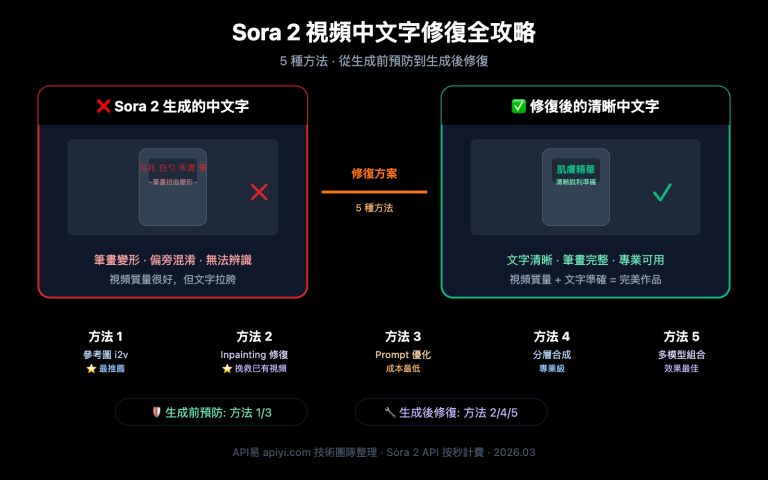
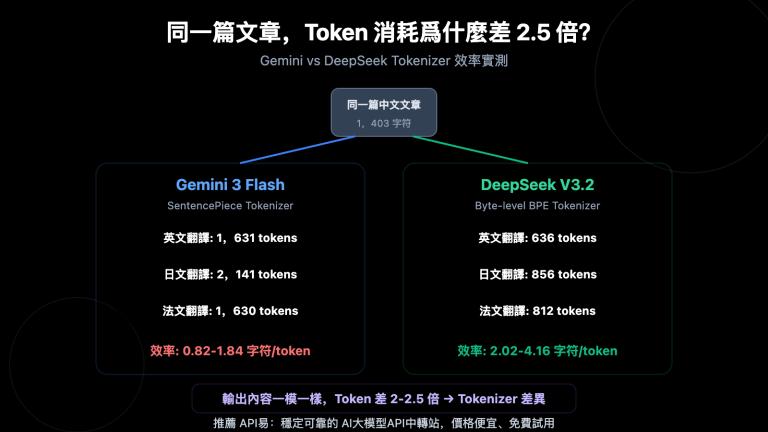
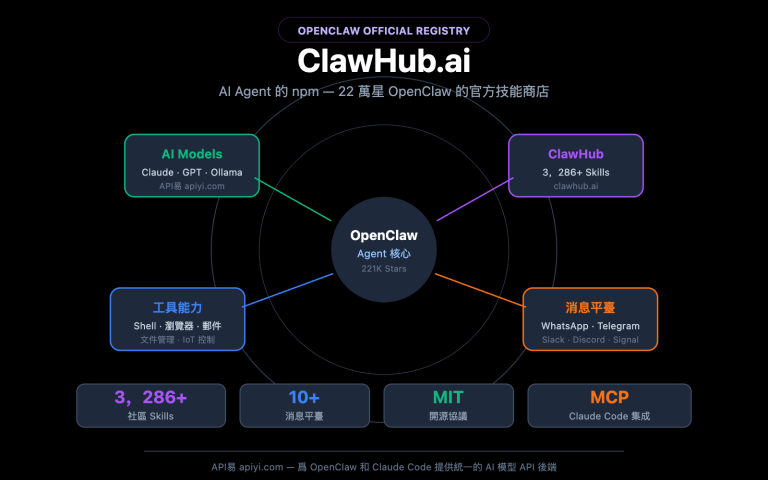
很多接入 Gemini API 做識圖業務的團隊都遇到過同一個困惑:在 gemini.google.com 網頁版上發同一張圖、用同一段提示詞,模型能精準識別細節、給出結構化答案;切到 gemini-3.5-flash API 上做同樣的事,結果卻明顯粗糙,甚至漏掉關鍵信息。這種"網頁強、API 弱"的體感差異,並不是模型本身被調弱了,而是網頁版和 API 在工程層面的差距被你看見了。
本文圍繞一個核心結論展開:網頁版 Gemini 是一套綜合 Agent,會自動做提示詞優化、多步推理、工具調用與結果校驗;API 調用的是裸模型,所見即所得。理解這個差距之後,6 個不止"調提示詞"的 API 提升技巧就能讓你的識圖效果穩定追上官網體感。

爲什麼 Gemini API 識圖效果不如網頁版:Agent 與裸模型的差距
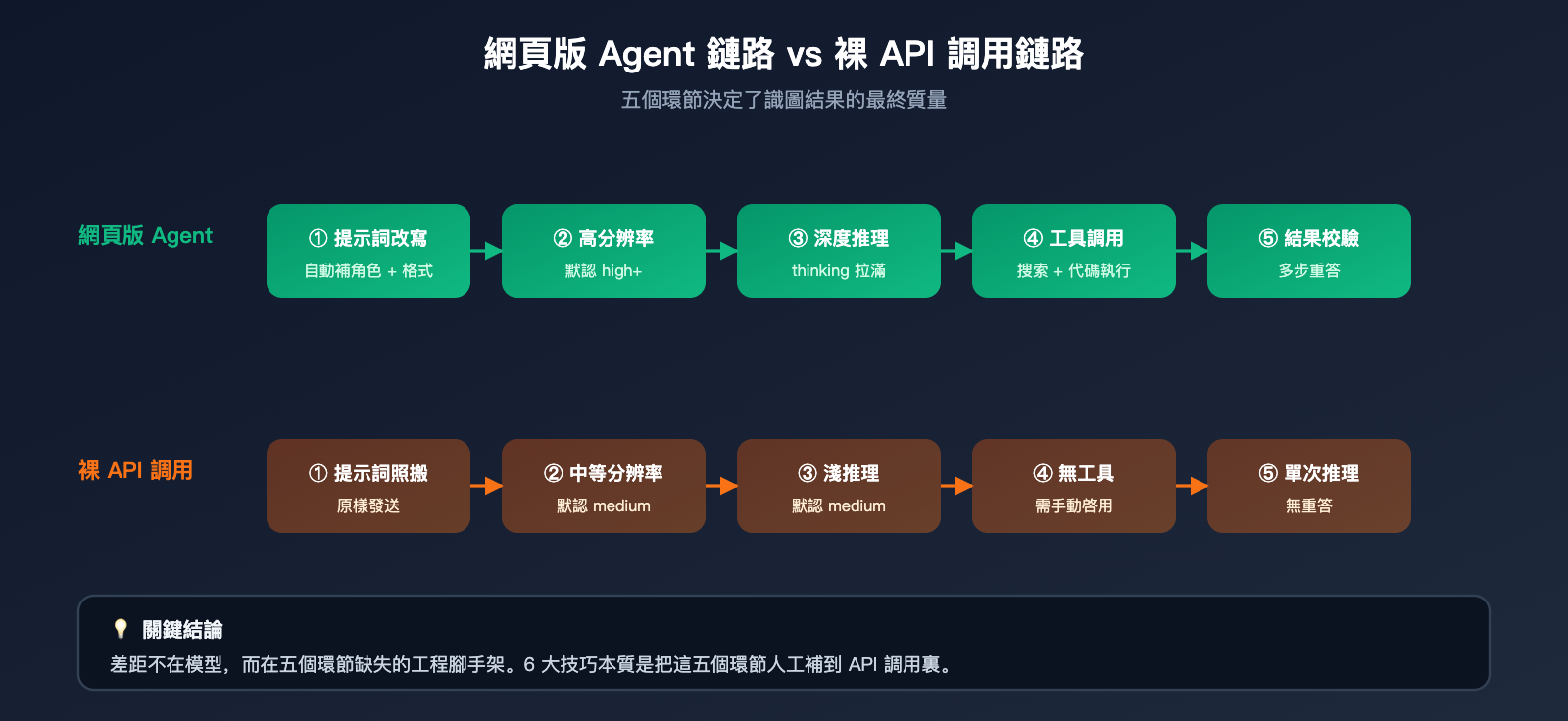
要把這個差距講清楚,先得理解 gemini.google.com 在你提交一張圖片到獲得最終回答之間,到底替你做了多少事。從 Google 公開的 Agentic Vision 文檔和我們在 API易(apiyi.com)上觀察到的官網 vs API 響應差異看,網頁版本質是一個圍繞基礎模型構建的產品級 Agent,它至少幫你完成了 5 件你沒顯式要求的事情:
- 自動改寫你的提示詞,把"識別這張圖"補充爲帶角色、任務、輸出格式的完整指令。
- 在內部用更高分辨率檔位處理圖像,確保細節不被壓縮成模糊像素。
- 默認開啓高強度推理預算(類似 thinking_level=high),讓模型有時間"想"。
- 在需要時調用代碼執行、網頁搜索等內置工具做交叉驗證,確認細節真實可信。
- 對輸出結果做格式化與"重答"判斷,遇到模糊回答會再問一遍模型。
而你直接調用 API 時,這 5 件事一件也不會自動發生。換句話說,你在調一個能力完整的"模型",但失去了一整套"工程腳手架"。下表把兩種使用方式在關鍵鏈路上的差異列清楚:
| 對比維度 | gemini.google.com 網頁版 | gemini-3.5-flash API |
|---|---|---|
| 提示詞處理 | 自動改寫、補全角色與格式 | 完全照搬用戶輸入 |
| 圖像分辨率 | 默認高檔位 | 默認中等檔位,需手動調高 |
| 推理預算 | 高強度,無顯式上限 | 默認中等,可手動設 thinking_level |
| 工具調用 | 默認接入搜索、代碼執行 | 默認關閉,需顯式啓用 |
| 結果校驗 | Agent 多步驗證 | 單次推理,無校驗 |
| 計費透明度 | 包月套餐覆蓋 | 按 Token 單獨計費 |
我們建議在 API易(apiyi.com)這種聚合網關上同時跑一份相同的圖像與提示詞,對比 gemini-3.5-flash API、Claude Opus、GPT-5.5 三家的識圖結果,可以快速判斷當前任務到底是被模型能力卡住,還是被工程鏈路卡住。
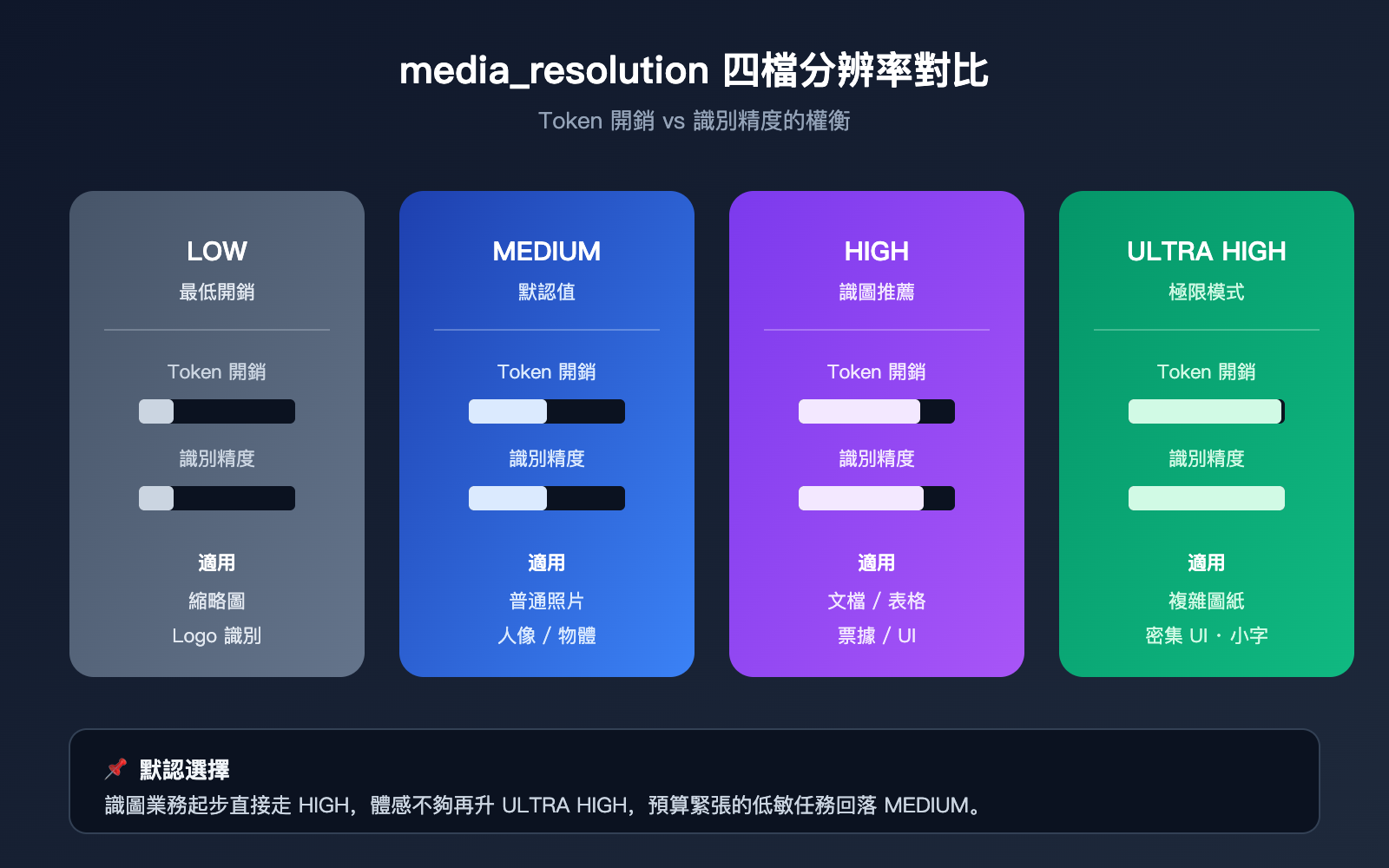
Gemini API 識圖技巧一:拉高 media_resolution 參數
Gemini 3 系列開始引入 media_resolution 參數,它直接控制 API 爲圖像分配多少 Token 來"看"。這個參數有 low、medium、high、ultra high 四檔,默認通常是 medium。對識別小字、票據、電路圖、UI 截圖這類細節密集的圖像,medium 往往不夠,模型會把圖像壓縮到一個粗糙的特徵圖,導致細節丟失。
下表給出四檔的實際差異,便於你按任務類型選擇:
| 分辨率檔位 | Token 開銷 | 適用場景 | 典型問題 |
|---|---|---|---|
| low | 最低 | 縮略圖、Logo 識別 | 小字幾乎全丟 |
