Примечание автора: GPT-5.4 или Claude Opus 4.6? В 2026 году две главные флагманские ИИ-модели сошлись в лобовом столкновении. В этой статье мы собрали свежие данные тестов Chatbot Arena, SWE-bench, ARC-AGI-2 и OpenClaw PinchBench, чтобы сравнить их возможности в деле: от написания кода и логики до работы агентов и стоимости токенов. В конце — четкие рекомендации, какую модель выбрать под ваши задачи.

GPT-5.4 vs Claude Opus 4.6: краткий обзор ключевых различий
При выборе флагманской модели ИИ стоит обратить внимание на несколько ключевых параметров:
| Критерий сравнения | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Дата выпуска | Конец 2025 г. | Февраль 2026 г. |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| Общий индекс интеллекта ИИ | 57 | 53 |
| Цена API (Input) | $2.50 / 1M токенов | $5.00 / 1M токенов |
| Цена API (Output) | $15.00 / 1M токенов | $25.00 / 1M токенов |
| Контекстное окно | ~1M токенов | 200K (1M в Beta) |
| Макс. длина вывода | — | 128K токенов |
| Статус | Актуальна | Актуальна |
Краткий вывод: GPT-5.4 обладает более высоким общим индексом интеллекта и стоит примерно на 50% дешевле. Claude Opus 4.6 занимает первое место в рейтинге удовлетворенности пользователей Chatbot Arena и лучше справляется со сложным программированием и задачами для ИИ-агентов.
🎯 Быстрый совет: Если вы разработчик и для вас важна цена, GPT-5.4 обеспечит лучшее соотношение стоимости и производительности. Если же ваш проект требует генерации сложного кода или обработки сверхдлинных документов, Opus 4.6 стоит вложений. Рекомендуем подключить обе модели через APIYI (apiyi.com) для сравнительного тестирования — платформа поддерживает единый интерфейс API для быстрого переключения.
Авторитетные бенчмарки: всестороннее сравнение GPT-5.4 и Claude Opus 4.6
Сравнение рассуждений и знаний
| Бенчмарк | GPT-5.4 | Claude Opus 4.6 | Описание |
|---|---|---|---|
| GPQA Diamond (наука, уровень аспирантуры) | 93.2% | 91.3% | GPT-5.4 лучше |
| MMLU (энциклопедические знания) | 89.6% | 91.1% | Opus 4.6 лучше |
| ARC-AGI-2 (абстрактное мышление) | 52.9% | 68.8% | Opus 4.6 значительно впереди |
| BigLaw Bench (юриспруденция) | — | 90.2% | Специализированное преимущество Opus 4.6 |
| MRCR v2 (длинный контекст 1M) | — | 76% | Opus 4.6 лидирует в работе с документами |
| GDPval-AA ELO (профессиональные задачи) | 1462 | 1606 | Opus 4.6 заметно превосходит |
Анализ: GPT-5.4 имеет небольшое преимущество в научных рассуждениях (GPQA Diamond), но Claude Opus 4.6 показывает себя гораздо сильнее в абстрактном мышлении (отрыв в 16 процентных пунктов), профессиональной юридической работе и обработке длинного контекста.

Сравнение программирования и возможностей ИИ-агентов
| Бенчмарк | GPT-5.4 | Claude Opus 4.6 | Описание |
|---|---|---|---|
| SWE-bench Verified (исправление реального кода) | ~77.2% | 80.8% | Opus 4.6 лучше |
| SWE-bench Pro (код профессионального уровня) | 57.7% | ~45% | GPT-5.4 лучше |
| Terminal-Bench 2.0 (работа в терминале) | 64.7% | 65.4% | Небольшое преимущество Opus 4.6 |
| OSWorld (управление компьютером) | 75.0% | 72.7% | Небольшое преимущество GPT-5.4 |
| BrowseComp (веб-поиск и исследования) | 77.9% | 84.0% | Opus 4.6 лучше |
| OpenRCA (анализ первопричин) | — | 34.9% | Специализированное преимущество Opus 4.6 |
Анализ: В программировании у каждой модели свои сильные стороны. Opus 4.6 лучше справляется с повседневным исправлением багов (SWE-bench Verified), тогда как GPT-5.4 лидирует в написании сложного кода корпоративного уровня (SWE-bench Pro). В управлении компьютером GPT-5.4 немного впереди, но Opus 4.6 показывает выдающиеся результаты в веб-исследованиях и анализе первопричин сбоев.
