阿里云 Qwen3.5 API 调用慢,是最近开发者社区中讨论最多的话题之一。作为阿里自研的模型,Qwen3.5-Plus 和 Qwen3.5-Flash 理论上应该在自有算力上表现出色,但实际体验却让不少开发者感到困惑——自家模型在自家平台上跑得慢,通过阿里云调用 GLM-5、Kimi-K2.5、MiniMax-M2.5 等第三方模型更是卡顿明显。
核心价值:本文将从算力供给、架构设计、调度策略 3 个维度深度解析阿里云 API 响应慢的根本原因,并给出 3 种经过验证的替代方案,帮助你在实际项目中获得更快的推理体验。

阿里云 Qwen3.5 API 慢的 5 大原因分析
原因一:全球 GPU 算力供给严重不足
这不仅是阿里云一家的问题,而是整个行业的结构性矛盾。2026 年数据中心级 GPU 的交付周期已经拉长到 36-52 周,阿里云高管公开承认——半导体制造商、存储芯片、内存器件全面短缺,供应端将成为未来 2-3 年的"较大瓶颈"。
| 算力供给指标 | 2025 年 | 2026 年 | 变化趋势 |
|---|---|---|---|
| GPU 交付周期 | 12-24 周 | 36-52 周 | ↑ 大幅延长 |
| 阿里云 AI 收入增长 | — | 34% | 需求爆发 |
| 阿里云算力价格调整 | 基准价 | 上调最高 34% | ↑ 2026年4月18日起 |
| 全球 AI 推理支出占比 | 42% | 55% | 首次超过训练 |
阿里云已官宣将从 2026 年 4 月 18 日起上调 AI 算力价格,涨幅最高达 34%,直接原因就是"全球 AI 需求爆发和供应链价格上涨"。阿里云收入增长了 34%,但公开表示仍然无法满足需求——这就是 Qwen3.5 API 慢的宏观背景。
原因二:Qwen3.5 模型架构的算力消耗
Qwen3.5 家族采用了 MoE(混合专家)架构,旗舰版 Qwen3.5-397B-A17B 总参数量达 3970 亿,每次推理激活 170 亿参数。即便是定位轻量的 Qwen3.5-Flash(基于 35B-A3B),也原生支持 100 万 token 上下文和多模态输入(文本+图像+视频)。
| 模型版本 | 总参数量 | 激活参数量 | 默认上下文 | 多模态支持 |
|---|---|---|---|---|
| Qwen3.5-397B-A17B(旗舰) | 3970 亿 | 170 亿 | 262K→1M | 文本+图像+视频 |
| Qwen3.5-Plus(API 版) | 未公开 | 未公开 | 1M | 文本+图像+视频 |
| Qwen3.5-Flash(API 版) | 350 亿 | 30 亿 | 1M | 文本+图像+视频 |
