅ 网关层统一计费 | ❌ 各账号各计费 |
差异 5: 生态与扩展能力
LiteLLM 的生态:
- Logging: Langfuse、Helicone、Sentry、OpenTelemetry
- Guardrails: 内置内容审核
- Routing: 负载均衡、Fallback、限速
- Cost tracking: 多模型、多用户、多 Key 维度
Claude Code 的生态:
- Hooks: 自定义命令钩子
- MCP: 通过 Model Context Protocol 接入外部工具
- IDE 集成: VS Code、JetBrains
- 紧密绑定 Anthropic 的工具调用能力
LiteLLM 是否支持 Prompt Caching 缓存计费?
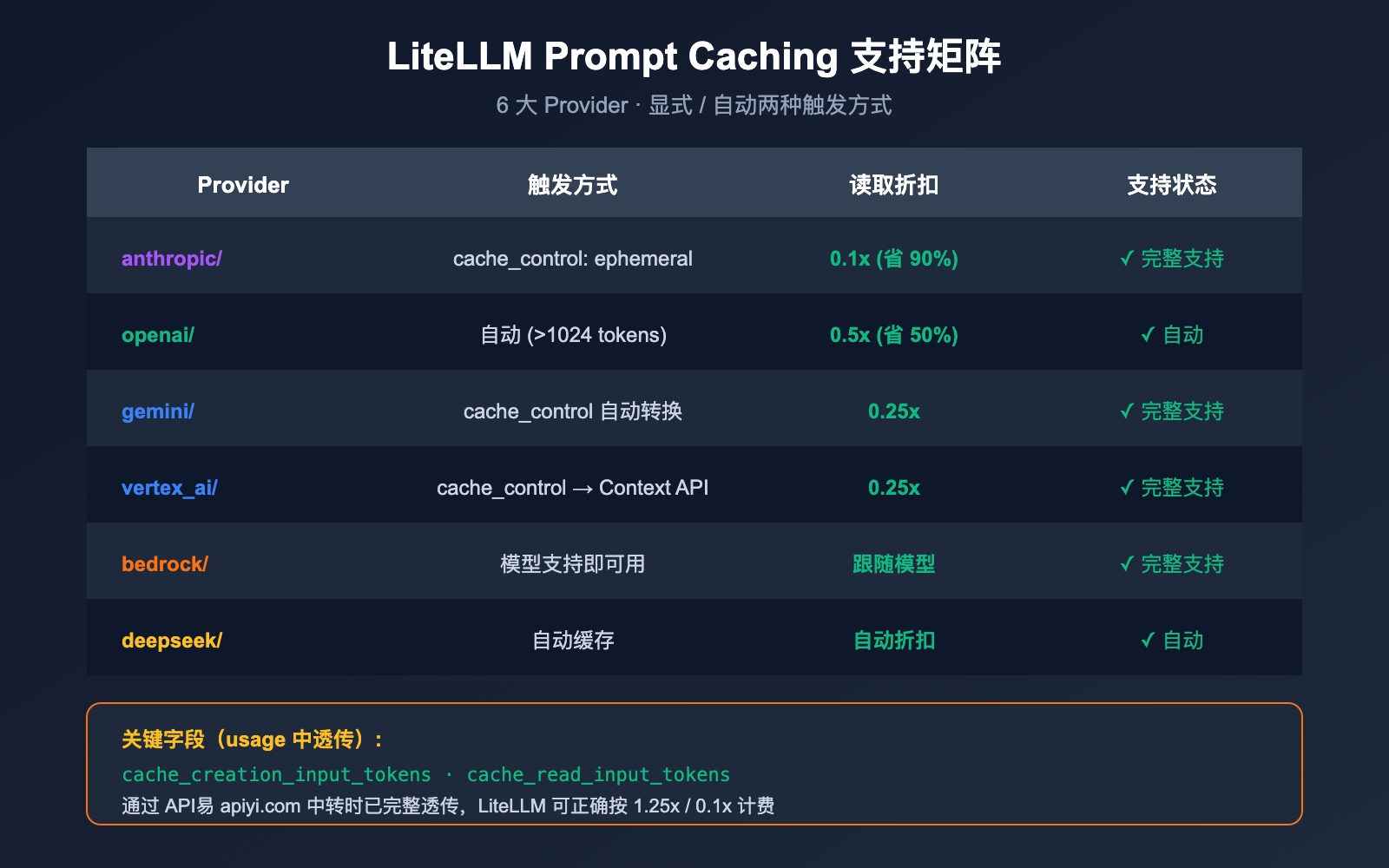
这是开发者最关心的一个问题。直接结论:支持,而且是一等公民。
支持矩阵
LiteLLM 官方文档明确列出,prompt caching 在以下 6 大 provider 上原生支持:
| Provider | LiteLLM 前缀 | 缓存触发方式 | 价格优势 |
|---|---|---|---|
| Anthropic | anthropic/ |
显式 cache_control: {"type": "ephemeral"} |
写入 1.25x,读取 0.1x (90% 折扣) |
| OpenAI | openai/ |
自动缓存 (>1024 tokens) | 自动 50% 折扣 |
| Google AI Studio | gemini/ |
显式 cache_control |
自动转换到 Context Caching API |
| Vertex AI | vertex_ai/ |
显式 cache_control |
同上 |
| Bedrock | bedrock/ |
模型支持即可用 | 跟随模型定价 |
| DeepSeek | deepseek/ |
自动缓存 | 自动折扣 |
代码示例:Anthropic 缓存
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "你是一个资深 Python 工程师...(长 system prompt)",
"cache_control": {"type": "ephemeral"}, # 关键:标记需缓存
}
],
},
{"role": "user", "content": "请审查这段代码"},
],
)
# 缓存使用量在 response.usage 中可见
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # 写入缓存的 token 数
# "cache_read_input_tokens": 0, # 第二次调用会变成 800
# "completion_tokens": 256,
# }
🎯 实战建议: Anthropic 的 prompt caching 在长 system prompt 和重复上下文场景下极其划算 —— 缓存读取只要原价的 10%。我们建议在长流程 Agent、RAG 检索增强、代码审查等场景下默认开启。如果你希望在国内稳定调用 Claude Opus 4.6 / Sonnet 4.6 并享受 prompt caching 折扣,可以通过 API易 apiyi.com 接入,平台完整透传缓存相关的 usage 字段。
Auto-Inject Cache Control(自动缓存)