💡 Совет разработчикам: Для задач генерации кода, идущего в продакшн, рекомендуем сначала протестировать обе модели через единый интерфейс APIYI (apiyi.com). Это позволит принять решение на основе особенностей вашей кодовой базы, при этом стоимость вызовов будет на 20–40% ниже, чем при прямом обращении к официальным API Anthropic или OpenAI.
OpenClaw в деле: свежие данные тестов PinchBench
Что такое OpenClaw и PinchBench?
OpenClaw — это опенсорсная платформа для создания AI-агентов с возможностью самохостинга (аналог Claude Code). Она поддерживает работу через терминал, редактирование нескольких файлов одновременно и интеграцию с более чем 50 инструментами, включая WhatsApp, Telegram и Slack. Проект был запущен австрийским разработчиком Петером Штайнбергером (Peter Steinberger) в ноябре 2025 года и сейчас стремительно набирает популярность на GitHub.
PinchBench — это бенчмарк, разработанный специально для агентов OpenClaw компанией Kilo.ai. В отличие от традиционных тестов, которые проверяют простые ответы на вопросы, здесь оценивается работа модели в реальных многошаговых сценариях:
- Назначение встреч и управление календарем
- Написание кода для проектов, состоящих из нескольких файлов
- Сортировка почты и управление файлами
- Поиск информации в вебе и её структурирование
На сегодняшний день это один из тестов, максимально приближенных к реальному использованию AI-агентов.
Рейтинг PinchBench (13 марта 2026 г., 47 моделей, 277 прогонов)
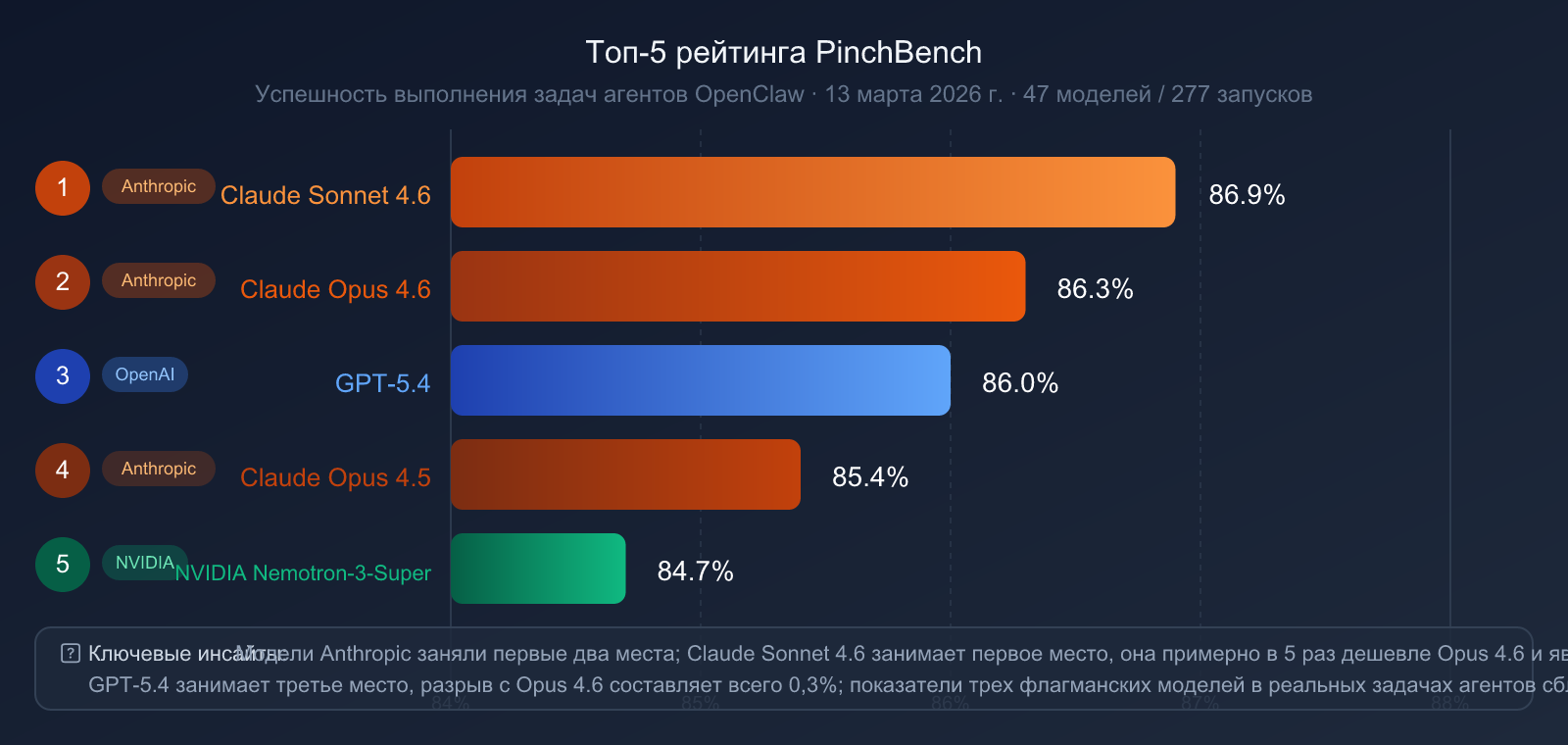
| Место | Модель | Успешность в PinchBench |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
Ключевые выводы:
- Серия Claude доминирует: Sonnet 4.6 и Opus 4.6 заняли первое и второе места соответственно. Это подтверждает системное преимущество Anthropic в разработке моделей для агентских задач.
- GPT-5.4 на третьем месте: Отставание от Opus 4.6 составляет всего 0,3 процентных пункта — разрыв минимален.
- Сюрприз по соотношению цена/качество: Claude Sonnet 4.6 (который примерно в 5 раз дешевле Opus 4.6) показал лучший результат в PinchBench. Это доказывает, что «дороже» не всегда значит «лучше» для конкретных задач.
- Новый взгляд на Claude Sonnet 4.6: Для задач в стиле OpenClaw модель Sonnet 4.6 сейчас является самым оптимальным выбором по соотношению эффективности и затрат.
🔍 Рекомендация для разработчиков: Если вы строите AI-агента на базе OpenClaw, разница между топ-3 моделями (Sonnet 4.6, Opus 4.6, GPT-5.4) составляет менее 1%. Мы рекомендуем подключать их через сервис-прокси API APIYI (apiyi.com). Это позволит гибко переключаться между моделями в зависимости от типа задачи, оптимизируя расходы без потери качества.
Chatbot Arena ELO: Самые мощные модели по мнению реальных пользователей
Chatbot Arena (ранее LMSYS) — это на сегодняшний день самый авторитетный рейтинг предпочтений пользователей ИИ-моделей. Рейтинг ELO здесь формируется на основе миллионов слепых тестов в ходе реальных диалогов.
Актуальный рейтинг на февраль 2026 года (Топ-5):
| Место | Модель | Баллы ELO |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 опережает GPT-5.4 на 40 баллов ELO, показывая особенно впечатляющие результаты в многоходовых диалогах, контроле стиля и креативном письме. В системе оценки Chatbot Arena такой разрыв считается значительным преимуществом.
GPT-4.5 (историческая справка): Выпущенная OpenAI в феврале 2025 года модель GPT-4.5 (кодовое название «Orion») была сфокусирована на эмоциональном интеллекте и качестве диалога. На старте она ненадолго возглавила рейтинг Chatbot Arena. Однако эта модель была выведена из API 14 июля 2025 года, а из интерфейса ChatGPT полностью исчезла в августе 2025-го. GPT-5.4 — её нынешний преемник, который превосходит предшественницу по всем параметрам.
Цены на API и соотношение цена/качество: что выбрать для экономных проектов
| Статья расходов | GPT-5.4 | Claude Opus 4.6 | Разница |
|---|---|---|---|
| Цена за вход (за млн токенов) | $2.50 | $5.00 | Opus 4.6 дороже в 2 раза |
| Цена за выход (за млн токенов) | $15.00 | $25.00 | Opus 4.6 дороже в 1.67 раза |
| Контекстное окно | ~1M токенов | 200K (1M Beta) | GPT-5.4 выигрывает |
| Макс. длина вывода | — | 128K токенов | Opus 4.6 выигрывает |
| Мультимодальность | ✅ Ввод изображений | ✅ Ввод изображений | Примерно равно |
Оценка затрат (при обработке 1 млн входных + 200 тыс. выходных токенов в день):
- GPT-5.4: около $5.50 в день (в среднем $165 в месяц)
- Claude Opus 4.6: около $10.00 в день (в среднем $300 в месяц)
💰 Вариант оптимизации затрат: Если у вас проект с высокой нагрузкой или бюджет ограничен, рекомендуем использовать Claude Sonnet 4.6 через сервис APIYI (apiyi.com) для повседневных задач, а Opus 4.6 вызывать только тогда, когда нужны максимальные возможности рассуждения. Это позволит снизить расходы на API на 60–75%. APIYI поддерживает единую тарификацию для разных моделей в одном аккаунте, что очень удобно для точного управления бюджетом.
Рекомендации по сценариям: что выбрать — GPT-5.4 или Claude Opus 4.6?