| medium(默認) | 中等 | 普通照片、人像 | 細節模糊 |
| high | 較高 | 文檔、表格、票據 | 信息基本可讀 |
| ultra high | 最高 | 複雜圖紙、密集 UI | 接近官網識別 |
對識圖業務來說,把這個參數從 medium 調到 high 通常就能立刻把識別精度提一個檔位。如果你的預算允許,且任務確實涉及小字、密集表格,直接走 ultra high 也是合理選擇。
# 通過 API易調用 gemini-3.5-flash,顯式指定 high 媒體分辨率
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "提取圖中所有可見文字並按表格輸出"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
在 API易(apiyi.com)側調用時,參數透傳到底層,不會被網關二次包裝,你可以放心按官方文檔傳值。
Gemini API 識圖技巧二:顯式開啓 thinking_level=high
Gemini 3.5 Flash 引入了 thinking_level 參數,控制模型在產出答案之前的內部推理深度。識圖任務裏,"想得夠久"和"想得夠仔細"往往就是看清細節和看錯的差距。API 默認檔位偏向速度而非質量,識圖業務建議主動設爲 high,讓模型像網頁版那樣有充足時間做空間推理與計數。
| thinking_level | 推薦場景 | 體感差異 |
|---|---|---|
| low | 極簡對話、風格判斷 | 速度快,識別粗糙 |
| medium | 普通問答 | 平均水平 |
| high(識圖推薦) | 文檔、票據、計數、空間推理 | 接近官網體感 |
官方文檔同時強調了一個反直覺的點:用了 thinking_level=high 之後,反而要把提示詞寫得更直接、更簡潔,避免一堆"請你一步步推理、請你考慮各種情況"的舊式 chain-of-thought 套路。這些套路是給老模型補能力的,對 Gemini 3 系列容易讓它"過度分析"。