如果不想手动给每条消息加 cache_control,LiteLLM 还提供自动注入:
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # 自动给所有 system 消息打缓存
],
)
这对接入老代码非常友好 —— 无需修改 messages 结构,就能享受 90% 缓存折扣。
缓存计费的"坑"与现状
LiteLLM 早期(2024 年)确实有过一个 bug(GitHub Issue #5443):cost tracking 没有正确区分 cache_creation_input_tokens 和 cache_read_input_tokens,导致计费偏差。但在 2025-2026 年的版本中,官方已修复。当前 LiteLLM 在 completion_cost() 函数中按以下规则计费:
| Token 类型 | 价格倍率 (相对 input price) | 说明 |
|---|---|---|
| Cache Write | 1.25x | 写入缓存有少量额外开销 |
| Cache Read | 0.1x | 读取缓存仅需 10% 价格 |
| 普通 Input | 1.0x | 标准输入 |
| Output | 由模型自定 | 输出 token |
🛡️ 重要提示: 如果你通过中转站调用,请确认中转站完整透传了
cache_creation_input_tokens和cache_read_input_tokens字段,否则 LiteLLM 在计费时会按普通 input 计算。API易 apiyi.com 已完整支持这两个字段的透传,配合 LiteLLM 即可获得真实的缓存折扣。
场景推荐:什么时候用 LiteLLM,什么时候用 Claude Code

场景 1: 个人开发者,主要做编码
推荐: 直接用 Claude Code
理由很简单 —— Claude 在编码场景上的体验目前仍是第一梯队,Tool Use 稳、文件改动准、上下文管理好。如果你是单兵作战、不需要切换模型,Claude Code 就是最省心的选择。如果在国内访问 Anthropic 官方有困难,可以把 ANTHROPIC_BASE_URL 指向 API易 apiyi.com 中转,体验完全一致。
场景 2: 团队搭建 AI 应用
推荐: LiteLLM Proxy + 应用代码
理由:你需要的是"统一计费 + 多模型路由 + Fallback",这正是 LiteLLM Proxy 的核心能力。Claude Code 是 CLI 工具,无法承担应用层网关角色。
最佳实践:
- 用 LiteLLM Proxy 跑一个独立服务(端口 4000)
- 所有底层模型通过 API易 apiyi.com 统一接入
- 应用层只调用 LiteLLM Proxy,看到的都是语义化模型名
场景 3: 既要 Claude Code 体验,又要切换模型
推荐: Claude Code + LiteLLM 组合
这是最强大的组合。配置非常简单:
# 启动 LiteLLM Proxy(指向多家模型)
litellm --config litellm_config.yaml --port 4000
# 让 Claude Code 走 LiteLLM
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# 用任意模型启动 Claude Code
claude --model claude-opus-4-6
claude --model gpt-5 # 同一个 CLI,背后是 GPT-5
claude --model gemini-3-pro # 同一个 CLI,背后是 Gemini 3 Pro
