很多人第一次用 ChatGPT 網頁版會有個錯覺:輸入一份 PDF 或一句話,它「啪」地一下吐出 5 張風格統一的配圖;可一旦切到 API,把 n 調到 5,得到的卻是 5 張大同小異、像抽卡一樣的隨機變體。同一個模型,爲什麼差別這麼大?
這篇文章不打算給一個標準答案,而是把我們在客戶支持中反覆遇到的這個問題拆開來聊。我們會講清楚 GPT Image 組圖生成背後的兩條完全不同的技術路徑,解釋爲什麼 n 參數做不出真正的「組圖」,以及如果你想用 API 自己實現多圖一致性,有哪些可落地的辦法。
一、GPT Image 組圖生成的兩條技術路徑
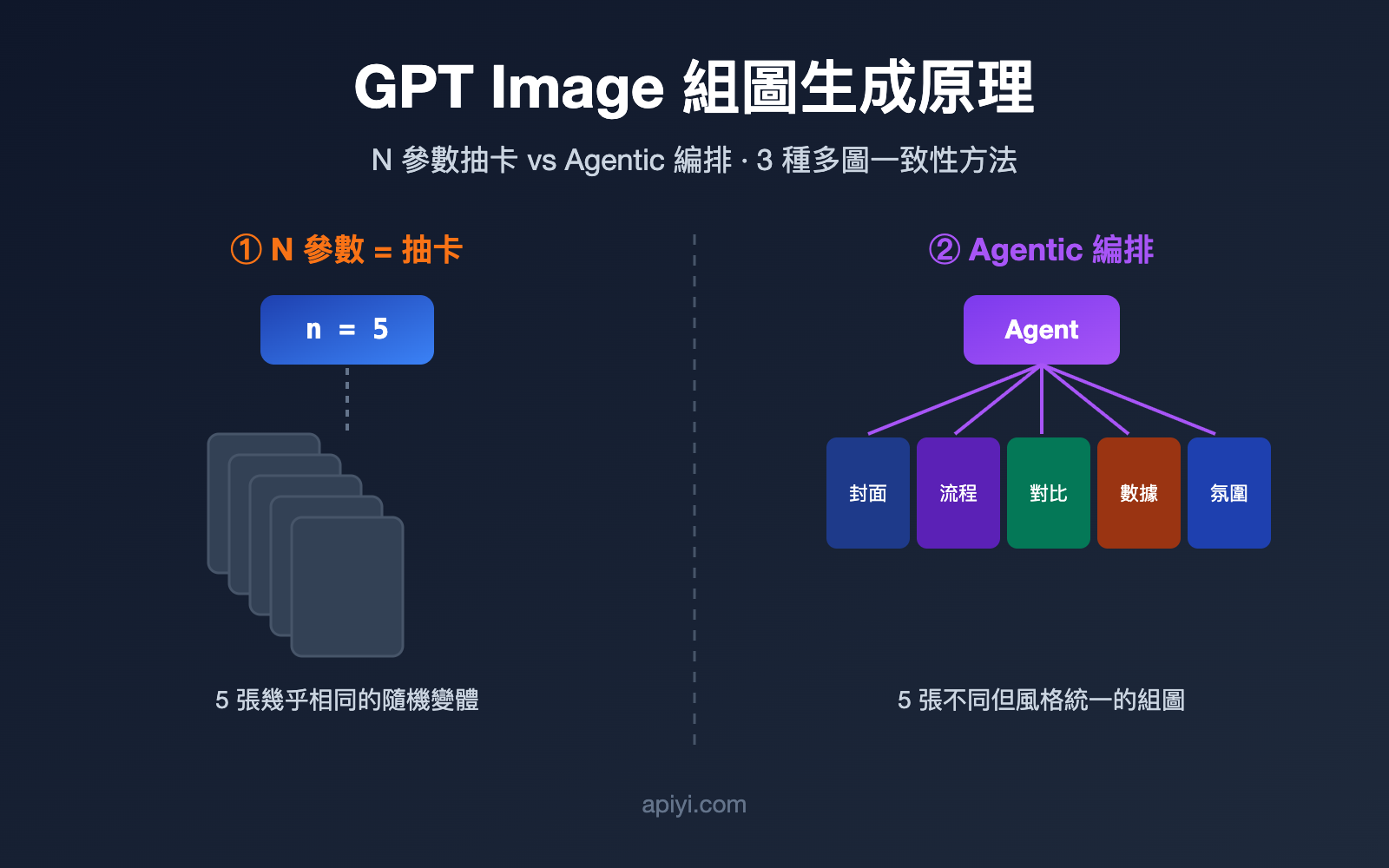
要理解這件事,先要承認一個容易被忽略的前提:「一次生成多張圖」和「生成一組有邏輯關係的圖」是兩回事。前者只是數量上的批量,後者纔是大家口中真正的「組圖」。
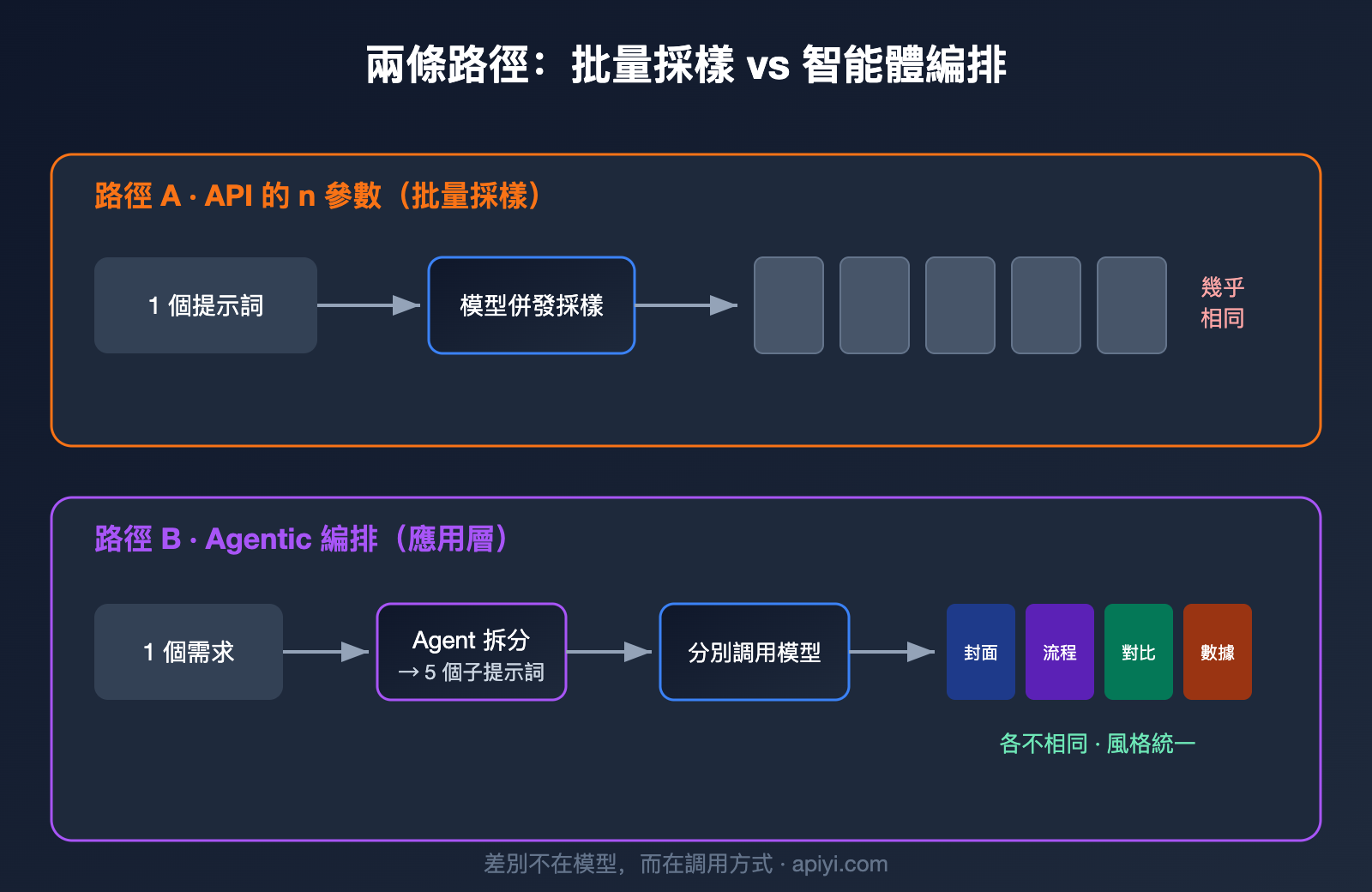
GPT Image 在工程實現上對應兩條路徑。第一條是模型層的批量採樣,也就是 API 裏的 n 參數:同一個提示詞、同一份輸入,讓模型並行採樣出多張結果。第二條是應用層的 Agentic 編排,由一個 Agent(智能體)先理解需求、把它拆成若干個子任務,再分別調用生圖能力,最後拼成一組。
下面這張表先把兩條路徑的核心差異擺清楚,後面幾節再逐條展開。
| 維度 | API 的 n 參數(批量採樣) | Agentic 編排(應用層) |
|---|---|---|
| 本質 | 同一提示詞重複隨機採樣 | 拆分需求後多次獨立生成 |
| 每張圖內容 | 幾乎相同,只有隨機差異 | 各不相同,但主題關聯 |
| 是否理解「組」 | 不理解,純併發 | 理解,有規劃邏輯 |
| 費用 | 單圖價格 × N | 多次調用費用累加 |
