Nota do autor: O gpt-5.4-nano da OpenAI, o mais barato de todos, custa apenas $0,20/$1,25, com um desempenho no τ2-Bench de 92,5%, quase igualando o mini. Este artigo detalha os 7 cenários de aplicação mais adequados para o nano, quando substituí-lo pelo mini e a estratégia de otimização definitiva com 90% de desconto via cache.
Se a sua aplicação realiza mais de 10 mil chamadas por dia, ou se você está selecionando modelos para tarefas de alto throughput como atendimento ao cliente, classificação ou roteamento de RAG, você deve ter notado que a OpenAI reduziu o "preço base" da série GPT-5.4 para um novo patamar: gpt-5.4-nano, $0,20 de entrada / $1,25 de saída por 1 milhão de tokens, sendo a entrada 3,75 vezes mais barata que a do 5.4-mini.
Isso não é apenas um "modelo barato capado". Os benchmarks divulgados pela OpenAI mostram que o nano atinge 92,5% em chamadas de ferramentas (τ2-Bench), quase empatando com os 93,4% do mini; e alcança 82,8% em conhecimentos gerais (GPQA Diamond), apenas 5,2 pontos percentuais abaixo do mini. Isso significa que, para uma vasta gama de cenários de "alto throughput e baixa complexidade", o nano é a verdadeira solução ideal.
Valor central: Este artigo analisa 7 cenários de aplicação específicos, detalhando em quais tarefas o nano é "suficiente e mais barato", em quais você "deve usar o mini", e fornece trechos de código e estimativas de custo para cada caso.

Pontos principais dos cenários de aplicação do GPT-5.4 nano
| Ponto | Descrição | Valor |
|---|---|---|
| Preço ultra baixo | $0,20 / $1,25 por 1M tokens | 3,75x mais barato que o 5.4-mini |
| Cache -90% | Entrada em cache por apenas $0,02 / 1M | Quase gratuito para contextos frequentes |
| Chamada de ferramentas próxima ao mini | τ2-Bench 92,5% vs mini 93,4% | Suficiente para a maioria dos cenários de uso de ferramentas |
| Forte em Q&A | GPQA Diamond 82,8% | Capaz em FAQ geral e busca de conhecimento |
| Contexto longo de 400K | 400K de entrada + 128K de saída | Processamento em lote de documentos longos sem pressão |
| Velocidade líder | ~200 t/s, 10% mais rápido que o mini | Primeira escolha para pipelines de alto throughput |
Como determinar o "limiar de suficiência" do GPT-5.4 nano
Para determinar se o nano é suficiente, você pode usar uma simples "classificação em três zonas":
Zona Verde (use o nano sem medo): Chamada de ferramentas, extração estruturada, classificação e rotulagem, perguntas e respostas, roteamento de conteúdo, tradução/resumo em lote — nessas tarefas, a diferença de pontuação do nano para o mini é inferior a 10 pontos percentuais, e a vantagem de preço supera totalmente a diferença de capacidade.
Zona Amarela (avalie com cautela): Raciocínio complexo em várias etapas, orquestração de Agentes de longa cadeia, geração de código — o SWE-Bench Pro de 52,4% ainda é capaz, mas recomendamos rodar um teste AB com o nano antes de decidir.
Zona Vermelha (use o mini diretamente): Uso de computador (Computer Use, o nano no OSWorld tem apenas 39%), tarefas longas de terminal (46,3% é fraco), cenários personalizados que exigem Fine-tuning — nesses cenários, o desempenho do nano claramente não acompanha, escolha diretamente o mini ou a versão padrão.

Cenário de aplicação 1 do GPT-5.4 nano: Classificação em tempo real
Descrição do cenário
A classificação em tempo real é a aplicação mais clássica do nano — incluindo análise de sentimento, reconhecimento de intenção, marcação de tópicos, moderação de conteúdo, entre outros. Essas tarefas geralmente exigem apenas algumas centenas de tokens de entrada e algumas dezenas de tokens de saída por invocação do modelo, sendo extremamente sensíveis à latência e ao custo.