Когда стоит выбрать GPT-5.4
✅ Универсальные задачи с отличным соотношением цены и качества
- Бюджет ограничен, но требуются флагманские возможности большой языковой модели.
- Повседневное создание контента, ответы службы поддержки, извлечение информации.
- Значительная экономия средств, если ежемесячные расходы на API превышают $500.
✅ Научные исследования и технические вопросы
- Лидерство в бенчмарке GPQA Diamond: модель лучше справляется с научными рассуждениями уровня доктора наук.
- Профессиональные ответы в таких областях, как химия, физика и биология.
✅ Сложный код корпоративного уровня (лидер SWE-bench Pro)
- Внесение правок на уровне архитектуры в сверхбольшие кодовые базы.
- Задачи по рефакторингу, требующие глубокого понимания сложных зависимостей.
✅ Сценарии с ультра-длинным контекстом
- Необходимо обрабатывать огромные документы или репозитории кода объемом около 1 млн токенов.
- Контекстное окно в 1 млн токенов у Opus 4.6 пока находится на стадии бета-тестирования.
Когда стоит выбрать Claude Opus 4.6
✅ Генерация и исправление кода продакшн-уровня
- Результат 80.8% в SWE-bench Verified: модель более надежна в повседневном исправлении багов и разработке новых функций.
- Возможности веб-исследований (BrowseComp 84%) идеально подходят для приложений с RAG-усилением.
✅ Проекты на базе ИИ-агентов (типа OpenClaw)
- Топ-2 в рейтинге PinchBench: модели Anthropic системно лучше показывают себя в реальных задачах для агентов.
✅ Продукты с высокими требованиями к качеству диалога
- Первое место в мире по удовлетворенности пользователей (ELO 1503 в Chatbot Arena).
- Более высокая связность в многошаговых диалогах и отличная способность адаптироваться к стилю общения.
✅ Профессиональная интеллектуальная работа
- Превосходство на 16 процентных пунктов в ARC-AGI-2: более сильное абстрактное мышление.
- Результат 90.2% в BigLaw Bench: высокая надежность в юридических вопросах, комплаенсе и анализе документов.
✅ Вывод длинных текстов
- Максимальный объем вывода (output) составляет 128K, что подходит для генерации полных отчетов и объемных документов.
🎯 Совет по выбору: Обе модели хороши по-своему, и разница между ними проявляется в специфических задачах. Мы рекомендуем провести A/B тестирование перед официальным запуском через платформу APIYI (apiyi.com). Платформа предоставляет единый интерфейс для быстрого переключения между моделями, помогая найти оптимальный вариант для вашего бизнеса.
Быстрое подключение: используйте обе модели через единый API
Вам не нужно регистрировать отдельные аккаунты в OpenAI и Anthropic. Через APIYI можно получить доступ ко всем ведущим моделям через один интерфейс:
from openai import OpenAI
# Через единый интерфейс APIYI поддерживаются и GPT-5.4, и Claude Opus 4.6
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Единый адрес подключения APIYI
)
# Вызов Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Помоги мне проанализировать потенциальные баги в этом коде..."}
],
max_tokens=4096
)
# Вызов GPT-5.4 (тот же интерфейс, просто меняем название модели)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "Помоги мне проанализировать потенциальные баги в этом коде..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 Инструкция по подключению: Установите
base_urlнаhttps://vip.apiyi.com/v1, аapi_keyзамените на ключ, полученный на сайте APIYI (apiyi.com). Теперь вы можете переключаться между моделями в один клик. При первом пополнении баланса предоставляется бонус, что удобно для тестирования реальной разницы между моделями перед запуском проекта.
Таблица соответствия моделей:
| Модель | ID модели для API | Средние затраты (100 млн токенов/мес) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
около $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
около $100+ |
| GPT-5.4 | gpt-5-4 |
около $250+ |
Часто задаваемые вопросы
В: GPT-4.5 и GPT-5.4 — это одна и та же модель?
Нет. GPT-4.5 (кодовое название «Orion») — это переходная модель, выпущенная OpenAI в феврале 2025 года. Она была ориентирована на эмоциональный интеллект и качество диалога, но имела крайне высокую стоимость ($75/$150 за 1 млн токенов) и была официально выведена из API 14 июля 2025 года. GPT-5.4 — это текущая флагманская модель OpenAI, которая по всем параметрам превосходит GPT-4.5, при этом её цена значительно снизилась до $2.50/$15 за 1 млн токенов. Если вам нужно вызвать самую мощную модель OpenAI, используйте GPT-5.4 — доступ к ней можно получить через APIYI на apiyi.com.