💡 组合价值: Claude Code 提供顶级的编码 Agent 体验,LiteLLM 提供模型自由度,API易 apiyi.com 提供稳定的国内中转。三者各司其职、互不干扰,是 2026 年最务实的"全栈 AI 编码"方案。
场景 4: 企业级生产部署
推荐: LiteLLM Proxy + Langfuse + API易
企业场景下,Claude Code 仅作为开发者本地工具使用,真正的生产流量需要:
- LiteLLM Proxy 做网关 + 限速 + Fallback
- Langfuse / Helicone 做 Logging 和成本分析
- API易 apiyi.com 做底层模型接入和稳定性保障
LiteLLM vs Claude Code 决策建议
下面这张决策表可以帮你 30 秒做出选择。
| 你的需求 | 推荐方案 |
|---|---|
| 我想在终端里让 AI 改代码 | Claude Code |
| 我想在 Python 应用里调用多家模型 | LiteLLM SDK |
| 我团队需要一个统一 LLM 入口 | LiteLLM Proxy |
| 我要给 Claude Code 切换底层模型 | Claude Code + LiteLLM |
| 我要做生产级 LLM 网关 | LiteLLM Proxy + 监控 |
| 我在国内访问海外模型不稳定 | 任选 + API易 apiyi.com 中转 |
| 我希望省 Anthropic 的 token 钱 | LiteLLM + prompt caching |
🚀 统一建议: 无论你选择哪个工具,底层接入 API易 apiyi.com 都是稳定性最高的选项。LiteLLM 可以通过
api_base直接指向 apiyi.com/v1,Claude Code 可以通过ANTHROPIC_BASE_URL间接走 LiteLLM 再到 apiyi.com,两条路径都已被大量开发者验证为稳定可用。
LiteLLM vs Claude Code 常见问题
Q1: LiteLLM 能完全替代 Claude Code 吗?
不能。LiteLLM 是 LLM 网关,没有 Claude Code 的"读你代码库 + 自主改文件 + 跑 Bash"那套 Agent 工具链。两者解决的是不同层面的问题,用 LiteLLM 替代 Claude Code 就像用"水管厂"替代"咖啡机"。
Q2: Claude Code 能完全替代 LiteLLM 吗?
也不能。Claude Code 是 CLI 工具,不是网关。它没有 model_list、router_settings、fallbacks 这些网关层概念,也无法被你的 Python 应用或 Web 服务直接调用。如果你要做"应用层的 AI 集成",Claude Code 帮不到你。
Q3: LiteLLM 真的支持 Anthropic 的 prompt caching 计费吗?
是的。LiteLLM 在 2025 年起完整支持 cache_control: {"type": "ephemeral"}、自动注入缓存点 cache_control_injection_points、以及 cache_creation_input_tokens / cache_read_input_tokens 的 usage 透传和 completion_cost() 计费。早期 Issue #5443 提到的成本计算 bug 已经修复,当前版本可以放心使用。
Q4: 通过 LiteLLM 调用 Anthropic 缓存,能省多少钱?