Exemplo de código minimalista
import openai
import json
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
def classify_intent(user_query: str) -> dict:
"""Classifica a intenção da consulta do usuário"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Você é um classificador de intenções. Retorne no formato JSON: {intent, confidence, sub_category}"},
{"role": "user", "content": user_query}
],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# Uso
result = classify_intent("Eu quero cancelar meu pedido da semana passada")
# {"intent": "refund_request", "confidence": 0.95, "sub_category": "subscription_cancel"}
Estimativa de custos
| Escala do cenário | Custo por chamada | Custo diário (100 mil chamadas) |
|---|---|---|
| Atendimento básico(50 entrada + 20 saída) | $0.000035 | $3.5 |
| SaaS de médio porte(200 entrada + 30 saída) | $0.000078 | $7.8 |
| Nível empresarial(500 entrada + 50 saída) | $0.000163 | $16.3 |
💡 Dica de otimização: Coloque os rótulos de classificação e exemplos no comando do sistema. Ao ativar o cache, o custo de entrada pode ser reduzido em mais 90%. Ao utilizar o serviço proxy de API da APIYI (apiyi.com), os descontos de cache são totalmente sincronizados.
Cenário de aplicação 2 do GPT-5.4 nano: Extração de dados
Descrição do cenário
Extrair campos estruturados de textos não estruturados (currículos, contratos, notícias, e-mails). Este é um ponto forte do nano — ao combinar com Structured Outputs (restrição rigorosa de esquema JSON), é possível atingir uma taxa de precisão de formato superior a 99%.
Código prático
from pydantic import BaseModel
from typing import Optional
class ContactInfo(BaseModel):
name: str
email: Optional[str]
phone: Optional[str]
company: Optional[str]
role: Optional[str]
def extract_contact(text: str) -> ContactInfo:
# Extrai informações de contato, retorna null para campos ausentes
response = client.beta.chat.completions.parse(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Extraia informações de contato, retorne null para campos ausentes"},
{"role": "user", "content": text}
],
response_format=ContactInfo
)
return response.choices[0].message.parsed
Lista de tarefas de extração adequadas para o nano
- Extração de campos-chave de currículos/CVs
- Reconhecimento numérico de faturas/recibos
- Análise de blocos de assinatura de e-mail
- Reconhecimento de entidades em notícias (nomes de pessoas, locais, organizações)
- Normalização de dados de formulários
- Classificação de eventos de log
GPT-5.4 nano Cenário de aplicação 3: Ordenação de conteúdo
Descrição do cenário
Realizar o reordenamento de resultados de busca, listas de recomendação e filas de mensagens. O baixo custo do nano torna o uso de um Modelo de Linguagem Grande como "reranker" economicamente viável em ambientes de produção.
Exemplo de código para reordenamento
def rerank_documents(query: str, candidates: list[str], top_k: int = 5) -> list:
"""Reordena documentos candidatos com base na relevância da consulta"""
docs_text = "\n".join([f"[{i}] {doc[:300]}" for i, doc in enumerate(candidates)])
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{
"role": "user",
"content": f"""Ordene os documentos abaixo por relevância com base na consulta "{query}".
Documentos:
{docs_text}
Retorne em JSON: {{"ranking": [lista de índices dos documentos, do mais relevante para o menos relevante]}}"""
}],
response_format={"type": "json_object"}
)
ranking = json.loads(response.choices[0].message.content)["ranking"]
return [candidates[i] for i in ranking[:top_k]]
🎯 Sugestão de cenário: O reordenamento com nano possui uma precisão maior do que o reranker tradicional de BM25 + busca vetorial, mas com um custo de apenas 27% do GPT-5.4-mini. Você pode acessar diretamente via APIYI apiyi.com, sem necessidade de solicitações para o grupo padrão.
GPT-5.4 nano Cenário de aplicação 4: Camada de execução de Sub-agent
Descrição do cenário
Em arquiteturas multi-agente, o agente principal (geralmente usando a versão mini ou padrão) é responsável pelo planejamento, enquanto o Sub-agent (worker de execução) cuida das chamadas de ferramentas, consultas de dados e atualizações de status. A pontuação de 92,5% do nano no τ2-Bench o torna totalmente capaz de desempenhar o papel de worker.
Exemplo de colaboração multi-agente
def execute_subtask(task: dict, available_tools: list) -> dict:
"""nano atuando como Sub-agent para executar uma subtarefa individual"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": f"Você é um worker de execução. Ferramentas disponíveis: {available_tools}"},
{"role": "user", "content": f"Execute a tarefa: {task['description']}"}
],
tools=task.get("tools", []),
tool_choice="auto"
)
return {
"task_id": task["id"],
"result": response.choices[0].message.content,
"tool_calls": response.choices[0].message.tool_calls
}
# Agente principal usa mini, Sub-agent usa nano — economia de custos superior a 60%
GPT-5.4 nano Cenário de aplicação 5: Camada de roteamento RAG
Descrição do cenário
Em sistemas RAG, o nano atua como uma "camada de roteamento" para identificar o tipo de consulta (questões técnicas / pré-venda / feedback de produto / conversa fiada) e distribuí-la para os processadores adequados. Esse design garante que as versões mini/padrão, que são mais caras, sejam acionadas apenas quando realmente necessário.
Exemplo de roteamento RAG
def route_query(query: str) -> str:
"""nano determina para qual processador RAG a consulta deve ser roteada"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": """Retorne a etiqueta de roteamento com base no tipo de consulta:
- "technical_docs": consulta de documentação técnica
- "product_faq": FAQ do produto
- "code_help": ajuda com código
- "small_talk": conversa fiada (não requer RAG)
- "complex_reasoning": raciocínio complexo (encaminhar para mini/versão padrão)"""},
{"role": "user", "content": query}
],
max_tokens=20
)
return response.choices[0].message.content.strip()
route = route_query(user_input)
if route == "complex_reasoning":
final_model = "gpt-5.4-mini" # Upgrade para mini
else:
final_model = "gpt-5.4-nano" # Continua com nano
💰 Otimização de custos: Esta arquitetura de "roteamento nano + processamento mini/padrão" geralmente reduz os custos totais de invocação do modelo em 60-80%. Você pode alternar entre os dois modelos de forma flexível usando a mesma chave API através do APIYI (apiyi.com), bastando alterar o parâmetro model.
GPT-5.4 nano Cenário de aplicação 6: Resumo e tradução de alto throughput
Descrição do cenário
Processamento em lote de resumos de notícias, tradução de documentos, reescrita de comentários, entre outras tarefas. Com o suporte a uma janela de contexto de 400K, o nano pode processar um artigo longo de uma só vez, com um custo por unidade quase desprezível.
Exemplo de Batch API
# Preparar tarefas em lote
batch_requests = []
for doc_id, content in documents.items():
batch_requests.append({
"custom_id": f"summary-{doc_id}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-nano",
"messages": [
{"role": "system", "content": "Resuma o conteúdo a seguir em 100 palavras"},
{"role": "user", "content": content}
],
"max_tokens": 200
}
})
# Enviar Batch API (mesmo preço, mas não consome a cota online)
batch = client.batches.create(
input_file_id=file_id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
GPT-5.4 nano Cenário de Aplicação 7: Uso de Ferramentas (Tool Use)
Descrição do Cenário
No benchmark τ2-Bench, o nano alcançou 92,5%, quase empatando com os 93,4% do mini. Para cenários padronizados de function calling, como "consultar previsão do tempo, verificar pedidos ou pesquisar documentos", o nano é perfeitamente capaz.
Exemplo de Function Calling
tools = [{
"type": "function",
"function": {
"name": "get_order_status",
"description": "Consulta o status do pedido",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"}
},
"required": ["order_id"]
}
}
}]
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{"role": "user", "content": "Como está o meu pedido #12345?"}],
tools=tools,
tool_choice="auto"
)
# O nano identifica com precisão a necessidade de chamar get_order_status, extraindo order_id="12345"
Detalhes de Preços do GPT-5.4 nano
Estrutura de Preços Oficial
| Tipo de Cobrança | Preço (por 1M de tokens) | Observação |
|---|---|---|
| Entrada | $0,20 | Preço padrão |
| Entrada em Cache | $0,02 | 90% de desconto |
| Saída | $1,25 | Inclui tokens de raciocínio |
| Batch API | $0,20 / $1,25 | Mesmo preço, não consome cota online |
| Residência de Dados Regional | +10% | Cenários de conformidade de dados |
Comparação de Preços: nano vs mini
| Dimensão | gpt-5.4-nano | gpt-5.4-mini | Multiplicador |
|---|---|---|---|
| Entrada | $0,20 | $0,75 | nano é 3,75x mais barato |
| Entrada em Cache | $0,02 | $0,075 | nano é 3,75x mais barato |
| Saída | $1,25 | $4,50 | nano é 3,6x mais barato |
| Velocidade de Resposta | ~200 t/s | ~180 t/s | nano é ~10% mais rápido |
| Contexto | 400K | 400K | Empatado |
| Saída Máxima | 128K | 128K | Empatado |
💰 Otimização de Custos: Para cenários de alto throughput com milhões de requisições por dia, a diferença de preço entre o nano e o mini pode acumular milhares de dólares por mês. Ao acessar via APIYI (apiyi.com), você ainda aproveita 10% de bônus em recargas de 100 dólares, o que equivale a um desconto de 15% sobre o preço oficial, resultando em um custo total até 25% menor que o site oficial.
Comparativo completo: GPT-5.4 nano vs. mini
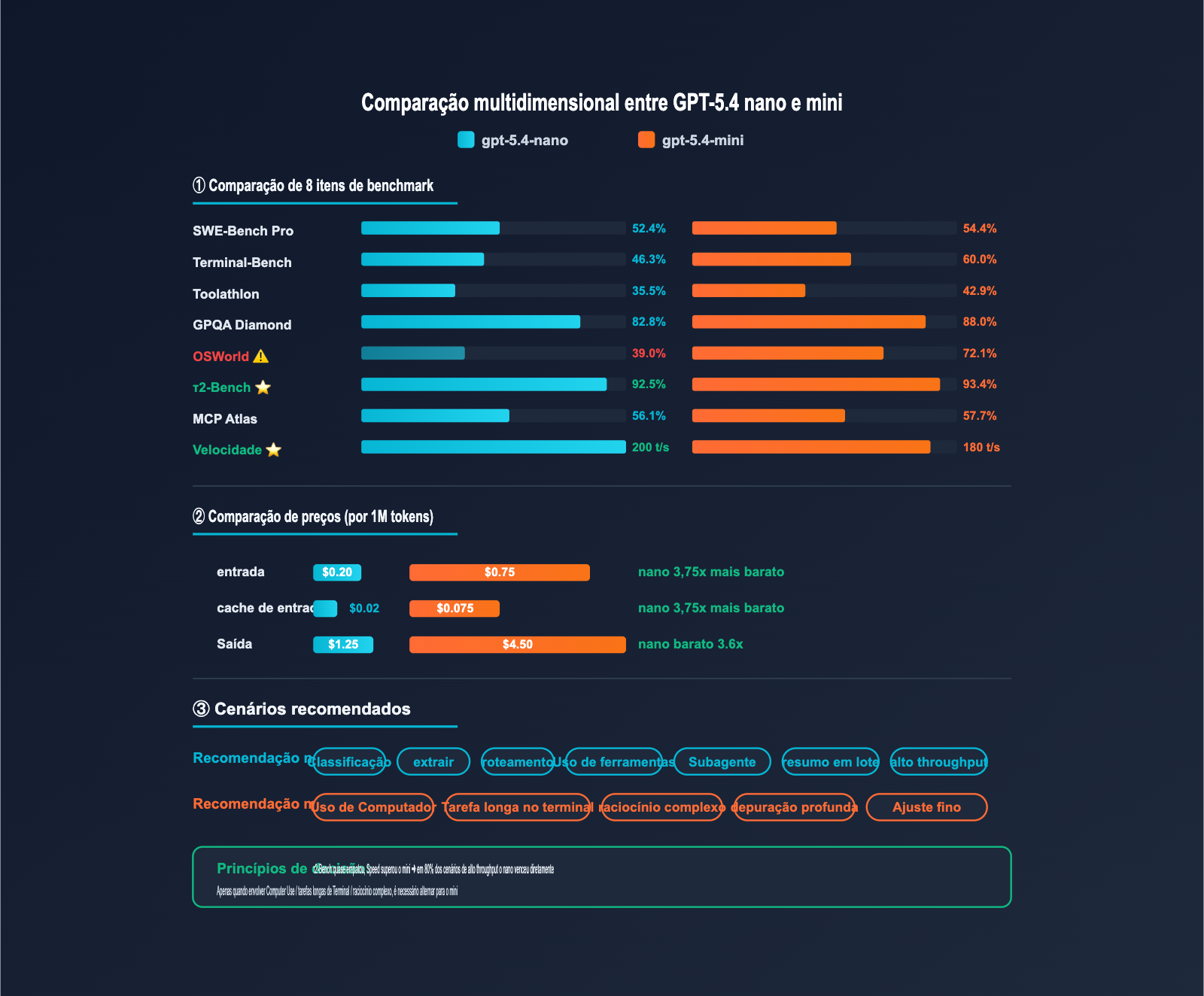
| Dimensão de Avaliação | gpt-5.4-nano | gpt-5.4-mini | Diferença | nano é suficiente? |
|---|---|---|---|---|
| SWE-Bench Pro | 52.4% | 54.4% | -2.0pp | ✅ Quase igual |
| Terminal-Bench 2.0 | 46.3% | 60.0% | -13.7pp | ⚠️ Use mini para tarefas longas |
| Toolathlon | 35.5% | 42.9% | -7.4pp | ✅ Suficiente para tarefas comuns |
| GPQA Diamond | 82.8% | 88.0% | -5.2pp | ✅ Capaz em perguntas de conhecimento |
| OSWorld-Verified | 39.0% | 72.1% | -33.1pp | ❌ Use mini para Computer Use |
| τ2-Bench(Tool Use) | 92.5% | 93.4% | -0.9pp | ✅ Quase igual |
| MCP Atlas | 56.1% | 57.7% | -1.6pp | ✅ Quase igual |
| Velocidade de resposta | ~200 t/s | ~180 t/s | +10% | ✅ nano é mais rápido |
Recomendações de escolha
Quando priorizar o nano:
- Tarefas na "zona verde" (classificação, extração, ordenação, roteamento, uso de ferramentas, processamento em lote)
- Volume de chamadas > 10 mil/dia, sensível a custos
- Necessidade de latência < 1 segundo
- Camada de execução de sub-agentes (use mini para o agente principal, nano para os trabalhadores)
Quando atualizar para o mini:
- Envolvimento com Computer Use (diferença decisiva no OSWorld)
- Tarefas longas no terminal (>10 passos)
- Necessidade de raciocínio complexo em várias etapas ou depuração profunda de código
- Quando a qualidade da tarefa é mais importante que o custo
📊 Dica de ouro: Em 80% dos cenários de "alto throughput + baixa complexidade", o custo-benefício do nano supera o do mini. Você pode comparar diretamente o desempenho de ambos em suas tarefas específicas através do serviço proxy de API da APIYI (apiyi.com), bastando alterar o parâmetro
model.
Instruções de integração do GPT-5.4 nano na APIYI
Disponível diretamente no grupo Default
A plataforma APIYI adota a mesma estratégia de abertura para o GPT-5.4 nano e o 5.4-mini:
- ✅ Grupo Default (Padrão): Totalmente aberto, disponível para invocação logo após o registro do novo usuário.
- ✅ Grupo SVIP (Avançado): Totalmente aberto, sem qualquer restrição.
- ✅ Sincronização de desconto de cache: O preço de $0,02/1M de cache é totalmente aplicável.
- ✅ Sincronização de Batch API: Tarefas em lote também aproveitam o mesmo preço.
Comparação de custos: APIYI vs. Site Oficial
| Item | Site Oficial da OpenAI | APIYI (apiyi.com) |
|---|---|---|
| Preço base | $0,20 / $1,25 por 1M | $0,20 / $1,25 por 1M (mesmo preço) |
| Desconto de cache | $0,02 / 1M (90%) | $0,02 / 1M (totalmente sincronizado) |
| Bônus de recarga | Nenhum | Recarregue $100 e ganhe $10 (10%) |
| Custo real | 100% do preço padrão | Aprox. 90% do preço padrão (cerca de 15% de desconto) |
| Acesso no Brasil/China | Requer VPN | Conexão direta, sem necessidade de VPN |
| Método de pagamento | Cartão de crédito internacional | Suporte a RMB, Alipay, WeChat |
| Compatibilidade SDK | Nativo OpenAI | Totalmente compatível com o SDK da OpenAI |
| Valor mínimo de recarga | $5 | A partir de $1 |
💰 Otimização de custos: Para aplicações com volume de chamadas superior a um milhão por mês, a integração do nano via APIYI (apiyi.com) permite combinar o desconto de cache com o bônus de recarga, resultando em um custo total de 25% a 35% menor do que a chamada direta pelo site oficial da OpenAI.
Perguntas Frequentes (FAQ)
Q1: O que é o gpt-5.4-nano? Qual a principal diferença para o gpt-5.4-mini?
O GPT-5.4-nano é o Modelo de Linguagem Grande mais barato e rápido da série GPT-5.4 da OpenAI ($0,20/$1,25 por 1M de tokens), com uma velocidade de resposta de cerca de 200 t/s. As diferenças principais em relação ao 5.4-mini são: 1) Preço de 3,6 a 3,75 vezes menor; 2) Desempenho em Computer Use (OSWorld 39% vs 72,1%) e tarefas longas no Terminal (46,3% vs 60%) significativamente inferior; 3) Em outros cenários (classificação, extração, uso de ferramentas, perguntas e respostas), a diferença geralmente é inferior a 10pp.
Q2: Para quais cenários o nano é mais indicado? Quais exigem o uso do mini?
Indicado para o nano (Zona Verde):
- Classificação em tempo real (sentimento, intenção, tópico)
- Extração de dados estruturados
- Ordenação e reordenamento de conteúdo
- Camada de execução de sub-agentes
- Camada de roteamento RAG
- Resumo/tradução de alto throughput
- Invocação de ferramentas padronizadas (τ2-Bench 92,5%)
Cenários que exigem o mini (Zona Vermelha):
- Automação de desktop via Computer Use (diferença de 33pp no OSWorld)
- Tarefas longas no Terminal (>10 passos)
- Raciocínio complexo de várias etapas
- Cenários personalizados que exigem Fine-tuning
Q3: Por que o nano não é recomendado para Computer Use?
Na avaliação OSWorld-Verified, o nano obteve apenas 39,0%, muito abaixo dos 72,1% do mini. Isso significa que, em operações de desktop de várias etapas (abrir navegador -> pesquisar -> clicar -> preencher formulário), a taxa de falha do nano é muito alta, impossibilitando a conclusão estável da cadeia de tarefas. Se o seu cenário exige Computer Use, escolha diretamente o mini ou a versão padrão do 5.4.
Q4: Como ativar o desconto de cache de $0,02/1M do nano?
O mecanismo de cache da OpenAI é acionado automaticamente, sem necessidade de parâmetros extras. Ele é ativado quando o prefixo do comando (geralmente o system prompt + contexto compartilhado) é consistente com as solicitações dos últimos 5 a 10 minutos, garantindo o desconto de 90%.
Dicas de otimização:
- Coloque o system prompt no início do array de mensagens.
- O contexto compartilhado (tags de classificação, definição de Schema) deve vir logo em seguida.
- Coloque a consulta real do usuário no final.
- Mantenha a frequência de chamadas (expira após >5 minutos).
Ao realizar a invocação via APIYI (apiyi.com), o desconto de cache é totalmente sincronizado com o site oficial.
Q5: Quais as melhores práticas para tarefas em lote com o nano?
Três estratégias principais:
- Use a Batch API: Utilize a interface
/v1/batchespara enviar tarefas em lote. Elas são concluídas em até 24 horas, mantêm o preço, mas não consomem a cota de RPM online. - Compartilhe o system prompt: Use as mesmas instruções para todas as tarefas para acionar o cache.
- Defina um max_tokens razoável: A saída do nano é barata, mas o acúmulo gera custos; defina um limite razoável entre 50-500 tokens.
Ao enviar tarefas em lote via APIYI (apiyi.com), você aproveita o bônus de 10% na recarga, reduzindo o custo real para cerca de 85% do valor oficial.
Q6: Como invocar o GPT-5.4 nano através da APIYI?
A APIYI é totalmente compatível com o SDK da OpenAI. Basta seguir três passos:
- Acesse apiyi.com e registre uma conta (sem necessidade de solicitação, o grupo Default está disponível imediatamente).
- Obtenha sua chave API.
- Altere o
base_urldo seu código parahttps://vip.apiyi.com/v1e defina o modelo comogpt-5.4-nano.
client = openai.OpenAI(
api_key="SUA_CHAVE",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[...]
)
Recargas de 100 dólares ganham 10% de bônus, equivalente a cerca de 15% de desconto sobre o preço oficial, com sincronização do desconto de cache.
Q7: Quando o nano compensa mais que o mini? Como calcular?
Fórmula de decisão:
Condição de vantagem do nano = (Tolerância à degradação da qualidade) × (Volume de chamadas) × (Diferença de preço)
> (Ganhos de qualidade ao subir para o mini)
Cenários reais:
- Volume > 10K/dia: Economia > $30/dia ($1000/mês)
- Volume > 100K/dia: Economia > $300/dia ($9000/mês)
- Volume > 1M/dia: Economia > $3000/dia ($90000/mês)
Para tarefas na zona verde (classificação, extração, uso de ferramentas), a perda de qualidade do nano é geralmente < 5%, mas a economia de custos é de 73% (fator de 3,6x no cálculo puro). O ROI geral quase sempre favorece o nano.
Q8: Quais são as limitações conhecidas do GPT-5.4 nano?
Principais limitações:
- Sem suporte a Computer Use: O desempenho de 39% no OSWorld é muito baixo para automação de desktop estável.
- Sem suporte a Fine-tuning: Não é possível realizar ajustes finos com datasets personalizados.
- Sem suporte a entrada de áudio/vídeo: Apenas entrada de texto e imagem.
- Fraco em tarefas longas no Terminal: 46,3% no Terminal-Bench; operações com mais de 10 passos tendem a falhar.
- Capacidade de raciocínio complexo limitada: 82,8% no GPQA, próximo ao mini, mas o desempenho cai significativamente em tarefas extremamente difíceis como o FrontierMath.
Alternativa: Ao encontrar essas limitações, mude diretamente para o gpt-5.4-mini ou para a versão padrão 5.4.
Pontos principais dos cenários de aplicação do GPT-5.4 nano
- Preço base: $0,20/$1,25 por 1 milhão de tokens, 3,6 a 3,75 vezes mais barato que o 5.4-mini.
- Desconto de 90% em cache: Entrada a partir de $0,02/1M, tornando cenários de contexto de alta frequência praticamente gratuitos.
- 7 principais cenários "zona verde": Classificação, extração, ordenação, subagentes, roteamento, processamento em lote e uso de ferramentas (Tool Use).
- τ2-Bench 92,5%: A invocação de ferramentas quase empata com o mini; suficiente para mais de 90% dos cenários de Function Calling.
- GPQA 82,8%: Forte capacidade de resposta a conhecimentos gerais, ideal para FAQs e moderação de conteúdo.
- Velocidade de 200 t/s: 10% mais rápido que o mini, sendo a escolha preferencial para pipelines de alta vazão.
- Alerta de "zona vermelha": Tarefas longas de Computer Use ou Terminal devem ser obrigatoriamente alternadas para o mini.
Resumo
Pontos principais sobre os cenários de aplicação do GPT-5.4 nano:
- Posicionamento de cenário: O nano é a melhor escolha para tarefas de alta vazão e baixa complexidade — classificação em tempo real, extração de dados, subagentes, roteamento de RAG e processamento em lote são seu campo de atuação principal.
- Limites de capacidade: O desempenho em τ2-Bench / GPQA / SWE-Bench Pro quase empata com o mini, mas as capacidades em tarefas longas de Computer Use / Terminal são visivelmente mais fracas.
- Como acessar: Acesse diretamente pelo grupo padrão da APIYI (apiyi.com), com descontos de cache sincronizados e bônus de 10% em recargas acima de 100.
O GPT-5.4 nano não é um produto barato que "faz tudo, mas nada bem feito", mas sim uma ferramenta leve e otimizada pela OpenAI especificamente para cenários de alta vazão e baixa complexidade. Se a sua aplicação se encaixa nos 7 cenários de "zona verde" listados aqui, o nano é quase sempre mais econômico que o mini. No entanto, se o projeto envolver Computer Use ou tarefas longas de Terminal, mudar para o mini é a escolha correta.
Recomendamos o acesso rápido ao GPT-5.4 nano através da plataforma APIYI (apiyi.com). O grupo padrão não exige solicitação, os descontos de cache são totalmente sincronizados, há um bônus de 10% em recargas e a conexão é estável a partir do Brasil.
Leitura Complementar
Se você se interessou pela API do GPT-5.4 nano, recomendo continuar a leitura com estes conteúdos:
- 📘 Guia de atualização da API GPT-5.4 mini – Entenda as capacidades e os cenários de uso do modelo mini da geração anterior.
- 📊 Análise profunda do mecanismo de cache da OpenAI: Melhores práticas para 90% de desconto – Domine as técnicas de engenharia para otimização de cache.
- 🚀 Prática de construção de camada de roteamento RAG baseada em GPT-5.4 nano – Explore a arquitetura híbrida de "roteamento nano + processamento mini".
📚 Referências
-
Documentação oficial do GPT-5.4 nano da OpenAI: especificações do modelo, preços e exemplos de invocação.
- Link:
developers.openai.com/api/docs/models/gpt-5.4-nano - Descrição: Obtenha os parâmetros técnicos oficiais mais recentes e confiáveis.
- Link:
-
Análise de Benchmark do AI Cost Check: avaliação multidimensional entre nano e mini.
- Link:
aicostcheck.com/blog/gpt-5-4-mini-nano-pricing-benchmarks - Descrição: Avaliação de terceiros, ideal para comparação horizontal das diferenças de capacidade.
- Link:
-
Documentação de acesso ao GPT-5.4 nano da APIYI: soluções de invocação no país, instruções de agrupamento e descontos em recargas.
- Link:
docs.apiyi.com - Descrição: Guia prático de integração para desenvolvedores locais.
- Link:
-
Página de preços da OpenAI: tabela completa de preços e explicações sobre o mecanismo de cache.
- Link:
developers.openai.com/api/docs/pricing - Descrição: Padrões de cobrança mais recentes para todos os modelos.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir suas experiências com o GPT-5.4 nano na seção de comentários. Para mais materiais sobre a integração de modelos, visite o centro de documentação da APIYI em docs.apiyi.com.