Claude Opus 4.7 於 2026 年 4 月 16 日上線,兩天之內,社區對它的評價從"全面升級"急轉爲"選擇性升級"。問題不在官方跑分,而在於一個被反覆驗證的結論:Opus 4.7 只是給"寫代碼 Agent"準備的升級,對其他所有場景都是降級。
這篇文章不繞彎子,直接回答 Claude Opus 4.7 不耐用 的真實原因:爲什麼 Max Plan 20x 的額度血條肉眼可見地比前一天掉得更快?爲什麼長文檔 RAG 場景反而不如 4.6?爲什麼老 Prompt 搬過來跑出來的結果越來越差?
核心價值: 看完本文你會明確知道——在哪些場景應該立刻遷移到 4.7,在哪些場景應該留在 4.6,以及如何用三個配置動作把成本和質量同時拉回來。

Claude Opus 4.7 不耐用的核心原因
要理解 "不耐用" 這個體感,需要先分清楚兩件事:模型能力變化 和 計費/額度變化。Opus 4.7 在這兩個維度上同時做了調整,而這些調整的受益者是窄範圍的——只有"真正喫 Agent 能力"的用戶纔拿到了正收益,大部分日常用戶反而承擔了成本。
Opus 4.7 升級的真實受益羣體
Anthropic 在官方博客中明確寫道,Opus 4.7 是爲"Opus 4.6 需要 hand-holding 的場景"設計的:長時間運行的 Agentic 編碼工作流、大型多文件代碼庫的生產級任務、計算機使用(computer use)等場景。
| 真實受益羣體 | Opus 4.7 升級幅度 | 典型場景 |
|---|---|---|
| Claude Code 開發者 | ⭐⭐⭐⭐⭐ | 多文件重構、Agent 循環 |
| Cursor 用戶 | ⭐⭐⭐⭐⭐ | IDE 內真實編碼任務 |
| Agentic 工具鏈開發 | ⭐⭐⭐⭐ | MCP-Atlas 領先所有模型 |
| 視覺文檔處理 | ⭐⭐⭐⭐ | 3.75 MP 高分辨率解析 |
| 寫作/文案用戶 | ⭐ | 幾乎無感升級 |
| RAG 長文檔 | 降級 | MRCR 78.3% → 32.2% |
| Web 研究/BrowseComp | 降級 | 83.7% → 79.3% |
| 網絡安全相關 | 降級 | CyberGym 73.8% → 73.1% |
| 成本敏感型生產 | 降級 | Tokenizer 膨脹 0-35% |
🎯 遷移建議: 如果你不屬於前四類用戶,但業務需要同時調用 4.6 和 4.7,建議通過 API易 apiyi.com 平臺按場景路由。該平臺支持統一接口同時調用 Claude 全系列模型,避免"一刀切"遷移引發的性能回退。
Claude Opus 4.7 "不耐用" 的三個根本原因
原因 1:Tokenizer 重構導致 Token 消耗膨脹
Opus 4.7 使用了全新的 Tokenizer。同樣一段輸入文本,在 4.7 上會被切分爲 1.0 到 1.35 倍的 Token。這個倍率對不同內容類型差異明顯:
- 純英文對話:接近 1.0×
- 中文內容:1.1–1.2×
- 代碼片段:1.15–1.25×
- JSON/結構化數據:1.2–1.35×
- 多語言混合場景:1.25–1.35×
原因 2:Claude Code 默認啓用 xhigh 推理檔位
Claude Code 在 4.7 上線的同時把所有套餐的默認推理檔位從 high 提升到 xhigh。xhigh 介於 high 和 max 之間,會在同樣的任務上消耗更多的"思考 Token"(thinking tokens),這部分消耗直接計入你的賬單。