| Qwen3.5-122B-A10B | 1220 亿 | 100 亿 | 262K | 文本+图像+视频 |
这些模型从训练阶段就采用了早期融合(early-fusion)的多模态架构,原生支持文本、图像和视频的统一处理。功能强大的代价就是:每个请求的计算开销远高于纯文本模型。再叠加百万级 token 上下文窗口,单次推理的显存和算力占用显著增加。
原因三:阿里云转售第三方模型的额外延迟
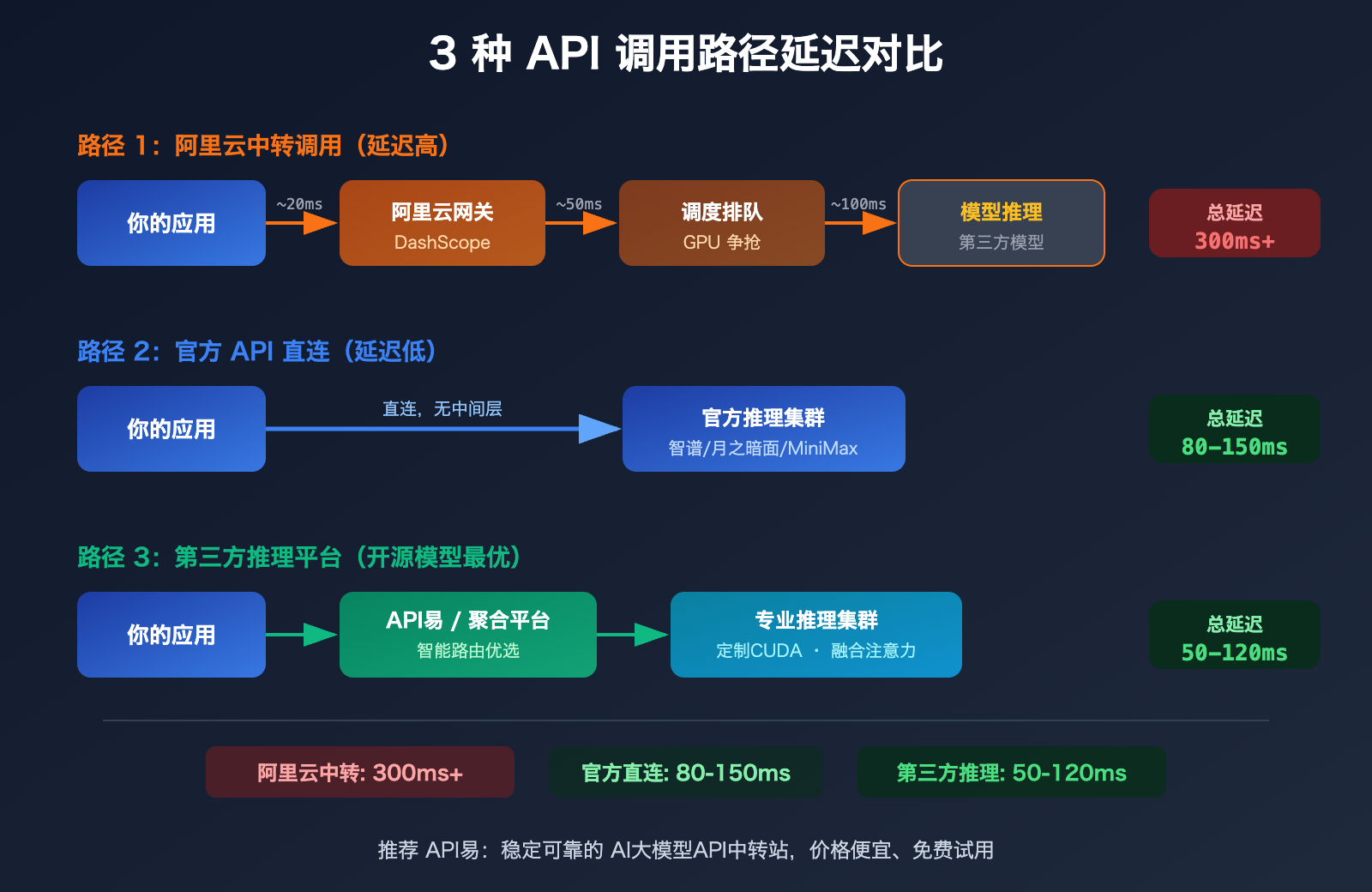
通过阿里云 DashScope 平台调用 GLM-5(智谱 AI)、Kimi-K2.5(月之暗面)、MiniMax-M2.5 这些第三方模型时,请求链路实际上变成了:
你的应用 → 阿里云 API 网关 → DashScope 调度层 → 第三方模型服务
每多一层转发,就多一层延迟。更关键的是,阿里云在转售这些模型时,GPU 资源的分配优先级可能低于自有模型——毕竟算力本身就不够用。圈内开发者的普遍反馈是:GLM-5、Kimi-K2.5、MiniMax-M2.5 通过阿里云调用明显比官方 API 慢。
原因四:推理调度策略的优化不足
专业的第三方推理平台(如 SiliconFlow、Fireworks AI、Together AI)通过定制 CUDA 内核、融合注意力机制、细粒度调度等技术手段,在推理效率上具有显著优势。实测数据显示:
- SiliconFlow:推理速度最高比通用云平台快 2.3 倍,延迟降低 32%
- Fireworks AI:FireAttention v2 技术声称最高 8 倍速度提升,实测约 747 TPS
- Together AI:通过投机解码和 FP4 量化,开源模型推理速度最高 2 倍提升
阿里云作为通用云平台,其推理调度更侧重通用性和稳定性,而非极致的推理速度优化。这在算力充裕时影响不大,但在 GPU 紧张时期,差距就会被放大。
原因五:多租户资源争抢
阿里云作为国内最大的云服务商,其 AI 推理集群同时服务海量用户。在高峰期,GPU 资源的争抢直接导致排队等待时间增加。阿里云开发的 Aegaeon 资源池化系统虽然声称将 GPU 利用率提升了 82%,但这本质上是"把有限的蛋糕切得更细",并不能从根本上解决算力总量不足的问题。
GLM-5、Kimi-K2.5、MiniMax-M2.5 阿里云调用 vs 官方 API 延迟对比
了解了原因之后,我们来看具体的模型调用场景。以下是 3 款热门模型在不同平台上的体验差异分析。
GLM-5(智谱 AI)API 调用延迟分析
GLM-5 是智谱 AI 于 2026 年 2 月发布的旗舰模型,总参数 7440 亿,激活参数 400 亿,采用 MoE 架构。它在华为昇腾芯片上训练,支持 20 万 token 上下文,并且已经开源(MIT 许可证)。
关键事实:GLM-5 原生支持 Agent 模式,能自主拆解任务为子任务执行,并可直接生成专业办公文档(.docx、.pdf、.xlsx)。其定价为输入 $1.00/M tokens、输出 $3.20/M tokens。
通过阿里云调用 GLM-5 时,请求需要经过额外的网关和调度层转发,延迟显著增加。而直连智谱 AI 官方 API(bigmodel.cn),请求直接到达智谱自有的推理集群,响应更快。
Kimi-K2.5(月之暗面)API 调用延迟分析
Kimi-K2.5 于 2026 年 1 月发布,是一个 1 万亿参数的 MoE 模型,每次请求仅激活 320 亿参数。它在 15 万亿混合视觉和文本 token 上预训练,原生多模态。
最大亮点:Agent Swarm 功能——可以同时协调最高 100 个专业 AI Agent 协同工作,执行时间缩短 4.5 倍。在 SWE-Bench Verified 上超越 Gemini 3 Pro,Cursor AI 已确认其 Composer 2 功能基于 Kimi 技术构建。
通过阿里云中转调用 Kimi-K2.5,额外的转发链路让这个本就需要大量算力的万亿参数模型体验更差。建议直接使用月之暗面官方 API(platform.moonshot.ai)。
MiniMax-M2.5 API 调用延迟分析
MiniMax-M2.5 于 2026 年 2 月发布,总参数 2300 亿,激活参数 100 亿。在 SWE-Bench Verified 上得分 80.2%,完成速度比 M2.1 快 37%,与 Claude Opus 4.6 持平。
成本优势突出:号称首个"用户无需担心成本"的前沿模型——以 100 tokens/秒的速度持续运行 1 小时仅需约 1 美元。已在 Hugging Face 开源,推荐使用 vLLM 或 SGLang 部署。
| 模型 | 发布时间 | 总参数 | 激活参数 | 建议调用方式 | 开源状态 |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 7440 亿 | 400 亿 | 智谱官方 API | MIT 开源 |
| Kimi-K2.5 | 2026.01.27 | 1 万亿 | 320 亿 | 月之暗面官方 API | 开源 |
| MiniMax-M2.5 | 2026.02.12 | 2300 亿 | 100 亿 | MiniMax 官方 / 第三方 | MIT 修改版 |
🎯 实测建议:对于 GLM-5、Kimi-K2.5、MiniMax-M2.5 这类闭源或半开源的第三方模型,推荐直连各家官方 API 获取最佳体验。如果需要统一管理多家模型的 API 接口,可以通过 API易 apiyi.com 平台实现一个 API Key 调用多家模型,同时享受更优的价格。
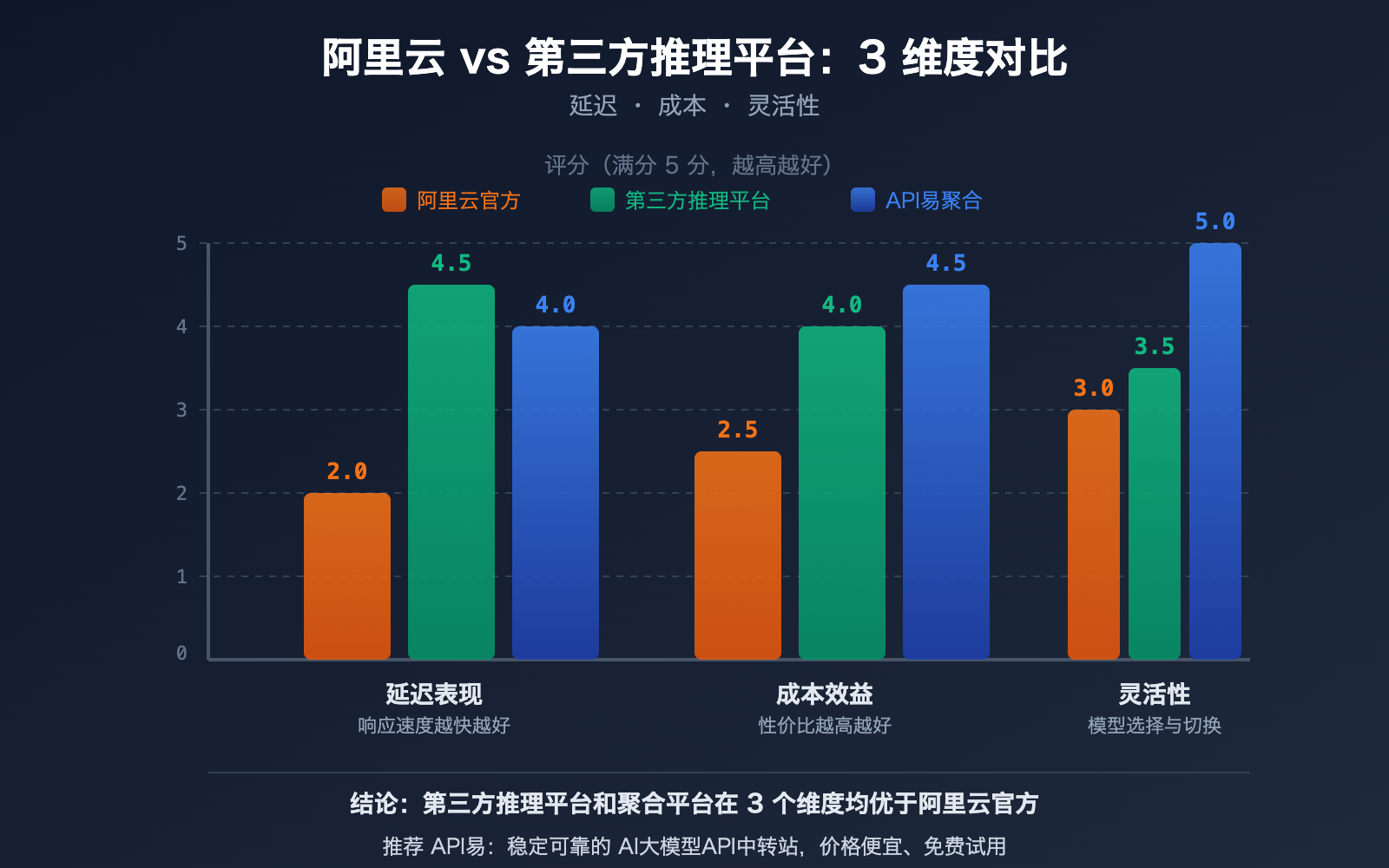
第三方推理平台 vs 阿里云:开源模型部署的 3 大优势
对于 Qwen3.5 这样的开源模型,除了阿里云官方 API,开发者还有更多选择。专业的第三方推理平台在部署开源模型方面,往往有着不输甚至超越原厂的表现。
优势一:推理速度更快
专业推理平台的核心竞争力就是速度。它们通过定制化的推理引擎优化,在相同模型上实现更低延迟:
| 平台类型 | 典型延迟 | 吞吐量 | 速度优势 |
|---|---|---|---|
| 通用云平台(阿里云等) | 100-300ms | 基准 | — |
| SiliconFlow | 降低 32% | 提升 2.3x | 定制 CUDA 内核 |
| Fireworks AI | ~0.17s | ~747 TPS | FireAttention v2 |
| Together AI | — | 提升 2x | 投机解码+FP4 量化 |
| API易 apiyi.com | 多通道优选 | 智能路由 | 自动选择最快通道 |
优势二:成本更低
2026 年 AI 推理支出首次超过训练支出,占 AI 云基础设施总支出的 55%。在这一背景下,推理成本优化变得至关重要:
- 开源模型通过第三方 API 调用,价格通常低于 $1/M tokens,比闭源模型节省 70-90%
- 专业推理平台利用 NVIDIA Blackwell 等新一代硬件,将 AI 推理成本降低最高 10 倍
- 无需自建 GPU 集群,按需付费,适合中小团队和个人开发者
优势三:更灵活的模型选择
第三方平台通常同时支持开源和闭源模型,提供统一的 API 接口和透明的定价。这意味着:
- 无厂商锁定:不绑定任何一家云服务商
- 快速切换:一个接口调用多个模型,对比效果后选择最优
- 自定义优化:开源模型支持量化、微调、合并等自定义操作
💡 选择建议:对于 Qwen3.5 等开源模型,第三方推理平台的部署效果可能比阿里云官方 API 更好。我们建议通过 API易 apiyi.com 平台进行实际测试对比,该平台聚合了多家推理通道,自动为你选择延迟最低的路径。
开源模型 API 调用快速上手:5 分钟接入指南
以 Qwen3.5-Flash 为例,展示如何通过第三方平台快速调用开源模型 API。
极简代码示例
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "分析 Qwen3.5 的 MoE 架构优势"}
]
)
print(response.choices[0].message.content)
查看完整代码(含多模型切换和错误处理)