| 一致性來源 | 提示詞與隨機種子 | 參考圖 + 統一提示約束 |
| 典型場景 | 海選一張滿意的圖 | 系列插畫、PPT 配圖、繪本 |
簡單說,n 參數解決的是「多給我幾張備選」,而組圖需要的是「按一個主題給我一系列內容」。這也是爲什麼直接調 API 想復刻網頁版體驗時,總覺得差了點意思。如果你想同時驗證這兩種路徑的真實表現,可以在 API易 apiyi.com 上用同一套密鑰分別測試,省去多平臺來回切換的成本。
二、爲什麼 API 的 n 參數做不出真正的組圖
很多開發者的第一反應是:既然要 5 張圖,那把 n 設成 5 不就行了?實際跑一遍就會發現,出來的 5 張圖往往是「同一個東西的 5 個微小變體」,而不是「一組互相配合的圖」。
原因在於 n 參數的工作機制。它並不會改變你的提示詞,而是用同一個提示詞再跑幾遍,靠模型生成過程中的隨機採樣製造差異。OpenAI 開發者社區裏有一句很貼切的描述:這些圖來自「同一輸入下隨機採樣產生的變化」(random sampling variations)。換句話說,這就是抽卡——同樣的卡池,抽 5 次,卡面相似、稀有度隨機。
這帶來兩個直接後果。其一,你無法在一次調用裏表達「第一張畫封面、第二張畫流程、第三張畫對比」這種結構化需求,因爲提示詞只有一個。其二,費用是線性疊加的:n=5 就是按 5 張圖計費,而不是打包優惠。
下表用一個具體場景說明這個差異,假設你想爲一篇文章生成 5 張不同用途的配圖。
| 需求 | 用 n=5 的結果 | 你真正想要的 |
|---|---|---|
| 封面圖 | 5 張都是封面候選 | 1 張封面 |
| 流程圖 | 拿不到 | 1 張流程圖 |
| 對比圖 | 拿不到 | 1 張對比圖 |
| 數據圖 | 拿不到 | 1 張數據圖 |
| 配圖 | 拿不到 | 1 張氛圍圖 |
結論很清楚:n 參數適合「我要一張好圖,多給幾個候選讓我挑」,不適合「我要一套內容不同的組圖」。理解了這一點,就不會再糾結於「爲什麼 API 出不來網頁版那種效果」——因爲你用錯了工具。想低成本驗證 n 參數的抽卡特性,API易 apiyi.com 支持按調用量計費,跑幾組對比實驗花不了多少錢。
三、網頁版組圖背後的 Agentic 編排原理
那 ChatGPT 網頁版憑什麼能「一個 PDF 出 5 張圖」?答案就是上面提到的第二條路徑——Agentic 編排,而這恰好是 2026 年 4 月發佈的 GPT Image 2 / ChatGPT Images 2.0 帶來的關鍵升級。
按照 OpenAI 的官方定位,GPT Image 2 是首個把「推理能力」內置進圖像模型的版本:它在動筆之前會先研究、規劃、推理圖像結構(proactively researches, plans, and reasons),這套機制在網頁端被稱爲 Thinking 模式。所以當你丟進去一份 PDF,模型不是簡單地「讀圖」,而是先理解文檔講了什麼、需要幾張圖、每張圖分別承擔什麼角色,再逐張生成。
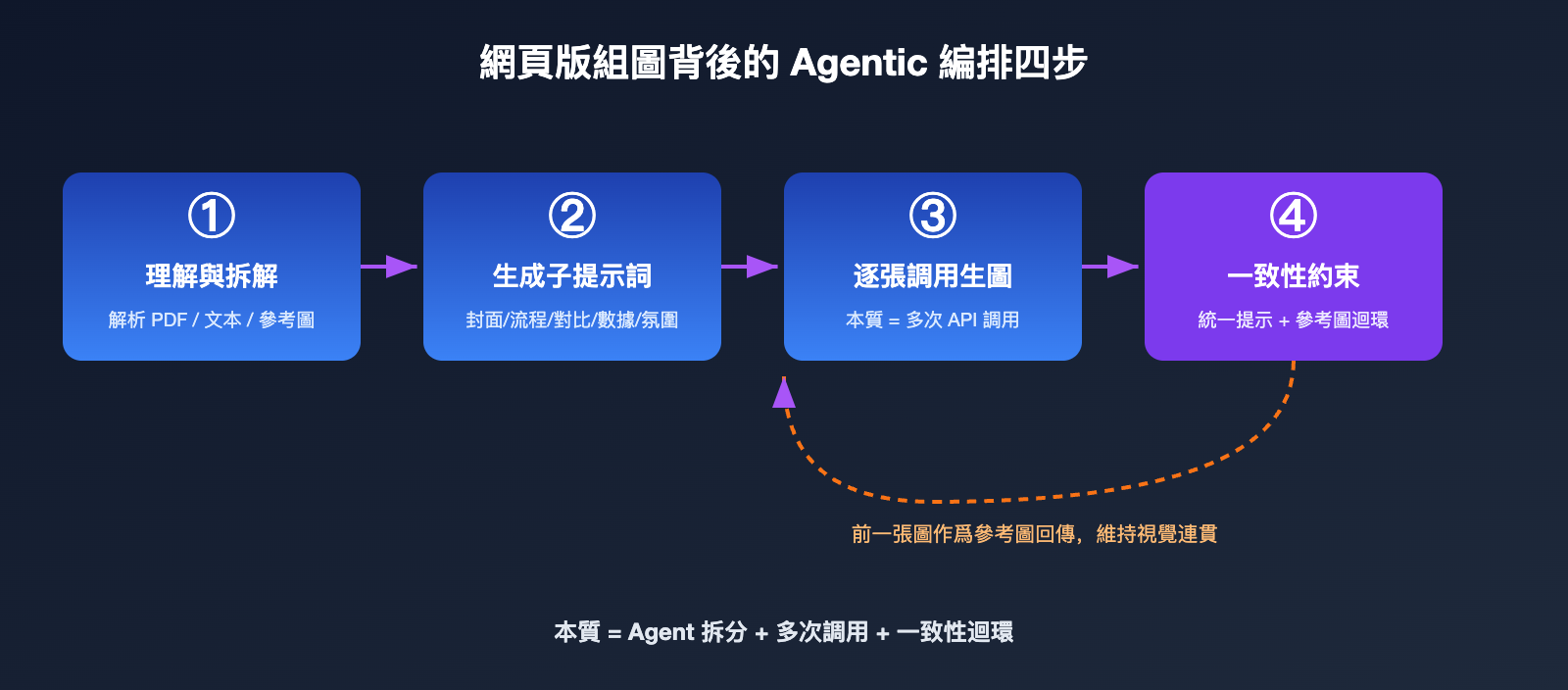
把這個過程翻譯成工程語言,大致是四步:
- 理解與拆解:Agent 解析輸入(文本、PDF、參考圖),判斷需要幾張圖、每張圖的主題。
- 生成子提示詞:爲每張圖各寫一條獨立的提示詞,例如「整體架構圖」「關鍵流程圖」「數據對比圖」。
- 逐張調用生圖:對每條子提示詞分別調用底層生圖能力,本質上是多次 API 調用。
- 一致性約束:在每條提示詞裏注入統一的風格描述,並把前面生成的圖作爲參考圖傳給後面,保證整組視覺統一。
學術界也在用類似思路。多智能體框架(如視頻生成裏的 ViMax、文生圖裏的 Maestro)會把一個大需求拆成多個細粒度的視覺子問題,並行生成、擇優選取,再把前一幀或前一張圖作爲後續生成的參考,以此維持角色和場景的連貫。GPT Image 2 的過人之處,是把這套原本要工程師手搭的編排,收進了模型自身的推理迴路裏。
這裏也藏着真正的難點:多次獨立調用天然會漂移。每一張圖都是一次新的隨機採樣,角色長相、配色、畫風都可能跑偏。這就是我們和客戶聊到的那個核心問題——「如何保持視覺一致性」,它比「如何出多張圖」難得多。下一節就專門講怎麼對付它。
四、用 API 復刻組圖:3 種實現多圖一致性的方法
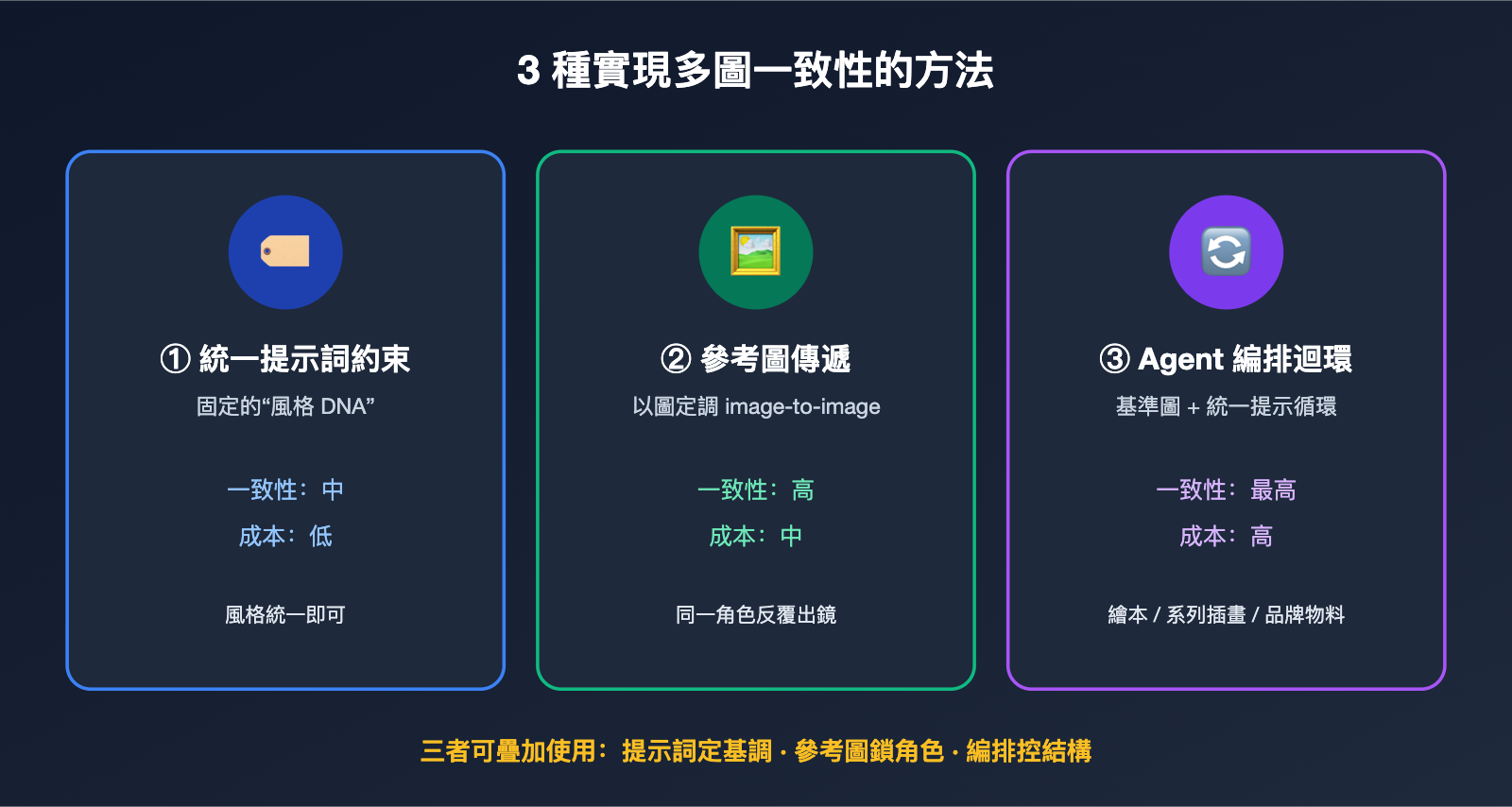
如果你不想依賴網頁版,而是要在自己的產品裏實現 GPT Image 組圖生成,那就得自己搭那套編排邏輯,核心是用工程手段把「視覺一致性」補回來。結合實踐,我們總結出三種由淺入深、可以疊加使用的方法。
方法一:統一提示詞約束(角色描述表)。 最低成本的做法,是爲整組圖寫一段固定的「風格 DNA」,每次調用都原樣附在提示詞裏。比如「統一採用扁平插畫風格、主色爲深藍與琥珀色、人物爲短髮女性工程師」。社區裏把這種固定描述叫 character bible(角色聖經),描述越具體,跨圖一致性越高。
方法二:參考圖傳遞(image-to-image)。 把已經生成滿意的第一張圖,作爲參考圖傳給後續每一次調用。GPT Image 2 在編輯/參考場景下可接收多張參考圖(官方文檔標註最多可達 16 張,具體以平臺實測爲準),這讓「以圖定調」成爲組圖一致性的主力手段。它的效果通常比純文字描述更穩,尤其是角色長相這類細節。
方法三:Agent 編排 + 參考圖迴環。 把前兩種結合進一個循環:先生成第一張作爲基準圖,後續每張都帶着基準圖 + 統一提示詞去生成,必要時把上一張也一起作爲參考。這就是網頁版 Thinking 模式在做的事,只是你把它顯式地寫進了代碼。
下面是一段精簡的編排示例,演示「先出基準圖,再帶着參考圖生成系列圖」的骨架邏輯。
from openai import OpenAI
# base_url 指向 API易,統一管理多模型密鑰
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "扁平插畫風格,主色深藍與琥珀,人物爲短髮女工程師" # 角色描述表
shots = ["封面:人物站在數據中心前", "流程:人物在白板畫架構", "總結:人物豎起大拇指"]
# 1. 先生成基準圖,鎖定整組風格
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. 後續每張都帶統一風格約束(進階可疊加 base 作爲參考圖傳入 edits 接口)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
爲了幫你快速選擇,下表對比三種方法的特點與適用場景。
| 方法 | 一致性強度 | 實現成本 | 適用場景 |
|---|---|---|---|
| 統一提示詞約束 | 中 | 低 | 風格統一即可,角色不嚴格 |
| 參考圖傳遞 | 高 | 中 | 同一角色/產品反覆出鏡 |
| Agent 編排迴環 | 最高 | 高 | 繪本、系列插畫、品牌物料 |
三種方法可以疊加:用提示詞定基調,用參考圖鎖角色,用編排控結構。我們建議先從「統一提示詞 + 參考圖」起步,跑通後再上完整編排。在 API易 apiyi.com,gpt-image-2、gpt-image-1.5 等模型共用同一個 base_url 和密鑰,方便你在不改代碼的情況下切換模型做一致性對比測試。
五、GPT Image 組圖生成的成本與模型選擇
組圖意味着多次調用,成本會被放大,所以選對模型很關鍵。目前 GPT Image 系列在生產環境常用的有幾檔,定位各有側重。
| 模型 | 定位 | 是否支持推理編排 | 適合的組圖場景 |
|---|---|---|---|
| gpt-image-2 | 旗艦,內置推理 | 是(Thinking) | 高質量系列物料、含文字海報 |
| gpt-image-1.5 | 上一代旗艦 | 部分 | 質量與成本平衡的批量出圖 |
| gpt-image-1 | 經典穩定 | 否 | 風格簡單的常規配圖 |
| gpt-image-1-mini | 輕量低價 | 否 | 大批量、對質量要求不高 |
關於費用要有個清醒認識:組圖是「按張數累加」計費的。以 1024×1024 爲例,不同質量檔位單張價格大致從幾毫美元到兩毫多美元不等(具體以官方與平臺實時報價爲準),一組 5 張圖就是 5 張的錢。如果你要批量生產上千張,成本會很可觀,提前估算很有必要。
我們的建議是:草稿階段用 mini 或低質量檔快速驗證構圖與一致性,定稿階段再用 gpt-image-2 出高質量終圖。這種「低成本試錯 + 高質量定稿」的組合,能在保證效果的同時把賬單壓下來。API易 apiyi.com 提供統一的用量看板,組圖調用花了多少、用了哪個模型一目瞭然,適合需要控制成本的團隊。
六、常見問題 FAQ
Q1:API 到底能不能一次出一組不同的圖?
不能,靠 n 參數不行。n 只是同一提示詞的隨機採樣(抽卡),內容幾乎相同。真正的組圖必須靠應用層編排:拆分需求、多次調用、再做一致性約束。
Q2:網頁版 ChatGPT 出組圖是用了什麼黑科技?
不是黑科技,是 GPT Image 2 把 Agentic 推理內置了。它在生成前會先規劃「需要幾張圖、每張畫什麼」,再逐張生成,本質仍是多次調用,只是規劃過程對用戶透明。
Q3:多圖一致性最有效的辦法是什麼?
實踐中參考圖傳遞最穩:把第一張滿意的圖作爲參考傳給後續每次調用,角色和配色的還原度明顯高於純文字描述。再疊加一段固定的風格描述表,效果更佳。你可以在 API易 apiyi.com 上用 gpt-image-2 的參考圖接口直接驗證。
Q4:組圖生成會很貴嗎?
取決於張數、分辨率和質量檔位,因爲是按張累加。建議草稿用輕量模型、定稿用旗艦模型,並通過平臺用量看板監控開銷。
Q5:用哪個模型做組圖最划算?
追求質量和文字渲染選 gpt-image-2;要平衡成本選 gpt-image-1.5;大批量低要求可用 gpt-image-1-mini。共用一套接口時,切換模型幾乎零成本。
七、總結
回到最初那個問題:同一個模型,API 像抽卡、網頁版能出組圖,差別不在模型,而在調用方式。n 參數是模型層的批量採樣,解決「多給幾張候選」;真正的 GPT Image 組圖生成是應用層的 Agentic 編排,靠拆分需求、多次調用和一致性約束拼出來。
這其中,多圖一致性始終是最難的一環。好在我們有三件趁手的工具:統一的角色描述表定基調、參考圖傳遞鎖角色、Agent 編排迴環控結構,三者疊加基本能逼近網頁版的體驗。GPT Image 2 的價值,正是把這套編排能力收進了模型的推理迴路,讓普通用戶也能享受到。
這個話題未必有標準答案,更多是一種經驗分享——希望能幫你少走一些彎路。如果你想動手驗證文中的每一種方法,API易 apiyi.com 提供 gpt-image-2、gpt-image-1.5 等模型的統一接口和用量看板,是做組圖實驗和成本對比的便捷起點,更多接入細節可參考幫助中心 help.apiyi.com。
本文爲 API易技術團隊基於客戶支持實踐整理的探討性內容,模型規格與價格請以官方及平臺實時信息爲準。