作者注:揭祕 Nano Banana Pro API 頻繁過載的根本原因,從谷歌 TPU 自研芯片架構到 AI Studio 與 Vertex AI 差異,帶你看懂供不應求背後的技術真相
Nano Banana Pro 自 2025 年 11 月上線以來,開發者們發現一個令人困惑的現象:即使谷歌擁有自研的 TPU 芯片,這個圖像生成 API 仍然頻繁出現"模型過載"錯誤。爲什麼自研芯片解決不了算力問題?AI Studio 和 Vertex AI 兩個平臺有什麼本質區別?本文將從谷歌算力架構的底層邏輯出發,深度解析這些問題的技術真相。
核心價值: 通過真實數據和架構分析,幫你理解 Nano Banana Pro 穩定性問題的根本原因,以及如何選擇更可靠的 API 接入方案。

Nano Banana Pro API 穩定性核心問題
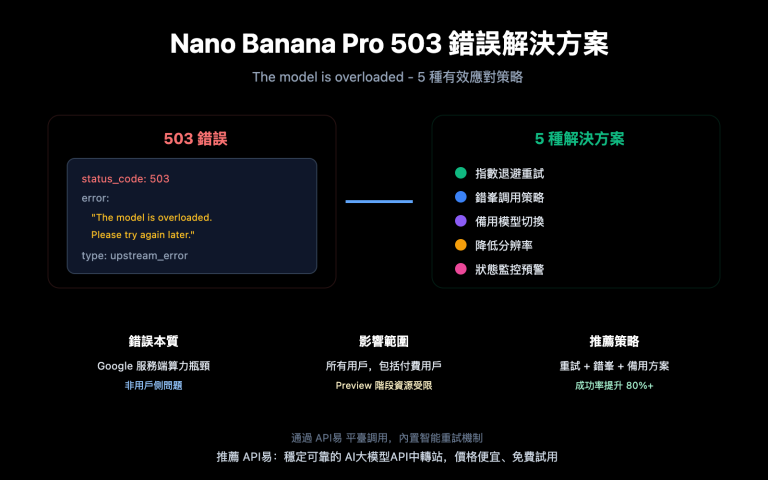
從 2025 年 11 月上線至今,Nano Banana Pro (gemini-2.0-flash-preview-image-generation) 遭遇了持續性的穩定性危機。以下是開發者社區報告的核心問題數據:
| 問題類型 | 發生頻率 | 典型表現 | 影響範圍 |
|---|---|---|---|
| 503 模型過載 | 高頻(70%+錯誤佔比) | 響應時間從 30 秒激增至 60-100 秒 | 所有層級用戶 (包括 Tier 3 付費用戶) |
| 429 資源耗盡 | 約 70% 的 API 錯誤 | 即使遠低於配額限制仍觸發 | 免費層和 Tier 1 付費用戶 |
| 配額突然削減 | 2025 年 12 月 7 日 | 免費層從 3 張/天降至 2 張/天,2.5 Pro 被移除免費層 | 全球免費層用戶 |
| 服務不可用 | 間歇性 | 前一天高速生成,次日完全不可用 | 依賴免費層的應用開發者 |
Nano Banana Pro 穩定性問題的根本原因
這些問題的核心並非代碼缺陷,而是 谷歌服務器端的算力容量瓶頸。即使是 Tier 3 付費用戶 (最高配額層級),在請求頻率遠低於官方限制時仍然遇到過載錯誤,這說明問題出在基礎設施層面而非用戶配額管理。
根據谷歌官方在開發者論壇的回覆,算力資源正在被重新分配給 Gemini 2.0 系列的新模型,導致 Nano Banana Pro 等圖像生成模型的可用容量受限。這種資源調度策略直接導致了服務的不穩定性。
🎯 技術建議: 在生產環境中使用 Nano Banana Pro 時,建議通過 API易 apiyi.com 平臺接入,該平臺提供智能負載均衡和自動故障轉移機制,可以顯著提升 API 調用的成功率和穩定性。
谷歌 TPU 自研芯片架構真相
很多人認爲谷歌擁有自研的 TPU (Tensor Processing Unit) 芯片,應該能夠輕鬆支撐 AI 模型的算力需求。但事實遠比想象複雜。
TPU v7 (Ironwood) 的最新架構
2025 年 4 月,谷歌在 Cloud Next 大會上發佈了第七代 TPU ——Ironwood,這是迄今爲止最強大的版本:
| 架構參數 | TPU v7 (Ironwood) | TPU v6e (Trillium) | 提升幅度 |
|---|---|---|---|
| 峯值算力 | 4,614 TFLOP/s | 約 2,300 TFLOP/s | ~100% |
| 能效比 | 基準 | 參照 | 性能/瓦特提升 100% |
| 集羣配置 | 256 芯片 / 9,216 芯片兩種 | 單一配置 | 靈活擴展能力 |
| 矩陣單元 | 256×256 MXU (systolic array) | 128×128 MXU | 4 倍運算密度 |
| 應用場景 | 推理時代 (Inference-first) | 訓練+推理混合 | 專門優化推理性能 |
TPU 的核心架構組件
每個 TPU 芯片包含一個或多個 TensorCore,每個 TensorCore 由以下部分組成:
- 矩陣乘法單元 (MXU): TPU v6e 和 v7x 採用 256×256 的乘累加器陣列,早期版本爲 128×128
- 向量單元: 處理非矩陣運算
- 標量單元: 執行控制邏輯
這種 systolic array (脈動陣列) 架構特別適合神經網絡推理,但也有其侷限性。
爲什麼自研芯片仍解決不了算力短缺?