🎯 參數選型建議:把
media_resolution=HIGH與thinking_level=high作爲識圖任務的默認組合,寫進 API易(apiyi.com)側調用模板。後續根據業務體感再向 ultra high 或 low 兩端微調,避免在每個請求裏反覆試參數。
Gemini API 識圖技巧三:把指令寫進 system_instruction 而非 user prompt
API 上的另一個常見誤區是把所有內容塞進 user prompt:角色設定、任務說明、輸出格式、用戶提問全部混在一段文本里。這種寫法等於讓模型每次都重新讀一遍上下文,而網頁版的"系統提示詞"是緩存複用的。
正確的做法是把"你的穩定指令"放進 system_instruction:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"你是一名嚴謹的圖像分析助手。"
"回答時只引用圖像中明確可見的細節,不要憑空推斷。"
"輸出結構化的 JSON,字段固定爲 entities/attributes/text。"
)
)
這樣寫帶來兩個收益:模型每次都按統一規則回答,結果更穩定;System Prompt Caching 啓用後輸入成本可下降 10 倍,對長期跑批的識圖業務非常有價值。在 API易(apiyi.com)後臺,可以按模型 ID 單獨看到緩存命中率,方便觀察優化效果。
Gemini API 識圖技巧四:啓用 code execution 讓模型 "放大看圖"
Google 在 Gemini 3 Flash 的 Agentic Vision 公告裏給出過一個明確數據:在原生模型基礎上啓用代碼執行工具,識圖類任務平均能再拿 5%~10% 的質量提升。原理是模型可以在內部生成 Python 代碼,對圖片做裁剪、放大、旋轉、像素讀取等操作,再把處理後的子圖重新餵給自己分析。這正是網頁版默認在做的事。
API 默認不會開啓代碼執行,需要顯式聲明:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "數出圖中所有紅色按鈕的數量並列出位置"],
config=config
)
對計數、空間推理、密集 UI 解析這種官方公認的"代碼執行加分項"任務,這是性價比最高的一檔優化。我們在 API易(apiyi.com)上觀察到,啓用代碼執行後整體延遲會有所上升,建議在異步業務裏默認開啓,在同步業務裏按需開啓。
Gemini API 識圖技巧五:大圖用 File API 而非 base64 內聯
對於體積超過幾 MB 的圖像,很多團隊直接用 base64 把圖嵌進請求體。這種做法在小圖上沒問題,但當總請求大小超過 20MB 時就會觸發 Gemini 的限制,部分圖像會被靜默壓縮,識別質量自然下降。
官方給出的判定邊界很清晰:
| 圖像大小 | 推薦傳輸方式 | 原因 |
|---|---|---|
| 小於 5MB | base64 內聯 | 請求輕量、調用簡單 |
| 5~20MB | File API 上傳 | 避免請求體積膨脹 |
| 大於 20MB | File API 必須 | base64 編碼會破壞請求 |
| 跨多次複用 | File API 推薦 | 一次上傳多次引用,省 Token |
File API 的另一好處是同一張圖可以在多個請求裏複用,省去重複上傳成本。在 API易(apiyi.com)網關後,File API 的 endpoint 走的是同一組憑證,無需爲圖片上傳單獨開 Google Cloud 賬號。
Gemini API 識圖技巧六:自己搭一條 Agent 鏈路做多步驗證
走完前 5 個技巧後,你的單次 API 調用已經接近官網體感了。但網頁版還有一招殺手鐧:多步驗證。它會在生成回答後用第二次推理校驗關鍵事實,遇到不確定的回答會再做一次"重答"。這個能力 API 上沒有現成開關,需要你自己搭一條簡單的 Agent 鏈路。
一個最小可用的兩步鏈路是:
- 第一次調用:讓 gemini-3.5-flash 生成結構化識別結果(JSON 輸出)。
- 第二次調用:把第一次的結果與原圖同時回灌,問模型"基於這張圖,下列結論是否每條都成立?"
如果第二次調用挑出任何"不成立"的字段,再觸發第三次"重答"。這套鏈路在 API易(apiyi.com)上可以直接用同一份 base_url 與 API Key 串起來,不需要額外服務。對識別準確率要求高的業務(合同識別、醫療影像輔助標註、安全合規審查)來說,多步驗證是把準確率從 90% 推到 98% 的關鍵一步。
| 任務類型 | 建議鏈路 | 單步參數 |
|---|---|---|
| 通用識圖問答 | 單步 | high + thinking_high |
| 文檔抽取 | 單步 + JSON 校驗 | ultra high + thinking_high |
| 複雜計數 | 兩步 + code execution | high + thinking_high + tools |
| 高準確率業務 | 三步鏈路(識別 → 校驗 → 重答) | ultra high + thinking_high + tools |
實戰參數模板:把 6 個技巧串成一次可複用調用
爲了方便你直接套用,下面給一份"識圖任務默認模板",已經把前面 6 個技巧串到位,適合大多數業務的起點:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"你是嚴謹的圖像分析助手。僅引用圖像中明確可見的內容,"
"不要憑空推斷。輸出嚴格 JSON,字段 entities/attributes/text。"
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "按 SYSTEM 要求識別這張圖"],
config=config
)
print(resp.text)
實際部署時建議在 API易(apiyi.com)側把模板抽成統一的 SDK 調用層,業務方只傳圖與提問,參數由網關統一注入,避免每個業務都重新踩一遍坑。

常見問題 FAQ:Gemini API 識圖與網頁版差距答疑
Q1:把這些參數都打開後,API 還會比網頁版差嗎?
絕大多數業務能追平官網,但少數高難度任務(極小字、低光照、特殊藝術風格圖)仍可能略差,因爲網頁版還會調用未公開的內部增強 Pipeline。對這類場景,可以在 API易(apiyi.com)上用其他廠商的視覺模型做橫向對照,找到最適合的工作模型。
Q2:thinking_level=high 會讓成本翻倍嗎?
會增加內部推理 Token 用量,但只對輸出階段產生影響,且識圖業務的整體成本里圖像 Token 通常更佔大頭。把 thinking 調到 high 帶來的準確率提升遠大於增加的成本,特別是在替代人工複覈的業務裏。
Q3:base_url 怎麼改?我用的是 Google 官方 SDK。
google-genai SDK 支持通過 http_options={"base_url": "https://api.apiyi.com"} 把請求轉到 API易(apiyi.com)網關。Key 用 API易後臺生成的即可,不需要單獨的 Google Cloud 項目。
Q4:可以只優化提示詞解決問題嗎?
只調提示詞的天花板很明顯,無法覆蓋分辨率、推理深度、工具調用這些"模型外"的能力。本文 6 個技巧裏只有第三條與提示詞相關,其餘 5 條都是工程層的槓桿。
Q5:網頁版能識別到的"圖片中文水印",API 總是漏掉怎麼辦?
水印類細節往往依賴高分辨率與代碼執行裁剪的組合。把 media_resolution 調到 ultra high,並啓用 code execution,再用兩步驗證鏈路檢查,通常能穩定識別。
總結:把網頁版的工程能力補到 API 調用裏
回到最初的問題:爲什麼 Gemini API 識圖效果不如網頁版?答案不是模型變弱了,而是網頁版自帶的工程腳手架太厚。當你直接調 gemini-3.5-flash API 時,提示詞改寫、分辨率檔位、推理預算、工具調用、結果校驗全都需要你自己顯式補齊。理解這一點之後,6 個技巧的本質就是"把網頁版替你做的事,搬到你自己的 API 調用鏈裏"。
實操路徑很清晰:先把 media_resolution 與 thinking_level 拉滿,再把指令搬進 system_instruction 並開啓緩存,對複雜識圖任務啓用 code execution,大圖統一走 File API,最後用兩到三步 Agent 鏈路兜住高準確率業務。這套組合拳跑下來,再回到 API易(apiyi.com)後臺對比命中率與延遲,多數團隊都能把識圖業務的"網頁 vs API"差距壓縮到肉眼幾乎看不出來的程度。
📌 作者署名:本文由 API易(apiyi.com)技術團隊整理,更多 Gemini、Claude、GPT 系列模型的接入實戰與調參指南,請關注 API易幫助中心。