Nota do autor: A mais recente série mini da OpenAI, o gpt-5.4-mini, já está disponível via API. Com 54,4% no SWE-Bench Pro, ele supera os 45,7% do GPT-5 mini. Este artigo traz uma análise completa sobre seu salto de desempenho, o desconto de 90% no cache de entrada e as decisões de upgrade em relação ao 4o-mini/5-mini.
Se você ainda usa o gpt-4o-mini ou o gpt-5-mini, talvez já tenha notado que a OpenAI lançou em 17/03/2026 o que chamam de "nosso modelo mini mais poderoso até hoje" — o gpt-5.4-mini. Ele alcançou 54,4% no SWE-Bench Pro (contra 45,7% do GPT-5 mini), 60,0% no Terminal-Bench 2.0 e 72,1% no OSWorld-Verified para tarefas de Computer Use, tudo isso com uma velocidade de resposta duas vezes mais rápida que a geração anterior.
Embora pareça apenas uma atualização menor, a intenção por trás do design vai muito além disso. A OpenAI posicionou oficialmente o gpt-5.4-mini como um modelo mini "otimizado para programação, Computer Use e subagentes" — é a primeira vez que a série mini traz capacidades de agente para a faixa de preço de entrada. Este artigo detalha o que é o GPT-5.4 mini, onde ele supera o 4o-mini/5-mini e o que isso significa para o seu trabalho na prática.
Valor central: Uma análise completa do plano de integração do GPT-5.4 mini, abordando o salto de capacidade, estrutura de preços, otimização de cache e critérios de decisão para o upgrade.

Principais pontos do GPT-5.4 mini API
| Ponto | Descrição | Valor |
|---|---|---|
| Salto de capacidade | SWE-Bench Pro 54,4% vs GPT-5 mini 45,7% | 19% de aumento na precisão de tarefas de codificação |
| Contexto longo de 400K | 400.000 tokens de entrada + 128.000 de saída | Processamento de bases de código/documentos longos |
| 90% de desconto no cache | Cache de entrada por apenas $0,075/1M | Redução drástica de custos em cenários de contexto frequente |
| Computer Use | OSWorld-Verified 72,1% | Suporte total à automação de desktop pela primeira vez na série mini |
| Acesso total padrão | Disponível no grupo padrão da APIYI | Uso imediato para novos usuários, sem necessidade de solicitação |
Diferenças principais entre o GPT-5.4 mini e a geração anterior
O GPT-5.4 mini não é apenas uma "versão com preço reduzido". A OpenAI realizou atualizações substanciais em três dimensões:
Primeiro, a orquestração de subagentes chega pela primeira vez à faixa de preço mini. Antigamente, era quase impossível fazer com que um modelo mini coordenasse de forma confiável múltiplos subagentes ou gerenciasse cadeias de chamadas de ferramentas — eles geralmente perdiam o contexto ou ignoravam comandos após 3 ou 4 etapas. O GPT-5.4 mini, através de um mecanismo aprimorado de Reasoning Tokens e treinamento de seguimento de instruções, alcançou cerca de 90% da confiabilidade da versão padrão do GPT-5.4 em cenários de colaboração entre agentes, custando apenas 1/6 do valor.
Segundo, suporte total a Computer Use. O GPT-5.4 mini é o primeiro da série mini da OpenAI a levar o OSWorld-Verified para mais de 70%. Isso significa que você pode implantar agentes de automação de desktop completos com o custo de um modelo mini, realizando cliques, preenchimento de formulários e operações de arquivos.
Terceiro, aumento de 2x na velocidade de resposta. Ao manter o salto de capacidade, o GPT-5.4 mini é duas vezes mais rápido que o GPT-5 mini. Para cenários de alto throughput (atendimento ao cliente, processamento em lote), isso representa uma economia direta de custos.