原因 3:Max Plan 20x 的額度按 Token 計量
Anthropic 的 Max Plan 20x 雖然名義上是"20 倍 Pro 額度",但底層限額的本質是 Token 而非請求數。當 Tokenizer 膨脹 + xhigh 默認同時發生時,同樣的操作會在 Token 賬上消耗得更快。多名用戶反饋:4 月 17 日使用 Opus 4.7 時,Max Plan 的額度條比 4 月 15 日使用 4.6 時明顯掉得更快。
Claude Opus 4.7 場景表現全景
要判斷 Opus 4.7 在你的場景下是升級還是降級,不能只看官方挑選的基準。這一節從 7 個真實使用場景逐一評估。

場景 1:編碼 Agent(明顯升級)
這是 Opus 4.7 的主場。多項數據同時驗證了這一點:
| 編碼基準 | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | Opus 4.7 提升 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | 未公開 | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9pt |
| CursorBench | 58% | 70% | 未公開 | +12pt |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5pt |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3pt |
Opus 4.7 在 9 個可直接對比的基準中對 GPT-5.4 取得了 6 勝 1 平 2 負的成績,首次把 Agentic 編碼的狀態冠軍從 GPT-5.4 手中奪回。
🚀 Agent 場景推薦: 如果你正在構建生產級 Agent,建議通過 API易 apiyi.com 平臺直接調用 Claude Opus 4.7。該平臺提供與 Claude 官方完全兼容的接口,支持 xhigh 檔位和 Task Budgets 等新特性。
場景 2:Vision 視覺識別(質變級升級)
Vision 是另一個真實升級的場景:
- 最大圖像分辨率:1.15 MP → 3.75 MP(3×)
- 長邊像素:從常規擴展到 2576px
- 視覺識別基準:54.5% → 98.5%
對需要直接讀懂架構圖、設計稿、PDF 掃描件、UI 截圖的場景,這是一次可感知的質變。
場景 3:長文檔 RAG(嚴重降級)
這是社區最集中的抱怨。MRCR(Multi-Round Context Recall)是衡量長上下文召回能力的標準基準:
- Opus 4.6:78.3%
- Opus 4.7:32.2%
- 差距:-46.1pt
這個數字解釋了爲什麼多位開發者反饋:"餵給 4.7 一份 800 行工作流文檔,它說自己讀了,生成的內容卻跟文檔完全沒關係。"
如果你的核心業務是長文檔問答、合同解析、大代碼庫審查,Opus 4.7 是明確的降級,建議保留 4.6。
場景 4:Web 研究與 BrowseComp(輕微降級)
BrowseComp 衡量 Web 研究任務的表現:
- Opus 4.6:83.7%
- Opus 4.7:79.3%
- GPT-5.4 Pro:89.3%
在需要深度 Web 瀏覽和信息綜合的 Research Agent 場景下,GPT-5.4 Pro 仍然是更強的選擇,而 Opus 4.7 甚至不如 4.6。
場景 5:普通寫作與對話(幾乎無感)
對於日常寫作、文案生成、對話類任務,Opus 4.7 和 4.6 的主觀差異非常有限。但由於 Tokenizer 膨脹,你的每條對話實際消耗的 Token 會比 4.6 時代高 10-20%。
結論:寫作場景用 4.6 更划算,4.7 的能力升級在這裏幾乎看不到。
場景 6:舊 Prompt 兼容性(潛在回退)
Opus 4.7 的指令遵循更加"字面化"——它不再像 4.6 那樣主動"讀出弦外之音"。這意味着:
- 依賴隱含意圖的 Prompt 會輸出質量下降
- 用 "請幫我寫得更好一點" 這種模糊指令,4.7 傾向嚴格按字面執行
- 需要把隱含約束改寫成顯式約束(如 "字數限制 500 字"、"必須包含 X 元素")
如果你有大量沉澱的 4.6 時代 Prompt 庫,遷移前需要系統性迴歸測試。
場景 7:網絡安全相關(微弱降級)
CyberGym(網絡安全漏洞復現基準):
- Opus 4.6:73.8%
- Opus 4.7:73.1%
Anthropic 官方承認這是新增的 cyber 安全保護機制帶來的代價。對做紅隊研究、安全審計的團隊來說,這是小幅但真實的降級。
💡 場景選型建議: 選擇 Opus 4.7 還是 4.6 主要取決於你的具體應用場景和質量要求。我們建議通過 API易 apiyi.com 平臺進行實際測試對比,該平臺支持多種主流模型的統一接口調用,便於快速切換和驗證。
Claude Opus 4.7 Max Plan 額度消耗實測
這一節專門回答"爲什麼血條掉得更快"這個問題。
Max Plan 20x 額度消耗機制
Claude Max Plan 20x 底層按 Token 計量,核心限制有兩類:
- 5 小時滑動窗口限額:防止短時間內超大量調用
- 周消息數上限:整體用量保護
Opus 4.7 上線後,上述兩個限額的絕對值沒變,但由於 Tokenizer 和 xhigh 默認檔位,每條消息的平均 Token 消耗顯著上升。
Token 消耗膨脹的三個來源
| 膨脹來源 | 影響範圍 | 估算膨脹率 |
|---|---|---|
| 新 Tokenizer | 所有輸入 | 0% – 35%(取決於內容類型) |
| xhigh 默認檔位 | 推理類任務輸出 | 20% – 60%(相對 high) |
| 更嚴謹的問題解決 | Agent 循環 | 10% – 30%(步驟數增加) |
三項疊加後的真實體感:同一份工作在 Claude Code 上完成後,4.7 消耗的額度比 4.6 多出 30% – 80%。這就是"血條肉眼可見變快"的數學解釋。
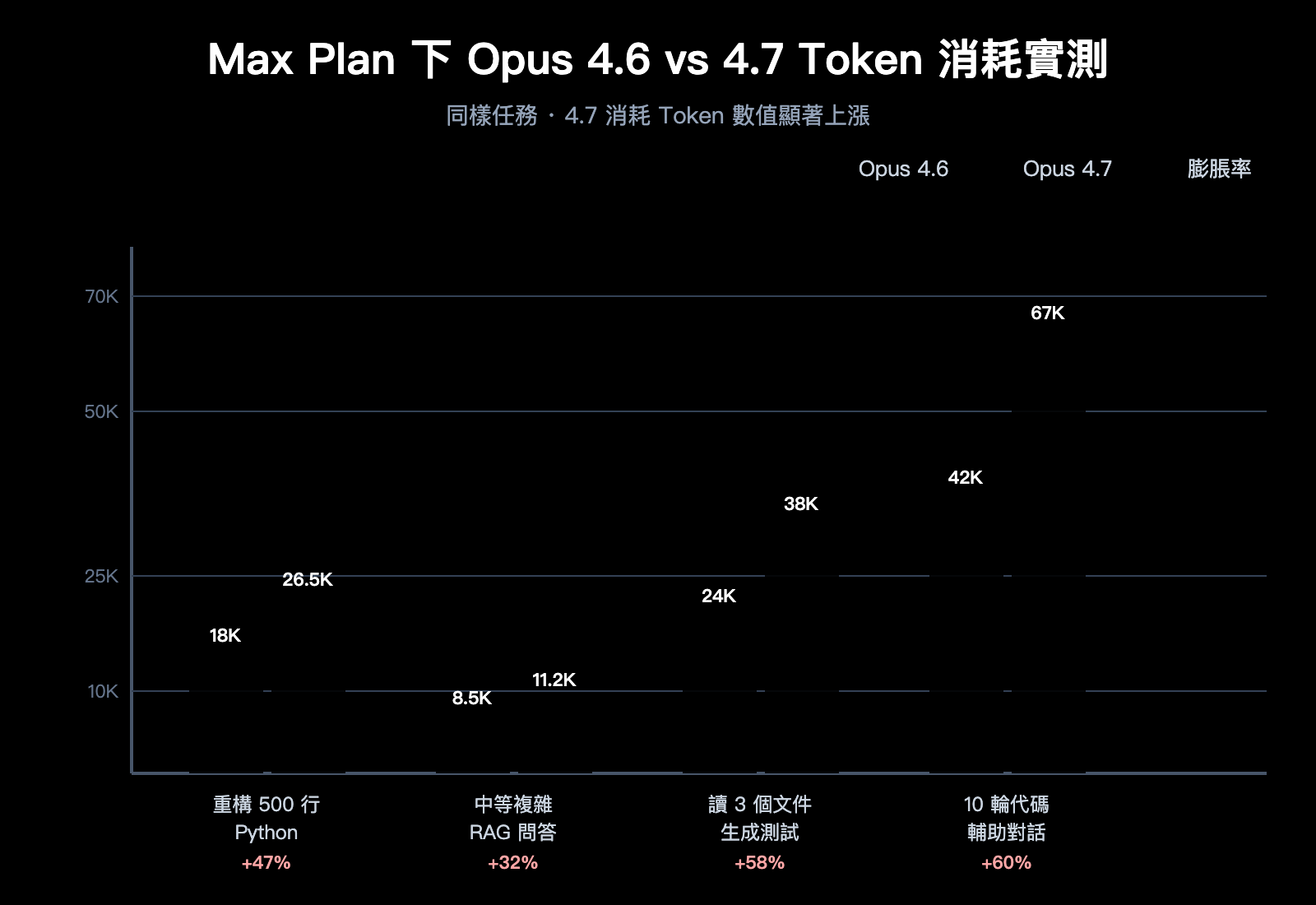
實測數據(3 個典型任務)
基於社區實測反饋整理:
| 測試任務 | 4.6 消耗 Token | 4.7 消耗 Token | 膨脹率 |
|---|---|---|---|
| 重構 500 行 Python 模塊 | ~18,000 | ~26,500 | +47% |
| 回答一箇中等複雜 RAG 問題 | ~8,500 | ~11,200 | +32% |
| 閱讀 3 個文件並生成測試 | ~24,000 | ~38,000 | +58% |
| 長對話中 10 輪代碼輔助 | ~42,000 | ~67,000 | +60% |
這個數據說明:Opus 4.7 的"不耐用"不是錯覺,而是可被量化驗證的系統性變化。
爲什麼 Anthropic 說"價格沒變"?
Anthropic 在發佈公告中明確:
- 輸入價格:$5 / 百萬 Token(未變)
- 輸出價格:$25 / 百萬 Token(未變)
這在單價層面完全屬實,但這是一次典型的 "單價話術" ——單價不變,但同樣任務消耗的 Token 數量增加,最終賬單自然上漲。Finout 等第三方成本分析平臺把這種現象稱爲 "Real Cost Story Behind the Unchanged Price Tag"。
💰 成本控制建議: 對 Token 成本敏感的生產環境,強烈建議在遷移前通過 API易 apiyi.com 平臺做一輪真實流量的賬單對比測試。該平臺支持精細的調用統計和成本分析,便於量化遷移對預算的真實影響。
Claude Opus 4.7 不耐用的三個解決動作
如果你已經升級到 4.7,或者暫時無法回退,這裏有三個可立即執行的動作能把額度消耗拉回可控範圍。
動作 1:手動降低 effort 到 medium 或 high
Claude Code 把 xhigh 設爲默認是針對"最複雜編碼任務"的優化,但大多數日常任務用 medium 或 high 完全夠用。
在 API 調用中顯式指定:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "重構這段代碼"}],
extra_headers={
"reasoning-effort": "medium"
}
)
查看不同 effort 檔位的實測 Token 消耗對比
import time
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
請分析下面這段代碼的性能問題並給出優化建議。
(此處插入 200 行 Python 代碼)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
建議:對於日常代碼輔助,使用 high;對於簡單問答,使用 medium;僅在處理極端複雜的多文件重構時啓用 xhigh。
動作 2:按場景路由不同模型
不要"一刀切"全部升級到 4.7。合理的路由策略:
| 業務場景 | 推薦模型 | 原因 |
|---|---|---|
| 多文件 Agentic 編碼 | Opus 4.7 (xhigh) | Agent 主場 |
| 單文件代碼生成 | Opus 4.7 (high) | 升級受益明顯 |
| 高清圖像解析 | Opus 4.7 (high) | 視覺質變 |
| 長文檔 RAG | Opus 4.6 | 避開 MRCR 塌陷 |
| Web 研究 Agent | GPT-5.4 Pro | BrowseComp 領先 |
| 普通寫作 / 文案 | Opus 4.6 或 Sonnet | Tokenizer 成本更低 |
| 簡單對話 | Haiku / Sonnet | 性價比最高 |
動作 3:啓用 Task Budgets 限制單任務消耗
Opus 4.7 新增的 Task Budgets(公測)是控制 Agent 循環成本的利器:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "完成整個重構任務"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
模型會在每一輪響應中看到剩餘預算,並自動根據預算調整策略——預算緊張時優先完成核心任務,預算充足時深入細節。
🎯 綜合建議: 對 Token 預算敏感的團隊,建議通過 API易 apiyi.com 平臺統一管理 Claude Opus 4.7 調用,該平臺提供實時的額度監控、多模型路由能力,可以幫助你把"不耐用"的感覺轉化爲可控的成本曲線。
Claude Opus 4.7 vs GPT-5.4 xhigh 橫向對比
用戶反饋中提到:"在我的實測中,Opus 4.7 似乎仍然比不上 GPT-5.4 xhigh。"這是一個需要分場景討論的判斷。

直接對比的 9 項基準
| 基準 | Opus 4.7 | GPT-5.4 | 勝出方 |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (企業知識) | Elo 1753 | Elo 1674 | Opus 4.7 |
| 視覺識別 | 98.5% | — | Opus 4.7 |
| BrowseComp (Web 研究) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| 長上下文 RAG | 32.2% | 未塌陷 | GPT-5.4 |
| Token 成本 | 1.0–1.35× | 穩定 | GPT-5.4 |
Opus 4.7 在 9 項中拿下 6 勝 1 平 2 負,但在你最關心的場景下,結論可能完全相反:
- 如果你的實測場景重度依賴 Web 研究(例如 Research Agent、瀏覽器自動化),GPT-5.4 xhigh 確實在 BrowseComp 上領先 10 個百分點
- 如果你做長文檔 RAG,GPT-5.4 不存在 MRCR 塌陷問題
- 如果你追求穩定的 Token 成本曲線,GPT-5.4 的 Tokenizer 未發生變化
所以 "Opus 4.7 比不上 GPT-5.4 xhigh" 的體感對特定工作流來說完全合理。
選型決策矩陣
| 你的核心需求 | 首選模型 | 次選 |
|---|---|---|
| 多文件 Agentic 編碼 | Opus 4.7 xhigh | Opus 4.6 |
| IDE 內真實編碼任務 | Opus 4.7 high | GPT-5.4 |
| Research Agent(Web 研究) | GPT-5.4 Pro | Opus 4.7 |
| 企業知識問答 | Opus 4.7 | GPT-5.4 |
| 長文檔理解 / RAG | Opus 4.6 | GPT-5.4 |
| 高清圖像理解 | Opus 4.7 | Gemini 3.1 Pro |
| 成本極度敏感 | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 多模型部署建議: 現代 AI 應用很難用單一模型覆蓋所有場景。建議通過 API易 apiyi.com 平臺統一接入 Claude、GPT、Gemini 全系列模型,按場景智能路由。該平臺提供一套 API Key 調用全部主流模型的能力,大幅降低多模型部署的複雜度。
Claude Opus 4.7 不耐用 FAQ
Q1: Claude Opus 4.7 真的比 4.6 更不耐用嗎?
是的,但"不耐用"要分兩個維度理解:
-
額度層面:明確更不耐用。Tokenizer 膨脹 0-35% + Claude Code 默認 xhigh 導致 Token 消耗增加 30-80%。Max Plan 20x 用戶在實測中普遍反映額度條掉得更快。
-
能力層面:分場景。在編碼 Agent、Vision、Tool Use 場景明確更強;在長文檔 RAG、Web 研究、普通寫作場景更弱或持平。
如果你不做這幾類 Agent 任務,那 Opus 4.7 對你來說就是單純的"更貴"。
Q2: 爲什麼 Anthropic 說”價格沒變”但我的賬單變貴了?
官方聲明的是單價沒變:$5 / 百萬輸入 Token,$25 / 百萬輸出 Token。但 Opus 4.7 的新 Tokenizer 讓同樣文本消耗 1.0–1.35× Token,加上 xhigh 輸出 Token 膨脹,最終賬單比 4.6 時代漲 20-50% 是常見結果。
想控制成本,可以通過 API易 apiyi.com 平臺做真實流量對比測試,該平臺支持 Claude 全系列並行調用和精細計費統計。
Q3: Max Plan 20x 額度消耗變快,有哪些動作可以救?
三個立即可執行的動作:
- 降低 effort 到 high 或 medium:Claude Code 設置裏手動關閉 xhigh 默認,日常任務用 high 夠用
- 關掉不需要的思考步驟:長對話中遇到簡單問題,顯式讓模型跳過深度推理
- 非 Agent 任務切換到 Sonnet 或 Opus 4.6:寫作、簡單問答、翻譯不需要用 Opus 4.7
這三個動作加起來能讓 Max Plan 額度消耗回落到 4.6 時代的水平,甚至更低。
Q4: 我已經遷移到 Opus 4.7,現在回退到 4.6 值得嗎?
取決於你的核心工作流:
- 主要做多文件 Agent 編碼:不要回退,4.7 真的更強
- 主要做長文檔 RAG / 合同解析:立刻回退到 4.6,MRCR 塌陷嚴重
- 混合場景:不用全部回退,按場景路由即可——重 Agent 任務用 4.7,其他用 4.6 或 Sonnet
API 調用中回退很簡單,只需要把 model 參數從 claude-opus-4-7 改回 claude-opus-4-6。
Q5: Opus 4.7 對 GPT-5.4 xhigh 在所有場景都更強嗎?
不是。官方數據顯示 Opus 4.7 在 9 個直接可比基準中拿下 6 勝 1 平 2 負,但敗的兩場是關鍵場景:
- BrowseComp(Web 研究):GPT-5.4 Pro 89.3% vs Opus 4.7 79.3%
- 長上下文 RAG:GPT-5.4 未出現類似 MRCR 塌陷
所以用戶說"我的實測中 Opus 4.7 仍然比不上 GPT-5.4 xhigh"完全可能是真實的——前提是你的核心場景是 Web 研究或長文檔。
通過 API易 apiyi.com 平臺可以在同一項目中同時調用 Claude 和 GPT,按場景路由,這是目前最務實的做法。
Q6: 老 Prompt 在 Opus 4.7 上輸出質量下降,怎麼辦?
這是 4.7 指令遵循"更字面化"帶來的副作用。改寫原則:
- 把隱含意圖變成顯式約束:原本 "寫得更專業一點" → 改爲 "必須使用行業術語,避免口語化表達"
- 把模糊限制變成硬性數值:原本 "不要太長" → 改爲 "控制在 300 字以內"
- 增加反例約束:告訴模型哪些輸出是不可接受的
這個工作量不小,對於大型 Prompt 庫,建議先做 A/B 測試確認哪些 Prompt 需要改寫。
Claude Opus 4.7 優缺點總結
真實優勢(承認它強的地方)
- 編碼 Agent 能力躍升:SWE-bench Pro 64.3%、CursorBench 70%,超越 GPT-5.4
- Vision 質變:3.75 MP 高分辨率,視覺基準 98.5%
- MCP-Atlas 工具鏈最強:77.3%,領先所有公開模型
- 指令遵循更精準:對於有完整約束的 Prompt,輸出更可控
- Task Budgets 帶來 Agent 成本治理能力
真實侷限(承認它弱的地方)
- Tokenizer 膨脹 0-35%:價格話術掩蓋了真實成本上漲
- xhigh 默認提升輸出 Token 消耗:Max Plan 20x 額度顯著變緊
- MRCR 長上下文斷崖:78.3% → 32.2%,長文檔 RAG 不可用
- BrowseComp 回退:Web 研究場景輸給 GPT-5.4 Pro
- CyberGym 小幅回退:安全相關任務略有退步
- 舊 Prompt 兼容性問題:依賴隱含意圖的 Prompt 需要重寫
總結
Claude Opus 4.7 是一次極其典型的"場景偏科"升級。它的所有升級都指向一個目標——讓 Anthropic 在 Agentic 編碼這個賽道上重新奪回狀態冠軍。這一目標它做到了,但代價是:"其他所有場景"的用戶一起爲這次升級買單。
如果你是構建 Agent、Claude Code 重度用戶、Cursor 深度用戶,Opus 4.7 值得立即遷移。但如果你的核心場景是寫作、RAG、Web 研究、成本敏感型生產,建議:
- 保留 Opus 4.6 用於非 Agent 任務
- 把 Claude Code 的默認 effort 從 xhigh 降到 high
- 按場景路由多個模型,不要一刀切升級
"價格沒變"從來不是完整的故事。真實成本藏在 Tokenizer、默認檔位和推理深度裏。Opus 4.7 不是不好,而是不通用——理解這一點,你就能用它發揮出正確的價值。
推薦通過 API易 apiyi.com 平臺統一管理 Claude 全系列模型調用,該平臺提供多模型智能路由、實時額度監控、與官方完全兼容的 API 接口,是應對 Opus 4.7 "場景偏科" 問題的最務實工具。
參考資料
-
Anthropic 官方發佈公告:Claude Opus 4.7 正式介紹
- 鏈接:
anthropic.com/news/claude-opus-4-7 - 說明: 官方能力定義與推薦使用場景
- 鏈接:
-
Anthropic 官方文檔:Opus 4.7 遷移指南
- 鏈接:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 說明: Tokenizer 變化與 xhigh 說明
- 鏈接:
-
Finout 成本分析:Unchanged Price Tag 背後的真實成本
- 鏈接:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - 說明: 第三方成本分析與賬單拆解
- 鏈接:
-
Artificial Analysis 橫評:GPT-5.4 xhigh vs Claude Opus 對比
- 鏈接:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - 說明: 獨立第三方多模型橫評數據
- 鏈接:
-
GitHub Issue #23706:Max Plan 用戶 Token 消耗反饋
- 鏈接:
github.com/anthropics/claude-code/issues/23706 - 說明: Claude Code Max Plan 用戶一手體感反饋
- 鏈接:
作者: APIYI 技術團隊
發佈日期: 2026-04-18
適用模型: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
技術交流: 歡迎通過 API易 apiyi.com 獲取多模型測試額度,親測不同場景下的真實差距