В: Что такое OpenClaw? Чем он отличается от Cursor / Claude Code?
OpenClaw — это платформа ИИ-агентов с открытым исходным кодом и возможностью самостоятельного хостинга. Она поддерживает доступ через терминал, редактирование многофайлового кода и интеграцию с более чем 50 инструментами (WhatsApp, Telegram, Slack и др.), а также обладает способностью к «самоэволюции» — автоматическому созданию новых навыков. В отличие от Cursor (коммерческий плагин для IDE) и Claude Code (официальный CLI от Anthropic), главное преимущество OpenClaw заключается в полной открытости и возможности развертывания в закрытом контуре, что идеально подходит для компаний с высокими требованиями к безопасности данных. PinchBench — это специальный бенчмарк для оценки работы больших языковых моделей именно в задачах агентов OpenClaw.
В: Какая модель лучше подходит для написания текстов?
Согласно рейтингу Chatbot Arena ELO, Claude Opus 4.6 занимает первое место в мире с результатом 1503 балла по результатам пользовательских тестов. Она особенно хороша в креативном письме, многошаговых диалогах и адаптации под конкретный стиль. GPT-5.4 также отлично справляется с текстами, но индекс удовлетворенности пользователей у неё чуть ниже. Рекомендуем протестировать обе модели под ваши конкретные задачи через APIYI на apiyi.com — результаты могут отличаться в зависимости от стиля и типа контента.
В: Насколько велика разница между Claude Sonnet 4.6 и Claude Opus 4.6?
Если смотреть на тест агентов PinchBench, то Sonnet 4.6 (86.9%) даже немного обходит Opus 4.6 (86.3%). В рейтинге Chatbot Arena ELO у Sonnet 4.6 около 1438 баллов, а у Opus 4.6 — 1503, разница составляет примерно 65 баллов. Для большинства задач по программированию и аналитике Sonnet 4.6 является более выгодным выбором (её цена составляет около 20% от стоимости Opus 4.6). Переходить на Opus 4.6 стоит только в сценариях со сложными рассуждениями, обработкой длинных документов или там, где требуется экстремальная точность.
Итог: какую флагманскую модель выбрать в 2026 году?
| Сценарий использования | Рекомендуемая модель | Основная причина |
|---|---|---|
| Повседневная разработка + экономия | GPT-5.4 | На 50% дешевле, отличные общие способности |
| Исправление сложного кода (SWE-bench) | Claude Opus 4.6 | 80.8% успеха против 77.2% у GPT-5.4 |
| Задачи для ИИ-агентов (OpenClaw) | Claude Sonnet 4.6 | №1 в PinchBench, при этом дешевле Opus |
| Диалоговые продукты / лояльность пользователей | Claude Opus 4.6 | №1 в Chatbot Arena ELO (1503) |
| Научные исследования / академические ответы | GPT-5.4 | Небольшое лидерство в GPQA Diamond (93.2%) |
| Анализ сверхдлинных документов | Claude Opus 4.6 | Вывод 128K токенов + MRCR v2 76% |
| Абстрактное мышление / задачи AGI | Claude Opus 4.6 | ARC-AGI-2 68.8% против 52.9% |
Ключевые выводы:
- GPT-5.4 — это выбор с лучшим соотношением цены и качества. Её индекс общего интеллекта чуть выше (57 против 53), а цена примерно в два раза ниже, чем у Opus 4.6.
- Claude Opus 4.6 — модель с самым высоким уровнем удовлетворенности пользователей в мире (ELO 1503). Она имеет явное преимущество в сложном коде, работе агентов и абстрактном мышлении.
- Для большинства реальных проектов Claude Sonnet 4.6 — это «золотая середина». Она занимает первое место в PinchBench, а стоит гораздо дешевле, чем Opus 4.6.
Не существует «абсолютно лучшей» модели — есть та, которая лучше всего подходит под ваши задачи.
🚀 Протестируйте прямо сейчас: на платформе APIYI (apiyi.com) вы можете через один API-ключ получить доступ сразу к GPT-5.4, Claude Opus 4.6 и Claude Sonnet 4.6. Сравните их работу и стоимость на своих реальных данных. Новые пользователи получают тестовый баланс при регистрации, что поможет принять верное решение перед запуском проекта.
Источники данных: официальная документация Anthropic и OpenAI, рейтинг Chatbot Arena (февраль 2026), рейтинг PinchBench (13 марта 2026), сравнение моделей Artificial Analysis, технические тесты DigitalApplied. Данные могут меняться по мере обновления моделей, рекомендуем сверяться с актуальной документацией.
Автор: Команда APIYI | Опубликовано на AI123.dev