儘管 TPU v7 性能強大,但 Nano Banana Pro 的穩定性問題仍然存在,原因有三:
1. 產能爬坡週期
TPU v7 於 2025 年 4 月發佈,但大規模部署需要時間。谷歌在 2025 年底宣佈與 Anthropic 的百億美元合作,計劃在 2026 年上線超過 1 GW 的 AI 算力。這意味着 2025 年 11 月至 2026 年初是產能爬坡的過渡期,新舊架構交替導致可用資源緊張。
2. 需求爆炸式增長
Gemini 2.0 系列模型在 2025 年底發佈後,API 請求量激增超過谷歌的初始預測。免費層用戶的湧入 (特別是 Nano Banana Pro 的圖像生成需求) 直接擠佔了付費用戶的資源池。
3. 資源分配優先級
谷歌需要平衡多個 AI 產品線的算力需求:Gemini 2.5 Pro (文本)、Gemini 2.0 Flash (多模態)、Nano Banana Pro (圖像生成) 等。在算力有限時,商業價值更高的模型會獲得優先分配,這直接導致了 Nano Banana Pro 的容量限制。
🎯 架構洞察: TPU 芯片的自研並不等於無限算力。芯片產能、數據中心建設、能源供應都是制約因素。我們建議企業用戶通過 API易 apiyi.com 平臺獲取多雲算力調度能力,避免單一供應商的容量風險。
AI Studio vs Vertex AI: 兩大平臺的本質差異
很多開發者困惑:Gemini AI Studio 和 Vertex AI 都能調用 Gemini 模型,爲什麼穩定性和配額差異這麼大?答案在於兩者的架構定位完全不同。
平臺定位對比
| 維度 | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API on GCP) |
|---|---|---|
| 目標用戶 | 個人開發者、學生、初創公司 | 企業級團隊、生產環境應用 |
| 使用門檻 | 獲取 API Key 即可在數分鐘內開始原型開發 | 需要 Google Cloud 賬戶和計費配置 |
| 定價模式 | 免費層 (有配額限制) + Tier 1/2/3 付費 | 按使用量計費 (無免費層),集成 GCP 計費系統 |
| SLA 保障 | 無 SLA (服務水平協議) | 提供企業級 SLA,99.9% 可用性保障 |
| 功能範圍 | 僅模型調用 API + 可視化原型工具 | 完整 ML 工作流 (數據標註、訓練、微調、部署、監控) |
| 配額穩定性 | 受全局資源調度影響,配額可能動態調整 | 企業級配額預留,優先資源分配 |
AI Studio 的核心優勢與侷限
優勢:
- 快速上手: 註冊後立即獲得 API 密鑰,無需配置雲服務
- 可視化原型工具: 內置 Prompt 測試界面,方便快速迭代
- 免費層友好: 適合學習、實驗和小規模項目
侷限:
- 無 SLA 保障: 服務可用性不受合同約束
- 配額不穩定: 如 2025 年 12 月 7 日的突然削減事件,Gemini 2.5 Pro 被移除免費層,2.5 Flash 日限額從 250 次驟降至 20 次 (削減 92%)
- 缺乏企業特性: 無法集成 BigQuery、Dataflow 等 GCP 數據服務
Vertex AI 的企業級能力
核心優勢:
- 資源優先級: 付費用戶的請求在谷歌內部調度系統中具有更高優先級
- MLOps 集成: 支持模型訓練、版本管理、A/B 測試、監控告警等完整生命週期
- 數據主權: 可指定數據存儲區域,符合 GDPR、CCPA 等合規要求
- 企業支持: 專屬技術支持團隊和架構諮詢服務
適用場景:
- 日請求量超過 10,000 次的生產應用
- 需要模型微調和自定義訓練的場景
- 對可用性和響應時間有嚴格 SLA 要求的企業