最高可省 ~90%。Anthropic 的 prompt caching 价格规则是:cache write 价格约为标准 input 的 1.25x,cache read 价格约为标准 input 的 0.1x。在长 system prompt 反复使用的场景(比如 RAG、代码审查、长流程 Agent),实际节省通常在 50-90% 之间。如果你通过 API易 apiyi.com 接入,这部分缓存折扣会完整体现到你的账单上。
Q5: Claude Code 用 LiteLLM 接到 GPT-5 后,效果会变差吗?
会有差异,但不一定变差。Claude Code 的 Tool Use 提示词是针对 Claude 优化的,切换到 GPT-5 后函数调用风格、文件编辑动作可能略有不同。建议把 Claude 系列作为主力模型,把其他模型作为"灵感/对比"备用。LiteLLM 的 Fallback 机制可以让你在 Claude 限流时自动降级到 GPT-5。
Q6: 国内开发者如何同时用好 Claude Code + LiteLLM + Anthropic Caching?
最务实的方案是三层结构: Claude Code (CLI) → LiteLLM Proxy (本地 4000 端口) → API易 apiyi.com (中转)。Claude Code 通过 ANTHROPIC_BASE_URL 指向 LiteLLM,LiteLLM 在 YAML 里把 model 配置成 anthropic/claude-opus-4-6,api_base 指向 apiyi.com/v1。这样既能用 Claude Code 的编码体验,又能享受 LiteLLM 的路由能力,还能通过 API易 解决网络与计费问题,并完整保留 prompt caching 折扣。
总结
LiteLLM 和 Claude Code 不是竞品,而是"网关层"和"应用层"两个不同抽象层次的工具。强行二选一是个伪命题,正确的问题应该是:你的场景适合哪种组合?
回到本文最初的两个问题:
- 哪个更好用? —— 取决于场景。个人编码用 Claude Code,应用开发用 LiteLLM,要兼顾两者就用 Claude Code + LiteLLM 组合
- LiteLLM 支持缓存计费吗? —— 完整支持,覆盖 Anthropic、OpenAI、Gemini、Vertex、Bedrock、DeepSeek 6 大 provider,最高可省 90% 输入 token 成本
🚀 行动建议: 如果你今天就想搭建一套"Claude Code + LiteLLM + Caching"的完整工作流,最快的路径是: 第一步在 API易 apiyi.com 注册并获取一个 Key;第二步用 LiteLLM 搭建本地 Proxy,把 api_base 指向 apiyi.com/v1;第三步在 Claude Code 里设置 ANTHROPIC_BASE_URL 指向本地 LiteLLM。整套链路 10 分钟内即可跑通,并可立即享受 prompt caching 带来的成本优势。
作者: APIYI Team — 专注于为开发者提供主流 AI 大模型的稳定接入,访问 apiyi.com 了解更多。
参考资料
-
LiteLLM 官方文档 – Prompt Caching
- 链接:
docs.litellm.ai/docs/completion/prompt_caching - 说明: 6 大 provider 的缓存支持矩阵和代码示例
- 链接:
-
LiteLLM 官方文档 – Auto-Inject Cache
- 链接:
docs.litellm.ai/docs/tutorials/prompt_caching - 说明: cache_control_injection_points 自动注入
- 链接:
-
LiteLLM 官方文档 – Claude Code Quickstart
- 链接:
docs.litellm.ai/docs/tutorials/claude_responses_api - 说明: ANTHROPIC_BASE_URL 配置和 1M context 支持
- 链接:
-
LiteLLM 官方文档 – Anthropic Provider
- 链接:
docs.litellm.ai/docs/providers/anthropic - 说明: cache_creation_input_tokens / cache_read_input_tokens 字段说明
- 链接:
-
GitHub Issue #5443 – Cache Cost Calculation
- 链接:
github.com/BerriAI/litellm/issues/5443 - 说明: 早期缓存计费 bug 与修复历史
- 链接:
-
LiteLLM GitHub 主仓库
- 链接:
github.com/BerriAI/litellm - 说明: 源码、Issue 与最新版本
- 链接: