Когда генерируешь изображения с помощью Nano Banana, многие разработчики сталкиваются с одной раздражающей проблемой: изображения получаются красивые, но текст на них либо с ошибками, либо размытый, либо вообще превращается в абракадабру.
Хорошая новость в том, что в официальной документации Google есть ключевой совет: сначала попросите модель сгенерировать текстовое содержимое, а затем запросите генерацию изображения, содержащего этот текст. Это так называемый «двухэтапный подход» (Two-Step Approach), который значительно повышает точность рендеринга текста.
В этой статье мы глубоко проанализируем технические причины этого явления и дадим 6 проверенных на практике советов по рендерингу текста, которые помогут вам сделать текст на изображениях от Nano Banana чётким и точным.
Основная ценность: Прочитав эту статью, вы поймёте, как работает рендеринг текста в Nano Banana, освоите двухэтапный подход и другие 6 практических приёмов, а также сможете повысить точность текста на изображениях с уровня «как повезёт» до контролируемого.
Текущее состояние рендеринга текста в Nano Banana: мощно, но требует сноровки
Сразу к выводам: возможности моделей серии Nano Banana по рендерингу текста в области генерации изображений с помощью ИИ находятся на высшем уровне, но это не значит, что "можно просто написать промпт и получить идеальный текст".
Данные по точности рендеринга текста Nano Banana
| Модель | Точность текста | Поддержка нескольких языков | Максимальная надёжная длина текста | Описание |
|---|---|---|---|---|
| Nano Banana Pro | ~94% | Отлично | около 25 символов | Максимальная точность, подходит для коммерческих плакатов |
| Nano Banana 2 | ~87% | Отлично | около 20 символов | Быстрая скорость, высокая экономичность |
| DALL-E 3 | ~78% | Хорошо | около 15 символов | Длинный текст часто содержит ошибки |
| Stable Diffusion XL | ~45% | Плохо | около 8 символов | В основном ненадёжно |
| Midjourney v6 | ~65% | Средне | около 12 символов | Хороший стиль, но слабый текст |
Как видно, 94% точности Nano Banana Pro — это уже самый высокий показатель в отрасли. Но оставшиеся 6% неудачных сценариев — орфографические ошибки, размытый текст, пропущенные символы — неприемлемы для коммерческого использования.
Почему рендеринг текста в изображениях, генерируемых ИИ, так сложен
Чтобы понять, почему нужен "двухэтапный метод", сначала разберёмся в трудностях генерации текста в изображениях, создаваемых ИИ:
- Требования к точности на уровне пикселей: Текст на изображении должен быть точным до пикселя, одна ошибка в штрихе превращает его в опечатку. В то время как другие элементы, генерируемые ИИ (пейзажи, люди), допускают некоторую степень размытости.
- Взрывное количество комбинаций символов: 26 букв английского алфавита, тысячи китайских иероглифов, плюс регистр, шрифты, комбинации расположения — возможности практически безграничны.
- Контекстные помехи: При генерации общей композиции изображения модель легко "отвлекается" — ей нужно одновременно хорошо нарисовать фон и правильно расположить текст, эти две задачи конкурируют за внимание.
- Смещение в обучающих данных: Доля изображений с идеальным текстом в обучающем наборе ограничена, и модель недостаточно хорошо изучает некоторые шрифты и комбинации макетов.
🎯 Технический совет: Поняв сложности рендеринга текста, можно целенаправленно оптимизировать промпт. Используя платформу APIYI apiyi.com для вызова Nano Banana Pro и Nano Banana 2, вы можете быстро сравнить эффекты рендеринга текста двух моделей и выбрать наиболее подходящее решение для вашего сценария.
Ключевой приём один: Двухэтапный метод — официально рекомендованная лучшая практика рендеринга текста
Это метод, прямо рекомендованный в официальной документации Google, и это самый важный приём в этой статье.
Принцип двухэтапного метода
Традиционный одноэтапный метод (плохой результат):
"Создай плакат с надписью 'SUMMER SALE 50% OFF'"
→ Модель одновременно обрабатывает композицию и текст → Текст легко содержит ошибки
Двухэтапный метод (хороший результат):
Шаг первый: "Пожалуйста, сгенерируй текст для плаката: Летняя распродажа 50% скидка"
→ Модель выводит текст: "SUMMER SALE 50% OFF"
Шаг второй: "Сгенерируй изображение плаката, на котором точно отображается текст 'SUMMER SALE 50% OFF'"
→ Модель фокусируется на рендеринге уже определённого текста в изображение → Точность значительно повышается
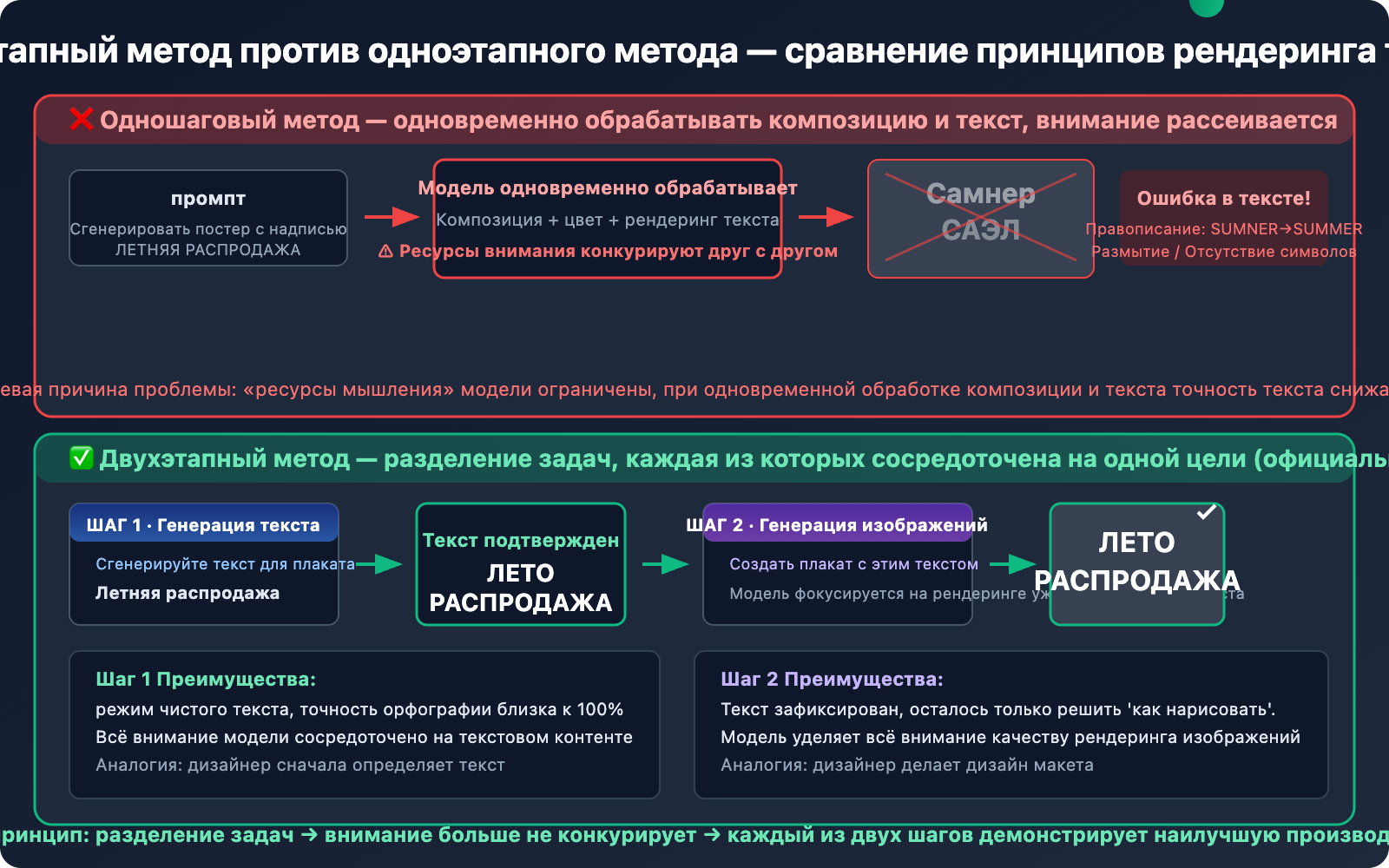
Почему двухэтапный метод эффективен — техническое объяснение
Nano Banana построен на базе мультимодальной Большой языковой модели Gemini. Когда вы используете одноэтапный метод, напрямую требуя "сгенерировать изображение, содержащее определённый текст", модель должна одновременно выполнить две задачи:
- Понять и спланировать композицию изображения — сцена, цвета, расположение.
- Точно отрендерить текстовые символы — орфография, шрифт, позиция.
Эти две задачи в механизме внимания модели будут конкурировать друг с другом. "Ресурсы для мышления" модели ограничены, и при одновременной обработке двух высокоточных задач текстовая часть часто становится жертвой.
Основная идея двухэтапного метода — это разделение задач:
- Первый шаг позволяет модели сосредоточиться на генерации и подтверждении текстового содержимого — в этот момент модель находится в чисто текстовом режиме, и точность орфографии чрезвычайно высока.
- Второй шаг позволяет модели сосредоточиться на рендеринге уже определённого текста в изображение — текстовое содержимое уже зафиксировано, и модели нужно решить только вопрос "как нарисовать".
Это как если бы художник сначала определил, какой текст будет на плакате (этап создания текста), а затем приступил к рисованию плаката (этап дизайна). Выполнение двух этапов по отдельности повышает эффективность и точность.
Реализация двухэтапного метода с помощью API
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
# ========== Шаг первый: Позволяем модели сгенерировать/подтвердить текстовое содержимое ==========
text_response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{
"role": "user",
"content": "Мне нужен рекламный плакат для кофейни. Пожалуйста, сгенерируйте английский текст, который должен быть на плакате, краткий и мощный, не более 20 символов. Выведите только текст, без другого содержимого."
}]
)
poster_text = text_response.choices[0].message.content.strip()
print(f"Шаг первый - Сгенерированный текст: {poster_text}")
# Пример вывода: "BREW YOUR PERFECT DAY"
# ========== Шаг второй: Генерируем изображение с определённым текстом ==========
image_response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{
"role": "user",
"content": f'Generate an image: A warm-toned coffee shop promotional poster. Display the exact text "{poster_text}" in bold serif font, centered at the top. Background shows a cozy cafe interior with warm lighting.'
}]
)
print("Шаг второй - Генерация изображения завершена")
Ключевые детали двухэтапного метода
| Деталь | Описание | Причина |
|---|---|---|
| Первый шаг в чисто текстовом режиме | Не требуйте генерации изображения на первом шаге | Позволяет модели сосредоточиться на качестве текста |
| Текст в двойных кавычках | Во втором промпте заключайте текст в "..." |
Чётко указывает модели, что это содержимое нужно отрендерить как есть |
| Второй промпт на английском | Инструкции по генерации изображения рекомендуется давать на английском | Точность понимания английских промптов выше |
| Указание стиля шрифта | Добавьте описание типа bold serif font и т.д. |
Помогает модели выбрать более легко рендерируемый шрифт |
| Ограничение длины текста | На первом шаге контролируйте длину до 25 символов | При длине более 25 символов точность значительно снижается |
Ключевой приём 2: Золотое правило 25 символов
Это самое важное жёсткое ограничение для рендеринга текста в Nano Banana.