Guia Rápido da API GPT-5.4 mini
Exemplo Python Minimalista (Substituindo o modelo mini antigo)
Se você já estava usando o gpt-4o-mini ou o gpt-5-mini, basta alterar o parâmetro model para mudar para o gpt-5.4-mini. O restante do código permanece exatamente o mesmo:
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini", # Apenas esta linha muda
messages=[
{"role": "user", "content": "Implemente um cache concorrente com suporte a LRU em Python"}
]
)
print(response.choices[0].message.content)
Exemplo cURL Minimalista
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer SUA_CHAVE_API" \
-d '{
"model": "gpt-5.4-mini",
"messages": [
{"role": "user", "content": "Resuma os pontos principais deste documento longo"}
]
}'
Paradigma de Chamada Computer Use (Suportado pela primeira vez na série mini)
# Habilitar ferramentas de Computer Use
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{
"role": "user",
"content": "Ajude-me a abrir o navegador, pesquisar por 'documentação da API OpenAI' e clicar no primeiro resultado"
}],
tools=[{
"type": "computer_use",
"config": {
"screen_width": 1920,
"screen_height": 1080
}
}]
)
# O modelo retorna instruções de operação estruturadas (click/type/scroll, etc.)
for action in response.choices[0].message.tool_calls:
print(f"Ação: {action.function.name}, Parâmetros: {action.function.arguments}")
Ver código completo de chamada em ambiente de produção (incluindo rastreamento de cache e estatísticas de custo)
import openai
from typing import List, Dict
# Preços do GPT-5.4 mini (por 1M de tokens)
PRICE_INPUT = 0.75
PRICE_INPUT_CACHED = 0.075 # Preço com cache (90% de desconto)
PRICE_OUTPUT = 4.50
def call_gpt54_mini(
messages: List[Dict],
api_key: str,
max_tokens: int = 4096
) -> Dict:
"""
Chamada de nível de produção para o GPT-5.4 mini, com rastreamento de taxa de acerto de cache
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=messages,
max_tokens=max_tokens
)
usage = response.usage
input_tokens = usage.prompt_tokens
output_tokens = usage.completion_tokens
# Tokens de cache (depende da versão do SDK)
cached_tokens = getattr(usage, 'prompt_tokens_details', {}).get('cached_tokens', 0)
regular_input = input_tokens - cached_tokens
# Cálculo de custo segmentado
input_cost = (
regular_input / 1_000_000 * PRICE_INPUT +
cached_tokens / 1_000_000 * PRICE_INPUT_CACHED
)
output_cost = output_tokens / 1_000_000 * PRICE_OUTPUT
total_cost = input_cost + output_cost
cache_rate = cached_tokens / max(input_tokens, 1) * 100
print(f"📊 Entrada: {input_tokens:,} | Cache: {cached_tokens:,} ({cache_rate:.1f}%)")
print(f"📊 Saída: {output_tokens:,} tokens")
print(f"💰 Custo desta chamada: ${total_cost:.4f}")
print(f"💰 Economia com cache: ${(cached_tokens / 1_000_000 * (PRICE_INPUT - PRICE_INPUT_CACHED)):.4f}")
return {
"content": response.choices[0].message.content,
"tokens": {
"input": input_tokens,
"cached": cached_tokens,
"output": output_tokens
},
"cost_usd": total_cost,
"cache_hit_rate": cache_rate
}
except openai.RateLimitError:
return {"error": "Limite de taxa excedido, tente novamente mais tarde"}
except openai.APIError as e:
return {"error": f"Erro na API: {str(e)}"}
# Exemplo de uso
result = call_gpt54_mini(
messages=[
{"role": "system", "content": "Você é um engenheiro Python sênior"},
{"role": "user", "content": "Ajude-me a revisar os problemas de segurança de concorrência neste código..."}
],
api_key="SUA_CHAVE_API"
)
print(result["content"])
🎯 Dica de início rápido: O GPT-5.4 mini já está totalmente aberto no grupo padrão da APIYI. Novos usuários podem realizar chamadas diretamente sem necessidade de solicitação. Recomendamos o acesso via plataforma APIYI (apiyi.com), onde recargas de 100 dólares ganham 10% de bônus, equivalente a cerca de 15% de desconto em relação ao site oficial, com conexão direta e compatibilidade total com o SDK da OpenAI.
Detalhes de Preços da API GPT-5.4 mini
Estrutura de Preços Oficial
O preço do GPT-5.4 mini é um pouco mais alto que a série mini anterior, mas o mecanismo de cache pode reduzir significativamente o custo real:
| Tipo de Cobrança | Preço (por 1M de tokens) | Observação |
|---|---|---|
| Entrada | $0,75 | Preço padrão |
| Entrada em Cache | $0,075 | 90% de desconto, redução drástica de custos |
| Saída | $4,50 | Inclui tokens de raciocínio |
| Entrada Batch API | $0,75 | Mesmo valor da entrada padrão |
| Endpoint de Residência de Dados | +10% | Cenários de conformidade de dados |
Comparação de Preços da Série mini (3 gerações)
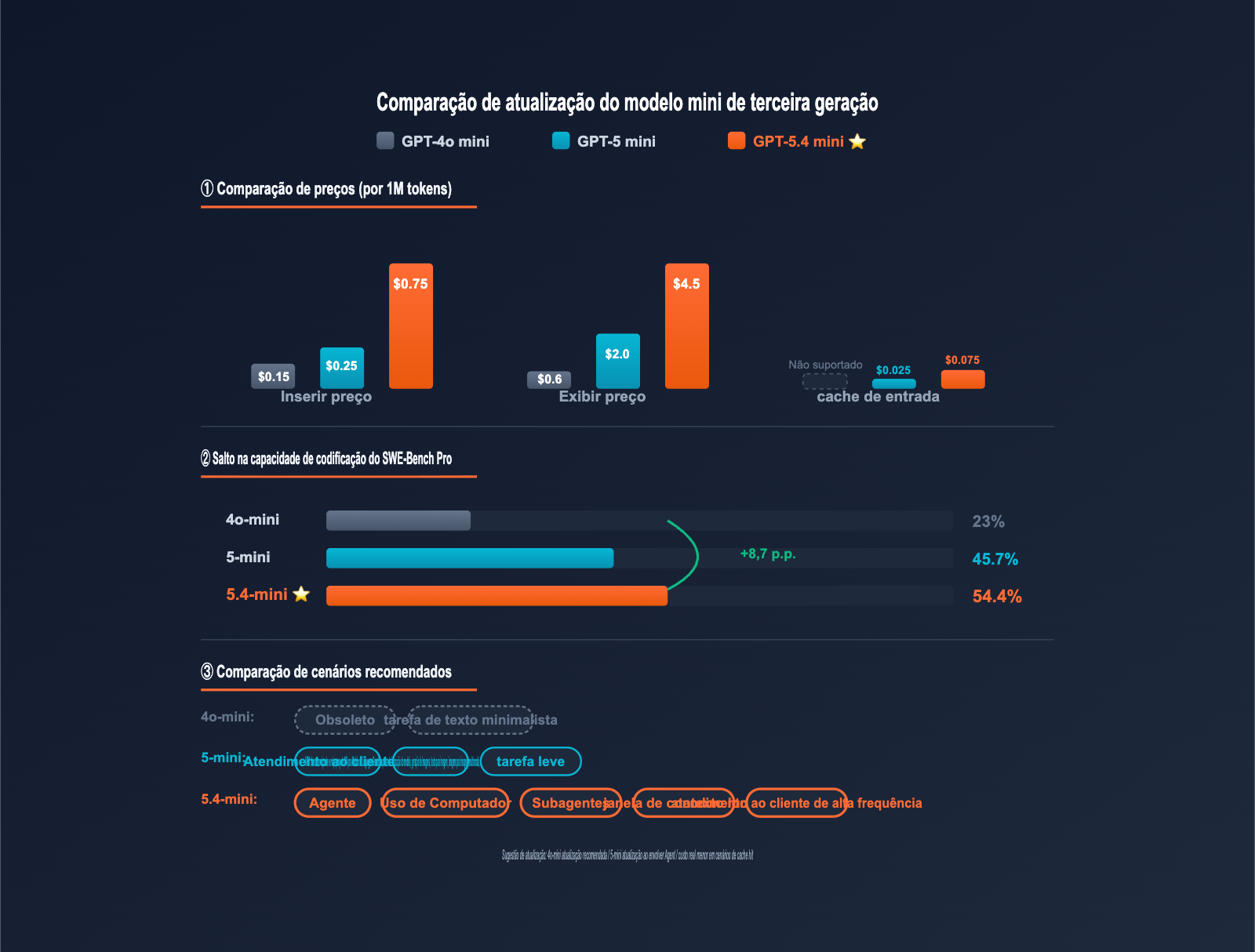
| Modelo | Preço de Entrada | Entrada em Cache | Preço de Saída | Janela de Contexto | Saída Máxima |
|---|---|---|---|---|---|
| GPT-4o mini | $0,15 | Não suportado | $0,60 | 128K | 16K |
| GPT-5 mini | $0,25 | $0,025 | $2,00 | 400K | 128K |
| GPT-5.4 mini | $0,75 | $0,075 | $4,50 | 400K | 128K |
⚠️ Observação importante: O preço padrão do GPT-5.4 mini é 5 vezes maior que o do GPT-4o mini e 3 vezes maior que o do GPT-5 mini. No entanto, considere dois fatos cruciais: 1) Com o cache ativado, o custo por chamada pode cair para $0,0075/1M (em cenários de alta frequência), e 2) O salto de capacidade significa que, muitas vezes, não são necessárias múltiplas rodadas de depuração, reduzindo o número total de chamadas.
Estimativa de Custo em Cenários de Cache
O desconto de 90% no cache do GPT-5.4 mini é a característica mais subestimada desta atualização:
| Cenário | Tokens de Entrada | Taxa de Acerto de Cache | Custo Real por Chamada |
|---|---|---|---|
| Atendimento ao Cliente (reuso de system prompt) | 5K | 80% | $0,0046 |
| Assistente de Código (reuso de contexto) | 50K | 70% | $0,034 |
| Q&A de Documentos Longos (reuso de doc) | 200K | 90% | $0,030 |
| Orquestração de Subagentes (instruções compartilhadas) | 30K | 85% | $0,0162 |
💰 Dica de otimização de cache: O mecanismo de cache do GPT-5.4 mini é mais eficaz em cenários com system prompt longo + contexto repetitivo. Para atendimento ao cliente, assistentes de código e Q&A de documentos, o custo real pode ser até menor que o do GPT-5 mini. Aproveite o bônus de 10% em recargas na APIYI (apiyi.com) para reduzir ainda mais sua fatura.
Salto de capacidade da API GPT-5.4 mini
Comparativo de Benchmark
| Dimensão de Avaliação | GPT-4o mini | GPT-5 mini | GPT-5.4 mini | Aumento |
|---|---|---|---|---|
| SWE-Bench Pro(Codificação) | ~23% | 45.7% | 54.4% | +8.7pp |
| Terminal-Bench 2.0 | ~30% | ~50% | 60.0% | +10pp |
| OSWorld-Verified(Uso de Computador) | Não suportado | ~58% | 72.1% | +14pp |
| Velocidade de resposta | Base | Base | 2x mais rápido | Dobro |
Interpretação da atualização de capacidades
SWE-Bench Pro 54.4%: Este é o dado mais notável do GPT-5.4 mini. Os 54.4% aproximam-se dos 57.7% da versão padrão do GPT-5.4, mas custam apenas 1/6 do preço. Para tarefas como correção de Issues reais no GitHub e refatoração de bases de código, o mini tornou-se uma escolha confiável.
Terminal-Bench 60.0%: Significa que o modelo mini consegue concluir com estabilidade mais de 60% das tarefas de execução de comandos de terminal, depuração e fluxos de trabalho automatizados. Combinado com a orquestração de subagentes, é possível construir aplicações robustas de automação de CI/CD e bots de revisão de código.
OSWorld 72.1%: Este é um avanço histórico para a série mini em tarefas de uso de computador. Agora é possível implantar agentes de automação de desktop com o custo do mini para lidar com formulários, cliques e operações de arquivos.
Comparativo: GPT-5.4 mini vs. Modelos da mesma categoria
| Modelo | Entrada / Saída | Contexto | Capacidade de Codificação | Computer Use | Cenários Recomendados |
|---|---|---|---|---|---|
| GPT-4o mini | $0.15 / $0.60 | 128K | Fraca | Não suportado | Obsoleto, tarefas simples |
| GPT-5 mini | $0.25 / $2.00 | 400K | Média | Suporte parcial | Atendimento ao cliente, tarefas leves |
| GPT-5.4 mini | $0.75 / $4.50 | 400K | Forte | Suporte completo | Agentes / Computer Use / Longo contexto |
| GPT-5.4 Standard | $5.00 / $30.00 | 1M | Topo de linha | Topo de linha | Raciocínio complexo, decisões críticas |
| Claude Haiku 4.5 | $0.80 / $4.00 | 200K | Forte | Não suportado | Escrita criativa / Redação |
Recomendações para a decisão de upgrade
4o-mini → 5.4-mini: O GPT-4o mini ainda mantém uma vantagem de preço em tarefas de texto simples. No entanto, suas capacidades estão significativamente defasadas. Sempre que sua aplicação envolver raciocínio, codificação ou longo contexto, a atualização para o 5.4-mini vale a pena. Mesmo com um custo unitário 5 vezes maior, a melhoria na qualidade e a redução na necessidade de reprocessamento tornam o custo-benefício mais vantajoso.
5-mini → 5.4-mini: O GPT-5 mini ainda é competente para atendimento ao cliente geral e tradução. Mas, se você precisa de Computer Use, orquestração de Subagentes ou fluxos de trabalho de Agentes complexos, o 5.4-mini é a escolha obrigatória. Além disso, embora o desconto de cache permaneça em 90%, o valor absoluto é mais eficiente a longo prazo.
5.4-mini → 5.4 Standard: O GPT-5.4 mini possui capacidades semelhantes em 80% das tarefas rotineiras, custando apenas 1/6 do preço. Apenas quando a tarefa exigir raciocínio de nível superior (provas matemáticas, Agentes complexos de longa duração), você deve migrar para a versão Standard.
📊 Sugestão de caminho para upgrade: Você pode usar o APIYI (apiyi.com) para comparar o desempenho real do 4o-mini, 5-mini, 5.4-mini e 5.4 Standard sob a mesma chave API, bastando alterar o parâmetro
model. Essa forma de acesso unificado é ideal para equipes que precisam realizar migrações graduais ou testes A/B.
Cenários de aplicação da API do GPT-5.4 mini
A combinação de "alta capacidade + otimização de cache + Computer Use + Subagentes" do GPT-5.4 mini é ideal para os seguintes cenários:
- Atendimento ao cliente de alto volume: Alta taxa de acerto de cache, resposta rápida e profundidade de raciocínio suficiente para problemas complexos.
- Geração de conteúdo em larga escala: Resumos, traduções e reescritas em lote; o contexto de 400K permite processar documentos inteiros de uma só vez.
- Colaboração de múltiplos Subagentes: Pela primeira vez, uma orquestração confiável de subtarefas na faixa de preço dos modelos "mini".
- Agentes de automação de desktop: Com 72,1% no OSWorld, torna possível a operação em navegadores, formulários e arquivos.
- Autocompletar e revisão de código leve: Com 54,4% no SWE-Bench Pro, aproxima-se da versão Standard, sendo ideal para integração em IDEs.
- Processamento de documentos em lote: Combinado com a Batch API e cache, oferece uma vantagem de custo extrema para processar milhares de documentos.
- Ferramentas de tutoria educacional: O reforço nos tokens de raciocínio proporciona uma capacidade mais confiável para resolução de problemas e esclarecimento de dúvidas.
🎯 Decisão de cenário: Se a sua aplicação realiza mais de 10 mil chamadas por dia, possui uma taxa de acerto de cache superior a 50% e exige capacidades de raciocínio ou ferramentas, o GPT-5.4 mini é o modelo "mini" mais recomendado para 2026. Você pode acessá-lo diretamente via APIYI (apiyi.com), sem necessidade de solicitações adicionais no grupo Default.
Instruções de Acesso ao GPT-5.4 mini na APIYI
Estratégia de Acesso do Grupo Padrão (Default)
A plataforma APIYI adota para o GPT-5.4 mini uma estratégia de acesso consistente com o Grok 4.3, mas diferente do GPT-5.5 Pro:
- ✅ Grupo Default (Padrão): Totalmente aberto, disponível para novos usuários logo após o registro.
- ✅ Grupo SVIP (Avançado): Totalmente aberto, sem qualquer restrição.
- ✅ Sincronização de Desconto de Cache: Preço de cache de $0,075/1M totalmente aplicável.
Por que o GPT-5.4 mini está aberto para todos os grupos, enquanto o GPT-5.5 Pro está restrito ao SVIP? O núcleo da decisão baseia-se na avaliação de risco por invocação do modelo:
- GPT-5.4 mini: O custo por invocação é geralmente de alguns centavos, sem riscos ao liberar para todos os grupos.
- GPT-5.5 Pro: O custo por invocação pode chegar a alguns dólares, exigindo a proteção do grupo SVIP para evitar uso indevido por iniciantes.
Este design de gerenciamento baseado em risco mantém uma barreira de entrada baixa para a série mini para todos os desenvolvedores, enquanto oferece proteção de grupo para modelos de alto valor.
Comparativo de Custos: APIYI vs. Site Oficial
| Item | Site Oficial OpenAI | APIYI apiyi.com |
|---|---|---|
| Preço Base | $0,75 / $4,50 por 1M | $0,75 / $4,50 por 1M (mesmo preço) |
| Desconto de Cache | $0,075 / 1M (90%) | $0,075 / 1M (totalmente sincronizado) |
| Bônus de Recarga | Nenhum | Recarregue $100 e ganhe $10 (10%) |
| Custo Real | 100% do preço padrão | Aprox. 90% do preço padrão (cerca de 15% de desconto) |
| Acesso no Brasil | Requer VPN | Conexão direta, sem necessidade de VPN |
| Pagamento | Cartão de crédito internacional | Suporte a PIX, Boleto, Cartão (via parceiros) |
| Compatibilidade SDK | Nativo OpenAI | Totalmente compatível com SDK OpenAI |
| Restrições de Grupo | Nenhuma | Default + SVIP totalmente abertos |
💰 Otimização de Custos: Ao acessar o GPT-5.4 mini via APIYI apiyi.com, a recarga de 100 dólares com 10% de bônus equivale a um desconto de 15% em relação ao site oficial, com o desconto de cache totalmente sincronizado. Para aplicações com alto volume de chamadas e alta taxa de acerto de cache, o custo total pode ser mais de 20% menor do que no site da OpenAI.
Perguntas Frequentes (FAQ)
Q1: O que é o GPT-5.4 mini? Qual a principal diferença dele para o GPT-5 mini e o GPT-4o mini?
O GPT-5.4 mini é a nova geração de modelos mini lançada pela OpenAI em 17/03/2026, posicionado como "nosso modelo mini mais forte até hoje". Diferenças principais: 1) SWE-Bench Pro com 54,4%, superando significativamente os 45,7% do GPT-5 mini e 23% do 4o-mini; 2) Suporte completo e inédito para Computer Use (OSWorld 72,1%); 3) Capacidade de orquestração de Subagents na faixa de preço mini; 4) Velocidade de resposta 2x mais rápida que o 5 mini. No entanto, o preço subiu para $0,75/$4,50, sendo possível compensar parte do custo via cache.
Q2: Atualmente uso gpt-4o-mini / gpt-5-mini, vale a pena atualizar para o 5.4-mini?
Usuários do 4o-mini: atualização altamente recomendada. A diferença de capacidade é muito grande; mesmo considerando um preço unitário 5 vezes maior, a qualidade geral e a redução na necessidade de depuração de múltiplas rodadas costumam compensar.
Usuários do 5-mini: depende do cenário:
- ✅ Recomendado atualizar: Aplicações que envolvem Computer Use, Subagents, cadeias de ferramentas complexas ou contexto longo (>200K).
- ⏸️ Pode continuar usando: FAQ de atendimento ao cliente simples, tradução leve, geração de texto puro, etc., onde o 5-mini já é suficiente.
Melhor prática: execute um teste A/B usando a mesma chave API na APIYI apiyi.com para verificar qual é mais vantajoso.
Q3: Como ativar o desconto de cache de $0,075/1M do GPT-5.4 mini?
O mecanismo de cache da OpenAI é acionado automaticamente, sem necessidade de parâmetros extras. Quando o prefixo do seu comando (geralmente o system prompt + contexto compartilhado) coincide com solicitações feitas nos últimos 5-10 minutos, o cache é atingido automaticamente, garantindo o desconto de 90% ($0,075/1M).
Dicas de otimização:
- Coloque o system prompt no início do array de mensagens.
- Coloque o contexto compartilhado (como base de conhecimento, resumo de documentos) após o system prompt.
- Coloque a consulta real do usuário no final.
- Mantenha chamadas de alta frequência (expira após >5 minutos).
Ao realizar a invocação pela plataforma APIYI apiyi.com, o desconto de cache é totalmente sincronizado com o site oficial, sem necessidade de configuração adicional.
Q4: Quando usar o GPT-5.4 mini e quando usar a versão padrão do GPT-5.4?
Cenários para priorizar o mini:
- Alto throughput (>10K chamadas/dia).
- Taxa de acerto de cache > 50%.
- Tarefas do tipo SWE-Bench / Terminal-Bench.
- Automação via Computer Use.
- Ambientes de produção sensíveis a custos.
Cenários para priorizar a versão padrão:
- Provas matemáticas de nível FrontierMath.
- Agentes complexos de longa duração (nível de 20 horas).
- Tarefas de alto risco, como leitura detalhada de contratos jurídicos ou diagnósticos médicos.
- Decisões críticas onde o valor de uma única chamada é > $0,10.
Princípio simples: 80% das tarefas são bem atendidas pelo mini; suba para a versão padrão apenas para raciocínios extremamente complexos.
Q5: Como invocar o GPT-5.4 mini via APIYI? Quais códigos preciso alterar?
A APIYI é totalmente compatível com o SDK da OpenAI, basta seguir três passos:
- Acesse APIYI apiyi.com e registre uma conta (sem necessidade de solicitação, o grupo Default está disponível imediatamente).
- Obtenha sua chave API.
- Altere o
base_urldo código parahttps://vip.apiyi.com/v1e defina omodelcomogpt-5.4-mini.
client = openai.OpenAI(
api_key="SUA_CHAVE",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[...]
)
Recarregue 100 dólares e ganhe 10% de bônus, equivalente a cerca de 15% de desconto em relação ao site oficial, com desconto de cache totalmente sincronizado.
Q6: O GPT-5.4 mini suporta ajuste fino (Fine-tuning)?
Não suporta. Esta é uma das principais limitações atuais do GPT-5.4 mini. Se sua aplicação exige obrigatoriamente fine-tuning, você precisará escolher:
- GPT-5 mini (suporta fine-tuning, capacidade ligeiramente inferior).
- GPT-4o mini (suporta fine-tuning, capacidade mais fraca).
- GPT-5.4 versão padrão (suporta fine-tuning, preço 6 vezes maior).
Alternativa: O Reasoning Token + Function Calling + mecanismo de cache do GPT-5.4 mini geralmente alcançam ótimos resultados sem a necessidade de fine-tuning.
Q7: Como invocar o Computer Use do GPT-5.4 mini?
Ative através do parâmetro tools:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": "Ajude-me a abrir o navegador e pesquisar..."}],
tools=[{
"type": "computer_use",
"config": {"screen_width": 1920, "screen_height": 1080}
}]
)
O modelo retornará instruções de operação estruturadas (click/type/scroll/screenshot). Você precisará implementar essas ações no cliente e enviar os resultados de volta ao modelo para continuar o raciocínio. A pontuação de 72,1% no OSWorld-Verified significa que a maioria das tarefas de desktop pode ser concluída.
Q8: Quais são as limitações conhecidas do GPT-5.4 mini?
As principais limitações incluem:
- Não suporta Fine-tuning: Não é possível ajustar com conjuntos de dados personalizados.
- Não suporta saída de imagem: Apenas saída de texto, não pode gerar imagens.
- Preço superior aos mini antigos: O preço padrão é 5 vezes o do 4o-mini, exigindo otimização com cache.
- Reasoning Token contabilizado na saída: O custo de saída para tarefas complexas pode exceder as expectativas.
- Residência de dados regional +10%: Cenários de conformidade possuem custos adicionais.
Para cenários extremamente sensíveis à latência (resposta < 1 segundo), recomenda-se realizar testes antes de decidir pela migração.
Principais pontos do GPT-5.4 mini API
- Salto de capacidade: 54,4% no SWE-Bench Pro, superando os 45,7% do GPT-5 mini em 8,7 pontos percentuais.
- Desconto em cache: 90% de desconto no cache de entrada a $0,075/1M, reduzindo drasticamente os custos em cenários de alta frequência.
- Computer Use: 72,1% no OSWorld; a série mini suporta pela primeira vez a automação de desktop completa.
- Amigável a Subagentes: Pela primeira vez, a colaboração multi-agente é disponibilizada na faixa de preço da série mini.
- Janela de contexto de 400K: Processa livros técnicos inteiros ou bases de código completas de uma só vez.
- Velocidade de resposta 2x: Velocidade dobrada mantendo o salto de capacidade.
- Acesso total padrão: Disponível diretamente no grupo padrão da APIYI, sem necessidade de solicitações.
Resumo
Os pontos principais da API GPT-5.4 mini são:
- Motivação da atualização: Salto abrangente nas três dimensões principais (SWE-Bench Pro / Terminal-Bench / OSWorld), com Computer Use e Subagentes chegando pela primeira vez à faixa de preço da série mini.
- Posicionamento de preço: $0,75 / $4,50 por 1M, com 90% de desconto no cache de entrada a $0,075. Em cenários de alta frequência, o custo real pode ser inferior ao do mini antigo.
- Como acessar: Chame diretamente através do grupo padrão da APIYI (apiyi.com). Recarregue 100 e ganhe 10; conexão direta no país sem necessidade de VPN.
O GPT-5.4 mini não é apenas uma "versão mais cara do GPT-5 mini", mas um passo fundamental da OpenAI para levar capacidades de agentes para a faixa de preço de entrada. Para aplicações que realizam > 10 mil chamadas por dia, possuem taxa de acerto de cache > 50% ou necessitam de capacidades de Agente ou Computer Use, esta atualização é praticamente obrigatória. Para tarefas de texto simples, o GPT-4o mini / GPT-5 mini ainda podem ser utilizados.
Recomendamos o acesso rápido ao GPT-5.4 mini através da plataforma APIYI (apiyi.com): o grupo padrão não requer solicitação, os descontos de cache são totalmente sincronizados, há bônus de 10% na recarga e a conexão é estável e direta.
Leitura Complementar
Se você se interessou pela API do GPT-5.4 mini, recomendo continuar a leitura:
- 📘 Guia de Integração da API GPT-5.5 Pro – Conheça o modelo de raciocínio de elite da OpenAI, que complementa perfeitamente o mini em diversos cenários.
- 📊 Análise Profunda do Mecanismo de Cache da OpenAI: Melhores Práticas para 90% de Desconto – Domine as técnicas de engenharia para otimização de cache.
- 🚀 Prática de Agente de Automação com Computer Use Baseado no GPT-5.4 mini – Explore aplicações de nível de produção para automação de desktop.
📚 Referências
-
Documentação Oficial do Modelo GPT-5.4 mini da OpenAI: Especificações do modelo, precificação e exemplos de invocação.
- Link:
developers.openai.com/api/docs/models/gpt-5.4-mini - Descrição: Obtenha os parâmetros técnicos oficiais mais recentes e confiáveis.
- Link:
-
Avaliação do GPT-5.4 mini pela DataCamp: Detalhamento dos benchmarks e comparação entre gerações.
- Link:
datacamp.com/blog/gpt-5-4-mini-nano - Descrição: Avaliação independente de terceiros, ideal para comparar modelos similares.
- Link:
-
Documentação de Integração do GPT-5.4 mini na APIYI: Soluções de invocação, explicações de grupos e promoções de recarga.
- Link:
docs.apiyi.com - Descrição: Guia prático de integração voltado para desenvolvedores.
- Link:
-
Página de Preços da OpenAI: Tabela completa de preços e explicações sobre o mecanismo de cache.
- Link:
developers.openai.com/api/docs/pricing - Descrição: Padrões de cobrança mais recentes para todos os modelos.
- Link:
Autor: Equipe Técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir sua experiência com a atualização do GPT-5.4 mini na seção de comentários. Para mais materiais sobre integração de modelos, visite a central de documentação da APIYI em docs.apiyi.com.