import openai
import time
# 初始化客户端 - 通过 API易 统一调用多家模型
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# 支持的模型列表
models = [
"qwen3.5-flash", # 阿里 Qwen3.5-Flash
"qwen3.5-plus", # 阿里 Qwen3.5-Plus
"glm-5", # 智谱 GLM-5
"kimi-k2.5", # 月之暗面 Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "用 3 句话解释 MoE 架构在大模型推理中的优势"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] 耗时: {elapsed:.2f}s")
print(f"回复: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] 调用失败: {e}")
🚀 快速开始:推荐使用 API易 apiyi.com 平台快速测试上述模型。注册即送免费额度,一个 API Key 即可调用 Qwen3.5、GLM-5、Kimi-K2.5、MiniMax-M2.5 等主流模型,无需分别注册多家平台。
不同场景下的模型调用方案推荐
根据你的实际需求,选择最合适的调用方式:
场景一:需要调用闭源/半闭源模型
如果你主要使用 GLM-5、Kimi-K2.5 等模型的闭源版本(非自部署),建议:
- 首选:直连各家官方 API,延迟最低
- 次选:通过 API易 apiyi.com 等聚合平台统一调用,牺牲少量延迟换取管理便利
场景二:需要部署开源模型
如果你使用 Qwen3.5、GLM-5 开源版、MiniMax-M2.5 开源版等模型:
- 预算充足:选择 SiliconFlow、Together AI 等专业推理平台,延迟最优
- 性价比优先:通过 API易 apiyi.com 聚合调用,自动路由到最优通道
- 完全自控:使用 vLLM 或 SGLang 自建推理服务,需要自有 GPU 资源
场景三:需要多模型对比测试
开发初期需要快速对比多个模型的效果时:
- 推荐:使用统一 API 接口(如 API易 apiyi.com),一次注册即可切换测试多个模型
- 避免为每个模型单独注册账号、管理多套 API Key
💰 成本优化建议:对于预算敏感的项目,通过 API易 apiyi.com 平台调用开源模型 API 是最具性价比的方案。平台提供灵活的计费方式,开源模型调用成本远低于闭源模型官方定价。
常见问题
Q1:Qwen3.5-Flash 号称轻量模型,为什么 API 还是慢?