Зависимость точности рендеринга текста Nano Banana от количества символов
| Диапазон символов | Точность | Рекомендации |
|---|---|---|
| 1-10 символов | ~98% | Оптимальный диапазон, почти без ошибок |
| 11-20 символов | ~92% | Безопасный диапазон, иногда мелкие проблемы |
| 21-25 символов | ~85% | Приемлемо, но требует проверки, возможно, потребуется повторная попытка |
| 26-40 символов | ~60% | Зона высокого риска, частые ошибки |
| 40+ символов | <40% | Не рекомендуется, в основном ненадежно |
Что делать, если текст превышает 25 символов
Если ваш текст действительно превышает 25 символов, есть 3 способа это обработать:
Стратегия 1: Разбить на несколько коротких строк
# ❌ Рендеринг длинного текста за один раз
prompt = 'Generate a poster with text "ANNUAL SUMMER CLEARANCE SALE - UP TO 70% OFF ALL ITEMS"'
# ✅ Разделение на несколько коротких строк
prompt = '''Generate a poster with two lines of text:
Line 1 (large, bold): "SUMMER SALE 70% OFF"
Line 2 (smaller, below): "ALL ITEMS INCLUDED"'''
Стратегия 2: Постепенное добавление в несколько этапов диалога
# Этап 1: Сгенерировать изображение только с основным заголовком
# Этап 2: Добавить подзаголовок на основе результата предыдущего этапа
# Этап 3: Затем добавить текст внизу
Стратегия 3: Использовать изображения для ключевого текста, а длинный текст добавлять на этапе пост-обработки
Для сценариев, где действительно требуется много текста (например, инфографика), рекомендуется использовать Nano Banana только для генерации ключевых коротких заголовков, а длинные текстовые блоки добавлять позже с помощью инструментов дизайна.
Ключевой приём 3: Заключение в двойные кавычки + явное указание шрифта
Комбинация этих двух небольших приёмов позволяет ещё больше повысить точность рендеринга текста.
Роль двойных кавычек
Двойные кавычки сообщают модели: содержимое в кавычках — это текст, который нужно точно отрендерить символ за символом, а не общее описание.
# ❌ Без кавычек модель может интерпретировать текст свободно
prompt = "Generate a sign that says Welcome to Tokyo"
# Может вывести: "WELCOME TO TOKIO" (ошибка в написании) или совершенно другой текст
# ✅ Заключение в двойные кавычки, принудительный посимвольный рендеринг
prompt = 'Generate a sign that displays the exact text "Welcome to Tokyo"'
# Вывод: "Welcome to Tokyo" (с высокой вероятностью точно)
Явное указание шрифта
Чёткое указание типа шрифта может помочь модели выбрать форму шрифта, которую легче отрендерить:
| Указание шрифта | Написание промпта | Эффект |
|---|---|---|
| Жирный шрифт с засечками | bold serif font |
Самый чёткий, рекомендуется для заголовков плакатов |
| Шрифт без засечек | clean sans-serif font |
Современный вид, подходит для технологических тем |
| Рукописный шрифт | handwritten script |
Низкая точность текста, используйте с осторожностью |
| Моноширинный шрифт | monospace font |
Подходит для скриншотов кода |
| Определённый шрифт | in Helvetica style |
Ссылка на стиль, полное совпадение не гарантируется |
💡 Полезный совет: Жирный шрифт с засечками (bold serif) — это тип шрифта с самой высокой точностью рендеринга текста. Из-за толстых штрихов и чёткой структуры модели легче его точно сгенерировать. Точность рукописных и декоративных шрифтов самая низкая, старайтесь избегать их для важного текста.
Ключевой приём четыре: Особенности рендеринга текста на разных языках
Nano Banana отлично справляется с рендерингом текста на разных языках, но стратегии для каждого языка могут отличаться.
Особенности рендеринга текста для разных языков
| Язык | Точность рендеринга | Оптимальное количество символов | Особые примечания |
|---|---|---|---|
| Английский | ~94% | ≤25 | Лучше всего работает с заглавными буквами |
| Китайский | ~85% | ≤8 иероглифов | Упрощённый лучше традиционного |
| Японский | ~82% | ≤10 | Хирагана лучше иероглифов |
| Корейский | ~80% | ≤12 | Необходимо явно указывать корейский язык |
| Арабский | ~75% | ≤8 | Обратите внимание на порядок справа налево |
Шаблон промпта для рендеринга текста на разных языках
# Английский — самый надёжный
prompt = 'Generate a poster with bold text "HELLO WORLD" in white serif font'
# Китайский — указываем язык + краткость
prompt = 'Generate a poster with Chinese text "欢迎光临" in bold Chinese calligraphy style font, centered'
# Японский — явно указываем язык
prompt = 'Generate a Japanese store sign with text "いらっしゃいませ" in clean sans-serif Japanese font'
# Смешанные языки — обрабатываем построчно
prompt = '''Generate a bilingual poster:
Top line in English: "GRAND OPENING"
Bottom line in Chinese: "盛大开业"
Both in bold, high contrast against dark background'''
🎯 Технический совет: Для рендеринга текста на разных языках рекомендуем проводить многократное тестирование и сравнение на платформе APIYI apiyi.com. Эффекты для разных языков могут сильно отличаться, и практические тесты надёжнее теоретических параметров. Платформа поддерживает быстрое переключение между моделями Nano Banana Pro и Nano Banana 2.
Ключевой приём пять: Структурированный шаблон промпта (обязательно для практики)
Давайте объединим все предыдущие приёмы в один стандартизированный шаблон промпта, который можно использовать для разных сценариев.
Универсальный шаблон промпта для рендеринга текста в Nano Banana
Generate an image:
[Описание сцены, до 100 символов].
Display the exact text "[Ваш текст, ≤25 символов]" in [Стиль шрифта] font,
positioned at [Позиция], [Описание размера].
The text should be [Цвет] with high contrast against the background.
Ensure the text is perfectly legible and correctly spelled.
Практические примеры для разных сценариев
Сценарий один: Коммерческий постер
prompt = '''Generate an image:
A vibrant summer sale promotional poster with tropical beach background.
Display the exact text "SUMMER SALE" in bold white serif font,
positioned at the center top, large and prominent.
Below it, display "50% OFF" in bold yellow sans-serif font.
The text should have high contrast against the background.
Ensure all text is perfectly legible and correctly spelled.'''
Сценарий два: Дизайн логотипа
prompt = '''Generate an image:
A minimalist tech company logo on a clean white background.
Display the exact text "NEXUS" in modern bold sans-serif font,
positioned at the center, medium size.
The text should be dark navy blue (#1a1a2e).
Ensure the text is perfectly legible and correctly spelled.'''
Сценарий три: Изображение для социальных сетей
prompt = '''Generate an image:
An inspirational quote card with soft gradient background (blue to purple).
Display the exact text "START NOW" in elegant white serif font,
positioned at the center, large and prominent.
The text should be pure white with subtle drop shadow.
Ensure the text is perfectly legible and correctly spelled.'''

Ключевой приём 6: Итеративная коррекция в многораундовом диалоге
Даже если вы использовали первые 5 приёмов, рендеринг текста всё равно может быть не идеальным. Одно из главных преимуществ Nano Banana — поддержка многораундового редактирования в диалоге: если результат не устраивает, вы можете сразу же внести исправления на основе предыдущего.
Процесс диалога для коррекции текста
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
messages = []
# Раунд 1: Генерация исходного изображения
messages.append({
"role": "user",
"content": 'Generate an image: A coffee shop menu board with text "TODAY\'S SPECIAL" in chalk-style white font on dark background'
})
response_1 = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=messages
)
messages.append({"role": "assistant", "content": response_1.choices[0].message.content})
# Раунд 2: Проверка и коррекция текста
messages.append({
"role": "user",
"content": 'The text is slightly blurry. Please regenerate with the text "TODAY\'S SPECIAL" rendered more sharply and clearly. Make the font bolder and increase the contrast.'
})
response_2 = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=messages
)
Часто используемые команды для коррекции
| Проблема | Промпт для коррекции |
|---|---|
| Размытый текст | "Make the text sharper and bolder, increase contrast" |
| Орфографическая ошибка | "Fix the spelling. The correct text should be exactly '[правильный текст]'" |
| Отсутствует текст | "The text '[текст]' is missing. Add it at [позиция] in [шрифт]" |
| Неправильный шрифт | "Change the font to bold serif, keep the same text content" |
| Смещение положения | "Move the text to the center of the image, keep everything else" |
| Неподходящий размер | "Make the text larger/smaller while keeping it legible" |
🚀 Быстрый старт: Многораундовое редактирование в диалоге идеально подходит для сценариев, где к текстовым эффектам предъявляются высокие требования. Используя платформу APIYI apiyi.com для вызова Nano Banana, каждая итерация редактирования стоит около $0.02, и 3-4 раунда обычно достаточно для достижения желаемого результата.
Полный рабочий процесс рендеринга текста в Nano Banana
Объединим 6 приёмов в стандартизированный рабочий процесс:
Шаг первый: Планирование текстового содержимого
- Определите текст для рендеринга (≤25 символов)
- Если текст длиннее 25 символов, разделите его на несколько строк
- Убедитесь в правильности написания
Шаг второй: Генерация в два этапа
- Сначала дайте модели подтвердить/оптимизировать текстовое содержимое
- Затем используйте подтверждённый текст для генерации изображения
Шаг третий: Оптимизация промпта
- Заключите текст в двойные кавычки
- Явно укажите стиль шрифта
- Используйте структурированный шаблон
- Добавьте ограничение
"Ensure text is perfectly legible"(Убедитесь, что текст идеально читаем)
Шаг четвёртый: Проверка и итерация
- Проверьте точность текста в сгенерированном результате
- Если результат не устраивает, используйте многораундовый диалог для коррекции
- Обычно 1-3 раунда достаточно для достижения желаемого эффекта
Посмотреть полный код рабочего процесса рендеринга текста
#!/usr/bin/env python3
"""
Оптимизированный рабочий процесс рендеринга текста в Nano Banana
Полная реализация двухэтапного метода + 6 основных приёмов
"""
import openai
import base64
import re
from datetime import datetime
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://api.apiyi.com/v1"
client = openai.OpenAI(api_key=API_KEY, base_url=BASE_URL)
def render_text_in_image(
scene_description: str,
desired_text: str,
font_style: str = "bold serif",
text_color: str = "white",
text_position: str = "centered",
model: str = "gemini-3.1-flash-image-preview",
max_fix_rounds: int = 2
):
"""
Генерирует изображение с точным текстом, используя двухэтапный метод
Args:
scene_description: Описание сцены (без требований к тексту)
desired_text: Текст для рендеринга (рекомендуется ≤25 символов)
font_style: Стиль шрифта
text_color: Цвет текста
text_position: Положение текста
model: Используемая модель
max_fix_rounds: Максимальное количество раундов коррекции
"""
# Проверка длины текста
if len(desired_text) > 25:
print(f"⚠️ Длина текста {len(desired_text)} превышает 25 символов, точность может снизиться")
# ===== Шаг первый: Подтверждение текстового содержимого =====
print(f"📝 Шаг первый: Подтверждение текстового содержимого → '{desired_text}'")
text_check = client.chat.completions.create(
model=model,
messages=[{
"role": "user",
"content": f"Please verify this text is correctly spelled and formatted: '{desired_text}'. Only reply with the verified text, nothing else."
}]
)
verified_text = text_check.choices[0].message.content.strip().strip("'\"")
print(f"✅ Подтверждённый текст: '{verified_text}'")
# ===== Шаг второй: Генерация изображения с текстом =====
print(f"🎨 Шаг второй: Генерация изображения...")
image_prompt = f'''Generate an image:
{scene_description}.
Display the exact text "{verified_text}" in {font_style} font,
positioned at {text_position}, with {text_color} color.
The text should have high contrast against the background.
Ensure the text is perfectly legible and correctly spelled.'''
messages = [{"role": "user", "content": image_prompt}]
response = client.chat.completions.create(
model=model,
messages=messages
)
content = response.choices[0].message.content
print(f"✅ Генерация изображения завершена")
# Сохранение изображения
save_image(content, f"text_render_{datetime.now().strftime('%H%M%S')}.png")
return content
def save_image(content, filename):
"""Извлекает и сохраняет изображение из ответа"""
patterns = [
r'data:image/[^;]+;base64,([A-Za-z0-9+/=]+)',
r'([A-Za-z0-9+/=]{1000,})'
]
for pattern in patterns:
match = re.search(pattern, content)
if match:
data = base64.b64decode(match.group(1))
with open(filename, 'wb') as f:
f.write(data)
print(f"💾 Сохранено в: {filename} ({len(data):,} байт)")
return True
print("⚠️ Данные изображения не найдены")
return False
# ===== Примеры использования =====
if __name__ == "__main__":
# Пример 1: Коммерческий постер
render_text_in_image(
scene_description="A vibrant promotional poster with tropical beach background, summer vibes",
desired_text="SUMMER SALE",
font_style="bold white serif",
text_position="top center, large and prominent"
)
# Пример 2: Логотип
render_text_in_image(
scene_description="A minimalist tech company logo on clean white background",
desired_text="NEXUS",
font_style="modern bold sans-serif",
text_color="dark navy blue",
text_position="centered"
)
# Пример 3: Китайский язык
render_text_in_image(
scene_description="A traditional Chinese restaurant sign with red and gold decorations",
desired_text="福满楼",
font_style="bold Chinese calligraphy",
text_color="gold",
text_position="centered, large"
)
Сравнение рендеринга текста в Nano Banana Pro и Nano Banana 2
Обе модели имеют свои особенности в рендеринге текста:
| Параметр сравнения | Nano Banana Pro | Nano Banana 2 | Рекомендация по выбору |
|---|---|---|---|
| Точность текста | ~94% | ~87% | Для коммерческих требований выбирайте Pro |
| Максимальное количество надёжных символов | ~25 | ~20 | Pro предлагает больший запас прочности |
| Многоязычная поддержка | Отлично | Отлично | Оба на одном уровне |
| Разнообразие стилей шрифтов | Богаче | Достаточно | Pro предлагает больше вариантов шрифтов |
| Скорость генерации | 10-20 секунд | 3-8 секунд | Для быстрой итерации выбирайте Banana 2 |
| Цена API | ~$0.04/вызов | ~$0.02/вызов | При чувствительности к стоимости выбирайте Banana 2 |
| Возможность итеративного исправления | Отлично | Отлично | Оба на одном уровне |
| ID модели | gemini-3.0-pro-image |
gemini-3.1-flash-image-preview |
Можно вызывать одновременно через APIYI apiyi.com |
Рекомендации по выбору модели для рендеринга текста
- Коммерческие постеры/брендовые материалы: Выбирайте Nano Banana Pro — 94% точность + больше стилей шрифтов
- Изображения для соцсетей/быстрые прототипы: Выбирайте Nano Banana 2 — высокая скорость + отличное соотношение цены и качества
- Сценарии, требующие многократных итераций: Выбирайте Nano Banana 2 — высокая скорость означает низкую стоимость итераций
- Многоязычный текст: Различия между моделями незначительны, выбирайте исходя из требований к скорости/стоимости
Часто задаваемые вопросы
Q1: Почему Google официально рекомендует «сначала генерировать текст, а затем изображение»?
Это связано с тем, что когда мультимодальная модель одновременно обрабатывает две задачи — "генерацию текстового контента" и "рендеринг текста на изображении" — ресурсы внимания конкурируют друг с другом, что приводит к снижению точности текста. Двухэтапный подход, разделяя задачи, позволяет модели на первом этапе сосредоточиться на корректности текста (в режиме чистого текста, с точностью почти 100%), а на втором — на рендеринге уже определённого текста на изображении. Этот принцип похож на то, как дизайнер сначала определяет текст, а затем приступает к дизайну. Вызов по двухэтапному методу через платформу APIYI apiyi.com очень удобен, а общая стоимость двух вызовов API составляет менее $0.05.
Q2: Ограничение в 25 символов является жёстким? Обязательно ли возникнут ошибки, если его превысить?
Это не жёсткое ограничение, а скорее водораздел для точности. В пределах 25 символов точность составляет 85-98%, но после превышения 25 символов она значительно падает ниже 60%. Если вам необходимо использовать более длинный текст, рекомендуется разбить его на несколько строк (не более 15 символов в каждой) или добавлять постепенно с помощью многораундового диалога.
Q3: Каково качество рендеринга китайского текста? Значительно ли оно хуже, чем для английского?
Nano Banana значительно лучше справляется с рендерингом китайского текста, чем большинство конкурентов, но всё же немного уступает английскому. Фактическая точность для китайского языка составляет около 85% (для английского — 94%). Рекомендуется ограничивать китайский текст 8 иероглифами, использовать жирный шрифт и явно указывать в промпте "Chinese text" и "Chinese calligraphy font" или "bold Chinese font". Через платформу APIYI apiyi.com можно быстро протестировать эффект рендеринга китайского текста с различными вариантами промптов.
Q4: Увеличит ли двухэтапный подход значительно стоимость?
Двухэтапный подход действительно требует двух вызовов API, но первый этап — это генерация чистого текста (без изображений), что очень дёшево (менее $0.001). Второй этап — это уже генерация изображений ($0.02-$0.04). Таким образом, общая стоимость увеличивается менее чем на 5%, но точность текста значительно повышается. Учитывая, что без двухэтапного подхода может потребоваться 3-5 попыток для получения правильного текста, двухэтапный подход на самом деле экономит деньги.
Q5: Существует ли метод, который полностью исключает ошибки?
В настоящее время рендеринг текста при генерации изображений с помощью ИИ не может гарантировать 100% точность. Даже при использовании всех методов оптимизации, всё равно рекомендуется включать этап ручной проверки в рабочий процесс — особенно для изображений, предназначенных для коммерческого использования. Для сценариев, требующих абсолютной точности (например, скриншоты юридических документов, официальные сертификаты), рекомендуется использовать ИИ для генерации фона и композиции, а текстовую часть накладывать позже с помощью дизайнерских инструментов.
Итоги
Способность Nano Banana к рендерингу текста в области генерации AI-изображений уже находится на высшем уровне (Pro 94%, Banana 2 87%), но для стабильного использования этой возможности нужно освоить правильные техники.
6 основных техник, отсортированных по важности:
- Двухэтапный подход — сначала генерируем текст, затем изображение; официально рекомендован, эффект наиболее заметен.
- Правило 25 символов — контролируем длину текста, слишком длинный текст разбиваем на части.
- Двойные кавычки + указание шрифта — принудительный посимвольный рендеринг + выбор шрифта с высокой точностью.
- Специальная обработка для разных языков — используем разные стратегии для разных языков.
- Структурированный шаблон промпта — стандартизация повышает стабильность.
- Многократная итерация и корректировка — если результат не устраивает, итерируем и оптимизируем.
Освоив эти техники, рендеринг текста в Nano Banana перестанет быть "удачей" и станет предсказуемой и управляемой возможностью. Рекомендуем быстро начать тестирование через APIYI apiyi.com, чтобы найти оптимальную комбинацию параметров для вашего сценария.
Ссылки
-
Официальная документация Google — Генерация изображений Nano Banana
- Ссылка:
ai.google.dev/gemini-api/docs/image-generation - Описание: Содержит официальные рекомендации по "сначала генерировать текст, затем изображение".
- Ссылка:
-
Блог Google Developers — Советы по промптам для Nano Banana Pro
- Ссылка:
blog.google/products/gemini/prompting-tips-nano-banana-pro/ - Описание: Официальные советы по оптимизации промптов.
- Ссылка:
-
Блог Google Developers — Как создавать промпты для генерации изображений Gemini 2.5 Flash
- Ссылка:
developers.googleblog.com/how-to-prompt-gemini-2-5-flash-image-generation-for-the-best-results/ - Описание: Стратегии оптимизации генерации изображений для моделей серии Flash.
- Ссылка:
📝 Автор: Команда APIYI | Для технического обмена и подключения к API посетите apiyi.com