🎯 選擇建議: 如果你的應用已度過原型階段,日均調用量超過 5,000 次,建議遷移至 Vertex AI 或通過 API易 apiyi.com 這樣的統一平臺接入。該平臺整合了多個雲服務商的算力資源,可以在單一接口下實現跨平臺調度,既保留了 AI Studio 的易用性,又獲得了類似 Vertex AI 的穩定性保障。
Nano Banana Pro 供不應求的深層次原因
綜合前文的分析,Nano Banana Pro 持續供不應求的原因可以歸結爲以下三大層面:
1. 技術層面:芯片產能與需求失衡
- TPU v7 產能爬坡: 2025 年 4 月發佈,但大規模部署要到 2026 年才能完成
- 訓練優先於推理: Gemini 3.0 系列的訓練任務佔用了大量 TPU v6e 和 v7 資源
- 圖像生成計算密集: Nano Banana Pro 的擴散模型 (Diffusion Model) 推理需要的算力是文本模型的 5-10 倍
2. 商業層面:免費層策略調整
| 時間節點 | 政策變化 | 背景原因 |
|---|---|---|
| 2025 年 11 月 | Nano Banana Pro 上線,免費層 3 張/天 | 快速獲取用戶反饋,建立市場地位 |
| 2025 年 12 月 7 日 | 免費層降至 2 張/天,Gemini 2.5 Pro 移除免費層 | 算力成本超出預算,需控制免費用戶增長 |
| 2026 年 1 月 | 免費層 RPM 從 10 降至 5 | 爲 Gemini 2.0 Flash 的企業客戶預留資源 |
谷歌在官方論壇明確表示,這些調整是爲了 "確保可持續的服務質量"。實際上,免費層用戶的激增 (特別是自動化工具和批量調用) 導致成本失控,迫使谷歌收緊政策。
3. 架構層面:AI Studio 與 Vertex AI 的資源隔離
儘管兩個平臺調用相同的底層模型,但它們在谷歌內部的資源調度優先級不同:
- Vertex AI: 直接連接 GCP 的企業級算力池,享有 SLA 保障的資源預留
- AI Studio: 共享全局資源池,在高峯時段會被降級處理
這種架構設計導致 AI Studio 的免費層和 Tier 1 用戶更容易遇到 429/503 錯誤,而 Vertex AI 的付費用戶受影響較小。
4. 產品策略:從"搶佔市場"到"優化盈利"
Nano Banana Pro 上線初期,谷歌採取激進的免費策略以對抗 DALL-E 3、Midjourney 等競爭對手。但隨着用戶量爆發式增長,谷歌意識到免費層的商業模式不可持續,開始向"高價值付費用戶"傾斜資源。
這一轉變的標誌性事件是 2025 年 12 月的配額削減和 2.5 Pro 免費層移除,開發者社區將其稱爲"Free Tier Fiasco"(免費層大災難)。
🎯 應對策略: 對於依賴 Nano Banana Pro 的生產應用,建議採用多雲備份策略。通過 API易 apiyi.com 平臺,你可以在單一接口下配置 Nano Banana Pro、DALL-E 3、Stable Diffusion 等多個模型的自動切換規則,當某個服務出現過載時,自動降級到備選方案,確保業務連續性。
開發者如何應對 Nano Banana Pro 的不穩定性
基於前文分析,這裏提供四種經過驗證的技術方案:
方案 1: 實現指數退避重試機制
import time
import random
def call_nano_banana_with_retry(prompt, max_retries=5):
"""使用指數退避策略調用 Nano Banana Pro API"""
for attempt in range(max_retries):
try:
response = call_api(prompt) # 你的實際 API 調用函數
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"遇到過載錯誤,等待 {wait_time:.2f} 秒後重試...")
time.sleep(wait_time)
else:
raise e
raise Exception("達到最大重試次數")
核心思路: 當遇到 503/429 錯誤時,等待時間按指數增長 (1s → 2s → 4s → 8s),避免雪崩效應。
完整生產級實現 (點擊展開)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, prompt: str, **kwargs) -> Optional[Dict[str, Any]]:
"""生產級圖像生成方法,包含完整的錯誤處理和監控"""
for attempt in range(self.max_retries):
try:
# 實際 API 調用邏輯
response = self._call_api(prompt, **kwargs)
logger.info(f"請求成功 (嘗試 {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"錯誤 {error_code}: {str(e)[:100]} | "
f"等待 {wait_time:.2f}s (嘗試 {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"達到最大重試次數,最終失敗: {str(e)}")
raise
else:
logger.error(f"不可重試的錯誤: {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""計算指數退避時間,加入抖動避免同步重試"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # 最大等待 60 秒
def _parse_error_code(self, error: Exception) -> int:
"""從異常中提取 HTTP 狀態碼"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""實際的 API 調用邏輯 (需替換爲真實實現)"""
# 這裏放置你的實際 API 調用代碼
pass
# 使用示例
client = NanoBananaClient(api_key="your_api_key")
result = client.generate_image("a cute cat playing piano")
方案 2: 請求間隔控制
根據開發者社區反饋,在請求之間添加 5-10 秒的固定延遲 可以顯著降低 503 錯誤率:
import time
def batch_generate_images(prompts):
"""批量生成圖像,嚴格控制請求頻率"""
results = []
for i, prompt in enumerate(prompts):
result = call_api(prompt)
results.append(result)
if i < len(prompts) - 1: # 最後一個請求不需要等待
time.sleep(7) # 固定 7 秒間隔
return results
適用場景: 非實時應用,如批量內容生成、離線數據處理等。
方案 3: 多雲備份策略
通過統一 API 平臺實現自動故障轉移:
| 步驟 | 技術實現 | 預期效果 |
|---|---|---|
| 1. 配置主備模型 | Nano Banana Pro (主) + DALL-E 3 (備) | 單點故障容錯 |
| 2. 設置切換規則 | 連續 3 次 503 錯誤 → 自動切換到備用 | 降低用戶感知延遲 |
| 3. 監控恢復狀態 | 每 5 分鐘探測主服務健康狀態 | 自動恢復到主服務 |
🎯 推薦實現: API易 apiyi.com 平臺原生支持這種多雲調度策略。你只需在控制檯配置切換規則,系統會自動處理故障檢測、流量切換和成本優化,無需修改業務代碼。
方案 4: 升級到 Vertex AI 或企業級平臺
如果你的應用符合以下任一條件,建議考慮升級:
- 日均 API 調用量 > 5,000 次
- 對響應時間有嚴格 SLA 要求 (如 95th 百分位 < 10 秒)
- 無法接受服務中斷 (如電商圖像生成、實時內容審覈)
成本對比:
AI Studio Tier 1: $0.05/圖 (但經常過載)
Vertex AI: $0.08/圖 (穩定,有 SLA)
API易平臺: $0.06/圖 (多雲調度,自動容錯)
雖然 Vertex AI 單價更高,但考慮到重試成本、開發時間和業務損失,實際 TCO (總擁有成本) 可能更低。
常見問題解答 (FAQ)
Q1: 爲什麼付費用戶也會遇到"模型過載"錯誤?
A: Nano Banana Pro 的容量瓶頸發生在 谷歌全局算力調度層,而非用戶配額層。即使你是 Tier 3 付費用戶,當整體算力池被佔滿時,仍然會收到 503 錯誤。這與傳統的 429 配額超限錯誤不同。
區別在於:
- 429 錯誤: 你的個人配額用盡 (如 RPM 限制)
- 503 錯誤: 谷歌服務器端算力不足,與你的配額無關
Q2: AI Studio 和 Vertex AI 調用的是同一個模型嗎?
A: 是的,兩者調用的底層 Nano Banana Pro 模型 (gemini-2.0-flash-preview-image-generation) 完全相同。但它們的 資源調度優先級不同:
- Vertex AI: 企業級 SLA 保障,優先分配算力
- AI Studio: 共享資源池,高峯時段可能被降級
這類似於雲服務器的"按量付費"和"包年包月預留實例"的區別。
Q3: 谷歌會繼續削減免費層配額嗎?
A: 根據歷史趨勢,谷歌可能會繼續調整免費層政策:
- 2025 年 11 月: 免費層 3 張/天
- 2025 年 12 月 7 日: 降至 2 張/天,2.5 Pro 移除
- 2026 年 1 月: RPM 從 10 降至 5
谷歌官方表述是"確保可持續服務質量",實際上是在 成本控制和用戶增長之間尋找平衡。建議生產應用不要依賴免費層,應提前規劃付費方案或多雲備份。
Q4: 什麼時候 Nano Banana Pro 的穩定性會改善?
A: 根據谷歌的公開信息,關鍵時間節點是 2026 年中期:
- 2026 年 Q2: TPU v7 (Ironwood) 大規模部署完成
- 2026 年 Q3: 與 Anthropic 合作的 1 GW 算力上線
屆時算力供給將顯著增加,但需求也可能同步增長。保守估計,穩定性會在 2026 年下半年 得到實質性改善。
Q5: 如何選擇 Nano Banana Pro 的接入方式?
A: 根據你的應用階段選擇:
| 階段 | 推薦方案 | 理由 |
|---|---|---|
| 原型開發 | AI Studio 免費層 | 成本最低,快速驗證想法 |
| 小規模上線 | AI Studio Tier 1 + 重試機制 | 平衡成本和穩定性 |
| 生產環境 | Vertex AI 或 API易平臺 | SLA 保障,企業級支持 |
| 關鍵業務 | 多雲備份策略 (如 API易平臺) | 最高可用性,自動故障轉移 |
🎯 決策建議: 如果你不確定如何選擇,建議通過 API易 apiyi.com 平臺進行 A/B 測試。該平臺支持在相同請求下對比 Nano Banana Pro (AI Studio)、Nano Banana Pro (Vertex AI)、DALL-E 3 等模型的實際表現,幫助你基於真實數據做出決策。
總結:理性看待 Nano Banana Pro 的算力挑戰
Nano Banana Pro 的穩定性問題不是孤立事件,而是整個 AI 行業面臨的 算力供需矛盾 的縮影:
核心矛盾:
- 需求側: 生成式 AI 應用爆發式增長,特別是圖像生成領域
- 供給側: 芯片產能爬坡緩慢,數據中心建設週期長 (12-18 個月)
- 經濟模型: 免費層策略不可持續,但付費轉化率低
三大技術真相:
-
TPU 自研 ≠ 無限算力: 谷歌雖然擁有 TPU v7 這樣的先進芯片,但產能爬坡、能源供應、數據中心建設都需要時間。2026 年是關鍵轉折點。
-
AI Studio vs Vertex AI 的本質: 兩者不是簡單的"免費版"和"付費版"關係,而是 不同資源調度優先級 的體現。Vertex AI 的企業級 SLA 背後,是獨立的算力預留機制。
-
供不應求將長期存在: 隨着 Gemini 3.0、GPT-5 等新一代模型的發佈,算力需求會持續增長。短期內 (2026-2027 年),供需緊張狀態不會根本改變。
實用建議:
- 短期: 採用重試機制、請求間隔控制等工程手段緩解問題
- 中期: 評估升級到 Vertex AI 或多雲平臺的 ROI
- 長期: 關注 2026 年中期谷歌算力擴容進展,適時調整策略
對於企業級應用,我們強烈建議採用 多雲備份策略,避免單一供應商的容量風險。通過 API易 apiyi.com 這樣的統一平臺,你可以在不增加代碼複雜度的前提下,獲得跨雲調度、自動故障轉移和成本優化能力。
最後的思考: Nano Banana Pro 的挑戰提醒我們,AI 應用的穩定性不僅取決於模型能力,更依賴於底層基礎設施的成熟度。在這個算力爲王的時代,架構設計的健壯性和供應商多元化 正在成爲產品競爭力的關鍵。
相關閱讀:
- Nano Banana Pro API 使用指南
- Google TPU v7 架構深度解析
- 如何選擇 AI 圖像生成 API:Nano Banana Pro vs DALL-E 3 vs Stable Diffusion
- 生產環境 AI API 調用的 10 個最佳實踐