Qwen3.5-Flash 虽然每次推理仅激活 30 亿参数,但它默认支持 100 万 token 上下文窗口,并且原生集成了多模态处理能力(文本+图像+视频)和内置工具调用。这些"隐藏成本"让它的实际算力消耗远高于同等参数量的纯文本模型。加上阿里云 GPU 资源紧张的大背景,排队等待时间进一步拉高了感知延迟。
Q2:开源模型用第三方平台部署,效果会不会打折扣?
不会。专业的第三方推理平台(如 SiliconFlow、Together AI)使用的是原版开源权重,配合优化的推理引擎,效果与原厂一致,推理速度反而更快。通过 API易 apiyi.com 平台可以快速对比不同通道的推理质量和速度,选择最优方案。
Q3:阿里云的算力问题什么时候能缓解?
根据阿里云高管的公开表态,GPU 供应短缺预计将持续 2-3 年。短期内,阿里云更倾向于通过 Aegaeon 等资源池化技术提高现有 GPU 的利用率,而非大幅扩容。建议开发者不要等待平台优化,而是主动选择更适合的调用方案——官方 API 直连或第三方推理平台都是当下可行的替代方案。可以通过 API易 apiyi.com 免费测试不同模型的调用速度。
总结:阿里云 Qwen3.5 API 慢的应对策略
阿里云 Qwen3.5 API 响应慢的根本原因是全球 GPU 算力供给不足,叠加模型架构的高算力消耗、多租户资源争抢等因素。对于通过阿里云调用 GLM-5、Kimi-K2.5、MiniMax-M2.5 等第三方模型出现的卡顿问题,本质上也是同一原因——阿里云的算力优先保障自有模型,第三方模型的资源分配处于次要位置。
3 条核心建议:
- 闭源模型直连官方:GLM-5 用智谱 API、Kimi-K2.5 用月之暗面 API、MiniMax-M2.5 用 MiniMax API,避免中间层转发延迟
- 开源模型选第三方:Qwen3.5 等开源模型在专业推理平台上的表现可能优于阿里云官方 API
- 统一管理用聚合平台:如果需要同时使用多个模型,推荐通过 API易 apiyi.com 实现一个接口调用所有模型,兼顾效率和管理便利
算力短缺是整个行业未来 2-3 年的常态。与其被动等待云平台扩容,不如主动优化调用策略——选择最适合的平台和模型组合,才是提升 AI 应用体验的最佳路径。
作者:APIYI Team | 更多 AI 模型 API 调用技巧,欢迎访问 API易 apiyi.com 获取最新教程和免费测试额度
📚 参考资料
-
Qwen3.5 模型系列官方文档:阿里云通义千问模型技术规格
- 链接:
github.com/QwenLM/Qwen3.5 - 说明: 包含完整的模型参数、基准测试和使用指南
- 链接:
-
阿里云算力价格调整公告:2026 年 4 月起 AI 算力价格上调
- 链接:
www.alibabacloud.com - 说明: 官方关于算力供需矛盾的说明
- 链接:
-
GLM-5 技术报告:智谱 AI 旗舰模型技术细节
- 链接:
github.com/THUDM/GLM-5 - 说明: 7440 亿参数 MoE 架构和 Agent 模式说明
- 链接:
-
Kimi-K2.5 官方文档:月之暗面万亿参数模型
- 链接:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - 说明: Agent Swarm 功能和 API 接入指南
- 链接:
-
MiniMax-M2.5 技术博客:前沿开源模型详解
- 链接:
www.minimax.io/news/minimax-m25 - 说明: 性能基准、部署建议和成本分析
- 链接: